
Abstract
Neutron-capture cross sections of neutron-rich nuclei are calculated using a Hauser–Feshbach model when direct experimental cross sections cannot be obtained. A number of codes to perform these calculations exist, and each makes different assumptions about the underlying nuclear physics. We investigated the systematic uncertainty associated with the choice of Hauser-Feshbach code used to calculate the neutron-capture cross section of a short-lived nucleus. The neutron-capture cross section for \(^{73}\hbox {Zn}\)(n,\(\gamma \))\(^{74}\hbox {Zn}\) was calculated using three Hauser-Feshbach statistical model codes: TALYS, CoH, and EMPIRE. The calculation was first performed without any changes to the default settings in each code. Then an experimentally obtained nuclear level density (NLD) and \(\gamma \)-ray strength function (\(\gamma \hbox {SF}\)) were included. Finally, the nuclear structure information was made consistent across the codes. The neutron-capture cross sections obtained from the three codes are in good agreement after including the experimentally obtained NLD and \(\gamma \hbox {SF}\), accounting for differences in the underlying nuclear reaction models, and enforcing consistent approximations for unknown nuclear data. It is possible to use consistent inputs and nuclear physics to reduce the differences in the calculated neutron-capture cross section from different Hauser-Feshbach codes. However, ensuring the treatment of the input of experimental data and other nuclear physics are similar across multiple codes requires a careful investigation. For this reason, more complete documentation of the inputs and physics chosen is important.
Similar content being viewed by others

1 Introduction
The astrophysical slow and rapid neutron-capture processes (s- and r-processes, respectively) are responsible for the majority of the abundance of the elements heavier than iron [1,2,3]. Both processes proceed through unstable nuclei and require knowledge of neutron-capture cross sections [4] that are not available by direct measurement techniques. This leads to a reliance on theoretical cross section values for short-lived isotopes. Theoretical calculations of the neutron-capture cross section can vary for stable nuclei [5], and the variation only gets larger further from stability [4, 6,7,8]. Statistical neutron capture can be described using a Hauser-Feshbach model [9] that requires an optical model potential (OMP) describing the interaction between the neutron and nucleus, as well as two important statistical properties of the compound nucleus: the nuclear level density (NLD) and \(\gamma \)-ray strength function (\(\gamma \hbox {SF}\)). The NLD describes the number of levels per unit energy in a nucleus, and increases exponentially with excitation energy. The \(\gamma \hbox {SF}\), which is related to the \(\gamma \)-ray transmission coefficient, describes the probability that a \(\gamma \)-ray of a given energy will be emitted from the nucleus. There are a number of models in use to describe the NLD and \(\gamma \hbox {SF}\) of nuclei [10], each with parameters that can be varied, which leads to many different ways to describe the shape and magnitude of both the NLD and \(\gamma \hbox {SF}\) for a given nucleus.
There are many Hauser-Feshbach statistical model codes available for calculating neutron-capture cross sections, including TALYS [10, 11], NON-SMOKER [12, 13], EMPIRE [14], CoH [15], SAPPHIRE [16], and CIGAR [5]. In each, a range of models for the NLD, \(\gamma \hbox {SF}\), and OMP are provided. A comparison of the neutron-capture cross sections calculated using four Hauser-Feshbach codes (TALYS, NON-SMOKER, CIGAR, and SAPPHIRE) on stable nuclei demonstrated that, as expected, variations in model parameters between the different codes result in variations in the neutron-capture cross sections [5]. Differences of a factor of 2–3 at 30 keV were found for nuclei at or near stability.
Investigating the discrepancy between Hauser-Feshbach codes becomes more complicated further from stability due to the potential for large uncertainties in the extrapolation of NLD and \(\gamma \hbox {SF}\) and the decreasing amount of experimentally known nuclear data. Even when nuclei are well studied, such as \(^{238}\hbox {U}\) and \(^{239}\hbox {Pu}\), it can be difficult to control for all possible differences between codes [17]. Despite the difficulties, the lack of directly measured neutron-capture cross sections off stability makes such an investigation important. Experimental efforts have focused on constraining the NLD and \(\gamma \hbox {SF}\), as they contribute the largest uncertainty to cross sections obtained from Hauser-Feshbach codes [18,19,20]. This can reduce the uncertainty in neutron-capture cross sections dramatically, even far from stability [7], but that reduction has so far only been achieved inside the framework of a single Hauser-Feshbach code.
