
Abstract
In this article, we develop a test for multivariate location parameter in elliptical model based on the forward search estimator for a specified scatter matrix. Here, we study the asymptotic power of the test under contiguous alternatives based on the asymptotic distribution of the test statistics under such alternatives. Moreover, the performances of the test have been carried out for different simulated data and real data, and compared the performances with more classical ones.
Similar content being viewed by others

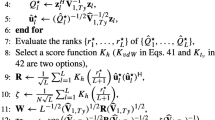
References
Babu, G.J. and Rao, C.R. (1988). Joint asymptotic distribution of marginal quantiles and quantile functions in sample from a multivariate population. J. Multivariate Anal.27, 15–23.
Bickel, P.J. (1965). On some robust estimates of location. Ann. Math. Statist.36, 847–858.
Billingsley, P. (1999). Convergence of Probability Measures. Wiley, New York.
Cerioli, A., Farcomeni, A. and Riani, M. (2014). Strong consistency and robustness of the Forward Search estimator of multivariate location and scatter. J. Multivariate Anal.126, 167–183.
Dhar, S.S., Dassios, A. and Bergsma, W. (2016). A study of the power and robustness of a new test for independence against contiguous alternatives. Electron. J. Stat.10, 330–351.
Fang, K.T., Kotz, S. and Ng, K.W. (1989). Symmetric Multivariate and Related Distributions. Chapman and Hall, New York.
Hajek, J., Sidak, Z. and Sen, P.K. (1999). Theory of Rank Tests. Academic Press, New York.
Hallin, M. and Paindaveine, D. (2002). Optimal tests for multivariate location based on interdirections and pseudo-Mahalanobis ranks. Ann. Stat.30, 1103–1133.
Hodges, J.L. and Lehmann, E.L. (1963). Estimation of location based on ranks. Ann. Math. Stat.34, 598–611.
Hotelling, H. (1931). The generalization of Student’s ratio. Ann. Math. Statist.2, 360–378.
Johansen, S. and Nielsen, B. (2010). Discussion: the forward search: theory and data analysis. J. Korean Statist. Soc.39, 137–145.
Lehmann, E.L. (2006). Nonparametrics: Statistical Methods Based on Ranks. Springer, Berlin.
Lehmann, E.L. and Romano, J.P. (2005). Testing Statistical Hypotheses. Springer Texts in Statistics.
Puri, M.L. and Sen, P.K. (1971). Nonparametric Methods in Multivariate Analysis. Wiley, New York.
Serfling, R.J. (1980). Approximation Theorems of Mathematical Statistics. Wiley, New York.
Shao, J. (2003). Mathematical Statistics. Springer Texts in Statistics.
Tukey, J.W. (1948). Some elementary problems of importance to small sample practice. Hum. Biol.20, 205–214.
Van der Vaart, A.W. (1998). Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics.
Acknowledgments
The authors are thankful to the Editor-in-Chief Prof. Dipak Kumar Dey, an anonymous Associate Editor and an anonymous reviewer for many suggestions, which improved the article significantly. The authors would like to thank Prof. Marc Hallin for notifying them his paper and pointed out the condition assumed in Theorem 3.1.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proofs
In this section, we present the proofs of the theorems and some related lemmas.
Lemma 1.
Asn →∞underH0, \(\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\)convergesweakly to ad-dimensional normal distribution with the location parameter = 0and the scatter parameter Σ1, where\({\Sigma }_{1} =\left [\frac {1}{d\gamma } \frac {\pi ^{\frac {d}{2}}}{{\Gamma }{(\frac {d}{2})}}\int \limits _{0}^{\infty } x^{\frac {d}{2}} g(x)dx\right ]{\Sigma }\).
Proof of Lemma 1.
