
Abstract
COVID-19 impacted citizens around the globe physically, economically, socially, or emotionally. In the first 2 years of its emergence, the virus dominated media in offline and online conversations. While fear was a justifiable emotion; were online discussions deliberately fuelling it? Concerns over the prominent negativity and mis/disinformation on social media grew, as people relied on social media more than ever before. This study examines expressions of stress and emotions used by bots on what was formerly known as Twitter. We collected 5.6 million tweets using the term “Coronavirus” over two months in the early stages of the pandemic. Out of 77,432 active users, we found that over 15% were bots while 48% of highly active accounts displayed bot-like behaviour. We provide evidence of how bots and humans used language relating to stress, fear and sadness; observing substantially higher prevalence of stress and fear messages being re-tweeted by bots over human accounts. We postulate, social media is an emotion-driven attention information market that is open to “automated” manipulation, where attention and engagement are its primary currency. This observation has practical implications, especially online discussions with heightened emotions like stress and fear may be amplified by bots, influencing public perception and sentiment.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The novel COVID-19 Coronavirus is thought to have first emerged in late 2019 in China. It started making the rounds on Twitter (now renamed X) long before the WHO declared that it had become a pandemic on 11th March 2020 [54], also see; [59], for a timeline). With the spread of the virus came the spread of mis/disinformation around it, and the WHO dubbed the stream of mis/disinformation invading our homepages as an “infodemic” [103]. In a public letter, the Dean and Professor of the Boston University School of Public Health, Galea [31] stated, “COVID-19 is the first global pandemic of the social media age, the first of the ‘alternative facts’ era, and is occurring at a moment when politics and society seem to be in a state of accelerated flux”. There has been mounting concern that certain content can potentially be amplified at unprecedented scale by automated social media accounts (also known as bots), for a variety of malicious purposes [13, 34, 39, 41, 42, 48, 53, 55]. Although some research investigating bot activity around the Coronavirus discourse exists (e.g., [28, 102]), to our knowledge, our study is the first to examine a wider range of affective language use by suspected bot accounts during the early months of the Coronavirus COVID-19 pandemic. We compare the proportion of highly charged emotional content and stress-bearing language stemming from automated bot accounts to non-bot accounts on Twitter/X,Footnote 1 a major social media platform. We outline the instrumental role emotions and stress play in engaging social media users with information and the related theory, proposing a way forward to ameliorate the problem of large-scale automated behaviour and its potential risk for amplifying mis/disinformation.
Wang et al. [98] explain that “amateur citizen journalism” that is generated through unqualified social media users gives way to the spread of mis/disinformation. Particularly in 2020, the pandemic was described by politicians as a “crisis” likened to “war” [85], where mis/disinformation emerged (arguably not unlike war-time propaganda) which had effects on societies which were under lockdown and were more reliant than ever on social media content [6, 33, 44]. Even before the pandemic and the ensuing lockdowns, research by Gil de Zúñiga and Diehl [36] found that news audiences had begun to shift their attention away from traditional news media platforms and look more towards social media content, which is why we believe that it is particularly important to understand (1) what kind of content was being amplified on Twitter about the Coronavirus in its very early days, (2) by whom, and (3) what effect this has on Twitter users who interact with this information. History has shown that the initial stages of any major event are often filled with uncertainty, confusion, and a lack of concrete information. This vacuum often gets filled with rumours, speculation, and, unfortunately, intentional disinformation which could contain negative emotional sentiment [30]. By analysing how misinformation spreads during the early days of the coronavirus pandemic, we can identify patterns and common sources of negative affect. It is generally accepted that social media can strongly influence public opinion [64, 66]. Communication on these platforms is shaped by user accounts belonging to individuals and organisations with various aims. The instrumental role emotions, and predominantly high arousal affective states such as anger, disgust, fear and stress, play in engaging users with content, and especially misinformation, has been acknowledged [87, 95, 96]. Trevors and Kendeou [87] experimentally show how using emotionally charged language can substantially mediate knowledge comprehension. Bakir and McStay [5] provide an explanation behind the high emotional content being pushed out. They explain that our emotional responses as consumers of mis/disinformation are viewed as a valuable commodity since content that generates heightened emotions is “leveraged to generate attention and viewing time”, which in turn, is converted to advertising revenue (ibid., p.155) particularly when hyperlinks are included in a tweet [60]. Engineering such content, emotional responses and interactions aligns well with ideas of an information market where attention and engagement are core components [23, 56, 106, 107].
Research indicates that a plethora of human behaviours, attentional patterns, and emotional responses are intricately intertwined with human language [12, 82]. Emotions are fundamentally understood as innate biological responses to different situations that individuals face [3]. Their instinctual nature plays a significant role in shaping human actions, a point emphasised by Barbalet [7, 8]. He draws his conclusions from the groundbreaking experiments of Kluver and Bucy back in 1939, which highlighted that modifications to the temporal lobes in primates, specifically the region of the amygdala responsible for fear and anxiety (both of which are linked to an increase in cortisol levels related to stress as reported by [65]), directly influenced their behaviour, making them less vigilant and more prone to take risks [21]. This aligns with Davidson’s [22] model of emotional processing which suggests that given the intertwined nature of emotions and actions, an emotional trigger typically leads to either a positive engagement or a negative withdrawal response. In the realm of social media, this suggests that emotional triggers can influence a user’s decision to engage with content or act on specific information. Kousta et al. [51] noted that emotionally rich words are comprehended faster and more accurately than neutral counterparts. While most studies do not differentiate between the processing of positive and negative emotions, Taylor [83] observed that negative emotions typically provoke more intense reactions. This suggests that reading text charged with negative emotions might have a profound impact, a hypothesis Cacioppo and Gardner [17] believe may be linked to primal survival mechanisms. Given the reliance on social media, particularly during the early stages of the pandemic, understanding these emotional dynamics becomes even more critical. Social media platforms filled with emotionally charged content, we argue, profoundly impact user behaviour, engagement, and decision-making, therefore making it worthwhile to understand who is responsible for tweeting such content. While there is a strong relationship between stress and emotions, for instance, conceptually on the dimensional model of emotion, stress being a high arousal state as are some emotions like fear and anger (see [80]), certain emotions often also accompany and lead to stress. Nevertheless, stress is well evidenced as a long lasting distinct state that occurs when demands surpass an individual's ability to cope, impacting them mentally, physiologically and emotionally [27]. Hence, the overarching role of stress during crises, specifically the pandemic, is especially noteworthy [25, 40].
Journalists have repeatedly pointed to anecdotal evidence of how social media often seems to amplify misleading content. For instance, Madrigal [54] argued how the most extreme statements that elicit an emotional “wow” reaction can be far more amplified than more measured messages. In late January of 2020 Madrigal (ibid.) described the case of a highly misjudged and sensational tweet posted by a Harvard public health expert, Dr Feigl-Ding, that was met with a correcting response by the science journalist Ferris Jabr, while the former went viral, the latter barely garnered any reaction on Twitter. Given that Twitter as a platform encourages user account automation [89] and arguably condones or at least struggles to effectively monitor the use of highly questionable bots (see Sect. 2), it is of utmost importance to understand the prevalence of bots on Twitter during this pandemic and the use of potentially manipulative affective language by such automated accounts, as opposed to non-automated human accounts. It has been suggested that large number of automated bots are attempting to influence public opinion at scale [13, 29, 48, 53, 55], and that they usually propagate low credibility information [42, 72]. Ross et al. [66] have shown using an agent-based model simulation, how bot participation as small as 2–4% of a communication network can be sufficient to tip over the opinion climate in two out of three cases, on substantive topics. Given the suspected key importance of affect and discrete emotions in communicated content on social media that has been identified in the literature review, and the initial research pointing to the substantial influence bots can have on opinion formation albeit the lack of thorough investigation of the emotion and stress-bearing content that bots on Twitter produce, we are proposing to address the following research questions in this study:
RQ1: What is the prevalence of automated bot-like accounts throughout the initial stages of the Coronavirus pandemic discussions on Twitter?
RQ2: Which specific emotions were more often tweeted (and re-tweeted) in the tweets by suspected bots in comparison to human accounts?
RQ3: Was language that is indicative of stress prevalent across the Coronavirus topic on Twitter?
