
Abstract
Key message
This study assessed the effect of ecological variables on tree allometry and provides more accurate aboveground biomass (AGB) models through the involvement of large samples representing major islands, biogeographical zones and various succession and degradation levels of natural lowland forests in the Indo-Malay region. The only additional variable that significantly and largely contributed to explaining AGB variation is grouping based on wood-density classes.
Context
There is a need for an AGB equation at tree level for the lowland tropical forests of the Indo-Malay region. In this respect, the influence of geographical, climatic and ecological gradients needs to be assessed.
Aims
The overall aim of this research is to provide a regional-scale analysis of allometric models for tree AGB of lowland tropical forests in the Indo-Malay region.
Methods
A dataset of 1300 harvested trees (5 cm ≤ trunk diameter ≤ 172 cm) was collected from a wide range of succession and degradation levels of natural lowland forests through direct measurement and an intensive literature search of principally grey publications. We performed ANCOVA to assess possible irregular datasets from the 43 study sites. After ANCOVA, a 1201-tree dataset was selected for the development of allometric equations. We tested whether the variables related to climate, geographical region and species grouping affected tree allometry in the lowland forest of the Indo-Malay region.
Results
Climatic and major taxon-based variables were not significant in explaining AGB variations. Biogeographical zone was a significant variable explaining AGB variation, but it made only a minor contribution on the accuracy of AGB models. The biogeographical effect on AGB variation is more indirect than its effect on species and stand characteristics. In contrast, the integration of wood-density classes improved the models significantly.
Conclusion
Our AGB models outperformed existing local models and will be useful for improving the accuracy on the estimation of greenhouse gas emissions from deforestation and forest degradation in tropical forests. However, more samples of large trees are required to improve our understanding of biomass distribution across various forest types and along geographical and elevation gradients.
Similar content being viewed by others

1 Introduction
Tropical lowland forests are one of the most important forest types in the Indo-Malay Archipelago, owing to its extent, species diversity and biomass accumulation (Whitten 1987; Jepson et al., 2001; Marshall and Beehler 2007). The forests in this region play a crucial role in economic development and in biodiversity conservation, environmental protection and climate-change mitigation (FAO 2015; MoEF 2015). Accurate estimation of forest biomass is important for understanding carbon balance and the dynamics of tropical ecosystems (Cramer et al., 2004; Clark and Kellner 2012). Landscape studies on biomass balance assessment commonly use ground measurement and remote sensing techniques, which require allometric equations to convert tree metrics derived from ground measurements to tree aboveground biomass (AGB) (Slik et al., 2008; Henry et al., 2015).
Unbiased and precise allometric equations would provide more accurate estimates of forest AGB stock and CO2 emissions associated with deforestation and forest-degradation activities (Chave et al., 2014). The term of bias used is to define systematic departure of predicted values from observed values (Avery and Burkhart 1983). Unbiased models have regression slopes between predicted and observed values not significantly different from one and intercepts not significantly different from zero. The scatter of the points around the line of observed and predicted values is a measurement of precision. Precision is commonly measured using standard deviation or root mean square error (RMSE).
The most accurate AGB equations commonly include traditional variables as predictor variables in the form of AGB = Exp (Ln α + Ln β*D 2 GH + ɛ), where AGB is a function of diameter at breast height (D, in cm), tree height (H, in m), specific wood density (G, in gramme.cm−3), α and β are model parameters and ɛ is the error term (Chave et al., 2005; Vieilledent et al., 2012). However, the choice of AGB models often depends not only on the accuracy of the model but also on the availability of the variables recorded during field inventories. In the absence of G or H, several authors use other model forms, for example, AGB = Exp (Ln α + Ln β*D 2 H + ɛ); AGB = Exp (Ln α + Ln β*D 2 G + ɛ) or AGB = Exp (Ln α + Ln β*D + ɛ) Basuki et al. (2009); Sileshi 2014). The more comprehensive the field measurements, the greater the logistical requirements. Thus, several models have been developed using fewer predictor variable, which leads to a trade-off between cost and accuracy (Brown et al., 1989). To overcome the logistical problem or reduce the cost for measuring every tree height, development of a local H-D model is often suggested for AGB estimation in tropical forests (Feldpausch et al., 2012). Ledo et al. (2016) found that local H-D model developed using the three-parameter Weibull model form was the most unbiased models compared to various H-D model forms.
Attempts to improve the AGB models have included adding more and a wider range of samples or explored additional predictor variables. Goodman et al. (2014) concluded that crown size is an additional important predictor variable, and that it is more influential than the tree-height variable in estimating tree AGB in Peru. However, performance assessment of model with additional variables needs to be carried out comprehensively, because the coefficient of determination will always increase when more predictor variable is added to the model (Neter et al., 1996).
G is another important factor, but it is not easy to define the appropriate values using global wood-density databases due to the high variation of G between and within species. Further, identifying tree species accurately from highly diverse tropical forests during forest inventory is difficult. In the absence of a scientific tree name, a simple species grouping based on similar wood classes improves AGB estimates in tropical peat swamp forests (Manuri et al., 2014). Further, taxon-based grouping improves the performance of the AGB model (Basuki et al., 2009; Paul et al., 2016).
Several studies have suggested developing regional allometric equations for nation-wide scales (Vieilledent et al., 2012; Ishihara et al., 2015). However, the influence of geographical, climatic and ecological gradients to the model need to be assessed to ensure precision of the AGB estimates and avoid biases of the estimates when the generic model is applied locally. A regional AGB equation for the Indo-Malay region has not been developed. Developing such a model requires a large dataset of destructive sampling collected from a wide range of geographical and environmental conditions. Anitha et al. (2015) found as many as 168 studies (mostly unpublished) on the development of local AGB equations in 21 forest ecosystems in Indonesia. Unfortunately, these local AGB equations were developed from either a low number of sample trees or a limited range of tree diameters. In addition, more than 68% of the equations were developed for species-specific equations, and thus were impractical for use in highly diverse tropical forest ecosystem. Compilation of existing datasets from published and unpublished studies is thus required for the development of the regional model to ensure the validity of the model across a vast area of the lowland tropical forests of the region.
