
Abstract
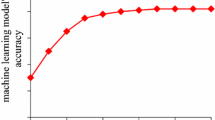
The era of big data has produced vast amounts of information that can be used to build machine learning models. In many cases, however, there is a point where adding more data only marginally increases model performance. This is especially important for scenarios of limited labeled data, as annotation can be expensive and time consuming. If the required sample size for accurate model performance can be determined early, then resources can be allocated appropriately to minimize time and cost. In this study, we explore sample size determination methods for four real-world biomedical datasets, spanning genomics, proteomics, electronic health records, and insurance claims data, all with millions of instances each and<2% class ratio. The methods used involve approximating a learning curve for a large amount of data using a small amount of data. We evaluate an existing method that fits an inverse power law model to a small learning curve and introduce a novel semi-supervised method that utilizes the large amount of unlabeled data for estimating a learning curve. We find that the inverse power law method is applicable to big data, while the semi-supervised method can be better at detecting convergence. To the best of our knowledge, this is the first study to apply an inverse power law curve fitting method to big data with limited labels and compare it to a semi-supervised approach.






Similar content being viewed by others


Notes
References
Agarwal A, Chapelle O, Dudk M, Langford J (2014) Reliable effective terascale linear learning system. J Mach Learn Res 15:1111–1133. http://jmlr.org/papers/v15/agarwal14a.html
Audet AM, Squires D, Doty MM (2014) Where are we on the diffusion curve? trends and drivers of primary care physicians’ use of health information technology. Health Serv Res 49(1pt2):347–360. https://doi.org/10.1111/1475-6773.12139
Bacardit J, Widera P, Marquez-Chamorro A, Divina F, Aguilar-Ruiz JS, Krasnogor N (2012) Contact map prediction using a large-scale ensemble of rule sets and the fusion of multiple predicted structural features. Bioinformatics 28(19):2441–2448. https://doi.org/10.1093/bioinformatics/bts472https://academic.oup.com/bioinformatics/article-lookup/doi/10.1093/bioinformatics/bts472
Baten A, Chang B, Halgamuge S, Li J (2006) Splice site identification using probabilistic parameters and SVM classification. BMC Bioinform. https://doi.org/10.1186/1471-2105-7-S5-S15
Bauder RA, Khoshgoftaar TM, Hasanin T (2018) An empirical study on class rarity in big data. In: 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), IEEE, Orlando, FL, pp 785–790. https://doi.org/10.1109/ICMLA.2018.00125, https://ieeexplore.ieee.org/document/8614150/
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Transac Intell Syst Technol 2:27:1–27:27. http://www.csie.ntu.edu.tw/~cjlin/libsvm
DARPA (2018) Learning with less labels (LwLL) - HR001118s0044 (Archived) - Federal Business Opportunities: Opportunities. https://www.fbo.gov/index?s=opportunity&mode=form&id=e76d8e2ccbb9361a9e2810adfb50146f&tab=core&_cview=1
Figueroa RL, Zeng-Treitler Q, Kandula S, Ngo LH (2012) Predicting sample size required for classification performance. BMC Med Inform Decision Making 12(1). https://doi.org/10.1186/1472-6947-12-8, http://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/1472-6947-12-8
Hajian-Tilaki K (2014) Sample size estimation in diagnostic test studies of biomedical informatics. J Biomed Inform 48:193–204. https://doi.org/10.1016/j.jbi.2014.02.013https://linkinghub.elsevier.com/retrieve/pii/S1532046414000501
Herland M, Khoshgoftaar TM, Wald R (2014) A review of data mining using big data in health informatics. J Big Data 1(1):1–35. https://doi.org/10.1186/2196-1115-1-2
Herland M, Khoshgoftaar TM, Bauder RA (2018) Big data fraud detection using multiple medicare data sources. J Big Data 5(1). https://doi.org/10.1186/s40537-018-0138-3, https://journalofbigdata.springeropen.com/articles/10.1186/s40537-018-0138-3
Jones E, Oliphant T, Peterson P (2014) SciPy: open source scientific tools for Python. http://www.scipy.org/
Karpathy A (2017) Software 2.0. https://medium.com/@karpathy/software-2-0-a64152b37c35
Leevy JL, Khoshgoftaar TM, Bauder RA, Seliya N (2018) A survey on addressing high-class imbalance in big data. J Big Data 5(1). https://doi.org/10.1186/s40537-018-0151-6, https://journalofbigdata.springeropen.com/articles/10.1186/s40537-018-0151-6
