
Abstract
How should one allocate a fleet of ambulances to fixed bases with the goal of keeping response times to calls as small as possible? We present two new models for this problem, both of which are based on the Erlang loss formula. The first model is stylized, and shows that allocating ambulances in proportion to the offered load is not necessarily optimal and can often be substantially improved upon. The second model can be used to screen potential allocations to try to identify top candidates for further investigation. Computational experiments on the first model provide insights on how we should modify ambulance allocations in response to different levels of offered load. Computational experiments on the second model compare this model with the so-called A-hypercube model and show that the our model has comparable, and in many cases, better performance in terms of the accuracy of the estimates of performance measures. Thus, our models can be used as pre-screening tools to identify promising ambulance allocations and these promising ambulance allocations can subsequently be evaluated carefully through simulation.





Similar content being viewed by others


References
Batta R, Dolan J, Krishnamurthy N (1989) The maximal expected covering location problem: revisited. Transp Sci 23:277–287
Berman O, Larson R (1982) The median problem with congestion. Comput Oper Res 9(22):119–126
Brandeau M, Larson RC (1986) Extending and applying the hypercube model to deploy ambulances in boston. In: Swersey A, Ignall E (eds) Delivery of urban services. North Holland
Brotcorne L, Laporte G, Semet F (2003) Ambulance location and relocation models. Eur J Oper Res 147(3):451–463
Budge S, Ingolfsson A, Erkut E (2006) Approximating vehicle dispatch probabilities for emergency service systems. Unpublished manuscript available at http://www.bus.ualberta.ca/aingolfsson/documents/PDF/Disp%20Prob.pdf
Church R, ReVelle C (1974) The maximal covering location problem. Pap Reg Sci Assoc 32:101–108
Daskin M (1983) A maximal expected covering location model: formulation, properties, and heuristic solution. Transp Sci 17:48–70
Erdogan G, Erkut E, Ingolfsson A (2007) Ambulance deployment for maximum survival. Nav Res Logist 55(1):42–58
Fox B (1966) Discrete optimization via marginal analysis. Manage Sci 13(3):210–216
Goldberg JB (2004) Operations research models for the deployment of emergency services vehicles. Emerg Med Serv Manage J 1(1):20–39
Goldberg JB, Paz L (1991) Locating emergency vehicle bases when service time depends on call location. Transp Sci 25(4):264–280
Goldberg JB, Szidarovsky F (1991) Methods for solving nonlinear equations used in evaluating emergency vehicle busy probabilities. Oper Res 39(6):903–916
Green LV, Kolesar PJ (2004) Improving emergency responsiveness with management science. Manage Sci 50(8):1001–1014
Gross D, Harris CM (1985) Fundamentals of queuing theory, 2nd edn. Wiley, New York
Harel A (1988) Convexity properties of the Erlang loss formula. Oper Res 38(3):499–505
Henderson SG, Mason AJ (2004) Ambulance service planning: simulation and data visualisation. In: Brandeau ML, Sainfort F, Pierskalla WP (eds) Operations research and health care: a handbook of methods and applications, handbooks in operations research and management science. Kluwer Academic, pp 77–102
Jagers AA, van Doorn EA (1986) On the continued Erlang loss function. Oper Res Lett 5(1):43–46
Jarvis J (1975) Optimization in stochastic systems with distinguishable servers. Technical Report, Operations Research Center, M.I.T.
Jarvis J (1985) Approximating the equilibrium behavior of multi-server loss systems. Manage Sci 31:235–239
Koole G, Talim J (2000) Exponential approximation of multi-skill call center architectures. In: Proceedings of QNETs 2000. QNETs, Ilkley (UK), pp 23/1-10
Larson RC (1974) A hypercube queuing model for facility location and redistricting in urban emergency services. Comput Oper Res 1(1):67–95
Larson RC (1975) Approximating the performance of urban emergency systems. Oper Res 23(5):845–868
Marianov V, ReVelle C (1994) The queuing probabilistic location set covering problem and some extensions. Socio-econ Plann Sci 167–178
ReVelle C, Hogan K (1989) The maximum reliability location problem and α-reliable p-center problem: derivatives of the probabilistic location set covering problems. Ann Oper Res 18:155–174
Richards DP (2007) Optimised ambulance redeployment strategies. PhD thesis, Department of Engineering Science, University of Auckland, Auckland, New Zealand
Singer M, Donoso P (2008) Assesing an ambulance service with queueing theory. Comp Oper Res 35:2549–2560
Swersey AJ (1994) The deployment of police, fire and emergency medical units. In: Pollock SM, Rothkopf M, Barnett A (eds) Operations research and the public sector, vol 6 of handbooks in operations research and management science. North-Holland, pp 151–190
Toregas G, Saqin R, ReVelle C, Berman L (1971) The location of emergency service facilities. Oper Res 19(6):1363–1373
Wolff RW (1989) Stochastic modeling and the theory of queues. Prentice-Hall, Englewood Cliffs, NJ
Acknowledgements
We thank Armann Ingolfsson for the data used for the numerical experiments in Section 5, and the referees for very helpful comments that improved both the content and exposition in the paper.
