
Abstract
Pine wood nematode infection is a devastating disease. Unmanned aerial vehicle (UAV) remote sensing enables timely and precise monitoring. However, UAV aerial images are challenged by small target size and complex surface backgrounds which hinder their effectiveness in monitoring. To address these challenges, based on the analysis and optimization of UAV remote sensing images, this study developed a spatio-temporal multi-scale fusion algorithm for disease detection. The multi-head, self-attention mechanism is incorporated to address the issue of excessive features generated by complex surface backgrounds in UAV images. This enables adaptive feature control to suppress redundant information and boost the model’s feature extraction capabilities. The SPD-Conv module was introduced to address the problem of loss of small target feature information during feature extraction, enhancing the preservation of key features. Additionally, the gather-and-distribute mechanism was implemented to augment the model’s multi-scale feature fusion capacity, preventing the loss of local details during fusion and enriching small target feature information. This study established a dataset of pine wood nematode disease in the Huangshan area using DJI (DJ-Innovations) UAVs. The results show that the accuracy of the proposed model with spatio-temporal multi-scale fusion reached 78.5%, 6.6% higher than that of the benchmark model. Building upon the timeliness and flexibility of UAV remote sensing, the proposed model effectively addressed the challenges of detecting small and medium-size targets in complex backgrounds, thereby enhancing the detection efficiency for pine wood nematode disease. This facilitates early preemptive preservation of diseased trees, augments the overall monitoring proficiency of pine wood nematode diseases, and supplies technical aid for proficient monitoring.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Pine wood nematode disease, also known as pine wilt disease and the ‘cancer’ of pines, is one of the most destructive diseases transmitted through insect vectors such as Monochamus alter-natus. The disease originated in North American countries and spread through the timber trade. At present, it is mainly found in the US, Canada, Mexico, France and Portugal, South Korea, North Korea, Japan and China. China is the country with the most serious infection of pine wood nematode disease (Hao et al. 2022; Zhou et al. 2022). Since it was first discovered in the Zhongshan Mausoleum in Nanjing, China, in 1982, it has gradually spread to north and southwest. The disease is characterized by its high pathogenicity and rapid spread, leading to quick death of infected trees. Infected pine needles are yellowish or reddish brown, wilted and drooping. From infection to death is less than two months. If infected trees are not quickly removed, it may take only 3–5 years for an entire pine forest to be infected from a single plant and to be completely destroyed. The disease has caused serious damage to China’s pine forest resources and considerable economic losses (Huang et al. 2022). Therefore, rapid, comprehensive and accurate identification of infected trees is of significance for controlling the spread of the disease and protecting pine forest resources.
Conventional monitoring relies on regular inspections conducted by forest rangers, which consumes significant manpower and material resources while having low efficiency and accuracy (Lim et al. 2022). With the continuous advancement of aerial photography technology, the utilization of remote sensing for identifying diseases in forest areas has become a crucial approach. Satellite remote sensing has multi-band and multi-phase capabilities, offering advantages of real-time dynamic monitoring and extensive area coverage. It serves as one of the essential means for forest pest surveillance (Zhang et al. 2022). Early satellite image classification focused on low-resolution images, predominantly employing pixel-based methods. Dennison et al. (2010) used 0.5-m spatial resolution, pan-sharpened GeoEye-1 images to differentiate between diseased pines (gray or red) and healthy pines (green) within forests in the US. Poona and Ismail (2012) used high-resolution Quick Bird data alongside feedforward neural networks and naive Bayesian classifiers to distinguish healthy crowns from infected ones. These traditional pixel-based classification methods exhibit considerable noise in object extraction results when applied to high-resolution images, lacking semantic features necessary for effective pine wood nematode monitoring. Huang et al. (2012) analyzed the hyperspectral time series characteristics and sensitivity of healthy and diseased trees, revealing that the spectral sequence of diseased trees exhibited irregularities characterized by a decrease in spectral reflectance at the red edge and a shift of the blue edge towards the red edge. This distinctive feature holds significant importance for monitoring pine wood nematodes. Kim et al. (2018) used the existing 10 vegetation indices (based on hyperspectral data) and the introduced Green–Red Spectral Area Index (GRSAI) to show that the reflectance of the infrared and mid-infrared bands of the trees changed two months after being infected, and there was no significant difference in the reflectance of the uninfected trees, which can serve as a reference for remote sensing-based monitoring. However, satellite remote sensing images are susceptible to resolution limitations, cloud cover, foggy weather, long satellite flight cycles, time delays, difficulties in identifying individual diseased trees, and high costs; all these factors hinder timely monitoring of pine wood nematode disease.
