Abstract
The Enhancing NeuroImaging Genetics through Meta-Analysis (ENIGMA) Consortium is a collaborative network of researchers working together on a range of large-scale studies that integrate data from 70 institutions worldwide. Organized into Working Groups that tackle questions in neuroscience, genetics, and medicine, ENIGMA studies have analyzed neuroimaging data from over 12,826 subjects. In addition, data from 12,171 individuals were provided by the CHARGE consortium for replication of findings, in a total of 24,997 subjects. By meta-analyzing results from many sites, ENIGMA has detected factors that affect the brain that no individual site could detect on its own, and that require larger numbers of subjects than any individual neuroimaging study has currently collected. ENIGMA’s first project was a genome-wide association study identifying common variants in the genome associated with hippocampal volume or intracranial volume. Continuing work is exploring genetic associations with subcortical volumes (ENIGMA2) and white matter microstructure (ENIGMA-DTI). Working groups also focus on understanding how schizophrenia, bipolar illness, major depression and attention deficit/hyperactivity disorder (ADHD) affect the brain. We review the current progress of the ENIGMA Consortium, along with challenges and unexpected discoveries made on the way.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Origins of brain imaging in human populations
During the “Decade of the Brain” in the 1990s (Jones and Mendell 1999), a number of major neuroimaging centers began to scan hundreds of patients and healthy individuals using a variety of neuroimaging methods. The accelerating pace of data collection was driven mainly by the wide availability of MRI around the world. The structure and function of the living brain was beginning to be mapped in unprecedented detail in human populations.
In a typical neuroimaging study—both now and 20 years ago—between ten and a few hundred subjects might have been scanned, and statistical models would be fitted to identify factors that affect brain structure and function. Early studies—such as lesion studies—correlated radiological measures with clinical diagnosis and behavior, but the study of large populations represented a new movement in human brain mapping. Fundamental questions in neuroscience could now be examined—what are the effects of aging, degenerative disease and psychiatric illness on the living brain? How do brain measures relate to cognition and behavior? Do brain measures predict our risk for disease, or prognosis in those who are ill?
There was growing confidence that questions of broad societal and medical impact could be better understood if enough brain scans were collected—projects were initiated to examine effects on the brain of psychiatric medications, drugs and alcohol abuse, dietary factors, and many other factors including education, cardiovascular fitness, as well as pharmacologic and behavioral interventions.
At the same time, the broad availability of brain scans led to the development of widely adopted tools to analyze the resulting data. Software such as Statistical Parametric Mapping (SPM; Friston et al. 1995; Frackowiak 1997), FSL (Jenkinson et al. 2012), BRAINS (Pierson et al. 2011) and FreeSurfer (Fischl et al. 2004) among many other tools, were widely distributed over the internet. This made it feasible to analyze neuroimaging data and compute standardized measures from brain scans in a consistent and agreed way, albeit with methods that are continually refined.
Early neuroimaging consortia
Early consortium efforts in neuroimaging included the International Consortium for Brain Mapping (ICBM; Mazziotta et al. 1995), which recognized the need to establish normative data on the brain from a wide range of human populations scanned in different parts of the world. The ICBM began with an effort to scan around 150 healthy subjects in Los Angeles, Montreal, and San Antonio, Texas, and grew to include sites in Europe and Asia that broadened the age range and ethnic groups assessed. Later, the ICBM also extended the depth of the neuroimaging measures to include functional MRI and even post mortem histology and cytoarchitecture (Amunts et al. 1999).
Given the wide variations in brain anatomy even among healthy subjects, consortia such as the ICBM developed a range of “average” anatomical templates based on MRI scans of hundreds of healthy subjects. Analysis software for brain images disseminated these average brain templates, and provided methods to relate new data to previously compiled atlases and data collections. This led to the notion of statistical representations of imaging signals in standardized coordinate spaces—or “statistical parametric maps”. The wide adoption of these standard spaces—such as the ICBM or MNI (Montreal Neurological Institute) spaces—was eased by the development of automated registration and alignment methods (Woods et al. 1993; Collins et al. 1994; Ashburner et al. 1999; Jenkinson et al. 2002) that allowed researchers to rapidly align their own data to the templates. This effort led to the rise of voxel-based morphometric approaches and statistical mapping approaches in general. These developments also allowed any group to compare and contrast their findings with ongoing findings from other groups around the world—a movement that was stimulated by the development of the Talairach and Tournoux brain atlases, which defined anatomical regions in stereotaxic space (Talairach et al. 1993). The Talairach atlas was among the first to compile a coordinate-based reference system, and it allowed researchers worldwide to relate their findings to existing data collections. In the mid-1990s, a group in San Antonio developed the “Talairach Daemon”, allowing electronic pooling of findings from brain mapping studies based on their coordinates in Talairach space. In addition to the use of standard anatomical templates for reporting results, this coordinate system opened the door for clinically-oriented consortia to scan and analyze large-scale patient populations in a consistent way. The rapid development of nonlinear registration methods also made it possible to improve the alignment of new datasets to digital anatomical templates, for coordinate based reporting of results.
The Alzheimer’s Disease Neuroimaging Initiative (ADNI), for example (Weiner et al. 2012), scanned around 800 people in its first phase, including healthy elderly people, individuals with mild cognitive impairment and patients with Alzheimer’s disease. ADNI began in 2005, after testing the feasibility and reproducibility of a range of scanning protocols. This led to standardized scanning methods implemented at 58 sites across North America (Leow et al. 2009; Jahanshad et al. 2010; Jack 2012; Zhan et al. 2012). Many other neuroimaging consortia have been established, including the functional Brain Imaging Research Network (FBIRN) (Potkin and Ford 2009) which has developed standardized methods for multi-center functional MRI studies (Glover et al. 2012) and the Mind Clinical Imaging Consortium (Gollub et al. 2013) focusing on schizophrenia, as well as research networks focusing on pediatric imaging (Evans 2006), autism (Ecker et al. 2013), HIV/AIDS (Cohen et al. 2010) and many others. In fact, the successes of these multi-site initiatives have led to large-scale neuroimaging efforts being initiated and funded in other countries (Carrillo et al. 2012; Alzheimer’s Association 2013; White et al. 2013).
Genome-wide association studies (GWAS)
At the same time, a number of genetic studies using twin or family-based designs had shown that many brain-derived measures were significantly heritable (Thompson et al. 2001; Baaré et al. 2001; White et al. 2002; Wright et al. 2002; van Erp et al. 2004a, b; Hulshoff Pol et al. 2006; Winkler et al. 2010; Kochunov et al. 2010; Blokland et al. 2012; Koten et al. 2009). In other words, a substantial fraction of the variability in brain measures—especially structural but also some functional measures, and even brain metabolites (Batouli et al. 2012)—could be explained by genetic relationships among individuals. The total amount of gray and white matter in the brain, the overall volume of the brain—and even activation patterns on fMRI or connections tracked with diffusion MRI—were more similar among family members than unrelated individuals (Peper et al. 2007; Koten et al. 2009; Glahn et al. 2010; Brouwer et al. 2010; Fornito et al. 2011; Blokland et al. 2012; Jahanshad et al. 2013a; Thompson et al. 2013; Van den Heuvel et al. 2013).
Arguably, it is equally important to identify regions or measures with low heritability as well. The reliability of imaging measures varies considerably by region or network, and so does the ability to detect heritability, even if present. Such information is immensely useful in constraining the potential phenotypes worth pursuing and interpreting results; we consider this further below.
Despite the high heritability of many brain measures (h2 up to 0.89; Kremen et al. 2009; or even up to 0.96: van Soelen et al. 2012), the specific genetic variants that contribute to this variability remain largely unknown. A possible exception is the Alzheimer’s disease (AD) risk gene, APOE: carriers of one or more risk-conferring alleles (APOE4) demonstrate accelerated gray matter loss with age (Lu et al. 2011). They also have a roughly three-fold increased risk for late-onset AD, for each risk allele they carry (Corder et al. 1993). In a recent meta-analysis of 35 prospective cohort studies with an average follow-up of 2.9 years, the odds ratio for conversion from mild cognitive impairment to Alzheimer’s dementia in APOE4 carriers was determined to be 2.29, relative to non-carriers (Elias-Sonnenschein et al. 2011). Other prior papers reported a higher odds ratio, around 4 for heterozygotes and >7 for homozygotes, with some differences depending on the ancestry of the cohort. According to another more recent review, one copy of ApoE4 increases risk by ~2.6–3.4, and homozygotes for ApoE4 have an odds ratio of 14.9 compared to the reference genotype of E3/3 (Liu et al. 2013).
A number of groups around the world began to perform GWAS on measures derived from brain images, with the goal of finding new genetic variants that might account for more of the variation in brain structure and function, and also for disease risk. The genetic variants of interest in a GWAS are single nucleotide polymorphisms, or SNPs, commonly carried variants in the genetic code. SNPs are DNA sequence variations that occur when a single nucleotide (A, G, C, or T) is altered; SNPs are thought to be point mutations that were not so damaging that evolution allowed them to be retained in a significant proportion of the population of a species. Within a population, SNPs can be assigned a minor allele frequency—the proportion of chromosomes in the population carrying the less common variant. Figure 1 illustrates the ideas behind this approach. Before we discuss GWAS, it is worth noting a distinction between narrow and broad-sense heritability: broad-sense heritability is the proportion of variation in a phenotype (here, individual variations in brain measures) that can be explained by genetic effects. These effects may include dominance and epistasis—interactions between SNPs or genes in different parts of the genome. The narrow-sense heritability is the proportion of variance in a brain measure that is accounted for by additive genetic factors (and this is typically a smaller proportion of the trait variance). These additive genetic effects are the types of statistical effects that GWAS aims to detect.

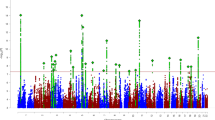
Steps involved in a genome-wide association study. A heritable brain measure (or “phenotype”) - which could be binary, such as a disease state, or continuous, such as the intracranial volume (ICV) - is extracted from brain imaging scans from a large group of people. To determine if there is any statistical association between this brain measure and the inter-subject variations at a single SNP, the genetic variations among individuals can be assessed at a single location along the genome, and correlated with differences in the trait of interest (here, ICV). Genome-wide association scans involve an unbiased search across the whole genome to discover novel genetic loci associated with the trait. Testing a million or more SNPs requires a strict multiple comparisons correction threshold, to avoid reporting spurious results; normally, credible findings have to achieve a significance value more extreme than p < 10−8. The so-called “Manhattan plot” on the right (by analogy with the Manhattan skyline in New York) displays the −log10 of the p-value for associations between the brain measure and genetic variation at each position along the genome; the higher the point on the plot, the more likely it is that an association exists. Of course, it is important not to see genome-wide significance as a “binary state”, whose conditions are either fulfilled or not—but rather a measure of the level of evidence for a genetic association. Findings in these plots must typically be replicated in several independent cohorts before they are considered credible or generalizable
In a typical GWAS analysis, one might test ~2.5 million common SNPs in the genome, to see if any of these genetic variants are associated with a trait, such as a brain-derived measure, or a specific disease such as AD. Although not the only important type of genetic variation, SNPs can be measured using readily available genotyping arrays, and individually provide adequate statistical power as the variants are common enough to test their effects statistically. Because only selected SNPs capturing the variability of the genome are genotyped, many authors have argued that this genotyping technology is much less expensive than whole-genome sequencing. However, new technologies using low coverage sequencing with imputation may in some cases yield several times the effective sample size of GWAS based on SNP array data, and a commensurate increase in statistical power as described in Pasaniuc et al. (2012).
GWAS has had many successes. Many common polymorphisms have now been found that increase genetic risk for AD (Harold et al. 2009; Lambert et al. 2009; Naj et al. 2011), age-related cognitive decline (Davies et al. 2012), schizophrenia (Almasy et al. 2008; Stefansson et al. 2009; Ripke et al. 2011; Rietschel et al. 2012), bipolar disorder (Sklar et al. 2011; Cichon et al. 2011) as well as obesity (Yang et al. 2012), alcohol drinking (Schumann et al. 2011), tobacco smoking (Thorgeirsson et al. 2008), cardiovascular disease (CARDIoGRAMplusC4D Consortium et al. 2013), osteoporosis (Estrada et al. 2012), prevalent psychiatric disorders (Cross-Disorder Group of the Psychiatric Genomics Consortium et al. 2013) and for many other traits and diseases.
Imaging may play a role in finding out how these genes create risk for illness through their impact on the brain, by comparing brain scans of carriers versus non-carriers. One such example is the ZNF804A story. A variant within ZNF804A was the first genome-wide significant SNP associated with risk for schizophrenia (O’Donovan et al. 2008). The function of this variant was initially not clear. Prominent papers later appeared (e.g., Esslinger et al. 2009) using imaging to establish disturbed connectivity as a neurogenetic risk mechanism for psychosis. They showed that some variant in ZNF804A (or some variations in linkage disequilibrium with them) must be functional in the human brain. This was one of many early studies to validate the intermediate phenotype strategy in psychiatry.
Ongoing work comparing genome-wide data from patients with AD and healthy elderly people had begun to unearth a growing set of new AD risk genes (Bertram 2009). By 2009, meta-analyses of GWAS from multiple elderly cohorts had implicated a trio of new AD risk genes—CLU, CR1 and PICALM (Harold et al. 2009). Each of these appeared to affect AD risk by around 10–20 %, consistently, in cohorts around the world (Logue et al. 2011). Additional AD risk variants were rapidly discovered as GWAS expanded to more populations with dementia and healthy controls (Hollingworth et al. 2011).
A flurry of such studies occurred—some showed brain differences in Alzheimer’s disease risk gene carriers a full 50 years before AD typically strikes (Braskie et al. 2011; Bralten et al. 2011). Others showed a pattern of brain changes in unaffected carriers that resembled the “footprint” of Alzheimer’s disease in the living brain (Biffi et al. 2010; Erk et al. 2011, Rajagopalan et al. 2013). These findings will require follow-up but illustrate the potential of using neuroimaging measures to explore the effects of genetic variation.
But a much more adventurous goal provided the driving force behind the new and emerging fields of imaging genomics. This goal was to use neuroimaging data directly, to screen the genome for common variants that might affect the brain. In other words, rather than using the images in secondary studies of what disease risk genes do, images could be screened to discover important genetic associations. (Instead of imaging genetics, the somewhat interchangeable term “imaging genomics” is also used; genomics tends to refer to any method that directly assesses variation in the genome, as opposed to studies that may assess a single locus only, or simpler family studies that may not even analyze DNA). The growing computational power to screen very large neuroimaging datasets—for the purpose of extracting meaningful features from them—made this an interesting and achievable objective. Advocates of “imaging genetics”—the genetic analysis of brain images (Glahn et al. 2007; Turner et al. 2006)—suggested that it might even be more efficient to screen traits derived from brain images to provide endophenotypes for brain disorders.