Together this presents a set of real challenges to address in order to proceed. One, there is a clear need for reliable neutron capture cross section predictions far from stability. Two, at present, there is no experimental capability for direct cross section measurements on these unstable isotopes comparable to what has been performed over the last 60 years for stable isotopes. Instead, rapid development of experimental techniques on unstable isotopes has offered new constraints on the model parameters used to calculate neutron capture cross sections. In contrast to a direct measurement, these measurements must necessarily be interpreted in the framework of a reaction model in order to comment on their impact on the unknown cross sections.
In this manuscript, we will discuss how the results from one such measurement can be used to understand differences between the predictions from different statistical model codes. We will illustrate how remaining nuclear data uncertainties give rise to remaining uncertainties in the cross section predictions. Finally, we will make recommendations on how experimental results from studies designed to inform Hauser-Feshbach model code predictions should report both results and calculation parameters in order to make it possible to compare predictions from different codes. We report on the first such comparison on neutron-rich nuclei, using the \(^{73}\hbox {Zn}\)(n,\(\gamma \))\(^{74}\hbox {Zn}\) reaction as a test case. While such comparisons are also possible on nuclei near stability, near stability there is general agreement on the underlying nuclear data in the calculations. \(^{73}\hbox {Zn}\) is only three units from stability, however, the limitations in data are more representative of the situation for a nucleus on the r-process path.
2 Comparison of Hauser-Feschbach statistical model codes
Three Hauser-Feshbach statistical codes were chosen to compare a calculated neutron-capture cross section: TALYS (v. 1.6), EMPIRE (v. 3.2.3), and CoH (v. 3.5.1). Adapting codes to use identical nuclear inputs in the same manner is not straightforward. In the previous study [5] the authors instead developed two new codes (CIGAR and SAPPHIRE) to guarantee identical treatment of nuclear inputs, and investigated the uncertainty in the Maxwellian-averaged cross section (MACS) resulting from differences such as how many of the known experimental levels were used in the calculation [5]. CoH, EMPIRE, and TALYS have a number of differences in physics input, model assumptions, and restrictions that were investigated.
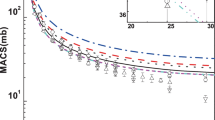
In the present study, the codes were first compared using a “black box” approach where as little information as possible was given to run the calculation. All of the default conditions, including the shape of the NLD and \(\gamma \hbox {SF}\), were not changed. As shown in Fig. 1, the shape and magnitude of the results of the default calculations do not agree. This points to differences in both the models for the NLD and \(\gamma \hbox {SF}\) (the defaults are very different between the codes, see Fig. 2), as well as some of the nuclear structure information that is being used in the calculations. For many unstable nuclei, this comparison gives a reasonable representation of the minimum level of uncertainty before a dedicated measurement to improve the statistical model parameters on a particular nucleus. For detailed tables of the NLD and \(\gamma \hbox {SF}\) values, see the Supplemental Information.

Comparison of \(^{73}\hbox {Zn}\)(n,\(\gamma \))\(^{74}\hbox {Zn}\) cross section calculated using TALYS, EMPIRE, and CoH without altering any of the default settings

(Top) Default NLD for \(^{74}\hbox {Zn}\) in TALYS, CoH, and EMPIRE compared to the experimental NLD obtained using the \(\beta \)-Oslo method [21]. (Bottom) Default \(\gamma \hbox {SF}\) for \(^{74}\)Zn in TALYS, CoH, and EMPIRE compared to the experimental \(\gamma \)SF obtained using the \(\beta \)-Oslo method [21]
2.1 Incorporating experimental data
The experimentally constrained NLD and \(\gamma \)SF from Ref. [21] were used for this comparison. A \(^{74}\)Cu \(\beta \)-decay experiment was performed to extract the NLD and \(\gamma \)SF of \(^{74}\)Zn using the \(\beta \)-Oslo method [22]. The \(\gamma \) rays observed in the Summing NaI detector (SuN) [23] provided the statistical decay information needed to determine the NLD and \(\gamma \)SF. This was the first experimental data for the NLD and \(\gamma \)SF of \(^{74}\)Zn, which allowed the shape of both to be better constrained in the Hauser-Feshbach statistical codes.