These RQs are significant with relation to the design and large scale deployment of automated behaviours, since besides mounting evidence of mis/disinformation, it remains largely unknown to what extent automated bot accounts are designed and used at scale to manipulate the information environment by spreading specific emotions and distress across social media.
The subsequent section elaborates on the choice of Twitter as the social media platform for this study. It also provides further background on social media specific aspects of automated bot accounts, trolls and related ongoing studies on COVID-19. Section “Methods and analysis” presents the dataset and methods, with results and discussion across Sects. “Results” and “Discussion”, respectively.
Background
In this study the popular social media platform Twitter,Footnote 2 which had around 326 million active users around the time of this study [74], was used. At the time of this study, Twitter was often used as a platform for users to take part in the political discourse [75]. Mellon and Prosser [57] found that Twitter users were more politically engaged than the general population, and Bennett [10] also importantly highlighted the instrumentality of Twitter in contemporary events, such as the Occupy Movement and the Arab Spring. This is further evident, in the role that Twitter played during US president Trumps’ election campaign and subsequent engagement with the American and World public via Twitter [9]. It was not uncommon for tweets to make headlines on mainstream media outlets [26], which then amplify a single tweet not only to the followers of the author of the tweet and their re-tweeters, but to the general public who may not be social media users. Twitter is also instrumental within the broader social media ecology, such as re-sharing content from YouTube content creators and influencers [56]. Twitter hence plays an important role in shaping how print, broadcast media as well as other elites (e.g., politicians) mediate and frame discourse around certain topics [55]. This phenomenon also amplifies the need to understand the source of some tweets in the context of the spread of mis/disinformation, especially now at a time where conspiracy theories around viral infections and vaccines are shared widely on social media [24, 99, 102] particularly on Twitter [60].
At the time of collecting the Twitter data, Twitter, like other social media platforms, sets out acceptable norms and standards of behaviour [90], asking its users for instance not to post violent threats, content that glorifies self-harm, etc. Twitter rules at the time of data collection (ibid.) stipulated that behaviours such as the abuse of trending topics or hashtags (topic words with a ‘#’ sign), posting similar messages over multiple accounts, repeatedly posting duplicate links, or sending automated replies, are not allowed. While sensible and well intentioned, one can see how these guidelines may be difficult to enforce and somewhat open to interpretation. More generally, at the time of data collection, Twitter rules and policies as well as the official Twitter REST API guidelines, supported and encouraged the development and use of automated bot accounts, as long as a set of automation rules [89] that stipulated not to abuse and downgrade the “Twitter experience” were observed by bot developers. Following much criticism in enforcing their own rules, from 2018 until its recent acquisition by Elon Musk, Twitter suspended accounts and removed several million accounts each month, as described in their official Twitter blog post by Roth and Harvey [67]. Nevertheless, according to some estimates [11, 66] bot and troll-like behaviour still remained rampant on Twitter. The Bot Sentinel project,Footnote 3 maintained a list of over 150 thousand active automated troll accounts. As of latest available analyses, despite various claims and measures taken, bots remain extremely and arguably more prevalent than ever on Twitter/X [37, 84].
Bots, trolls and malicious automation
Lynn et al. [53] point out that especially in health related conversations, bot activity matters, “the trustworthiness and credibility of [users] should play a role and, where one’s health and well-being is at stake, it is not irrational to suggest that this role should be significant” (p.18). A number of studies have been conducted on health-related tweeting behaviours displayed by bots and trolls prior to the pandemic. Broniatowski et al. [14] examined bot and troll behaviours on Twitter in the context of vaccinations. Their (ibid.) findings showed that both trolls and bots posted more antivaccine content than average Twitter users. They (ibid.) define trolls as Twitter accounts that are operated by humans who misrepresent their identities and exhibit malicious behaviours. Bots, however, are broadly defined as automated accounts [14]. Iyengar and Massey [43] describe a troll as an “actor who uses social media to start arguments, upset people, and sow confusion among users by circulating inflammatory and often false information online” (p.7657). Sutton [77] warned that there is emerging empirical evidence of how bots and trolls influence social media conversations about public health. Besinque [11] also points out the prevalence of bots and trolls on social media, warning that the field of medicine is particularly impacted by “the spread of inaccurate, incomplete, or patently false health information” (p.7). Iyengar and Massey [43] attribute this increase in online mis/disinformation circulating in medical science to ambiguous funds that sponsor trolls and bots in order to create a climate of confusion and distrust. Similar findings regarding the spread of mis/disinformation of public health messages by bots on Twitter were reported by Jamison et al. [45], even in specific fields such as in dentistry [20]. More generally, a report entitled “Industrialised Disinformation” by Bradshaw et al. [13] at the Oxford Internet Institute, introduces so called “Cyber Troops”. These are effectively bots, semi-automated, or human operated content farms, spreading harmful content for various governments or government-linked operators online. Bradshaw et al. (ibid.) point out that many bot accounts seem to be human orchestrated,operated by humans with a level of automation to help push out their content at scale. In our methodology, Sect. “Bot detection”, we elaborate on how we operationalise the definition of a bot for the purposes of this study.
Coronavirus COVID-19 Twitter studies
Early in the pandemic, Ferrara [28] examined the conspiracies circulated about the Coronavirus on Twitter by bot accounts. Their findings show that bot accounts generated conspiracies around COVID-19 in the period between February and March, concluding that these automated accounts were used maliciously. In line with prior research, Yang et al. [101] found that suspected bots in particular were actively involved in amplifying tweets containing low-credibility links about the Coronavirus during the analysed time period around March 2020. Kouzy et al. [52] manually examined a random sample of 673 tweets (with up to five retweets per tweet) collected in February 2020 and found that early on, 153 tweets (24.8%) included misinformation, and 107 (17.4%) included unverifiable information about COVID-19. Sharma et al. [69] used fastText [46] for topic modelling to provide a dashboard of misinformation topics spreading on Twitter about the pandemic. They (ibid.) also applied sentiment analysis using VADER [35] on prevailing topics and found that “social distancing” and “working from home” generated more positive than negative sentiment and observed a spike in newly created accounts tweeting about the pandemic. Budhwani and Sun’s [16] research took a different angle, they examined Twitter discourse around the virus after President Trump referred to it as the “Chinese virus”. They emphasise the emergence of stigma from negative health related outcomes. Beyond studies focusing on the early time period of the pandemic, several studies of social media-use during the pandemic have since investigated a broad range of issues, from discourse around COVID-19 mental health issues [92], loneliness during quarantine [50], to the continued spread of misinformation [38]. Account automation and bot behaviour throughout COVID-19 has received some initial attention, and we now know that bots play a role in posting and amplifying low-credibility information [101], populating social media with a range of conspiracy theories [28, 34], with evidence of coordinated sharing [102], and potential state-actor involvement in such activities [15, 43]. More recently, work by Zhang et al. [104] focused on the topics communicated by bots and humans across Twitter, finding that public health news were dominant across bot accounts, while humans were tweeting more about individual health and their daily lives. The authors (ibid.) suggested that bots were constructing an “authoritative” image over time by posting a lot of news, which in turn gains attention and has a significant effect on human users. However, Zhang et al. [104] only studied a small 56,897 tweet convenience sample across seven days from January 2022, and as most other prior work did not investigate the role of affective nor emotional language use.
Hence, what remains largely unclear is the extent to which specific emotions and affective language was leveraged by automated bots throughout the initial period of the pandemic. Beyond basic sentiment analysis, no other research to date has explored the use of specific emotions by bots during the pandemic or how emotional content compares between human and suspected bot accounts. Only general observations off Twitter bots being employed to instil confusion around health-related topics have been made [14, 25, 43, 71],and while there is emerging evidence that bots and inauthentic accounts explicitly leverage emotional language and emotional strategies over time in order to manipulate discourse and perceptions on social media [61], the work only looked at the US 2016 presidential elections and employed simplistic positive/negative sentiment measures. Hence there is a distinct and pressing need for research to expand understanding of emotion-driven bot behaviour during the pandemic.
Methods and analysis
The studied dataset consists of a sample of over five million tweets posted during 31st January to 26th March 2020 that contains any mention of the term “Coronavirus” on Twitter during this time period. The term and this period align with the key initial timeline of the disease spreading across the globe, as documented and archived by Nature [59]. A mixed methods approach was employed in this study, to provide further nuance in understanding the content and to ensure accuracy. We primarily leveraged three automated machine learning and semantic approaches to detect, (i) emotional language, (ii) expressions of stress-bearing language, and (iii) bot assessment of user accounts and their past tweets. In order to provide a level of face validity to ensure accuracy and qualitative appreciation for the tweet texts, as per recommendations by Kim et al. [49] and Sykora et al. [79], we also took uniform random samples across the various dimensions detected from i–iii, for further manual qualitative inspection of the communicated content.