The main motivation to screen brain images was to find some heritable measure of disease burden that might be closer to the underlying genetic effect than clinical diagnosis based on cognitive and clinical tests. The endophenotype hypothesis, long advocated by psychiatric geneticists such as Irving Gottesman (Gottesman and Gould 2003; Blangero 2004; Goldman 2012; White and Gottesman 2012; Kendler and Neale 2010) suggested that one might fruitfully apply genetic screening to any reliable and heritable biomarkers of a disease—measures from the blood or cerebrospinal fluid (CSF), or even from brain scans, which by now had become quite plentiful. The original definition of “endophenotype” for an illness or disorder (see Gottesman and Gould 2003) suggested that an endophenotype should (i) be associated with the illness/disorder of interest, (ii) be heritable, (iii) be state-independent, i.e., seen in people even when they do not show symptoms of the illness/disorder, (iv) co-segregate with illness/disorder within families, and (v) be observed in relatives of affected family members at a higher rate than in the general population.
The search for endophenotypes of disease, for genetic analysis, is related to the goal of finding biomarkers for AD or any psychiatric illness, although the quest for biomarkers pre-dated efforts to find endophenotypes of disease. In addition, biomarkers may not be stable, as they may change during the disease course. The term “biomarkers” has been used with many different meanings, but in general biomarkers are measures of disease burden that can be objectively quantified, ideally allowing more objective or earlier diagnosis, and making it easier to test the effects of treatment or prevention.
Advocates of using imaging for genetic analysis pointed to several advantages that imaging provides now, as well as several potential advantages that it could provide in the foreseeable future. First, neuroimaging can yield reproducible measures of brain structure and (perhaps to a lesser extent) brain function. Structural measures of the brain, from MRI, tend to have relatively high reproducibility across measurement methods, and are generally consistent with expert tracings of the same structures (see Supplement of Stein et al. 2012; many studies have investigated the reliability of measures from brain MRI, e.g., Pengas et al. 2009). In a recent GWAS analysis, Holmes et al. (2012) showed high reliability for automated brain volumes of hippocampus (r = .98), amygdala (r = .91), and intracranial volume (r = .99) for a cohort of data collected across investigators and matched scanners. Nugent et al. (2012) also studied the inter-scanner reliability of the FIRST software for segmentation (Patenaude et al. 2011), and found it to be high. However, it is overly optimistic to always expect high reproducibility from automated segmentations of brain MRI, and the reproducibility is region specific. For example, both FSL and FreeSurfer tend to do less well in segmenting small structures relative to larger structures. There are also differences in accuracy and reliability among different methods for automated segmentation of the brain (Shokouhi et al. 2011). Cortical thickness and other local gray matter density measures can show reduced reliability owing to sensitivity to image contrast variability, which becomes particularly challenging in multicenter studies (Schnack et al. 2010). The volumes of some structures, such as the caudate, may even show systematic biases in certain populations because of tissue class ambiguity that arises as a consequence of white matter degradation near gray matter structures. Some cortical regions are also difficult to delineate accurately due to the large intersubject variability. As noted below, one goal of ENIGMA has been to screen brain measures for reproducibility, heritability, and association with disease, to see which ones are likely to be promising for genetic analysis (we return to this topic below; see also Table 1).
Second, measures of brain volume, integrity, receptor distribution, or chemical composition, might be more directly related to the function of genes—both genes whose function is unknown, and known candidate genes—such as growth factors, transcription factors, guidance molecules, or neurotransmitters and their transporters. Many of these had already been implicated in the risk for psychiatric illness, and imaging offered the opportunity to study differences in brain connectivity or function, in carriers of genetic variants associated with disease risk. In the future, advanced MRI methods such as [1H]MR spectroscopy could be used for population genetic studies of the brain’s chemical composition, or PET studies to measure receptor distribution, but work soon began in earnest on the genetic analysis of more common and widely available types of brain scans—MRI and DTI (Diffusion Tensor Imaging).
At the same time, some seasoned geneticists were skeptical about imaging genetics. Concerns were raised about the costs of image acquisition, relative to a standard psychiatric diagnostic test. For a study to be feasible, the cost of data collection must be borne in mind, regardless of which method is ultimately more efficient in discovering genes and mechanisms contributing to brain disease.
By 2009, a number of GWAS studies had been performed on neuroimaging data. Among the first studies to report a positive finding—a so-called “genome-wide hit”—was the report by (Potkin et al. 2009a) that identified a key genetic variant in TOMM40, in linkage disequilibrium with APOE, the known risk gene for AD. Using hippocampal atrophy as a quantitative phenotype in a genome-wide scan, they assessed 381 participants in the ADNI (Alzheimer’s Disease Neuroimaging Initiative) study, to identify SNPs for which there was an interaction between the genotype and diagnosis on the quantitative trait. Variants in TOMM40 appeared to affect hippocampal volume differently in AD patients versus controls. Working with genetic-founder populations, some GWAS-based studies revealed genome-wide hits in relatively small samples; in the Saguenay Youth Study, genetic variations in the KCTD8 region were associated with brain size in a community-based sample of adolescent girls (rs716890, P = 5.40 × 10−9); (Paus et al. 2012). Furthermore, genotype in the top hit (rs716890) interacted with prenatal exposure to maternal cigarette smoking vis-à-vis cortical area and cortical folding; in exposed girls only, this genotype explained ~21 % of variance in the cortical area (Paus et al. 2012).
The ADNI work analyzed a publicly available dataset (adni.loni.usc.edu) for which MRI scans and GWAS data could be freely downloaded from approximately 800 people. The ease of access of the ADNI data, and the principle of broad dissemination of the genomic data with fairly few restrictions led to over 100 genetic studies of the ADNI data, many of them using GWAS designs (Saykin et al. 2010).
The ADNI dataset stimulated work in imaging genetics, as evidenced by the large number of published papers using the data (all ADNI genetics studies from the period 2009–2012,are reviewed by Shen et al., 2013; this volume). Even so, data from other elderly cohorts is needed to determine how well ADNI’s genetic findings generalize to other non-selected cohorts. ADNI deliberately selected participants who are predominantly Caucasian, and relatively free from drug or alcohol abuse and vascular disease. Genetic associations detected in ADNI may be stronger or weaker, or even not supported at all, in cohorts with different ethnic composition, or with other co-morbid health conditions. Because of this, it is important to recognize that some genetic associations may depend on the cohort studied, diagnostic or demographic criteria, and we should not expect all true genetic associations to be detectable in all cohorts.
Sample sizes and power for GWAS
As with other phenotypes, the first GWAS findings for imaging phenotypes were difficult to replicate, probably due to the limited availability of replication samples. Prior work had cautioned that, using the most standard kind of univariate analysis of SNP effects, very large sample sizes would be required—far larger than a typical neuroimaging study—to discover influential genetic variants, unless their effect sizes on the brain phenotypes being analyzed were unusually large (Potkin et al. 2009b). The power of a GWAS study depends on the number of null genetic variants assessed, the expected effect size of the genetic variant (typically less than 1 % of the trait variance), and the population frequency of the variant (Potkin et al. 2009b; Flint et al. 2010; Paus et al. 2012). The power obviously also depends on the genetic architecture of the trait—key factors are the large number of effectively independent LD regions in the genome (regions of linkage disequilibrium, with correlated SNPs) and the number of detectable causal loci per phenotype (which is typically small). The first series of studies identifying genetic markers for MRI phenotypes that replicated across independent samples, used a Norwegian discovery sample and replicated the findings in the ADNI or PING cohorts (Joyner et al. 2009; Rimol et al. 2010; Bakken et al. 2012).
Even for high frequency variants, neuroimaging databases of 1,000 subjects would be underpowered to detect commonly observed effect sizes. We must bear in mind that, in the standard experimental design (see below for others), the significance of a genome-wide hit has to be at least 20 million to one, to account for the very large number of variants tested. Some have argued that neuroimaging studies reporting effects of candidate genes—such as COMT or BDNF—are also at risk for false positive effects, in the sense that any number of genes could have been assessed, with no way to verify whether the paper was selectively reporting the successes (Flint and Munafo 2013; Ioannidis 2005). While this problem is shared by selective reporting of results in many fields, imaging genetics is particularly at risk because of the ease of retesting the same data. Some have raised the concern that a considerable proportion of neuroimaging genetics associations, especially those found in small samples, may not replicate in subsequent analysis. Clearly, although the number of genes in the human genome is limited, an almost unlimited number of candidate genes could be still tested (Bishop 2013; Flint and Munafo 2013).
Even so, others have argued that this might be an obvious but not in itself sufficient argument for needing very large sample sizes, as it does not take into account the increase in effect sizes enabled by careful selection of phenotypes (this is an area of neuroimaging research in itself; see Table 1), nor corroborative evidence from other sets of data, nor independent replication of top hits—which is commonly performed in GWAS studies. Clearly, an alternative way to avoid false positives is to collect additional functional evidence for a variant (the “convergent approach”). A final approach is to focus on candidate variants with known molecular function, and there is a long tradition of work relating genetic variants in the monoamine neurotransmitter pathways to risk for psychiatric illness. For instance, lower hippocampal but larger amygdala volumes have been associated with the long variant of the serotonin transporter polymorphism in major depression (Frodl et al. 2004, 2008), and variants in the 5-HT1A receptor gene have been related to amygdala volume in borderline personality disorder (Zetzsche et al. 2008). Variants in the Huntington’s disease gene have also been shown to affect normal brain structure (Mühlau et al. 2012).
As the field began to come to terms with the sample sizes needed to demonstrate or replicate a genome-wide hit, alliances began to form and some studies reported genetic associations with volumetric brain measures supported by evidence from more than one cohort. Stein et al. (2011) reported a variant associated with caudate volume in young and old cohorts scanned on two continents at two different field strengths. Hibar et al. (2013b) also reported a variant associated with the volume of the lentiform nucleus on MRI scans. In some of these reports, a meta-analysis approach was used, to combine the evidence for genetic association across cohorts, in a way that weights the cohorts by their sample size or error variance.
Formation of the ENIGMA Consortium and first project (ENIGMA1; Stein et al. 2012)
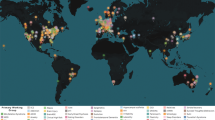
In December 2009, a group of researchers expert in large-scale neuroimaging or large-scale genetics studies formed a network called “Enhancing NeuroImaging Genetics through Meta-Analysis” or ENIGMA. The goal of the effort was to bring together researchers with genome-wide data and images, to meta-analyze evidence in neuroimaging datasets worldwide (see Fig. 2).

ENIGMA founding sites. The first ENIGMA project (Stein et al. 2012) was initiated in 2009, by a consortium of research groups worldwide involved in neuroimaging and genetics. Several existing consortia and research networks are taking part, including IMAGEN, EPIGEN, SYS, FBIRN, and ADNI. Many of these efforts pre-dated ENIGMA and continue today; each conducts its own projects in addition to their collaborative work within ENIGMA. ADNI collects data at 58 sites around the U.S.; for clarity, not all data collection sites are shown here. Each symbol represents a site contributing to ENIGMA, as of June 2013
In Stein et al. (2012), the ENIGMA consortium, in collaboration with another multi-site consortium (CHARGE; Seshadri et al. 2010; Fornage et al. 2011; Bis et al. 2012; Ikram et al. 2012) reported that the mean bilateral volume of the hippocampus was significantly associated with the intergenic variant rs7294919 (see Forest plots, Fig. 3).

Forest plots from the ENIGMA1 study (adapted from Stein et al. 2012). Forest plots are a graphical display designed to illustrate the relative strength of an effect in different cohorts. In the left panel, we show the effect of the genetic variant at rs7294919 on the hippocampal volume, in a range of cohorts in ENIGMA. In ADNI, for example, the confidence interval on the effect overlaps zero, which means that there is no evidence to reject the hypothesis of no effect, if only that cohort were considered. The “ENIGMA Discovery” line combines the effects of all cohorts above it. At the bottom of the figure, the meta-analysis of all effects above the line includes data from another large consortium, CHARGE, and several replication samples. The area of each square is proportional to the study’s weight in the meta-analysis. The right panel shows a similar plot for the effect on intracranial volume of the common genetic variant at rs10784502. It is not necessary for the effect to be detected in all cohorts for the meta-analysis to support the effect. The abbreviations denote the names of the different cohorts in ENIGMA (please see Stein et al. 2012, for details). [Adapted, with permission, from Stein et al., Nature Genetics, April 15 2012]
The genotype at that locus was also nominally associated with expression levels of the positional candidate gene TESC in adult human temporal lobe tissue, based on the UCL database of brain tissue resected during epilepsy surgeries. TESC is currently not well studied, but it is known that it is expressed during brain development in mice and chickens (Bao et al. 2009). It encodes tescalcin, which interacts with the Na+/H+ exchanger (NHE1) (Baumgartner et al. 2004), important in the regulation of intracellular pH, cell volume and cytoskeletal organization. In addition, intracranial volume was significantly associated with a variant (rs10784502) in the HMGA2 gene that had been previously tied to height. The CHARGE consortium had focused on elderly cohorts recruited primarily for studies of cardiovascular health in old age, whereas ENIGMA had aggregated data from cohorts across the lifespan showing the genetic effect was strong, happening over multiple stages of brain growth. Both efforts had strengths—the number of cohorts in ENIGMA (23) was larger than that of CHARGE, but some of the constituent cohorts in CHARGE numbered over 2,800 individuals.
Practical considerations and opportunities
The first ENIGMA project demonstrated the feasibility of discovering statistically significant effects of “single letter” genomic differences in brain data worldwide, using imaging and genetic data collected using diverse protocols. Novel, harmonized data analysis and meta-analysis protocols were vital to the success of this project.