The NLD, shown in Fig. 2, was formatted so that it could be read in to each code without any changes or renormalizations. TALYS has options for both spin-dependent and spin- and parity-dependent tables to read in the NLD, but because there was no information about the parity distribution from the experimental data, only a spin-dependent NLD was used, which assumed an equal parity distribution. CoH and EMPIRE required a spin- and parity-dependent table, which was generated with an equal parity distribution to match the NLD for TALYS. The spin dependence developed by Gilbert and Cameron [24] was used in all cases. The \(\gamma \)SF was restricted in CoH to a combination of a generalized Lorentzian (GLO) [25] function for the E1 component and a standard Lorentzian (SLO) [26] function for the M1 upbend component. The E1 parameters were restricted based on a GLO fit to photoabsorption cross section data [27], then the GLO+SLO function was fit to the \(\gamma \)SF data. The parameters from the fit (Fig. 3) are shown in Table 1. In TALYS the function needed to be added directly to the source code due to constraints on the M1 SLO parameter values, while in CoH the GLO and SLO parameters were defined in the input file. EMPIRE allows for the \(\gamma \)SF to be read in from a table, which was generated using the GLO+SLO function and fit parameters. The NLD and \(\gamma \)SF were checked at various stages in the calculation to make sure no further adjustments were made in the calculation process.

The cross sections from each code after adding in the experimentally-constrained NLD and \(\gamma \)SF are shown in Fig. 4. It is evident that much of the discrepancy in the cross sections between Fig. 1 and Fig. 4 came from the default choices for the parameters in the NLD and \(\gamma \)SF. With experimental data the cross sections are in much better agreement, especially at lower neutron energies (e.g., below 100 keV). This suggests that by requiring the three codes to use exactly the same NLD and \(\gamma \)SF, the large discrepancy between the calculated cross sections can be limited. However, there are still differences in the shape of the cross section at neutron energies above 100 keV. The bottom portion of Fig. 4 shows the percent deviation of the CoH and EMPIRE cross sections compared to the TALYS cross section. The deviation ranges from \(-14\%\) to 175%, with the largest deviation occurring at higher neutron energies. A particularly large change can be seen around 195 keV, the energy of the first excited state in \(^{73}\)Zn, of which the spin and parity was only tentatively assigned as a (5/2\(^+\)) [28].

(Top) TALYS, EMPIRE, and CoH \(^{73}\)Zn(n,\(\gamma \))\(^{74}\)Zn cross sections using experimentally obtained NLD and \(\gamma \)SF. All other aspects of the codes were left to default conditions. (Bottom) Percent deviation of the CoH and EMPIRE cross sections compared to the TALYS cross section after including the experimental NLD and \(\gamma \)SF
2.2 Spin and parity assignments
The spins and parities of levels in the nuclei involved had an impact on the cross sections. In both \(^{73,74}\)Zn many of the levels included in the RIPL-3 database [29] have unknown spins and parities. Tables 2 and 3 list the known excited states of both nuclei, along with the spins and parities suggested in RIPL-3, the final spins and parities used in the comparison calculation, and the original assignments made by each of the three codes. The first excited state of \(^{73}\)Zn at 195.5 keV for example, shows how large the impact of unknown spins and parities can be. Both CoH and EMPIRE did not consider the 195.5 keV level for inelastic neutron scattering due to the lack of a firm \(\hbox {J}^{\pi }\) assignment, while TALYS used the level with its tentative assignment for inelastic neutron scattering. The CoH and EMPIRE cross sections deviate from the TALYS cross section significantly at this energy. By giving the level a 5/2\(^+\) assignment, which is what TALYS had already assigned the level, inelastic scattering to the first excited state in \(^{73}\)Zn became possible in the calculated cross sections from EMPIRE and CoH. The 5/2\(^+\) assignment has been recently confirmed [30, 31]. The updated \(\hbox {J}^{\pi }\) value for the level described highlights the importance of continually updating cross sections as nuclear data improves, as it can impact statistical calculations.
