
Abstract
Frequently finding a visual search target in one region of space induces a spatial attentional bias toward that region. Past studies on this effect typically tested fewer than 20 participants. The small sample prevents an investigation of two properties of learning: visual field uniformity and role of explicit awareness. Pooling data from multiple studies, here we examined location probability learning from ~120,000 visual search trials across 420 participants. Participants performed a serial search task. Unbeknownst to them, the target was disproportionately likely to appear in one visual quadrant. Location probability learning (LPL) was measured as the difference in reaction time to targets in the high-probability “rich” quadrant and the low-probability “sparse” quadrants. Results showed a lack of visual field effect. LPL was equivalent for “rich” quadrant in the upper left, upper right, lower left, and lower right. Learning did not induce a hotspot diagonal to the “rich” quadrant. To the contrary, RT was the longest in the diagonal quadrant. Recognition rate of the “rich” quadrant was above chance. However, recognition accuracy was unrelated to the size of LPL. Implicit learning induces visual-field-independent changes in spatial attention.
Similar content being viewed by others
Introduction
In daily tasks, such as driving, people prioritize important visual locations. Consistent spatial distribution of important stimuli allows for learning of the probable locations of those stimuli. When the target appears in one visuospatial region disproportionately often, search reaction time (RT) is faster in that high-probability region than elsewhere (Jiang, 2018; Miller, 1988). Location probability learning (LPL) often reduces RT by 10–20%. It alleviates hemifield neglect and aids search in people with an Autism Spectrum Disorder or Parkinson’s Disease (Geng & Behrmann, 2002; Jiang, Capistrano, Esler, & Swallow, 2013; Sisk, Twedell, Koutstaal, Cooper, & Jiang, 2018). Because the target frequently appears in one region of space across all trials, LPL induces a general spatial preference. This differs from contextual cueing (Chun & Jiang, 1998), in which distinct spatial contexts are associated with different target locations.
Owing to its large effect size, studies of LPL have typically employed fewer than 20 participants. This sample size is inadequate for answering two questions: Is LPL uniform across the visual field? Is learning implicit? Addressing these questions entails comparison across participants and necessitates a large sample. We combined data across ~400 participants to examine the interaction of LPL with visual fields and its implicit/explicit nature.
Several types of visual field effects manifest in spatial attention. First, anisotropy across the visual field occurs in phenomena such as crowding, in which surrounding distractors reduce discriminability of a target. Crowding is more severe in the upper than the lower visual field (He, Cavanagh, & Intriligator, 1996), and the spatial resolution of attention is superior in the lower visual field (Intriligator & Cavanagh, 2001). Reading habits may also foster anisotropy (Rinaldi, Di Luca, Henik, & Girelli, 2014), resulting in an upper-left bias – a recent conference report uncovered higher change-detection accuracy in the upper-left than in other quadrants (Quirk, Adam, & Vogel, 2018). Second, attention behaves differently across bilateral compared to unilateral locations. In multiple object tracking, it is easier to track targets distributed across, rather than within, a hemifield, displaying a bilateral advantage (Alvarez & Cavanagh, 2005). Unilateral advantages manifest as easier detection of repeated stimuli when repetitions occur within, rather than across, hemifields (Butcher & Cavanagh, 2008). Third, the spread of attention is non-linear. Sometimes, locations near the target are enhanced, while farther locations are suppressed (Müller & Kleinschmidt, 2004). Other times, peripheral cues enhance processing of a spot in the quadrant diagonal to the target’s location (Tse, Sheinberg, & Logothetis, 2003).
The studies reviewed above tap into goal-driven or exogenous attention. We aim to determine whether implicitly-learned attention also exhibits visual field non-uniformity. As noted, LPL occurs rapidly, induces a large RT gain, and is unimpaired by working memory load. Its preservation in neglect patients suggests independence from the frontoparietal network. One theory of LPL characterizes it as a search habit (Jiang, 2018) – a habit of shifting attention in the direction of the high-probability locations. The habit, instantiated either overtly (by shaping saccadic directions) or covertly (by reinforcing a direction of attentional movement), is more akin to action than perception. As such, LPL may not exhibit visual field effects arising from inhomogeneity of receptive field properties of visual neurons. Alternatively, because LPL involves learning of statistical regularities, it may be sensitive to pre-existing spatial biases, such as reading direction.
