
Abstract
Gaussian processes are powerful non-parametric probabilistic models for stochastic functions. However, the direct implementation entails a complexity that is computationally intractable when the number of observations is large, especially when estimated with fully Bayesian methods such as Markov chain Monte Carlo. In this paper, we focus on a low-rank approximate Bayesian Gaussian processes, based on a basis function approximation via Laplace eigenfunctions for stationary covariance functions. The main contribution of this paper is a detailed analysis of the performance, and practical recommendations for how to select the number of basis functions and the boundary factor. Intuitive visualizations and recommendations, make it easier for users to improve approximation accuracy and computational performance. We also propose diagnostics for checking that the number of basis functions and the boundary factor are adequate given the data. The approach is simple and exhibits an attractive computational complexity due to its linear structure, and it is easy to implement in probabilistic programming frameworks. Several illustrative examples of the performance and applicability of the method in the probabilistic programming language Stan are presented together with the underlying Stan model code.
Similar content being viewed by others
1 Introduction
Gaussian processes (GPs) are flexible statistical models for specifying probability distributions over multi-dimensional non-linear functions (Rasmussen and Williams 2006; Neal 1997). Their name stems from the fact that any finite set of function values is jointly distributed as a multivariate Gaussian distribution. GPs are defined by a mean and a covariance function. The covariance function encodes our prior assumptions about the functional relationship, such as continuity, smoothness, periodicity and scale properties. GPs not only allow for non-linear effects but can also implicitly handle interactions between input variables (covariates). Different types of covariance functions can be combined for further increased flexibility. Due to their generality and flexibility, GPs are of broad interest across machine learning and statistics (Rasmussen and Williams 2006; Neal 1997). Among others, they find application in the fields of spatial epidemiology (Diggle 2013; Carlin et al. 2014), robotics and control (Deisenroth et al. 2015), signal processing (Särkkä et al. 2013), neuroimaging (Andersen et al. 2017) as well as Bayesian optimization and probabilistic numerics (Roberts 2010; Briol et al. 2015; Hennig et al. 2015).
The key element of a GP is the covariance function that defines the dependence structure between function values at different inputs. However, computing the posterior distribution of a GP comes with a computational issue because of the need to invert the covariance matrix. Given n observations in the data, the computational complexity and memory requirements of computing the posterior distribution for a GP in general scale as \(O(n^3)\) and \(O(n^2)\), respectively. This limits their application to rather small data sets of a few tens of thousands observations at most. The problem becomes more severe when performing full Bayesian inference via sampling methods, where in each sampling step we need \(O(n^3)\) computations when inverting the Gram matrix of the covariance function, usually through Cholesky factorization. To alleviate these computational demands, several approximate methods have been proposed.
Sparse GPs are based on low-rank approximations of the covariance matrix. The low-rank approximation with \(m \ll n\) inducing points implies reduced memory requirements of O(nm) and corresponding computational complexity of \(O(nm^2)\). A unifying view on sparse GPs based on approximate generative methods is provided by Quiñonero-Candela and Rasmussen (2005), while a general review is provided by Rasmussen and Williams (2006). Burt et al. (2019) show that for regression with normally distributed covariates in D dimensions and using the squared exponential covariance function, \(M=O(\log ^DN)\) is sufficient for an accurate approximation. An alternative class of low-rank approximations is based on forming a basis function approximation with \(m \ll n\) basis functions. The basis functions are usually presented explicitly, but can also be used to form a low-rank covariance matrix approximation. Common basis function approximations rest on the spectral analysis and series expansions of GPs (Loève 1977; Van Trees 1968; Adler 1981; Cramér and Leadbetter 2013). Sparse spectrum GPs are based on a sparse approximation to the frequency domain representation of a GP (Lázaro Gredilla 2010; Quiñonero-Candela et al. 2010; Gal and Turner 2015). Recently, Hensman et al. (2017) presented a variational Fourier feature approximation for GPs that was derived for the Matérn class of kernels. Another related method for approximating kernels relies on random Fourier features (Rahimi and Recht 2008, 2009). Certain spline smoothing basis functions are equivalent to GPs with certain covariance functions (Wahba 1990; Furrer and Nychka 2007). Recent related work based on a spectral representation of GPs as an infinite series expansion with the Karhunen-Loève representation (see, e.g., Grenander 1981) is presented by Jo et al. (2019). Yet another approach is to present Gaussian process using precision matrix, which is the inverse of the covariance matrix. If the precision matrix is sparse, computation taking the benefit of that sparsity can scale much better than \(O(n^3)\). See, for example, review by Lindgren et al. (2022).
In this paper, we focus on a recent framework for fast and accurate inference for fully Bayesian GPs using basis function approximations based on approximation via Laplace eigenfunctions for stationary covariance functions proposed by Solin and Särkkä (2020). Using a basis function expansion, a GP is approximated with a linear model which makes inference considerably faster. The linear model structure makes GPs easy to implement as building blocks in more complicated models in modular probabilistic programming frameworks, where there is a big benefit if the approximation specific computation is simple. Furthermore, a linear representation of a GP makes it easier to be used as latent function in non-Gaussian observational models allowing for more modelling flexibility. The basis function approximation via Laplace eigenfunctions can be made arbitrary accurate and the trade-off between computational complexity and approximation accuracy can easily be controlled.
The Laplace eigenfunctions can be computed analytically and they are independent of the particular choice of the covariance function including the hyperparameters. While the pre-computation cost of the basis functions is \(O(m^2n)\), the computational cost of learning the covariance function parameters is \(O(mn+m)\) in every step of the optimizer or sampler. This is a big advantage in terms of speed for iterative algorithms such as Markov chain Monte Carlo (MCMC). Another advantage is the reduced memory requirements of automatic differentiation methods used in modern probabilistic programming frameworks, such as Stan (Carpenter et al. 2017) and others. This is because the memory requirements of automatic differentiation scale with the size of the autodiff expression tree which in direct implementations is simpler for basis function than covariance matrix-based approaches. The basis function approach also provides an easy way to apply a non-centered parameterization of GPs, which reduces the posterior dependency between parameters representing the estimated function and the hyperparameters of the covariance function, which further improves MCMC efficiency.
While Solin and Särkkä (2020) have fully developed the mathematical theory behind this specific approximation of GPs, further work is needed for its practical implementation in probabilistic programming frameworks. In this paper, the interactions among the key factors of the method such as the number of basis functions, domain of the prediction space, and properties of the true functional relationship between covariates and response variable, are investigated and analyzed in detail in relation to the computational performance and accuracy of the method. Practical recommendations are given for the values of the key factors based on simple diagnostic values and intuitive graphical summaries that encode the recognized relationships. Our recommendations help users to choose valid and optimized values for these factors, improving computational performance without sacrificing modeling accuracy. The proposed diagnostic can be used to check whether the chosen values for the number of basis functions and the domain of the prediction space are adequate to model the data well. On that basis, we also develop an iterative procedure to achieve accuracte approximation performance with minimal computational costs.
We have implemented the approach in the probabilistic programming language Stan (Carpenter et al. 2017) as well as subsequently in the brms package (Bürkner 2017) of the R software (R Core Team 2019). Several illustrative examples of the performance and applicability of the method are shown using both simulated and real datasets. All examples are accompanied by the corresponding Stan code. Although there are several GP specific software packages available to date, for example, GPML (Rasmussen and Nickisch 2010), GPstuff (Vanhatalo et al. 2013), GPy (GPy 2012), and GPflow (Matthews et al. 2017), each provide efficient implementations only for a restricted range of GP-based models. In this paper, we do not focus on the fastest possible inference for a small set of specific GP models, but instead we are interested in how GPs can be easily used as modular components in probabilistic programming frameworks.
The remainder of the paper is structured as follows. In Sect. 2, we introduce GPs, covariance functions and spectral density functions. In Sect. 3, the reduced-rank approximation to GPs proposed by Solin and Särkkä (2020) is described. In Sect. 4, the accuracy of these approximations under several conditions is studied using both analytical and numerical methods. Practical diagnostics are developed there as well. Several case studies in which we fit exact and approximate GPs to real and simulated data are provided in Sect. 5. A brief conclusion of the work is made in Sect. 6. Appendix A includes a brief presentation of the mathematical details behind the Hilbert space approximation of a stationary covariance function, and Appendix B presents a low-rank representation of a GP for the particular case of a periodic covariance function. Online supplemental material with more case studies illustrating the performance and applicability of the method can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper in the subfolder online_supplemental_material.
2 Gaussian process as a prior
A GP is a stochastic process which defines the distribution of a collection of random variables indexed by a continuous variable, that is, \(\left\{ f(t): t \in \mathcal {T}\right\} \) for some index set \(\mathcal {T}\). GPs have the defining property that the marginal distribution of any finite subset of random variables, \(\left\{ f(t_1), f(t_2), \ldots , f(t_N) \right\} \), is a multivariate Gaussian distribution.
In this work, GPs will take the role of a prior distribution over function spaces for non-parametric latent functions in a Bayesian setting. Consider a data set \(\mathcal {D} = \left\{ ({\varvec{x}}_n, y_n) \right\} _{n=1}^N\), where \(y_n\) is modelled conditionally as \(p(y_n \mid f({\varvec{x}}_n),\phi )\), where p is some parametric distribution with parameters \(\phi \), and f is an unknown function with a GP prior, which depends on an input \({\varvec{x}}_n\in \mathrm{I\!R}^D\). This generalizes readily to more complex models depending on several unknown functions, for example such as \(p(y_n \mid f({\varvec{x}}_n),g({\varvec{x}}_n))\) or multilevel models. Our goal is to obtain the posterior distribution for the value of the function \(\tilde{f}=f(\tilde{{\varvec{x}}})\) evaluated at a new input point \(\tilde{{\varvec{x}}}\).
We assume a GP prior for \(f \sim {{\,\mathrm{\mathcal{G}\mathcal{P}}\,}}(\mu ({\varvec{x}}), k({\varvec{x}}, {\varvec{x}}'))\), where \(\mu : \mathrm{I\!R}^D \rightarrow \mathrm{I\!R}\) and \(k: \mathrm{I\!R}^D \times \mathrm{I\!R}^D \rightarrow \mathrm{I\!R}\) are the mean and covariance functions, respectively,
The mean and covariance functions completely characterize the GP prior, and control the a priori behavior of the function f. Let \({\varvec{f}}=\left\{ f({\varvec{x}}_n) \right\} _{n=1}^N\), then the resulting prior distribution for \({\varvec{f}}\) is a multivariate Gaussian distribution \({\varvec{f}} \sim {{\,\textrm{Normal}\,}}({\varvec{\mu }}, {\varvec{K}})\), where \({\varvec{\mu }} = \left\{ \mu ({\varvec{x}}_n) \right\} _{n=1}^N\) is the mean and \({\varvec{K}}\) the covariance matrix, where \(K_{i,j}=k({\varvec{x}}_i,{\varvec{x}}_j)\). In the following, we focus on zero-mean Gaussian processes, that is set \(\mu ({\varvec{x}}) = 0\). The covariance function \(k({\varvec{x}}, {\varvec{x}}')\) might depend on a set of hyperparameters, \({\varvec{\theta }}\), but we will not write this dependency explicitly to ease the notation. The joint distribution of \({\varvec{f}}\) and a new \(\tilde{f}\) is also a multivariate Gaussian as,
where \({\varvec{k}}_{{\varvec{f}},\tilde{f}}\) is the covariance between \({\varvec{f}}\) and \(\tilde{f}\), and \(k_{\tilde{f},\tilde{f}}\) is the prior variance of \(\tilde{f}\).
If \(p(y_n \mid f({\varvec{x}}_n),\phi )={{\,\textrm{Normal}\,}}(y_n \mid f({\varvec{x}}_n),\sigma )\) then \({\varvec{f}}\) can be integrated out analytically (with a computational cost of \(O(n^3)\) for exact GPs and \(O(nm^2)\) for sparse GPs). If \(p(y_n \mid f({\varvec{x}}_n),g({\varvec{x}}_n))={{\,\textrm{Normal}\,}}(y_n \mid f({\varvec{x}}_n),g({\varvec{x}}_n))\) or \(p(y_n \mid f({\varvec{x}}_n),\phi )\) is non-Gaussian, the marginalization does not have a closed-form solution. Furthermore, if a prior distribution is imposed on \(\phi \) and \({\varvec{\theta }}\) to form a joint posterior for \(\phi \), \({\varvec{\theta }}\) and \({\varvec{f}}\), approximate inference such as Markov chain Monte Carlo (MCMC; Brooks et al. 2011), Laplace approximation (Williams and Barber 1998; Rasmussen and Williams 2006), expectation propagation (Minka 2001), or variational inference methods (Gibbs and MacKay 2000; Csató et al. 2000) are required. In this paper, we focus on the use of MCMC for integrating over the joint posterior. MCMC is usually not the fastest approach, but it is flexible and allows accurate inference and uncertainty estimates for general models in probabilistic programming settings. We consider the computational costs of GPs specifically from this point of view.
2.1 Covariance functions and spectral density