Lwanga SK, Lemeshow S, Organization WH et al (1991) Sample size determination in health studies: a practical manual. World Health Organization, Geneva
McKinney W (2010) Data structures for statistical computing in python. In: van der Walt S, Millman J (eds) Proceedings of the 9th Python in Science Conference, pp 51 – 56
Mukherjee S, Tamayo P, Rogers S, Rifkin R, Engle A, Campbell C, Golub TR, Mesirov JP (2003) Estimating dataset size requirements for classifying DNA microarray data. J Comput Biol 10(2):119–142. https://doi.org/10.1089/106652703321825928, http://www.liebertpub.com/
NIH (2018) Cancer statistics. https://www.cancer.gov/about-cancer/understanding/statistics
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12:2825–2830
Provost F, Jensen D, Oates T (1999) Efficient progressive sampling. In: Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining - KDD ’99, ACM Press, San Diego, California, United States, pp 23–32. https://doi.org/10.1145/312129.312188, http://portal.acm.org/citation.cfm?doid=312129.312188
R Core Team (2017) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
Richter AN, Khoshgoftaar TM (2017a) Modernizing analytics for melanoma with a large-scale research dataset. In: 2017 IEEE International Conference on Information Reuse and Integration (IRI), IEEE, San Diego, CA, pp 551–558. https://doi.org/10.1109/IRI.2017.45, http://ieeexplore.ieee.org/document/8102982/
Richter AN, Khoshgoftaar TM (2017b) Predicting sentinel node status in melanoma from a real-world EHR dataset. In: 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), IEEE, Kansas City, MO, pp 1872–1878. https://doi.org/10.1109/BIBM.2017.8217945, http://ieeexplore.ieee.org/document/8217945/
Richter AN, Khoshgoftaar TM (2019) Melanoma risk modeling from limited positive samples. Netw Model Anal Health Inform Bioinform 8(1). https://doi.org/10.1007/s13721-019-0186-4, http://link.springer.com/10.1007/s13721-019-0186-4
Rio Sd, Benitez JM, Herrera F (2015) Analysis of data preprocessing increasing the oversampling ratio for extremely imbalanced big data classification. In: 2015 IEEE Trustcom/BigDataSE/ISPA, vol 2, pp 180–185. https://doi.org/10.1109/Trustcom.2015.579
Sam S (2019) Learning with limited labeled data. http://vision.cloudera.com/learning-with-limited-labeled-data/
Settles B (2009) Active learning literature survey. University of Wisconsin-Madison Department of Computer Sciences, Madison, p 47
Shendure J, Ji H (2008) Next-generation DNA sequencing. Nat Biotechnol 26(10):1135
Sonnenburg S, Franc V (2010) COFFIN: A computational framework for linear SVMs. In: ICML, pp 999–1006
Sun C, Shrivastava A, Singh S, Gupta A (2017) Revisiting unreasonable effectiveness of data in deep learning era. In: 2017 IEEE International Conference on Computer Vision (ICCV), IEEE, Venice, pp 843–852. https://doi.org/10.1109/ICCV.2017.97, http://ieeexplore.ieee.org/document/8237359/
Triguero I, del Ro S, Lpez V, Bacardit J, Bentez JM, Herrera F (2015) ROSEFW-RF: The winner algorithm for the ECBDL14 big data competition: an extremely imbalanced big data bioinformatics problem. Knowledge-based systems 87:69–79. https://doi.org/10.1016/j.knosys.2015.05.027, http://linkinghub.elsevier.com/retrieve/pii/S0950705115002130
van der Walt S, Colbert SC, Varoquaux G (2011) The numpy array: a structure for efficient numerical computation. Comput Sci Eng 13(2):22–30. https://doi.org/10.1109/MCSE.2011.37
van der Ploeg T, Austin PC, Steyerberg EW (2014) Modern modelling techniques are data hungry: a simulation study for predicting dichotomous endpoints. BMC medical research methodology 14(1):137. https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/1471-2288-14-137
Van Hulse J, Khoshgoftaar TM, Napolitano A (2007) Experimental perspectives on learning from imbalanced data. In: Proceedings of the 24th international conference on Machine learning, ACM, pp 935–942. http://dl.acm.org/citation.cfm?id=1273614
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Richter, A.N., Khoshgoftaar, T.M. Sample size determination for biomedical big data with limited labels. Netw Model Anal Health Inform Bioinforma 9, 12 (2020). https://doi.org/10.1007/s13721-020-0218-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13721-020-0218-0