Tree diversity can reach more than 200 species per hectare in lowland tropical forests of the Indo-Malay region, making it one of the most diverse forest types in the world (Kartawinata 1990). The development of species-specific biomass equations is not a feasible option for such highly diverse tropical forests. However, specific equations based on geographical, climatic and ecological gradients can be used to improve the AGB models (Alvarez et al., 2012). Differences in vegetation characteristics and species diversity among the geographical regions of Indo-Malay are evident (Van Welzen et al., 2011). The Indo-Malay regions have been divided by the imaginary Wallace and Lydekker lines. Although these lines were drawn based on the faunal distinction and the historical geological formation (Mayr 1944), this division can be used for differentiating phytogeographical zones because the lines discontinued or lessened the dispersal of many plant species (Van Welzen et al., 2011).
The overall aim of this research is to provide a regional-scale analysis on tree biomass allometric models for lowland forests across the Indo-Malay Archipelago. The study compiled harvested tree AGB databases of lowland tropical forests and developed regional allometric equations for lowland forests on mineral soils. The study also assessed the influence of species grouping and site-related variables (including climatic and geographical variables) on tree AGB variations.
2 Material and methods
2.1 Study sites
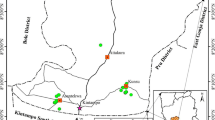
We compiled sampled sites with lowland forests within the Indo-Malay Archipelago, including major island groups (i.e. Malay Peninsula, Sumatra, Borneo, Java, Nusa Tenggara, Maluku and Papua; see Fig. 1). The latitude and longitude of the study sites ranged from 10.31° south to 4.039° north and 98.79° east to 140.50° east. The mean annual precipitation of the study sites ranged from 1375 to 3992 mm with altitudes between 16 and 1000 m above sea level. We limited our study to only natural lowland forests on mineral soils. Therefore, we excluded mountain forests, peat swamp forests, mangroves and plantation forests from this study. Our interest lies not only in primary forests but also in logged-over and secondary forests. We divided our study sites into three regions: west, middle and east following the biogeographical theory based on floristic similarities (Fig. 1). The dominance of Dipterocarpaceae in the western region diminished towards the middle and eastern parts of the region, replaced by Ericaceae, Monimiaceae and Sapindaceae (Van Welzen et al., 2011). In the southeastern part of the middle region, with the influence of dry climate, savannah and deciduous vegetation dominate the landscape (Monk et al., 1997).

Distribution of destructive-sampling plots used in this study. Darker grey colours indicated areas of higher elevation. The dashed lines represent bio-geographical borders suggested by Van Welzen et al. (2011)
2.2 Tree AGB data
We collected data through direct measurement and supplemented these data with a literature review of principally grey publications (see Appendix S1 for detail of the method applied and Appendix S4 for a list of compiled studies). A total of 1463 of destructive-sampling data from direct measurement and literature were compiled from 22 independent studies in 43 different sites (Table 1, Appendix S5). Eighty-six per cent of our datasets were originally derived from lowland dipterocarp forest in the western region, and only 4 and 9% of the total samples were derived from lowland forests in the middle and eastern regions of the Indo-Malay region, respectively. Approximately 30% of the datasets were derived from Chave et al. (2014) with n = 425 (Appendix S5). We excluded trees with D less than 5 cm due to their small contribution to the landscape-level carbon budget and high variation of residuals, which resulted in a total of 1300 samples compiled from direct measurements and literature review (Table 1).
Compiled datasets from the literature were principally collected from independent studies. They were collected using different methods for field and lab measurements. Some of the studies did not provide details of how the data were collected and could not be verified further for data validation. Therefore, we performed ANCOVA for the 43 sites to evaluate possible outlier trends of each dataset. Dataset that is represented by a separate regression line may be collected using different method and thus should be excluded in the analysis. We found that two datasets (EasKal10 and CenKal2) were represented by separated regressions lines (Fig. 2). These datasets were collected from lowland dipterocarp forests in Borneo, which is one of the major forest types in Borneo and well represented in our samples. We suspected this is because of systematic errors in definition and assumptions used during the field-data collection and laboratory analysis (Manuri et al., 2016).

ANCOVA for 43 study sites. The solid lines represent the regression lines of the outlier datasets, which are separated from the majority dashed lines. The cross marks denote datasets from EasKal10 and CenKal2, respectively
Given that not all studies measured G, we used the global wood-density database from Chave et al. (2009) based on the closest taxonomy to fill in the missing data. We validated the species names following the nomenclature from the available tree flora checklists (Slik 2009 onwards; The Plant List 2013). For evaluating the influence of site variables, we extracted mean annual precipitation (P) from global climate data (Hijmans et al., 2005) and global environmental stress data (E) provided by Chave et al. (2014) for each field plot.
2.3 Assessment of influencing factors on AGB estimation
D, G and H are the most frequently used predictor variables in estimating tree AGB due to their capability in explaining AGB variation in tropical forests (Brown 1997; Chave et al., 2014). In addition to those traditional variables, we performed a regression analysis to assess other additional factors related to climatic conditions, biogeographical regions (R) and species grouping based on wood density and taxonomy. We used mean annual precipitation (P) and environmental stress (E) as variables related to climatic conditions. We tested the potential of species grouping, using tree family (F) and wood-density class (GC) (i.e. low, medium and high-density classes). GC was derived from the G values by applying threshold values of 0.5 and 0.6 cm3 g−1. Due to the high diversity of tree species, family grouping (FG) was also defined based on major family groups, dipterocarp and non-dipterocarp. To assess the variable effect to the model, we compared LogWorth values of the variables, which were calculated as -log10 (p value) for better scaling purpose (Sall 2002). We evaluated the multicollinearity of each variable using the variance inflation factor (VIF). Variables with VIF more than five were expected to have multicollinearity (Sileshi 2014). The model forms, in which the variables have large VIF, were excluded in the model development.