A straightforward application of polar transformation for an elliptical distribution and the construction of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) along with the central limit theorem and Slutsky’s theorem (see, e.g., Billingsley (1999)), it follows that \(\sqrt {n}(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}-{\boldsymbol {\mu }}_{0})\) converges weakly to d-dimensional Gaussian distribution with mean = 0 and variance-covariance matrix \(= \left [\frac {1}{d\gamma } \frac {\pi ^{\frac {d}{2}}}{{\Gamma }{(\frac {d}{2})}}\int \limits _{0}^{\infty } x^{\frac {d}{2}} g(x)dx\right ]{\Sigma }\) under H0. This implies \({\dot {\boldsymbol {\mu }}}_{\gamma ,n}\) is a consistent estimator of μ, which follows from Prohorov’s theorem (see, e.g., Van Der Vaart (1998)). □
Proof of Theorem 2.1.
To test H0 : μ = μ0 against H1 : μ≠ μ0, the power of the test based on \({T_{n}^{1}}\) is given by \(P_{H_{1}}[{T_{n}^{1}} > c_{\alpha }]\), where cα is the (1 − α)-th (0 < α < 1) quantile of the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}{Z_{i}^{2}}\). Here, λis are the eigen values of \({\Sigma }_{1} = \left [\frac {1}{d\gamma } \frac {\pi ^{\frac {d}{2}}}{\Gamma }{(\frac {d}{2})}\int \limits _{0}^{\infty } x^{\frac {d}{2}} g(x)dx\right ]{\Sigma }\), and Zis are the i.i.d. N(0,1) random variables. In view of the orthogonal decomposition of multivariate normal distribution, \({T_{n}^{1}}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}{Z_{i}^{2}}\), and hence, the asymptotic size of the test based on \({T_{n}^{1}}\) is α. Let us now denote μ = μ1(≠ μ0) under H1, and we now consider
The last implication follows from the fact that \(\left |\left |\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{1})\right |\right |^2\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}{Z_{i}^{2}}\) under H1, and cα − n ||(μ1 −μ0)||2 converges to −∞ as n →∞. This fact leads to the result. □
Proof of Proposition 2.1.
For testing H0 : μ = μ0 against H1 : μ ≠ μ0, the power of the test based on \({T_{n}^{2}}\) will be \(P_{H_{1}}[{T_{n}^{2}} > c^{*}_{\alpha }]\), where \(c^{*}_{\alpha }\) is the (1 − α)-th (0 < α < 1) quantile of the distribution of \(\sum \limits _{i = 1}^{d}\lambda ^{*}_{i}Z_{i}^{*2}\). Here, \(\lambda ^{*}_{i}\)s are the eigen values of \({\sigma _{2}^{2}}{\Sigma }\), and \(Z^{*}_{i}\)’s are i.i.d. N(0,1) random variables. In view of the orthogonal decomposition of multivariate normal distribution, \({T_{n}^{2}}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}^{*}Z_{i}^{*2}\), and hence, the asymptotic size of the test based on \({T_{n}^{2}}\) is α. As earlier, let us again denote μ = μ1(≠ μ0) under H1, and we now have
The last implication follows from the fact that \(\left |\left |\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{SM} - {\boldsymbol {\mu }}_{1})\right |\right |^{2}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda ^{*}_{i}Z_{i}^{*2}\) under H1, and \(c^{*}_{\alpha } - n\left |\left |({\boldsymbol {\mu }}_{1}-{\boldsymbol {\mu }}_{0})\right |\right |^{2}\) converges to −∞ as n →∞. This completes the proof. □
Proof of Proposition 2.2.
In order to test H0 : μ = μ0 against H1 : μ≠ μ0, the form of the power function of the test based on \({T_{n}^{3}}\) is \(P_{H_{1}}[{T_{n}^{3}} > c^{**}_{\alpha }]\), where \(c^{**}_{\alpha }\) is same as described in the statement of the proposition. In view of the orthogonal decomposition of multivariate normal distribution, \({T_{n}^{3}}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}^{**}Z_{i}^{**2}\), and hence, the asymptotic size of the test based on \({T_{n}^{3}}\) is α Further, we denote that μ = μ1(≠ μ0) under H1, and we then have
The last implication follows from the fact that \(\left |\left |\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{CM} - {\boldsymbol {\mu }}_{1})\right |\right |^2\) converges weakly to the same distribution as described in the statement of the proposition, and \(c^{**}_{\alpha } - n\left |\left |({\boldsymbol {\mu }}_{1}-{\boldsymbol {\mu }}_{0})\right |\right |^2\) converges to −∞ as n →∞. This completes the proof. □
Proof of Proposition 2.3.