First, all genotypic data was imputed to the HapMap3 reference dataset to correct for diversity of the genotyping chips (this reference was subsequently updated to the 1,000 Genomes dataset for ENIGMA2, which began in May 2012). The imputation protocols (detailed at enigma.ini.usc.edu) and the standard reference datasets allow the consistent reporting of genotypes at the same set of genetic loci across cohorts. Imputation effectively adds prior knowledge to the data and may in this way also increase the power of a study. Not all ENIGMA cohorts are Caucasian: the GOBS cohort consists of Mexican-Americans and the NIMH cohort contains a significant number of African-Americans. As in any GWAS, population structure is taken into account during the statistical modeling of associations, to ensure that differences in SNP frequencies with ancestry are not picked up as spurious associations. Also in the imputation step, the appropriate reference populations are used for each individual, which may in some cases be Yoruban or Hispanic, as well as the CEU population that is used to represent Caucasians. However, it is not a computationally trivial task to impute very large samples of data from so many subjects. The successive refinement of reference panels means that re-imputing the same dataset to the most current standards is likely to further boost power.
Second, the exchange of data between the ENIGMA and CHARGE consortia, for the Stein et al. (2012) study, involved a reciprocal look-up rather than an exchange of the full meta-analyzed data across the entire genome. This effort found that the top hits of both consortia were in fact the same ones—providing extremely high credibility to the hits. Even so, the full genomic data were not exchanged or meta-analyzed; this more powerful effort is currently underway.
Third, the effort to harmonize the analysis of imaging data involved development of new quality control procedures. Considerable time was devoted to checking outliers, testing of the histograms and statistical distributions of brain structure volumes, and checking the allele frequencies, genomic inflation factors, and other statistical summaries of the cohort data. The genetic and MRI analysis protocols used in ENIGMA2, including quality control steps, are available online, at http://enigma.ini.usc.edu/ongoing/gwasma-of-subcortical-structures/ and the DTI analysis protocols are available at http://enigma.ini.usc.edu/ongoing/dti-working-group/.
In a project of such a scale, the need for adequate data curation is paramount. Several measures were assessed to determine whether structures had values in the expected range for volume, hemispheric asymmetry, etc. In the end, the large number of contributing authors and contributing sites made it easier to identify sites that had outliers in their genotypic or brain measurement data, partly because normative data were becoming available from all the other sites. All relevant demographic factors were controlled for at each site, including population structure that might lead to ancestry differences masquerading as true genetic associations to brain traits.
Among these tests, we demonstrated that different, widely-used programs to measure regional brain volumes produced consistent results on a broad range of cohorts worldwide, based on data from young and old samples and mixtures of both (Stein et al. 2012; see supplement comparing FSL and FreeSurfer segmentations). It was not feasible to require all sites to use one specific program to measure brain regions; as might be predicted, no single algorithm performed best for quantifying brain volumes across all datasets.
Fourth, ENIGMA did not use the “mega-analysis” model adopted by the Psychiatric Genomics Consortium, where all phenotypic and genotype data are sent to a centralized site for analysis. Instead, ENIGMA uses a “meta-analysis” concept: GWAS was run locally using pre-agreed covariates—often with and without adjustments that may affect interpretation (e.g., adjustments for overall head size). Subsequently, and after quality control at each site, the p-values and regression coefficients were combined and meta-analyzed in a way that weights the results based on the sample sizes of each contributing cohort.
Many cohorts within ENIGMA have restrictions on data use and data access. Some preclude the sending of data out of the lab where the data were collected. Some restrict the sending of personally identifying information to any other site. A founding goal of ENIGMA was to not require cohort data to be shared outside the center that collected it, to avoid creating ethical and legal issues for the study sites. Although data sharing is a laudable goal in science, a more pragmatic compromise has been to send protocols to distributed sites and analyze summaries of the resulting data that lack personally identifying information. This also encourages maximum participation as each site retains fiduciary responsibility for their data and its curation and integrity. Nevertheless, there is a growing perception of the community that data sharing is one fundamental building block of reproducibility in science, and a rapidly expanding number of imaging datasets are being shared thus facilitating discoveries. New ways of acknowledging data acquisition are being developed concurrently (Poline et al. 2012).
However, there are also disadvantages associated with the meta-analysis approach. For instance, it is more challenging to perform meta-analyses for more complex and potentially more informative analyses such as (1) polygenic scoring, which determines how much of the phenotypic variance can be explained by common SNPs in aggregate (Purcell et al. 2009), (2) structural equation modeling to demonstrate evidence for the endophenotype concept (Kendler and Neale 2010), and (3) stepwise linear or ridge regression, to identify the causal variant at an associated locus (McCarthy et al. 2008; McCarthy and Hirschhorn 2008). Not being able to perform interaction analyses (e.g., disease by SNP) is also a limitation, although this could be overcome as ENIGMA’s disease related working groups expand.
In the aftermath of ENIGMA1, several investigators requested access to the GWAS meta-analyzed results, and the meta-analyzed data were made available online through an interactive website named ENIGMA-Vis (Novak et al. 2012; http://enigma.ini.usc.edu/enigma-vis/). This interface allows a user to input any gene (or SNP) that they are interested in, and query its effects on a wide variety of brain measures. The current dataset also allows targeted studies of individual genes, enabling research groups, even if they are not involved in human studies, to assess the possible impact on the brain of genes they are studying (via the ENIGMA-Vis search tool).
In one study, Bulayeva and colleagues (Bulayeva et al. 2013) performed a linkage analysis of psychosis and mental retardation in population isolates in remote areas of Dagestan and Chechnya. They were able to implicate the top hits in ENIGMA1 in these illnesses, supporting a psychiatric effect of the genetic variant in human populations. Erk et al. (2013) also studied rs7294919—ENIGMA1’s top hit for association with hippocampal volume, and found that it related to behavioral differences and different patterns of brain activation in memory tasks. Work by Ming Li and colleagues (Li et al. 2013) also found SNPs in the candidate gene CREB1 that were associated with bipolar disorder (the most significant of which was rs6785) and were also associated with measures of hippocampal volume and function.
Current projects of the ENIGMA Consortium
ENIGMA2 is a follow-on study from ENIGMA1, in which the volumes of all major subcortical structures are subjected to genome-wide association analysis (Hibar et al. 2013a). These volumes are known to be moderately to highly heritable, with one recent study reporting highest heritability estimates for the thalamus (0.80) and caudate nucleus (0.88) and lowest for the left nucleus accumbens (0.44; den Braber et al. 2013). The structures are also implicated in a wide range of psychiatric and degenerative brain disorders, making it crucial to identify genetic and environmental factors that may influence them. Preliminary meta-analysis is underway which will be followed by functional characterization of the key hits, with a full report to be submitted soon. A range of functional evaluations is envisaged over the short and long term, ranging from in silico assessments of eQTL data (for instance), all the way to new functional experiments in neuronal cell lines or animal models. This kind of follow up study is crucial, given the difficulties of obtaining robust functional variants from GWAS studies.
ENIGMA-CHARGE genome-wide meta-analysis
Researchers from the ENIGMA and CHARGE consortia have recently joined forces to perform a genome-wide meta-analysis of hippocampal and intracranial volume using updated versions of the data analyzed in ENIGMA1. Specifically, both CHARGE and ENIGMA will be meta-analyzing GWAS results from the much more densely sampled 1,000 Genomes reference set; rather than exchanging only the top hits, the entire genome-wide data is being meta-analyzed. In addition, the ENIGMA project will be contributing updated results from many new samples who have joined the effort since the completion of the ENIGMA1 project. This analysis is currently ongoing.
ENIGMA-DTI is a Working Group developing a harmonized protocol for analyzing DTI data for GWAS meta-analysis (Kochunov et al. 2012). Diffusion tensor imaging offers a range of measures that reflect the microstructure of both white and gray matter (by probing the diffusion profile of the water molecules). It is also possible to reconstruct macroscopic structures such as tracts, using the tensor’s directional information. Understanding the genetic factors underlying the connections of the brain is one of the most challenging projects in the imaging genetics field. This is especially true since the inherent plasticity of the developing brain allows for the remodeling of connectivity based on environmental influences. Interestingly though, heredity of diffusion weighted measures remains quite high, suggesting that factors related to brain growth, development, and plasticity are also highly heritable (White et al. 2013).
A major theme in prioritizing brain phenotypes for large-scale genetic analyses is the presence of significant heritability, indicating that a proportion of individual variance in the phenotypes can be explained by genetic variation. The effect size of individual variants cannot be inferred from the heritability and higher heritability does not translate to a higher likelihood of a positive GWAS finding. However, phenotypes whose heritability is not significantly different from zero may not be good candidates for GWAS analysis because of the lack of variance due to additive genetic factors. Jahanshad et al. (2013a) screened a number of regions of interest across multiple cohorts, finding high heritability for most major white matter pathways and consistent heritability across pedigree-based and twin-based samples (Fig. 4; Kochunov et al. 2012; Jahanshad et al. 2013a). A variety of DTI parameters could be measured reliably among individuals, and genetic factors explained a substantial proportion of the variance for the most commonly used DTI measures.

A meta-analysis of tract-wise heritability, by the ENIGMA-DTI working group, showed most tracts in the brain are moderately to highly heritable across cohorts of different ethnicities, even though they were imaged with different parameters. The “skeleton” of the white matter, reconstructed using a widely used DTI analysis program called “tract-based spatial statistics” (TBSS; Smith et al. 2006), is shown in purple for reference. The corticospinal tract (in light blue) was the least heritable region of interest and therefore, will not be carried forward as a phenotype in an initial GWAS of DTI-FA measures. Other methods for phenotype selection and prioritization are summarized in Table 1
Penke et al. (2010) showed strong correlations among measures of DTI-derived fractional anisotropy (FA) from a range of major white matter tracts in the Lothian Birth Cohort 1936 (LBC1936), a group of community-dwelling subjects in their seventies. Applying principal component analysis, a general white matter integrity factor was found that explained around 45 % of the individual differences in FA across eight tracts, and was significantly correlated with processing speed. Lopez et al. (2012) conducted a GWAS on this general white matter integrity factor on 535 subjects of the LBC1936 study and found suggestive genome-wide association with SNPs in ADAMTS18 and LOC388630. Initial studies suggest that a proportion of the variance in fiber integrity can be predicted from common variants (Kohannim et al. 2012; Jahanshad et al. 2012, 2013c; Thompson and Jahanshad 2012; Braskie et al. 2012; Sprooten et al. 2013).
Genome-wide screens of connectome data have also been successful, and have shown the benefit of ranking connections by their heritability, prior to entering the genome-wide screening phase (Jahanshad et al. 2013b; Thompson et al. 2013). ENIGMA has not yet attempted a multi-site genetic study of brain connectivity. Agreement on a protocol depends on ongoing harmonization of DTI analysis across ENIGMA sites, which is being finalized by the ENIGMA-DTI working group (Jahanshad et al. 2013a). The harmonized DTI analysis will also allow a multi-cohort examination of the association between white matter integrity and general cognitive ability across the life course from late adolescence to old age (see also Penke et al. 2012). Also underway is a harmonization of cortical segmentation, which is being studied empirically by the ENIGMA working groups that focus on psychiatric illness (see below).
ENIGMA Disease Working Groups
An implicit goal of ENIGMA is to see whether genetic variants impact the brain in a way that affects disease risk. In fact, a number of imaging genetics papers have identified genetic variants that appear to affect the brain and behavior; Hall et al. (2006) and McIntosh et al. (2008) reported a variant in the neuregulin 1 gene that was associated with abnormal cortical function, altered white matter integrity, and with psychosis, and there are many other examples of variants with wide-ranging effects.
Around a third of the data in ENIGMA is from patients with psychiatric illness, so once ENIGMA1 was complete, a large volume of new data could be brought to bear on the question of brain differences in a variety of disorders. To make connections between psychiatric risk genes and brain measures, it may make sense to prioritize brain measures with robust case–control differences. Of course, robust case–control differences do not, in themselves, imply that the same genetic variants influencing the phenotype will be the same as those associated with disease risk. A more informed way to rank brain measures for genetic screening is to use the endophenotype ranking value (ERV; Glahn et al. 2012), which aims to rank biomarkers in terms of their promise as endophenotypes for any heritable illness.
The ERV balances the strength of the genetic signal for the endophenotype and the strength of its relation to the disorder of interest. It is defined using the square-root of the heritability of the illness (h i 2), the square-root of the heritability of the endophenotype (h e 2), and their genetic correlation (ρg):
In schizophrenia, for example, decades of studies have reported morphometric differences in patients versus controls, for a range of different structures. ENIGMA offers a promising framework to rank brain measures in order of their effect sizes for case–control differences; these effects could also be further weighted based on their genetic correlation with the illness, to give another ranking. Nor is it expected that the disease should have identical effects on the brain in all cohorts; the variety of participating cohorts in ENIGMA makes it possible to dig deeper into medication-related, or even geographic or demographic factors to explain why brain differences vary so drastically across different studies (see Fig. 5 for the locations of ENIGMA sites in disease-related working groups).

Locations of the ENIGMA Working Groups. After ENIGMA’s first project was completed (ENIGMA1; Stein et al. 2012), large amounts of brain imaging data had been analyzed from patients with a variety of psychiatric disorders. Working groups (WGs) were formed to understand the effects on the brain of bipolar disorder, major depressive disorder (MDD), schizophrenia, by pooling and comparing data from many neuroimaging centers. These groups are open to any researchers who have collected MRI scans from patients with these illnesses. No genetic data is needed to join. In fact, most projects study factors that might influence how these disorders affect the brain—medications, geographic factors, and the age and gender of the patient. A further working group focuses on diffusion tensor imaging, which assesses white matter integrity; current projects relate DTI measures to individual differences in cognition and genetic make-up. The institutions in the working groups, as of June 2013, are shown on the map (see color key, inset)
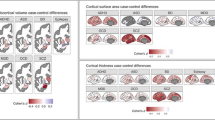
In a meta-analysis of data from 1,136 patients and 1,401 controls, the ENIGMA-Schizophrenia Working Group found that hippocampal volume gave among the highest effect sizes for any subcortical brain structural difference in schizophrenia (Turner et al. 2013; van Erp et al. 2013). In a related meta-analysis of structural MRI data from 1,022 patients and 1,415 controls, the ENIGMA-Bipolar Disorder Working Group found consistent differences across the subcortical regions, but in a different pattern than that characteristic of schizophrenia (Hibar et al. 2013a). There were significant reductions in the bilateral thalamus, hippocampus, and amygdala in patients diagnosed with bipolar disorder. In general, the trend revealed a decrease in subcortical volumes throughout the brain in patients with bipolar disorder. This work is clinically important, as the alterations in limbic and some cortical regions are thought to underlie some of the affective symptoms in bipolar disorder; even so, the source of many of the subcortical and cortical differences in the disorders has been a matter of debate, and for many structures, morphometric findings have not always been consistent. This work is still ongoing, with a total sample of 4,729 subjects from 15 cohorts worldwide (2,060 patients and 2,669 controls, as of November 2013).