Data collection
The dataset was collected live, using the official Twitter REST API (GET /1.1/search/ endpoint), following their terms of service at the time, as well as the official Twitter developer guidelines best practice, with only public and consented tweets being included in our analysis. To minimise any self-selection bias stemming from the selection of hashtags, as previously detailed by Tufekci [88], we selected the case-insensitive broad search term “Coronavirus”. In total 5,647,004 tweets by 2,320,405 users were collated. Since our focus is on most active accounts that are likely shaping the discourse on Twitter, similarly to Lynn et al. [53] and Marlow et al. [55], we have further filtered this dataset to users who tweeted at least 10 times. This resulted in 2,039,977 tweets by 79,726 users, which also represents a feasible amount of users to be assessed with the bot detection tool, as this is a resource intensive process (see Sect. “Bot detection”). All tweets were filtered for English language tweets only, as the applied analytics methods are language specific (see Sect. “Detecting discrete emotions and stress expressions”).
The early continuous time period between Friday 31st January to Thursday 26th March 2020, represents exactly eight continuous calendar weeks and accounts for day-of-the-week variation in posting [97]. This period covers 55 days of the Coronavirus pandemic and was chosen for several reasons. During this time there was much initial deliberation concerning the emerging pandemic, which for the same reason was also the focus of related research [28, 56, 105]. As subsequent global and local events, and public policy implementations emerged throughout 2020 and 2021, a multitude of themes and topics oversaturated the Twitter stream, while interest groups and other actors increasingly entered these conversations [55]. Hence, the early months of the emergence of the virus provide for an authentic, potentially less noisy, and suitable time period for our study. Especially given findings by Marlow et al. (ibid.) that show how bots are more likely to participate in Twitter discourse during subsequent time periods following major events, we were interested in organic levels of bots, in order to assess the immediate differences in affective communication. Research by Asur et al. [2] shows that trending topics are discussed on social media profusely for a short time before they fizzle out, and we therefore aimed to capture tweets when the term “Coronavirus” was trending on Twitter. Indeed, retrospectively, we note that the broader online landscape as captured by Google Trends (including all Google search based platformsFootnote 4), happens to also represent a key growth and peak-use of “Coronavirus” as a term, during the time period under study. It is also envisaged that studying the early time frame will provide more relevant insights to help preparedness at the early stages of future infodemics. In the interest of reproducibility, the dataset is provided to other researchers in the form of tweet-IDs on OSF,Footnote 5 with links to related COVID-19 archived datasets that might also be useful to researchers.
Detecting discrete emotions and stress expressions
We employed the EMOTIVE advanced sentiment detection system [19, 78] that looks for words, phrases and patterns of phrases to detect expressions linked to eight basic emotions, anger, confusion, disgust, fear, happiness, sadness, shame and surprise. This system is based on an extensive and validated semantic model which has been designed for the sentiment analysis of Big Data (e.g., social media data, blogs, etc.). EMOTIVE also employs statistical word sense disambiguation to improve the precision of emotion scores. We also considered related methods from [64], such as VADER [35], however, since in RQ2 we are interested in specific emotions rather than broad positive and negative sentiment, EMOTIVE was judged to be most suitable. This state-of-the-art tool allows us to differentiate fear and disgust from other negative emotions, including low arousal emotions such as sadness and shame and can detect multiple emotions within one social media post. High arousal negative emotions specifically were shown to be most relevant and of consequence in behavioural choices during health crises [95]. Besides measuring the emotionality of tweets, sentiment analysis tools generally neglect closely related affective states such as psychological distress. Hence, we also employed the recently released Stresscapes tool [27], which is an automated approach similar to EMOTIVE, for the targeted detection of word use and expressions linked to psychological distress. The system was found to perform well (in terms of recall and precision) on this task (ibid.). In sum, both tools together provide nine numerical scores representing the strength of emotional and stress expressions contained in a single tweet.
Bot detection
To detect fully or partially automated accounts (i.e., Bots) on Twitter, we utilised the widely adopted BotometerFootnote 6 (API, v.3) machine learning bot detection tool [100] that was popular at the time. Although it has been offline since the acquisition of Twitter by Musk, at the time of conducting our research, this tool used a state-of-the art Twitter bot detection approach, which was based on a random forest model and was the culmination of numerous years of development stemming from a winning system led by Indiana University at the DARPA bot detection competition [76]. The approach considered over 1000 features of a user’s account, such as profile description, Twitter joining date, social network measures, while also requiring some amount of recent tweet history (usually up to 200 past tweets) to incorporate tweet content and temporal patterns of tweeting. A range of the features used by Botometer, have similarly been used successfully in social media user spam detection approaches [1], p. 65). Since this was a data intensive task, there were further demands on time and resources in assessing large quantities of accounts, as it requires rate limited Twitter API calls, in addition to querying the Botometer API itself. Due to this constrain we selected users who tweeted at least 10 times in our 5.6 million tweet dataset. This was a common practice [53, 55] that allowed us to understand users that drive content generation on Twitter, although we do acknowledge some specific limitations of this approach in Sect. “Discussion”. As is usually the case with social media, a fairly small proportion of users is often responsible for a large proportion of content. Taking users who tweeted 10 or more times, resulted in 79,726 users, that is only 3.44% of all users, while these were responsible for as many as 36.13% of all tweets. The threshold of 10 was chosen as we wanted to ensure that a substantive proportion of overall discourse, at least a third of all tweets posted, was linked to the selected users. Since we considered a set time-window for our analysis period, a user posting 10 tweets in the span of 2 days in the data set would be considered equally active as a user that posted 10 tweets over the entire timespan considered.
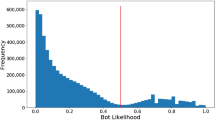
Botometer produced a bot likelihood score, as well as six subscores (e.g., social network, timing…, see [94]) to help identify which features contributed most to the overall account automation score. The developers at Indiana University recommended using a threshold of 0.5 on the scores when a binary bot classification is needed [70, 94, 101] and is commonly used in related work (e.g., [104]), although lower scores (0.3–0.4) have been often used too (e.g., [55]). Since only English tweets were filtered, we employed the language specific overall score for more accurate Botometer estimates to detect bots. To detect semi-automated or “suspicious” bot like behaviour, we threshold at 0.5 for any of the six subscores, in line with Sykora et al. [81] and a qualitative inspection of example accounts with such subscores. These subscores are directly linked to Botometer’s Random Forest model, where they form six categories of input features out of over 1000 input features [94], pp. 281–282), that their model was trained and evaluated on, and hence they are linked to the likelihood of an account being automated. This effectively meant that accounts, which had at least one substantive suspicious aspect about their behaviour would have been considered as signalling partial bot automation, which as Bradshaw et al. [13] show is an increasingly common phenomenon, where lower levels of automation are used with some level of human management and curation of the content (ibid., p.11). Lynn et al. (53, p.5) refer to such bot-assisted human or human-assisted accounts as “cyborgs”, while in our study we also consider such partial automation to be an important aspect of scalable account automation. It is important to note that accounts detected in this way were not necessarily fully automated bots, but rather also included accounts that were likely to be partly automated, as per Botometer’s model. Our own manual qualitative inspection revealed that across such accounts there was indeed obsessive, repetitive or suspicious behaviour, which was observable by a trained social media discourse analyst (one of the co-authors).
Results
Out of the 79,726 users, a total of 77,432 users were successfully assessed with the Botometer tool (these having tweeted 1,980,590 tweets in total), with Fig. 1 illustrating the overall data collection and filtering process. Hence, within the two week time period it took to retrieve additional timeline tweets for each user and to run Botometer, 2273 accounts were either suspended, deleted or switched from public to private profiles, while 21 accounts were empty (all tweets were deleted). The deleted tweets potentially also indicate content that was removed by Twitter as it may have been deemed inappropriate by their community standards, although this distinction was not possible from the API provided response data. Tweet deletions are sometimes used in manipulative ways, and while this is beyond the scope of our study, such behaviours have been explicitly investigated in prior research [86].