UAV remote sensing is a low-altitude monitoring method characterized by strong timelines, minimal atmospheric interference, and high flexibility. It has gradually become a primary tool for identifying infestations (Guimarães et al. 2020). With the continuous advancement of computer technology, UAV images, combined with machine learning, image analysis, and other algorithms, are increasingly being utilized in agriculture and forestry. Yuan and Hu (2016) proposed a novel approach to effectively detect forest pests in UAV images by dividing the image into multiple super pixels, followed by the counting of texture information for each for training and classification purposes. While this technique considers manually designed low-level features such as tree color and texture, the recognition process is time-consuming, and it does not leverage the real-time monitoring of forest diseases.
With advancements in deep learning in recent years, the object detection algorithm, based on convolutional neural networks (CNNs), has undergone continuous refinement. The integration of UAV remote sensing images and deep learning object detection technology has expanded applications in agricultural and forestry disease recognition. Object detection models, such as region-based convolutional neural networks (R-CNN) and ‘You Only Look Once’ (YOLO) are increasingly being integrated into remote sensing. Deng et al. (2020) developed a pine wood nematode disease detection model based on the Faster R-CNN deep learning framework. By adding a geographic location information module to the network and carrying out numerous optimizations, the detection and location of diseased and dead trees were possible. Hu et al. (2022) proposed a remote sensing monitoring method for UAV pine forest disease utilizing an improved Mask R-CNN. This serves as the backbone network to construct the monitoring model, which incorporates an enhanced multi-scale receptive field block module and a multi-level fusion residual pyramid structure to accurately detect diseased trees. The two-stage detection algorithm, R-CNN, exhibits a high, accurate detection rate. However, it increases computational costs, extends training times, reduces detection speeds, and demands higher hardware requirements. Consequently, it cannot provide for the real-time detection of pine wood nematode disease. In contrast, the single-stage detection algorithm YOLO offers a shorter operation time, making it more suitable for rapid identification of the disease. Wu et al. (2023) proposed an enhanced model, Effi_YOLO_v3, based on the characteristics of the three stages of the disease, achieving classification and detection of different infection stages. Their efforts produced satisfactory results in terms of recognition speed and accuracy. Zhu et al. (2023) advanced a phased detection and classification approach which leverages dead, nematode-infected wood as its foundation, incorporating YOLOv4 and GoogLeNet. It employs high-resolution images obtained via helicopter for enhanced precision. This phased detection and classification method sustains the rapid training and detection pace of the primary target detection model while significantly augmenting detection accuracy in the face of limited data volume. It demonstrates superior adaptability in achieving accurate classification and addresses the needs for the prevention and control of pine wood nematode disease.
Although these research methods have yielded good results in identifying pine wood nematode diseased trees, low resolution of some small targets in aerial images, limited semantic information, and complex surface backgrounds render the algorithm incapable of extracting small target features effectively. Consequently, the extracted feature information is inadequate, leading to a substantial number of small-scale diseased trees going undetected. In addition, the model has stringent, real-time requirements for detection, as time lag hinders timely monitoring and feedback control. As the YOLO model continues to iteratively improve, it has demonstrated commendable accuracy and speed in detecting normal-size targets with significant contrast from the background (Liu and Wang 2020; Zhu et al. 2021; Terven et al. 2023). However, its detection performance for complex backgrounds and small-size objects in drone images remains suboptimal.
