
Abstract
An important societal problem is that people underinsure against risks that are unlikely or occur in the far future, such as natural disasters and long-term care needs. One explanation is that uncertainty about the risk of non-reimbursement induces ambiguity averse and risk prudent decision makers to take out less insurance. We set up an insurance experiment to test this explanation. Consistent with the theoretical predictions, we find that the demand for insurance is lower when the nonperformance risk is ambiguous than when it is known and when decision makers are risk prudent. We cannot attribute the lower take-up of insurance to our measure of ambiguity aversion, probably because ambiguity attitudes are richer than aversion alone.
Similar content being viewed by others


1 Introduction
The motivation for this paper is an important puzzle in insurance economics: why do people take out too little insurance against risks with potential huge consequences, such as natural disasters and long-term care needs. Standard insurance theory suggests that such insurance should be valuable as it protects individuals against the potentially devastating costs of these events. In practice, however, the holding of such insurance is (too) low.Footnote 1 Although various reasons have been put forward to explain this puzzle, it is still only partially understood. A better understanding is important for policy, as it may protect people from financial distress and governments from footing the bill.
One possible reason is that people are concerned that insurers will not pay out future claims. This is not unheard of. For example, after Hurricane Katrina, insurers denied coverage to people who had home insurance, but no additional flood coverage (Kunreuther & Pauly 2006). During the COVID-19 pandemic, insurers across the globe have been hesitant to pay out claims for business interruption insurance and there is a fair amount of ongoing litigation about whether lost business income due to lockdowns is covered or not. Concerns about such nonperformance may be particularly grave when benefits occur in the far future, which carries the risk that insurers may go bankrupt, and which makes the value of insurance inherently more risky and ambiguous.Footnote 2Footnote 3 The purpose of this paper is to explore the role of ambiguity regarding nonperformance on insurance take-up. We consider the case of full insurance. Because full insurance is equivalent to what Ehrlich and Becker (1972) call self-protection, our results also help to better understand underinvestment in prevention.
Multiple theoretical predictions relevant to insurance with nonperformance risk pointed to the importance of (higher order) risk and ambiguity attitudes in explaining behavior.Footnote 4 While the effect of risk aversion is equivocal (Dionne & Eeckhoudt, 1985), Peter & Ying (2020) show that ambiguity averse decision makers will reduce their demand for insurance when the nonperformance risk is ambiguous. Moreover, developments in the domain of higher order risk preferences, which relate to how people prefer to combine risks, suggest that risk prudence has an important effect: it decreases the demand for insurance with nonperformance risk (Eeckhoudt & Gollier, 2005). These theoretical predictions have, however, received little attention in the empirical literature.
We set up an experiment and relate uptake decisions for full insurance to both ambiguity and (higher order) risk and ambiguity preferences. Our main finding is that ambiguity of the nonperformance risk indeed decreases the demand for insurance. Risk attitudes are important in explaining insurance behavior: risk aversion increases insurance demand, while risk prudence, as predicted, affects it negatively. We could not link the observed insurance behavior to our measure of ambiguity aversion. The reason was that the ambiguity attitudes we observed were richer than aversion alone: for more likely events our subjects were predominantly ambiguity loving (remember that insurance decisions involve losses). The main factor influencing insurance demand is the size of the insurable risk. The larger this probability is, the more likely our subjects were to demand insurance. While our findings on ambiguity attitudes are consistent with prospect theory, the findings on the role of the loss probability are not. They pose a challenge to prospect theory.
This paper proceeds as follows. Section 2 provides a review of the literature. Section 3 presents our experiment design. Section 4 presents our empirical findings. Implications of which are discussed in Section 5. Section 6 concludes.
2 Background
2.1 Theory
Consider a standard full insurance policy. This theoretical product fully reimburses a loss \(L\) occurring with probability \(p\) (the insurable risk) and is available at an actuarially fair premium \(\pi =pL\). In practice, however, insurance has a probability of nonperformance with which insurers do not pay out a valid claim. Nonperformance may occur for various reasons, one of which is that that benefits occur in the far future and the insurance company may no longer exist.
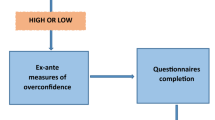
If there is a risk of nonperformance \(q\), buying insurance no longer eliminates the insurable risk, but reduces it from \(p\) to \(pq>0\). In our experiment, \(p\) and \(q\) may or may not be objectively known. If either \(p\) or \(q\) is unknown (or if both are), the decision is made under ambiguity. An individual’s choice whether to buy insurance can be schematically depicted as in Fig. 1.In the special case of full insurance, insurance with nonperformance risk is equivalent to Ehrlich and Becker's (1972) concept of self-protection (also called prevention): both reduce the risk of incurring a loss, but they do not completely remove it.Footnote 5 Hence, while part of the literature that we discuss below is framed as prevention, their results are equally applicable to insurance decisions with a risk of nonperformance in the special case of full insurance. One caveat that should be made here is that in Fig. 1 the choice is binary: either insurance or no insurance. Most of the literature on self-protection is about the level of effort. Denuit et al. (2016) show, however, that the same difficulties that have been identified to choice of the optimal level of self-protection apply to the binary choice between two levels of self-protection.

The insurance choice: no insurance (left) versus insurance with nonperformance risk (right)
The literature has identified several factors that affect demand for insurance with nonperformance risk. The first contributions focused on the role of risk aversion, taking \(q\), the probability of nonperformance, as known. Dionne and Eeckhoudt (1985) show that for expected utility maximizers with a quadratic utility function, risk aversion increases (decreases) the uptake of insurance with nonperformance risk when \(p<0.5\) (\(p>0.5\)). This result arises because the insurance itself is risky; purchasing it deteriorates the worst possible outcome with the insurance premium paid (Bryis & Schlesinger, 1990).Footnote 6 Jullien et al. (1999) extend Dionne and Eeckhoudt’s (1985) analysis to more general utility functions. They derive that in general the effect of risk aversion on insurance uptake is also inverse U-shaped: risk aversion increases insurance uptake up to some endogenous threshold of \(p\), which depends on the utility functions of both agents under comparison, and then decreases it.Footnote 7
Eeckhoudt and Gollier (2005) show that higher order risk attitudes also affect the demand for insurance. In particular, they prove that, compared with the risk-neutral benchmark, risk prudence reduces the demand for insurance. Peter (2020) shows that this also holds when the benchmark agents has more general risk preferences. Risk prudence implies an aversion to downside risk or to combining bad events with bad events (Eeckhoudt & Schlesinger, 2006). Buying insurance with nonperformance risk entails more downside risk, as two bad events can occur simultaneously: paying the premium, while also incurring the loss. This makes such insurance unattractive to risk prudent individuals. Menegatti (2009) and Peter (2017) extend these findings to an intertemporal model where the decision maker pays an insurance premium now to cover a future loss in the presence of nonperformance risk. Courbage and Rey (2006) extend the analysis of the effect of prudence on insurance to decisions involving both health and wealth. They show that individuals who lose more from being sick will demand more insurance, provided that they are less prudent about wealth.