In order to test H0 : μ = μ0 against H1 : μ≠ μ0, the form of the power function of the test based on \({T_{n}^{4}}\) is \(P_{H_{1}}[{T_{n}^{4}} > c^{***}_{\alpha }]\), where \(c^{***}_{\alpha }\) is same as described in the statement of the proposition. In view of the orthogonal decomposition of multivariate normal distribution, \({T_{n}^{4}}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}^{***}Z_{i}^{***2}\), and hence, the asymptotic size of the test based on \({T_{n}^{4}}\) is α Further, we denote that μ = μ1(≠ μ0) under H1, and we then have
The last implication follows from the fact that \(\left |\left |\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{HL} - {\boldsymbol {\mu }}_{1})\right |\right |^{2}\) converges weakly to the same distribution as described in the statement of the proposition, and \(c^{***}_{\alpha } - n\left |\left |({\boldsymbol {\mu }}_{1}-{\boldsymbol {\mu }}_{0})\right |\right |^{2}\) converges to −∞ as n →∞. This completes the proof. □
Proof of Theorem 2.2.
At first, one needs to know the form of g(x) in the expressions of e1(d) and e2(d) that provided in the first paragraph in Section 2.2. Note that for a d-dimensional Gaussian distribution, \(g(x) = e^{-\frac {x}{2}}\), in the case of a d-dimensional Cauchy distribution, \(g(x) = \frac {1}{(1 + x)^{\frac {d + 1}{2}}}\), and for the given d-dimensional Spherical distribution, \(g(x)= e^{-x^{100}}\). Now, using the form of g(x), we have \(e_{1}(d) = \frac {\gamma }{{2\pi }^{\frac {d}{2}}}\), \(e_{2}(d) = \frac {\gamma {\pi }^{1-\frac {d}{2}}}{{2}^(1+\frac {d}{2})}\) and \(e_{3}(d) = \frac {\gamma \pi ^{1-\frac {d}{2}}}{3 \times {(2)}^{\frac {d}{2}}}\) for a d-dimensional Gaussian distribution. Since π > 1, one can conclude that \(\displaystyle \lim _{d\rightarrow \infty } e_{1}(d) = 0\). Next, note that \(e_{2}(d) = \frac {\gamma {\pi }^{1-\frac {d}{2}}}{{2}^(1+\frac {d}{2})} = \frac {\gamma \pi }{2\times (2\pi )^{\frac {d}{2}}}\rightarrow 0\) and \(e_{3}(d) = \frac {\gamma {\pi }^{1-\frac {d}{2}}}{3 \times {(2)}^{\frac {d}{2}}} = \frac {\gamma \pi }{3\times (2\pi )^{\frac {d}{2}}}\rightarrow 0\) as d →∞ since 2π > 1. Further, note that since Var(Y1) = ∞ for a Cauchy distribution, we have e1(d) = ∞ for all d, and hence, \(\displaystyle \lim _{d\rightarrow \infty } e_{1}(d) = \infty \) for a d-dimensional Cauchy distribution. Similarly, using the form of g(x) associated with Cauchy distribution, we have \(e_{2}(d) = \frac {\gamma d {\pi }^{\frac {3-d}{2}} {\Gamma }({\frac {d + 1}{2}})}{4}\) and \(e_{3}(d) = \frac {\gamma d {\pi }^{\frac {3-d}{2}} {\Gamma }({\frac {d + 1}{2}})}{12}\). In order to investigate the limiting properties of e2(d), we consider \(\frac {e_{2}(d + 1)}{e_{2}(d)} = \frac {d + 1}{d}\times \frac {1}{\sqrt {\pi }}\times \frac {{\Gamma }(d/2 + 1)}{{\Gamma }(d/2 + 1/2)}\). Next, using Stirling’s approximation formula: \({\Gamma }(n + 1) = \sqrt {2\pi }e^{-n} n^{n + 1/2}\) when n is an integer and n →∞, we have