To achieve efficient detection of small-scale diseased tree targets in UAV remote sensing images with complex backgrounds, this study presents a spatio-temporal multi-scale fusion algorithm. The approach incorporates a multi-head attention mechanism into the YOLOv8 backbone network to mitigate the effects of numerous redundant features generated by complex surface backgrounds during detection. In addition, the SPD-Conv module, designed for small targets, is incorporated to enhance the model’s capability for extracting features from small targets. The Neck component incorporates the GD (Gather-and-Distribute) mechanism, which boosts the model’s multi-scale fusion ability and improves its detection performance by integrating information from different scales through a unified module. Lastly, Focal-EIoU is employed instead of CIoU to increase the contribution of high-quality anchor frames to the regression loss of bounding boxes, enhance the model’s attention towards information and compel it to acquire crucial task-related features, thereby augmenting accuracy. The enhanced model demonstrates accurate detection and classification of diseased and dead trees from UAV remote sensing images, effectively meeting the real-time monitoring requirements under UAV remote sensing.
Materials and methods
Study area
Huangshan was selected as the research area and is in Huangshan City, southern Anhui Province at 118°01ʹ–118°17ʹ E, 30°01ʹ− 30°18ʹ N. It has a subtropical monsoon climate. The Huangshan area is a famous scenic spot with a forest cover more than 70%. There are a several pine species in the area, including Pinus hwangshanensis, Pinus massoniana, and Pinus thunbergii. The five-year action plan (2021−2025) for the prevention and control of national pine wood nematode disease epidemic has been initiated, and the disease in the Huangshan area is typical, with need for prevention and control. At the same time, Huangshan City, has also introduced China’s first municipal pine wood nematode disease prevention and control regulations, and therefore Huangshan was selected as a test area.
Data acquisition and marking
UAV took visible light remote sensing images October 18th and 19th. The flight platform was M300RTK with a Zen p1 lens. The pixel count was 45 million, the ground resolution 6.15 cm, the flight height 490 m, the heading overlap 80%, and the lateral overlap 70%. The isometric photography mode was adopted, and the route speed was 13 m s−1.
After the UAV collected visible light images, due to the variety of species in the Huangshan area according to the data, the area with distinct pine infection was identified. Thirty UAV images with a resolution of 8192 × 5460 pixels were selected as data set images (Fig. 1). The discolored wood in the image was identified visually and the open-source annotation tool LabelImg used to annotate infected trees in the thirty images. According to external characteristics such as degree of discoloration and wilting state, infected pines were divided into two categories: “diseased tree” and “dead tree”. Yellow–green, yellow–brown and red-brown crowns were “diseased trees”; white crowns were “dead trees”. Annotation included the coordinates of the rectangular bounding box around the infected tree and the category of the infection stage. Due to the large resolution of the original image, synchronous cutting of the image and the annotation file was carried out. A total of 2478 images with a resolution of 640 × 640 pixels were cut out and made into data sets. According to the ratio 8:1:1, 1966 training sets, 256 validation sets, and 256 test sets were obtained (Table 1). To improve the generalization ability of the model to the data set, the data set was enhanced by mosaic data enhancement and the pictures spliced by random scaling, cropping and arrangement. At the same time, random horizontal flipping, enhanced image tone, saturation, brightness and other data enhancement methods were used to enrich the detection data set. In particular, random scaling increased numerous small targets, making the network more robust. At the same time, YOLOv8 introduced the operation of closing mosaic enhancement in the last 10 epoch of YOLOX, which can effectively improve the accuracy of the model.

Data set production
A spatio-temporal multi-scale fusion algorithm for disease detection
Overall structure
The YOLO model has been used extensively in the detection and classification of plant diseases and insect pests within the agricultural and forestry sectors (Tian et al. 2019). YOLOv8 is the most recent iteration of the YOLO series. The C2f module is incorporated into the Backbone and Neck components to further facilitate model lightweighting (Liu et al. 2018; Wang et al. 2020); the Anchor-Free concept is adopted in the Head and DFL Loss + CIOU Loss employed as the classification loss function (Zheng et al. 2020). Given the significant variation in target scale within UAV aerial images, YOLOv8 divides the input image into smaller grids. Each grid solely predicts a single target, resulting in challenges when addressing targets with substantial scale changes. For small size trees, this may lead to missed or false detections, hindering timely monitoring.