The covariance function is the crucial ingredient in a GP as it encodes our prior assumptions about the function, and characterizes the correlations between function values at different locations in the input space. A covariance function needs to be symmetric and positive semi-definite (Rasmussen and Williams 2006). A stationary covariance function is a function of \({\varvec{\tau }}={\varvec{x}}-{\varvec{x}}' \in \mathrm{I\!R}^D\), such that it can be written \(k({\varvec{x}},{\varvec{x}}') = k({\varvec{\tau }})\), which means that the covariance is invariant to translations. Isotropic covariance functions depend only on the input points through the norm of the difference, \(k({\varvec{x}},{\varvec{x}}') = k(|{\varvec{x}}-{\varvec{x}}'|) = k(r), r\in \mathrm{I\!R}\), which means that the covariance is both translation and rotation invariant. The most commonly used distance between observations is the L2-norm \((|{\varvec{x}}-{\varvec{x}}'|_{L2})\), also known as Euclidean distance, although other types of distances can be considered.
The Matérn class of isotropic covariance functions is given by,
where \(\nu > 0\) is the order the kernel, \(K_{\nu }\) the modified Bessel function of the second kind, and the \(\ell > 0\) and \(\alpha > 0\) are the length-scale and magnitude (marginal variance), respectively, of the kernel. The particular case where \(\nu =\infty \), \(\nu =3/2\) and \(\nu =5/2\) are probably the most commonly used kernels (Rasmussen and Williams 2006),
The former is commonly known as the squared exponential or exponentiated quadratic covariance function. As an example, assuming the Euclidean distance between observations, \(r=|{\varvec{x}}-{\varvec{x}}'|_{L2}=\sqrt{\sum _{i=1}^{D}(x_i-x_i')^2}\), the kernel \(k_{\infty }\) written above takes the form
Notice that the previous expressions \(k_{\infty }(r)\) has been easily generalized to using a multidimensional length-scale \({\varvec{\ell }}\in \mathrm{I\!R}^D\). Using individual length-scales for each dimension turns an isotropic covariance function into a non-isotropic covariance function. That is, for a non-isotropic covariance function, the smoothness may vary across different input dimensions.
Stationary covariance functions can be represented in terms of their spectral densities (see, e.g., Rasmussen and Williams 2006). In this sense, the covariance function of a stationary process can be represented as the Fourier transform of a positive finite measure (Bochner’s theorem; see, e.g., Akhiezer and Glazman 1993). If this measure has a density, it is known as the spectral density of the covariance function, and the covariance function and the spectral density are Fourier duals, known as the Wiener-Khintchine theorem (Rasmussen and Williams 2006). The spectral density functions associated with the Matérn class of covariance functions are given by
in D dimensions, where vector \({\varvec{\omega }}\in \mathrm{I\!R^D}\) is in the frequency domain, and \(\ell \) and \(\alpha \) are the length-scale and magnitude (marginal variance), respectively, of the kernel. The particular cases, where \(\nu =\infty \), \(\nu =1/2\), \(\nu =3/2\) and \(\nu =5/2\), take the form
For instance, with input dimensionality \(D=3\) and \({\varvec{\omega }}=(\omega _1,\omega _2,\omega _3)^\intercal \), the spectral densities written above take the form
where individual length-scales \(\ell _i\) for each frequency dimension \(\omega _i\) have been used.
3 Hilbert space approximate Gaussian process model
The approximate GP method, developed by Solin and Särkkä (2020) and further analysed in this paper, is based on considering the covariance operator of a stationary covariance function as a pseudo-differential operator constructed as a series of Laplace operators. Then, the pseudo-differential operator is approximated with Hilbert space methods on a compact subset \(\varOmega \subset \mathrm{I\!R}^D\) subject to boundary conditions. For brevity, we will refer to these approximate Gaussian processes as HSGPs. Below, we will present the main results around HSGPs relevant for practical applications. More details on the theoretical background are provided by Solin and Särkkä (2020). Our starting point for presenting the method is the definition of the covariance function as a series expansion of eigenvalues and eigenfunctions of the Laplacian operator. The mathematical details of this approximation are briefly presented in Appendix A.
3.1 Unidimensional GPs
We begin by focusing on the case of a unidimensional input space (i.e., on GPs with just a single covariate) such that \(\varOmega \in [-L,L] \subset \mathrm{I\!R}\), where L is some positive real number to which we also refer as boundary condition. As \(\varOmega \) describes the interval in which the approximations are valid, L plays a critical role in the accuracy of HSGPs. We will come back to this issue in Sect. 4.
Within \(\varOmega \), we can write any stationary covariance function with input values \(x,x' \in \varOmega \) as
where \(s_{\theta }\) is the spectral density of the stationary covariance function k (see Sect. 2.1) and \(\theta \) is the set of hyperparameters of k (Rasmussen and Williams 2006). The terms \(\{\lambda _j\}_{j=1}^{\infty }\) and \(\{\phi _j(x)\}_{j=1}^{\infty }\) are the sets of eigenvalues and eigenvectors, respectively, of the Laplacian operator in the given domain \(\varOmega \). Namely, they satisfy the following eigenvalue problem in \(\varOmega \) when applying the Dirichlet boundary condition (other boundary conditions could be used as well)
The eigenvalues \(\lambda _j>0\) are real and positive because the Laplacian is a positive definite Hermitian operator, and the eigenfunctions \(\phi _j\) for the eigenvalue problem in Eq. (5) are sinusoidal functions. The solution to the eigenvalue problem is independent of the specific choice of covariance function and is given by
If we truncate the sum in Eq. (4) to the first m terms, the approximate covariance function becomes
where \({\varvec{\phi }}(x)=\{\phi _j(x)\}_{j=1}^{m} \in \mathrm{I\!R}^{m}\) is the column vector of basis functions, and \(\varDelta \in \mathrm{I\!R}^{m\times m}\) is a diagonal matrix of the spectral density evaluated at the square root of the eigenvalues, that is, \(s_{\theta }(\sqrt{\lambda _j})\),
Thus, the Gram matrix \({\varvec{K}}\) for the covariance function k for a set of observations \(i=1,\ldots ,n\) and corresponding input values \(\{x_i\}_{i=1}^{n}\) can be represented as
where \(\varPhi \in \mathrm{I\!R}^{n\times m}\) is the matrix of eigenfunctions \(\phi _j(x_i)\)
As a result, the model for f can be written as
This equivalently leads to a linear representation of f via
where \(\beta _j \sim {{\,\textrm{Normal}\,}}(0,1)\). Thus, the function f is approximated with a finite basis function expansion (using the eigenfunctions \(\phi _j\) of the Laplace operator), scaled by the square root of spectral density values. A key property of this approximation is that the eigenfunctions \(\phi _j\) do not depend on the hyperparameters of the covariance function \(\theta \). Instead, the only dependence of the model on \(\theta \) is through the spectral density \(s_{\theta }\). The eigenvalues \(\lambda _j\) are monotonically increasing with j and \(s_{\theta }\) goes rapidly to zero for bounded covariance functions. Therefore, Eq. (8) can be expected to be a good approximation for a finite number of m terms in the series as long as the inputs values \(x_i\) are not too close to the boundaries \(-L\) and L of \(\varOmega \). The computational cost of evaluating the log posterior density of univariate HSGPs scales as \(O(nm + m)\), where n is the number of observations and m the number of basis functions.
The parameterization in Eq. (8) is naturally in the non-centered parameterization form with independent prior distribution on \(\beta _j\), which can make the posterior inference easier (see, e.g., Betancourt and Girolami 2019). Furthermore, all dependencies on the covariance function and the hyperparameters is through the prior distribution of the regression weights \(\beta _j\). The posterior distribution of the parameters \(p({\varvec{\beta }}|{\varvec{y}})\) is a distribution over a m-dimensional space, where m is much smaller than the number of observations n. Therefore, the parameter space is greatly reduced and this makes inference faster, especially when sampling methods are used.
3.2 Generalization to multidimensional GPs
The results from the previous section can be generalized to a multidimensional input space with compact support, \(\varOmega =[-L_1,L_1] \times \dots \times [-L_D,L_D]\) and Dirichlet boundary conditions. In a D-dimensional input space, the total number of eigenfunctions and eigenvalues in the approximation is equal to the number of D-tuples, that is, possible combinations of univariate eigenfunctions over all dimensions. The number of D-tuples is given by
where \(m_d\) is the number of basis function for the dimension d. Let \(\mathbb {S}\in \mathrm{I\!N}^{m^{*} \times D}\) be the matrix of all those D-tuples. For example, suppose we have \(D=3\) dimensions and use \(m_{1}=2\), \(m_{2}=2\) and \(m_{3}=3\) eigenfunctions and eigenvalues for the first, second and third dimension, respectively. Then, the number of multivariate eigenfunctions and eigenvalues is \(m^{*} = m_{1} \cdot m_{2} \cdot m_{3} = 12\) and the matrix \(\mathbb {S}\in \mathrm{I\!N}^{12 \times 3}\) is given by
Each multivariate eigenfunction \(\phi ^{*}_j:\varOmega \rightarrow \mathrm{I\!R}\) corresponds to the product of the univariate eigenfunctions whose indices corresponds to the elements of the D-tuple \(\mathbb {S}_{j\cdot p}\), and each multivariate eigenvalue \({\varvec{\lambda }}^{*}_j\) is a D-vector with elements that are the univariate eigenvalues whose indices correspond to the elements of the D-tuple \(\mathbb {S}_{j{\varvec{\cdot p}}}\). Thus, for \({\varvec{x}}=\{x_d\}_{d=1}^D \in \varOmega \) and \(j=1,2,\ldots ,m^{*}\), we have
The approximate covariance function is then represented as
where \(s^{*}_{\theta }\) is the spectral density of the D-dimensional covariance function (see Sect. 2.1) as a function of \(\sqrt{{\varvec{\lambda }}^{*}_j}\) that denotes the element-wise square root of the vector \({\varvec{\lambda }}^{*}_j\). We can now write the approximate series expansion of the multivariate function f as
where, again, \(\beta _j \sim {{\,\textrm{Normal}\,}}(0,1)\). The computational cost of evaluating the log posterior density of multivariate HSGPs scales as \(O(n m^{*} + m^{*})\), where n is the number of observations and \(m^{*}\) is the number of multivariate basis functions. Although this still implies linear scaling in n, the approximation is more costly than in the univariate case, as \(m^{*}\) is the product of the number of univariate basis functions over the input dimensions and grows exponentially with respect to the number of dimensions.
3.3 Linear representation of a periodic squared exponential covariance function
A GP model with a periodic covariance function does no fit in the framework of the HSGP approximation covered in this study as a periodic covariance function has not a spectral representation, but it has also a low-rank representation. In Appendix B, we briefly present the approximate linear representation of a periodic squared exponential covariance function as developed by Solin and Särkkä (2014), analyze the accuracy of this approximation and, finally, derive the GP model with this approximate periodic squared exponential covariance function.
4 The accuracy of the approximation
The accuracy and speed of the HSGP model depends on several interrelated factors, most notably on the number of basis functions and on the boundary condition of the Laplace eigenfunctions. Furthermore, appropriate values for these factors will depend on the degree of non-linearity (wigglyness/smoothness) of the function to be estimated, which is in turn characterized by the length-scale of the covariance function. In this section, we analyze the effects of the number of basis functions and the boundary condition on the approximation accuracy. We present recommendations on how they should be chosen and diagnostics to check the accuracy of the obtained approximation.
Ultimately, these recommendations are based on the relationships among the number of basis functions m, the boundary condition L, and the length-scale \(\ell \), which depend on the particular choice of the kernel function. In this work we investigate these relationships for the squared exponential and the Matérn (\(\nu =3/2\) and \(\nu =5/2\)) covariance functions in the present section, and for the periodic squared exponential covariance function in Appendix B. For other kernels, the relationships will be slightly different depending on the smoothness or wigglyness of the non-linear effects generated from the covariance function.
4.1 Dependency on the number of basis functions and the boundary condition
As explained in Sect. 3, the approximation of the covariance function is a series expansion of eigenfunctions and eigenvalues of the Laplace operator in a given domain \(\varOmega \), for instance in a one-dimensional input space \(\varOmega =[-L,L]\subset \mathrm{I\!R}\)
where L describes the boundary condition, j is the index for the eigenfunctions and eigenvalues, and \(\tau =x-x'\) is the difference between two covariate values x and \(x'\) in \(\varOmega \). The eigenvalues \(\lambda _j\) and eigenfunctions \(\phi _j\) are given in Eqs. (6) and (7) for the unidimensional case and in Eqs. (11) and (12) for the multidimensional case. The number of basis functions can be truncated at some finite positive value m such that the total variation difference between the exact and approximate covariance functions is less than a predefined threshold \(\varepsilon > 0\):
This inequality can be satisfied for arbritrary small \(\epsilon \) provided that L and m are sufficiently large (Solin and Särkkä 2020, Theorem 1 and 4). The specific number of basis functions m needed depends on the degree of non-linearity of the function to be estimated, that is on its length-scale \(\ell \), which constitutes a hyperparameter of the GP. The approximation also depends on the boundary L (see Eqs. (6), (7), (11) and (12)), which will affect its accuracy especially near the boundaries. As we will see later on, L will also influence the number of basis functions required in the approximation.
In this work, we choose L such that the domain \(\varOmega = \left[ -L, L\right] \) contains all the inputs points \(x_i\), and the set \(\{x_i\}_{i=1}^n\) of input points is centered around zero. Let
then it follows that \(x_i \in \left[ -S, S\right] \) for all i. We now define L as
where \(S > 0\) represents the maximum absolute value of the input space, and \(c \ge 1\) is the proportional extension factor. In the following, we will refer to c as the boundary factor of the approximation. The boundary factor can also be regarded as the boundary L normalized by the boundary S. Notice that \({\varvec{x}}\) need not be symmetric around zero, but need to be contained in \(\left[ -S, S\right] \) (although it is recommended that \({\varvec{x}}\) fits tightly the interval \(\left[ -S, S\right] \) to optimize computation and the iterative diagnostic presented in Sect. 4.5).