This implies that \(\displaystyle \lim _{d\rightarrow \infty } e_{2}(d) = \infty \). Arguing in similar way one can say that \(\displaystyle \lim _{d\rightarrow \infty } e_{3}(d) = \infty \). Furthermore, for d-dimensional Spherical distribution with \(g(x) = e^{-x^{100}}\), we have \(e_{1} (d) = \frac {100 d\gamma {\Gamma }(\frac {d}{2})}{\pi ^{\frac {d}{2}} {\Gamma }(\frac {1}{100}(\frac {d}{2}+ 1))}\), \(e_{2}(d) = \frac {d\gamma {\Gamma }(\frac {d}{2}) ({\Gamma }(\frac {1}{200}))^{2}}{400 \pi ^{\frac {d}{2}} {\Gamma }(\frac {1}{100}(\frac {d}{2}+ 1))}\) and \(e_{3}(d) = \frac {53188.48 d\gamma {\Gamma }(\frac {d}{2})}{ \pi ^{\frac {d}{2}} {\Gamma }(\frac {1}{100}(\frac {d}{2}+ 1))} \). In order to investigate the limiting properties of e1(d) the repeated use of Stirling’s approximation formula leads to
This leads us to \(\displaystyle \lim _{d\rightarrow \infty } e_{1}(d) = \infty \). Similarly one can say that \(\displaystyle \lim _{d\rightarrow \infty } e_{2}(d) = \infty \) and \(\displaystyle \lim _{d\rightarrow \infty } e_{3}(d) = \infty \), and hence the proof is complete. □
Proof of Theorem 3.1.
In order to establish the contiguity of the distributions associated with sequence {H1n} relative to those of {H0n}, it is enough to show that Λn, the logarithm of the likelihood ratio, converges weakly to a random variable associated with a normal distribution with location parameter \(= -\frac {\sigma ^{2}}{2}\) and variance = σ2, where σ is a positive constant (see Hajek et al. 1999, p. 254, Corollary to Lecam’s first lemma). Let y1, …, yn be i.i.d. random variables with the probability density function f(y;(.),Σ), where (.) denotes the location parameter involved in the distribution, and Σ is the scatter matrix. We now consider
where ζn is any point lying on the straight line joining μ0 and \({\boldsymbol {\mu }}_{0}+\frac {{\boldsymbol {\delta }}}{\sqrt {n}}\), ▽ (.) denotes the gradient vector of (.), and H(.) denotes the Hessian matrix of (.). Note that ζn →μ0 as n →∞.
It now follows from the central limit theorem that \(\sum \limits _{i = 1}^{n}\frac {{\boldsymbol {\delta }}^{T}}{\sqrt {n}}\bigtriangledown \{h\left (\mathbf {y}_{i},{\boldsymbol {\mu }}_{0}\right )\}\) converges weakly to a random variable associated with normal distribution with mean = E[δT ▽{h (y,μ0)}] = 0 and variance = E[δT ▽{h (y,μ0)}]2 when E[δT ▽{h (y,μ0)}]2 < ∞ for all δ. Moreover, a direct algebra implies that E[δT ▽{h (y,μ0)}]2 = −E[δTH{h (yi,μ0)}δ] (see, e.g., Shao 2003). Hence, the asymptotic normality of \(\sum \limits _{i = 1}^{n}\frac {{\boldsymbol {\delta }}^{T}}{\sqrt {n}}\bigtriangledown \{h\left (\mathbf {y}_{i},{\boldsymbol {\mu }}_{0}\right )\}\) holds when \(E\left \{\frac {\partial ^{2}}{\partial \mu _{i}\partial \mu _{j}}\log f(\mathbf {y}, {\boldsymbol {\mu }}) \right \} < \infty \), where μi and μj are the i-th and the j-th components of μ.