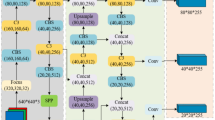
In order to discern the efficient detection of small-scale diseased targets in UAV remote sensing images under complex backgrounds, aiming at problems of extraction of feature information and lack of feature expression, this study added the multi-head attention mechanism (MHSA) to the backbone network to suppress irrelevant information generated by complex backgrounds. SPD-Conv convolution was introduced to improve feature extraction ability of small targets. Due to the limitations of the feature pyramid network (FPN) structure in YOLOv8, which can only fuse features of adjacent levels, the Gather-and-Distribute (GD) mechanism was introduced into the Neck to enhance the multi-scale fusion capability of the model. This enables the model to better capture diverse aspects of features. Further, Focal-EIoU was used as the bounding box regression loss to increase the contribution of high-quality anchor boxes, significantly improving model accuracy. The overall improved YOLOv8 model structure is shown in Fig. 2. This improved model accurately detects and classifies diseased and dead trees from UAV remote sensing images, fulfilling the timely monitoring requirements under UAV remote sensing.

A spatio-temporal multi-scale fusion network structure
Multi-head self-attention (MHSA)
The UAV remote sensing image provides wide coverage and high resolution, resulting in the classification of all ground object categories into the background except for diseased and dead tree targets. The complex background of UAV aerial images poses challenges for the network’s feature extraction capabilities. Traditional convolutional neural networks are limited by their convolution kernels, which hinders extraction of contextual information. To address this, this study incorporated an attention mechanism within the backbone network of feature extraction. This effectively mitigates interference caused by intricate surface background, thereby enhancing the model’s feature extraction performance. The multi-head attention mechanism increases spatial resolution, concurrency, and computational efficiency of the attention mechanism. Consequently, this study employed the mechanism to further mitigate interference caused by redundant information and enhance the model’s perception of pertinent information.
The multi-head self-attention (MHSA) mechanism refers to the combination of multiple self-attention structures and is a core component of the transformer model. It employs a split-head processing technique, treating each position in the input sequence as a vector and applying the self-attention mechanism to generate multiple output vectors. Subsequently, these vectors are connected to obtain the final vector representation, enabling the capture of inter-position correlations, enhanced characterization of diverse aspects, and improved model performance (Fig. 3). Four attention heads were utilized, along with relative position coding (Rh, Rw) and 1 × 1 point-by-point convolution. The multi-head attention mechanism was encoded by the YOLO backbone to obtain a feature map of Q, K and V, which is linearly transformed to generate WQ (query), WK (keys), WV (values), height (Rh) and width (Rw), the output of the module is Zi. The attention score is calculated by Q and K and multiplied by the vector V to suppress redundant information so as to improve model perception ability to the effective information.

Multi-head self-attention (MHSA) structure
The result after each mapping is inputted into the zoom dot product attention mechanism. The result obtained each time is called a head, and the formula is:
The formula of multi-head attention is:
Introduced into the YOLOv8 backbone network, the MHSA structure facilitates concentration of the network’s attention on the target for detection, augments target feature representation, attenuates background features, and enhances the model’s performance and detection accuracy.
SPD-Conv module for small targets
Although the convolutional neural network is proficient in target detection tasks, it encounters challenges in small target detection due to the substantial down-sampling induced by YOLO. This hampers the deep neural network’s ability to absorb feature information from small targets, resulting in the loss of fine-grained data and a decline in the efficiency of feature representation learning. Consequently, the preservation of small target feature information during extraction is critical in enhancing detection performance. To mitigate the loss of fine-grain feature information during the convolution process, this study introduces a novel convolutional neural network structure, SPD-Conv, which replaces the original in the backbone network.