2.4 Development of AGB equations
Several considerations are crucial in selecting the best AGB model, i.e. (1) statistical correctness (including the best goodness of fit of model parameters, applying appropriate correction factor for log linear models, normal residuals distribution, excluding models with high collinearity among predictor variables), (2) high accuracy and predictive capability and (3) practical for field implementation (Overman et al., 1994).
Through the Breusch–Pagan test and abridged White’s test (Gujarati 2014), we found that our data exhibited heteroscedasticity (p < 0.0001; see Appendix S2). Therefore, we transformed AGB into a natural logarithm to overcome the heteroscedasticity problem. To reduce systematic bias from back-transformation, we tested two correction factors, i.e. the ‘MM’ correction factor (Shen and Zhu 2008), as suggested by Clifford et al. (2013), and ratio estimator (REst) (Snowdon 1991). Manuri et al. (2014) suggested that back-transforming using REst provide more accurate models than using correction factor suggested by Baskerville (1972).
To accommodate the availability of field-data parameters, we developed equations from a wide range of model forms as suggested by Chave et al. (2014) and Sileshi (2014). We categorised the AGB models, based on the use of traditional predictor variables, into four model types (i.e. those using D, DH, DG and DGH). The selection of the best equations was based on the highest adjusted coefficient of determination (adj R 2), the lowest RMSE and the lowest corrected Akaike information criterion (AICc). To test the accuracy of the AGB model that incorporated the local H-D model, we developed a regional H-D model using the three-parameter Weibull model form (Bailey 1980; Feldpausch et al., 2012; Ledo et al., 2016).
We evaluated the precision and bias of the models when applied to the individual dataset, species groups and forest type. Unbiased models have regression slopes between predicted and observed values not significantly different to 1 and intercepts not significantly different from 0. Precision is commonly measured using adj R 2 or RMSE. Additionally, we calculated the mean relative error (MRE) and the mean absolute relative error (MARE) of each model (Picard et al., 2015). Most of the statistical analyses in this study were performed using JMP 12 software (SAS II, 2015). For calculating the MM correction factors, we used the code provided by Clifford et al. (2013) for R statistical package (R-Development-Core 2013).
3 Results
3.1 Factors affecting AGB estimation
We assessed the influence of traditional (i.e. Ln D, Ln G, Ln H) and additional variables (i.e. R, GC, P, FG and E) when fitted to various linear Ln AGB models using regression analysis. We found that the traditional and most of the additional variables were significant at p < 0.05 for estimating AGB (Table 2). The traditional variables had larger LogWorth values than the additional variables. This means that they had greater influence in explaining the variation of AGB. The variables related to Ln D, either stand-alone or in combination with G or H, were always the most prominent factors, followed by Ln G and Ln H.
GC and R were the most influential additional variables. Both had the highest LogWorth values after the traditional variables (Table 2). In the DH model, the LogWorth of GC was higher than Ln H, with values of 48.7 and 16.1, respectively. P and E variables were not significant in explaining the AGB variations in most model types. In the DGH models, most additional variables were either not significant or the less influential than traditional variables (with very small LogWorth values). Only models that included Ln H and Ln D separately had problems with collinearity (VIF greater than 5).
3.2 AGB equations for lowland forests
We developed linear models with a combination of traditional factors (i.e. D, H and G) and additional factors (i.e. GC and R). The previous analysis provided justification for selection of the best eight model types. All the multivariate model forms involving the D and H variables separately revealed multicollinearity with VIF > 5 (Table 2). The selected linear AGB models were fitted to the compiled dataset from the lowland tropical forests of Indo-Malay region (Appendix S3) and were back-transformed using the MM and REst correction factors. We found that models back-transformed using REst performed better than the ones back-transformed using MM correction factor. The MREs and MAREs of the REst back-transformed models were lower than the MM back-transformed models, except for all DH models (Appendix S6). Therefore, we used the models that back-transformed using REst correction factors for further analysis.
The simplest model (D1) was the least precise and unbiased model, with the highest MRE and MARE (14.0 and 41.5%, respectively) (Table 3). Residuals of D1 and DH1 against wood-density values did not depict normal distribution, with regression slopes further from zero (Appendix S7). This means that trees of high wood density tended to have positive errors and vice versa. The inclusion of GC in the D2 and DH2 models reduced the slopes of residual distribution to close to zero. GC integration in the D2 and DH2 models increased the adjusted R 2 by 3.3 and 3.7%, respectively. The inclusion of G variable reduced bias (MRE) and precision (MARE), 35 and 26%, respectively (Table 3). The H variable was less influential in the models performance, increasing R 2 by only 0.3–0.4%. In addition, the DG2 and DGH2 models did not perform better than the models without the additional variable of R (DG1 and DGH1).
To assess the accuracy of the AGB model that involved the H-D model, we developed a regional model using three-parameters Weibull function (n = 1057). We found that tree diameter explained 85.6% of tree-height variation (Fig. 3). We integrated the H-D model into the DHW and DGHW models. Both models performed only slightly worse than the original models that used measured H (Table 3; Fig. 4).