Next, the other term \(\frac {1}{2n}\sum \limits _{i = 1}^{n}{\boldsymbol {\delta }}^{T}H\{h\left (\mathbf {y}_{i},\boldsymbol {\zeta }_{n}\right )\}{\boldsymbol {\delta }}\stackrel {p}\rightarrow \frac {1}{2}E [{\boldsymbol {\delta }}^{T}H\{h\left (\mathbf {y},{\boldsymbol {\mu }}_{0}\right )\}{\boldsymbol {\delta }}]\) in view of weak law of large number and ζn →μ0 as n →∞. Finally, using Slutsky’s result, one can conclude that Λn converges weakly to a normal distribution with mean \(= \frac {1}{2}E [{\boldsymbol {\delta }}^{T}H\{h\left (\mathbf {y}_{i},{\boldsymbol {\mu }}_{0}\right )\}{\boldsymbol {\delta }}]\) and variance = −E[δTH{h (yi,μ0)}δ], where E[δTH{h (yi,μ0)}δ] is a negative constant. Hence, the proof is complete. □
Proof of Theorem 3.2.
To establish this result, one first needs to show that the joint distribution of \(\{\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0}), {\Lambda }_{n}\}\) is asymptotically Gaussian under H0, which is asserted in Le Cam’s third lemma (see, e.g., Hajek et al. 1999). Note that Lemma 1 asserts, \(\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\) converges weakly to a d-dimensional Gaussian distribution under H0, and further, it follows from the proof of Theorem 3.1 that Λn converges weakly to a univariate Gaussian distribution with certain parameters under some conditions. Suppose now that \(\mathbf {L}\in \mathbb {R}^{d}\) and \(m\in \mathbb {R}\) are two arbitrary constants. In view of the linearization of \(\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\) and Λn along with a direct application of central limit theorem, one can establish that \(\mathbf {L}^{T}.\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\} + m{\Lambda }_{n}\) converges weakly to a univariate Gaussian distribution under H0, where (.) denotes the inner product. This fact implies that the joint distribution of \(\{\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0}), {\Lambda }_{n}\}\) is asymptotically (d + 1)-dimensional Gaussian under H0. Note that the i-th component of d-dimensional covariance between \(\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\) and Λn is \(E\left \{(\dot {{\boldsymbol {\mu }}}_{\gamma ,n, i} - {\boldsymbol {\mu }}_{0, i})\sum \limits _{j = 1}^{d}\delta _{j}\frac {\partial g(\mathbf {y}, {\boldsymbol {\mu }})}{\partial \mu _{j}}|_{{\boldsymbol {\mu }} = {\boldsymbol {\mu }}_{0}}\right \}\), where δi, \(\dot {{\boldsymbol {\mu }}}_{\gamma , n, i}\), μ0,i and μi are the i-th component of δ, \(\dot {{\boldsymbol {\mu }}}_{\gamma , n}\), μ0 and μ, respectively, and g(y,μ) = log f(y,μ).
Now, using Le Cam’s third lemma, one can directly establish that under Hn, \(\{\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0})\}\) converges weakly to d-dimensional Gaussian distribution with mean vector a = (a1,…,ad) and variance-covariance matrix \(= \left [\frac {1}{d\gamma } \frac {\pi ^{\frac {d}{2}}}{\Gamma (\frac {d}{2})}\int \limits _{0}^{\infty } x^{\frac {d}{2}} g(x)dx\right ]{\Sigma }\), where \(a_{i} = E\left \{(\dot {{\boldsymbol {\mu }}}_{\gamma ,n, i} - {\boldsymbol {\mu }}_{0, i})\sum \limits _{j = 1}^{d}\delta _{j}\frac {\partial g(\mathbf {y}, {\boldsymbol {\mu }})}{\partial \mu _{j}}|_{{\boldsymbol {\mu }} = {\boldsymbol {\mu }}_{0}}\right \}\). Hence, under Hn, for any orthogonal matrix A, \(\{A\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0} - \mathbf {a})\}\) converges weakly to a d-dimensional Gaussian distribution with mean vector = 0 and variance-covariance matrix = Diag(λ1,…,λd), where λi is the i-th eigenvalue of \(\left [\frac {1}{d\gamma } \frac {\pi ^{\frac {d}{2}}}{\Gamma (\frac {d}{2})}\int \limits _{0}^{\infty } x^{\frac {d}{2}} g(x)dx\right ]{\Sigma }\), and consequently, as A is an orthogonal matrix, i.e., ATA = AAT = Id, \(\{A\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0} - \mathbf {a})\}^{T}\{A\sqrt {n} (\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0} - \mathbf {a})\} = n||\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0} - \mathbf {a}||^{2}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}{Z_{i}^{2}}\), where Zi’s are i.i.d. standard normal random variables. This fact directly imply that under Hn and condition assumed in Theorem 3.1., \({T_{n}^{1}} = n||\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - {\boldsymbol {\mu }}_{0}||^{2}\) converges weakly to the distribution of \(\sum \limits _{i = 1}^{d}\lambda _{i}(Z_{i} + a_{i})^{2}\).