TALYS assigns a spin and parity based on statistical spin rules, while CoH uses statistical spin rules to make an assignment up to a certain number of levels, which is specified in a level file for each nucleus. EMPIRE also assigns a spin and parity up to a certain number of levels, though for the even-even nucleus \(^{74}\)Zn all of the assignments were 0\(^{+}\). Assignments do not always match those suggested in RIPL-3 and are not consistent between the three codes. As an additional example, RIPL-3 suggests a spin and parity assignment of (0\(^+\), 4\(^+\)) for the second excited state at 1418 keV in \(^{74}\)Zn, but the assignment in TALYS was 3\(^+\), EMPIRE made an assignment of 0\(^{+}\), and CoH made no assignment at all. For the purpose of the present comparison, levels that had unknown spins/parities were assigned a value that was the same across all three codes. The 1418 keV level was assigned a spin and parity of 4\(^+\) due to an updated ENSDF evaluation in 2017 that suggested a 4\(^+\) assignment from Coulomb excitation [32], though the spin change had no impact on the cross section calculation.
It is generally assumed that not all the excited states of a nucleus have been observed, especially for nuclei far from stability. TALYS uses the discrete levels provided in the RIPL-3 table, then creates levels at higher energies until there are at least 100 discrete levels. The levels are created based on the microscopic level density of Goriely, Hilaire, and Koning calculated using the Hartree-Fock-Bogoliubov plus combinatorial method using the Skyrme force [33]. The addition of the theoretical levels is a default setting, but can be turned off in the input file. CoH provides the option to populate the nucleus with a continuum of states above a given level, which can start at a lower energy than the highest level in RIPL-3. The continuum is based on the level density that is being used in the calculation. This is not an option that can be changed in the input file, but is still easily modified in the list of levels that is read in. Finally, EMPIRE does not provide any discrete levels beyond those in RIPL-3. For the present comparison, only the levels in RIPL-3 were included, with spins and parities of those levels edited to be consistent among the codes. While new structure information is always becoming available (e.g., for \(^{73}\hbox {Zn}\)), there are still many neutron-rich nuclei that need to be studied so that there is complete low- and high-energy structure information that is vital for cross section calculations.
3 Discussion
After accounting for all of the differences, the calculated neutron-capture cross sections from TALYS, CoH, and EMPIRE agree well, as shown in Fig. 5. The small discrepancy in the EMPIRE cross section, which is about 10% higher than those of CoH and TALYS, is most likely due to the different width fluctuation corrections (WFC) that are used in the calculations. CoH uses WFC described in [34], which are based on the Moldauer approach that is used in TALYS [35], which leads to very similar treatments and therefore very similar cross sections. EMPIRE uses the Hofmann, Richert, Tepel, and Weidenmüller (HRTW) approach [36, 37], which was shown to differ from the Moldauer formulation [34, 38].
Producing a neutron-capture cross section that incorporates experimental data for the NLD and \(\gamma \)SF requires choosing a code that allows for the data to be included as accurately as possible; the choice also brings in a set of assumptions such as those detailed in Table 2. A casual user is more likely to arrive at disagreements resembling Fig. 1 than to reach results similar to those in Fig. 5. A dedicated experiment to improve the uncertainties in predictions for unstable nuclei would likely achieve the level of agreement observed in Fig. 4. However, if only one code is used, the systematic uncertainty explored here is still unknown.
This points to a dilemma in reaction modeling for cases where the underlying nuclear data (such as level energies, spins, and parities) are not well known. One path is to force the inclusion of known physical processes, even when the data are inadequate to calculate them properly. Another option is to only calculate those processes where the data are adequate for a robust calculation. To be clear, this is not a deficiency in the model, but rather a deficiency in the nuclear data used in the calculation. Both choices are reasonable assumptions under adverse conditions; the choice is likely driven by the primary physics problems being addressed. These two options are illustrated in the differing treatments for inelastic scattering in \(^{73}\)Zn where spectroscopic level information is incomplete. Improving agreement beyond what is observed in Fig. 4 requires improved nuclear data.
Based on these observations, we recommend that experimental work using statistical model codes to interpret the measurements report not only the quantities measured in the experiment, but the additional nuclear data used in the statistical model calculations. In the case of \(^{73}\)Zn discussed here, that would mean reporting the \(\gamma \)SF parameters from Table 1 as well as the structure parameters from Tables 2 and 3 taken from literature and used in the interpretation. In this way, later work can make direct comparisons and clearly differentiate differences arising from input data versus those arising from code techniques. Finally, this gives a clearer picture of where additional measurements could improve the uncertainties in theoretical predictions.