For the regional H-D model, we fitted nonlinear regression using Weibull function (a) and fitted the predicted H with observed H (b). The cross marks represent the outlier dataset (i.e. EasKal10) defined in the AGB–D relationship

Scatterplots of the observed (y-axis) and the predicted (x-axis) root AGB of selected best models. The lines are the fitted lines. Outlier datasets, EasKal10 and CenKal2, are represented by the cross and x marks, respectively
Finally, we evaluated the precision and bias of the models on various islands, forest types and tree families. The models have high bias and low precision for the Java and Sulawesi datasets (Fig. 5). We found that most of the models did not perform well on the secondary forest, heat forest and agroforestry datasets, particularly the D and DH models. At the tree-family level, Rutaceae, Asteraceae, Apocynaceae, Sabiaceae, Rhizophoraceae, Euphorbiaceae, Cannabaceae, Crypteroniaceae, Pipperaceae, Anisophylleaceae and Sapindaceae show high bias, where −0.5 > MRE > 0.5 (Fig. 5).

Relationship between MARE and MRE of the AGB models for each (a) island, (b) forest type and (c) family
4 Discussion
4.1 Importance of traditional variables in explaining tree AGB variations
The model with the diameter as the only predictor variable performed worse than the models with the added variables of tree height and wood density. This finding was in agreement with other studies on highly diverse tropical forests (Chave et al., 2014; Manuri et al., 2014) but contrasted with several studies in low-diversity ecosystems such as secondary forests (Hashimoto et al., 2004), Australian dry sclerophyll forests (Paul et al., 2013) and swidden fallow forests (McNicol et al., 2015). The inclusion of wood-density classes improved the performance of our models for lowland tropical forests. Substantial differences of mean wood density among species, forest type and successions influenced the variation of tree allometry in tropical forests (Hashimoto et al., 2004; Slik 2006). We concluded that diameter and wood density are essential variables in estimating AGB in highly diverse tropical ecosystems. We also found that the inclusion of H variables only slightly improved the performance of the regional AGB models, and performed no better than when G was included. The potential reason could be that H and D in our datasets have a strong correlation and thus introduce collinearity.
4.2 Effect of site-related and species-grouping variables in tree allometry
Most of the additional variables had less influence on the AGB models than the traditional variables. Although mean annual precipitation and environmental stress were significant variables in explaining AGB variations, their inclusion only slightly improved the precision of the models. The inclusions of climate-related variables were not considered worthwhile given the effort of collecting the variable data. Further, their influence diminished with the introduction of the G and H variables to the models. This was likely because climate influences stand characteristics more than AGB variation directly (Durán et al., 2015). For example, a low-precipitation environment tended to have trees with high wood density (Onoda et al., 2010) and stimulated taller trees (Banin et al., 2012). Thus, the inclusion of G and H into the AGB model could explain the AGB variation created by the climate-related variables.
Despite the evident differences in the vegetation characteristics and species composition between the western and eastern regions of Indo-Malay (Van Welzen et al., 2011), our biogeographical-wise equations only slightly improved the accuracy of AGB estimation. The influence of the biogeographical region remained prominent in the AGB model without the variables of wood density and tree height. Further, the effect of the region on the H-D model was more influential than it was on the AGB models (results not shown). In addition, edaphic and climatic factors associated with biogeographic variables had correlations with tree-wood density (Slik et al., 2010). This suggests that the biogeographical effect on AGB variation is more indirect than its effect on species and stand characteristics such as wood density and tree height.
We found that the wood-density class was the only additional variable that contributed to a substantial improvement in the accuracy of AGB estimation. This finding was in agreement with an earlier study conducted in tropical peat swamp forests (Manuri et al., 2014). Kenzo et al. (2009) also emphasised the need for differentiating tree allometry of primary forests and secondary forests, which are substantially different in the mean value of their wood density. Thus, species groupings based on similar wood density could be factored into biomass equations for a wide range of characteristics related to wood density, including heavy and light timber species, climax and pioneer species or secondary and primary forests (Slik 2006). However, our species grouping, which was based on major family groups (i.e. dipterocarp and non-dipterocarp) had little influence in explaining the variation of tree AGB. This finding is in contrast to the study in tropical peat swamp forests, where species grouping based on dipterocarp and non-dipterocarp family group improves the accuracy of AGB estimation (Manuri et al., 2014). Although our analysis demonstrated that the species grouping based on family was a significant variable to AGB estimates (result not shown), we decided not to develop taxon-based models due to their inapplicability in highly diverse tropical forests and an insufficient sample number to represent each family.
4.3 Implication for forest-biomass assessment approach
Our regional models were developed based on samples collected from several tropical lowland forest types on mineral soils on several major islands in the Indo-Malay region. Thus, these models are more representative of major lowland forest types than the existing local models that have been created from the region. None of the existing local models perform better than our regional models because the sample sizes used for developing the local models were generally limited in number, diameter range, species diversity and environmental condition (Ishihara et al., 2015). Our samples better represent the various succession and degradation levels of the natural lowland forests than the samples used in the local models. Given these limitations, the local models fail to estimate AGB accurately beyond their range of validity. Thus, validation is crucial before the use of local models, particularly when estimating forest AGB outside the area where the models were developed.
It is common that during the process of forest inventory, the field crew measure only trunk diameter due to difficulties in species identification, occlusion of tree tops or simply because of logistical constraints (Higgins and Ruokolainen 2004). The use of an H-D model and the recording of local commercial names instead of scientific species names were endorsed through a government regulation for forest inventories conducted by timber concessionaires or local communities in Indonesia (MoF 2007). Therefore, the results of this study should be able to overcome the limitations in measuring H.