Similarly, based on the Bahadur expansion of the median (see, e.g., Serfling 1980), the Hodges-Lehmann estimator (see, e.g., Lehmann 2006) and the definition of the sample mean vector, one can conclude that under H0, \(\mathbf {L}^{T}.\{\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{CM} - {\boldsymbol {\mu }}_{0})\} + m{\Lambda }_{n}\), \(\mathbf {L}^{T}.\{\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{HL} - {\boldsymbol {\mu }}_{0})\} + m{\Lambda }_{n}\) and \(\mathbf {L}^{T}.\{\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{SM} - {\boldsymbol {\mu }}_{0})\} + m{\Lambda }_{n}\) converge weakly to a Gaussian random variable with certain parameters for arbitrary constants \(\mathbf {L}\in \mathbb {R}^{d}\) and \(m\in \mathbb {R}\). This fact along with Le Cam’s third lemma imply that under Hn, both \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{CM} - {\boldsymbol {\mu }}_{0})\), \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{HL} - {\boldsymbol {\mu }}_{0})\) and \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{SM} - {\boldsymbol {\mu }}_{0})\) converge weakly to a d-dimensional Gaussian random vector with non-zero mean vectors and certain variance-covariance matrix. The i-th component of the mean vector for \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{SM} - {\boldsymbol {\mu }}_{0})\), \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{CM} - {\boldsymbol {\mu }}_{0})\) and \(\sqrt {n} (\hat {{\boldsymbol {\mu }}}_{HL} - {\boldsymbol {\mu }}_{0})\) are \(a_{i}^{*}\), \(a_{i}^{**}\) and \(a_{i}^{***}\), respectively, where i = 1,…,d. Finally, as we argued earlier, based on the well-known orthogonalization of the multivariate Gaussian distribution, one can conclude that under Hn, \({T_{n}^{2}}\) converges weakly to \(\sum \limits _{i = 1}^{d}\lambda ^{*}_{i}(Z_{i}^{*} + a_{i}^{*})^{2}\), \({T_{n}^{3}}\) converges weakly to \(\sum \limits _{i = 1}^{d}\lambda ^{**}_{i}(Z_{i}^{**} + a_{i}^{**})^{2}\), and \({T_{n}^{4}}\) converges weakly to \(\sum \limits _{i = 1}^{d}\lambda ^{***}_{i}(Z_{i}^{***} + a_{i}^{***})^{2}\). The description of \(\lambda _{i}^{*}\), \(a_{i}^{*}\), \(Z_{i}^{*}\), \(\lambda _{i}^{**}\), \(a_{i}^{**}\), \(Z_{i}^{**}\), \(\lambda _{i}^{***}\), \(a_{i}^{***}\) and \(Z_{i}^{***}\) are provided in the statement of the theorem. The proof is complete now. □
Proof of Corollary 3.1.
It follows from the assertion in Theorem 3.2. that under Hn, the power of the test based on \({T_{n}^{1}}\) is \(P_{{\boldsymbol {\delta }}}\left [\sum \limits _{i = 1}^{d}\lambda _{i}(Z_{i} + a_{i})^{2} > c_{\alpha }\right ]\). Here cα is such that \(P_{\boldsymbol {\delta } = \mathbf {0}}\left [\sum \limits _{i = 1}^{d}\lambda _{i}(Z_{i} + a_{i})^{2} > c_{\alpha }\right ]\) = α since Hn coincides with H0 when δ = 0. Arguing exactly in a similar way, one can establish the asymptotic power of the tests based on \({T_{n}^{2}}\), \({T_{n}^{3}}\) and \({T_{n}^{4}}\) under Hn. □
Appendix B: Properties of Forward Search Estimator
Here, we study a few fundamental properties of the multivariate forward search location estimator along with its performances.