We also aim to evaluate the role of explicit awareness in LPL. Although previous studies have demonstrated implicit guidance of attention, researchers have challenged the strength (Kunar, Flusberg, Horowitz, & Wolfe, 2007) and implicit nature (Colagiuri & Livesey, 2016; Smyth & Shanks, 2008; Vadillo, Konstantinidis, & Shanks, 2016) of that guidance. Participants classified as “aware” or “unaware” in individual experiments often number fewer than 10. Because many participants have been trained under similar conditions in our lab, we were able to analyze data from several hundred participants. This provides a powerful test of the role of explicit awareness in LPL.
Method
Study selection
We examined data obtained over the last 7 years. We tried to maximize sample size while preserving study consistency. Included studies exhibited the following characteristics.
Search task
In all but one study, participants searched for a letter T among letter Ls. In the remaining study, they searched for the number 2 among 5s. The 2-among-5 task yielded similar RT and search slope as the T-among-L task (Jiang, Swallow, Won, Cistera, & Rosenbaum, 2015).
Set size
Set size was 12 in most experiments. Some studies had an equal distribution of set sizes 8, 12, and 16. These studies were included because 12 was the average set size and LPL at set size 12 was similar to the average of LPL at set sizes 8 and 16.
Training length
The studies varied in training length. Only the first 288 trials were analyzed – the shortest existing study length.
Other inclusion criteria
In all studies, (1) training was conducted under incidental learning conditions; (2) participants were healthy young adults; (3) viewpoint did not vary; (4) participants had unlimited search time; (5) the target was present on all trials; and (6) participants were tested without a working memory load. Most studies were previously published (Jiang, Koutstaal, & Twedell, 2016; Jiang, Swallow, & Sun, 2014; Jiang & Swallow, 2013b, 2013a; Jiang, Swallow, & Rosenbaum, 2013; Jiang, Swallow, Rosenbaum, & Herzig, 2013; Jiang, Swallow, et al., 2015; Twedell, Koutstaal, & Jiang, 2016).
Participants
Data from 420 participants were included (273 females). Participants were college students (18–35 years; mean age 20.2 years) naïve to the purpose of the experiments. All had normal color vision and normal or corrected-to-normal visual acuity.
Procedure
On each trial, participants first maintained central fixation. The search array appeared and remained until participants responded. Participants had to find the target and press a button to report its orientation or color. A tone provided accuracy feedback.
Study design
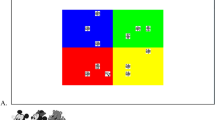
The target appeared in one quadrant on 50% of trials, and in each of the other three quadrants on 16.7% of trials. The high-probability quadrant was counterbalanced across participants (Fig. 1).

Left: A sample search display. Right: An illustration of the location probability manipulation, assuming the high-probability, “rich” quadrant is in the upper left. The three sparse quadrants are in the same or different hemifield, or diagonal to the rich quadrant
Explicit recognition
Upon task completion, participants were asked whether they thought the target appeared in some locations disproportionately often. Next, participants were informed that the target more often appeared in one quadrant and were asked to choose that quadrant. This procedure was administered to 336 participants. The remaining participants were excluded because in their study, recognition test was absent, it was performed using a different procedure, or it was conducted after a 1-week delay.
Data analysis
To adjust for RT differences across experiments, each participant’s average RT within a block was z-score transformed relative to that participant’s grand mean and standard deviation (Faust, Balota, Spieler, & Ferraro, 1999). Given the large sample, spurious significant effects could occur. We therefore reported effect size. In ANOVA, Cohen’s f2 of 0.02, 0.15, and 0.35 correspond to small, medium, and large effects. In t-tests, Cohen’s d of 0.2, 0.5, and 0.8 correspond to small, medium, and large effects.
Results
Anisotropy
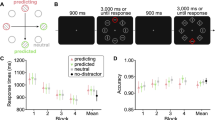
We first examined whether LPL differed across different high-probability, henceforth referred to as “rich,” quadrants. Data were binned into 12 blocks of 24 trials each (Fig. 2). We conducted an ANOVA on z-transformed RT using target’s location (low- vs. high-probability quadrant) and block (1–12) as within-subject factors, and training group (“rich” quadrant in upper left, upper right, lower left, or lower right) as a between-subject factor. We observed location probability learning, as demonstrated by a main effect of the target’s location, F(1, 416) = 1172.23, p < .001, Cohen’s f2 = 2.82, as well as general practice effects, shown by the main effect of block, F(11, 4576) = 114.28, p < .001, Cohen’s f2 = 0.28. Learning was gradual, as the interaction between target’s location and block was significant, F(11, 4576) = 10.81, p < .001, Cohen’s f2 = 0.027, with a strong linear trend, F(1, 416) = 92.14, p < .001, Cohen’s f2 = 0.22. Visual field effects were negligible: the effect size for the interaction between training group and the target’s location was Cohen’s f2 = 0.018, F(3, 416) = 2.51, p > .05, and the effect size for the three-way interaction was Cohen’s f2 = 0.004, F < 1. LPL in z-scores was 0.92, 0.78, 0.97, and 0.91 when the “rich” quadrant was in the upper left, upper right, lower left, and lower right, respectively.