As there is a high uncertainty in H measurement of trees in dense tropical forests, a simple approach using the H-D model was suggested to substitute H values in AGB models (Feldpausch et al., 2012). Our testing on the integration of H prediction into AGB models suggested that the models had almost similar precision to the model using H from field measurement. However, the models demonstrated a larger bias than the model with field-measured H. Therefore, we suggest further evaluation of the use of H prediction in the AGB models using the whole-plot datasets.
In cases where tree height (both from field measurement and local H-D model) cannot be determined, the D2 and DG1models, which perform at a comparably level of accuracy to our more complex DGH1 model, should be used. During forest inventory, G was commonly estimated using the proxy data (i.e. tree taxonomy). This could be a source of error due to G variation inter and within species (Henry et al., 2010), which was influenced by species life strategy, individual competition and site characteristics (Muller-Landau 2004). He and Deane (2016) concluded that tree size also plays role in explaining the variation of wood density of tree trunks and branches.
A globally compiled wood-density database was often used for this purpose, which potentially introduced error, particularly for trees of small diameter and uncommercial trees (Manuri et al., 2014). Furthermore, the number of species listed in the global database is far less the total global species number, whereas tropical tree species contributed to a major unmeasured species (Williamson and Wiemann 2010). However, the error of G estimation at species level from the taxon-based approach should not be of great concern when estimating AGB at plot and landscape level because the G variation at tree level is strongly related to the G at genus level (Chave et al., 2006; Slik 2006).
The D2 model included species grouping based on wood-density class, which improved the accuracy of the original D1 model. Such an approach will be very useful for field biomass measurements made by timber concessions or small-scale community forests. Determining high-density or low-density wood without a scientific name should not be problematic. Often forest managers employ villagers who can accurately identify tree species based on local names. Databases linking local names and wood-density values are commonly initiated at local levels (Martawijaya et al., 2005; Putra et al., 2011). Alternatively, the collection of data on wood density using non-destructive techniques (e.g. small cores or pilodyn) should be able to provide accurate wood-density values or classes and thus AGB accuracy (Williamson and Wiemann 2010; Kotowska et al., 2015).
Finally, for more accurate AGB estimations, we propose using the DGH1or DG1 models because the influence of region is trivial for the accuracy of the AGB estimates. When G is unavailable, we suggest using D2 or DH2, which have additional variables for wood-density classes. Our models should be valid for AGB assessment in a wide range of succession and degradation levels of natural lowland forests in the region.
4.4 Limitations and future research directions
Although the coverage of forest types used in this study accounted for more than 65% of total forests from their original distribution (Whitten 1987; MacKinnon 1996; Marshall and Beehler 2007), our samples were drawn principally from dipterocarp forest and a limited number of samples from other vegetation types such as non-dipterocarp lowland forests, limestone forests, heath forests and deciduous forests. Further research is thus required to fine-tune these equations, and should focus on lowland non-dipterocarp forests, particularly freshwater swamp forests, forests on ultrabasic soils, and deciduous forests. Further, the datasets used for this study were skewed in geographical distribution. Thirty-one of 43 sites were located in the western Indo-Malay region. Due to the high variation in ecological and geographical conditions among islands, more datasets derived from islands in the central (Sulawesi and Maluku) and eastern regions (Papua) are required to improve our understanding of biomass distribution across various forest types and along geographical and elevation gradients. We also suggest further sampling of non-dipterocarp species and from the middle and eastern regions, which are underrepresented in our study. However, although the dipterocarp trees are better represented in this study, the model precision of this species group is still relatively low due to the high diversity of the dipterocarp family.
Datasets from independent research are often subjected to incomparable datasets due to unstandardised methods in destructive sampling. Although a national standard for tree allometric development has been developed for Indonesia (BSN 2011), most of the studies in Indonesia did not comply with this standard. Specific attention must focus on standardising the G measurement method for converting stem and large branch volumes into biomass during destructive sampling. Williamson and Wiemann (2010) identified several common mistakes in G measurement, including unrepresentativeness of wood samples, low temperature drying and incorrect measurement of wood-sample volume.
More than 5000 trees were felled for studies on local biomass equations using destructive sampling in Indonesia (Anitha et al., 2015). However, the datasets were difficult to access due to the scarcity of published reports or literature. Database repositories that compile data from existing studies must be created because destructive sampling is time-consuming and logistically demanding, particularly in relation to managing felling permits and local logistical arrangements.
Further, the focus of such data repositories and data collection should be for large trees with trunk diameters of more than 60 cm. New methods of terrestrial laser scanning (TLS) used for generating three-dimensional (3D) features using point clouds could be a potential approach for non-destructive sampling of very large trees (Olagoke et al., 2016). The number of TLS studies on forest structures and individual trees has increased in the past decade, including studies that perform tree-volume estimation using the 3D cylinder-fitting method. Pfeifer et al. (2004) and Raumonen et al. (2013) found that tree AGB estimates using TLS were more than 90% accurate, and thus far, better than estimates using allometric equations. Such methods will be very useful for assessing the AGB of large trees, particularly in areas where tree harvesting is restricted by legal or logistical limitation.
5 Conclusion
This study provides more accurate regional AGB models through the involvement of large samples representing major islands, biogeographical zones and various succession and degradation levels of natural lowland forests in the Indo-Malay region. Our models outperformed existing local models. The traditional variables explained more AGB variation than additional variables related to species grouping and site characteristics. Wood-density class is the most influential additional variables to tree AGB allometry. Despite its significance in explaining AGB variations, the inclusion of biogeographical region as an independent variable only slightly improved the accuracy of AGB models.