Mean posterior predictive functions (top), posterior standard deviations (center), and covariance functions (bottom) of both the exact GP model (red line) and the HSGP model for (1) different number of basis functions m, with the boundary factor fixed to a large enough value (left column) and (2) different values of the boundary factor c, with a large enough fixed number of basis functions (right column)

Posterior mean predictive functions (top), posterior standard deviations (center) and covariance functions (bottom) of both the exact GP model and the HSGP model for different number of basis functions m and for different values of the boundary factor c (columns)
We start by illustrating how the number of basis functions m and boundary factor c influence the accuracy of the HSGP approximations individually. For this purpose, a set of noisy observations are drawn from an exact GP model with a squared exponential covariance function of length-scale \(\ell =0.3\) and marginal variance \(\alpha =1\), using input values within the interval \([-1,1]\) that leads to a boundary S of \(S=1\) as per Eq. (16). In this case the domain of input points \(x_i\) matches exactly the interval \(\left[ -S, S\right] \). Several HSGP models with varying m and c are fitted to this data. In this example, the length-scale and marginal variance parameters used in the HSGPs are fixed to the true values of the data-generating model. Figures 1 and 1 illustrate the individual effects of m and c, respectively, on the posterior predictive mean and standard deviation of the estimated function as well as on the covariance function itself. For a sufficiently large fixed value of c, Fig. 1 shows clearly how m affects the accuracy on the approximation for both the posterior mean or uncertainty. It is seen that if the number of basis functions m is too small, the estimated function tend to be overly smooth because the necessary high frequency components are missing. In general, the higher the degree of wigglyness of the function to be estimated, the larger number of basis functions will be required. If m is fixed to a sufficiently large value, Fig. 1 shows that c affects the approximation of the mean mainly near the boundaries, while the approximation of the standard deviation is affected across the whole domain. The approximation error tends to be bigger for the standard deviation than for the mean.
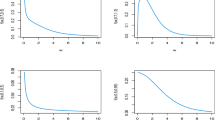
Next, we analyze how the interaction between m and c affects the quality of the approximation. The length-scale and marginal variance of the covariance function will no longer be fixed but instead we compute the joint posterior distribution of the function values and the hyperparameters using the dynamic HMC (Betancourt 2017) algorithm implemented in Stan (Stan Development Team 2021) for both the exact GP and the HSGP models. Figure 2 shows the posterior predictive mean and standard deviation of the function as well as the covariance function obtained after fitting the model for varying m and c. Figure 3 shows the root mean square error (RMSE) of the HSGP models computed against the exact GP model. Figure 4 shows the estimated length-scale and marginal variance for the exact GP model and the HSGP models. Looking at the RMSEs in Fig. 3, we can conclude that the optimal choice in terms of precision and computation time for this example would be \(m = 15\) basis functions and a boundary factor between \(c = 1.5\) and \(c = 2.5\). Further, the less conservative choice of \(m = 10\) and \(c = 1.5\) could also produce a sufficiently accurately approximation depending on the application. We may also come to the same conclusion by looking at the posterior predictions and covariance function plots in Fig. 2. From these results, some general conclusions may be drawn:
-
As c increases, m has to increase as well (and vice versa). This is consistent with the expression for the eigenvalues in Eq. (6), where L appears in the denominator.
-
There exists a minimum c below which an accurate approximation will never be achieved regardless of the number of basis functions m.

Root mean square error (RMSE) of the proposed HSGP models computed against the exact GP model. RMSE versus the number of basis functions m and for different values of the boundary factor c (left). RMSE versus the boundary factor c and for different values of the number of basis functions m (right)

Estimated length-scale (left) and marginal variance (right) parameters of both exact GP and HSGP models, plotted versus the number of basis functions m and for different values of the boundary factor c
4.2 Near linear proportionality between m, c and \(\ell \)
A priori, the terms in the series expansion (14) with very small spectral density are unlikely to contribute to the approximation. Given the boundary factor c and the length-scale \(\ell \), we can compute the cumulative sum of the spectral densities and find out how many basis functions are, a priori, explaining almost 100% of the variation. Thus, given c and \(\ell \), we can estimate a good choice for the number of basis functions m for any covariance function.
When considering squared exponential and Matérn covariance functions, we can show with simple algebra that when c is larger than the minimal value recommendation, the number of m first terms needed to explain almost 100% of the variation has a near linear relationship with \(\ell \) and c. With decreasing \(\ell \), the m should grow near linearly with \(1/\ell \), and with increasing c, the m should grow near linearly with c. This is natural as with decreasing \(\ell \), more higher frequency basis functions are needed. With increasing c, as a smaller range of the basis functions are used in the approximation, the expected number of zero up-crossings goes down linearly with c, and thus more higher frequency basis functions are needed to compensate this. When c is below our recommendations given \(\ell \) (recommendations that we give later throughout the paper and specifically in the next Sects. 4.3 and 4.3.1), the effect of \(\ell \) and c to the recommended m is more non-linear, but as long as we stay in the recommended range the linearity assumption is useful thumb rule for how to change m, if \(\ell \) or c are changed.
4.3 Empirical discovering of the functional form of the relationships between m, c and \(\ell \)