This manuscript is based upon work supported by the National Science Foundation Grants No. DMI 0400287 and DMI 0422133. All opinions, findings, and conclusions or recommendations expressed in this manuscript are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Detailed derivation of approximation procedure
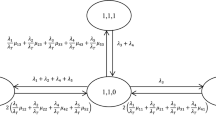
In this appendix we provide the derivation of a system of nonlinear equations that will yield, upon its solution, the probabilities s jk that a call produced at zone j will be served by an ambulance stationed at base j(k).
Define, for all k = 1, ..., B + 1, \(\mathcal A_{jk}(t)\) to be the event that the first k − 1 bases in demand node j’s ranking of bases are busy at time t. In other words, \(\mathcal A_{jk}(t)\) is the event that none of the bases preferred to the k-th base in demand node j’s list has an available ambulance at time t. The event \(\mathcal A_{j1}(t)\) has probability 1 by definition. If a call is generated at demand node j at time t, then on the event \(\mathcal A_{jk}(t)\), the call is offered to base j(k). We write \(\mathcal A_{jk}\) for \(\mathcal A_{jk}(0)\) and let \(a_{jk} = P(\mathcal A_{jk})\) be the stationary probability of the event \(\mathcal A_{jk}(t)\). We can interpret a jk as the probability that a call originating at demand node j will be offered to base j(k). (We are implicitly using a Poisson-arrivals-see-time-averages argument here to ensure that the Poisson arrivals at demand node j see the time-average behavior of the system. We also use the fact that the time-average behavior corresponds with the stationary behavior. For background on both of these topics, we refer the reader to Wolff [29].) Similarly, we let \(\mathcal S_{jk}(t)\) denote the event that the first available ambulance in the priority list of bases j(1), ..., j(B) at time t is at j(k), and write \(\mathcal S_{jk}\) for S jk (0). Thus, as defined in Section 4 \(s_{jk} = P(\mathcal S_{jk})\) is the probability that a call originating at node j will be answered by an ambulance from base j(k). We extend the definition of s j k to include k = B + 1, so that s j, B + 1 is the probability that no ambulance is available anywhere.
We therefore turn to developing an approximation for the probabilities s jk for all j = 1, ..., J, k = 1, ..., B. An approximation for s j,B + 1 will follow from the fact that \(\sum_{k=1}^{B+1} s_{j,k} = 1\), this being the probability that a call is either answered by one of the bases or lost.
We begin by noting that \(\mathcal A_{j, k+1} \subseteq \mathcal A_{jk}\) and \(\mathcal S_{jk} = \mathcal A_{jk} \backslash \mathcal A_{j,k+1}\) for all k = 1, ..., B. In other words, the first k bases on demand node j’s list can be busy only when the first k − 1 bases are busy, and a call is answered by the k-th base in demand node j’s list if and only if the first k − 1 bases are busy, but the k-th base is not. Hence, for k = 1,..., B, s jk = a jk − a j, k + 1, \(\mathcal A_{jk} = \cup_{i=k}^{B+1} \mathcal S_{ji}\), and \(a_{jk} = \sum_{i=k}^{B+1} s_{ji}\) for all k = 1, ..., B. We let A and S respectively be the matrix of values {a jk : j = 1, ...J, k = 1, ..., B + 1} and { s jk : j = 1, ...J, k = 1, ..., B + 1}. Since we can recover either of these matrices from the other one, we focus on computing A through a fixed point equation.
Recall that a j1 = 1 for all j = 1,...,J. To approximate a j2, we first let λ b be the “offered” load to base b, so that
where j − 1(b) stands for base b’s index in node j’s ranking. We then approximate a j2, the probability that no ambulances are available at base j(1), by
(The number of ambulances n k and the service rate μ k at base k are constants that do not change in our scheme.) It now remains to show how to compute approximations for a jm for m > 2. The nested nature of the events \(\mathcal A_{jm}\) for all m = 1,...,B ensures that we have
for m > 2. We approximate each factor of the form \(P(\mathcal A_{j, k+1} | \mathcal A_{jk})\) by
for all k = 2, ..., B, where λ(j, k) represents the conditional demand rate offered to base j(k), given \(\mathcal A_{jk}\). By conditioning on \(\mathcal A_{jk}\), the demand offered to base j(k) may not be Poisson, but we ignore this issue in our approximation. In analogy with (9), the conditional demand can be written as
where i − 1(j(k)) is defined as the n for which i(n) = j(k), i.e., the index of base j(k) in demand node i’s list of bases. The probability in (13) is the conditional probability that a call originating at demand node i will be offered to base j(k), conditional on the first k − 1 bases in demand node j’s priority list being busy.
