
Abstract
Current control systems regulate the behavior of dynamic systems by reacting to noise and unexpected disturbances as they occur. To improve the performance of such control systems, experience from iterative executions can be used to anticipate recurring disturbances and proactively compensate for them. This paper presents an algorithm that exploits data from previous repetitions in order to learn to precisely follow a predefined trajectory. We adapt the feed-forward input signal to the system with the goal of achieving high tracking performance—even under the presence of model errors and other recurring disturbances. The approach is based on a dynamics model that captures the essential features of the system and that explicitly takes system input and state constraints into account. We combine traditional optimal filtering methods with state-of-the-art optimization techniques in order to obtain an effective and computationally efficient learning strategy that updates the feed-forward input signal according to a customizable learning objective. It is possible to define a termination condition that stops an execution early if the deviation from the nominal trajectory exceeds a given bound. This allows for a safe learning that gradually extends the time horizon of the trajectory. We developed a framework for generating arbitrary flight trajectories and for applying the algorithm to highly maneuverable autonomous quadrotor vehicles in the ETH Flying Machine Arena testbed. Experimental results are discussed for selected trajectories and different learning algorithm parameters.























Similar content being viewed by others
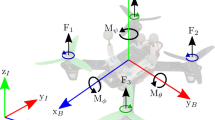

Notes
The accompanying video is found at http://tiny.cc/QuadroLearnsTrajectory.
The accompanying video is found at http://tiny.cc/QuadroLearnsTrajectory.
References
Ahn, H.-S., Moore, K. L., & Chen, Y. (2007). Communications and control engineering. Iterative learning control: robustness and monotonic convergence for interval systems (1st ed.). Berlin: Springer.
Al-Hiddabi, S. (2009). Quadrotor control using feedback linearization with dynamic extension. In Proceedings of the international symposium on mechatronics and its applications (ISMA) (pp. 1–3).
Alexis, K., Nikolakopoulos, G., & Tzes, A. (2010). Constrained-control of a quadrotor helicopter for trajectory tracking under wind-gust disturbances. In Proceedings of the IEEE Mediterranean electrotechnical conference (MELECON) (pp. 1411–1416).
Amann, N., Owens, D. H., & Rogers, E. (1996). Iterative learning control using optimal feedback and feedforward actions. International Journal of Control, 65(2), 277–293.
Anderson, B. D. O., & Moore, J. B. (2005). Dover books on engineering. Optimal filtering. New York: Dover.
Arimoto, S., Kawamura, S., & Miyazaki, F. (1984). Bettering operation of robots by learning. Journal of Robotic Systems, 1(2), 123–140.
Bamieh, B., Pearson, J. B., Francis, B. A., & Tannenbaum, A. (1991). A lifting technique for linear periodic systems with applications to sampled-data control. Systems & Control Letters, 17(2), 79–88.
Barton, K., Mishra, S., & Xargay, E. (2011). Robust iterative learning control: L1 adaptive feedback control in an ILC framework. In Proceedings of the American control conference (ACC) (pp. 3663–3668).
Bauer, P., Kulcsar, B., & Bokor, J. (2009). Discrete time minimax tracking control with state and disturbance estimation ii: Time-varying reference and disturbance signals. In Proceedings of the Mediterranean conference on control and automation (MED) (pp. 486–491).
Boost—Basic Linear Algebra Library (2012). Last accessed at 08 Feb 2012. [Online]. Available: http://www.boost.org/doc/libs/1_46_1/libs/numeric/ublas/doc/index.htm.
Bouabdallah, S., & Siegwart, R. (2005). Backstepping and sliding-mode techniques applied to an indoor micro quadrotor. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (pp. 2247–2252).
Bouktir, Y., Haddad, M., & Chettibi, T. (2008). Trajectory planning for a quadrotor helicopter. In Proceedings of the Mediterranean conference on control and automation (pp. 1258–1263).
Boyd, S., & Vandenberghe, L. (2004). Convex optimization. Cambridge: Cambridge University Press.
Bristow, D. A., Tharayil, M., & Alleyne, A. G. (2006). A survey of iterative learning control. IEEE Control Systems Magazine, 26(3), 96–114.
Castillo, C. L., Moreno, W., & Valavanis, K. P. (2007). Unmanned helicopter waypoint trajectory tracking using model predictive control. In Proceedings of the Mediterranean conference on control automation (pp. 1–8).
Chen, Y., & Wen, C. (1999). Lecture notes in control and information sciences. Iterative learning control: convergence, robustness and applications (1st ed.). Berlin: Springer.
Chin, I., Qin, S. J., Lee, K. S., & Cho, M. (2004). A two-stage iterative learning control technique combined with real-time feedback for independent disturbance rejection. Automatica, 40(11), 1913–1922.
Cho, M., Lee, Y., Joo, S., & Lee, K. S. (2005). Semi-empirical model-based multivariable iterative learning control of an RTP system. IEEE Transactions on Semiconductor Manufacturing, 18(3), 430–439.