Relation among the minimum number of basis functions m, the boundary factor c (\(c = \frac{L}{S}\)) and the length-scale \(\ell \) normalized by the input space boundary S (\(\frac{\ell }{S}\)), for the squared exponential, Matérn (\(\nu \)=3/2) and Matérn (\(\nu \)=5/2) covariance functions
Empirical simulations are carried out to analyze the relationships between m, c and \(\ell \). Figure 5 depicts how m, c and \(\frac{\ell }{S}\) (lengthscale \(\ell \) normalized by the input space boundary S) interact and affect the accuracy of the HSGP approximation for a GP with squared exponential, Matérn (\(\nu \)=3/2), and Matérn (\(\nu \)=5/2) covariance functions and a single input dimension. More precisely, for a given GP model (with a particular covariance function) with length-scale \(\ell \) and given a input space boundary S and a boundary factor c, Fig. 5 shows the minimum number of basis functions m required to obtain an accurate approximation in the sense of satisfying Eq. (15). We considered an approximation to be a sufficiently accurate when the total variation difference between the approximate and exact covariance functions, \(\varepsilon \) in Eq. (15), is below 1\(\%\) of the total area under the curve of the exact covariance function k such that
where \(\tilde{k}_m\) is the approximate covariance function with m basis functions. Alternatively, these figures can be understood as providing the minimum c that we should use for given \(\frac{\ell }{S}\) and m. Of course, we may also read it as providing the minimum \(\frac{\ell }{S}\) that can be approximated with high accuracy given m and c. We obtain the following main conclusions:
-
As \(\ell \) increases, m required for an accurate approximation decreases. (Notice that the larger \(\ell \) the smoother the functions generated from a covariance function, and vice versa; see covariance functions equations in Sect. 2.1.)
-
The lower c, the smaller m can and \(\ell \) must be to achieve an accurate approximation.
-
For a given \(\ell \) there exist a minimum c under which an accurate approximation is never going to be achieved regardless of m. This fact can be seen in Fig. 5 as the contour lines which represent c have an end in function of \(\ell \) (Valid c are restricted in function of \(\ell \)). As \(\ell \) increases, the minimum valid c also increases.
4.3.1 Numerical equations
As explained in Sect. 4.2, when c is large enough, there is a near linear proportionality between m, \(\ell \) and c. To obtain practical numerical functions that can be used to guide the selection of these parameters, we have empirically checked this linear relationship and derived the practically useful constant terms. We require a lower bound for c of \(c \ge 1.2\) such that the equations below are precise enough for practical application.
Squared exponential:
Matérn (\(\nu \)=5/2):
Matérn (\(\nu \)=3/2):
These constants vary monotonically with respect to \(\nu \) (squared exponential corresponding to Matérn with \(\nu \rightarrow \infty \)). Using the formula for Matérn (\(\nu \)=3/2) provides the largest m and c, and thus this formula alone could be used as a conservative choice for all Matérn covariance functions with \(\nu \ge 3/2\) and likely as a good initial guess for many other covariance functions. If the aim is to find minimal m to speedup the computation, a further refined formula can be obtained for new covariance functions.
Figure 5 and previous Eqs. (19)–(22) were obtained for a GP with a unidimensional covariance function, which result in a surfaces depending on three variables, m, c and \(\frac{\ell }{S}\). Equivalent results for a GP model with a two-dimensional covariance function would result in a surface depending on four variables, m, c, \(\frac{\ell _1}{S}\) and \(\frac{\ell _2}{S}\). More precisely, in the multi-dimensional case, whether the approximation is close enough might depend only on the ratio between wigglyness in every dimensions. For instance, in the two-dimensional case, it would depend on the ratio between \(\frac{\ell _1}{S}\) and \(\frac{\ell _2}{S}\). Future research will focus on building useful graphs or analytical models that provide these relations in multi-dimensional cases. However, as an approximation, we can use the unidimensional GP conclusions in Fig. 5 or Eqs. (19)–(22) to check the accuracy by analyzing individually the different dimensions of a multidimensional GP model.
4.4 Relationships between m and \(\ell \) for a periodic squared exponential covariance function
As commented in Sect. 3.3, in Appendix B we present an approximate linear representation of a periodic squared exponential covariance function. In Appendix B, we also analyze the accuracy of this linear representation and derive the minimum number of terms m in the approximation required to achieve a close approximation to the exact periodic squared exponential kernel as a function of the length-scale \(\ell \) of the kernel. Since this is a series expansion of sinusoidal functions, the approximation does not depend on any boundary condition, nor is there a need for a normalized length-scale, since the length-scale refers to the period of a sinusoidal function. This relationship between m and \(\ell \) for a periodic squared exponential covariance function is gathered in Fig. 17 and the numerical equation was estimated in Eq. (B.6) which is depicted next:
4.5 Diagnostics of the approximation
Equations (19), (21), (23) and (B.6) (depending on which kernel is used) provide the minimum length-scale that can be accurately inferred given m and c. This information serves as a powerful diagnostic tool in determining if the obtained accuracy is acceptable. As the length-scale \(\ell \) controls the wigglyness of the function, it strongly influences the difficulty of estimating the latent function from the data. Basically, if the length-scale estimate is accurate, we can expect the HSGP approximation to be accurate as well.
Having obtained an estimate \(\hat{\ell }\) for a HSGP model with prespecified m and c, we can check whether \(\hat{\ell }\) exceeds the smallest length-scale that can be accurately inferred, provided as a function of m and c by Eqs. (19), (21), (23) and (B.6) (depending on which kernel is used). If \(\hat{\ell }\) exceeds this value, the approximation is assumed to be good. If \(\hat{\ell }\) does not exceed this value, the approximation may be inaccurate, and m and/or c need to be increased. In Figs. 3 and 4, \(m = 10\) and \(c = 1.5\) were sufficient for an accurate modeling of function with \(\ell = 0.3\) and \(S=1\), which matches the diagnostic based on Eqs. (19) and (20).
Equations in Sect. 4.3.1 to update m and c imply:
-
c must be big enough for a given \(\ell \), and
-
m must be big enough for given \(\ell \) and c.
If larger than minimal c and m (for a given \(\ell \)) are used in the initial HSGP model, it is likely that the results are already sufficiently accurate. As \(\ell \) is initially unknown, we recommend using this diagnostic in an iterative procedure by starting with c and m based on some initial guess about \(\ell \), and if the estimated \(\hat{\ell }\) is below the diagnostic threshold, select new c and m using \(\hat{\ell }\). This can be repeated until
-
the estimated \(\hat{\ell }\) is larger than the diagnostic threshold given c and m, and
-
the predictive accuracy measures, for example, root mean square error (RMSE), coefficient of determination (\(R^2\)), or expected log predicitve density (ELPD) do not improve.
As commented above, the estimated \(\hat{\ell }\) being larger than diagnostic threshold does not guarantee that the approximate is sufficiently accurate, and thus we recommend to look at the predicitve accuracy measures, too.
Apart from providing a powerful diagnostic tool in determining if the approxiamtion is sufficiently accurate, the equations in the previous Sect. 4.3.1 also provide the optimal values for m (the minimum m required for an accurate approximation) and c (the minimum c that allows for the minimum m) that can be used to minimize the computational cost in repeated computations (e.g., in cross-validation and simulation based calibration). This is even more useful in multi-dimensional cases (\(2 \le D \le 4\)), where knowing the smallest useful value of m for each dimension has even bigger effect on the total computational cost.
4.5.1 A step-by-step user-guide to apply the diagnostics
Based on the above proposed diagnostics, we obtain a simple, iterative step-by-step procedure that users can follow in order to obtain an accurate HSGP approximation. The procedure is split into two phases, Phase A and B, which have to be completed consecutively.
Phase A:
-
A0.
Compute the boundary S of the input values by using Eq. (16).
-
A1.
Set the iteration index to \(k=1\). Make an initial guess on the length-scale \(\ell ^{(k)}\). If there is no useful information available, we recommend to start with a large length-scale, such as the normalized length-scale being in the interval \(\frac{\ell ^{(k)}}{S} \in [0.5, 1]\).
-
A2.
Obtain the minimum valid boundary factor \(c^{(k)}\) determined by \(\ell =\ell ^{(k)}\) for the given kernel and boundary S as per Sect. 4.3.1.
-
A3.
Obtain the mimimum valid number of basis functions \(m^{(k)}\) determined by \(\ell =\ell ^{(k)}\) and \(c = c^{(k)}\) for the given kernel and boundary S as per Sect. 4.3.1.
-
A4.
Fit an HSGP model using \(m^{(k)}\) and \(c^{(k)}\) and ensure convergence of the MCMC chains.
-
A5.
Perform the length-scale diagnostic by checking if \(\hat{\ell }^{(k)} + 0.01 \ge \ell ^{(k)}\).
If the diagnostic is FALSE, the HSGP approximation is not yet sufficiently accurate. Set \(\ell ^{(k+1)} = \hat{\ell }^{(k)}\), increase the iteration index \(k = k + 1\), and go back to A2.
If the diagnostic is TRUE, the HSGP approximation is close to be sufficiently accurate. Continue with Phase B.
Phase B:
-
B1.
For the current HSGP model, compute measures of predictive accuracy, for example, RMSE, \(R^2\), or ELPD.
-
B2.
Set \(m^{(k+1)} = m^{(k)} + 5\) and increase the iteration index \(k = k + 1\).
-
B3.
Obtain the minimum valid boundary factor \(c^{(k)}\) determined by \(\ell = \hat{\ell }^{(k-1)}\) for the given kernel and boundary S as per Sect. 4.3.1.
-
B4.
Obtain the minimum valid length-scale \(\ell ^{(k)}\) that can be accurately estimated by \(m = m^{(k)}\) and \(c = c^{(k)}\) for the given kernel and boundary S as per Sect. 4.3.1.
-
B5.
Fit an HSGP model using \(m^{(k)}\) and \(c^{(k)}\) and ensure convergence of the MCMC chains.
-
B6.
Perform the length-scale diagnostic by checking if \(\hat{\ell }^{(k)} + 0.01 \ge \ell ^{(k)}\).
Check the stability of both \(\hat{\ell }^{(k)}\) and the measures of predictive accuracy relative to the previous iteration.
If all the stability checks succeed, the HSGP approximation of the latest model should be sufficiently accurate and the procedure ends here.
Otherwise, go back to B1.
In our experiments this procedure converges quickly after only few iterations in all the cases (see Fig. 7, Table 1, and Sect. 5). That said, we cannot rule out that there may be cases where convergence is much slower (in terms of number of required diagnostic iterations) to a degree where HSGPs become impractical and an early stopping of the procedure would be advisable. Importantly though, this scenario should not be confused with the scaling of computational cost due to higher dimensional input spaces, an issue discussed in detail in Sect. 4.8. In a nutshell, according to our experiments, increasing the dimensionality of the input space does not increase the number of required diagnostic iterations to a relevant degree but only the computational cost per iteration.
4.6 Performance analysis of the diagnostics
In this section, we first illustrate that accurate estimates of the length-scale implies accurate approximations via HSGPs. Figure 6 left shows a comparison of the length-scale estimates obtained from the exact GP and HSGP models with a squared exponential kernel, from various noisy datasets drawn from underlying functions with varying smoothness. Different values for the number of basis functions m are used when estimating the HSGP models, and the boundary factor c is set to a valid and optimum value in every case by using Eq. (20). Figure 6 (right) shows the RMSE of the HSGP models with the exact GP model as the reference. It can be seen that accurate estimates of the length-scale imply small RMSEs.
Table 1 shows the iterative steps of applying the diagnostic procedure explained in Sect. 4.5.1 over some of the data sets also used in the analysis in Fig. 6. It is clearly visible that by following our recommendations, an optimum solution with minimum computational requirements is achieved in these cases. Figure 7 graphically compares the exact GP length-scale and the estimated HSGP length-scale in every iteration and data set. Between two and four iterations, depending on wigglyness of the function to be learned and the distance between the initial guess of the length scale and the true length scale, are sufficient to reach the optimal values of m and c.
As concrete examples, the iterative steps applied to perform diagnostic on two of the data sets in Table 1 are described in Appendix C.

Exact GP length-scale (\(\ell _{GP}\)) and approximate HSGP length-scale (\(\hat{\ell }\)) for various datasets with varying smoothness (left) and their corresponding root mean squared errors (RMSE) computed with the exact GP model as the reference