The above analyses are based on expected utility. Baillon et al. (2020) consider rank-dependent utility (prospect theory for losses) and derive the implications of probability weighting on prevention, which, as we noted above, is equivalent to full insurance with nonperformance risk. They show that for intermediate probabilities, inverse S-shaped probability weighting, the most commonly observed case, will lead to underinsurance.
Finally, Snow (2011) and Peter and Ying (2020) study the impact of ambiguity aversion when the insurance decision is made under ambiguity. They both assume that the decision maker is risk and ambiguity averse. This assumption is not uncontroversial as people tend to be ambiguity seeking for unlikely events and losses (Kocher et al., 2018), which typically occur in insurance decisions. Peter and Ying (2020) show that an ambiguous nonperformance risk always reduces the demand for insurance (compared with a known nonperformance risk), regardless of whether the insurable risk is ambiguous or not. Snow (2011) shows that an ambiguous insurable risk increases the demand for insurance in the presence of a known nonperformance risk.Footnote 8 This happens because insurance reduces the ambiguity of the insurable risk and an ambiguity averse decision maker likes reductions in ambiguity.Footnote 9
Table 1 summarizes the various cases. The first letter indicates whether the insurable risk (\(p\)) is known (\(K\)) or unknown (\(U\)) and the second letter whether the nonperformance risk (\(q\)) is known (\(K\)) or unknown (\(U\)). A \(+\) (\(-\)) sign indicates that insurance demand is higher (lower) for the row combination than for the column combination. A question mark indicates that this case has not yet been explored in the literature. Combining the results of Peter and Ying (2020) and Snow (2011), Table 1 shows that the demand for insurance must be higher when the insurable risk is unknown and the nonperformance risk is known than when the insurable risk is known and the nonperformance risk is unknown: in the first case, insurance reduces ambiguity, whereas in the latter case, it increases it.Footnote 10
The impact of higher order ambiguity preferences has hardly been explored. This is partly because they were defined only recently (Baillon, 2017). Peter and Ying (2020) derive that more ambiguity leads to less insurance demand provided that ambiguity prudence is not too large.
2.2 Empirical evidence
Several studies have shown that the introduction of a known nonperformance risk decreases the demand for full insurance (Herrero et al., 2006; Wakker et al., 1997; Zimmer et al., 2009, 2018). Bajtelsmit et al. (2015) show that this also holds when the nonperformance risk is ambiguous. Biener, Landman and Santana (2019) find tentative evidence that an ambiguous nonperformance risk may reduce insurance demand compared to a known one. This is an empirical matter that we will further address in our current study.
Krieger and Mayrhofer (2017) and Masuda and Lee (2019) investigate the role of higher-order risk preferences in prevention decisions. Krieger and Mayrhofer (2017) find that more prudent decision makers invest less in prevention, which is consistent with the predictions of Eeckhoudt and Gollier (2005). Masuda and Lee (2019) also find that their subjects exert too little preventive effort regardless of the timing of the loss. They argue that their results cannot be explained by expected utility and suggest probability weighting as an alternative explanation, in line with the analysis of Baillon et al. (2020).
3 Experiment
The purpose of our paper is twofold. First, we empirically test the theoretical predictions in Table 1 and provide a complete picture of the effects of unknown insurable and nonperformance risks on the demand for insurance. Second, we explore whether the demand for insurance can be related to risk aversion and prudence and, in the cases where the risks are unknown, to ambiguity aversion and prudence. We therefore consider both known and unknown insurable risk and nonperformance risk: we consider each of the four cases \(KK\)(both the probability of the insurable loss and the probability of nonperformance are known), \(KU\), \(UK\), and \(UU\).
3.1 Subjects
117 students from Erasmus University Rotterdam participated in the experiment, which was conducted at the Erasmus Behavioural Lab (EBL). There were 12 sessions with a maximum of 12 participants per session. Participants were seated in cubicles to avoid interaction. They were recruited from the subject pool of the EBL and they were instructed that the experiment could last up to 1 h and 15 min. Participants were told that their expected payoff from the experiment was €25 with a minimum of €3.40 and a maximum of €134.20. Before starting the experiment, participants received €25 in cash. They were told that the experiment involved both the possibility of losing money and the possibility of gaining money and that they could pay eventual losses out of the €25. In this way, participants were stimulated to think of the average €25 payment as a reference point. The average payment per participant turned out to be €23.90.
3.2 Incentives
The experiment was incentivized using the PRINCE incentive system (Johnson et al. 2021), which has the advantage of making incentive compatibility transparent to the participants. The main property of PRINCE is that the choice to be played out for real is chosen upfront. In our study, prior to the experiment, participants were asked to pick any of 92 sealed envelopes representing the 92 choice tasks in the experiment. The participants took their selected envelope to their cubicle, making it clear that their answers could not affect the selection of the task that they would play out for real. They were not allowed to open their envelope until they returned to the instruction room after the experiment. The experiment choices were framed as instructions to the experimenters: for all 92 choice tasks participants were asked: “If your envelope contains this choice, which option would you like us to play out for real?” The choice tasks that the envelope contained described the entire choice task (that is, both options from a given task). The option that was played out for real was the one chosen by the participant in that choice task.
3.3 Experiment design
The experiment consisted of two parts, one measuring the demand for insurance with nonperformance risk, the other measuring participants’ attitudes towards risk and ambiguity. In total, the experiment consisted of 92 binary choices: 56 choices measuring the demand for insurance, 32 choices measuring risk and ambiguity attitudes, and 4 choices that were repeated to test the quality of the data. A complete list of the choices is presented in Tables 4–9 in Online Appendix A.