In addition, following the model of the Schizophrenia and Bipolar Disorder and working groups, an ENIGMA-Major Depressive Disorder (MDD) Working group was recently initiated. It already includes structural MRI data from 1,850 patients and 3,483 controls. Data analysis is currently in progress.
An additional working group on attention deficit/hyperactivity disorder is currently being formed, ENIGMA-ADHD, which will analyze data from more than 1,500 cases (children and adults) with the disorder and over 2,000 controls.
An even more recent extension is a developing ENIGMA-Addiction working group that will analyze data relevant to addiction phenotypes including case-control comparisons across a variety of substances, and going beyond this to examine the influence of comorbidities, gender and stages of disorder. The ENIGMA meta-analytic approach will be used to aggregate data from case-control and developmental cohorts to examine the relative contribution of various genetic and brain correlates to risk for early onset substance misuse, transition to regular use, susceptibility to dependence, and individual differences in relapse vulnerability. We will also examine variants common to all addictive behaviors, and attempt to identify those that might be specific to homogeneous addiction profiles. To date, a pooled sample of 8,000 participants with neuroimaging, genetics and addiction phenotypes has been identified; their data will be re-analyzed to address these questions.
Clearly, these studies aggregate data from cohorts that are heterogeneous in terms of duration of illness, disease etiology, medication history, demographics, exposure to potentially neuroprotective substances such as lithium, and many other factors. But part of the richness of the ENIGMA efforts is that they afford sufficient power to begin to see which of these factors—including geographic factors, perhaps—affect disease expression in the brain and the universality, or otherwise, of the biomarkers of brain disease. Based on these findings, a key direction for ENIGMA is to see how genes that affect the brain relate to genes that affect risk for psychiatric illness (identified by the Psychiatric Genomics Consortium, https://pgc.unc.edu/), to identify shared biology between brain characteristics and disease. A collaboration between ENIGMA and the PGC is now underway to study these relationships.
One limitation of ENIGMA to date is that the sites contributing to the meta-analysis include a clinically somewhat heterogeneous group of population-based studies, and case–control cohorts from multiple psychiatric and neurological diseases. ENIGMA’s working groups on psychiatric disorders are meta-analyzing representative datasets from schizophrenia, bipolar, depressed, ADHD, autism, OCD, 22q deletion syndrome, HIV, addiction, and other cohorts worldwide. Eventually, cross-disorder comparisons should be able to identify common and distinctive patterns of brain morphometry, and how they depend on genetic variation, and diagnostic criteria. Psychiatric cohorts vary in their inclusion and exclusion criteria, and in duration of illness, medication history, ethnicity, and in other demographics. Some studies include patients with co-morbid conditions deliberately excluded by other studies. The diversity of psychiatric cohorts in ENIGMA suggests a second wave of analyses to understand cohort-specific factors that might account for, or contribute to, the heterogeneity in results across sites. Recent work by the Psychiatric Genomics Consortium Cross-Disorders working group has identified considerable genetic overlap between several major disorders, at the level of common genetic variants (Lee et al. 2013). ENIGMA may be able to do the same from a neuroimaging perspective, to determine if genetic factors implicated in different disorders account for some of the cross-disorder differences in the brain imaging meta-analyses.
Future directions and caveats
Perhaps the most exciting strength of ENIGMA is its ability to unite researchers using neuroimaging worldwide in a common purpose. The fact that so many investigators are actively involved makes it possible to benefit from the combined resources and talents of all participants for “crowd-sourcing” discovery. Also, the sample sizes involved—unprecedented for a neuroimaging study—alleviate some of the concerns about underpowered studies and unreliable findings (Button et al. 2013). In addition, apart from identifying genetic variants, another important role for the ENIGMA consortium is to help understand how GWAS-derived genetic variants for behavioral phenotypes influence the brain. Exploring the effects of disease risk alleles on brain measures can help us understand the brain systems affected, and at which stage—and also whether the effects are pervasive or selective (de Geus 2010).
Much of this overview of the history and future efforts of ENIGMA highlights its relevance to studies of disease, focusing on psychiatric and neurodegenerative disorders such as Alzheimer’s disease. Even so, only around a third of the ENIGMA data comes from patients with psychiatric illness, and much can be learned about the genetic factors that drive normal variation in the general population. A great deal of fundamental information on the biology of the human brain can be discovered from efforts such as ENIGMA, irrespective of whether it has a direct relevance to any specific disease.
There are limitations to a study like ENIGMA despite its strengths. The first is that many other types of genetic or epigenetic variation other than GWAS are important—rare variants, CNVs, expression and methylation analyses are all crucial; they simply have not yet been evaluated through ENIGMA, but that is likely to change in the future. In recent genome-wide complex trait analyses (“GCTA” analyses; Yang et al. 2011; Lee et al. 2011), Wray, Visscher and their colleagues have shown that GWAS data may account for a surprisingly high proportion of genetic variance in a trait, even when the individual predictive value of a given locus or SNP is low.
As a basic principle of genetics, an overall large heritability does not guarantee locus specific heritability, but recent discoveries have surprised some geneticists in supporting the explanatory power of SNPs. For example, despite early results that accounted for about 5 % of the variance in height, large studies have now demonstrated SNPs can account for around 45 % of the variance in height (for which the overall heritability is around 80 %). Also, common causal variants may account for around 23 % of the risk for schizophrenia (Lee et al. 2013) and up to 60 % of the risk for autism (Klei et al. 2012). Given the polygenic architecture of these disorders, these results suggest that more individual SNP associations will be detected for each disorder, as sample sizes increase.
Some authors have emphasized that similar kinds of “polygene” scores to the ones used to predict illness risk can be used to explain variation in related phenotypes, such as cognition (Davies et al. 2011), structural MRI (Holmes et al. 2012), neural activation on functional MRI (Whalley et al. 2013a) and white matter integrity (Whalley et al. 2013b).
Even so, some geneticists argue that rarer variants are in some cases more worthy of study than GWAS as they tend to have larger effects that are more easily validated functionally. GWAS has been successful when used for QTL localization, but the over-arching goal of complex disease genetics is to identify the causal genes and functional variants responsible for phenotypic variation. So some have argued that GWAS is useful for detecting the signal from common variants, but that few GWAS results have turned into functional variants or genes (across all disease domains). In principle, ENIGMA could be used to study rare variants as well, but a range of complementary approaches are always necessary.
Second, the geographical diversity of ENIGMA is higher than that of most neuroimaging studies, but there may be important ethnic differences in allele frequency that complicate the generalization of results to all human populations. This limitation is not specific to ENIGMA, and its consortium structure could be expanded geographically to assess ethnic differences in factors associated with disease and their relationship to brain structure. Ethnic differences in genetic effects are well known: the meta-analysis of the effects of the APOE risk gene for Alzheimer’s disease shows a difference between European and Asian populations. So far, people in Africa and Asia are under-represented on the ENIGMA map; we are therefore keen to include samples from these continents.
Third, the need for multivariate analysis has long been known in the neuroimaging field—no serious neuroscientist would predict diagnosis from a single pixel or voxel in an image—the multivariate pattern of signals is paramount. Methods to access and recover the maximum amount of pertinent information in an image dataset are only just in their infancy in the fields of genetics and neuroimaging—partially due to the lack of sufficient data to test competing methods, until recently (Liu et al. 2009; Stein et al. 2010; Hibar et al. 2011b; Vounou et al. 2010; Le Floch et al. 2012; Rosenblatt et al. 2013; Meda et al. 2010, 2012).
Fourth, the discovery of a GWAS hit—in ENIGMA or any other GWAS study—is the beginning of a long road of discovery, especially if the finding is intergenic or in a gene of unknown function. Some genomic screens of anatomical or structural connectivity data have implicated genes such as SPON1 (Jahanshad et al. 2013b) and FRMD6 (Ryles et al. 2012) that were discovered in later case–control studies to be risk genes for AD (Hong et al. 2012; Sherva et al. 2013). Functional validation of genetic variants reliably implicated in large scale studies will be the way we learn new biological processes and further our understanding of risk for psychiatric diseases.
Fifth, ENIGMA has started by analyzing those phenotypes that are easily measured in a standardized way. Brain images can be analyzed in more sophisticated ways than traditional morphometric methods; shape analysis, for example, has long been used to characterize features of brain structure, including cortical complexity, curvature, fractal dimension, spectral content, and other indices. Also, the reporting of regional summaries from DTI data clearly does not exploit all of the available information in the data—DTI can be analyzed using automatic whole-brain tractography to reveal the brain’s fiber patterns and measure connectivity, and even the topology of these brain networks. Despite the ever-expanding landscape of brain features that can be studied, the large samples required for genetic analysis have motivated the study of the simplest brain measures first. Undoubtedly the future will hold large scale genetic studies of brain connectivity, anatomical shapes, functional networks, and features that are as yet unknown and undiscovered.
As a final limitation, ENIGMA analyses have been cross-sectional to date, rather than longitudinal. Genetic predictors of brain changes over time have substantial importance for clinical trial enrichment (e.g., TREM2, which harbors variants that predict rates of brain atrophy over time; Rajagopalan et al. 2013; see Kohannim et al. 2013, for an approach to boost power in drug trials by multi-locus genetic profiling; see Andreasen et al. 2012, for an approach examining epistatic relationships between multiple genes and progressive brain tissue loss in schizophrenia).
Are fewer subjects needed with imaging?
An open question is whether GWAS meta-analyses really do require fewer subjects with imaging than they do when behavior is the target of study. In 2009, before ENIGMA began, one of its founders noted, “Just because the phenotypes are expensive to collect does not change the power calculations.” (N. Martin, pers. commun., 2009). But more recently, Rose and Donohoe (2013) performed an empirical analysis of effect sizes in genetic studies of cognitive and neuroimaging traits in schizophrenia, and found evidence supporting the efficiency of using imaging traits. However, some evidence does suggest that imaging traits may have intermediate effect sizes when compared to phenotypes theoretically closer or farther away from the underlying biology. The percent variance explained in gene expression GWASs (often called eQTL studies) for the top SNP hits are well above 10 % of the variance in the expression of a particular gene (Stranger et al. 2007). The percentage of trait variance in hippocampal volume explained by the top genetic variant in ENIGMA1 was 0.27 % (Stein et al. 2012) although independent cohorts will be required to estimate the explained variance in the population at large. Finally, the top hit in one genome-wide analysis of traits correlated with cognition—such as educational attainment—explained 0.02 % of the variance (Rietveld et al. 2013).
It is interesting to compare the effect of ENIGMA’s top SNPs with the effects of common psychiatric and neurological conditions on hippocampal volumes. In a recent meta-analysis (Barnes et al., 2009), patients with Alzheimer’s disease have a 24.1 % mean hippocampal volume deficit. Patients with mild cognitive impairment have a 15.3 % deficit relative to cognitively healthy controls (calculated from Table 9 in Leung et al. 2010). In psychiatric disorders, the hippocampal volume deficit is typically reported to be smaller. Although hippocampal volume deficits are one of the more robust MRI findings in schizophrenia, they are not always evident in single site studies (Shenton et al. 2001). The ENIGMA Disease Working Groups now suggest a mean hippocampal volume deficit, relative to controls, of around 3.6 % in schizophrenia and 2.9 % in bipolar disorder—depending, of course, on cohort-specific factors (medication, duration of illness, etc.). By contrast, in ENIGMA1, the rs7294919 genetic variant was associated with a hippocampal volume decreased by 47.6 mm3 or by 1.2 % of the average hippocampal volume per risk allele. Bearing in mind that the cause of the effects is quite different, the effect of ENIGMA’s top hippocampal SNPs on hippocampal volume is approximately 5 % of the mean effect of Alzheimer’s disease, around one-third of the effect of schizophrenia, and around 40 % of the effect of bipolar disorder. If such effect sizes are typical, sample size requirements will generally be larger in genetic association studies than in neuroimaging studies of disease effects on the same phenotypes, but not vastly larger.
To some researchers, these preliminary observations suggest an expected pattern of effect sizes, whereby GWAS for cognitive traits may have top hits with smaller effect sizes than those for imaging traits, which in turn may tend to have smaller effect sizes than expression traits. Also, now that consistent hits have been identified in ENIGMA1 and ENIGMA2, it should be possible to estimate effect sizes for the same hits in new replication samples, to understand what sample sizes are sufficient to detect them. Conversely, some have argued that the available data on genetic effect sizes at different levels of neuroscience are currently too limited to draw conclusions from only the three data points cited here. Clearly, we do not yet have sufficient information to say whether imaging genetics effects sizes will always be larger than effect sizes for cognitive/behavioral phenotypes. One way to begin to address this question might be to quantify effects of some specific functional SNP at three different related levels, such as eQTL data from the hippocampus, hippocampal volume on MRI, and a behavior that is tightly dependent on hippocampal function; this may show the appropriate differential effect sizes in one framework.
A further interesting angle is the follow-up of the top ENIGMA1 hits in ethnically isolated cohorts of Dagestan and Chechnya by Bulayeva et al. (2013). Genetic isolates can be valuable for studying any human phenotypes; required sample sizes for studying genetic effects can be smaller than in heterogeneous outbred populations due to the genetic homogeneity of these isolates. This has long been noted by classical statistical and population geneticists (e.g., Falconer 1960; Neel 1992; Bulayeva et al. 2005). As genetic isolates have a high rate of traditional endogamy and inbreeding, it is not possible to perform GWAS, but genome-wide linkage analysis is possible (Sheffield et al. 1998). In particular, the analysis of isolated populations makes it less challenging to study polygenic disorders by reducing the number of loci possibly involved in the disorder.
ENIGMA now focuses on genetic analysis of neuroimaging measures, but psychiatric diagnosis is important as well. ENIGMA does not simply relate imaging data to genetics; many of its working groups study the relationship between imaging measures and diagnosis. So, in a sense, psychiatric diagnosis is also a key target of study. For example, recent GWAS and follow-up studies have provided strong statistical evidence that variation in the NCAN gene is a common risk factor for bipolar disorder and schizophrenia (Cichon et al. 2011; Mühleisen et al. 2012). Both studies found that the A allele of SNP rs1064395 is a risk-mediating allele and that rs1064395 influences risk to a broad psychosis phenotype. To identify a putative mechanism, Schultz et al. (2013) tested whether the risk allele has an influence on brain structure. In patients with schizophrenia, they found a significant association with higher folding in a right lateral occipital region and at a trend level for the left dorsolateral prefrontal cortex. Controls did not show an association. The findings suggest a role of NCAN in visual processing and top-down cognitive functioning. Both major cognitive processes are known to be disturbed in schizophrenia. Another GWAS study by Rietschel et al. (2012) identified a risk factor for schizophrenia in a chromosomal region harboring the genes AMBRA1/CHRM4/DGKZ/MDK (rs11819869). In an independent follow-up analysis, they found that healthy carriers of the risk allele T showed altered activation in the subgenual cingulate cortex during a cognitive control task. This brain region is a critical interface between emotion regulation and cognition, which are structurally and functionally abnormal in schizophrenia and bipolar disorder.