(Property 1) Robustness of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\)
The robustness property of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) is described by the finite sample breakdown point, which is defined as follows. For the estimator \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) based on the data \({\mathcal {Y}} = \{\mathbf {y}_{1}, \ldots , \mathbf {y}_{n}\}\), its finite sample breakdown point is defined as \(\epsilon (\dot {{\boldsymbol {\mu }}}_{\gamma ,n}, {\mathcal {Y}}) = \displaystyle \min _{m^{\star }\leq n^{\star }\leq n}\left \{\frac {n^{\star }}{n}:\sup _{{\mathcal {Y}^{*}}}\left |\left |\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - \dot {{\boldsymbol {\mu }}}_{\gamma ,n}^{(n^{\star })}\right |\right | = \infty \right \}, \) where m∗ is the cardinality of the initial subset, and \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}^{(n^{\star })}\) is the forward search estimator of μ based on a modified sample \({\mathcal {Y}^{*}} = \{\mathbf {y}^{*}_{1}, \ldots , \mathbf {y}^{*}_{n^{*}}, \mathbf {y}_{n^{*} + 1},\) …,yn}. The following theorem describes the breakdown point of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\).
Theorem 6.1.
Suppose thaty’s are in general position i.e., one cannot draw a hyperplanepassing through all the observations, in the case of\(\dot {{\boldsymbol {\mu }}}_{\gamma , n}\)forγ-thstep. Then, we have\(\epsilon (\dot {{\boldsymbol {\mu }}}_{\gamma ,n}, {\mathcal {Y}}) = 1-\gamma \).
Proof of Theorem 6.1.
Suppose that the original observations are denoted by \({\mathcal {Y}} = \{\mathbf {y}_{1}, \ldots , \mathbf {y}_{n}\}\), and without loss of generality, first n∗ < n obervations are corrupted. Let \({\mathcal {Y}}^{*} = \{\mathbf {y}_{1}^{*}, \ldots , \mathbf {y}_{n^{*}}^{*}, \mathbf {y}_{n^{*} + 1}, \ldots , \mathbf {y}_{n}\}\) denote the contaminated sample, where \(\mathbf {y}_{i}^{*}\) are corrupted observations, i = 1,…,n∗. It follows from the construction of the estimator that \(\displaystyle \sup _{{\mathcal {Y}}^{*}}\left |\left |\dot {{\boldsymbol {\mu }}}_{\gamma ,n} - \dot {{\boldsymbol {\mu }}}_{\gamma ,n}^{(n^{\star })}\right |\right | = \infty \) if and only if \(\left |\left |\mathbf {y}_{i^{\star }}^{\star }\right |\right |=\infty \) for any i = 1,…,n∗. Without loss of generality, suppose that the aforementioned equivalent relationship holds for some k, and we than have ηk,γ,n = 1 since \(\sum \limits _{i = 1}^{n}\eta _{i,\gamma , n} = m>0\). This fact implies that \(Md^{2}_{k,n} = \infty \) for those choices of k. Let us further consider that there are \(n_{1}^{*} < n^{*}\) many choices of k for which \(Md^{2}_{k,n} = \infty \). Now, in view of the definition of ηk,γ,n, we have \(\eta _{j,\gamma ,n} = I(Md^{2}_{j,n} \leq \delta ^{2}_{\gamma , n}) = I(Md^{2}_{j, n} \leq Md^{2}_{(m), n}) = 0\) for \(j = 1, \ldots , n_{1}^{*}\) when \(n_{1}^{*} < n - m\). Further, note that \(Md^{2}_{k,n} = \infty \) for any k = 1,…,n∗ when \(n_{1}^{*} = n^{*}\). Hence, \(\epsilon (\dot {{\boldsymbol {\mu }}}_{\gamma ,n}, {\mathcal {Y}}) = 1-\gamma ,\) and the proof is complete. □
Remark 6.1.