Final cross section comparison of TALYS, EMPIRE, and CoH using experimentally obtained NLD and \(\gamma \)SF. Other parameters were also changed to be consistent between the three codes, including spins and parities of levels (see text for detail)
4 Conclusions
As demonstrated, it is possible to obtain the same cross section (within 10%) with TALYS, CoH, and EMPIRE for a neutron-rich nucleus using experimentally obtained inputs. This ultimately indicates that the choice of Hauser-Feshbach code has a small impact on the overall uncertainty of the calculated cross section, as expected, when the differing assumptions are addressed. However, there are inherent challenges in calculating neutron-capture cross sections in regions where the underlying nuclear data are incomplete. A calculation must necessarily make assumptions about unknown nuclear quantities in order to complete the calculation. In the case of \(^{73}\)Zn(n, \(\gamma \))\(^{74}\)Zn, even after identical experimentally derived NLD and \(\gamma \)SF were incorporated into TALYS, CoH, and EMPIRE, the calculated results differed in scale and energy dependence. This was due to the underlying assumptions about the existence and properties of states in the initial and final nucleus, which were all supported by a robust physics justification. Further, each code has different restrictions on how to incorporate the experimental data. The major cause of the deviation between codes after incorporating the experimental NLD and \(\gamma \)SF comes from the lack of information about low-lying levels, which is information that can be obtained for many neutron-rich nuclei with spectroscopic experiments. Concerns about accurately representing and incorporating data into the calculation can limit which codes can be used for a particular nucleus, and that choice brings with it the underlying assumptions of the code. Future measurements should provide more complete documentation of the nuclear data inputs chosen in the reaction model calculations when interpreting the experimental results.
Data availability
This manuscript has associated data in a data repository. [Authors’ comment: Tables of the default code NLD and \(\gamma \)SF for \(^{73}\)ZN are available in the supplementary material.]
References
E. Margaret Burbidge, G.R. Burbidge, W.A. Fowler, F. Hoyle, Synthesis of the elements in stars. Rev. Mod. Phys. 29, 547 (1957)
F. Käppeler, R. Gallino, S. Bisterzo, W. Aoki, The s process: nuclear physics, stellar models, and observations. Rev. Mod. Phys. 83, 157 (2011)
M. Arnould, S. Goriely, K. Takahashi, The r-process of stellar nucleosynthesis: astrophysics and nuclear physics achievements and mysteries. Phys. Rep. 450(4–6), 97–213 (2007)
M.R. Mumpower, R. Surman, G.C. McLaughlin, A. Aprahamian, The impact of individual nuclear properties on r-process nucleosynthesis. Prog. Part. Nucl. Phys. 86, 86 (2016)
M. Beard, E. Uberseder, R. Crowter, M. Wiescher, Comparison of statistical model calculations for stable isotope neutron capture. Phys. Rev. C 90, 034619 (2014)
R. Surman, J. Engel, Changes in r-process abundances at late times. Phys. Rev. C 64, 035801 (2001)
S.N. Liddick, A. Spyrou, B.P. Crider, F. Naqvi, A.C. Larsen, M. Guttormsen, M. Mumpower, R. Surman, G. Perdikakis, D.L. Bleuel, A. Couture, L. Crespo Campo, A.C. Dombos, R. Lewis, S. Mosby, S. Nikas, C.J. Prokop, T. Renstrom, B. Rubio, S. Siem, S.J. Quinn, Experimental neutron capture rate constraint far from stability. Phys. Rev. Lett. 116, 242502 (2016)