3.3.1 Insurance tasks
We used four treatments to measure the demand for insurance with nonperformance risk, which varied depending on whether the insurable risk and the nonperformance risk were known (\(K\)) or unknown (\(U\)). Thus, we studied all situations \(KK\), \(KU\),\(UK\) and \(UU\) listed in Table 1. There were 9 choices per treatment. In addition, we included five choices per treatment involving gains to make sure the expected payment from the experiment was €25. These choices are not used in the analyses.
Figure 2 shows an example of a choice from treatment \(KK\), Fig. 3 shows the counterpart from treatment \(UU\). All choices were represented as situations where a token is drawn from a bag, possibly followed by a second draw from another bag. All bags contained 10 tokens. For risky choices, the tokens were colored (red and yellow or blue and orange as in Fig. 2), for ambiguous choices, they had a question mark (see Fig. 3). It was explained that the ambiguous bags contained 10 tokens with letters (A – J or Q – Z) in unknown proportion and that each letter could occur between 0 and 10 times. The bags were filled according to the instructions of a random person not affiliated with the experiment and participants were informed about this. To avoid suspicion, we asked each participant before the start of the incentivized choice tasks whether they wanted the letter A to be associated with the best outcome, the letter B with the second best outcome etcetera, or whether they wanted the ranking to be reversed (such that A was associated with the worst outcome and Z with the best outcome).

Example of a choice task with known probabilities

Example of a choice task with unknown probabilities
Figures 2 and 3 show that in the tasks measuring insurance demand, one option resembled no insurance and the other resembled insurance with a nonperformance risk. The no insurance option (we did not use this term in the experiment) involved a possible loss (€17.50 in Figs. 2 and 3). In the insurance option, subjects paid an actuarially fair premium (€1.40 in Figs. 2 and 3) to reduce the probability of the loss, but there was a nonperformance risk. This is depicted by the bag containing orange and blue tokens in Fig. 2 and by the bag containing tokens with letters Q – Z in Fig. 3. Note that we deliberately presented the insurance options as compound lotteries, to emphasize the differences in potential outcomes with the no insurance option.
3.3.2 Risk and ambiguity attitudes
The second part measured risk aversion (9 choices), risk prudence (9 choices), ambiguity aversion (9 choices), and ambiguity prudence (5 choices). Figures 10–13 in Online Appendix A give examples for each of these tasks. We used fewer choices to measure ambiguity prudence, because these questions were more complex and cognitively demanding. We developed these choice tasks to stay as close as possible to the insurance tasks. Hence, all tests involved only losses and €0. In addition, the risk and ambiguity prudence tasks were also presented in a compound form.Footnote 11
A decision maker is risk averse when preferring a lottery over a mean-preserving spread of that lottery. To avoid the certainty effect, we chose to have both options risky. Then, risk aversion is defined as the preference:
for all \(p\in [\mathrm{0,1}]\) and \(k,r>0\). In the left lottery the harms \(-k\) and \(-r\) are disaggregated, i.e., only one of them occurs, while in the right lottery they are aggregated. In our experiment, \(p\) varied from \(0.1\;{\mathrm{to}}\;0.9\) in steps of \(0.1\).
Eeckhoudt and Schlesinger (2006) define risk prudence as the preference of \((0.5:-k,0.5: \tilde{\varepsilon })\) over \((0.5:-k+\tilde{\varepsilon }, 0.5:0)\) for all \(k>0\) and for all zero mean random variables \(\tilde{\varepsilon }\). This can be interpreted as a preference to disaggregate the two harms \(-k\) and \(\tilde{\varepsilon }\) over aggregating them.Footnote 12 The decision maker rather bears the loss in the state of the world where they do not bear the risk. In our experiment, \(\tilde{\varepsilon }\) is a binary random variable with equiprobable outcomes \(s\) and \(-s\). For each task, a sure amount c was deducted such that all possible outcomes were in the loss domain and choices could not be affected by loss aversion.
Where risk aversion and risk prudence are conditions about the spread of outcomes over different states, ambiguity aversion and ambiguity prudence are conditions about the spread in probabilities. Let \(\tilde{\varepsilon }\) now denote a zero-mean nondegenerate random variable to which a probability \(p\) can be added such that \(p+\tilde{\varepsilon }\in [\mathrm{0,1}]\). The lotteries \((p:-k,1-p:0)\) and \((p+\tilde{\varepsilon }:-k,1-p-\tilde{\varepsilon }:0)\) then have the same expected probabilities of losing \(k\), but for the first lottery this probability is known, while for the second lottery it is unknown. A decision maker is ambiguity averse if they prefer the lottery with known probabilities over the lottery with unknown probabilities:
for all zero mean random variables \(\tilde{\varepsilon }\), for all \(p+\tilde{\varepsilon }\in[\mathrm{0,1}]\) and for all \(k\).
Baillon (2017) defined the notion of ambiguity prudence. To define ambiguity prudence, we change the notation slightly. Let \((\{p,q+\tilde{\varepsilon }\}:-L)\) denote a lottery that determines with an unknown probability whether a loss of \(L>0\) is given with known probability \(p\) or with unknown probability \(q+\tilde{\varepsilon }\) and else nothing happens (i.e., the outcome is 0). Now consider a given increase \(k\) in the probability of the loss \(L\). Ambiguity prudence says that the decision maker will prefer to disaggregate these two harms. In other words, ambiguity prudent decision makers will prefer \((\{p+k,q+\tilde{\varepsilon }\}:-L)\) to \((\{p,q+\tilde{\varepsilon }+k\}:-L)\).Footnote 13 As an example, we have \(p=0.5\), \(q=0.35\) and \(k=0.4\) in Fig. 10 in the Online Appendix A.
Participants randomly started with the insurance part or with the risk and ambiguity part of the experiment. The order of the sub-parts within these parts and of the choice tasks within these sub-parts was also randomized.Footnote 14 The location (left or right) of any two options was randomized for each decision for each subject. After answering the incentivized choice tasks, participants were asked to answer four background questions. Two of these asked for subjects’ gender and nationality (two of the main sources of variation in experimental samples). The other two were directly related to insurance uptake, asking subjects to indicate which insurance products (e.g., mobile phone insurance, legal aid insurance) they have and how large the voluntary deductible on their mandatory health insurance is.