Data for participants trained in different high-probability, “rich” quadrants. Error bars show ±1 S.E. of the difference between “rich” and “sparse” quadrants
Visual field relationship and spread of attention
Next, we examined the spread of attention within and across visual fields. We classified the three low-probability quadrants as: (1) “sparse-diagonal” – diagonal to the “rich” quadrant; (2) “sparse-same-HF” – adjacent to, and in the same hemifield as, the “rich” quadrant; and (3) “sparse-diff-HF” – adjacent to, but in the hemifield opposite the “rich” quadrant. This analysis was conducted across all participants. Because the target appeared in the “rich” quadrant on half of the trials in a block, and because the other half of trials were now divided into three sparse conditions, each sparse condition constituted a very small number of trials per block. We therefore binned the data into larger trial blocks: eight 36-trial blocks (Fig. 3).

Spread of attention from the “rich” quadrant to the other quadrants. Error bars show ±1 S.E. of the mean of each condition
If the two hemispheres have separate attentional resources (Cavanagh & Alvarez, 2005), there may be greater spread of attention from the “rich” quadrant to a sparse quadrant in the same, rather than a different, hemifield. However, we found that there was no difference in performance between the two sparse quadrants that flank the rich quadrant, one in the same and one in the opposite hemifield. An ANOVA on hemifield (sparse-same-HF vs. sparse-diff-HF) and block showed no effect of hemifield, F < 1, Cohen’s f2 = 0.002. Furthermore, LPL did not induce a hotspot in the diagonal quadrant. A comparison between the sparse-diagonal and the two sparse-adjacent quadrants showed significantly slower RT in the sparse-diagonal than in the adjacent quadrants, F(1, 419) = 133.68, p < .001, Cohen’s f2 = 0.32 for diagonal versus same-HF, F(1, 419) = 146.35, p < .001, Cohen’s f2 = 0.25 for diagonal versus diff-HF. Rather, the RT slowing in the sparse-diagonal quadrant (diagonal minus “rich” RT: 25.1% RT difference, z-score difference = 0.99) was about 1.4 times that calculated from adjacent quadrants (adjacent minus “rich” RT: 17.8% RT difference, z-score difference = 0.69). This is a remarkable coincidence considering that locations in the diagonal quadrant are about 1.4 times farther than locations in the adjacent quadrants.
Explicit awareness
The 336 participants fell into four groups depending on response accuracy on the recognition questions. At one extreme, 117 (34.8%) participants failed both questions (“unaware” group). They reported even target distribution and selected a low-probability quadrant as “rich.” At the other extreme, 70 (20.8%) participants passed both questions (“aware” group). They reported biased target distribution and correctly identified the “rich” quadrant. The remaining participants failed one recognition question: 72 (21.4%) reported even target distribution but correctly guessed the “rich” quadrant (“partially aware 1”); 77 (22.9%) reported biased target distribution but chose the wrong quadrant (“partially aware 2”).
Recognition rate for question 2 (42.2%) was higher than expected by chance, χ2(1) = 53.40, p < .001. But does this mean that explicit knowledge guided search? If so, LPL should be larger in those with higher awareness.
Figure 4 shows search data for the four awareness groups. We observed typical LPL effects, and these effects did not differ across awareness groups. We performed an ANOVA on z-transformed RT, using answers to recognition question 1 (evenly or unevenly distributed) and question 2 (correct or incorrect quadrant identification) as between-subject factors, and target’s location (high- vs. low-probability quadrant) and block as within-subject factors. Results showed main effects of the target’s location, F(1, 332) = 932.86, p < .001, Cohen’s f2 = 2.82, and block, F(11, 3652) = 89.57, p < .001, Cohen’s f2 = 0.27, and their interaction, F(11, 3652) = 10.40, p < .001, Cohen’s f2 = 0.03. Target’s location did not interact with response to either recognition question, Fs < 1, Cohen’s f2 = 0. None of the higher-order interactions was significant, smallest p = 0.12, largest Cohen’s f2 = 0.007.