Overview of our data collection and data filtering process
From the 77,432 users assessed with Botometer, 12,046 accounts (15.56%) were classified as bots, which is a very high proportion of automated behaviour. This is considerably higher than the 6% bots reported by Shao et al. [70] and at the upper range of the 9–15% reported by Varol et al. [94].Footnote 7 In terms of top accounts driving the content posting, taking the top ranked 20 most active accounts (by tweet count, and these being responsible for 24,537 tweets) contained twice the proportion of bots. Out of top 20 users, 6 (30%) were classified as bots, while two further accounts have been suspended by Twitter. This finding is in line with Lynn et al. [53] who reported 35% (7 out of 20 most active) users being automated bots on a healthy dieting related Twitter dataset. Leveraging the Botometer subscores (see subsection “Bot detection”) resulted in classifying as many as 37,277 (48.14%) accounts from all Botometer assessed users as having some aspect of bot-like behaviour and hence being potentially partly automated. This is in line with some previous suggestions (e.g., [94]) of likely considerably higher proportions of partially automated accounts on platforms such as Twitter, although it is notoriously challenging to discern these accounts accurately at scale, from highly active human users. Relying on the subscores from Botometer, as many as 15 accounts (75%) were classified as likely semi-automated accounts out of the top 20 active users. Figure 2 illustrates the distribution of proportion of stress and emotions containing tweets across tweets of the 20 top ranked users, with stress and fear language being used most frequently.Footnote 8

Proportion of stress and emotion tweets for each of the 20 top ranked users (x-axis: affective expressions; y-axis: proportion of twets per user; triangle: potential bot; circle: human)
The prevalence of emotions and stress across all 1.9 million tweets posted by the 77,432 Botometer assessed users was found to be highest for stress (151,535 tweets), followed by fear (29,494), sadness (23,828), and surprise (11,847). Figure 3 outlines the prevalence of stress and all measured emotions, broken down by (i) whether the tweet was posted by a likely bot or a likely human account,Footnote 9 and (ii) whether the tweet was an original message or a re-tweet further spreading an already existing affective message.

Prevalence of stress and emotion across all the 1.9 million tweets with error bars highlighting 95% confidence intervals from 1000 bootstraps (x-axis: affective expressions, y-axis: proportion of tweets, left-panel: original tweets, right-panel: re-tweets)
From Fig. 3 it is evident that stress dominated both, original as well as re-tweeted messages, though there were also indicative yet substantial differences between bots and humans. To assess the uncertainty of these measurements, similarly to Garcia and Rimé [32], we calculated 95% percentile confidence intervals (Cis) on the affective measures from 1000 generated bootstrapped samples (of the 1.9 million tweets) in each type of account (i.e., suspected bot and humans) and tweet type (i.e., re-tweet and original tweet).Footnote 10 Table 1 summarises the CIs and highlights the degree to which they differ and where these overlap across bot and human posted affective content. This analysis confirmed that stress was tweeted much more frequently by humans in original messages (on average, a difference of at least 1.187% overall prevalence), while bots were considerably more likely to re-tweet stress containing messages than humans (at least by 0.759%). The prevalence of sadness in original messages by humans was also significantly and substantially higher than posts by bots (0.607%), while the difference in sadness among re-tweets was not found to be significant (i.e., the 95% percentile Cis overlapped). Happiness, disgust, and surprise also show substantially higher prevalence among human posted content, given by the upper bot and lower human CI differences, 0.239%, 0.233% and 0.148%, respectively (see Table 1). However, bots were more likely to re-tweet fear compared to human accounts (0.058%). Although variations across the remaining emotions and tweet types are negligible (see rows below the bold line in Table 1), some of these still show significant differences.
A noteworthy conclusion from this analysis is that bots were more likely to re-tweet affective content at higher proportions than in original tweets, compared to human accounts; with stress and fear showing most substantial differences for suspected bots. While Table 1 and Fig. 3 illustrate how human accounts always tweeted higher proportions of affective content across original tweets, in particular stress, sadness, happiness, disgust and surprise, the remaining emotion differences were relatively small and not significant. Nevertheless, the overall activity of automated accounts leveraging affective language was especially high for re-tweets in general, which highlights the potential role bots have in amplifying affective content.
Following the approach in Kim et al. [49] and Sykora et al. [79], a manual qualitative examination of a random sample of tweets that contained emotive and stress-related expressions for both bot and non-bots proved further insightful. We chose 10 bots and 10 humans per negative emotion and stress-related expressions (20 tweets per each emotion and the stress expression; 180 tweets in total).Footnote 11 The assumingly human generated content that expressed emotions or anxiety related to the Coronavirus used loaded terms such as “apocalyptic” and “awful” to describe the virus itself and terms such “panic” and “disgusting” to describe mainstream medias’ responses to it. There were some openly racist tweets around the origins of the virus using expressions such as “sickening”. Upon examining the automated bot tweets, the language was not particularly visibly different, with terms such as “disgusting” and “sickening” frequently appearing in the dataset. Out of a random sample of 10 bot tweets for the emotion disgust, 3 were tweets stating that COVID-19 was a biological weapon, 3 tweets expressed disgust that President Trump was being criticised, and 2 were tweets praising President Trump’s response to the virus. Examining the sample for the emotion of fear, there were clear differences between tweets generated earlier and later throughout the captured period. Earlier tweets referred to the Coronavirus as a “scare” hence the high count for “fear”, however the human generated tweets posted later in the study period included expressions such as “prepare for the panic”Footnote 12 or “so sad”. Accounts that were classified as bots by Botometer seem to have begun making light of the pandemic—for example stating that “more people have died from the flu”, or “fear is spreading faster than the virus”. Nevertheless, given the fairly small qualitative sample size, these results are meant to be indicative, providing only some qualitative appreciation for the posted content.
Discussion
In this study we found evidence of emotional and stress-bearing messaging were being extensively used by potentially manipulative automated accounts in the early months following the emergence of the virus. We employed established automated methods to detect bots and measure the prevalence of emotions and stress-related expressions generated by three categories of accounts; fully automated bot accounts, semi-automated bot accounts, and human accounts. Our findings demonstrate that the prevalence of automated bot-like accounts is high (RQ1), ranging from 15.56 to 48.14% of all assessed accounts being at least partly automated. These are higher proportions of bots than some previously reported across large scale Twitter datasets [53, 70, 94], though align more closely with Zhang et al. [104]. Fear and sadness were found to be the most frequent emotions, with some difference in the qualitative aspects of emotional language use, and while we found bots tweeting comparably similar levels of emotional content as human accounts, significant differences were observed across original tweets and re-tweets (RQ2). We also observed a pronounced and significant prevalence of bot like accounts re-tweeting messages containing stress, while original tweets posted by humans were more common (RQ3). This highlights the role bots likely have in amplifying negative affect-bearing content in general. There is some evidence [92] that the effects of the psychological and emotional toll that the pandemic has had on us will remain with us for several years to come. The decrease or loss of income are a cause of stress, anxiety and/or depression [68], and Horesh and Brown [40] have already shown that the traumatic stress caused by the uncertainty surrounding fear of the future due to COVID-19 pandemic will have long lasting effects. In an already frightening and stressful time, we have observed that bots on Twitter are further fuelling these emotions by tweeting content containing stress-bearing language. Therefore, this study aimed to understand the early Twitter discussions around the Coronavirus pandemic and the (particularly negative) contribution bots made to the Twitter rhetoric.
More generally, the design, prevalence and potential impact of automated accounts interfacing with social information systems, such as the Twitter API platform for large scale account automation, especially systems that facilitate public opinion, conversations and audience attention to be shaped in a profound manner, is naturally quite worrisome. As Starbird [73] points out, holistically measuring and modelling the impact of manipulative automated behaviours will remain an ongoing challenge for the coming years, while it is becoming increasingly clear that the issues centre not only around the scale and speed at which automated bots can interfere and push out content, but also the potential manipulative nature of emotional and highly charged messaging in such settings. Although the platform has seen many changes since its acquisition, at the time of the data collection, Twitter represented a fairly open and public platform for information exchange [88], and by the very nature of its userbase during the time of the pandemic, this included news agencies, journalists and influential elites from all walks of life, as well as bots and semi-automated accounts. This environment created an information market where attention and engagement are the primary currency [23, 106, 107], while the role of emotions especially in politicised topics might be of key significance [5]. Since emotions have been shown to foster engagement [95, 96], Bakir and McStay’s [5] description of emotions as a “valuable commodity” in mis/disinformation is particularly significant within the context of the pandemic. Although this was not the focus of our study, content around the COVID-19 virus that generated heightened emotions was likely to increase attention and viewing times [95], and in turn more generally advertising revenue [56, 60, 107]. This conceptual idea of information markets implies that regulation and/or transparency may provide useful levers to help address some of these issues (ibid.). We discuss this further in the Sect. “Conclusion and future work” on future work.