References
Alvarez E, Rodríguez L, Duque A, Saldarriaga J, Cabrera K, de las Salas G, del Valle I, Lema A, Moreno F, Orrego S (2012) Tree above-ground biomass allometries for carbon stocks estimation in the natural forests of Colombia. For Ecol Manag 267:297–308. doi:10.1016/j.foreco.2011.12.013
Anitha K, Verchot LV, Joseph S, Herold M, Manuri S, Avitabile V (2015) A review of forest and tree plantation biomass equations in Indonesia. Ann Forest Sci 72:1–17
Avery TE, HE Burkhart (1983) FOREST MEASUREMENTS, Mcgraw-hill, New York
Bailey RL (1980) The potential of Weibull-type functions as flexible growth curves: discussion. Can J For Res 10:117–118
Banin L, Feldpausch T, Phillips O, Baker T, Lloyd J, Affum-Baffoe K, Arets E, Berry N, Bradford M, Brienen R (2012) What controls tropical forest architecture? Testing environmental, structural and floristic drivers. Glob Ecol Biogeogr 21:1179–1190
Baskerville G (1972) Use of logarithmic regression in the estimation of plant biomass. Can J For Res 2:49–53
Basuki TM, van Laake PE, Skidmore AK, Hussin YA (2009) Allometric equations for estimating the above-ground biomass in tropical lowland dipterocarp forests. For Ecol Manag 257:1684–1694. doi:10.1016/j.foreco.2009.01.027
Brown S (1997) Estimating biomass and biomass change of tropical forests a primer. Food and Agriculture Organization of the United Nations
Brown S, Gillespie AJ, Lugo AE (1989) Biomass estimation methods for tropical forests with applications to forest inventory data. For Sci 35:881–902
BSN (2011) Penyusunan persamaan alometrik untuk penaksiran cadangan karbon hutan berdasar pengukuran lapangan (ground based forest carbon accounting). Standar Nasional Indonesia SNI 7725:2011
Chave J, Kira T, Lescure JP, Nelson BW, Ogawa H, Puig H, Riéra B, Yamakura T, Andalo C, Brown S, Cairns MA, Chambers JQ, Eamus D, Fölster H, Fromard F, Higuchi N (2005) Tree allometry and improved estimation of carbon stocks and balance in tropical forests. Oecologia 145:87–99. doi:10.1007/s00442-005-0100-x
Chave J, Muller-Landau HC, Baker TR, Easdale TA, Ht S, Webb CO (2006) Regional and phylogenetic variation of wood density across 2456 neotropical tree species. Ecol Appl 16:2356–2367
Chave J, Coomes D, Jansen S, Lewis SL, Swenson NG, Zanne AE (2009) Towards a worldwide wood economics spectrum. Ecol Lett 12:351–366
Chave J, Réjou-Méchain M, Búrquez A, Chidumayo E, Colgan MS, Delitti WB, Duque A, Eid T, Fearnside PM, Goodman RC, Henry M, Martínez-Yrízar A, Mugasha WA, Muller-Landau HC, Mencuccini M, Nelson BW, Ngomanda A, Nogueira EM, Ortiz-Malavassi E, Pélissier R, Ploton P, Ryan CM, Saldarriaga JG, Vieilledent G (2014) Improved allometric models to estimate the aboveground biomass of tropical trees. Glob Chang Biol 20:3177–3190
Clark DB, Kellner JR (2012) Tropical forest biomass estimation and the fallacy of misplaced concreteness. J Veg Sci 23:1191–1196
Clifford D, Cressie N, England JR, Roxburgh SH, Paul KI (2013) Correction factors for unbiased, efficient estimation and prediction of biomass from log–log allometric models. For Ecol Manag 310:375–381. doi:10.1016/j.foreco.2013.08.041
Cramer W, A Bondeau, S Schaphoff, W Lucht, B Smith, S Sitch, e Institutionen för naturgeografi och, u Lunds, f Naturvetenskapliga, U Lund, S Faculty of, G Dept of Physical, S Ecosystems (2004) Tropical forests and the global carbon cycle: impacts of atmospheric carbon dioxide, climate change and rate of deforestation. Philosophical Transactions of the Royal Society of London Series B: Biological Sciences 359:331–343. doi: 10.1098/rstb.2003.1428
Durán SM, Sánchez-Azofeifa GA, Rios RS, Gianoli E (2015) The relative importance of climate, stand variables and liana abundance for carbon storage in tropical forests. Glob Ecol Biogeogr 24:939–949
FAO (2015) Global Forest Resources Assessment 2015: How are the world’s forests changing? Food and Agriculture Organization of the United Nations, Rome
Feldpausch TR, J Lloyd, SL Lewis, RJ Brienen, M Gloor, A Monteagudo Mendoza, G Lopez-Gonzalez, L Banin, K Abu Salim, K Affum-Baffoe (2012) Tree height integrated into pantropical forest biomass estimates. Biogeosciences 3381–3403
Goodman RC, Phillips OL, Baker TR (2014) The importance of crown dimensions to improve tropical tree biomass estimates. Ecol Appl 24:680–698
Gujarati D (2014) Econometrics by example. Palgrave Macmillan, New York
Hashimoto T, Tange T, Masumori M, Yagi H, Sasaki S, Kojima K (2004) Allometric equations for pioneer tree species and estimation of the aboveground biomass of a tropical secondary forest in East Kalimantan. Tropics 14:123–130
He D, Deane DC (2016) The relationship between trunk-and twigwood density shifts with tree size and species stature. For Ecol Manag 372:137–142
Henry M, Besnard A, Asante W, Eshun J, Adu-Bredu S, Valentini R, Bernoux M, Saint-Andre L (2010) Wood density, phytomass variations within and among trees, and allometric equations in a tropical rainforest of Africa. For Ecol Manag 260:1375–1388