The SPD-Conv module (Sunkara and Luo 2023) consists of a spatial depth layer (SPD) and a non-stride convolution (Fig. 4). By employing image conversion technology, SPD-Conv effectively down-samples the feature mapping within the CNN and the entire network while retaining all channel-dimension information. The process involves splitting the feature graph of \(S\times S\times {C}_{1}\) N times along the channel direction. Figure 4 shows an example when N = 2, the number of channels is C1, and the size becomes \(\left( {\frac{S}{2} \times \frac{S}{2} \times C_{1} } \right)\), X is down-sampled by factor 2. The sub-feature graph is connected along the channel dimension, and the SPD module transforms the feature graph X (S × S × \({C}_{1}\)) into the intermediate feature graph \(X_{1} \left( {\frac{S}{N} \times \frac{S}{N} \times N^{2} C_{1} } \right)\). The spatial dimension is reduced twice, and the number of channels becomes 4C1. Eventually, a non-stride convolution layer is incorporated after the SPD module to mitigate information loss by amplifying the utilization of learnable parameters within the convolution layer and preserving the maximum feature information. Finally, the feature graph is \(X_{1} \left( {\frac{S}{N} \times \frac{S}{N} \times N^{2} C_{1} } \right)\) transformed into feature graph \(X_{2} \left( {\frac{S}{N} \times \frac{S}{N} \times C_{2} } \right)\)

SPD structure
In summary, the SPD-Conv module effectively reduces the loss of detailed features by using SPD instead of traditional convolution for down-sampling. Therefore, the introduction of the module effectively improves the preservation rate of key features in low-resolution images and small target detection tasks, which is of significance to improve small target detection in UAV remote sensing images.
Multi-scale fusion gather-and-distribute mechanism
When the convolutional neural network extracts image features, the deep layer contains more semantic information but the spatial resolution of the feature map is low, which is particularly obvious when detecting small targets. The shallow layer contains more location and detail information, which can make up for the shortcomings of deep features to a certain extent. However, if only shallow features are used to detect targets, it will cause serious false detection and missed detection due to the lack of guidance of high-level semantic information. The scale of different epidemic trees varies greatly in UAV images due to height and shooting angle issues. The utilization of a traditional FPN network is not conducive to the model’s detection of targets at different scales (Lin et al. 2017). Thus, this study incorporated the Gather-and-Distribute (GD) mechanism into the original YOLOv8 framework to bolster the ability for multi-scale feature fusion, to circumvent the loss of local detail features during fusion, and to elevate the detection performance for targets of varying scales.
The GD mechanism, proposed by Huawei’s Noah’s Ark Laboratory (Wang et al. 2023), is characterized by its three-module structure: FAM (feature alignment module), IFM (information fusion module), and Inject (information injection module). This mechanism collects, fuses, and distributes information at each scale through its respective modules, effectively circumventing the information loss typically associated with the FPN structure and enhancing the Neck part’s information fusion capabilities. To improve the model’s ability to detect targets of varying sizes, the GD mechanism incorporates two branches: the Low-GD is designed for extracting and fusing large-size feature maps, while the High-GD focuses on extracting and fusing small-size feature maps. The GD mechanism is structured as Fig. 5.

Gather-and-distribute structure
The Low-GD module is designed to integrate shallow feature information and preserve the high-resolution features of small target data. The FAM module facilitates the standardization of feature map dimensions. The fusion feature, generated by the Repblock module, is split channel-wise. Subsequently, the Low-GD fusion feature undergoes the High-FAM module, resulting in a size-unified input feature followed by feature map splicing. Ultimately, the fusion process is administered by Transformer, preceded by a convolution operation to adjust the number of channels for subsequent segmentation and feature distribution. The Low-GD and High-GD modules are show in Figs. 6 and 7.

Low-GD module

High-GD module
Introducing the GD mechanism in the Neck part of the model enhances its multi-scale feature fusion capability. This enables information transmission and fusion between different level feature maps, enabling the model to learn more contour and location information about small target trees; as a result, the detection efficacy of the model on various scale target trees is improved. It effectively addresses the challenges of single detection scale and the difficulty in detecting small targets in UAV remote sensing images within the current forestry remote sensing domain.
Experimental environment and evaluating indicator
The experiment is based on the PyTorch 1.10 framework and the CUDA 11.3 version is used for training. The YOLOv8 is the basic model, the batch-size set to 8, the input image resolution 640 × 640 pixels, the total iteration 200 rounds, the learning rate 0.01, and the SGD optimizer is used. The specific experimental configuration is indicated in Table 2.
To verify the validity of the model, the mean average precision mAP was selected as the index, and the mAP calculated by the precision P and the recall rate R.
To consider comprehensively the two indicators P and R, a \({F}_{1}\)-score is proposed (the weighted harmonic mean of precision and recall), which is the harmonic mean of precision and recall, with a maximum of 1 and a minimum of 0.