Comparison of the true and estimated length-scales in every iteration for the different data sets varying the length-scale
4.7 Other covariance functions
Above, we thoroughly studied the relationship between the number of basis functions in the approximation and the approximation accuracy across different configurations. We specifically focused on the Matérn and squared exponential families of covariance functions, yet there exists other families of stationary covariance functions. The basis function approximation can easily be implemented for any stationary covariance function, where the spectral density function is available. The assess the accuracy of a basis function approximation for a kernel, where the diagnostic plots like Fig. 5 or Eqs. (19)–(22) are not available, we suggest to use the relative total variational distance between the true covariance function and the approximate covariance function as given in Eq. (18). Ensuring that the relative distance is bounded by a small constant for the relevant lengthscale implies a high quality approximation. Another possibility to asses the accuracy of the approximation is to look at the cumulative sum of the spectral densities terms used in the series expansion and find out how much of the total variation they are actually explaining, as already mentioned in Sect. 4.2.
To select c for many other covariance functions, users can be guided by Eqs. (20), (22) and (24), as pointed in Sect. 4.3.1.
4.8 The computational cost in the multi-dimensional setting
The HSGP model is computationally superior to the exact GP in 1D and 2D even for highly wiggly functions, except when the number of data points is so small (\(n \lesssim 300\), i.e., n smaller than some value around 300) that exact GPs are already reasonably fast themselves. However, the computation time of the HSGP model increases rapidly with the number of input dimensions (D) since the number of multivariate basis functions \(m^*=m_1\times \cdots \times m_D\) in the approximation increases exponentially with D (see Eq. (9)). Yet, the HSGP method can still be computationally faster than the exact GP for larger datasets due the latter’s cubic scaling in n.
In our experiments of multivariate problems (see Sect. 5.3.1), the computation time for the HSGP model was faster than for the exact GP for most of the non-linear 2D functions or moderate-to-large sized 3D datasets (\(n \gtrsim 1000\), i.e., n greater than some value around 1000), even for highly wiggly 3D functions (e.g., \(\frac{\ell _1}{S}, \frac{\ell _2}{S}, \frac{\ell _3}{S} \approx 0.1\)).
For small sized datasets (\(n\lesssim 1000\)), HSGPs are likely to be slower than exact GPs already for highly to moderated wiggly 3D functions (e.g., \(\frac{\ell _1}{S} \lesssim 0.1\), and \(\frac{\ell _2}{S}, \frac{\ell _3}{S} \gtrsim 0.3\)) and for overall smooth 4D functions (e.g., \(\frac{\ell _1}{S} \lesssim 0.1\), and \(\frac{\ell _2}{S}, \frac{\ell _3}{S}, \frac{\ell _4}{S} \gtrsim 0.4\)).
As it has been shown in case study III (Sect. 5.3), the proposed diagnostic tool can be very useful for multivariate problems as it allows one to reduce \(m^*\) to the minimum sufficient value, reducing computational time drastically, and still getting an accurate approximation. For example, assuming a squared exponential covariance function, choosing the optimal value for c allows one to use few basis functions in every single dimension (i.e., \(m \lesssim 10\) for \(\frac{\ell }{S} \gtrsim 0.3\); \(20 \gtrsim m \gtrsim 10\) for \(0.3 \gtrsim \frac{\ell }{S} \gtrsim 0.1\); and \(m \gtrsim 20\) for \(\frac{\ell }{S} \lesssim 0.1\)), which, from results presented in Fig. 14, implies that the HSGP model can be, in general terms, useful for highly wiggly 3D functions and smooth 4D functions.
Whether HSGP or exact GP is faster will also depend on the specific implementation details, which can have big effects on the scaling constants. Thus, more detailed recommendations would depend on the specific software implementation.
5 Case studies
In this section, we will present several simulated and real case studies in which we apply the developed HSGP models and the recommended steps to fit them. More case studies are presented in the online supplemental materials.
5.1 Simulated data for a univariate function
In this experiment, we analyze a synthetic dataset with \(n = 250\) observations, where the true data generating process is a Gaussian process with additive noise. The data points are simulated from the model \(y_i = f(x_i) + \epsilon _i\), where f is a sample from a Gaussian process \(f(x) \sim {{\,\mathrm{\mathcal{G}\mathcal{P}}\,}}(0, k(x, x', \theta ))\) with a Matérn (\(\nu \)=3/2) covariance function k with marginal variance \(\alpha =1\) and length-scale \(\ell =0.2\) at inputs values \({\varvec{x}}=(x_1,x_2,\dots ,x_n)\) with \(x_i \in [-1,1]\) that lead to an input space boundary S of \(S=1\) as per Eq. (16). \(\epsilon _i\) is additive Gaussian noise with standard deviation \(\sigma =0.2\).
In the HSGP model, the latent function values f(x) are approximated as in Eq. (8), with the Matérn (\(\nu \)=3/2) spectral density s as in Eq. (2), and eigenvalues \(\lambda _j\) and eigenfunctions \(\phi _j\) as in Eqs. (6) and (7), respectively.
The joint posterior parameter distributions are estimated by sampling using the dynamic HMC algorithm implemented in Stan (Stan Development Team 2021). \(\textrm{Normal}(0,1)\), \(\textrm{Normal}(0,3)\) and \(\textrm{Gamma}(1.2,0.2)\) prior distributions has been used for the observation noise \(\sigma \), covariance function marginal variance \(\alpha \), and length-scale \(\ell \), respectively. We use the same prior distributions to fit the exact GP model.
The HSGP model is fitted following the recommended iterative steps as in Sect. 4.5.1. A initial value for the minimum lengthscale \(\ell \) to use at the first iteration is guessed to be 0.5. While diagnostic \(\hat{\ell } + 0.01 \ge \ell \) is false, c and m are updated by Eqs. (24) and (23), respectively, and the minimum \(\ell \) is updated with the estimated \(\hat{\ell }\). After the diagnostic generated the first true, m is updated by increasing the m of the previous iteration by 5 additional basis functions, c is updated by Eq. (24) as a function of the estimated \(\hat{\ell }\) at previous iteration, and the minimum \(\ell \) is set by Eq. (23) as function of c and m. Table 2 contains the values for the parameters \(\ell \), c, m, the estimated \(\hat{\ell }\), the diagnostic \(\hat{\ell } + 0.01 \ge \ell \) and the RMSE compute with both the data and the GP as the reference for every iterative steps of the fitting process.
Figure 8 shows the posteriors predictive distributions of the exact GP and the HSGP models, the later using the parameter values as the third iterative step, \(c=1.2\) (\(L=c\cdot S= 1.2\); see Eq. (17)) and \(m=40\) basis functions.

Posterior predictive means of the proposed HSGP model and the exact GP model. 95% credible intervals are plotted as dashed lines
Figure 9 shows both the standardized root mean squared error (SRMSE) of the models for the sample data and the computational times in seconds per iteration (iteration of the HMC sampling method), as a function of the number of basis functions m. The HSGP model is on average roughly 400 times faster than the exact GP for this particular model and data. Also, it is seen that the computation time increases slowly as a function of m.

Computational time (y-axis), in seconds per iteration (iteration of the HMC sampling method), as a function of the number of basis functions m. The y-axis is on a logarithmic scale. The standard deviation of the computational time is plotted as dashed lines
The Stan model code for the exact GP model and the HSGP model, and R-code to reproduce this case study can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper/Case-study_1D-Simulated-data .
5.2 Birthday data
This example is an analysis of patterns in birthday frequencies in a dataset containing records of all births in the United States on each day during the period 1969–1988. The model decomposes the number of births along all the period in longer-term trend effects, patterns during the year, day-of-week effects, and special days effects. The special days effects cover patterns such as possible fewer births on Halloween, Christmas or new year, and excess of births on Valentine’s Day or the days after Christmas (due, presumably, to choices involved in scheduled deliveries, along with decisions of whether to induce a birth for health reasons). Gelman et al. (2013) presented an analysis using exact GP and maximum a posteriori inference. As the total number of days within the period is \(T=7305\) (\(t=1,2,\dots ,T\)), a full Bayesian inference with MCMC for a exact GP model is memory and time consuming. We will use the HSGP method as well as the low-rank GP model with a periodic covariance function described in Appendix B which is based on expanding the periodic covariance function into a series of stochastic resonators (Solin and Särkkä 2014).
Let \(y_t\) denote the number of births on the t’th day. The observation model is a normal distribution with mean function \(\mu (t)\) and noise variance \(\sigma ^2\),
The mean function \(\mu (t)\) will be defined as an additive model in the form
The component \(f_1(t)\) represents the long-term trends modeled by a GP with squared exponential covariance function,
which means the function values \({\varvec{f}}_1=\{f_1(t)\}_{t=1}^T\) are multivariate Gaussian distributed with covariance matrix \({\varvec{K}}_1\), where \(K_{1_{t,s}}=k_1(t,s)\), with \(t,s=1,\dots ,T\). \(\alpha _1\) and \(\ell _1\) represent the marginal variance and length-scale, respectively, of this GP prior component. The component \(f_2(t)\) represents the yearly smooth seasonal pattern, using a periodic squared exponential covariance function (with period 365.25 to match the average length of the year) in a GP model,
The component \(f_3(t)\) represents the weekly smooth pattern using a periodic squared exponential covariance function (with period 7 of length of the week) in a GP model,
The component \(f_4(t)\) represents the special days effects, modeled as a Student’s t prior model with 1 degree of freedom and variance \(\tau ^2\):
The component \(f_1\) will be approximated using the HSGP model and the function values \(f_1\) are approximated as in Eq. (8), with the squared exponential spectral density s as in Eq. (1), and eigenvalues \(\lambda _j\) and eigenfunctions \(\phi _j\) as in Eqs. (6) and (7). The year effects \(f_2\) and week effects \(f_3\) use a periodic covariance function and thus do no fit under the main framework of the HSGP approximation covered in this paper. However, they do have a representation based on expanding periodic covariance functions into a series of stochastic resonators (Appendix B). Thus, the functions \(f_2\) and \(f_3\) are approximated as in Eq. (B.8), with variance coefficients \(\tilde{q}_j^2\) as in Eq. (B.5). The input variable \({\varvec{t}}=\{1,2,\dots ,7305\}\) is previously standardized to have zero mean and unit variance \(\left( \frac{{\varvec{t}}-\text {mean}({\varvec{t}})}{\text {sd}({\varvec{t}})}\right) \), and then it follows a input space boundary \(S=1.732\).
The joint posterior parameter distributions are estimated by sampling using the dynamic HMC algorithm implemented in Stan (Stan Development Team 2021). \(\textrm{Normal}(0,1)\), \(\textrm{Normal}(0,10)\) and \(\textrm{Normal}(0,2)\) prior distributions has been used for the observation noise \(\sigma \), covariance function marginal variances \({\varvec{\alpha }}=\{\alpha _1, \alpha _2, \alpha _3\}\), and length-scales \({\varvec{\ell }}=\{\ell _1, \ell _2, \ell _3\}\), respectively. A \(\textrm{Normal}(0,0.1)\) prior distribution has been used for the standard deviation \(\tau \) of the Student’s t distribution with 1 degree of freedom used to model \(f_4\) (i.e., the special days effects).
The HSGP model is fitted following the recommended iterative steps as in Sect. 4.5.1, where in each iteration the diagnosis is applied on \(f_1\), \(f_2\) and \(f_3\), where for each one these functions the parameters c, m, minimum \(\ell \), estimated \(\hat{\ell }\) and diagnostic \(\hat{\ell } + 0.01 \ge \ell \) are updated. For functions \(f_2\) and \(f_3\) there are not boundary factor c as they use periodic covariance functions, and m and minimum \(\ell \) are updated by Eq. (B.6). A initial value for the minimum lengthscale \(\ell _1\) of \(f_1\) is guessed to correspond to around 3 years (i.e., \(\ell _1=3\) years \(= 3\cdot 365=1095\) days) in the original scale or around 0.52 (i.e., \(\ell _1=\nicefrac {1095}{\text {sd}({\varvec{t}})}=0.52\)) in the standardized scale used as input in the model. Initial values for the minimum lengthscales \(\ell _2\) and \(\ell _3\) of \(f_2\) and \(f_3\), respectively, are guessed to correspond to half of the period (i.e., \(\ell _2=\ell _3=0.5\)). After the diagnostic generated the first true, m is updated by increasing the m of the previous iteration by 5 additional basis functions and c and the minimum \(\ell \) updated accordingly as explained in Sect. 4.5.1. The full diagnosis process is applied until two trues are achieved for each function. Table 3 contains the values for the parameters \(\ell \), c, m, the estimated \(\hat{\ell }\), the diagnostic \(\hat{\ell } + 0.01 \ge \ell \) for each function, and the RMSE compute with the data as the reference for every iterative steps of the fitting process.
Figure 10 shows the posterior means of the long-term trend \(f_1\) and yearly pattern \(f_2\) for the whole period, jointly with the observed data. Figure 11 shows the model for 1 year (1972) only. In this figure, the special days effects \(f_4\) in the year can be clearly represented. The posterior means of the the function \(\mu \) and the components \(f_1\) (long-term trend) and \(f_2\) (year pattern) are also plotted in this Fig. 11. Figure 12 show the process in the month of January of 1972 only, where the week pattern \(f_3\) can be clearly represented. The mean of the the function \(\mu \) and components \(f_1\) (long-term trend), \(f_2\) (year pattern) and \(f_4\) (special-days effects) are also plotted in this Fig. 12.
The Stan model code for the HSGP model and R-code to reproduce this case study can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper/Case-study_Birthday-data.