Limitations
Any analysis of social media content ought to be interpreted with some caution and the approaches that rely on such data have their limitations [47]. There are issues around demographics, for instance a study on UK users by Mellon and Prosser [57] found that Twitter users did not reflect the British population accurately. Primarily due to feasibility constraints discussed in Sect. “Bot detection”, we selected a subset of users that tweeted at least 10 times in the collated dataset of tweets containing the term “Coronavirus”. This focuses our analysis on users that were overall more highly engaged with the topic. This may potentially introduce bias that could impact the likelihood of bots or human-driven accounts having been selected, and hence inadvertently omitting certain accounts that may well be tweeting highly charged emotional content. Although all three tools employed (Botometer, EMOTIVE and Stresscapes) have been validated in prior peer reviewed work, as is generally the case with automated methods, there is some potential for false positives and false negatives to occur. Relying on the Botometer subscores to classify accounts as bots may well miss-classify legitimate human users that simply happen to display an element of highly intense or suspicious bot-like behaviour on Twitter. Hence the subscore based high estimates ought to be interpreted with some caution and are strictly only indicative of potential partial automation, although extreme values across similar features have been consistently identified to be indicative of non-authentic user accounts [1]. This automation detection approach might have at times detected organisational accounts (that often use publishing software) and other false positives, and while the approach is still noteworthy and useful, we fully acknowledge that the classification of bots is a broadly challenging issue and refer the interested reader to a dedicated paper on this by Varol et al. [93]. Further research across different datasets, as well as more extensive qualitative assessments, including the study of specific events and behaviours across time, are needed, and welcomed. In spite of these limitations, we believe this study takes important steps towards framing the problem of automated accounts, steering the trending conversations on social media and towards an improved empirically informed understanding of the scale and scope of the issues we face with automated affectively charged bot content. We believe that X and other social media platforms should open their APIs to researchers to allow such valuable research to be conducted in order to study malicious behaviours of trolls, bots and other types of automated accounts that may be pushing out harmful content.
Conclusion and future work
Our study contributes to existing work on bot behaviours on social media in several ways, by examining the affect-bearing content that bots have generated during the early months of the Coronavirus pandemic. The main finding that bots and semi-automated accounts tended to use expressions that convey stress and emotions at high levels comparable to human accounts is noteworthy. This could be explained either by the simple observation that automated accounts are part of the social network on the platform and often re-tweet existing content that fits certain narratives as hypothesised by [39], although we did find higher levels of stress and fear containing re-tweets by bots. Alternatively the use of affect by bot accounts could be explained by automated accounts wanting to appeal to the platform audiences with highly emotional content in an attention information market [23, 107] for instance for purposes of persuasion and engagement as highlighted in Van Bavel et al. [95], or that bots want to ultimately fit in to avoid detection by using emotions as a means of helping to achieve that [73]. Either of these may be the case and is currently unclear and will require further study of the motives and drivers behind automated accounts use (although efforts such as [13], are noteworthy in this regard). Our study is also one of the first to include the important distinction between suspected bots and suspected semi-automated bots, where the latter may have partial automation otherwise driven and orchestrated by humans, as well as how we have operationalised this using a widely used tool in the literature (i.e., Botometer).
We envisage two primary ways forward in more effectively countering the here described bot behaviours. First, there is undoubtedly some onus of responsibility on Twitter as a platform facilitating automated behaviours to provide an easily discernible indication of which accounts are fully or partially automated. As of writing, all Twitter API interactions must be authenticated at application level (optionally also at a user level) and hence Twitter’s platform can indeed keep track of scripted automated behaviours. An unambiguous and systematic labelling system for automated and semi-automated accounts, whether malicious or not, would improve much needed transparency. Others have also called for action, including Im et al. [41], Marlow et al. [55], and Bradshaw et al. [13] in their “Cyber Troops” report, all call on Twitter to take responsibility for reporting and curating such automated behaviours, pointing out that the social media platforms should provide a level of transparency around account automation. Before Elon Musk’s takeover, Twitter seemed to have been reacting to these sporadic calls for action, and in a 2020 December blog post (Twitter [91]) announced that they would, later throughout 2021, consider introducing visible bot markers to user-accounts, similar to current validation blue ticks. This was a promising development, but as of writing (early 2023), this commitment has simply not materialised in any meaningful way. Even Elon Musk’s takeover of Twitter has only led to minor changes of contested benefit [4], while unfortunately some transparency regarding provenance has been removed altogether (i.e., the source information was removed, that is a marker of what software was used to post a tweet), additional information about the account (i.e., whether it is a business, government, paid verification or unknown) is being added [62]. Bots also remain extremely prevalent on the platform according to the work conducted by Timothy and FitzGerald [37]; see also Taylor [84]. The newly introduced Twitter Blue subscription based payment verification costing around $8 per month, has been controversial and initial evidence points towards a substantial proportion of subscribers being suspicious in their behaviour, with our own analysis of the publicly available Twitter Blue tracker dataset (see https://github.com/travisbrown/blue) showing for instance that 12,038 accounts only had 5 or less followers, with 2679 paying accounts having 0 followers, as of May 2023.
Currently, it is also unclear how Twitter would address semi-automated behaviours and the specific characteristics of any planned bot account labelling. Second, promising work by Mønsted et al. [58] illustrates the potential of automated behaviours being used in positive ways to spread information, and in a call for action to computational and information systems scientists, Ciampaglia [18] proposes such automation to be deployed in countering dis/misinformation at scale—“good bots”. Specifically, regarding the COVID-19 pandemic, Pennycook et al. [63] have shown in an experimental study how a simple accuracy reminder when judging headlines, introduced once, nearly tripled the level of truth discernment in participants’ subsequent sharing intentions. Hence, automated strategies that provide simple nudging reminders, and use an emotionally charged tone as shown by Trevors and Kendeou [87], may be highly effective in helping to curb the spread of inaccurate information around COVID-19 and health related topics. The issue with fact checking has been that once news is assessed as false, it has already garnered and often keeps receiving substantial engagement and attention [18], which is why the above approach may be more effective on already exposed users. Importantly, both proposed ways forward are not only Twitter specific but apply to a range of platforms, including Reddit, Facebook and Pinterest.
With respect to the practical implications stemming from our findings, practitioners must now contend with a reality where bots mimic human emotional expressions in their posts, and their role in amplifying specific content types, especially those bearing negative affect. This understanding is crucial when strategizing communication campaigns or assessing online sentiment, as it brings to light the potential skewing of perceived public sentiment by automated entities. Practitioners need to employ advanced tools and methodologies to discern genuine organic sentiment from bot-driven narratives. The pronounced role of bots in amplifying negative emotional content, even if they mimic human-like emotional expressions, also points to the urgent need for enhanced bot-detection and content moderation mechanisms across platforms, beyond just Twitter. Ensuring that genuine human discourse is not overshadowed or manipulated by automated entities is paramount to maintaining platform credibility and user trust.
Data availability
The R-code and data from our analysis and base underlying social media data is available to other researchers, on reasonable request.
Notes
Twitter was rebranded to X since July 2023 (see https://en.wikipedia.org/wiki/Twitter#Rebrand_to_X). Since our study was conducted during the times of the Twitter branded platform, for simplicity we refer to X as Twitter throughout this article.
Twitter/X users can post “tweets” which are 280-character messages, publicly tweet at others (tweet @mentions), reply to tweets within tweet threads, follow other users as well as be followed by others, and it also allows users to present their identity via a fairly simple profile, using a custom profile picture, nickname and description, among some other profile customisation settings. Other actions with high public visibility include re-tweeting and favouriting tweets, which in turn are employed by Twitter/X’s black-box algorithms to populate popular content across users’ timelines, hence instrumental in driving the exposure of tweets across Twitter/X’s userbase.