Role of awareness in modulating LPL. Participants were divided into four groups depending on their accuracy in the recognition tests. Error bars show ±1 S.E. of the difference between high- and low- probability quadrants
Consider the two extreme groups: LPL led to an RT saving of 19.2% (z-score gain of 0.85) in “unaware” participants, which was comparable to the RT saving of 20.5% (z-score gain of 0.88) in “aware” participants, t(185) = 0.42, p = .673, Cohen’s d = 0.06.
Because awareness may emerge gradually, we also analyzed data from the last four blocks, when the level of awareness further diverged between aware and unaware participants. Still, awareness did not affect LPL. RT saving was comparable between the aware group (25.3%) and the unaware group (24.3%), p = .714.
Discussion
This study reports location probability learning across several hundred participants. Results demonstrate uniformity of LPL across the visual field. Although participants may habitually scan the display from left to right and top to bottom, this did not affect LPL. RT was not faster and LPL was not different in the upper-left quadrant, compared to the other quadrants. This contrasts a recent report of upper-left biases in change detection (Quirk et al., 2018). Task differences likely explain this disparity. Change detection tasks present the encoding display briefly, encouraging global processing. Reduced serial scanning opportunity may limit search habit formation. Location probability manipulations in change detection may instead impact strategies for memory-based comparison between the encoded display and the test display. Pre-existing biases, such as upper-left biases, may influence this comparison. This is speculative, but regardless, the spatial uniformity of LPL in visual search suggests that it is unconstrained by reading habits or neuronal receptive field properties.
Additionally, spatial attention spread evenly from the trained quadrant to unilateral and bilateral locations. LPL also did not induce an attentional hotspot in the diagonal quadrant – such hotspots were observed in peripheral cueing studies and variably attributed to inhibition of return for the cued location or attentional momentum from shifting attention from the cued location to the center (Tse et al., 2003). In our study, the diagonal quadrant had the slowest RT. Thus, in LPL, attention spreads gradually from trained to neighboring locations.
Analysis of several hundred participants shows that LPL often results in explicit knowledge of target’s location probability. The percentage of participants correctly identifying the high-probability quadrant exceeded chance. Nonetheless, participants did not intentionally use this information to prioritize the high-probability quadrant. If they had, LPL should have increased across participants as level of explicit awareness increased. Previous studies showed that the RT advantage in the “rich” quadrant was doubled under intentional learning conditions, compared to incidental LPL (Jiang, Sha, & Remington, 2015; Won & Jiang, 2015). In contrast, we found no increase in LPL in participants with greater awareness.
The co-existence of above-chance recognition and lack of modulation by awareness is reminiscent of a distinction Buchner and Wippich (1998) made between implicit learning and implicit memory. Implicit learning can produce explicit knowledge, and explicitly-learned information might sometimes only be accessible through implicit measures. LPL presents an example of implicit learning yielding explicit knowledge. It produces consciously accessible information about where the target most often occurred. Yet learning itself is not under deliberate control. Participants may be able to access the information when queried, but do not spontaneously realize this during search.
Although LPL is largely implicit, this does not imply that explicit awareness cannot modulate LPL. LPL is larger under intentional than incidental learning conditions (Jiang, Sha, et al., 2015; Jiang et al., 2014; Won & Jiang, 2015). Thus, with prolonged training, explicit guidance might eventually occur. Nonetheless, under incidental learning conditions, implicit learning is an important component of LPL. Claims to the contrary, such as those that equate LPL with goal-driven attention, are problematic. These claims cannot explain the lack of an effect of awareness across the 336 participants examined here. They also cannot explain dissociations between LPL and goal-driven attention: LPL is insensitive to working memory load, cognitive aging, and brain damage, factors that interfere with goal-driven attention.
The combination of data across multiple studies may raise validity questions. The similarity of tasks and identical statistical manipulations across these studies alleviate this concern. The assignment of high-probability quadrants was counterbalanced within each study, so no quadrant was disproportionately represented in the analysis. Studies with extended training might yield greater awareness, yet increases in awareness likely only influence later performance. Our analysis was restricted to the first 288 trials, in which LPL largely reflected implicit learning.