Henry M, Jara MC, Réjou-Méchain M, Piotto D, Fuentes JMM, Wayson C, Guier FA, Lombis HC, López EC, Lara RC (2015) Recommendations for the use of tree models to estimate national forest biomass and assess their uncertainty. Ann Forest Sci 72:769–777
Higgins MA, Ruokolainen K (2004) Rapid tropical forest inventory: a comparison of techniques based on inventory data from western Amazonia. Conserv Biol 18:799–811
Hijmans RJ, Cameron SE, Parra JL, Jones PG, Jarvis A (2005) Very high resolution interpolated climate surfaces for global land areas. Int J Climatol 25:1965–1978. doi:10.1002/joc.1276
Ishihara MI, Utsugi H, Tanouchi H, Aiba M, Kurokawa H, Onoda Y, Nagano M, Umehara T, Ando M, Miyata R (2015) Efficacy of generic allometric equations for estimating biomass: a test in Japanese natural forests. Ecol Appl 25:1433–1446
Jepson P, Jarvie JK, MacKinnon K, Monk KA (2001) The end for Indonesia’s lowland forests? Science 292:859–861
Kartawinata K (1990) A review of natural vegetation studies in Malesia, with special reference to Indonesia. The plant diversity of Malesia Proc symposium, Leiden 1989:121–132
Kenzo T, Takahashi N, Okamoto M, Tanaka-Oda A, Sakurai K, Ninomiya I, Ichie T, Hattori D, Itioka T, Handa C, Ohkubo T, Kendawang JJ, Nakamura M, Sakaguchi M (2009) Development of allometric relationships for accurate estimation of above- and below-ground biomass in tropical secondary forests in Sarawak, Malaysia. J Trop Ecol 25:371–386. doi:10.1017/s0266467409006129
Kotowska MM, Leuschner C, Triadiati T, Meriem S, Hertel D (2015) Quantifying above-and belowground biomass carbon loss with forest conversion in tropical lowlands of Sumatra (Indonesia). Glob Chang Biol 21:3620–3634
Ledo A, Cornulier T, Illian JB, Iida Y, Kassim AR, Burslem DF (2016) Re-evaluation of individual diameter: height allometric models to improve biomass estimation of tropical trees. Ecol Appl 26:2374–2380
MacKinnon K (1996) The ecology of Kalimantan. Oxford University Press, Hong Kong
Manuri S, Brack C, Nugroho NP, Hergoualc’h K, Novita N, Dotzauer H, Verchot L, Putra CAS, Widyasari E (2014) Tree biomass equations for tropical peat swamp forest ecosystems in Indonesia. For Ecol Manag 334:241–253
Manuri S, Brack C, Noor’an F, Rusolono T, Anggraini SM, Dotzauer H, Kumara I (2016) Improved allometric equations for tree aboveground biomass estimation in tropical dipterocarp forests of Kalimantan, Indonesia. Forest Ecosystems 3:28
Marshall AJ, BM Beehler (2007) Ecology of Indonesian Papua Part One, Tuttle Publishing
Martawijaya A, I Kartasujana, K Kadir, S Prawira (2005) Atlas kayu Indonesia Jilid II: 91–95. Badan Penelitian dan Pengembangan Kehutanan, Departemen Kehutanan Bogor Edisi revisi
Mayr E (1944) Wallace’s line in the light of recent zoogeographic studies. Q Rev Biol 19:1–14
McNicol IM, Berry NJ, Bruun TB, Hergoualc’h K, Mertz O, de Neergaard A, Ryan CM (2015) Development of allometric models for above and belowground biomass in swidden cultivation fallows of northern Laos. For Ecol Manag 357:104–116
MoEF (2015) National Forest Reference Emission Level for Deforestation and Forest Degradation: In the Context of Decision 1/CP.16 para 70 UNFCCC (Encourages developing country Parties to contribute to mitigation actions in the forest sector). Directorate General of Climate Change The Ministry of Environment and Forestry Indonesia
MoF (2007) Pedoman Inventarisasi Hutan Menyeluruh Berkala (IHMB) pada Usaha Pemanfaatan Hasil Hutan pada Hutan Produksi. Ministry of Forestry, Republic of Indonesia, Jakarta Permenhut No 34/2007
Monk KA, de Fretes Y, Reksodiharjo-Lilley (1997) The ecology of Nusa Tenggara and Maluku. Indonesian Ministry of Environment and Dalhausie University. Halifax, Nova Scotia
Muller-Landau HC (2004) Interspecific and inter-site variation in wood specific gravity of tropical trees. Biotropica 36:20–32
Neter J, MH Kutner, CJ Nachtsheim, W Wasserman (1996) Applied linear statistical models, Irwin Chicago
Olagoke A, Proisy C, Féret J-B, Blanchard E, Fromard F, Mehlig U, de Menezes MM, Dos Santos VF, Berger U (2016) Extended biomass allometric equations for large mangrove trees from terrestrial LiDAR data. Trees 30:935–947
Onoda Y, Richards AE, Westoby M (2010) The relationship between stem biomechanics and wood density is modified by rainfall in 32 Australian woody plant species. New Phytol 185:493–501
Overman JPM, Witte HJL, Saldarriaga JG (1994) Evaluation of regression models for above-ground biomass determination in Amazon rainforest. J Trop Ecol 10:207–218
Paul KI, Roxburgh SH, Ritson P, Brooksbank K, England JR, Larmour JS, John Raison R, Peck A, Wildy DT, Sudmeyer RA, Giles R, Carter J, Bennett R, Mendham DS, Huxtable D, Bartle JR (2013) Testing allometric equations for prediction of above-ground biomass of mallee eucalypts in southern Australia. For Ecol Manag 310:1005–1015. doi:10.1016/j.foreco.2013.09.040