Posterior means of the long-term trend \(f_1\) and year effects pattern (\(f_2\)) for the whole series

Posterior means of the function \(\mu \) for the year 1972 of the series. The special days effects pattern \(f_4\) in the year is also represented, as well as the long-term trend \(f_1\) and year effects pattern \(f_2\)

Posterior means of the function \(\mu \) for the month of January of 1972. The week effects pattern \(f_3\) in the month is also represented, as well as the long-term trend \(f_1\), year effects pattern \(f_2\) and special days effects pattern \(f_4\)
5.3 Case study: simulated data for 2D and 3D functions
In this case study, we apply the diagnostic tool to fit and diagnose two different data sets, one data set simulated from a bivariate (\(D=2\)) function and another data set simulated from a 3-dimensinal (\(D=3\)) function. Furthermore, in Sect. 5.3.1 we present results of the computational time required to fit the HSGP model in 2D, 3D and 4D input spaces, with different sized data sets and as a function of the number of multivariate basis functions \(m^*=m_1\times \cdots \times m_D\) used in the approximation.
2D and 3D synthetic functions were drawn from 2D and 3D GP priors, with input values \({\varvec{x}}_i \in [-1,1]^2\) and \({\varvec{x}}_i \in [-1,1]^3\), respectively, and the input space boundary is \(S=1\) for both the 2D and 3D functions. Squared exponential covariance functions with marginal variance \(\alpha =1\) and length-scales \(\ell _1=0.10\), \(\ell _2=0.3\), and \(\ell _3=0.4\), where \(\ell _i\) is the length scale for the i’th dimension, were used in the GP priors. 200 and 1000 data points were sampled from the 2D and 3D drawn functions, respectively, and independent Gaussian noise with standard deviation \(\sigma =0.2\) was added to the data points to form the final noisy sets of observations.
In the HSGP models with 2 and 3 input dimensions, the underlying functions \(f({\varvec{x}})\) are approximated as in eq. (13), with the D-dimensional squared exponential spectral densities s as in Eq. (1), and the D-vectors of eigenvalues \({\varvec{\lambda }}_j\) and the multivariate eigenfunctions \(\phi _j\) as in Eqs. (12) and (11), respectively.
The joint posterior parameter distributions are estimated via the dynamic HMC sampling algorithm implemented in Stan (Stan Development Team 2021). \(\textrm{Normal}(0,1)\), \(\textrm{Normal}(0,3)\), and \(\textrm{InverseGamma}(2,0.5)\) priors were used for the observation noise \(\sigma \), marginal variance \(\alpha \), and length-scales \(\ell \), respectively. We used the same priors to fit the exact GP model serving as benchmark.
The HSGP models are fitted following the recommended iterative procedure detailed in Sect. 4.5.1, where the diagnostic is applied on every dimension, separately. For each dimension, the parameters c, m, minimum \(\ell \), estimated \(\hat{\ell }\), and the diagnostic \(\hat{\ell } + 0.01 \ge \ell \) are updated using the equations in Sect. 4.3.1. The values 0.5, 1, and 1 are set as initial values for the minimum lengthscales \(\ell _1\), \(\ell _2\) and \(\ell _3\), respectively. In order to be as efficient as possible, after the diagnostic generated the first true for a certain dimension, its corresponding m is updated by increasing the m of the previous iteration by only 2 additional basis functions and, after the second true, m is no longer increased. The full diagnostic process is applied until two trues are achieved for each dimension.
Tables 4 and 5 contain the iterative steps to fit and diagnose the 2D and 3D data sets, respectively. The minimum requirements to fit the models were easily achieved by performing 4 iterations: from a \(1^{\text {st}}\) iteration that uses few multivariate basis functions \(m^*\) (\(m^*=m_1(=6) \times m_2(=6)=36\) and \(m^*=m_1(=6) \times m_2(=6) \times m_3(=6)=216\) for the 2D and 3D data sets, respectively) to the \(4^{\text {th}}\) iteration that uses the minimum multivariate basis functions (\(m^*=m_1(=22) \times m_2(=11)=242\) and \(m^*=m_1(=21) \times m_2(=10) \times m_3(=12)=2520\) for the 2D and 3D data sets, respectively) required to accurately approximate these notably wiggly functions. Without using our recommended guidelines and diagnostics, it would likely have taken the user several more trials to get the optimal solution and to spend a significant amount of time, as using a larger number of basis functions in multivariate cases increases time of computation drastically.

Error between the 2D data-generating function and posterior mean functions of the GP (a) and HSGP (b) models. Sample points are plotted as circles. The right side plot shows the root mean square error (RMSE) of the different methods, and plotted as a function of the boundary factor c and number of univariate basis functions m (the same m is used per dimension, resulting in a total number of \(m^D\) multivariate basis functions)
Figure 13 shows the difference between the true underlying data-generating function and the posterior means of GP and HSGP models for the 2D data set. For the 3D data set, posterior functions are not plotted because it is difficult to plot functions in a 3D input space. Figure 13-left shows the root mean squared error (RMSE), computed against the data-generating function, as a function of the boundary factor c and number of univariate basis functions m.
The Stan model codes for the exact GP model and the HSGP model, and R-code to reproduce this case study can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper/Case-study_2D%263D-Simulated-data . In the online supplementary material there are two other case studies of real data with multidimensional and spatio-temporal (3D) input spaces, for which the Stan model codes can be found at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper and subfolders Case-study_Land-use-classification and Case-study_Salinity, respectively.
5.3.1 Computation requirements in 2D, 3D, and 4D input spaces
Figure 14 shows the computation time for dynamic HMC (in seconds per iteration) in 2D, 3D and 4D input spaces and different sized data sets, \(n=300, n=500, n=1000\), and \(n=3000\), as a function of the number of multivariate basis functions \(m^*=m_1\times \cdots \times m_D\) used in the approximation. Both the time of computation and \(m^*\) are plotted in the logarithmic scale.
Looking back at Fig. 5, or Eqs. (19), (23), and (21), and assuming squared exponential covariance function, any univariate function (or single dimensions of a multivariate function) with true lengthscales bigger than 0.3 can be accurately fitted using only \(10-12\) basis functions. For lengthscales between 0.1 and 0.3, \(10-22\) basis functions are sufficient.
For a very wiggly 2D function (say, with \(\ell _1=0.1\) and \(\ell _2=0.1\)), the approximate number of multivariate basis functions needed is \(m^*=22\times 22= 484\), which results in significantly faster computation than the exact GP, even with small data sets (i.e., \(n \lesssim 300\)) (see Fig. 14). For a very wiggly 3D function (say, with \(\ell _1=0.1\), \(\ell _2=0.1\) and \(\ell _3=0.1\)), the approximate number of multivariate basis functions needed is \(m^*=22\times 22\times 22= 10648\), which, unless for small data sets (i.e., \(n \lesssim 1000\)), the method is still significantly faster than the regular GP. A 3D function where each dimension has a lengthscale around 0.1 is not that common in statistical analysis, and thus in many cases the approximation will be significantly faster than excat GP. For 4D data sets, the method can still be more efficient than the exact GP for moderate-to-large data sets (i.e., \(n \lesssim 1000\)).
Finally, for \(D>5\) the method starts to be impractical even for smooth univariate functions. However, in these cases, the method may still be used for lower dimensional components in an additive modeling scheme.
The Stan model codes for the exact GP model and the HSGP model for these 2D, 3D, and 4D cases can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper/Stan_code_2D_3D_4D .

Computational time in seconds per iteration (iteration of the HMC sampling method) for different datasets with different dimensionalties and data points, and plotted as a function of the number of multivariate basis functions \(m^*=m_1\times \cdots \times m_D\)
5.4 Leukemia data
The next example presents a survival analysis in acute myeloid leukemia (AML) in adults, with data recorded between 1982 and 1998 in the North West Leukemia Register in the United Kingdom. The data set consists of survival and censoring times \(t_i\) and censoring indicator \(z_i\) (0 for observed and 1 for censored) for \(n=1043\) cases (\(i=1,\dots ,n\)). About 16% of cases were censored. Predictors are age (\(x_1\)), sex (\(x_2\)), white blood cell (WBC) (\(x_3\)) count at diagnostic with 1 unit = \(50\times 109/L\), and the Townsend deprivation index (TDI) (\(x_4\)) which is a measure of deprivation for district of residence. We denote \({\varvec{x}}_i=(x_{i1},x_{i2},x_{i3},x_{i4}) \in \mathrm{I\!R}^{4}\) as the vector of predictor values for observation i.
As the WBC predictor values were strictly positive and highly skewed, a logarithm transformation is used. Continuous predictors were normalized to have zero mean and unit standard deviation. We assume a log-normal observation model for the observed survival time, \(t_i\), with a function of the predictors, \(f({\varvec{x}}_i):\mathrm{I\!R}^4 \rightarrow \mathrm{I\!R}\), as the location parameter, and \(\sigma \) as the Gaussian noise:
We do not have a full observation model, as we do not have a model for the censoring process. We use the complementary cumulative log-normal probability distribution for the censored data conditionally on the censoring time \(t_i\):
where \(y_i>t_i\) denotes the unobserved survival time and \(\varPhi \) is the standard normal cumulative distribution function. The latent function \(f(\cdot )\) is modeled as a Gaussian process, centered around a linear model of the predictors \({\varvec{x}}\), and with a squared exponential covariance function k. Due to the predictor sex (\(x_2\)) being a categorical variable (‘1’ for female and ‘2’ for male), we apply indicator variable coding for the GP functions, in a similar way such coding is applied in linear models (Gelman et al. 2020). The latent function \(f({\varvec{x}})\), besides of being centered around a linear model, is composed of a general mean GP function, \(h({\varvec{x}})\), defined for all observations, plus a second GP function, \(g({\varvec{x}})\), that only applies to one of the predictor levels (’male’ in this case) and is set to zero otherwise:
where \(\mathbb {I}\left[ \cdot \right] \) is an indicator function. Above, c and \({\varvec{\beta }}\) are the intercept and vector of coefficients, respectively, of the linear model. \(\theta _0\) contains the hyperparameters \(\alpha _0\) and \(\ell _0\) which are the marginal variance and length-scale of the general mean GP function, and \(\theta _1\) contains the hyperparameters \(\alpha _1\) and \(\ell _1\) which are the marginal variance and length-scale, respectively, of a GP function specific to the male sex (\(x_2=2\)). Scalar length-scales, \(\ell _0\) and \(\ell _1\), are used in both multivariate covariance functions, assuming isotropic functions.

Expected lifetime conditional comparison for each predictor with other predictors fixed to their mean values. The thick line in each graph is the posterior mean estimated using a HSGP model, and the thin lines represent pointwise 95% credible intervals
Using the HSGP approximation, the functions \(h({\varvec{x}})\) and \(g({\varvec{x}})\) are approximated as in Eq. (14), with the D-dimensional (with a scalar length-scale) squared exponential spectral density s as in Eq. (1), and the multivariate eigenfunctions \(\phi _j\) and the D-vector of eigenvalues \({\varvec{\lambda }}_j\) as in Eqs. (12) and (11), respectively.
Figure 15 shows estimated conditional functions of each predictor with all others fixed to their mean values. These posterior estimates correspond to the HSGP model with \(m=10\) basis functions and \(c=3\) boundary factor. There are clear non-linear patterns and the right bottom subplot also shows that the conditional function associated with WBC has an interaction with TDI. Figure 16 shows the expected log predictive density (ELPD; Vehtari and Ojanen 2012; Vehtari et al. 2017) and time of computation as function of the number of univariate basis functions m (\(m^{*}=m^D\) in Eq. (14)) and boundary factor c. As the functions are smooth, a few number of basis functions and a large boundary factor are required to obtain a good approximation (Fig. 16-left); Small boundary factors are not appropriate for models for large length-scales, as can be seen in Fig. 5. Increasing the boundary factor also significantly increases the time of computation (Fig. 16-right). With a moderate number of univariate basis functions (\(m=15\)), the HSGP model becomes slower than the exact GP model, in this specific application with 3 input variables, as the total number of multivariate basis functions becomes \(15^3 = 3375\) and is therefore quite high.