The recent successes of psychiatric GWAS have unearthed a vast resource of findings when sample sizes became very large (Ripke et al. 2011, for the Schizophrenia Psychiatric Genome-Wide Association Study (GWAS) Consortium; Sklar et al. 2011, for the Psychiatric GWAS Consortium Bipolar Disorder Working Group; Cichon et al. 2011, for the MooDS consortium Bipolar Disorder Group; Rietschel et al. 2012, for the MooDS consortium Schizophrenia Group; Cross-Disorder Group of the Psychiatric Genomics Consortium et al. 2013). In fact, it was the need for large samples that encouraged the ENIGMA groups to work together, realizing that otherwise their power to make credible discoveries in genomic scans would be severely limited.
A second question is which of the recently reported GWAS findings are true or credible if they were discovered in small cohorts. ENIGMA focuses on meta-analyses, but some have argued that smaller individual studies—when replicated—may discover interesting (and strong) associations. Paus et al. (2012) noted that they had run a successful GWAS in only around 300 participants. Also, some GWAS signals may be important in the context of some individual cohorts, but may be washed out in meta-analyses. A more skeptical line of argument is that if we need 20,000+ samples to detect an effect, most likely what we see has very small effect size. Even so, some recent GWAS analyses appear to have picked up variants with strong effects—e.g., that roughly double disease risk (e.g., in TREM2), and these effects have been confirmed in smaller cohorts by comparing brain images from carriers and non-carriers (Rajagopalan et al. 2013).
One testable hypothesis is that GWAS would be more powerful and efficient if we select imaging phenotypes in a principled way; if this is true, it may be possible to perform GWAS with consistently replicated hits, that do not require tens of thousands of subjects to reject the null hypothesis. In fact, the ENIGMA working groups each aim to find heritable brain measures that maximize case–control differentiation, for studies of disease. This will help us to prioritize the future targets of study for influential genes. Although ENIGMA is data-driven, that does not mean that we cannot use patterns in the findings to design more targeted approaches that prioritize phenotypes and genetic loci for follow-up analyses.
One such analysis (Desrivieres et al. 2013) evaluates pre-selected genes that are expressed in the brain and change in their expression throughout brain development. By narrowing the search space to genes that are likely to play a role—and whose functions have more chance of being understood—the power of the study is also increased, as is its practical value for neuroscience and medicine. This must be balanced with the knowledge that approximately 88 % of GWAS hits are in intergenic regions (Hindorff et al. 2009) and almost all genes are expressed at some location in the brain at some period of the lifespan (www.brainspan.org).
ENIGMA, to date, has used a mass-univariate analysis, where each trait (or brain measure) is considered on its own, and each genetic variant is considered on its own. Recent multivariate analyses can cluster voxels in the brain—or SNPs on the genome—to empower analyses, sometimes with both forms of clustering occurring at once (Hibar et al. 2011a; Thompson et al. 2013). Some of these multivariate analysis methods have been used to detect significant hits in image-wide genome-wide searches in cohorts of under 1,000 subjects (Ge et al. 2012; Chen et al. 2012b; Jahanshad et al. 2013b). In most analyses, multivariate refers to condensing information on the imaging side, not the genetic side, although both methods and joint methods are emerging. Multivariate methods can be quite sophisticated mathematically. Some draw upon a century of powerful work in classical quantitative genetics and twin designs. Chiang and colleagues (Chiang et al. 2011, 2012), for example, computed the “cross-trait cross-twin correlation” between all pairs of voxels in an image, to pull out “image clusters” with common genetic determination (see also Chen et al. 2011, 2012a). Others have incorporated knowledge of the genetic or imaging relationships to guide the solution (Chen et al. 2013). Such tactics, among others, offer a principled way to mine high-dimensional datasets, boosting power for any subsequent GWAS.
A further line of work studies the “interactome”: it is now possible to search pairs or sets of SNPs for interaction effects in images (Hibar et al. 2013c) and some have argued that this is the norm for mechanisms of gene action, and the context of other genetic variants should be included in the analyses (Hariri and Weinberger 2003). For instance, Roffman et al. (2008) were the first to show functional MRI evidence of epistasis in schizophrenia. Their findings were consistent with epistatic effects of the COMT and MTHFR polymorphisms on prefrontal dopamine signaling, suggesting that in schizophrenia patients, the MTHFR 677 T allele exacerbates prefrontal dopamine deficiency. Andreasen et al. (2012) used a machine learning algorithm to identify genes/SNPs that were interacting with one another and predicting a continuous outcome measure that is a biologically meaningful phenotype (“intermediate phenotype”) for schizophrenia: changes in brain structure occurring after the onset of the illness.
Expanding the study of interactions to the whole genome, Kam-Thong et al. (2012) presented a whole genome analysis of epistasis (SNP-by-SNP) on several traits, including hippocampal volume. Pandey et al. (2012) reported a pathway analysis, which includes information from the network of gene–gene interactions as well as main effects when prioritizing genes for pathway analysis. Clearly no genetic variant acts alone; however, multiple comparisons increase exponentially with this approach implying difficulty obtaining enough power.
In conclusion, when the next round of ENIGMA studies has been completed, there will be a scaffolding of credible genetic variants on which to build and test new models of macroscale brain development, the implications of those variants for neuropsychiatric disease, and a new basis to probe the genetic architecture of the living human brain.
References
Almasy, L., Gur, R. C., Haack, K., Cole, S. A., Calkins, M. E., Peralta, J. M., et al. (2008). A genome screen for quantitative trait loci influencing schizophrenia and neurocognitive phenotypes. The American Journal of Psychiatry, 165, 1185–1192.
Alzheimer’s Association. (2013). The Worldwide ADNI. URL: http://www.alz.org/research/funding/partnerships/ww-adni_overview.asp. Accessed 2 June 2013.
Amunts, K., Schleicher, A., Burgel, U., Mohlberg, H., Uylings, H. B., & Zilles, K. (1999). Broca’s region revisited: cytoarchitecture and intersubject variability. The Journal of Comparative Neurology, 412, 319–341.
Andreasen, N. C., Wilcox, M. A., Ho, B. C., Epping, E., Ziebell, S., Zeien, E., et al. (2012). Statistical epistasis and progressive brain change in schizophrenia: an approach for examining the relationships between multiple genes. Molecular Psychiatry, 17(11), 1093–1102.
Ashburner, J., Andersson, J. L., & Friston, K. J. (1999). High-dimensional image registration using symmetric priors. NeuroImage, 9, 619–628.
Baaré, W. F., Hulshoff Pol, H. E., Boomsma, D. I., Posthuma, D., de Geus, E. J., Schnack, H. G., et al. (2001). Quantitative genetic modeling of variation in human brain morphology. Cerebral Cortex, 11, 816–824.
Bakken, T. E., Roddey, J. C., Djurovic, S., Akshoomoff, N., Amaral, D. G., Bloss, C. S., et al. (2012). Association of common genetic variants in GPCPD1 with scaling of visual cortical surface area in humans. Proceedings of the National Academy of Sciences of the United States of America, 109, 3985–3990.
Bao, Y., Hudson, Q. J., Perera, E. M., Akan, L., Tobet, S. A., Smith, C. A., et al. (2009). Expression and evolutionary conservation of the tescalcin gene during development. Gene expression patterns : GEP, 9, 273–281.
Batouli, S. A. H., Sachdev, P. S., Wen, W., Wright, M. J., Suo, C., Ames, D., et al. (2012). The heritability of brain metabolites on proton magnetic resonance spectroscopy in older individuals. Neuroimage, 62, 281–289.
Barnes, J., Bartlett, J. W., van de Pol, L. A., Loy, C. T., Scahill, R. I., Frost, C., et al. (2009) A meta-analysis of hippocampal atrophy rates in Alzheimer's disease. Neurobiol Aging, 30(11), 1711–23.
Baumgartner, M., Patel, H., & Barber, D. L. (2004). Na(+)/H(+) exchanger NHE1 as plasma membrane scaffold in the assembly of signaling complexes. American Journal of Physiology - Cell Physiology, 287, C844–C850.
Bertram, L. (2009). Alzheimer’s disease genetics current status and future perspectives. International Review of Neurobiology, 84, 167–184.
Biffi, A., Anderson, C. D., Desikan, R. S., Sabuncu, M., Cortellini, L., Schmansky, N., et al. (2010). Genetic variation and neuroimaging measures in Alzheimer disease. Archives of Neurology, 67, 677–685.
Bis, J. C., DeCarli, C., Smith, A. V., van der Lijn, F., Crivello, F., Fornage, M., et al. (2012). Common variants at 12q14 and 12q24 are associated with hippocampal volume. Nature Genetics, 44, 545–551.
Bishop, D. (2013). Blog posting: http://deevybee.blogspot.co.uk/2013/01/genetic-variation-and-neuroimaging-some.html. Accessed 5 June 2013.
Blangero, J. (2004). Localization and identification of human quantitative trait loci: King Harvest has surely come. Current Opinion in Genetics & Development, 14, 233–240.
Blokland, G. A., de Zubicaray, G. I., McMahon, K. L., & Wright, M. J. (2012). Genetic and environmental influences on neuroimaging phenotypes: a meta-analytical perspective on twin imaging studies. Twin Research and Human Genetics: the Official Journal of the International Society for Twin Studies, 15, 351–371.
Bralten, J., Arias-Vásquez, A., Makkinje, R., Veltman, J. A., Brunner, H. G., Fernández, G., et al. (2011). Association of the Alzheimer’s gene SORL1 with hippocampal volume in young, healthy adults. The American Journal of Psychiatry, 168(10), 1083–1089. doi:10.1176/appi.ajp.2011.10101509.
Braskie, M. N., Jahanshad, N., Stein, J. L., Barysheva, M., McMahon, K. L., de Zubicaray, G. I., et al. (2011). Common Alzheimer’s disease risk variant within the CLU gene affects white matter microstructure in young adults. Journal of Neuroscience, 31, 6764–6770.
Braskie, M. N., Jahanshad, N., Stein, J. L., Barysheva, M., Johnson, K., McMahon, K. L., et al. (2012). Relationship of a variant in the NTRK1 gene to white matter microstructure in young adults. Journal of Neuroscience, 32, 5964–5972.
Brouwer, R. M., Mandl, R. C., Peper, J. S., van Baal, G. C., Kahn, R. S., Boomsma, D. I., et al. (2010). Heritability of DTI and MTR in nine-year-old children. Neuroimage, 53(3), 1085–1092.
Bulayeva, K. B., Leal, S. M., Pavlova, T. A., Kurbanov, R. M., Glatt, S. J., Bulayev, O. A., et al. (2005). Mapping genes of complex psychiatric diseases in Daghestan genetic isolates. American Journal of Medical Genetics Part B: Neuropsychiatric Genetics, 132B(1), 76–84.
Bulayeva, K., Glatt, S., Walsh, C., Gurgenova, F., Berdichevets, I., Bulayev, O., et al. (2013). Significant linkage and structural genomic variants at 12q24.21-q24.32 found in genetic isolate with aggregation of unspecific mental retardation. Open Journal of Genomics, 2, 3.
Button, K. S., Ioannidis, J. P., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S., et al. (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nature Review Neuroscience, 14(5), 365–376. doi:10.1038/nrn3475.
Calhoun, V. D., Liu, J., & Adali, T. (2009). A review of group ICA for fMRI data and ICA for joint inference of imaging, genetic, and ERP data. Neuroimage, 45(1 Suppl), S163–S172. doi:10.1016/j.neuroimage.2008.10.057.
CARDIoGRAMplusCD4_Consortium, Deloukas, P., Kanoni, S., Willenborg, C., Farrall, M., Assimes, T. L., et al. (2013). Large-scale association analysis identifies new risk loci for coronary artery disease. Nature Genetics, 45, 25–33.
Carrillo, M. C., Bain, L. J., Frisoni, G. B., & Weiner, M. W. (2012). Worldwide Alzheimer’s Disease Neuroimaging Initiative. Alzheimer’s & Dementia : the Journal of the Alzheimer’s Association, 8, 337–342.
Chen, C. H., Panizzon, M. S., Eyler, L. T., Jernigan, T. L., Thompson, W., Fennema-Notestine, C., et al. (2011). Genetic influences on cortical regionalization in the human brain. Neuron, 72, 537–544.
Chen, C. H., Gutierrez, E. D., Thompson, W., Panizzon, M. S., Jernigan, T. L., Eyler, L. T., et al. (2012a). Hierarchical genetic organization of human cortical surface area. Science, 335, 1634–1636.
Chen, J., Calhoun, V. D., Pearlson, G. D., Ehrlich, S., Turner, J., Ho, B. C., et al. (2012b). Multifaceted genomic risk for brain function in schizophrenia. NeuroImage, 61, 866–875.
Chen, J., Calhoun, V.D., Pearlson, G.D., Perrone-Bizzozero, N., Sui, J., Turner, J.A., et al. (2013). Guided exploration of genomic risk for gray matter abnormalities in schizophrenia using parallel independent component analysis with reference. NeuroImage (in press).
Chiang, M. C., McMahon, K. L., de Zubicaray, G. I., Martin, N. G., Hickie, I., Toga, A. W., et al. (2011). Genetics of white matter development: a DTI study of 705 twins and their siblings aged 12 to 29. NeuroImage, 54, 2308–2317.
Chiang, M. C., Barysheva, M., McMahon, K. L., de Zubicaray, G. I., Johnson, K., Montgomery, G. W., et al. (2012). Gene network effects on brain microstructure and intellectual performance identified in 472 twins. Journal of Neuroscience, 32, 8732–8745.
Cichon, S., Mühleisen, T. W., Degenhardt, F. A., Mattheisen, M., Miró, X., Strohmaier, J., et al. (2011). Genome-wide association study identifies genetic variation in neurocan as a susceptibility factor for bipolar disorder. American Journal of Human Genetics, 88(3), 372–381.