Before the experiment, participants were given a generic instruction of the incentive structure in the instruction room (see Online Appendix B1). Further instructions for the choice tasks were provided upon starting the experiment and are shown in Online Appendix B2. After these instructions, participants answered four true–false questions to check their comprehension of the experiment. They could only proceed to the incentivized choice tasks once they had answered all comprehension questions correctly. In this way, participants received feedback on their understanding of the choice tasks. Additionally, summaries of the particularities of the choice tasks were given at the start of each sub-part and were followed by one true–false question. We ensured that an experimenter was available at all times to answer participants’ questions.
After the experiment, participants were asked to return to the instruction room and choices were played out for real. A token was drawn for each of the possible bags used in the experiment. After drawing the tokens, participants could open their envelopes and the choice task it contained was recreated. Risky probabilities were played out by drawing colored tokens from a bag. For each probability \(p\), a token was drawn from a bag with a total of 10 red or yellow tokens. The bags with colored tokens were filled while the participants were present so that they could check that the bags contained the correct number of red and yellow tokens. Then, a token was drawn 9 times; that is for all probabilities \(0.1\le p\le 0.9\) (Fig. 2 shows \(p=0.1\)). Similarly, for \(q\), a token was drawn from a bag with a total of 10 blue or orange tokens in compositions representing \(0.1\le q\le 0.9\) (Fig. 2 shows \(q=0.2\)). Ambiguous probabilities were played out by drawing a token from a bag containing letters A – J (for \(p\)) and from a bag containing letters Q – Z (for \(q\)).
4 Results
4.1 Risk and ambiguity attitudes
The theoretical results that we discussed in Section 2 show that risk and ambiguity attitudes play a central role in explaining insurance decisions with nonperformance risk. We, therefore, first present the results on risk aversion, risk prudence, ambiguity aversion, and ambiguity prudence before discussing our main result, the effect of ambiguity on the demand for insurance.
Figure 4 shows the proportion of risk and ambiguity averse choices split out by the loss probability. In the case of ambiguity, the displayed probability is the proportion of letters associated with the worst outcome. The figure shows evidence for the loss part of the fourfold pattern of risk and ambiguity aversion suggested by prospect theory: for small probabilities, subjects were mostly risk and ambiguity averse, for larger probabilities they were mostly risk and ambiguity seeking.

Proportion of risk averse and ambiguity averse choices for different loss probabilities
Overall, neither risk nor ambiguity aversion dominates. Bayesian tests provide strong support for the null that overall subjects are equally likely to choose the risky and the less risky option (Bayes factorFootnote 15 (\(BF\)) \(=0.08\)) and support for the null that they are equally likely to choose the ambiguous and the unambiguous option (\(BF=0.11\)). However, as we noted, this is driven by a consistent aggregate pattern of risk and ambiguity aversion for small loss probabilities and risk and ambiguity loving choices for medium and large loss probabilities. Bayesian testing shows support for the hypothesis that the proportion of risk averse choices is correlated with the loss probability (\(BF=5.7\)) and very strong support for the hypothesis that the proportion of ambiguity averse choices is correlated with the loss probability (\(BF=50.9\)).
Individual tests show support for risk aversion for probabilities less than \(0.6\) (all \(BF>4.38\) except for probability \(0.1\) for which the Bayesian test is inconclusive (\(BF=0.72\)), support for risk neutrality for probability \(0.6\) (\(BF=0.23\)), and very strong support for risk seeking for probabilities exceeding \(0.6\) (all \(BF>62.5\)). They also show very strong support for ambiguity aversion for probabilities less than \(0.4\) (all \(BF>2.03\times {10}^{5}\), for probability \(0.4\) the test is inconclusive (\(BF=2.86\))), support for ambiguity neutrality for probability \(0.5\) (\(BF=0.27\)), and very strong support for ambiguity seeking for probabilities exceeding \(0.5\) (all \(BF>472.8\)).
We further investigate subjects’ risk and ambiguity attitudes by classifying them into four different types: averse, loving, inverse S-shaped, and S-shaped. Inverse S-shaped is the assumption underlying prospect theory. It involves aversion for small probabilities of a loss but loving for large probabilities. S-shaped is the opposite, loving for small loss probabilities but aversion for large probabilities.
Subjects were classified as risk [ambiguity] averse if they chose the least risky [ambiguous] option at least twice both in the three tasks where the probability of a loss was at most \(0.3\) (‘small probabilities’) and in the three tasks where the probability was at least \(0.7\) (‘large probabilities’). They were classified as risk [ambiguity] loving if they chose the most risky [ambiguous] option at least twice in both the small and the large probability tasks. Subjects were classified as inverse S-shaped if they chose the least risky [ambiguous] option at least twice in the small probability tasks and no more than once in the large probability tasks. Finally, they were classified as S-shaped if they chose the riskiest option at least twice in the small probability tasks and no more than once in the large probability tasks.
Figure 5 shows the classification of subjects for both risk and ambiguity. Inverse S is clearly the most common pattern. This is consistent with common findings (for risk, see e.g., Abdellaoui (2000) and Etchart-Vincent (2004), for ambiguity see e.g., Viscusi and Chesson (1999) and Baillon and Bleichrodt (2015)). Only a minority of the subjects behaved in line with the theoretically common assumptions of risk and ambiguity aversion. There are even substantially more subjects who were risk loving than risk averse.

Proportion of subjects by risk and ambiguity attitudes
Figure 6 shows the subdivision of subjects depending on the number of risk prudent choices. The figure displays a tendency to risk prudence with on average \(5.31\) risk prudent choices across the 9 tasks. A Bayesian test gives decisive support for risk prudence over the null of risk imprudence or neutrality (\(BF = 3.51\times {10}^{6}\)). This is inconsistent with the findings of Bleichrodt and van Bruggen (forthcoming), who found risk imprudence for losses.

Number of subjects choosing each number of risk prudent choices
Finally, Fig. 7 shows the subdivision of subjects depending on their number of ambiguity prudent choices. There is a slight tilt towards ambiguity imprudence. A Bayesian test shows support for the ambiguity imprudence over ambiguity prudence or neutrality (\(BF = 24.13\)). This finding goes against Baillon et al. (2018) who found predominant ambiguity prudence. However, they used gains whereas we use losses, which might explain the difference as this is consistent with a reflection effect for higher order preferences (Bleichrodt & van Bruggen, forthcoming).