Chui, C. K., & Chen, G. (1998). Springer series in information sciences. Kalman filtering: with real-time applications. Berlin: Springer.
Cowling, I., Yakimenko, O., Whidborne, J., & Cooke, A. (2007). A prototype of an autonomous controller for a quadrotor UAV. In Proceedings of the European control conference (ECC) (pp. 1–8).
Curve Fitting Toolbox Splines and MATLAB Splines (2012). Last accessed 08 Feb 2012. [Online]. Available: http://www.mathworks.com/help/toolbox/curvefit/f2-10452.html.
Diao, C., Xian, B., Yin, Q., Zeng, W., Li, H., & Yang, Y. (2011). A nonlinear adaptive control approach for quadrotor UAVs. In Proceedings of the Asian control conference (ASCC) (pp. 223–228).
Dierks, T., & Jagannathan, S. (2010). Output feedback control of a quadrotor UAV using neural networks. IEEE Transactions on Neural Networks, 21(1), 50–66.
Gurdan, D., Stumpf, J., Achtelik, M., Doth, K.-M., Hirzinger, G., & Rus, D. (2007). Energy-efficient autonomous four-rotor flying robot controlled at 1 kHz. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (pp. 361–366).
Hoffmann, G., Waslander, S., & Tomlin, C. (2008). Quadrotor helicopter trajectory tracking control. In Proceedings of the AIAA guidance, navigation and control conference and exhibit, Honolulu, Hawaii.
How, J. P., Bethke, B., Frank, A., Dale, D., & Vian, J. (2008). Real-time indoor autonomous vehicle test environment. IEEE Control Systems Magazine, 28(2), 51–64.
Huang, H., Hoffmann, G., Waslander, S., & Tomlin, C. (2009). Aerodynamics and control of autonomous quadrotor helicopters in aggressive maneuvering. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (pp. 3277–3282).
IBM ILOG CPLEX Optimizer (2012). Last accessed 08 Feb 2012. [Online]. Available: http://www-01.ibm.com/software/integration/optimization/cplex-optimizer/.
Lee, K. S., Lee, J., Chin, I., Choi, J., & Lee, J. H. (2001). Control of wafer temperature uniformity in rapid thermal processing using an optimal iterative learning control technique. Industrial & Engineering Chemistry Research, 40(7), 1661–1672.
Lee, D., Burg, T., Dawson, D., Shu, D., Xian, B., & Tatlicioglu, E. (2009). Robust tracking control of an underactuated quadrotor aerial-robot based on a parametric uncertain model. In Proceedings of the IEEE international conference on systems, man and cybernetics (SMC) (pp. 3187–3192).
Lin, S.-H., & Lian, F.-L. (2005). Study of feasible trajectory generation algorithms for control of planar mobile robots. In Proceedings of the IEEE international conference on robotics and biomimetics (ROBIO) (pp. 121–126).
Longman, R. W. (2000). Iterative learning control and repetitive control for engineering practice. International Journal of Control, 73(10), 930–954.
Lupashin, S., & D’Andrea, R. (2011). Adaptive open-loop aerobatic maneuvers for quadrocopters. In Proceedings of the IFAC World congress (Vol. 18(1), pp. 2600–2606).
Lupashin, S., Schoellig, A.P., Sherback, M., & D’Andrea, R. (2010). A simple learning strategy for high-speed quadrocopter multi-flips. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (pp. 1642–1648).
Madani, T., & Benallegue, A. (2006). Backstepping control for a quadrotor helicopter. In Proceedings of the IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 3255–3260).
Mellinger, D., Michael, N., & Kumar, V. (2010). Trajectory generation and control for precise aggressive maneuvers with quadrotors. In Proceedings of the international symposium on experimental robotics.
Michael, N., Mellinger, D., Lindsey, Q., & Kumar, V. (2010). The GRASP multiple micro UAV testbed. IEEE Robotics & Automation Magazine, 17(3), 56–65.
Mokhtari, A., & Benallegue, A. (2004). Dynamic feedback controller of Euler angles and wind parameters estimation for a quadrotor unmanned aerial vehicle. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (Vol. 3, pp. 2359–2366).
Moore, K. L. (1998). Multi-loop control approach to designing iterative learning controllers. In Proceedings of the IEEE conference on decision and control (CDC) (Vol. 1, pp. 666–671).
Nicol, C., Macnab, C. J. B., & Ramirez-Serrano, A. (2011). Robust adaptive control of a quadrotor helicopter. Mechatronics, 21(6), 927–938.
Norrloef, M., & Gunnarsson, S. (2002). Time and frequency domain convergence properties in iterative learning control. International Journal of Control, 75(14), 1114–1126.
Phan, M. Q., & Longman, R. W. (1988). A mathematical theory of learning control for linear discrete multivariable systems. In Proceedings of the AIAA/AAS astrodynamics conference (pp. 740–746).
Piazzi, A., & Guarino Lo Bianco, C. (2000). Quintic G 2-splines for trajectory planning of autonomous vehicles. In Proceedings of the IEEE intelligent vehicles symposium (pp. 198–203).