Cohen, R. A., Harezlak, J., Schifitto, G., Hana, G., Clark, U., Gongvatana A., et al. (2010). Effects of nadir CD4 count and duration of human immunodeficiency virus infection on brain volumes in the highly active antiretroviral therapy era. Journal of neurovirology, 16(1), 25–32.
Collins, D. L., Neelin, P., Peters, T. M., & Evans, A. C. (1994). Automatic 3D intersubject registration of MR volumetric data in standardized Talairach space. Journal of Computer Assisted Tomography, 18, 192–205.
Corder, E. H., Saunders, A. M., Strittmatter, W. J., Schmechel, D. E., Gaskell, P. C., Small, G. W., et al. (1993). Gene dose of apolipoprotein E type 4 allele and the risk of Alzheimer’s disease in late onset families. Science, 261, 921–923.
Cross-Disorder_Group_of_the_Psychiatric_Genomics_Consortium, Smoller, J. W., Craddock, N., Kendler, K., Lee, P. H., Neale, B. M., et al. (2013). Identification of risk loci with shared effects on five major psychiatric disorders: a genome-wide analysis. Lancet, 381, 1371–1379.
Davies, G., Tenesa, A., Payton, A., Yang, J., Harris, S. E., Liewald, D., et al. (2011). Genome-wide association studies establish that human intelligence is highly heritable and polygenic. Molecular Psychiatry, 16(10), 996–1005. doi:10.1038/mp.2011.85.
Davies, G., Harris, S.E., Reynolds, C.A., Payton, A., Knight, H.M., Liewald, D.C., et al. (2012). A genome-wide association study implicates the APOE locus in nonpathological cognitive ageing. Molecular Psychiatry (in Press).
De Geus, E. J. C. (2010). From genotype to EEG endophenotype: a route for post-genomic understanding of complex psychiatric disease? Genome Medicine, 2, 63. http://genomemedicine.com/content/2/9/63.
Den Braber, A., Bohlken, M.M., Brouwer, R.M., van ’t Ent, D., Kanai, R., Kahn, R.S., et al. (2013). Heritability of subcortical brain measures: a perspective for future genome-wide association studies. NeuroImage (in press).
Desrivieres, S., et al. (2013). Single nucleotide polymorphism in the neuroplastin locus associates with cortical thickness and verbal intelligence, submitted.
Ecker, C., Ginestet, C., Feng, Y., Johnston, P., Lombardo, M. V., Lai, M. C., et al. (2013). Brain surface anatomy in adults with autism: the relationship between surface area, cortical thickness, and autistic symptoms. JAMA Psychiatry, 70, 59–70.
Elias-Sonnenschein, L. S., Viechtbauer, W., Ramakers, I. H., Verhey, F. R., & Visser, P. J. (2011). Predictive value of APOE-ε4 allele for progression from MCI to AD-type dementia: a meta-analysis. Journal of Neurology, Neurosurgery and Psychiatry, 82(10), 1149–1156. doi:10.1136/jnnp.2010.231555.
Erk, S., Meyer-Lindenberg, A., Opitz von Boberfeld, C., Esslinger, C., Schnell, K., Kirsch, P., et al. (2011). Hippocampal function in healthy carriers of the CLU Alzheimer’s disease risk variant. Journal of Neuroscience, 49, 18180–18184.
Erk, S., Meyer-Lindenberg, A., Schmierer, P., Grimm, O., Tost, H., Mühleisen, T., et al. (2013). Functional impact of a recently identified quantitative trait locus for hippocampal volume with genome-wide support. Translational Psychiatry (in press).
Esslinger, C., Walter, H., Kirsch, P., Erk, S., Schnell, K., Arnold, C., et al. (2009) Neural mechanisms of a genome-wide supported psychosis variant. Science, 324(5927), 605.
Estrada, K., Styrkarsdottir, U., Evangelou, E., Hsu, Y. H., Duncan, E. L., Ntzani, E. E., et al. (2012). Genome-wide meta-analysis identifies 56 bone mineral density loci and reveals 14 loci associated with risk of fracture. Nature Genetics, 44, 491–501.
Evans, A. C. (2006). The NIH MRI study of normal brain development. NeuroImage, 30, 184–202.
Falconer, D. S. (1960). Introduction to quantitative genetics. Edinburgh: Oliver and Boyd.
Fischl, B., van der Kouwe, A., Destrieux, C., Halgren, E., Segonne, F., Salat, D. H., et al. (2004). Automatically parcellating the human cerebral cortex. Cerebral Cortex, 14, 11–22.
Flint, J., & Munafo, M. R. (2013). Candidate and non-candidate genes in behavior genetics. Current Opinion in Neurobiology, 23, 57–61.
Flint, J., Greenspan, R. J., & Kendler, K. S. (2010). How genes influence behavior. Oxford, NY: Oxford University Press.
Fornage, M., Debette, S., Bis, J. C., Schmidt, H., Ikram, M. A., Dufouil, C., et al. (2011). Genome-wide association studies of cerebral white matter lesion burden: the CHARGE consortium. Annals of Neurology, 69, 928–939.
Fornito, A., Zalesky, A., Bassett, D. S., Meunier, D., Ellison-Wright, I., Yücel, M., et al. (2011). Genetic influences on cost-efficient organization of human cortical functional networks. Journal of Neuroscience, 31, 3261–3270. doi:10.1523/jneurosci.4858-10.2011.
Frackowiak, R. S. J. (1997). Human brain function. San Diego: Academic.
Friston, K. J., Holmes, A. P., Poline, J. B., Grasby, P. J., Williams, S. C., Frackowiak, R. S., et al. (1995). Analysis of fMRI time-series revisited. NeuroImage, 2, 45–53.
Frodl, T., Meisenzahl, E. M., Zill, P., Baghai, T., Rujescu, D., Leinsinger, G., et al. (2004). Reduced hippocampal volumes associated with the long variant of the serotonin transporter polymorphism in major depression. Archives of General Psychiatry, 61(2), 177–183.
Frodl, T., Koutsouleris, N., Bottlender, R., Jäger, M., Born, C., Mörgenthaler, M., et al. (2008). Reduced gray matter brain volumes are associated with variants of the serotonin transporter gene in major depression. Molecular Psychiatry, 13(12), 1093–1101.
Ge, T., Feng, J., Hibar, D. P., Thompson, P. M., & Nichols, T. E. (2012). Increasing power for voxel-wise genome-wide association studies: the random field theory, least square kernel machines and fast permutation procedures. NeuroImage, 63, 858–873.
Glahn, D. C., Thompson, P. M., & Blangero, J. (2007). Neuroimaging endophenotypes: strategies for finding genes influencing brain structure and function. Human Brain Mapping, 28, 488–501.
Glahn, D. C., Winkler, A. M., Kochunov, P., Almasy, L., Duggirala, R., Carless, M. A., et al. (2010). Genetic control over the resting brain. Proceedings of the National Academy of Sciences of the United States of America, 107, 1223–1228.
Glahn, D. C., Curran, J. E., Winkler, A. M., Carless, M. A., Kent, J. W., Jr., Charlesworth, J. C., et al. (2012). High dimensional endophenotype ranking in the search for major depression risk genes. Biological Psychiatry, 71, 6–14.
Glover, G. H., Mueller, B. A., Turner, J. A., van Erp, T. G., Liu, T. T., Greve, D. N., et al. (2012). Function biomedical informatics research network recommendations for prospective multicenter functional MRI studies. Journal of Magnetic Resonance Imaging, 36(1), 39–54.
Goldman, D. (2012). Our genes, our choices : how genotype and gene interactions affect behavior. London: Elsevier/Academic Press.
Gollub, R., Shoemaker, J.M., King, M., White, T., Ehrlich, S., Sponheim, S., et al. (2013) The MCIC collection: a shared repository of multi-modal, multi-site brain image data from a clinical investigation of schizophrenia. Journal of NeuroInformatics. PMID: 23760817.
Gottesman, I. I., & Gould, T. D. (2003). The endophenotype concept in psychiatry: etymology and strategic intentions. The American Journal of Psychiatry, 160, 636–645.
Hall, J., Whalley, H. C., Job, D. E., Baig, B. J., McIntosh, A. M., Evans, K. L., et al. (2006). A neuregulin 1 variant associated with abnormal cortical function and psychotic symptoms. Nature Neuroscience, 9(12), 1477–1478.
Hariri, A. R., & Weinberger, D. R. (2003). Imaging genomics. British Medical Bulletin, 65, 259–270.
Harold, D., Abraham, R., Hollingworth, P., Sims, R., Gerrish, A., Hamshere, M. L., et al. (2009). Genome-wide association study identifies variants at CLU and PICALM associated with Alzheimer’s disease. Nature Genetics, 41, 1088–1093.
Hibar, D. P., Kohannim, O., Stein, J. L., Chiang, M. C., & Thompson, P. M. (2011a). Multilocus genetic analysis of brain images. Frontiers in Genetics, 2, 73.
Hibar, D. P., Stein, J. L., Kohannim, O., Jahanshad, N., Saykin, A. J., Shen, L., et al. (2011b). Voxelwise gene-wide association study (vGeneWAS): multivariate gene-based association testing in 731 elderly subjects. NeuroImage, 56, 1875–1891.
Hibar, D. P., van Erp, T. G. M., Turner, J. A., Haukvik, U. K., Agartz, I., et al. (2013a). Meta-analysis of structural brain differences in bipolar disorder: the ENIGMA-Bipolar Disorder Project. Seattle, WA: OHBM.
Hibar, D. P., Stein, J. L., Ryles, A. B., Kohannim, O., Jahanshad, N., Medland, S. E., et al. (2013b). Genome-wide association identifies genetic variants associated with lentiform nucleus volume in N = 1345 young and elderly subjects. Brain Imaging and Behavior, 7, 102–115.
Hibar, D., Stein, J.L., Jahanshad, N., Toga, A.W., McMahon, K.L., de Zubicaray, G.I., et al. (2013c). Exhaustive search of the SNP-SNP interactome identifies replicated epistatic effects on brain volume. MICCAI 2013, Nagoya, Japan, Sept. 22–26 2013 (in press).
Hindorff, L. A., Sethupathy, P., Junkins, H. A., Ramos, E. M., Mehta, J. P., Collins, F. S., et al. (2009). Potential etiologic and functional implications of genome-wide association loci for human diseases and traits. Proceedings of the National Academy of Sciences of the United States of America, 106, 9362–9367.
Hollingworth, P., Harold, D., Sims, R., Gerrish, A., Lambert, J. C., Carrasquillo, M. M., et al. (2011). Common variants at ABCA7, MS4A6A/MS4A4E, EPHA1, CD33 and CD2AP are associated with Alzheimer’s disease. Nature Genetics, 43(5), 429–435. doi:10.1038/ng.803.
Holmes, A. J., Lee, P. H., Hollinshead, M. O., Bakst, L., Roffman, J. L., Smoller, J. W., et al. (2012). Individual differences in amygdala-medial prefrontal anatomy link negative affect, impaired social function, and polygenic depression risk. Journal of Neuroscience, 32(50), 18087–18100.
Hong, M. G., Reynolds, C. A., Feldman, A. L., Kallin, M., Lambert, J. C., Amouyel, P., et al. (2012). Genome-wide and gene-based association implicates FRMD6 in Alzheimer disease. Human Mutation, 33, 521–529.
Hulshoff Pol, H. E., Schnack, H. G., Mandl, R. C., Brans, R. G., van Haren, N. E., Baare, W. F., et al. (2006). Gray and white matter density changes in monozygotic and same-sex dizygotic twins discordant for schizophrenia using voxel-based morphometry. Neuroimage, 31(2), 482–488.
Ikram, M. A., Fornage, M., Smith, A. V., Seshadri, S., Schmidt, R., Debette, S., et al. (2012). Common variants at 6q22 and 17q21 are associated with intracranial volume. Nature Genetics, 44, 539–544.
Ioannidis, J. P. (2005). Why most published research findings are false. PLoS Medicine, 2, e124.
Jack, C. R., Jr. (2012). Alzheimer disease: new concepts on its neurobiology and the clinical role imaging will play. Radiology, 263, 344–361.
Jahanshad, N., Zhan, L., Bernstein, M.A., Borowski, B.J., Jack, C.R., Toga, A.W., et al. (2010). Diffusion tensor imaging in seven minutes: determining trade-offs between spatial and directional resolution. In: Biomedical Imaging: From Nano to Macro (pp. 1161–1164). 2010 IEEE International Symposium on Biomedical Imaging (ISBI).
Jahanshad, N., Kohannim, O., Hibar, D. P., Stein, J. L., McMahon, K. L., de Zubicaray, G. I., et al. (2012). Brain structure in healthy adults is related to serum transferrin and the H63D polymorphism in the HFE gene. Proceedings National Academy Science USA, 109(14), E851–9. doi:10.1073/pnas.1105543109.
Jahanshad, N., Kochunov, P., Sprooten, E., Mandl, R.C., Nichols, T.E., Almasy, L., et al. (2013a). Multi-site genetic analysis of diffusion images and voxelwise heritability analysis: A pilot project of the ENIGMA-DTI working group. Neuroimage, 81, 455–469.
Jahanshad, N., Rajagopalan, P., Hua, X., Hibar, D. P., Nir, T. M., Toga, A. W., et al. (2013b). Genome-wide scan of healthy human connectome discovers SPON1 gene variant influencing dementia severity. Proceedings of the National Academy of Sciences of the United States of America, 110, 4768–4773.
Jahanshad, N., Nir, T. M., Toga, A. W., Jack, C. R., Bernstein, M. A., Weiner, M. W., & Thompson, P. M. (2013c). Seemingly Unrelated Regression empowers detection of network failure in dementia. Neurobiol Aging. In Press (SI: Neuroimaging Biomarkers in Alzheimer's Disease).
Jenkinson, M., Bannister, P., Brady, M., & Smith, S. (2002). Improved optimization for the robust and accurate linear registration and motion correction of brain images. NeuroImage, 17(2), 825–841.
Jenkinson, M., Beckmann, C. F., Behrens, T. E., Woolrich, M. W., & Smith, S. M. (2012). FSL. NeuroImage, 62, 782–790.
Jones, E. G., & Mendell, L. M. (1999). Assessing the decade of the brain. Science, 284, 739.
Joyner, A. H., J, C. R., Bloss, C. S., Bakken, T. E., Rimol, L. M., Melle, I., Agartz, I., et al. (2009). A common MECP2 haplotype associates with reduced cortical surface area in humans in two independent populations. Proceedings of the National Academy of Sciences of the United States of America, 106, 15483–15488.