Alternative approaches exist. But accessibility of raw data makes our study superior to meta-analytical approaches because we directly addressed questions of homogeneity across studies. And though in ideal situations, a 400-person LPL study would be more desirable than pooling data across (similar) experiments, time and resource constraints render this unfeasible. The current approach presents a balance between large sample size and conservation of resources.
Conclusion
An evaluation of data from 420 participants shows that implicitly-learned attention is uniform across the visual field. Unlike crowding, LPL is not greater in the lower than the upper visual field. Unlike change detection, LPL in visual search is not influenced by pre-existing biases toward the upper left. The spread of attention from the trained location is graded, declining with increasing distance from the trained location. Although more participants than expected by chance can correctly identify the “rich” locations, awareness did not increase LPL. Implicit location probability learning induces a visual-field-independent change in spatial attention.
References
Alvarez, G. A., & Cavanagh, P. (2005). Independent resources for attentional tracking in the left and right visual hemifields. Psychological Science, 16(8), 637–643. https://doi.org/10.1111/j.1467-9280.2005.01587.x
Buchner, A., & Wippich, W. (1998). Differences and commonalities between implicit learning and implicit memory. In Handbook of implicit learning (pp. 3–46). Thousand Oaks, CA, US: Sage Publications, Inc.
Butcher, S. J., & Cavanagh, P. (2008). A unilateral field advantage for detecting repeated elements. Perception & Psychophysics, 70(4), 714–724.
Cavanagh, P., & Alvarez, G. A. (2005). Tracking multiple targets with multifocal attention. Trends in Cognitive Sciences, 9(7), 349–354. https://doi.org/10.1016/j.tics.2005.05.009
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36(1), 28–71. https://doi.org/10.1006/cogp.1998.0681
Colagiuri, B., & Livesey, E. J. (2016). Contextual cuing as a form of nonconscious learning: Theoretical and empirical analysis in large and very large samples. Psychonomic Bulletin & Review, 23(6), 1996–2009. https://doi.org/10.3758/s13423-016-1063-0
Faust, M. E., Balota, D. A., Spieler, D. H., & Ferraro, F. R. (1999). Individual differences in information-processing rate and amount: Implications for group differences in response latency. Psychological Bulletin, 125(6), 777–799.
Geng, J. J., & Behrmann, M. (2002). Probability cuing of target location facilitates visual search implicitly in normal participants and patients with hemispatial neglect. Psychological Science, 13(6), 520–525.
He, S., Cavanagh, P., & Intriligator, J. (1996). Attentional resolution and the locus of visual awareness. Nature, 383(6598), 334–337. https://doi.org/10.1038/383334a0
Intriligator, J., & Cavanagh, P. (2001). The spatial resolution of visual attention. Cognitive Psychology, 43(3), 171–216. https://doi.org/10.1006/cogp.2001.0755
Jiang, Y. V. (2018). Habitual versus goal-driven attention. Cortex; a Journal Devoted to the Study of the Nervous System and Behavior, 102, 107–120. https://doi.org/10.1016/j.cortex.2017.06.018
Jiang, Y. V., Capistrano, C. G., Esler, A. N., & Swallow, K. M. (2013). Directing attention based on incidental learning in children with autism spectrum disorder. Neuropsychology, 27(2), 161–169. https://doi.org/10.1037/a0031648
Jiang, Y. V., Koutstaal, W., & Twedell, E. L. (2016). Habitual attention in older and young adults. Psychology and Aging, 31(8), 970–980. https://doi.org/10.1037/pag0000139
Jiang, Y. V., Sha, L. Z., & Remington, R. W. (2015). Modulation of spatial attention by goals, statistical learning, and monetary reward. Attention, Perception & Psychophysics, 77(7), 2189–2206. https://doi.org/10.3758/s13414-015-0952-z
Jiang, Y. V., & Swallow, K. M. (2013a). Body and head tilt reveals multiple frames of reference for spatial attention. Journal of Vision, 13(13), 9. https://doi.org/10.1167/13.13.9
Jiang, Y. V., & Swallow, K. M. (2013b). Spatial reference frame of incidentally learned attention. Cognition, 126(3), 378–390. https://doi.org/10.1016/j.cognition.2012.10.011