P. Denissenkov, G. Perdikakis, F. Herwig, H. Schatz, C. Ritter, M. Pignatari, S. Jones, S. Nikas, A. Spyrou, The impact of ( n, \(\gamma \) ) reaction rate uncertainties of unstable isotopes near N = 50 on the i-process nucleosynthesis in He-shell flash white dwarfs. J. Phys. G: Nucl. Part. Phys. 45, 055203 (2018)
W. Hauser, H. Feshbach, The inelastic scattering of neutrons. Phys. Rev. 87, 366 (1952)
A.J. Koning, D. Rochman, Modern nuclear data evaluation with the TALYS code system. Nucl. Data Sheets 113, 2927 (2012)
A. Koning, S. Hilaire, and M.C. Duijvestijn. TALYS-1.0. In Proceedings of the International Conference on Nuclear Data for Science and Technology 2007, pages 211–214. EDP Sciences, Nice, France, 2007, (2007)
T. Rauscher, F.-K. Thielemann, Astrophysical reaction rates from statistical model calculations. At. Data Nucl. Data Tables 75, 1 (2000)
T. Rauscher, F.-K. Thielemann, Stellar evolution, stellar explosions, and galactic chemical evolution (IOP, Bristol, 1998)
M. Herman, R. Capote, B.V. Carlson, P. Obložinský, M. Sin, A. Trkov, H. Wienke, V. Zerkin, EMPIRE: nuclear reaction model code system for data evaluation. Nucl. Data Sheets 108, 2655 (2007)
T. Kawano, R. Capote, S. Hilaire, P. Chau Huu-Tai, Statistical Hauser-Feshbach theory with width-fluctuation correction including direct reaction channels for neutron-induced reactions at low energies. Phys. Rev. C 94, 014612 (2016)
E. Uberseder, T. Adachi, T. Aumann, S. Beceiro-Novo, K. Boretzky, C. Caesar, I. Dillmann, O. Ershova, A. Estrade, F. Farinon, J. Hagdahl, T. Heftrich, M. Heil, M. Heine, M. Holl, A. Ignatov, H.T. Johansson, N. Kalantar, C. Langer, T. Le Bleis, Y.A. Litvinov, J. Marganiec, A. Movsesyan, M.A. Najafi, T. Nilsson, C. Nociforo, V. Panin, S. Pietri, R. Plag, A. Prochazka, G. Rastrepina, R. Reifarth, V. Ricciardi, C. Rigollet, D.M. Rossi, D. Savran, H. Simon, K. Sonnabend, B. Streicher, S. Terashima, R. Thies, Y. Togano, V. Volkov, F. Wamers, H. Weick, M. Weigand, M. Wiescher, C. Wimmer, N. Winckler, P.J. Woods, First experimental constraint on the \(^{59}{{\rm Fe}}(n,{\gamma })^{60}{{\rm Fe}}\) reaction cross section at astrophysical energies via the coulomb dissociation of \(^{60}{{\rm Fe}} \). Phys. Rev. Lett. 112, 211101 (2014)
R. Capote, S. Hilaire, O. Iwamoto, T. Kawano, M. Sin, Inter-comparison of Hauser-Feshbach model codes toward better actinide evaluations. EPJ Web Conf. 146, 12034 (2017)
A.C. Larsen, N. Blasi, A. Bracco, F. Camera, T.K. Eriksen, A. Görgen, M. Guttormsen, T.W. Hagen, S. Leoni, B. Million, H.T. Nyhus, T. Renstrøm, S.J. Rose, I.E. Ruud, S. Siem, T. Tornyi, G.M. Tveten, A.V. Voinov, M. Wiedeking, Evidence for the dipole nature of the low-energy g enhancement in Fe56. Phys. Rev. Lett. 111, 242504 (2013)
J.a. Cizewski, R. Hatarik, K.L. Jones, S.D. Pain, J.S. Thomas, M.S. Johnson, D.W. Bardayan, J.C. Blackmon, M.S. Smith, and R.L. Kozub., (d, p\(\gamma \)) Reactions and the surrogate reaction technique. Nucl. Instr. Meth. Phys. Res. A 261(1–2), 938–940 (2007)
H. Utsunomiya, S. Goriely, H. Akimune, H. Harada, F. Kitatani, S. Goko, H. Toyokawa, K. Yamada, T. Kondo, O. Itoh, M. Kamata, T. Yamagata, Y.-W. Lui, I. Daoutidis, D.P. Arteaga, S. Hilaire, A.J. Koning, \(\gamma \) -ray strength function method and its application to 107 Pd. Phys. Rev. C 82, 064610 (2010)
R. Lewis, S.N. Liddick, A.C. Larsen, A. Spyrou, D.L. Bleuel, A. Couture, L. Crespo Campo, B.P. Crider, A.C. Dombos, M. Guttormsen, S. Mosby, F. Naqvi, G. Perdikakis, C.J. Prokop, S.J. Quinn, T. Renstrøm, S. Siem, Experimental constraints on the \(^{73}\rm Zn (n,\gamma )^{74}\rm Zn \) reaction rate. Phys. Rev. C 99(3), 034601 (2019)