Bot Sentinel Project, see https://help.botsentinel.com/support/home
Google trends has been similarly used in the past as a helpful corroborating indicator for broad public term popularity by other studies looking at Twitter content (e.g., [104]). It captures overall online usage of particular search terms, see this link for the specific time-period in question https://trends.google.com/trends/explore?date=2020-01-01%202020-05-31&q=Coronavirus&hl=en-GB.
Tweet IDs are 18–19 long numeric IDs, e.g., 1,309,183,054,317,981,696. These tweet-IDs need to be subsequently rehydrated, where rehydration is a simple process involving sending requests to the official Twitter API /statuses/lookup endpoint with tweet-IDs uniquely identifying a tweet, and Twitter responding with the tweet and metadata. This ensures that in case a user has set their account to private or deleted their tweet, effectively withdrawing consent, their tweet would no longer be available for analysis. This allows us to share tweets in line with Twitter’s terms of use and while respecting user privacy (see https://osf.io/u5y9m/). Nevertheless, unfortunately Twitter/X has now made access to the API quite costly, and the extent of reproducibility may hence be limited in this regard, please see their current available API access levels at https://developer.twitter.com/en/portal/products.
See Botometer website https://botometer.iuni.iu.edu
This is a high proportion in context of previous baseline of emotional language use across large tweet datasets (e.g., Sykora et al., 2014).
Here we classified accounts based on the Botometer subscores, however, we have also classified and run this comparison based on the overall Botometer scores, finding no significant differences in the distribution. This indicates that automated bots and semi-automated bots both have a tendency to tweet highly affective content, at least in the assessed dataset, which we consider to be representative of Coronavirus discourse in the early stage the pandemic.
The bootstrapping samples were generated using the rsample R library’s bootstraps() function, and int_pctl() function for calculating the percentile confidence intervals. The complete R code used in bootstrapping, and for generating all figures and the table, as well as the bootstrapping estimates from the 1,000 bootstraps themselves, are available at https://osf.io/u5y9m/.
The R code used to generate this random stratified sample is also available at https://osf.io/u5y9m/.
Some tweets have been paraphrased to shorten the text while keeping the main message intact.
References
Al-Zoubi, A. M., Alqatawna, J. F., Faris, H., & Hassonah, M. A. (2021). Spam profiles detection on social networks using computational intelligence methods: The effect of the lingual context. Journal of Information Science, 47(1), 58–81.
Asur, S., Huberman, B. A., Szabo, G., & Wang, C. (2011). Trends in social media: Persistence and decay. 5th ICWSM International AAAI Conference on Web and Social Media, Barcelona, Spain.
Arnold, M. B. (1967). Stress and Emotion. Psychological. Stress, 4, 123–140.
Barrie, C. (2022). Did the Musk Takeover Boost Contentious Actors on Twitter?. arXiv preprint arXiv:2212.10646.
Bakir, V., & McStay, A. (2018). Fake news and the economy of emotions: Problems, causes, solutions. Digital Journalism, 6(2), 154–175.
Balakrishnan, S., Elayan, S., Sykora, M., Solter, M., Feick, R., Hewitt, C., Liu, Y. Q., & Shankardass, K. (2023). Sustainable smart cities—Social media platforms and their role in community neighborhood resilience—A systematic review. International Journal of Environmental Research and Public Health, 20(18), 6720.
Barbalet, J. (2001). On the origins of human emotions: a sociological inquiry in the evolution of human affect.
Barbalet, J. (2006). Emotion. Contexts, 5(2), 51–53.
Benkler, Y. (2019). Cautionary notes on disinformation and the origins of distrust, MediaWell: Expert reflection. Available at: https://mediawell.ssrc.org/expert-reflections/cautionary-notes-on-disinformation-benkler/ . Accessed: 20 Jan 2020.
Bennett, W. L. (2012). The personalization of politics: Political identity, social media and changing patterns of participation. The ANNALS of the American Academy of Political and Social Science, 644(1), 20–39.
Besinque, G. (2019). Keeping it real in the era of bots and trolls. Journal of Contemporary Pharmacy Practice, 66(1), 7–8.
Boyd, R. L., & Pennebaker, J. W. (2017). Language-based personality: A new approach to personality in a digital world. Current opinion in behavioral sciences, 18, 63–68.
Bradshaw, S., Bailey, H., & Howard P.N. (2020). Industrialized disinformation: 2020 Global Inventory of Organized Social Media Manipulation. Oxford Internet Institute, Available at: https://comprop.oii.ox.ac.uk/research/posts/industrialized-disinformation/. Accessed 10 Jan 2021.
Broniatowski, D. A., Jamison, A. M., Qi, S., AlKulaib, L., Chen, T., Benton, A., Quinn, S. C., & Dredze, M. (2018). Weaponized health communication: Twitter bots and Russian trolls amplify the vaccine debate. American Journal of Public Health, 108(10), 1378–1384.
Broniatowski, D. A., Kerchner, D., Farooq, F., Huang, X., Jamison, A. M., Dredze, M., & Quinn, S. C. (2020). The covid-19 social media infodemic reflects uncertainty and state-sponsored propaganda. arXiv preprint arXiv:2007.09682.
Budhwani, H., & Sun, R. (2020). Creating COVID-19 stigma by referencing the novel coronavirus as the “Chinese virus” on Twitter: Quantitative analysis of social media data. Journal of Medical Internet Research, 22(5), e19301.
Cacioppo, J. T., & Gardner, W. L. (1999). Emotion. Annual review of psychology, 50(1), 191–214.
Ciampaglia, G. L. (2018). Fighting fake news: a role for computational social science in the fight against digital misinformation. Journal of Computational Social Science, 1(1), 147–153.
Chen X., Sykora M., Elayan, S., Jackson, T.W., & Fehmidah, M. (2018). Tweeting your mental health: Exploration of different classifiers and features with emotional signals in identifying mental health conditions, 51st HICCS Hawaii International Conference on Computer Systems, Hawaii, USA.
da Silva, M. A. D., & Walmsley, A. D. (2019). Fake news and dental education. British Dental Journal, 226(6), 397–399.
Dalgleish, T. (2004). The emotional brain. Nature Reviews Neuroscience, 5(7), 583–589.
Davidson, R. J. (1992). Prolegomenon to the structure of emotion: Gleanings from neuropsychology. Cognition & Emotion, 6(3–4), 245–268.
Davenport, T. H., & Beck, J. C. (2002). Attention economy: Understanding the new currency of business. Harvard Business Review Press.
Dredze, M., Broniatowski, D. A., & Hilyard, K. M. (2016). Zika vaccine misconceptions: A social media analysis. Vaccine, 34(30), 3441.
Edry, T., Maani, N., Sykora, M., Elayan, S., Hswen, Y., Wolf, M., Rinaldi, F., Galea, S., & Gruebner, O. (2021). Real-time geospatial surveillance of localized emotional stress responses to COVID-19: A proof of concept analysis. Health & Place, 70, 102598.
Elayan, S., Sykora, M., & Jackson, T. (2020). “His Tweets Speak for Themselves”: An analysis of Donald Trump’s Twitter behavior. International Journal of Interdisciplinary Civic and Political Studies, 15(1), 119–127.
Elayan, S., Sykora, M., Shankardass, K., Robertson, C., Feick, R., Shaughnessy, K., Haydn, L., Jackson, T.W. (2020). The stresscapes ontology system: Detecting and measuring stress on social media, ECSM-2020—7th European Conference on Social Media, Larnaca, Cyprus.
Ferrara, E. (2020). What types of covid-19 conspiracies are populated by twitter bots? First Monday. https://doi.org/10.5210/fm.v25i6.10633
Ferrara, E., Varol, O., Davis, C., Menczer, F., & Flammini, A. (2016). The rise of social bots. Communications of the ACM, 59(7), 96–104.
Fischer, H. W., III. (1996). What emergency management officials should know to enhance mitigation and effective disaster response. Journal of contingencies and crisis management, 4(4), 208–217.
Galea, S. (2020). COVID-19 and Mental Health, Available at: https://www.bu.edu/sph/2020/03/20/mental-health-in-a-time-of-pandemic/. Accessed 20 March 2020.
Garcia, D., & Rimé, B. (2019). Collective emotions and social resilience in the digital traces after a terrorist attack. Psychological Science, 30(4), 617–628.