Number of subjects choosing each number of ambiguity prudent choices
4.2 Insurance choices
The central question of our paper is how unknown insurable risks and nonperformance risks change insurance decisions compared to the case where these risks are known. Figure 8 shows the mean number of choices (out of 9) in which subjects chose the insurance option. The results illustrate that moving from a known to an unknown probability made the insurance option less attractive. This effect is particularly pronounced for the probability of nonperformance. Bayesian testing shows support for the hypothesis that subjects choose insurance more often when the nonperformance risk is known than when it is unknown (treatments \(KK\) and \(UK\) versus treatments \(KU\) and \(UU\)) (\(BF=13.1\)).Footnote 16 However, when comparing choices for known and unknown insurable risks (treatments \(KK\) and \(KU\) versus treatments \(UK\) and \(UU\)), we find support for the null that the number of insurance choices is the same (\(BF=0.18\)).

Mean number of insurance choices (out of 9) per treatment. Notes: Treatments \(KK\), \(KU\), \(UK\) and \(UU\) indicate whether the insurable risk and nonperformance risk respectively are known \((K)\) or unknown \((U)\)
We obtain mixed results regarding the theoretical predictions outlined in Table 1. As mentioned in the previous paragraph, we find support for the prediction of Peter and Ying (2020) that an ambiguous nonperformance risk reduces the demand for insurance.Footnote 17 However, we find no support for Snow’s (2011) prediction that insurance demand should be higher in treatment UK than in treatment KK. A Bayesian test supports the null that insurance demand was the same in these two treatments (\(BF=0.13\)). Similarly, we find no support for the prediction derived by combining the results of Peter and Ying (2020) and Snow (2011) that the demand for insurance should be higher in treatment UK than in treatment KU. A Bayesian test again supports the null that the demand for insurance was the same in these two treatments (\(BF=0.18\)).
It should be kept in mind though that the theoretical predictions of Peter and Ying (2020) and Snow (2011) are made under the assumption that subjects are risk and ambiguity averse. We saw in Sect. 4.1 that this is true for most subjects for probabilities less than 0.5. The probability of nonperformance was always less than 0.5 in our experiment, but the insurable risk could exceed \(0.5\). An analysis of only those insurance choices in which the insurable risk was at most 0.4 confirmed all previous results with one important exception: Snow's (2011) prediction that subjects should be more inclined to choose insurance in treatment \(UK\) than in treatment \(KK\) was now very strongly supported (\(BF=39.6\)).Footnote 18
Figure 9 shows for each of the four treatments how the proportion of insurance choices varies with the insurable risk. There is a trend for subjects to choose insurance more often when the insurable risk increases,Footnote 19 particularly when it is known. Bayesian tests shows support for a positive correlation between the number of insurance choices and the insurable risk in all treatments (all \(BF>4.8\), taking all treatments together the \(BF=12.4\)).

Proportion of insurance choices for each treatment by insurable risk. Notes: Treatments \(KK\), \(KU\), \(UK\) and \(UU\) indicate whether the insurable risk and nonperformance risk respectively are known \((K)\) or unknown \((U)\). Trend line fitted by loess method. Bands show the 95% confidence interval
The dependence of insurance choice on the insurable risk is at odds with the predictions of inverse S-shaped weighting, the dominant pattern observed in our risk aversion tasks, if utility is linear and reduction of compound lotteries holds.Footnote 20 Inverse S with linear utility predicts that subjects will be more inclined to buy insurance for small than for large loss probabilities, which is the opposite pattern of what we observe. The same pattern emerges when we restrict the analysis to those subjects who were actually classified as inverse S in the analysis of risk attitudes described above. The pattern of insurance choices is consistent with S-shaped weighting, but the number of subjects displaying S-shaped weighting is too low to perform meaningful analyses. The assumption of reduction of compound lotteries is not innocuous (e.g., Bernasconi, 1994). We therefore also analyzed the results under a recursive rank-dependent utility model, but this performed even worse (see Online Appendix D for details).
To extend our understanding of what drives the observed insurance decisions, we performed probit analyses with the choices in our insurance tasks as the dependent variables. In line with theoretical predictions, the results in Table 2 show that an unknown nonperformance risk leads to less insurance demand. On the other hand, ambiguity of the insurable risk has no effect on insurance demand. The lower demand for insurance with unknown nonperformance risk cannot be attributed to our measure of ambiguity aversion. Because ambiguity preferences cannot impact insurance decisions in treatment \(KK\), where all risks were known, and because ambiguity aversion is predicted to affect demand differently for different treatments, we included interaction terms of ambiguity preferences and our treatments.Footnote 21 None of the interaction terms is statistically significant. Ambiguity aversion has a positive impact only when it is included as a general variable for the subjects who had been classified as ambiguity averse (see Table 10 in Online Appendix E). However, this has no clear interpretation. Ambiguity prudence never affects the demand for insurance, but this should perhaps not come as a surprise given that its effect is not unequivocal as derived by Peter and Ying (2020).
Table 2 also shows that the insurable risk (\(p\)) has the largest marginal effect on insurance choice. It is positive, confirming that subjects were more inclined to choose the insurance option for higher loss probabilities. Subjects who were more risk averse chose insurance more often. The negative effects of risk prudence on insurance demand are in line with Eeckhoudt and Gollier (2005). Finally, we corrected for gender and nationality, the two main sources of variation in experimental studies.Footnote 22 Males were more likely to choose insurance, but nationality had no effect.Footnote 23Footnote 24
Because the theoretical models discussed in Section 2 concentrate on the risk and ambiguity averse subjects, we also separately analyzed choices with insurable loss probabilities of at most 0.5, the range for which most subjects were risk and ambiguity averse. Table 3 shows that the results change somewhat. In this range, the effect of an unknown nonperformance risk becomes less pronounced. On the other hand, the uptake of insurance with an unknown insurable risk and known nonperformance risk is higher and becomes significant, as predicted by Snow (2011). Also, the effect of risk attitudes becomes more important. As the results reported in Online Appendix E (Table 11; Fig. 14) suggest, consistent with the theoretical predictions of Jullien et al. (1999), this is because risk aversion only increases insurance demand up to a threshold of \(p\).