A. Spyrou, S.N. Liddick, A.C. Larsen, M. Guttormsen, K. Cooper, A.C. Dombos, D.J. Morrissey, F. Naqvi, G. Perdikakis, S.J. Quinn, T. Renstrøm, J.A. Rodriguez, A. Simon, C.S. Sumithrarachchi, R.G.T. Zegers, Novel technique for Constraining r-Process (n, \(\gamma \)) Reaction Rates. Phys. Rev. Lett. 113, 232502 (2014)
A. Simon, S.J. Quinn, A. Spyrou, A. Battaglia, I. Beskin, A. Best, B. Bucher, M. Couder, P.A. Deyoung, X. Fang, J. Görres, A. Kontos, Q. Li, S.N. Liddick, A. Long, S. Lyons, K. Padmanabhan, J. Peace, A. Roberts, D. Robertson, K. Smith, M.K. Smith, E. Stech, B. Stefanek, W.P. Tan, X.D. Tang, M. Wiescher, SuN: summing NaI(Tl) gamma-ray detector for capture reaction measurements. Nucl. Instr. Methods Phys. Res. A 703, 16 (2013)
A. Gilbert, A.G.W. Cameron, A composite nuclear level density formula with shell corrections. Can. J. Phys. 43, 1446 (1965)
J. Kopecky, M. Uhl, Test of gamma-ray strength functions in nuclear reaction model calculations. Phys. Rev. C 41, 1941 (1990)
D.M. Brink. PhD thesis, Oxford University (1955)
A.M. Goryachev, G.N. Zalesnyy, The studying of the photoneutron reactions cross sections in the region of the giant dipole resonance in zinc, germanium, selenium, and strontium isotopes. Voprosy Teoreticheskoy i Yadernoy Fiziki 8, 121 (1982)
M. Huhta, P. Mantica, D. Anthony, P. Lofy, J. Prisciandaro, R. Ronningen, M. Steiner, W. Walters, New evidence for deformation in 73Zn. Phys. Rev. C 58(6), 3187–3194 (1998)
R. Capote, M. Herman, P. Obložinský, P.G. Young, S. Goriely, T. Belgya, A.V. Ignatyuk, A.J. Koning, S. Hilaire, V.A. Plujko, M. Avrigeanu, O. Bersillon, M.B. Chadwick, T. Fukahori, Zhigang Ge, S. Yinlu Han, J. Kailas, V.M. Kopecky, G. Maslov, M. Reffo, ESh. Sin, Soukhovitskii, P. Talou., RIPL - Reference Input Parameter Library for Calculation of Nuclear Reactions and Nuclear Data Evaluations. Nuclear Data Sheets 110(12), 3107–3214 (2009)
C. Wraith, X.F. Yang, L. Xie, C. Babcock, J. Bieroń, J. Billowes, M.L. Bissell, K. Blaum, B. Cheal, L. Filippin, R.F. Garcia Ruiz, W. Gins, L.K. Grob, G. Gaigalas, M. Godefroid, C. Gorges, H. Heylen, M. Honma, P. Jönsson, S. Kaufmann, M. Kowalska, J. Krämer, S. Malbrunot-Ettenauer, R. Neugart, G. Neyens, W. Nörtershäuser, F. Nowacki, T. Otsuka, J. Papuga, R. Sánchez, Y. Tsunoda, D.T. Yordanov, Evolution of nuclear structure in neutron-rich odd-Zn isotopes and isomers. Phys. Lett. Sect. B: Nucl. Element Particle High-Energy Phys. 771, 385–391 (2017)
X.F. Yang, Y. Tsunoda, C. Babcock, J. Billowes, M.L. Bissell, K. Blaum, B. Cheal, K.T. Flanagan, R.F. Garcia Ruiz, W. Gins, C. Gorges, L.K. Grob, H. Heylen, S. Kaufmann, M. Kowalska, J. Krämer, S. Malbrunot-Ettenauer, R. Neugart, G. Neyens, W. Nörtershäuser, T. Otsuka, J. Papuga, R. Sánchez, C. Wraith, L. Xie, D.T. Yordanov, Investigating the large deformation of the 5/2+ isomeric state in Zn 73: An indicator for triaxiality. Phys. Rev. C 97(4), 1–8 (2018)
J. Van De Walle, F. Aksouh, T. Behrens, V. Bildstein, A. Blazhev, J. Cederkäll, E. Clément, T.E. Cocolios, T. Davinson, P. Delahaye, J. Eberth, A. Ekström, D.V. Fedorov, V.N. Fedosseev, L.M. Fraile, S. Franchoo, R. Gernhauser, G. Georgiev, D. Habs, K. Heyde, G. Huber, M. Huyse, F. Ibrahim, O. Ivanov, J. Iwanicki, J. Jolie, O. Kester, U. Köster, T. Kröll, R. Krücken, M. Lauer, A.F. Lisetskiy, R. Lutter, B.A. Marsh, P. Mayet, O. Niedermaier, M. Pantea, R. Raabe, P. Reiter, M. Sawicka, H. Scheit, G. Schrieder, D. Schwalm, M.D. Seliverstov, T. Sieber, G. Sletten, N. Smirnova, M. Stanoiu, I. Stefanescu, J.C. Thomas, J.J. Valiente-Dobón, P. Van Duppen, D. Verney, D. Voulot, N. Warr, D. Weisshaar, F. Wenander, B.H. Wolf, M. Zielińska, Low-energy Coulomb excitation of neutron-rich zinc isotopes. Phys. Rev. C- Nuclear Phys. 79(1), 1–13 (2009)