If all of the bases that appear before base j(k) in demand node i’s list also appear in demand node j’s list before base j(k), then we know that they are all busy, since we are conditioning on \(\mathcal A_{jk}\). In that case, the conditional probability that the call originating at demand node i will be offered to base j(k) is 1. If not, then we essentially need to compute the probability that a subset of the bases are busy, given that another subset of the bases are busy. In principle, it is possible to include such probabilities as separate variables and to write linking equations for them. However, this would cause a dramatic increase in the number of variables. To produce a tractable set of equations, we instead adopt the following approximation.
For given demand nodes i, j and a given base j(k), we let n : = i − 1(j(k)), i.e., the index of base j(k) in node i’s list. In this case, since \(\mathcal A_{in} = \cup_{m=n}^{B+1} \mathcal S_{im}\), we have
On the event \(\mathcal A_{jk}\), bases j(1), ..., j(k − 1) are busy. Therefore, if base i(m) is contained in this list, then base i(m) cannot answer the call originating at demand node i. In such a case, we have \(\mathcal S_{im} \cap \mathcal A_{jk} = \emptyset\). Consequently, we define the set \(M = \big\{m: n \le m \le B+1,~ i(m) \notin \{j(1), \ldots, j(k-1)\} \big\}\) of bases that are not necessarily busy on the event \(\mathcal A_{jk}\). In this case, we have
where the numerator essentially states that a call originating at i must be answered by a base that is not busy, and therefore, not in the list of busy ambulances j(1), ..., j(k − 1). Finally, letting c ∧ d = min {c, d}, we make the crude approximation that
which amounts to neglecting the “higher order” correction to \(P(\mathcal S_{im})\) that comes from intersecting with \(\mathcal A_{jk}\). Taking the minimum with a jk ensures that (14) yields a result in [0, 1].
Combining (9)-(14) with the (linear) equations relating s jk to a jk , we obtain a system of equations for the entries of the matrix S that has the form S = f(S) for an appropriately specified function f. Thus, S is a fixed point of the system, and once we determine S, we can compute performance measures as described earlier.
Appendix B: Initializing the iterative procedure for solving the overflow model fixed-point equations
Here we comment on different ways to initialize the matrix S 0 at the start of the iterative procedure described in Section 4.
The solution matrix should satisfy \(\sum_{k=1}^{B+1} s_{jk} = 1\) for every j = 1, ..., J, i.e., it is stochastic. So it is natural to choose an S 0 having this property as well. We tried 2 possibilities.
-
1.
For each j = 1,...,J let \(s^0_{j1}=1\) and \(s^0_{jk}=0\) for k = 2,..., B + 1, i.e., allocate all of the demand coming from j to its preferred base.
-
2.
For each j = 1, ..., J let \(s^0_{jk}= \bar{\rho}^{\sum_{l=1}^{k-1} n_{j(l)}}(1- \bar{\rho}^{n_{j(k)}})\), for k = 1,...,B, and \(s^0_{j,B+1} = 1 - \sum_{k=1}^N s^0_{jk}\) where \(\bar{\rho}:=\lambda/N\mu\) is the average system utilization. Under the independent server approximation, the value of \(s^0_{jk}\) corresponds to the probability that all bases preferred to j(k) in node j’s ranking are busy but base j(k) is not.
Appendix C: Detailed definition of function R(·)
Let R(S) : = (R(S)1, R(S)2, ..., R(S) N ) where R(S) v , for v = 1, ..., N represents the utilization of ambulance v. Denote by b = b(v) the base at which ambulance v is stationed, and by λ b = λ b (S), the total demand offered to this base, as defined by Eq. 9; recall from Appendix A that \(a_{jk}= \sum_{i=k}^{B+1} s_{ji}\). Then, according to the Erlang loss model, the utilization of each of the n b ambulances stationed at base b equals the average expected utilization
where
is the Erlang probability that k out of the n ambulances are busy.
Rights and permissions
About this article
Cite this article
Restrepo, M., Henderson, S.G. & Topaloglu, H. Erlang loss models for the static deployment of ambulances. Health Care Manag Sci 12, 67–79 (2009). https://doi.org/10.1007/s10729-008-9077-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10729-008-9077-4