5 Discussion
Our main conclusion is that an ambiguous nonperformance risk indeed leads to a reduction in insurance demand compared to a known nonperformance risk. Previous studies have already shown that nonperformance risk reduces the demand for insurance. We show that the more realistic case where the nonperformance risk is unknown further reduces the demand for insurance. This could help explain people’s reluctance to take up insurance against for example natural disasters or long-term care needs. Our results may also help to understand why people fail to undertake prevention measures, which is equivalent to the full insurance decisions that we – like previous experiments on nonperformance risk – examine.
Previous theoretical studies have primarily analyzed insurance decisions with nonperformance risk by assuming that decision makers are risk and ambiguity averse. If we restrict attention to the choices for which most subjects were risk or ambiguity averse, then most of these predictions were supported. Risk aversion leads to more insurance demand, while risk prudence reduces it, which is consistent with theoretical predictions (Dionne & Eeckhoudt, 1985; Eeckhoudt & Gollier, 2005). We can also confirm Peter and Ying's (2020) prediction that an ambiguous nonperformance risk leads to less insurance than a known nonperformance risk. At probabilities for which most individuals are risk and ambiguity averse, we found support for Snow's (2011) prediction that ambiguity of the insurable risk leads to more insurance demand.
Although we find that ambiguity of the nonperformance risk decreases the demand for insurance, ambiguity aversion did not appear to drive this effect in our regression analysis. In the analysis, ambiguity aversion was included as a dummy indicating whether a subject mostly chose the ambiguity averse option or not, consistent with the theoretical literature where ambiguity aversion is taken as a universal preference.Footnote 25 Our data shows that the assumption of uniform risk and ambiguity aversion is too restrictive. Most subjects displayed the common empirical pattern of risk and ambiguity aversion for small loss probabilities and risk and ambiguity seeking for larger loss probabilities. A general ambiguity aversion variable cannot capture this diversity of ambiguity preferences within subjects and may therefore fail to fully pick up the effects of ambiguity averse (or seeking) preferences.
We find that most subjects are risk prudent, which goes against Bleichrodt and van Bruggen (forthcoming) who find clear evidence of risk imprudence for losses. The different findings may be due to differences in presentation: to ensure internal consistency with the presentation of the insurance tasks, the presentation of the prudence tasks in our experiment differed from the presentation in Bleichrodt and van Bruggen (forthcoming).Footnote 26 We find evidence of ambiguity imprudence for losses, which is consistent with the reflection effect for higher order risk preferences observed by Bleichrodt and van Bruggen (forthcoming) and the predominant ambiguity prudence observed by Baillon, Schlesinger and van de Kuilen (2018) for gains.
The dependence of insurance choices on the insurable risk remains puzzling. Experimental research has long found (and been unable to explain) a similar dependency in actuarily fair insurance choices without nonperformance risk (Slovic et al., 1977). As we pointed out, this dependency is inconsistent with inverse S-shaped probability weighting if utility is linear. Usually empirical studies find that utility is close to linear for the stakes involved in our study. This poses the question about the external validity of elicited risk preferences: to what extent can they explain other choices people make? We are not alone in observing that inverse S-shaped probability weighting does not predict choice behavior well. Baillon et al. (2019) performed a field experiment in the Philippines in which they tried to nudge health behavior but did not observe the pattern predicted by inverse S-shaped weighting. Jaspersen et al. (forthcoming) explored to what extent models of decision under risk can predict insurance choices. While they found that these insurance choices were coherent and correlated with measures of risk attitude, the models they explored (which included expected utility and prospect theory) predicted these choices poorly and generally performed worse than simple heuristics.
Our results offer insights into the demand for long-term care insurance, which can benefit both policy makers and insurers. Uncertainty about the pay-out of future claims reduces insurance demand. Reducing such ambiguity could increase insurance uptake. This can be achieved through, for example, a common guarantee fund that insures against insurer bankruptcy. When such funds are already in place, increased awareness and transparency may further reduce ambiguity. The premium increase people would be willing to pay for such ambiguity reducing guarantees can be examined in future research. If needed, governments could support or subsidize such guarantees. Our study suggests that it is a worthwhile avenue to explore.
6 Conclusion
An important policy puzzle is why people underinsure against uncertain losses that occur in the far future, such as long-term care needs. Our results show that one possible reason is the unknown nonperformance risk that comes with such insurance. Our results are largely consistent with the predictions made by theoretical models. An ambiguous nonperformance risk decreased the demand for insurance compared with a known nonperformance risk. Risk attitudes play an important role in explaining insurance demand: risk aversion increases insurance demand, while risk prudence reduces it. The effect of ambiguity attitudes was less clear, probably because they are richer than ambiguity aversion alone.
Change history
12 February 2022
A Correction to this paper has been published: https://doi.org/10.1007/s11166-022-09372-1
Notes
Li et al. (2020) make a similar point and observe that insolvency risk of insurers increases over time.
Although state guaranty associations exist in the US to protect against the insolvency of insurers, some states do not allow to advertise this fact, and many consumers are unaware of their existence.
Most predictions have been made in the context of self-protection. Given the equivalence to full insurance with nonperformance risk, we refer to these as insurance predictions throughout.
Buying insurance at premium \(\pi =p(1-q)L\) is then a risk reducing activity equivalent to exerting preventive effort.
Doherty and Schlesinger (1990) show that a similar argument applies to partial insurance with a nonperformance risk, rendering the effect of risk aversion on insurance demand indeterminate.
Peter (2020) finds qualitatively similar results for an exogenous threshold that depends only on the utility of the benchmark agent.
Viscusi (1979) already noted that a more precise (i.e., less ambiguous) probability assessment conversely reduces insurance demand.
Alary et al. (2013) derive the opposite prediction when assuming that insuring (in their paper self-protection) increases the ambiguity of the insurable risk. When insuring does not affect ambiguity, ambiguity aversion may either decrease or increase insurance demand. Snow's (2011) assumption is more natural for our context, and matches our experimental implementation, hence we follow his prediction.
Of course, the lottery \(\stackrel{\sim }{\varepsilon }\) is only seen as a harm if the decision maker is risk averse.
This definition implicitly assumes that all probabilities of a loss lie within the \([\mathrm{0,1}]\) interval.
However, the ambiguity prudence sub-part was always last within the risk and ambiguity part of the experiment, because of the complexity of those choice tasks.