TP (true positives) represents the number of targets correctly detected, FP (false positives) the number of background targets detected, and FN (false negatives) the number of targets detected as background. The precision P and the recall rate R affect each other. To comprehensively consider the influence of the two on the accuracy of the model, the average precision AP (average precision) is introduced. In multi-class target detection, the AP is calculated for the target category and averaged to obtain the performance of the mAP evaluation model of the model. The value of mAP is between 0 and 1, and the closer it is to 1, the better the performance of the model and the more accurate the detection.
Please note that the bold emphasis removed from the Tables 3–5. Kindly check and confirm.OK, I see
Results and discussion
Comparative experiments with different models
The target detection algorithm is divided into one-stage and two-stage algorithms. The one-stage algorithm is more in line with the real-time disease detection of aerial images. The training platform and environment remain unchanged. Using the same data set, YOLOv4, YOLOv5, YOLOv7, YOLOX, SSD-VGG16, Faster-RCNN and EfficientDet algorithms are used for training. Three images were used to test the detection effects of different models (Table 3). The detection effect is shown in Fig. 8.

Different model detection effect diagram
Ablation experiment
The pine wood nematode detection model presented in this study focuses on enhancing the backbone network and Neck component of the benchmark model (YOLOv8), adopting Focal-EIoU as the bounding box regression loss. To analyze the performance improvement of each module, we defined A as the benchmark model, B as the MHSA attention mechanism, C as the SPD module, and D as the GD mechanism. Consequently, we designated models A, A + B, A + C, A + D, A + B + C, and A + B + C + D. The evaluation indicators, including mean average precision (mAP), accuracy (P), recall (R) and mAP in each category were used (Table 4).
The benchmark model shows the minimum accuracy; the model proposed in this paper is 6.6% higher than the benchmark YOLOv8 model. The dataset contains a substantial number of diseased trees, with some having small targets, resulting in low detection efficiency under the baseline model.
By incorporating modules B, C, and D, the model surpasses the benchmark in terms of accuracy. The introduction of a multi-head attention mechanism, SPD convolution module, and GD mechanism enhances both feature extraction and fusion capabilities of the model. This enables better extraction of information features from small target trees and further improves the detection ability of the model.
Adding the C module further boosts accuracy compared to the benchmark model, while the SPD module effectively preserves small target information and reduces the likelihood of false detections. However, the absence of an attention mechanism results in a large number of redundant features during extraction, hindering the model’s performance. The accuracy achieved by adding modules A, B, and C is lower than that obtained by adding the D module. This is attributed to the utilization of a conventional FPN structure, which results in inadequate fusion of target features at varying scales and consequently, a less effective performance.
Upon integration of improved modules B, C, and D, irrelevant information is suppressed, and the model’s feature extraction and fusion capabilities are enhanced. The model’s average accuracy improved by 6.6%. Overall, it outperformed the benchmark model, and the detection efficiency for smaller targets was significantly improved (Fig. 9).

Inspection result diagram
Loss function experiment
Compared to the CloU loss function, the Focal-EloU loss function addresses the issue of sample imbalance in the optimization process of bounding box regression tasks, enhancing the contribution of high-quality anchor frames to the bounding box regression loss, minimizing the contribution of low-quality anchor frames. It enhances the model’s attention towards information and compels it to acquire crucial task-related features, thereby augmenting its accuracy. Consequently, this study employed Focal-EIoU loss as the loss function. To validate its effectiveness, WIoU (different parameters), GIoU, DIoU, CIoU and Focal-EIoU comparative experiments were carried out and continued to utilize mAP50, P, R, and the accuracy of both types of targets as performance indicators (Table 5). The results indicate that the Focal-EIoU loss function model demonstrates the highest accuracy.