Jiang, Y. V., Swallow, K. M., & Rosenbaum, G. M. (2013). Guidance of spatial attention by incidental learning and endogenous cuing. Journal of Experimental Psychology. Human Perception and Performance, 39(1), 285–297. https://doi.org/10.1037/a0028022
Jiang, Y. V., Swallow, K. M., Rosenbaum, G. M., & Herzig, C. (2013). Rapid acquisition but slow extinction of an attentional bias in space. Journal of Experimental Psychology. Human Perception and Performance, 39(1), 87–99. https://doi.org/10.1037/a0027611
Jiang, Y. V., Swallow, K. M., & Sun, L. (2014). Egocentric coding of space for incidentally learned attention: Effects of scene context and task instructions. Journal of Experimental Psychology. Learning, Memory, and Cognition, 40(1), 233–250. https://doi.org/10.1037/a0033870
Jiang, Y. V., Swallow, K. M., Won, B.-Y., Cistera, J. D., & Rosenbaum, G. M. (2015). Task specificity of attention training: The case of probability cuing. Attention, Perception & Psychophysics, 77(1), 50–66. https://doi.org/10.3758/s13414-014-0747-7
Kunar, M. A., Flusberg, S., Horowitz, T. S., & Wolfe, J. M. (2007). Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology. Human Perception and Performance, 33(4), 816–828. https://doi.org/10.1037/0096-1523.33.4.816
Miller, J. (1988). Components of the location probability effect in visual search tasks. Journal of Experimental Psychology. Human Perception and Performance, 14(3), 453–471.
Müller, N. G., & Kleinschmidt, A. (2004). The attentional “spotlight’s” penumbra: Center-surround modulation in striate cortex. Neuroreport, 15(6), 977–980.
Quirk, C., Adam, K., & Vogel, E. (2018). Preexisting spatial biases influence the encoding of information into visual working memory. Presented at the Vision Sciences Society, St. Pete, FL.
Rinaldi, L., Di Luca, S., Henik, A., & Girelli, L. (2014). Reading direction shifts visuospatial attention: An Interactive Account of attentional biases. Acta Psychologica, 151, 98–105. https://doi.org/10.1016/j.actpsy.2014.05.018
Sisk, C. A., Twedell, E. L., Koutstaal, W., Cooper, S. E., & Jiang, Y. V. (2018). Implicitly learned spatial attention is unimpaired in patients with Parkinson’s Disease. Neuropsychologia, 119, 34–44. https://doi.org/10.1016/j.neuropsychologia.2018.07.030
Smyth, A. C., & Shanks, D. R. (2008). Awareness in contextual cuing with extended and concurrent explicit tests. Memory & Cognition, 36(2), 403–415.
Tse, P. U., Sheinberg, D. L., & Logothetis, N. K. (2003). Attentional enhancement opposite a peripheral flash revealed using change blindness. Psychological Science, 14(2), 91–99. https://doi.org/10.1111/1467-9280.t01-1-01425
Twedell, E. L., Koutstaal, W., & Jiang, Y. V. (2016). Aging affects the balance between goal-guided and habitual spatial attention. Psychonomic Bulletin & Review. https://doi.org/10.3758/s13423-016-1214-3
Vadillo, M. A., Konstantinidis, E., & Shanks, D. R. (2016). Underpowered samples, false negatives, and unconscious learning. Psychonomic Bulletin & Review, 23(1), 87–102. https://doi.org/10.3758/s13423-015-0892-6
Won, B.-Y., & Jiang, Y. V. (2015). Spatial working memory interferes with explicit, but not probabilistic cuing of spatial attention. Journal of Experimental Psychology. Learning, Memory, and Cognition, 41(3), 787–806. https://doi.org/10.1037/xlm0000040
Author information
Authors and Affiliations
Corresponding author
Additional information
Significance
The modern world confronts our visual system with unique challenges. For example, people often have seconds to notice and react to road signs when driving. Learning where important signs are most likely to appear can be a matter of life and death. Is such learning uniform across the visual field? Is it implicit? Here, drawing data from 420 participants tested in the last 7 years in our lab, we showed that location probability learning is both uniform and implicit. The findings provide the most compelling evidence, to date, that implicit learning induces visual field-independent changes in spatial attention.
Rights and permissions
About this article

Cite this article
Jiang, Y.V., Sha, L.Z. & Sisk, C.A. Experience-guided attention: Uniform and implicit. Atten Percept Psychophys 80, 1647–1653 (2018). https://doi.org/10.3758/s13414-018-1585-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1585-9