The Bayes factor (BF) indicates how much more likely the alternative hypothesis is than the null. A BF larger than 3 is usually interpreted as providing some support for the alternative, a BF larger than 10 as providing strong support for the alternative, and a BF larger than 30 as providing very strong support for the alternative. Similarly a BF less than 0.33 is interpreted as providing some support for the null, less than 0.1 as providing strong support for the null, and less than 0.03 as providing very strong support for the null. BFs between 0.3 and 3 are interpreted as inconclusive evidence.
We tested this using the contingencyBF function in the R package BayesFactor (Morey & Rouder, 2018) with the assumption that the sampling type was joint multinomial.
However, if we separately compared treatments \(KK\) and \(KU\) and \(UK\) and \(UU\) the evidence was inconclusive (\(BF=1.01\) and \(BF=1.46\), respectively).
Most other tests were inconclusive.
This may sound trivial, but keep in mind that insurance was always actuarially fair, so the insurance premium also increased with the insurable risk. Jang and Hadar (1995) have shown that demand for actuarially fair insurance is not necessarily monotonic in the loss probability for a risk averse expected utility maximizer.
See Online Appendix C for a derivation.
Note that although ambiguity preferences should not play a role for decisions without ambiguity, risk preferences may play a role in decisions with or without ambiguity. Hence, there is no need to similarly interact risk preferences with our treatments.
None of these was associated with insurance choices in the experiment.
Excluding gender and nationality does not affect the interpretation of our results.
Dummies for the holding of different types of real-life insurance were not correlated with the insurance choices in our experiment. This is perhaps not surprising, as the sample consisted of students, who typically have few assets to insure.
Peter and Toquebeuf (2020) propose a framework that allows to formally derive results for ambiguity lovers, who often exhibit reversed behavior.
The difference was not due to the inclusion of the insurance task, as we found no difference in risk prudent choices between the subjects who started with the elicitation of risk and ambiguity attitudes and those who started with the insurance choices.
References
Abdellaoui, M. (2000). Parameter-free elicitation of utility and probability weighting Functions. Management Science, 46(11), 1497–1512. https://doi.org/10.1287/mnsc.46.11.1497.12080
Alary, D., Gollier, C., & Treich, N. (2013). The effect of ambiguity aversion on insurance and self-protection. The Economic Journal, 123(573), 118–1202. https://doi.org/10.1111/ecoj.12035
Baillon, A. (2017). Prudence with respect to ambiguity. The Economic Journal, 127(604), 1731–1755. https://doi.org/10.1111/ecoj.12358
Baillon, A., & Bleichrodt, H. (2015). Testing ambiguity models through the measurement of probabilities for gains and losses. American Economic Journal: Microeconomics, 7(2), 77–100. https://doi.org/10.1257/mic.20130196
Baillon, A., Bleichrodt, H., Emirmahmutoglu, A., Jaspersen, J.G., & Peter, R. (2020). When risk perception gets in the way: Probability weighting and underprevention. Operations Research. https://doi.org/10.1287/opre.2019.1910
Baillon, A., Capuno, J., O’Donnell, O., Tan, C., & van Wilgenburg, K. (2019). Persistent effects of temporary incentives: Evidence from a nationwide health insurance experiment. Tinbergen Institute Discussion Paper Series, 2019–078/V.
Baillon, A., Schlesinger, H., & van de Kuilen, G. (2018). Measuring higher order ambiguity preferences. Experimental Economics, 21(2), 233–256. https://doi.org/10.1007/s10683-017-9542-3
Bajtelsmit, V., Coats, J. C., & Thistle, P. (2015). The effect of ambiguity on risk management choices: An experimental study. Journal of Risk and Uncertainty, 50(3), 249–280. https://doi.org/10.1007/s11166-015-9218-3
Bernasconi, M. (1994). Nonlinear preference and two-stage lotteries: Theories and evidence. The Economic Journal, 104(422), 54–70. https://doi.org/10.2307/2234674
Biener, C., Landmann, A., & Santana, M. (2019). Contract nonperformance risk and uncertainty in insurance markets. Journal of Public Economics, 175, 65–83. https://doi.org/10.1016/j.jpubeco.2019.05.001
Bleichrodt, H., & van Bruggen, P. (forthcoming). Reflection for higher order risk preferences. Review of Economics and Statistics. https://doi.org/10.1162/rest_a_00980
Bryis, E., & Schlesinger, H. (1990). Risk aversion and the propensities for self-insurance and self-protection. Southern Economic Journal, 57(2), 485–467. https://doi.org/10.2307/1060623
Courbage, C., & Rey, B. (2006). Prudence and optimal prevention for health risks. Health Economics, 15(12), 1323–1327. https://doi.org/10.1002/hec.1138
Deck, C., & Schlesinger, H. (2018). On the robustness of higher order risk preferences. Journal of Risk and Insurance, 85(2), 313–333. https://doi.org/10.1111/jori.12217
Denuit, M. M., Eeckhoudt, L., Liu, L., & Meyer, J. (2016). Tradeoffs for downside risk-averse decision-makers and the self-protection decision. The Geneva Risk and Insurance Review, 41(1), 19–47. https://doi.org/10.1057/grir.2015.3
Dionne, G., & Eeckhoudt, L. (1985). Self-insurance, self-protection and increased risk aversion. Economics Letters, 17(1–2), 39–42. https://doi.org/10.1016/0165-1765(85)90123-5
Doherty, N. A., & Schlesinger, H. (1990). Rational insurance purchasing: Consideration of contract nonperformance. The Quarterly Journal of Economics, 105(1), 243–253. https://doi.org/10.2307/2937829
Eeckhoudt, L., & Gollier, C. (2005). The impact of prudence on optimal prevention. Economic Theory, 26(4), 989–994. https://doi.org/10.1007/s00199-004-0548-7
Eeckhoudt, L., & Schlesinger, H. (2006). Putting risk in its proper place. American Economic Review, 96(1), 280–289. https://doi.org/10.1257/000282806776157777
Ehrlich, I., & Becker, G. (1972). Market insurance, self-insurance, and self-protection. Journal of Political Economy, 80(4), 623–648. https://doi.org/10.1086/259916
Etchart-Vincent, N. (2004). Is probability weighting sensitive to the magnitude of consequences? An experimental investigation on losses. Journal of Risk and Uncertainty, 28(3), 217–235. https://doi.org/10.1023/B:RISK.0000026096.48985.a3
Haering, A., Heinrich, T., & Mayrhofer, T. (2020). Exploring the consistency of higher order risk preferences. International Economic Review, 61(1), 283–320. https://doi.org/10.1111/iere.12424
Herrero, C., Tomás, J., & Villar, A. (2006). Decision theories and probabilistic insurance: An experimental test. Spanish Economic Review, 8(1), 35–52. https://doi.org/10.1007/s10108-005-0102-1
Jang, Y. S., & Hadar, J. (1995). A note on increased probability of loss and the demand for insurance. The Geneva Papers on Risk and Insurance Theory, 20(2), 213–216. https://doi.org/10.1007/BF01258398
Jaspersen, J.G., Ragin, M.A., & Sydnor, J.R. (forthcoming). Predicting insurance demand from risk attitudes. Journal of Risk and Insurance.