Conclusion
Based on UAV remote sensing images, the spatio-temporal multi-scale fusion algorithm was used to detect pine wood nematode disease in Huangshan. To address the issue of redundant feature generation in UAV aerial images due to complex surface backgrounds, a multi-head attention mechanism (MHSA) was incorporated into the model to enable adaptive feature control, enhance effective information, and suppress unnecessary data. Additionally, recognizing the limitations of deep neural networks in extracting shallow information for small targets, a small target detection convolution module was incorporated to minimize the loss of fine-grained feature information during the convolution process, thereby enhancing model performance for small target detection. In addition, due to the insufficient feature fusion in the YOLOv8 model, a Gather-and-Distribute (GD) mechanism was introduced to augment the model multi-scale feature fusion capabilities and improve its detection performance for targets of varying scales. Lastly, the Focal-EIoU was used as the bounding box regression loss to effectively enhance model accuracy. An UAV collected pine wood nematode data in Huangshan City, Anhui Province, serving as the experimental verification object. A series of comparative experiments, module ablation tests, and loss function parameter experiments involving various models were designed. The feasibility and effectiveness of the proposed method were expounded from multiple perspectives. The results indicate that the proposed enhanced approach improves the mean average precision (mAP) by 6.6% on the test set in comparison to the benchmark model. Compared to other phase detection algorithms, the method presented in this paper exhibits the highest accuracy, holding significant implications for mitigating the impact of harmful biological infestations, safeguarding greening accomplishments and upholding ecological security. The method proposed utilizes spectral information from visible light imagery for binary classification detection. Considering the distinct color variations at different stages of pine wood nematode infection, future research will explore categorizing the disease into multiple stages based on the severity of infection, such as early, intermediate, and advanced stages. This approach should enable accurate detection of pine trees with varying degrees of infection, particularly in the early stage, thereby enhancing early warning capabilities and facilitating timely detection and treatment. Additionally, by integrating auxiliary remote sensing data sources, multi-source remote sensing data fusion was conducted to further enhance detection accuracy while strengthening overall monitoring performance and enabling timely protection against this devastating infestation.
References
Deng XL, Tong ZJ, Lan YB, Huang ZX (2020) Detection and location of dead trees with pine wilt disease based on deep learning and UAV remote sensing. AgriEngineering 2(2):294–307. https://doi.org/10.3390/agriengineering2020019
Dennison PE, Brunelle AR, Carter VA (2010) Assessing canopy mortality during a mountain pine beetle outbreak using GeoEye-1 high spatial resolution satellite data. Remote Sens Environ 114(11):2431–2435. https://doi.org/10.1016/j.rse.2010.05.018
Guimarães N, Pádua L, Marques P, Silva N, Peres E, Sousa JJ (2020) Forestry remote sensing from unmanned aerial vehicles: a review focusing on the data, processing and potentialities. Remote Sens 12(6):1046. https://doi.org/10.3390/rs12061046
Hao ZQ, Huang JX, Li XD, Sun H, Fang GF (2022) A multi-point aggregation trend of the outbreak of pine wilt disease in China over the past 20 years. For Ecol Manag 505:119890. https://doi.org/10.1016/j.foreco.2021.119890
Hu GS, Wang TX, Wan MZ, Bao WX, Zeng WH (2022) UAV remote sensing monitoring of pine forest diseases based on improved Mask R-CNN. Int J Remote Sens 43(4):1274–1305. https://doi.org/10.1080/01431161.2022.2032455
Huang JX, Lu X, Chen LY, Sun H, Wang SH, Fang GF (2022) Accurate identification of pine wood nematode disease with a deep convolution neural network. Remote Sens 14(4):913. https://doi.org/10.3390/rs14040913
Huang MX, Gong JH, Li S, Zhang B, Hao QT (2012) Study on pine wilt disease hyper-spectral time series and sensitive features. Remote Sens Technol Appl 27(6):954–960 (in Chinese)
Kim SR, Lee WK, Lim CH, Kim M, Kafatos M, Lee SH, Lee SS (2018) Hyperspectral analysis of pine wilt disease to determine an optimal detection index. Forests 9(3):115. https://doi.org/10.3390/f9030115