Kam-Thong, T., et al. (2012). GLIDE: GPU-based linear regression for detection of epistasis. Human Heredity, 73(4), 220–236.
Kendler, K. S., & Neale, M. C. (2010). Endophenotype: a conceptual analysis. Molecular Psychiatry, 15, 789–797.
Klei, L., Sanders, S., Murtha, M., Hus, V., Lowe, J., Willsey, A., et al. (2012). Common genetic variants, acting additively, are a major source of risk for autism. Molecular Autism, 3 (1). doi:10.1186/2040-2392-3-9. http://www.molecularautism.com/content/3/1/9.
Kochunov, P., Glahn, D. C., Lancaster, J. L., Winkler, A. M., Smith, S., Thompson, P. M., et al. (2010). Genetics of microstructure of cerebral white matter using diffusion tensor imaging. NeuroImage, 53, 1109–1116.
Kochunov, P., Jahanshad, N., Sprooten, E., Thompson, P., McIntosh, A., Deary, I., et al. (2012) Genome-wide association of full brain white matter integrity—from the ENIGMA DTI working group. In: Organization of Human Brain Mapping, Beijing, China.
Kohannim, O., Jahanshad, N., Braskie, M. N., Stein, J. L., Chiang, M. C., Reese, A. H., et al. (2012). Predicting white matter integrity from multiple common genetic variants. Neuropsychopharmacology : official publication of the American College of Neuropsychopharmacology, 37, 2012–2019.
Kohannim, O., Hua, X., Rajagopalan, P., Hibar, D.P., Jahanshad, N., Grill, J., et al. (2013). Multilocus genetic profiling to empower drug trials and predict brain atrophy, Neuroimage-Clinical (in press).
Koten, J. W., Jr., Wood, G., Hagoort, P., Goebel, R., Propping, P., Willmes, K., et al. (2009). Genetic contribution to variation in cognitive function: an FMRI study in twins. Science, 323, 1737–1740. doi:10.1126/science.1167371.
Kremen, W. S., Prom-Wormley, E., Panizzon, M. S., Eyler, L. T., Fischl, B., Neale, M. C., et al. (2009). Genetic and environmental influences on the size of specific brain regions in midlife: the VETSA MRI study. NeuroImage, 49(2), 1213–1223. doi:10.1016/j.neuroimage.2009.09.043.
Lambert, J. C., Heath, S., Even, G., Campion, D., Sleegers, K., Hiltunen, M., et al. (2009). Genome-wide association study identifies variants at CLU and CR1 associated with Alzheimer’s disease. Nature Genetics, 41(10), 1094–1099.
Lango Allen, H., Estrada, K., Lettre, G., Berndt, S. I., Weedon, M. N., Rivadeneira, F., et al. (2010). Hundreds of variants clustered in genomic loci and biological pathways affect human height. Nature, 467, 832–838.
Le Floch, Guillemot, V., Frouin, V., Pinel, P., Lalanne, C., Trinchera, L., et al. (2012). Significant correlation between a set of genetic polymorphisms and a functional brain network revealed by feature selection and sparse Partial Least Squares. NeuroImage, 63(1), 11–24.
Lee, S. H., Wray, N. R., Goddard, M. E., & Visscher, P. M. (2011). Estimating missing heritability for disease from genome-wide association studies. Am J Hum Genet, 88, 294–305.
Lee, S. H., Ripke, S., Neale, B. M., Faraone, S. V., Purcell, S. M., Perlis, R. H. et al. (2013). Genetic relationship between five psychiatric disorders estimated from genome-wide SNPs. Nature Genetics, 45, 984–994.
Leow, A. D., Yanovsky, I., Parikshak, N., Hua, X., Lee, S., Toga, A. W., et al. (2009). Alzheimer’s disease neuroimaging initiative: a one-year follow up study using tensor-based morphometry correlating degenerative rates, biomarkers and cognition. NeuroImage, 45, 645–655.
Leung, K. K., Barnes, J., Ridgway, G. R., Bartlett, J. W., Clarkson, M. J., Macdonald, K., et al. (2010). Automated cross-sectional and longitudinal hippocampal volume measurement in mild cognitive impairment and Alzheimer's disease. Neuroimage, 51(4), 1345–59.
Li, M., Luo, X.J., Rietschel, M., Lewis, C.M., Mattheisen, M., Muller-Myhsok, B., et al. (2013) Allelic differences between Europeans and Chinese for CREB1 SNPs and their implications in gene expression regulation, hippocampal structure and function, and bipolar disorder susceptibility. Molecular Psychiatry (in press).
Liu, J., Pearlson, G., Windemuth, A., Ruano, G., Perrone-Bizzozero, N. I., & Calhoun, V. (2009). Combining fMRI and SNP data to investigate connections between brain function and genetics using parallel ICA. Human Brain Mapping, 30(1), 241–255.
Liu, C. C., Kanekiyo, T., Xu, H., & Bu, G. (2013). Apolipoprotein E and Alzheimer disease: risk, mechanisms and therapy. Nature Reviews Neurology, 9(2), 106–118. doi:10.1038/nrneurol.2012.263.
Logue, M. W., Schu, M., Vardarajan, B. N., Buros, J., Green, R. C., Go, R. C., et al. (2011). A comprehensive genetic association study of Alzheimer disease in African Americans. Archives of Neurology, 68, 1569–1579.
Lopez, L. M., Bastin, M. E., Munoz Maniega, S., Penke, L., Davies, G., Christoforou, A., et al. (2012). A genome-wide search for genetic influences and biological pathways related to the brain’s white matter integrity. Neurobiology of Aging, 33, 1847.e1–14.
Lu, P. H., Thompson, P. M., Leow, A., Lee, G. J., Lee, A., Yanovsky, I., et al. (2011). Apolipoprotein E genotype is associated with temporal and hippocampal atrophy rates in healthy elderly adults: a tensor-based morphometry study. Journal of Alzheimer’s disease : JAD, 23, 433–442.
Mazziotta, J. C., Toga, A. W., Evans, A., Fox, P., & Lancaster, J. (1995). A probabilistic atlas of the human brain: theory and rationale for its development. The International Consortium for Brain Mapping (ICBM). NeuroImage, 2, 89–101.
McCarthy, M. I., & Hirschhorn, J. N. (2008). Genome-wide association studies: potential next steps on a genetic journey. Human Molecular Genetics, 17, R156–R165.
McCarthy, M. I., Abecasis, G. R., Cardon, L. R., Goldstein, D. B., Little, J., Ioannidis, J. P., et al. (2008). Genome-wide association studies for complex traits: consensus, uncertainty and challenges. Nature Reviews Genetics, 9, 356–369.
McIntosh, A. M., Moorhead, T. W., Job, D., Lymer, G. K., Muñoz Maniega, S., McKirdy, J., et al. (2008). The effects of a neuregulin 1 variant on white matter density and integrity. Molecular Psychiatry, 13(11), 1054–1059.
Meda, S. A., Jagannathan, K., Gelernter, J., Calhoun, V. D., Liu, J., Stevens, M. C., et al. (2010). A pilot multivariate parallel ICA study to investigate differential linkage between neural networks and genetic profiles in schizophrenia. (2010). NeuroImage, 53(3), 1007–1015.
Meda, S. A., Narayanan, B., Liu, J., Perrone-Bizzozero, N. I., Stevens, M. C., Calhoun, V. D., et al. (2012). A large scale multivariate parallel ICA method reveals novel imaging-genetic relationships for Alzheimer’s disease in the ADNI cohort. NeuroImage, 60(3), 1608–1621. doi:10.1016/j.neuroimage.2011.12.076.
Mühlau, W., Winkelmann, J., Rujescu, D., Giegling, I., Koutsouleris, N., Gaser, C., et al. (2012). Variation within the Huntington’s disease gene influences normal brain structure. PLoS One, 7(1), e29809.
Mühleisen, T. W., Mattheisen, M., Strohmaier, J., Degenhardt, F., Priebe, L., Schultz, C. C., et al. (2012). Association between schizophrenia and common variation in neurocan (NCAN), a genetic risk factor for bipolar disorder. Schizophrenia Research, 138(1), 69–73.
Naj, A. C., Jun, G., Beecham, G. W., Wang, L. S., Vardarajan, B. N., Buros, J., et al. (2011). Common variants at MS4A4/MS4A6E, CD2AP, CD33 and EPHA1 are associated with late-onset Alzheimer’s disease. Nature Genetics, 43, 436–441.
Neel, J. (1992). Minority populations as genetic isolates: the interpretation of inbreeding results. In A. H. Bittles & D. F. Roberts (Eds.), Minority populations: Genetics demography and health. London: The MacMillan Press.
Novak, N. M., Stein, J. L., Medland, S. E., Hibar, D. P., Thompson, P. M., & Toga, A. W. (2012). EnigmaVis: online interactive visualization of genome-wide association studies of the Enhancing NeuroImaging Genetics through Meta-Analysis (ENIGMA) consortium. Twin Research and Human Genetics, 15, 414–418.
Nugent, A. C., Luckenbaugh, D. A., Wood, S. E., Bogers, W., Zarate, C. A., Jr., & Drevets, W. C. (2012). Automated subcortical segmentation using FIRST: Test-retest reliability, interscanner reliability, and comparison to manual segmentation. Human Brain Mapping. doi:10.1002/hbm.22068.
O'Donovan, M. C., Craddock, N., Norton, N., Williams, H., Pierce, T., Moskvina, V., Nikolov, I. et al. (2008). Identification of loci associated with schizophrenia by genome-wide association and follow-up. Nature Genetics, 40(9), 1053–1055.
Pandey, A., Davis, N. A., White, B. C., Pajewski, N. M., Savitz, J., & Drevets, W. C. (2012). Epistasis network centrality analysis yields pathway replication across two GWAS cohorts for bipolar disorder. Translational Psychiatry, 2, e154. doi:10.1038/tp.2012.80.
Pasaniuc, B., Rohland, N., McLaren, P. J., Garimella, K., Zaitlen, N., Li, H., et al. (2012). Extremely low-coverage sequencing and imputation increases power for genome-wide association studies. Nature Genetics, 44(6), 631–635.
Patenaude, B., Smith, S. M., Kennedy, D. N., & Jenkinson, M. (2011). A Bayesian model of shape and appearance for subcortical brain segmentation. NeuroImage, 56(3), 907–922.
Paus, T., Bernard, M., Chakravarty, M. M., Davey Smith, G., Gillis, J., Lourdusamy, A., et al. (2012). KCTD8 gene and brain growth in adverse intrauterine environment: a genome-wide association study. Cerebral Cortex, 22(11), 2634–2642. doi:10.1093/cercor/bhr350.
Pengas, G., Pereira, J. M., Williams, G. B., & Nestor, P. J. (2009). Comparative reliability of total intracranial volume estimation methods and the influence of atrophy in a longitudinal semantic dementia cohort. Journal of Neuroimaging, 19(1), 37–46. doi:10.1111/j.1552-6569.2008.00246.x.
Penke, L., Munoz Maniega, S., Murray, C., Gow, A. J., Valdes Hernandez, M. C., Clayden, J. D., et al. (2010). A general factor of brain white matter integrity predicts information processing speed in healthy older people. Journal of Neuroscience, 30(7559), 7674.
Penke, L., Maniega, S. M., Bastin, M. E., Hernandez, M. C. V., Murray, C., Royle, N. A., et al. (2012). Brain white matter integrity as a neural foundation for general intelligence. Molecular Psychiatry, 17, 1026–1030.
Peper, J. S., Brouwer, R. M., Boomsma, D. I., Kahn, R. S., & Hulshoff Pol, H. E. (2007). Genetic influences on human brain structure: a review of brain imaging studies in twins. Human Brain Mapping, 28(6), 464–473. Review.
Pierson, R., Johnson, H., Harris, G., Keefe, H., Paulsen, J. S., Andreasen, N. C., et al. (2011). Fully automated analysis using BRAINS: AutoWorkup. NeuroImage, 54(1), 328–336.
Poline, J. B., Breeze, J. L., Ghosh, S., Gorgolewski, K., Halchenko, Y. O., Hanke, M., et al. (2012). Data sharing in neuroimaging research. Frontiers in Neuroinformatics, 6, 9.
Potkin, S. G., & Ford, J. M. (2009). Widespread cortical dysfunction in schizophrenia: the FBIRN imaging consortium. Schizophrenia Bulletin, 35, 15–18.
Potkin, S. G., Guffanti, G., Lakatos, A., Turner, J. A., Kruggel, F., Fallon, J. H., et al. (2009a). Hippocampal atrophy as a quantitative trait in a genome-wide association study identifying novel susceptibility genes for Alzheimer’s disease. PLoS One, 4, e6501.
Potkin, S. G., Turner, J. A., Guffanti, G., Lakatos, A., Torri, F., Keator, D. B., et al. (2009b). Genome-wide strategies for discovering genetic influences on cognition and cognitive disorders: methodological considerations. Cognitive Neuropsychiatry, 14, 391–418.
Purcell, S. M., Wray, N. R., Stone, J. L., Visscher, P. M., O’Donovan, M. C., Sullivan, P. F., et al. (2009). Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature, 460, 748–752.
Rajagopalan, P., Hibar, D.P., Thompson, P.M. (2013). TREM2 Alzheimer risk gene carriers lose brain tissue faster, Letter to the Editor. New England Journal of Medicine (in press).
Rietschel, M., Mattheisen, M., Degenhardt, F., Kahn, R. S., Linszen, D. H., Os, J. V., et al. (2012). Association between genetic variation in a region on chromosome 11 and schizophrenia in large samples from Europe. Molecular Psychiatry, 17(9), 906–917.
Rietveld, C.A., Medland, S.E., Derringer, J., Yang, J., Esko, T., Martin, N.W., et al. (2013). GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science (in Press).
Rimol, L. M., Agartz, I., Djurovic, S., Brown, A. A., Roddey, J. C., Kahler, A. K., et al. (2010). Sex-dependent association of common variants of microcephaly genes with brain structure. Proceedings of the National Academy of Sciences of the United States of America, 107, 384–388.
Ripke, S., Sanders, A. R., Kendler, K. S., Levinson, D. F., Sklar, P., Holmans, P. A., et al. (2011). Genome-wide association study identifies five new schizophrenia loci. Nature Genetics, 43(10), 969–976. doi:10.1038/ng.940.