Johnson, C. A., Baillon, A., Bleichrodt, H., Li, Z., van Dolder, D., & Wakker, P. P. (2021). Prince: An improved method for measuring incentivized preferences. Journal of Risk and Uncertainty, 62(1), 1–28. https://doi.org/10.1007/s11166-021-09346-9
Jullien, B., Salanié, B., & Salanié, F. (1999). Should more risk-averse agents exert more effort? The Geneva Papers on Risk and Insurance Theory, 24(1), 19–28. https://doi.org/10.1023/A:1008729115022
Kocher, M., Lahno, A., & Trautmann, S. (2018). Ambiguity aversion is not universal. European Economic Review, 101, 268–283. https://doi.org/10.1016/j.euroecorev.2017.09.016
Krieger, M., & Mayrhofer, T. (2017). Prudence and prevention: An economic laboratory experiment. Applied Economics Letters, 24(1), 19–24. https://doi.org/10.1080/13504851.2016.1158909
Kunreuther, H. (1996). Mitigating disaster losses through insurance. Journal of Risk and Uncertainty, 12(2–3), 171–187. https://doi.org/10.1007/BF00055792
Kunreuther, H., & Pauly, M. (2006). Rules rather than discretion: Lessons from Hurricane Katrina. Journal of Risk and Uncertainty, 12(2–3), 101–116. https://doi.org/10.1007/s11166-006-0173-x
Li, H., Neumuller, S., & Rothschild, C. (2020). Optimal annuitization with imperfect information about insolvency risk. Journal of Risk and Insurance. https://doi.org/10.1111/jori.12318
Masuda, T., & Lee, E. (2019). Higher order risk attitudes and prevention under different timings of loss. Experimental Economics, 22(1), 197–215. https://doi.org/10.1007/s10683-018-9588-x
Menegatti, M. (2009). Optimal saving in the presence of two risks. Journal of Economics, 96(3), 277–288. https://doi.org/10.1007/s00712-008-0049-4
Morey, R., & Rouder, J. (2018). Bayesfactor: computation of Bayes factors for commondesigns. (version 0.9.12–4.2) [Computer software] from: CRAN.R-project.org/package=BayesFactor
Pestieau, P., & Ponthière, P. (2012). Long-term care insurance puzzle. In J. Costa-Font & C. Courbage (Eds.), Financing long-term care in Europe (pp. 44–52). Palgrave Macmillan.
Peter, R. (2020). Who should exert more effort? Risk aversion, downside risk aversion and optimal prevention. Economic Theory. https://doi.org/10.1007/s00199-020-01282-0
Peter, R. (2017). Optimal self-protection in two periods: On the role of endogenous saving. Journal of Economic Behavior and Organization, 137, 19–36. https://doi.org/10.1016/j.jebo.2017.01.017
Peter, R., & Toquebeuf, P. (2020). Separating ambiguity and ambiguity attitude with mean-preserving capacities: Theory and applications. Working paper.
Peter, R., & Ying, J. (2020). Do you trust your insurer? Ambiguity about contract nonperformance and optimal insurance demand. Journal of Economic Behavior and Organization. https://doi.org/10.1016/j.jebo.2019.01.002
Slovic, P., Fischhoff, B., Lichtenstein, S., Corrigan, B., & Combs, B. (1977). Preference for insuring against probable small losses: Insurance implications. Journal of Risk and Insurance, 44(2), 237–258. https://doi.org/10.2307/252136
Snow, A. (2011). Ambiguity aversion and the propensities for self-insurance and self-protection. Journal of Risk and Uncertainty, 42(1), 27–43. https://doi.org/10.1007/s11166-010-9112-y
Viscusi, W. K. (1979). Insurance and individual incentives in adaptive contexts. Econometrica, 47(5), 1195–1207. https://doi.org/10.2307/1911958
Viscusi, W. K., & Chesson, H. W. (1999). Hopes and fears: The conflicting effects of risk ambiguity. Theory and Decision, 47, 153–178. https://doi.org/10.1023/A:1005173013606
Wakker, P.P., Thaler, R.H., & Tversky, A. (1997). Probabilistic insurance. Journal of Risk and Uncertainty, 15(1), 7–28. https://doi.org/10.1023/A:1007799303256
Zimmer, A., Gründl, H., Schade, C.D., & Glenzer, F. (2018). An incentive-compatible experiment on probabilistic insurance and implications for an insurer’s solvency level. Journal of Risk and Insurance, 85(1), 245–273. https://doi.org/10.1111/jori.12148
Zimmer, A., Schade, C.D., & Gründl, H. (2009). Is default risk acceptable when purchasing insurance? Experimental evidence for different probability representations, reasons for default, and framings. Journal of Economic Psychology, 30(1), 11–23. https://doi.org/10.1016/j.joep.2008.09.001
Acknowledgements
We thank Aurélien Baillon for his help in designing our study, Alice Havrileck for her assistance in executing the experiment and David Dicks, Richard Peter, Erik Schut, participants of the 46th seminar of the European Group of Risk and Insurance Economists, the 11th lowlands Health Economics Study Group and the Smarter Choices for Better Health symposium and an anonymous referee for their helpful comments on previous versions of this paper. Financial support from Erasmus University Rotterdam through the Research Excellence Initiative 2015 is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised: The wrong Supplementary file was originally published with this article; it has now been replaced with the correct file.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lambregts, T.R., van Bruggen, P. & Bleichrodt, H. Insurance decisions under nonperformance risk and ambiguity. J Risk Uncertain 63, 229–253 (2021). https://doi.org/10.1007/s11166-021-09364-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11166-021-09364-7