Lim W, Choi K, Cho W, Chang B, Ko DW (2022) Efficient dead pine tree detecting method in the forest damaged by pine wood nematode (Bursaphelenchus xylophilus) through utilizing unmanned aerial vehicles and deep learning-based object detection techniques. For Sci Technol 18(1):36–43. https://doi.org/10.1080/21580103.2022.2048900
Lin TY, Dollár P, Girshick R, He KM, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, Honolulu, pp 936–944
Liu J, Wang XW (2020) Tomato diseases and pests detection based on improved yolo V3 convolutional neural network. Front Plant Sci 11:898. https://doi.org/10.3389/fpls.2020.00898
Liu S, Qi L, Qin HF, Shi JP, Jia JY (2018) Path aggregation network for instance segmentation. In: 2018 IEEE/CVF conference on computer vision and pattern recognition. IEEE, Salt Lake City, pp 8759–8768
Poona NK, Ismail R (2012) Discriminating the occurrence of pitch canker infection in Pinus radiata forests using high spatial resolution QuickBird data and artificial neural networks. In: 2012 IEEE international geoscience and remote sensing symposium. IEEE, Munich, pp 3371–3374
Sunkara R, Luo T (2023) No more strided convolutions or Pooling: a new CNN building block for Low-Resolution images and Small objects. In: Machine learning and knowledge discovery in databases. Springer Nature Switzerland, pp 443–459. https://doi.org/10.1007/978-3-031-26409-2_27
Terven J, Córdova-Esparza DM, Romero-González JA (2023) A comprehensive review of YOLO architectures in computer vision: from YOLOv1 to YOLOv8 and YOLO-NAS. Mach Learn Knowl Extr 5(4):1680–1716. https://doi.org/10.3390/make5040083
Tian YN, Yang GD, Wang Z, Wang H, Li E, Liang ZZ (2019) Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput Electron Agric 157:417–426. https://doi.org/10.1016/j.compag.2019.01.012
Wang CY, Mark Liao HY, Wu YH, Chen PY, Hsieh JW, Yeh IH (2020) CSPNet: a new backbone that can enhance learning capability of CNN. In: 2020 IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW). IEEE, Seattle, pp 1571–1580
Wang CC, He W, Nie Y, Guo JY, Liu CJ, Han K, Wang YH (2023) Gold-YOLO: efficient object detector via gather-and-distribute mechanism. https://doi.org/10.48550/arXiv.2309.11331
Wu KJ, Zhang JT, Yin XC, Wen S, Lan YB (2023) An improved YOLO model for detecting trees suffering from pine wilt disease at different stages of infection. Remote Sens Lett 14(2):114–123. https://doi.org/10.1080/2150704x.2022.2161843
Yuan Y, Hu XY (2016) Random forest and objected-based classification for forest pest extraction from UAV aerial imagery. Int Arch Photogramm Remote Sens Spatial Inf Sci XLI-B1:1093–1098
Zhang JZ, Cong SJ, Zhang G, Ma YJ, Zhang Y, Huang JP (2022) Detecting pest-infested forest damage through multispectral satellite imagery and improved UNet+. Sensors (Basel) 22(19):7440. https://doi.org/10.3390/s22197440
Zheng ZH, Wang P, Liu W, Li JZ, Ye RG, Ren DW (2020) Distance-IoU loss: faster and better learning for bounding box regression. Proc AAAI Conf Artif Intell 34(7):12993–13000. https://doi.org/10.1609/aaai.v34i07.6999
Zhou HW, Yuan XP, Zhou HY, Shen HY, Ma L, Sun LP, Fang GF (2022) Sun H (2022) Surveillance of pine wilt disease by high resolution satellite. J for Res 33:1401–1408. https://doi.org/10.1007/s11676-021-01423-8
Zhu XH, Wang RR, Shi W, Yu Q, Li XT, Chen XW (2023) Automatic detection and classification of dead nematode-infested pine wood in stages based on YOLO v4 and GoogLeNet. Forests 14(3):601. https://doi.org/10.3390/f14030601
Zhu XK, Lyu SC, Wang X, Zhao Q (2021) TPH-YOLOv5: improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In: 2021 IEEE/CVF international conference on computer vision workshops (ICCVW). IEEE, Montreal, pp 2778–2788
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Project funding: This study was funded by The National Natural Science Foundation of China (32271865), The Fundamental Research Funds for Central Universities (2572023CT16), and the Fundamental Research Funds for Natural Science Foundation of Heilongjiang for Distinguished Young Scientists (JQ2023F002).
The online version is available at https://link.springer.com/.
Corresponding editor: Lei Yu.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, C., Li, K., Ji, Y. et al. A spatio-temporal multi-scale fusion algorithm for pine wood nematode disease tree detection. J. For. Res. 35, 109 (2024). https://doi.org/10.1007/s11676-024-01754-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11676-024-01754-2