We would like to discuss on the breakdown point of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\). Note that (1 − γ) is essentially the trimming proportion of the observations in the forward search estimator, and for that reason, it is expected that this estimator cannot be breakingdown even in the presence of (1 − γ) proportion outliers in the data. It indicates that γ controls the breakdown point of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\). For instance, the breakdown point of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) will achieve the highest possible value = 1/2 when γ = 1/2, and on the other hand, when γ = 1 ⇔ m = n, the breakdown point of the forward search estimator will be = 0. Overall, the robustness behaviour of the forward search estimator is similar to any other trimming based estimator, e.g., the trimmed mean (see, e.g., Tukey 1948; Bickel 1965).
(Property 2) Finite Sample Efficiency of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\)
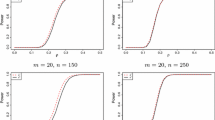
We here investigate the finite sample efficiency of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) relative to the sample mean, the co-ordinate wise median and the Hodges-Lehmann estimator for d-dimensional Gaussian distribution, d-dimensional Cauchy distribution with probability density function fC(x) = (Γ((d + 1)/2)/πd/2Γ(1/2))(1 + xTx)−(d+ 1)/2 and d-dimensional Spherical distribution with with \(g(x) = e^{-x^{100}}\). In this simulation study, the finite sample efficiency of an estimator Tn relative to \({T}_{n}^{\prime }\) is defined as \(\{|COV(T_{n}^{\prime })|/|COV(T_{n})|\}^{1/d}\), where |COV (Tn)| is the determinant of \(COV({T}_{n}) = \frac {1}{m}\sum \limits _{i = 1}^{m}({T}_{n}^{i} -\bar {{T}}_{n})({T}_{n}^{i} -\bar {{T}}_{n})^{T}\), and m is the number of Monte-Carlo replications. Here, \({T}_{n}^{i}\) is the estimate of Tn based on the i-th replication, and \(\bar {{T}}_{n} = \frac {1}{m}\sum \limits _{i = 1}^{m}{T}_{n}^{i}\). In this simulation study, we consider m = 1000, and n = 10 and 100, and the results are summarized in Table 3.
Here, \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) performs well in term of finite sample efficiency for Cauchy distribution. The Hodges-Lehmann estimator also has better efficiency than the co-ordinate wise median for like Cauchy distribution. For normal distribution, the sample mean performs best although it fails to perform well for Cauchy distribution. The Hodges-Lehmann estimator is nearly as efficient as the sample mean for the normal distribution. For Spherical distribution with with \(g(x) = e^{-x^{100}}\), \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) performs best compared to other three estimators.
(Property 3) Asymptotic Efficiency of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\)
In this study, we consider d-dimensional Gaussian, d-dimensional Cauchy distributions and d-dimensional Spherical distribution with \(g(x)=e^{-x^{100}}\) to carry out this study. The asymptotic efficiencies of \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) relative to the sample mean, the co-ordinate wise median and the Hodges-Lehmann estimator for the aforementioned distributions are reported in Table 4.
It is evident from the figures in Table 4 that \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\) performs well in term of asymptotic efficiency for Cauchy distribution. For Spherical distribution with \(g(x)=e^{-x^{100}}\), it performs best among all the estimators. As expected, the sample mean performs best for normal distribution since it is the maximum likelihood estimator of location parameter in the normal distribution. The Hodges-Lehmann estimator is nearly as efficient as the sample mean for the normal distribution. On the other hand, the sample mean was outperformed by \(\dot {{\boldsymbol {\mu }}}_{\gamma ,n}\), co-ordinate wise median and Hodges-Lehmann estimator for Cauchy distribution since the sample mean does not have finite second moment when data follow Cauchy distribution.
Rights and permissions
About this article

Cite this article
Chakraborty, C., Dhar, S.S. A Test for Multivariate Location Parameter in Elliptical Model Based on Forward Search Method. Sankhya A 82, 68–95 (2020). https://doi.org/10.1007/s13171-018-0149-3
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13171-018-0149-3