Expected log predictive density (ELPD; left) and time of computation in seconds per iteration (iteration of the HMC sampling method; right) as a function of the number of basis functions m and boundary factor c
The Stan model code for the exact GP and the HSGP models of this case study can be found online at https://github.com/gabriuma/basis_functions_approach_to_GP/tree/master/Paper/Case-study_Leukemia-data .
6 Conclusion
Modeling unknown functions using exact GPs is computationally intractable in many applications. This problem becomes especially severe when performing full Bayesian inference using sampling-based methods. In this paper, a recent approach for a low-rank representation of stationary GPs, originally proposed by Solin and Särkkä (2020), has been analyzed in detail. The method is based on a basis function approximation via Laplace eigenfunctions. The method has an attractive computational cost as it effectively approximates GPs by linear models, which is also an attractive property in modular probabilistic programming programming frameworks. The dominating cost per log density evaluation (during sampling) is \(O(nm+m)\), which is a big benefit in comparison to \(O(n^3)\) of an exact GP model. The obtained design matrix is independent of hyperparameters and therefore only needs to be constructed once, at cost O(nm). All dependencies on the kernel and the hyperparameters are through the prior distribution of the regression weights. The parameters’ posterior distribution is m-dimensional, where m is usually much smaller than the number of observations n.
As one of the main contributions of this paper, we provided an in-depth analysis of the approximation’s performance and accuracy in relation to the key factors of the method, that is, the number of basis functions, the boundary condition of the Laplace eigenfunctions, and the non-linearity of the function to be learned. On that basis, as our second main contribution, we developed practical diagnostics to assess the approximation’s performance as well as an iterative procedure to obtain an accurate approximation with minimal computational costs.
The developed approximate GPs can be easily applied as modular components in probabilistic programming frameworks such as Stan in both Gaussian and non-Gaussian observation models. Using several simulated and real datasets, we have demonstrated the practical applicability and improved sampling efficiency, as compared to exact GPs, of the developed method. The main drawback of the approach is that its computational complexity scales exponentially with the number of input dimensions. Hence, choosing optimal values for the number of basis functions and the boundary factor, using the recommendations and diagnostics provided in Fig. 5, is essential to avoid a excessive computational time especially in multivariate input spaces. However, in practice, input dimensionalities larger than three start to be computationally demanding even for moderately wiggly functions and few basis functions per input dimension. In these high dimensional cases, the proposed approximate GP methods may still be used for low-dimensional components in an additive modeling scheme but without modeling very high dimensional interactions, as complexity is linear with the number of additive components.
In this paper, the obtained functional relationships between the key factors influencing the approximation and corresponding diagnostics were studied primarily for univariate inputs. Accordingly, investigating the functional relationships more thoroughly for multivariate inputs remains a topic for future research.
References
Abramowitz, M., Stegun, I.: Handbook of Mathematical Functions. Dover Publishing, New York (1970)
Adler, R.J.: The Geometry of Random Fields. SIAM, Philadelphia (1981)
Akhiezer, N.I., Glazman, I.M.: Theory of Linear Operators in Hilbert Space. Dover, New York (1993)
Andersen, M.R., Vehtari, A., Winther, O., Hansen, L.K.: Bayesian inference for spatio-temporal spike-and-slab priors. J. Mach. Learn. Res. 18(139), 1–58 (2017)
Betancourt, M.: A conceptual introduction to Hamiltonian Monte Carlo. arXiv preprint arXiv:1701.02434 (2017)
Betancourt, M., Girolami, M.: Hamiltonian Monte Carlo for hierarchical models. In: Current Trends in Bayesian Methodology with Applications. Chapman and Hall/CRC, pp. 79–101 (2019)
Briol, F.X., Oates, C., Girolami, M., Osborne, M.A., Sejdinovic, D.: Probabilistic integration: a role in statistical computation? arXiv preprint arXiv:1512.00933 (2015)
Brooks, S., Gelman, A., Jones, G., Meng, X.L.: Handbook of Markov Chain Monte Carlo. CRC Press, London (2011)
Bürkner, P.C.: brms: an R package for Bayesian multilevel models using Stan. J. Stat. Softw. 80(1), 1–28 (2017)
Burt, D., Rasmussen, C.E., Van Der Wilk, M.: Rates of convergence for sparse variational Gaussian process regression. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, vol. 97, pp. 862–871 (2019)
Carlin, B.P., Gelfand, A.E., Banerjee, S.: Hierarchical Modeling and Analysis for Spatial Data. Chapman and Hall/CRC, London (2014)
Carpenter, B., Gelman, A., Hoffman, M.D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., Riddell, A.: Stan: a probabilistic programming language. J. Stat. Softw. 76(1), 1–32 (2017)
Cramér, H., Leadbetter, M.R.: Stationary and Related Stochastic Processes: Sample Function Properties and Their Applications. Courier Corporation, North Chelmsford (2013)
Csató, L., Fokoué, E., Opper, M., Schottky, B., Winther, O.: Efficient approaches to Gaussian process classification. In: Advances in Neural Information Processing Systems, pp. 251–257 (2000)
Deisenroth, M.P., Fox, D., Rasmussen, C.E.: Gaussian processes for data-efficient learning in robotics and control. IEEE Trans. Pattern Anal. Mach. Intell. 37(2), 408–423 (2015)
Diggle, P.J.: Statistical Analysis of Spatial and Spatio-temporal Point Patterns. Chapman and Hall/CRC, London (2013)
Furrer, E.M., Nychka, D.W.: A framework to understand the asymptotic properties of kriging and splines. J. Korean Stat. Soc. 36(1), 57–76 (2007)
Gal, Y., Turner, R.: Improving the Gaussian process sparse spectrum approximation by representing uncertainty in frequency inputs. In: Bach, F., Blei, D. (eds.) Proceedings of the 32nd International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, vol. 37, pp. 655–664 (2015)
Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., Vehtari, A., Rubin, D.B.: Bayesian Data Analysis. Chapman and Hall/CRC, London (2013)
Gelman, A., Hill, J., Vehtari, A.: Regression and Other Stories. Cambridge University Press, Cambridge (2020)
Gibbs, M.N., MacKay, D.J.: Variational Gaussian process classifiers. IEEE Trans. Neural Netw. 11(6), 1458–1464 (2000)
GPy: GPy: a Gaussian process framework in Python. http://github.com/SheffieldML/GPy (2012)
Grenander, U.: Abstract Inference. Wiley, Hoboken, NJ (1981)
Hennig, P., Osborne, M.A., Girolami, M.: Probabilistic numerics and uncertainty in computations. Proc. R. Soc. A: Math. Phys. Eng. Sci. 471(2179), 20150142 (2015)
Hensman, J., Durrande, N., Solin, A.: Variational Fourier features for Gaussian processes. J. Mach. Learn. Res. 18(1), 5537–5588 (2017)
Jo, S., Choi, T., Park, B., Lenk, P.: bsamGP: an R package for Bayesian spectral analysis models using Gaussian process priors. J. Stat. Softw. Artic. 90(10), 1–41 (2019)
Lázaro Gredilla, M.: Sparse Gaussian processes for large-scale machine learning. Ph.D. thesis, Universidad Carlos III de Madrid (2010)
Lindgren, F., Bolin, D., Rue, H.: The SPDE approach for Gaussian and non-Gaussian fields: 10 years and still running. Spatial Stat. 50, 100599 (2022)
Loève, M.: Probability Theory. Springer-Verlag, New York (1977)
Matthews, A.G.G., van der Wilk, M., Nickson, T., Fujii, K., Boukouvalas, A., León-Villagrá, P., Ghahramani, Z., Hensman, J.: GPflow: a Gaussian process library using TensorFlow. J. Mach. Learn. Res. 18(40), 1–6 (2017)
Minka, T.P.: Expectation propagation for approximate Bayesian inference. In: Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc., pp. 362–369 (2001)
Neal, R.M.: Monte Carlo implementation of Gaussian process models for Bayesian regression and classification. arXiv preprint physics/9701026 (1997)
Quiñonero-Candela, J., Rasmussen, C.E.: A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 6(Dec), 1939–1959 (2005)
Quiñonero-Candela, J., Rasmussen, C.E., Figueiras-Vidal, A.R.: Sparse spectrum Gaussian process regression. J. Mach. Learn. Res. 11(Jun), 1865–1881 (2010)
R Core Team: R: a language and environment for statistical computing. http://www.R-project.org/ (2019)
Rahimi, A., Recht, B.: Random features for large-scale kernel machines. In: Platt, J.C., Koller, D., Singer, Y., Roweis, S.T. (eds.) Advances in Neural Information Processing Systems, vol. 20, pp. 1177–1184. Curran Associates Inc., Red Hook (2008)
Rahimi, A., Recht, B.: Weighted sums of random kitchen sinks: replacing minimization with randomization in learning. In: Koller, D., Schuurmans, D., Bengio, Y., Bottou, L. (eds.) Advances in Neural Information Processing Systems, vol. 21, pp. 1313–1320. Curran Associates Inc, Red Hook (2009)
Rasmussen, C.E., Nickisch, H.: Gaussian processes for machine learning (GPML) toolbox. J. Mach. Learn. Res. 11, 3011–3015 (2010)
Rasmussen, C.E., Williams, C.K.: Gaussian Processes for Machine Learning. MIT Press, Cambridge (2006)
Roberts, S.J.: Bayesian Gaussian processes for sequential prediction, optimisation and quadrature. Ph.D. thesis, University of Oxford (2010)
Solin, A., Särkkä, S.: Explicit link between periodic covariance functions and state space models. In: Kaski, S., Corander, J. (eds.) Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, PMLR, Proceedings of Machine Learning Research, vol. 33, pp. 904–912 (2014)
Solin, A., Särkkä, S.: Hilbert space methods for reduced-rank Gaussian process regression. Stat. Comput. 30(2), 419–446 (2020). much of the work in this paper is based on the pre-print version predating the published paper. Pre-print available at https://arxiv.org/abs/1401.5508
Särkkä, S., Solin, A., Hartikainen, J.: Spatiotemporal learning via infinite-dimensional Bayesian filtering and smoothing: a look at Gaussian process regression through Kalman filtering. IEEE Signal Process. Mag. 30(4), 51–61 (2013)
Stan Development Team: Stan modeling language users guide and reference manual, 2.28. https://mc-stan.org (2021)
Van Trees, H.L.: Detection, Estimation, and Modulation Theory, Part I: Detection, Estimation, and Linear Modulation Theory. John Wiley & Sons, New York, NY (1968)
Vanhatalo, J., Riihimäki, J., Hartikainen, J., Jylänki, P., Tolvanen, V., Vehtari, A.: GPstuff: Bayesian modeling with Gaussian processes. J. Mach. Learn. Res. 14(1), 1175–1179 (2013)
Vehtari, A., Ojanen, J.: A survey of Bayesian predictive methods for model assessment, selection and comparison. Stat. Surv. 6, 142–228 (2012)
Vehtari, A., Gelman, A., Gabry, J.: Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 27(5), 1413–1432 (2017)
Wahba, G.: Spline Models for Observational Data, vol. 59. SIAM, Philadelphia (1990)
Williams, C.K., Barber, D.: Bayesian classification with Gaussian processes. IEEE Trans. Pattern Anal. Mach. Intell. 20(12), 1342–1351 (1998)
Acknowledgements
We thank Academy of Finland (Grants 298742, 308640, and 313122), Instituto de Salud Carlos III, Spain (Grant CD21/00186 - Sara Borrell Postdoctoral Fellowship) and co-funded by the European Union, Finnish Center for Artificial Intelligence, and Technology Industries of Finland Centennial Foundation (Grant 70007503; Artificial Intelligence for Research and Development), and Conselleria de Innovación, Universidades, Ciencia y Sociedad Digital, Generalitat Valenciana, Spain (Grant AICO/2020/285) for partial support of this research. We also acknowledge the computational resources provided by the Aalto Science-IT project.
Funding
Open Access funding provided by Aalto University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
A Approximation of the covariance function using Hilbert space methods
In this section, we briefly present a summary of the mathematical details of the approximation of a stationary covariance function as a series expansion of eigenvalues and eigenfunctions of the Laplacian operator. This statement is based on the work by Solin and Särkkä (2020), who developed the mathematical theory behind the Hilbert Space approximation for stationary covariance functions.
Associated to each covariance function \(k({\varvec{x}},{\varvec{x}}')\) we can also define a covariance operator \(\mathcal {K}\) over a function \(f({\varvec{x}})\) as follows:
From the Bochner’s and Wiener-Khintchine theorems, the spectral density of a stationary covariance function \(k({\varvec{x}},{\varvec{x}}') = k({\varvec{\tau }})\), \({\varvec{\tau }}=({\varvec{x}}-{\varvec{x}}')\), is the Fourier transform of the covariance function,
where \({\varvec{w}}\) is in the frequency domain. The operator \(\mathcal {K}\) will be translation invariant if the covariance function is stationary. This allows for a Fourier representation of the operator \(\mathcal {K}\) as a transfer function which is the spectral density of the Gaussian process. Thus, the spectral density \(s({\varvec{w}})\) also gives the approximate eigenvalues of the operator \(\mathcal {K}\).
In the isotropic case \(s({\varvec{w}}) = s(||{\varvec{w}}||)\) and assuming that the spectral density function \(s(\cdot )\) is regular enough, then it can be represented as a polynomial expansion:
The Fourier transform of the Laplace operator \(\nabla ^2\) is \(-||{\varvec{w}}||\), thus the Fourier transform of \(s(||{\varvec{w}}||)\) is
defining a pseudo-differential operator as a series of Laplace operators.
If the negative Laplace operator \(-\nabla ^2\) is defined as the covariance operator of the formal kernel l,
then the formal kernel can be represented as
where \(\{\lambda _j\}_{j=1}^{\infty }\) and \(\{\phi _j({\varvec{x}})\}_{j=1}^{\infty }\) are the set of eigenvalues and eigenvectors, respectively, of the Laplacian operator. Namely, they satisfy the following eigenvalue problem in the compact subset \({\varvec{x}} \in \varOmega \subset \mathrm{I\!R}^D\) and with the Dirichlet boundary condition (other boundary conditions could be used as well):
Because \(-\nabla ^2\) is a positive definite Hermitian operator, the set of eigenfunctions \(\phi _j(\cdot )\) are orthonormal with respect to the inner product
that is,
and all the eigenvalues \(\lambda _j\) are real and positive.
Due to normality of the basis of the representation of the formal kernel \(l({\varvec{x}},{\varvec{x}}')\), its formal powers \(s=1,2,\dots \) can be written as
which are again to be interpreted to mean that
This implies that we also have
Then, looking at Eqs. (A.2) and (A.3), it can be concluded
By letting \(||{\varvec{w}}||^2=\lambda _j\) the spectral density in Eq. (A.1) becomes
and substituting in Eq. (A.4) then leads to the final form
where \(s(\cdot )\) is the spectral density of the covariance function, \(\lambda _j\) is the jth eigenvalue and \(\phi _j(\cdot )\) the eigenfunction of the Laplace operator in a given domain.
B Low-rank Gaussian process with a periodic covariance function
A GP model with a periodic covariance function does no fit in the framework of the HSGP approximation covered in this study, but it has also a low-rank representation. In this section, we first give a brief presentation of the results by Solin and Särkkä (2014), who obtain an approximate linear representation of a periodic squared exponential covariance function based on expanding the periodic covariance function into a series of stochastic resonators. Secondly, we analyze the accuracy of this approximation and, finally, we derive the GP model with this approximate periodic squared exponential covariance function.