S. Goriely, S. Hilaire, A.J. Koning, Improved microscopic nuclear level densities within the Hartree-Fock-Bogoliubov plus combinatorial method. Phys. Rev. C 78, 064307 (2008)
T. Kawano, P. Talou, Numerical simulations for low energy nuclear reactions to validate statistical models. Nucl. Data Sheets 118(1), 183–186 (2014)
P.A. Moldauer, Statistics and the average cross section. Nucl. Phys. A 344, 185–195 (1980)
H.M. Hofmann, J. Richert, J.W. Tepel, Direct reactions and hauser-feshbach theory II numerical methods and statistical tests. Ann. Phys. 90, 391–402 (1975)
H.M. Hofmann, T. Mertelmeier, M. Herman, J.W. Tepel, Hauser-Feshbach calculations in the presence of weakly absorbing channels with special reference to the elastic enhancement factor and the factorization assumption. Zeitschrift für Physik A Atoms and Nuclei 297, 153–160 (1980)
C. S. Hilaire, Lagrange, A. J. Koning, Comparisons between various width fluctuation correction factors for compound nucleus reactions. Ann. Phys. 306(2), 209–231 (2003)
Acknowledgements
This work was supported by the National Science Foundation under Grants No. PHY 1350234 (CAREER), No. PHY 1102511 (NSCL), No. PHY 1404442, and No. PHY 0822648 (Joint Institute for Nuclear Astrophysics). We would also like to acknowledge the support of the Department of Energy National Nuclear Security Administration (NNSA) under Grant No. DE-NA0003221 and the Nuclear Science and Security Consortium under Award No’s. DE-NA0000979 and DE-NA0003180. This work was supported by the US Department of Energy through the Los Alamos National Laboratory. Los Alamos National Laboratory is operated by Triad National Security, LLC, for the National Nuclear Security Administration of U.S. Department of Energy (Contract No. 89233218CNA000001). This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. A.C. was supported by the Laboratory Directed Research and Development program of Los Alamos National Laboratory under project number(s) LDRD201600173ER. A.C.L. gratefully acknowledges funding through ERC-STG-2014, Grant Agreement No. 637686.
Funding
National Science Foundation under Grants No. PHY 1350234 (CAREER), No. PHY 1102511 (NSCL), No. PHY 1404442, and No. PHY 0822648 (Joint Institute for Nuclear Astrophysics). Department of Energy National Nuclear Security Administration (NNSA) under Grant No. DE-NA0003221 and the Nuclear Science and Security Consortium under Award No’s. DE-NA0000979 and DE-NA0003180. National Nuclear Security Administration of U.S. Department of Energy (Contract No. 89233218CNA000001). Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. Los Alamos National Laboratory under project number(s) LDRD201600173ER. A.C.L. gratefully acknowledges funding through ERC-STG-2014, Grant Agreement No. 637686.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Nicolas Alamanos.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lewis, R., Couture, A., Liddick, S.N. et al. Statistical (n,\(\gamma \)) cross section model comparison for short-lived nuclei. Eur. Phys. J. A 59, 42 (2023). https://doi.org/10.1140/epja/s10050-023-00920-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epja/s10050-023-00920-0