Roffman, J. L., Gollub, R. L., Calhoun, V. D., Wassink, T. H., Weiss, A. P., Ho, B. C., et al. (2008). MTHFR 677C -> T genotype disrupts prefrontal function in schizophrenia through an interaction with COMT 158Val -> Met. Proceedings of the National Academy of Sciences of the United States of America, 105(45), 17573–17578. doi:10.1073/pnas.0803727105.
Rose, E. J., & Donohoe, G. (2013). Brain vs behavior: an effect size comparison of neuroimaging and cognitive studies of genetic risk for schizophrenia. Schizophrenia Bulletin, 39(3), 518–526. doi:10.1093/schbul/sbs056.
Rosenblatt, J., Benjamini, Y., Bogomolov, M., Stein, J. L., & Thompson, P. M. (2013). vGWAS revisited: A novel and powerful approach to voxelwise genomewide association studies. Seattle, WA: OHBM.
Ryles, A. B., Kohannim, O., Toga, A. W., Jack, C. R., Jr., Weiner, M. W., McMahon, K. L., et al. (2012). Alzheimer’s disease risk variant in the FRMD6 gene is associated with altered brain structure: Opposite Effects in 740 elderly and 755 young adults. New Orleans, LA: Society for Neuroscience Annual Conference.
Saykin, A. J., Shen, L., Foroud, T. M., Potkin, S. G., Swaminathan, S., Kim, S., et al. (2010). Alzheimer’s Disease Neuroimaging Initiative biomarkers as quantitative phenotypes: genetics core aims, progress, and plans. Alzheimer’s & Dementia : the Journal of the Alzheimer’s Association, 6, 265–273.
Schnack, H. G., van Haren, N. E., Brouwer, R. M., van Baal, G. C., Picchioni, M., Weisbrod, M., et al. (2010). Mapping reliability in multicenter MRI: voxel-based morphometry and cortical thickness. Human Brain Mapping, 31(12), 1967–1982. doi:10.1002/hbm.20991.
Schultz, C.C., Mühleisen, T.W., Nenadic, I., Koch, K., Wagner, G., Schachtzabel, C., et al. (2013). Common variation in NCAN, a risk factor for bipolar disorder and schizophrenia, influences local cortical folding in schizophrenia. Psychological Medicine. Manuscript accepted for publication.
Schumann, G., Coin, L. J., Lourdusamy, A., Charoen, P., Berger, K. H., Stacey, D., et al. (2011). Genome-wide association and genetic functional studies identify autism susceptibility candidate 2 gene (AUTS2) in the regulation of alcohol consumption. Proceedings of the National Academy of Sciences of the United States of America, 108(17), 7119–7124. doi:10.1073/pnas.1017288108.
Seshadri, S., Fitzpatrick, A. L., Ikram, M. A., DeStefano, A. L., Gudnason, V., Boada, M., et al. (2010). Genome-wide analysis of genetic loci associated with Alzheimer disease. JAMA, the Journal of the American Medical Association, 303, 1832–1840.
Sheffield, V. C., Stone, E. M., & Carmi, R. (1998). Use of isolated inbred human populations for identification of disease genes. Trends in Genetics, 14(10), 391–396.
Shenton, M. E., Dickey, C. C., Frumin, M., & McCarley, R. W. (2001). A review of MRI findings in schizophrenia. Schizophr Res, 49(1–2), 1–52.
Sherva, R., Tripodis, Y., Bennett, D.A., Chibnik, L.B., Crane, P.K., de Jager, P.L., et al (2013). Genome-wide association study of the rate of cognitive decline in Alzheimer’s disease. Alzheimer’s & Dementia : the Journal of the Alzheimer’s Association.
Shokouhi, M., Barnes, A., Suckling, J., Moorhead, T. W., Brennan, D., Job, D., et al. (2011). Assessment of the impact of the scanner-related factors on brain morphometry analysis with Brainvisa. BMC Medical Imaging, 11, 23. doi:10.1186/1471-2342-11-23.
Silver, M., Janousova, E., Hua, X., Thompson, P. M., Montana, G., & Alzheimer’s Disease Neuroimaging Initiative. (2012). Identification of gene pathways implicated in Alzheimer’s disease using longitudinal imaging phenotypes with sparse regression. NeuroImage, 63(3), 1681–1694. doi:10.1016/j.neuroimage.2012.08.002.
Sklar, P., Ripke, S., Scott, L. J., Andreassen, O. A., Cichon, S., Craddock, N., et al. (2011). Large-scale genome-wide association analysis of bipolar disorder identifies a new susceptibility locus near ODZ4. Nature Genetics, 43(10), 977–983. doi:10.1038/ng.943.
Smith, S. M., Jenkinson, M., Johansen-Berg, H., Rueckert, D., Nichols, T. E., Mackay, C. E., et al. (2006). Tract-based spatial statistics: voxelwise analysis of multi-subject diffusion data. NeuroImage, 31(4), 1487–1505.
Speliotes, E. K., Willer, C. J., Berndt, S. I., Monda, K. L., Thorleifsson, G., Jackson, A. U., et al. (2010). Association analyses of 249,796 individuals reveal 18 new loci associated with body mass index. Nature Genetics, 42, 937–948.
Sprooten, E., Fleming, K. M., Thomson, P. A., Bastin, M. E., Whalley, H. C., Hall, J., et al. (2013). White matter integrity as an intermediate phenotype: exploratory genome-wide association analysis in individuals at high risk of bipolar disorder. Psychiatry Research, 206, 223–231.
Stefansson, H., Ophoff, R. A., Steinberg, S., Andreassen, O. A., Cichon, S., Rujescu, D., et al. (2009). Nature, 460, 744–747.
Stein, J. L., Hua, X., Lee, S., Ho, A. J., Leow, A. D., Toga, A. W., et al. (2010). Voxelwise genome-wide association study (vGWAS). NeuroImage, 53, 1160–1174.
Stein, J. L., Hibar, D. P., Madsen, S. K., Khamis, M., McMahon, K. L., de Zubicaray, G. I., et al. (2011). Discovery and replication of dopamine-related gene effects on caudate volume in young and elderly populations (N = 1198) using genome-wide search. Molecular Psychiatry, 16(927–937), 881.
Stein, J. L., Medland, S. E., Vasquez, A. A., Hibar, D. P., Senstad, R. E., Winkler, A. M., et al. (2012). Identification of common variants associated with human hippocampal and intracranial volumes. Nature Genetics, 44, 552–561.
Stranger, B. E., Nica, A. C., Forrest, M. S., Dimas, A., Bird, C. P., Beazley, C., et al. (2007). Population genomics of human gene expression. Nature Genetics, 39, 1217–1224.
Talairach, J., Tournoux, P., & Missir, O. (1993). Referentially oriented cerebral MRI anatomy: an atlas of stereotaxic anatomical correlations for gray and white matter. Stuttgart: G. Thieme Verlag.
Thompson, P. M., & Jahanshad, N. (2012). Ironing out neurodegeneration: is iron intake important during the teenage years? Expert Review of Neurotherapeutics, 12, 629–631.
Thompson, P. M., Cannon, T. D., Narr, K. L., van Erp, T., Poutanen, V. P., Huttunen, M., et al. (2001). Genetic influences on brain structure. Nature Neuroscience, 4, 1253–1258.
Thompson, P.M., Ge, T., Glahn, D.C., Jahanshad, N., Nichols, T.E. (2013). Genetics of the connectome. Neuroimage.
Thorgeirsson, T. E., Geller, F., Sulem, P., Rafnar, T., Wiste, A., Magnusson, K. P., et al. (2008). variant associated with nicotine dependence, lung cancer and peripheral arterial disease. Nature, 452(7187), 638–642. doi:10.1038/nature06846.
Turner, J. A., Smyth, P., Macciardi, F., Fallon, J. H., Kennedy, J. L., & Potkin, S. G. (2006). Imaging phenotypes and genotypes in schizophrenia. Neuroinformatics, 4(1), 21–49.
Turner, J. A., Hibar, D. P., Rasmussen, J., Andreassen, O., Haukvik, U. K., Agartz, I., et al. (2013). A prospective meta-analysis of subcortical bain volumes in schizophrenia via the ENIGMA consortium. Seattle, WA: OHBM.
van den Heuvel, M. P., van Soelen, I. L., Stam, C. J., Kahn, R. S., Boomsma, D. I., & Hulshoff Pol, H. E. (2013). Genetic control of functional brain network efficiency in children. European Neuropsychopharmacology, 23, 19–23. doi:10.1016/j.euroneuro.2012.06.007.
van Erp, T. G., Saleh, P. A., Huttunen, M., Lonnqvist, J., Kaprio, J., Salonen, O., et al. (2004a). Hippocampal volumes in schizophrenic twins. Archives of General Psychiatry, 61(4), 346–353.
van Erp, T., Cannon, T., Tran, H., Wobbekind, A., Huttunen, M., Lönnqvist, J., et al. (2004) Genetic influences on human brain morphology. IEEE International Symposium on Biomedical Imaging, 583–586.
van Erp, T.G.M., Hibar, D.P., Rasmussen, J., Potkin, S., Ophoff, R., Andreassen, O., et al. (2013). A large-scale meta-analysis of subcortical brain volume abnormalities in schizophrenia via the ENIGMA consortium, Society for Biological Psychiatry (SOBP).
van Soelen, I. L., Brouwer, R. M., Peper, J. S., van Leeuwen, M., Koenis, M. M., van Beijsterveldt, T. C., et al. (2012). Brain SCALE: brain structure and cognition: an adolescent longitudinal twin study into the genetic etiology of individual differences. Twin Research and Human Genetics, 15(3), 453–467. doi:10.1017/thg.2012.4.
Vounou, M., Nichols, T. E., & Montana, G. (2010). Discovering genetic associations with high-dimensional neuroimaging phenotypes: a sparse reduced-rank regression approach. NeuroImage, 53, 1147–1159.
Vounou, M., Janousova, E., Wolz, R., Stein, J. L., Thompson, P. M., Rueckert, D., et al. (2012). Sparse reduced-rank regression detects genetic associations with voxel-wise longitudinal phenotypes in Alzheimer’s disease. NeuroImage, 60(1), 700–716.
Weiner, M. W., Veitch, D. P., Aisen, P. S., Beckett, L. A., Cairns, N. J., Green, R. C., et al. (2012). The Alzheimer’s disease neuroimaging initiative: a review of papers published since its inception. Alzheimer’s & Dementia : the Journal of the Alzheimer’s Association, 8, S1–S68.
Whalley, H. C., Papmeyer, M., Sprooten, E., Romaniuk, L., Blackwood, D. H., Glahn, D. C., et al. (2013a). The influence of polygenic risk for bipolar disorder on neural activation assessed using fMRI. Translational Psychiatry, 2, e130. doi:10.1038/tp.2012.60.
Whalley, H. C., Sprooten, E., Hackett, S., Hall, L., Blackwood, D. H., Glahn, D. C., et al. (2013b). Polygenic risk and white matter integrity in individuals at high risk of mood disorder. Biological Psychiatry. doi:10.1016/j.biopsych.2013.01.027.
White, T., & Gottesman, I. I. (2012). Brain connectivity and gyrification as endophenotypes for schizophrenia: weight of the evidence. Current Trends in Medicinal Chemistry, 12, 2393–2403.
White, T., Andreasen, N. C., & Nopoulos, P. (2002). Brain volumes and surface morphology in monozygotic twins. Cerebral Cortex, 12, 486–493.
White, T., El Marroun, H., Nijs, I., Schmidt, M. N., van der Lugt, A., Wielopolski, P., et al. (2013). Pediatric population-based imaging and the Generation R Study: the intersection of developmental neuroscience and epidemiology. European Journal of Epidemiology, 28, 99–111.
Winkler, A. M., Kochunov, P., Blangero, J., Almasy, L., Zilles, K., Fox, P. T., et al. (2010). Cortical thickness or grey matter volume? The importance of selecting the phenotype for imaging genetics studies. NeuroImage, 53(3), 1135–1146. doi:10.1016/j.neuroimage.2009.12.028.
Woods, R. P., Mazziotta, J. C., & Cherry, S. R. (1993). MRI-PET registration with automated algorithm. Journal of Computer Assisted Tomography, 17, 536–546.
Wright, I. C., Sham, P., Murray, R. M., Weinberger, D. R., & Bullmore, E. T. (2002). Genetic contributions to regional variability in human brain structure: methods and preliminary results. Neuroimage,17(1), 256–271.
Yang, J., Lee, S. H., Goddard, M. E., & Visscher, P. M. (2011). GCTA: a tool for genome-wide complex trait analysis. American Journal of Human Genetics, 88, 76–82.
Yang, J., Loos, R. J., Powell, J. E., Medland, S. E., Speliotes, E. K., Chasman, D. I., et al. (2012). FTO genotype is associated with phenotypic variability of body mass index. Nature, 490, 267–272.
Zetzsche, T., Preuss, U. W., Bondy, B., Frodl, T., Zill, P., Schmitt, G., et al. (2008). 5-HT1A receptor gene C-1019 G polymorphism and amygdala volume in borderline personality disorder. Genes, Brain and Behavior, 7(3), 306–313.
Zhan, L., Jahanshad, N., Ennis, D.B., Jin, Y., Bernstein, M.A., Borowski, B.J., et al. (2012) Angular versus spatial resolution trade-offs for diffusion imaging under time constraints. Human Brain Mapping.
Conflict of interest
The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Consortia
Corresponding author
Additional information
Guest Editor: John D. Van Horn
This article reviews work published by the ENIGMA Consortium and its Working Groups (http://enigma.ini.usc.edu). It was written collaboratively; P.T. wrote the first draft and all listed authors revised and edited the document for important intellectual content, using Google Docs for parallel editing, and approved it. Some ENIGMA investigators contributed to the design and implementation of ENIGMA or provided data but did not participate in the analysis or writing of this report. A complete listing of ENIGMA investigators is available at http://enigma.ini.usc.edu/publications/the-enigma-consortium-in-review/ For ADNI, some investigators contributed to the design and implementation of ADNI or provided data but did not participate in the analysis or writing of this report. A complete listing of ADNI investigators is available at http://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf The work reviewed here was funded by a large number of federal and private agencies worldwide, listed in Stein et al. (2012); the funding for listed consortia is also itemized in Stein et al. (2012).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Thompson, P.M., Stein, J.L., Medland, S.E. et al. The ENIGMA Consortium: large-scale collaborative analyses of neuroimaging and genetic data. Brain Imaging and Behavior 8, 153–182 (2014). https://doi.org/10.1007/s11682-013-9269-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11682-013-9269-5