Relation among the minimum number of terms J in the approximation and the length-scale (\(\ell \)) of the periodic squared exponential covariance function. The right-side plot is a zoom in of the left-side plot
The periodic squared exponential covariance function takes the form
where \(\alpha \) is the magnitude scale of the covariance, \(\ell \) is the characteristic length-scale of the covariance, and \(\omega _0\) is the angular frequency defining the periodicity.
Solin and Särkkä (2014) derive a cosine series expansion for the periodic covariance function (B.1) as follows,
which comes basically from a Taylor series representation of the periodic covariance function. The coefficients \(\tilde{q}_j^2\)
where \(j=1,2,\ldots ,J\), and \(\lfloor \cdot \rfloor \) denotes the floor round-off operator. For the index \(j=0\), the coefficient is
The covariance in Eq. (B.2) is a Jth order truncation of a Taylor series representation. This approximation converges to Eq. (B.1) when \(J \rightarrow \infty \).
An upper bounded approximation to the coefficients \(\tilde{q}_j^2\) and \(\tilde{q}_0^2\) can be obtained by taking the limit \(J \rightarrow \infty \) in the sub-sums in the corresponding Eqs. (B.3) and (B.4), and thus leading to the following variance coefficients:
for \(j=1,2,\ldots ,J\), and where the \(\textrm{I}_{j}(z)\) is the modified Bessel function (Abramowitz and Stegun 1970) of the first kind. This approximation implies that the requirement of a valid covariance function is relaxed and only an optimal series approximation is required. A more detailed explanation and mathematical proofs of this approximation of a periodic covariance function are provided by Solin and Särkkä (2014).
In order to assess the accuracy of this representation as a function of the number of cosine terms J considered in the approximation, an empirical evaluation is carried out in a similar way than that in Sect. 4 of this work. Thus, Fig. 17 shows the minimum number of terms J required to achieve a close approximation to the exact periodic squared exponential kernel as a function of the length-scale of the kernel. We have considered an approximation to be close enough in terms of satisfying Eq. (15) with \(\varepsilon =0.005 \int k(\tau ) \,\textrm{d}\tau \) (0.5\(\%\) of the total area under the curve of the exact covariance function k). Since this is a series expansion of sinusoidal functions, the approximation does not depend on any boundary condition.
From the empirical observations, a numerical equation governing the relationships between J and \(\ell \) were estimated in Eq. (B.6), which show linear proportionality between J and \(\ell \):
The function values of a GP model with this low-rank representation of the periodic exponential covariance function can be easily derived. Considering the identity
the covariance \(k(\tau )\) in Eq. (B.2) can be written as
With this approximation for the periodic squared exponential covariance function \(k(x,x')\), the approximate GP model \(f(x) \sim {{\,\mathrm{\mathcal{G}\mathcal{P}}\,}}\left( 0,k(x,x')\right) \) equivalently leads to a linear representation of \(f(\cdot )\) via
where \(\beta _j \sim {{\,\textrm{Normal}\,}}(0,1)\), with \(j=1,\dots ,2J+1\). The cosine \(\cos (j\omega _0 x)\) and sinus \(\sin (j\omega _0 x)\) terms do not depend on the covariance hyperparameters \(\ell \). The only dependence on the hyperparameter \(\ell \) is through the coefficients \(\tilde{q}_j\), which are J-dimensional. The computational cost of this approximation scales as \(O\big (n(2J+1) + (2J+1)\big )\), where n is the number of observations and J the number of cosine terms. The parameterization in Eq. (B.8) is naturally in the non-centered form with independent prior distributions on \(\beta _j\), which makes posterior inference easier.
C Description of the iterative steps applied to perform diagnostic on two of the data sets in Fig. 1
As concrete examples, the iterative steps applied to perform diagnostic on two of the data sets in Table 1 are described next:
Data set with the squared exponential kernel and true length-scale \(\ell _{\text {GP}} = 0.08\):
-
Iteration 1:
-
1.
Compute the boundary S of the input values by using Eq. (16) \(\rightarrow \) \(S=1\).
-
2.
Make an initial guess for the length-scale \(\ell \) \(\rightarrow \) \(\ell _1=0.5\).
-
3.
Compute the optimal \(c_1\) as a function of \(\ell _1\) and S by using Eq. (20) \(\rightarrow \) \(c_1=1.60\).
-
4.
Compute the minimum \(m_1\) as a function of \(c_1\), \(\ell _1\), and S by using Eq. (19) \(\rightarrow \) \(m_1=6\).
-
5.
Fit the HSGP model and obtain the estimated \(\hat{\ell }_1\) \(\rightarrow \) \(\text {mean}(\hat{\ell }_1)=0.17\).
-
6.
The diagnostic \(\hat{\ell }_1 + 0.01 \ge \ell _1\) gives FALSE.
-
1.
-
Iteration 2:
-
1.
As the diagnostic in iteration 1 was FALSE, set \(\ell _2 = \hat{\ell }_1\).
-
2.
Compute the optimal \(c_2\) as a function of \(\ell _2\) and S by using Eq. (20) \(\rightarrow \) \(c_2=1.20\).
-
3.
Compute the minimum \(m_2\) as a function of \(c_2\), \(\ell _2\), and S by using Eq. (19) \(\rightarrow \) \(m_2=13\).
-
4.
Fit the HSGP model using \(c_2\) and \(m_2\) and obtain the estimated \(\hat{\ell }_2\) \(\rightarrow \) \(\hat{\ell }_2=0.07\).
-
5.
The diagnostic \(\hat{\ell }_2 + 0.01 \ge \ell _2\) gives FALSE.
-
1.
-
Iteration 3:
-
1.
As the diagnostic in previous iteration 2 was FALSE, updating \(\ell _3\) with \(\hat{\ell }_2\) and repeat the process as in iteration 2.
-
2.
The diagnostic \(\hat{\ell }_3 + 0.01 \ge \ell _3\) gives TRUE.
-
1.
-
Iteration 4:
-
1.
As the diagnostic in step 4 in previous iteration 3 was TRUE, set \(m_4 = m_3 + 5\).
-
2.
Compute the optimal \(c_4\) as a function of \(\ell _3\) and S by using Eq. (20) to \(c_4=1.20\).
-
3.
Fit the HSGP model using \(c_4\) and \(m_4\) and obtain the estimated \(\hat{\ell }_4\) to \(\hat{\ell }_4=0.08\).
-
4.
The diagnostic \(\hat{\ell }_4 + 0.01 \ge \ell _4\) gives TRUE.
-
5.
As RMSE, \(R^2\), and ELPD are stable relative to previous iteration 4, the HSGP approximation is likely sufficiently accurate and the procedure ends here.
-
1.
Data set with the squared exponential kernel and true length-scale \(\ell _{\text {GP}} = 1.4\):
-
Iteration 1:
-
1.
Compute the boundary S of the input values by using Eq. (16) \(\rightarrow \) \(S=1\).
-
2.
Make an initial guess for the length-scale \(\ell \) \(\rightarrow \) \(\ell _1=1\).
-
3.
Compute the optimal \(c_1\) as a function of \(\ell _1\) and S by using Eq. (20) \(\rightarrow \) \(c_1=3.20\).
-
4.
Compute the minimum \(m_1\) as a function of \(c_1\), \(\ell _1\), and S by using Eq. (19) \(\rightarrow \) \(m_1=6\).
-
5.
Fit the HSGP model and obtain the estimated \(\hat{\ell }_1\) \(\rightarrow \) \(\hat{\ell }_1=1.02\).
-
6.
The diagnostic \(\hat{\ell }_1 + 0.01 \ge \ell _1\) gives TRUE.
-
1.
-
Iteration 2:
-
1.
As the diagnostic in previous iteration 1 was TRUE, set \(m_2 = m_1 + 5\).
-
2.
Compute the optimal \(c_2\) as a function of \(\ell _2\) and S by using Eq. (20) \(\rightarrow \) \(c_2=3.27\).
-
3.
Fit the HSGP model using \(c_2\) and \(m_2\) and obtain the estimated \(\hat{\ell }_2\) \(\rightarrow \) \(\hat{\ell }_2=1.23\).
-
4.
The diagnostic \(\hat{\ell }_2 + 0.01 \ge \ell _2\) gives TRUE.
-
5.
As RMSE, \(R^2\), and ELPD are stable relative to previous iteration 2, the HSGP approximation is likely sufficiently accurate and the procedure ends here.
-
1.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Riutort-Mayol, G., Bürkner, PC., Andersen, M.R. et al. Practical Hilbert space approximate Bayesian Gaussian processes for probabilistic programming. Stat Comput 33, 17 (2023). https://doi.org/10.1007/s11222-022-10167-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-022-10167-2