Paul KI, Roxburgh SH, Chave J, England JR, Zerihun A, Specht A, Lewis T, Bennett LT, Baker TG, Adams MA, Huxtable D, Montagu KD, Falster DS, Feller M, Sochacki S, Ritson P, Bastin G, Bartle J, Wildy D, Hobbs T, Larmour J, Waterworth R, Stewart HTL, Jonson J, Forrester DI, Applegate G, Mendham D, Bradford M, O'Grady A, Green D, Sudmeyer R, Rance SJ, Turner J, Barton C, Wenk EH, Grove T, Attiwill PM, Pinkard E, Butler D, Brooksbank K, Spencer B, Snowdon P, O'Brien N, Battaglia M, Cameron DM, Hamilton S, McAuthur G, Sinclair J (2016) Testing the generality of above-ground biomass allometry across plant functional types at the continent scale. Glob Chang Biol 22:2106–2124. doi:10.1111/gcb.13201
Pfeifer N, B Gorte, D Winterhalder (2004) Automatic reconstruction of single trees from terrestrial laser scanner data. Proceedings of 20th ISPRS Congress, pp. 114–119
Picard N, Rutishauser E, Ploton P, Ngomanda A, Henry M (2015) Should tree biomass allometry be restricted to power models? For Ecol Manag 353:156–163
Putra CAS, Manuri S, Heriyanto SC (2011) Pohon-Pohon Hutan Alam Rawa Gambut Merang. MRPP-GIZ, Palembang
Raumonen P, Kaasalainen M, Åkerblom M, Kaasalainen S, Kaartinen H, Vastaranta M, Holopainen M, Disney M, Lewis P (2013) Fast automatic precision tree models from terrestrial laser scanner data. Remote Sens 5:491–520
R-Development-Core T (2013) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna
Sall J (2002) Monte carlo calibration of distributions of partition statistics. SAS Institute Inc
SAS II (2015) Using JMP 12. SAS Institute Inc, Cary, NC
Shen H, Zhu Z (2008) Efficient mean estimation in log-normal linear models. Journal of Statistical Planning and Inference 138:552–567
Sileshi GW (2014) A critical review of forest biomass estimation models, common mistakes and corrective measures. For Ecol Manag 329:237–254
Slik JWF (2006) Estimating species-specific wood density from the genus average in Indonesian trees. J Trop Ecol 22:481–482. doi:10.1017/s0266467406003324
Slik JWF (2009 onwards) Plants of Southeast Asia. http://www.asianplant.net (accessed 1 May 2016)
Slik JWF, Beek VM, Breman FC, Bernard CS, Eichhorn KAO (2008) Tree diversity, composition, forest structure and aboveground biomass dynamics after single and repeated fire in a Bornean rain forest. Oecologia 158:579–588. doi:10.1007/s00442-008-1163-2
Slik J, Aiba SI, Brearley FQ, Cannon CH, Forshed O, Kitayama K, Nagamasu H, Nilus R, Payne J, Paoli G (2010) Environmental correlates of tree biomass, basal area, wood specific gravity and stem density gradients in Borneo's tropical forests. Glob Ecol Biogeogr 19:50–60
Snowdon P (1991) A ratio estimator for bias correction in logarithmic regressions. Can J For Res 21:720–724
The Plant List (2013) The Plant List Version 1.1. http://www.theplantlist.org (accessed 1 May 2016)
Van Welzen PC, Parnell JAN, Slik JWF (2011) Wallace’s line and plant distributions: two or three phytogeographical areas and where to group Java? Biol J Linn Soc 103:531–545. doi:10.1111/j.1095-8312.2011.01647.x
Vieilledent G, Vaudry R, Andriamanohisoa SFD, Rakotonarivo OS, Randrianasolo HZ, Razafindrabe HN, Rakotoarivony CB, Ebeling J, Rasamoelina M (2012) A universal approach to estimate biomass and carbon stock in tropical forests using generic allometric models. Ecol Appl 22:572–583. doi:10.1890/11-0039.1
Whitten T (1987) The ecology of Sumatra. Gadjah Mada University Press, Yogyakarta
Williamson GB, Wiemann MC (2010) Measuring wood specific gravity… correctly. Am J Bot 97:519–524
Acknowledgements
The authors would like to acknowledge the support from GIZ Forclime, KfW Forclime, PT Intracawood Industry, PT Inhutani I and PT Karya Rekanan Bina Bersama during field-data collection. We would like to thank Giono, Tokarena, Indra Kumara and Erik Somala for assistance with felling permits and logistical arrangements. We are indebted to numerous workers who contributed during the difficult fieldwork. We thank Julie Watson and Ding Li Yong for their critical reading of the previous manuscript, Elite Editing for proof reading of the draft manuscript and the three anonymous reviewers for their insightful comments and suggestions to improve the manuscript. We also thank Clive Hilliker for the support in graphic editing. Solichin Manuri gratefully acknowledges the support of Australia Award Scholarship from 2013 to 2017.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
We are grateful to GIZ and KFW Forclime for supporting field-data collection. The support of the Australia Award Scholarship is gratefully acknowledged.
Additional information
Handling Editor: Gilbert Aussenac
Contribution of the co-authors
SM, CB, TR and FN formulated the idea and developed methodology. SM, TR, FN, SIM, WCA, HK, DWS, GAK, AB, RSA, CAS, O, ES and DY collected data. SM performed statistical analyses and wrote the manuscript. TR, FN, LV, SIM, WCA, HK, DWS, GAK, AB, RSA, CAS, O, DY and ES revised the manuscript.
Electronic supplementary material
ESM 1
(DOCX 253 kb)
Rights and permissions
About this article

Cite this article
Manuri, S., Brack, C., Rusolono, T. et al. Effect of species grouping and site variables on aboveground biomass models for lowland tropical forests of the Indo-Malay region. Annals of Forest Science 74, 23 (2017). https://doi.org/10.1007/s13595-017-0618-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13595-017-0618-1