George, J. O., Elayan, S., Sykora, M., Solter, M., Feick, R., Hewitt, C., Liu, Y., & Shankardass, K. (2023). The role of social media in building pandemic resilience in an urban community: A qualitative case study. International Journal of Environmental Research and Public Health, 20(17), 6707.
Giachanou, A., Ghanem, B., & Rosso, P. (2021). Detection of conspiracy propagators using psycho-linguistic characteristics. Journal of Information Science, 49(1), 3–17. https://doi.org/10.1177/0165551520985486
Hutto, E., & Gilbert, C. (2014). Vader: A parsimonious rule-based model for sentiment analysis of social media text. 8th International Conference on Weblogs and Social Media (ICWSM-14), Ann Arbor. USA
Gil de Zúñiga, H., & Diehl, T. (2019). News finds me perception and democracy: Effects on political knowledge, political interest, and voting. New media & society, 21(6), 1253–1271.
Graham, T., & FitzGerald, K.M. (2023). Bots, fake news and election conspiracies: Disinformation during the republican primary debate and the Trump interview, Digital Media Research Centre, Queensland University of Technology, Brisbane, Qld., Available at: https://eprints.qut.edu.au/242533/ . Accessed 10 Nov 2023.
Gruzd, A., De Domenico, M., Sacco, P. L., & Briand, S. (2021). Studying the COVID-19 infodemic at scale. Big Data & Society. https://doi.org/10.1177/20539517211021115
González-Bailón, S., & De Domenico, M. (2020). Bots are less central than verified accounts during contentious political events. Available at SSRN 3637121.
Horesh, D., & Brown, A. D. (2020). Traumatic stress in the age of COVID-19: A call to close critical gaps and adapt to new realities. Psychological Trauma: Theory, Research, Practice, and Policy, 12(4), 331.
Im, J., Chandrasekharan, E., Sargent, J., Lighthammer, P., Denby, T., Bhargava, A., & Gilbert, E. (2020). Still out there: Modeling and identifying Russian troll accounts on Twitter. WebSci 20–0-12th ACM Conference on Web Science, Southampton, UK.
Imran, M., & Ahmad, A. (2023). Enhancing data quality to mine credible patterns. Journal of Information Science, 49(2), 544–564.
Iyengar, S., & Massey, D. S. (2019). Scientific communication in a post-truth society. Proceedings of the National Academy of Sciences, 116(16), 7656–7661.
Jadhav, V. (2020). Role of social media during lockdown on various health aspects. 6(4), 236–238.
Jamison, A. M., Broniatowski, D. A., & Quinn, S. C. (2019). Malicious actors on Twitter: A guide for public health researchers. American Journal of Public Health, 109(5), 688–692.
Joulin, A., Grave, E., Bojanowski, P., Douze, M., Jégou, H., & Mikolov, T. (2016). Fasttext. zip: Compressing text classification models. arXiv preprint arXiv:1612.03651.
Kar, A. K., & Dwivedi, Y. K. (2020). Theory building with big data-driven research—Moving away from the “What” towards the “Why.” International Journal of Information Management, 54(102205), 1–10.
Khan, A., Brohman, K., & Addas, S. (2021). The anatomy of ‘fake news’: Studying false messages as digital objects. Journal of Information Technology. https://doi.org/10.1177/02683962211037693
Kim, H., Jang, S. M., Kim, S. H., & Wan, A. (2018). Evaluating sampling methods for content analysis of Twitter data. Social Media + Society, 4(2), 2056305118772836.
Koh, J. X., & Liew, T. M. (2020). How loneliness is talked about in social media during COVID-19 pandemic: Text mining of 4,492 Twitter feeds. Journal of Psychiatric Research. https://doi.org/10.1016/j.jpsychires.2020.11.015
Kousta, S. T., Vinson, D. P., & Vigliocco, G. (2009). Emotion words, regardless of polarity, have a processing advantage over neutral words. Cognition, 112(3), 473–481.
Kouzy, R., Abi Jaoude, J., Kraitem, A., El Alam, M. B., Karam, B., Adib, E., et al. (2020). Coronavirus goes viral: Quantifying the COVID-19 misinformation epidemic on Twitter. Cureus, 12(3), e7255.
Lynn, T., Rosati, P., Leoni Santos, G., & Endo, P. T. (2020). Sorting the healthy diet signal from the social media expert noise: Preliminary evidence from the healthy diet discourse on twitter. International Journal of Environmental Research and Public Health, 17(22), 1–28. https://doi.org/10.3390/ijerph17228557
Madrigal, A. C. (2020). How to misinform yourself about the coronavirus. Available at: https://amp.theatlantic.com/amp/article/605644/ . Accessed 28 Jan 2020.
Marlow, T., Miller, S., & Roberts, J. T. (2021). Bots and online climate discourses: Twitter discourse on President Trump’s announcement of US withdrawal from the Paris Agreement. Climate Policy. https://doi.org/10.1080/14693062.2020.1870098
Matamoros-Fernández, A., Bartolo, L., & Alpert, B. (2024). Acting like a bot as a defiance of platform power: Examining YouTubers’ patterns of “inauthentic” behaviour on Twitter during COVID-19. New Media & Society, 26(3), 1290–1314.
Mellon, J., & Prosser, C. (2017). Twitter and Facebook are not representative of the general population: Political attitudes and demographics of British social media users. Research and Politics, 4(3), 1–9.
Mønsted, B., Sapieżyński, P., Ferrara, E., & Lehmann, S. (2017). Evidence of complex contagion of information in social media: An experiment using Twitter bots. PloS one, 12(9), e0184148
Nature. (2020). Coronavirus latest: Updates on the respiratory illness that has infected hundreds of thousands of people and killed several thousand, Available at: https://www.nature.com/articles/d41586-020-00154-w, https://doi.org/10.1038/d41586-020-00154-w . Accessed: 25 March 2020.
Palau-Sampio, D. (2023). Pseudo-media disinformation patterns: Polarised discourse, clickbait and twisted journalistic mimicry. Journalism Practice, 17(10), 2140–2158.
Park, S., Strover, S., Choi, J., & Schnell, M. (2021). Mind games: A temporal sentiment analysis of the political messages of the Internet Research Agency on Facebook and Twitter. New Media & Society. https://doi.org/10.1177/14614448211014355
Parack A. [@suhemparack]. (2023). A few recent updates to the #TwitterAPI v2 [Internet]. https://twitter.com/suhemparack/status/1611085481395224576 (2023 Jan 5, Accessed: 6 January, 2023).
Pennycook, G., McPhetres, J., Zhang, Y., Lu, J. G., & Rand, D. G. (2020). Fighting COVID-19 misinformation on social media: experimental evidence for a scalable accuracy-nudge intervention. Psychological science, 31(7), 770–780.
Ravi, K., & Ravi, V. (2015). A survey on opinion mining and sentiment analysis: Tasks. Approaches and Applications, Knowledge-Based Systems, 89(1), 14–46.
Ressler, K. J. (2010). Amygdala activity, fear, and anxiety: Modulation by stress. Biological psychiatry, 67(12), 1117–1119.
Ross, B., Pilz, L., Cabrera, B., Brachten, F., Neubaum, G., & Stieglitz, S. (2019). Are Social Bots a Real Threat? An agent-based model of the spiral of silence to analyse the impact of manipulative actors in social networks. European Journal of Information Systems, 28(4), 394–412.
Roth, Y., & Harvey, D. (2018). How Twitter is fighting spam and malicious automation, Available at: https://blog.twitter.com/official/en_us/topics/company/2018/how-twitter-is-fighting-spam-and-malicious-automation.html. Accessed: 15 April 2020.
Santiago, C. D., Wadsworth, M. E., & Stump, J. (2011). Socioeconomic status, neighborhood disadvantage, and poverty-related stress: Prospective effects on psychological syndromes among diverse low-income families. Journal of Economic Psychology, 32(2), 218–230.
Sharma, K., Seo, S., Meng, C., Rambhatla, S., & Liu, Y. (2020). Covid-19 on social media: Analyzing misinformation in twitter conversations. arXiv:2003.12309.
Shao, C., Ciampaglia, G. L., Varol, O., Yang, K. C., Flammini, A., & Menczer, F. (2018). The spread of low-credibility content by social bots. Nature Communications, 9(1), 1–9.