Pounds, P., Mahony, R., & Corke, P. (2006). Modelling and control of a quad-rotor robot. In Proceedings of the Australasian conference on robotics and automation.
Purwin, O., & D’Andrea, R. (2009). Performing aggressive maneuvers using iterative learning control. In Proceedings of the IEEE international conference on robotics and automation (ICRA) (pp. 1731–1736).
Raffo, G., Ortega, M., & Rubio, F. (2008). Backstepping/nonlinear H ∞ control for path tracking of a quadrotor unmanned aerial vehicle. In Proceedings of the American control conference (ACC) (pp. 3356–3361).
Rice, J. K., & Verhaegen, M. (2010). A structured matrix approach to efficient calculation of LQG repetitive learning controllers in the lifted setting. International Journal of Control, 83(6), 1265–1276.
Ritz, R., Hehn, M., Lupashin, S., & D’Andrea, R. (2011). Quadrotor performance benchmarking using optimal control. In Proceedings of the IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 5179–5186).
Schoellig, A. P., & D’Andrea, R. (2009). Optimization-based iterative learning control for trajectory tracking. In Proceedings of the European control conference (ECC) (pp. 1505–1510).
The Mathworks Optimization Toolbox (2012). Last accessed 08 Feb 2012. [Online]. Available: http://www.mathworks.com/help/toolbox/optim/ug/fmincon.html.
Tousain, R., van der Meche, E., & Bosgra, O. (2001). Design strategy for iterative learning control based on optimal control. In Proceedings of the IEEE conference on decision and control (CDC) (Vol. 5, pp. 4463–4468).
Waslander, S. L., Hoffmann, G. M., Jang, J. S., & Tomlin, C. (2005). Multi-agent quadrotor testbed control design: integral sliding mode vs. reinforcement learning. In Proceedings of the IEEE/RSJ international conference on intelligent robots and systems (IROS), August 2005 (pp. 3712–3717).
Zhang, C., Wang, N., & Chen, J. (2010). Trajectory generation for aircraft based on differential flatness and spline theory. In Proceedings of the international conference on information networking and automation (ICINA) (Vol. 1, pp. V1-110–V1-114).
Zhou, Q.-L., Zhang, Y., Qu, Y.-H., & Rabbath, C.-A. (2010a). Dead reckoning and Kalman filter design for trajectory tracking of a quadrotor UAV. In Proceedings of the IEEE/ASME international conference on mechatronics and embedded systems and applications (MESA) (pp. 119–124).
Zhou, Q.-L., Zhang, Y., Rabbath, C.-A., & Theilliol, D. (2010b). Design of feedback linearization control and reconfigurable control allocation with application to a quadrotor UAV. In Proceedings of the conference on fault-tolerant systems (SysTol) (pp. 371–376).
Zhu, B., & Huo, W. (2010). Trajectory linearization control for a quadrotor helicopter. In Proceedings of the IEEE international conference on control and automation (ICCA) (pp. 34–39).
Zuo, Z. (2010). Trajectory tracking control design with command-filtered compensation for a quadrotor. IET Control Theory & Applications, 4(11), 2343–2355.
Acknowledgements
This research was funded in part by the Swiss National Science Foundation (SNSF). The authors thank the anonymous reviewers for their thoughtful comments.
Author information
Authors and Affiliations
Corresponding author
Electronic Supplementary Material
Below is the link to the electronic supplementary material.
(WMV 43.5 MB)
Appendix: Input update as convex optimization problem
Appendix: Input update as convex optimization problem
The update law defined in (28) can be transformed into a convex optimization problem of the form:
where z represents the vector of decision variables and V is a symmetric positive semi-definite matrix. The number of constraints is defined by the length of w. We call (64) a ‘linear program’ if V is zero and a ‘quadratic program’ otherwise, cf. Boyd and Vandenberghe (2004).
For simplicity, we consider α=0 in the following derivations. However, similar arguments can be made for arbitrary α>0. In case of norms ∥⋅∥ ℓ ,ℓ∈{1,∞}, which are inherently nonlinear, non-quadratic functions, (28) is re-formulated by extending the original vector of decision variables u j+1 and adding additional inequality constraints. Thus, in case of the 1-norm, the objective function in (28) is replaced by
where \(e\in \mathbb {R}^{Nn_{\textup {\MakeLowercase {\MakeLowercase {x}}}}}\) and \(\mathbb{I}\) represent a vector of ones, \(\mathbb{I}=[1, 1, 1, \ldots]^{T}\in \mathbb {R}^{Nn_{\textup {\MakeLowercase {\MakeLowercase {x}}}}}\). Similarly, for the maximum norm, the extended equation reads as
with e∈ℝ. In both cases, the constraints in (28) must still be satisfied. The 2-norm results in the following objective function:
Rights and permissions
About this article
Cite this article
Schoellig, A.P., Mueller, F.L. & D’Andrea, R. Optimization-based iterative learning for precise quadrocopter trajectory tracking. Auton Robot 33, 103–127 (2012). https://doi.org/10.1007/s10514-012-9283-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10514-012-9283-2