Shi, W., Liu, D., Yang, J., Zhang, J., Wen, S., & Su, J. (2020). Social bots’ sentiment engagement in health emergencies: A topic-based analysis of the COVID-19 pandemic discussions on Twitter. International Journal of Environmental Research and Public Health, 17(22), 8701.
Shu, K., Bhattacharjee, A., Alatawi, F., Nazer, T. H., Ding, K., Karami, M., et al. (2020). Combating disinformation in a social media age. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 10(6), e1385
Starbird, K. (2019). Disinformation’s spread: Bots, trolls and all of us. Nature, 571(7766), 449.
Statista. (2020). Global Social Media Ranking 2020 | Statistic. Available at: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ .Accessed: 08 July 2020.
Stieglitz, S., & Dang-Xuan, L. (2012). Political communication and influence through microblogging—An empirical analysis of sentiment in Twitter messages and retweet behavior, 45th Hawaii International Conference on System Sciences, Hawaii, USA, pp. 3500–3509. https://doi.org/10.1109/HICSS.2012.476
Subrahmanian, V.S., Azaria, A., Durst, S., Kagan, V., Galstyan, A., Lerman, K., ... and Menczer, F (2016) The DARPA Twitter Bot Challenge, IEEE Computer, 49(6), pp. 38–46
Sutton, J. (2018). Health communication trolls and bots versus public health agencies’ trusted voices. American Journal of Public Health, 108(9), 1281–1282.
Sykora, M., Elayan, S., Jackson, T. W., & O’Brien, A. (2013). Emotive ontology: Extracting fine-grained emotions from terse. Informal Messages, International Journal on Computer Science and Information Systems, 8(2), 106–118.
Sykora, M., Elayan, S., & Jackson, T. W. (2020). A qualitative analysis of sarcasm, irony and related# hashtags on Twitter. Big Data & Society, 7(2), 2053951720972735.
Sykora, M., Elayan, S., Angelini, L., El Christina Röcke, M., Kamali, E. M., & Guye, S. (2021). Understanding older adults’ affect states in daily life for promoting self-reflection about mental wellbeing. In G. Andreoni & C. Mambretti (Eds.), Digital health technology for better aging: A multidisciplinary approach (pp. 179–193). Springer International Publishing. https://doi.org/10.1007/978-3-030-72663-8_11
Sykora, M., Elayan, S., Hodgkinson, I. R., Jackson, T. W., & West, A. (2022). The power of emotions: Leveraging user generated content for customer experience management. Journal of Business Research, 144, 997–1006.
Tausczik, Y. R., & Pennebaker, J. W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of language and social psychology, 29(1), 24–54.
Taylor, S. E. (1991). Asymmetrical effects of positive and negative events: the mobilization-minimization hypothesis. Psychological bulletin, 110(1), 67.
Taylor, J. (2023). Bots on X worse than ever according to analysis of 1m tweets during first Republican primary debate, The Guardian: Tech, Available at: https://www.theguardian.com/technology/2023/sep/09/x-twitter-bots-republican-primary-debate-tweets-increase . Accessed 10 Nov 2023.
Time Magazine. (2020). Trump refashions himself as a wartime president. Available at: https://time.com/5806657/donald-trump-coronavirus-war-china/ . Accessed 19 Mar 2020.
Torres-Lugo, C., Pote, M., Nwala, A.C., & Menczer, F. (2022). Manipulating Twitter through Deletions. 16th ICWSM International AAAI Conference on Web and Social Media, Atlanta, USA.
Trevors, G., & Kendeou, P. (2020). The effects of positive and negative emotional text content on knowledge revision. Quarterly Journal of Experimental Psychology, 73(9), 1326–1339.
Tufekci, Z. (2014). Big questions for social media big data: representativeness, validity and other methodological pitfalls, Proceedings of the 8th International AAAI Conference on Weblogs and Social Media, Ann Arbor, USA.
Twitter. (2017). General Guidelines and Policies: Automation Rules, Available at: https://help.twitter.com/en/rules-and-policies/twitter-automation . Accessed 15 Apr 2020.
Twitter. (2020). Twitter Rules and Policies, Available at: https://help.twitter.com/en/rules-and-policies#twitter-rules . Accessed 15 Apr 2020.
Twitter Blog. (2020). Our plans to relaunch verification and what's next. Twitter Inc.—Official Blog, Available at: https://blog.twitter.com/en_us/topics/company/2020/our-plans-to-relaunch-verification-and-whats-next.html . Accessed 17 Dec 2020.
Valdez, D., Ten Thij, M., Bathina, K., Rutter, L. A., & Bollen, J. (2020). Social media insights into US mental health during the COVID-19 pandemic: Longitudinal analysis of twitter data. Journal of Medical Internet Research, 22(12), e21418.
Varol, O. (2023). Should we agree to disagree about Twitter’s bot problem? Online Social Networks and Media, 37,
Varol, O., Ferrara, E., Davis, C. A., Menczer, F., & Flammini, A. (2017). Online human-bot interactions: Detection, estimation, and characterization. 11th ICWSM International AAAI Conference on Web and Social Media, Montréal, Canada.
Van Bavel, J. J., Baicker, K., Boggio, P. S., Capraro, V., Cichocka, A., Cikara, M., et al. (2020). Using social and behavioural science to support COVID-19 pandemic response. Nature Human Behaviour, 4(1), 460–471.
Vosoughi, S., Roy, D., & Aral, S. (2018). The spread of true and false news online. Science, 359(6380), 1146–1151.
Wang, W., Hernandez, I., Newman, D. A., He, J., & Bian, J. (2016). Twitter analysis: Studying US weekly trends in work stress and emotion. Applied Psychology, 65(2), 355–378.
Wang, P., Angarita, R., & Renna, I. (2018). Is this the era of misinformation yet: Combining social bots and fake news to deceive the masses. WWW 18—The Word Wide Web Conference, Lyon, France.
Wood, M. J. (2018). Propagating and debunking conspiracy theories on Twitter during the 2015–2016 Zika Virus Outbreak. Cyberpsychology, Behavior, and Social Networking, 21(8), 485–490.
Yang, K. C., Varol, O., Davis, C. A., Ferrara, E., Flammini, A., & Menczer, F. (2019). Arming the public with artificial intelligence to counter social bots. Human Behavior and Emerging Technologies, 1(1), 48–61.
Yang, K. C., Torres-Lugo, C., & Menczer, F. (2020). Prevalence of low-credibility information on twitter during the covid-19 outbreak. arXiv preprint arXiv:2004.14484.
Yang, K. C., Pierri, F., Hui, P. M., Axelrod, D., Torres-Lugo, C., Bryden, J., & Menczer, F. (2021). The COVID-19 Infodemic: Twitter versus Facebook. Big Data & Society, 8(1), 20539517211013860.
Zarocostas, J. (2020). How to fight an infodemic. Lancet, 395(10225), 676.
Zhang, Y., Song, W., Shao, J., Abbas, M., Zhang, J., Koura, Y. H., & Su, Y. (2023). Social bots’ role in the COVID-19 pandemic discussion on Twitter. International Journal of Environmental Research and Public Health, 20(4), 3284. https://doi.org/10.3390/ijerph20043284
Zhen, L., Yan, B., Tang, J. L., Nan, Y., & Yang, A. (2022). Social network dynamics, bots, and community-based online misinformation spread: Lessons from anti-refugee and COVID-19 misinformation cases. The Information Society, 39(1), 17–34.
Zuboff, S. (2015). Big other: Surveillance capitalism and the prospects of an information civilization. Journal of Information Technology, 30(1), 75–89. https://doi.org/10.1057/jit.2015.5
Zuboff, S. (2019). The age of surveillance capitalism. Profile Books, UK.
Acknowledgements
We thank our reviewers and editor who have further helped improve this manuscript.
Funding
No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
Both authors made a significant contribution to the acquisition, analysis, and interpretation of the data and to the conception, writing and editing of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable, although our institutional guidelines as well as AoIR Internet Research Ethical Guidelines 3.0 on conducting observational social media studies were followed.
Consent for publication
All authors consent to the manuscript being published.
Conflict of interest
There is no conflit of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elayan, S., Sykora, M. Digital intermediaries in pandemic times: social media and the role of bots in communicating emotions and stress about Coronavirus. J Comput Soc Sc (2024). https://doi.org/10.1007/s42001-024-00314-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42001-024-00314-2