
Abstract
Many research questions concern treatment effects on outcomes that can recur several times in the same individual. For example, medical researchers are interested in treatment effects on hospitalizations in heart failure patients and sports injuries in athletes. Competing events, such as death, complicate causal inference in studies of recurrent events because once a competing event occurs, an individual cannot have more recurrent events. Several statistical estimands have been studied in recurrent event settings, with and without competing events. However, the causal interpretations of these estimands, and the conditions that are required to identify these estimands from observed data, have yet to be formalized. Here we use a formal framework for causal inference to formulate several causal estimands in recurrent event settings, with and without competing events. When competing events exist, we clarify when commonly used classical statistical estimands can be interpreted as causal quantities from the causal mediation literature, such as (controlled) direct effects and total effects. Furthermore, we show that recent results on interventionist mediation estimands allow us to define new causal estimands with recurrent and competing events that may be of particular clinical relevance in many subject matter settings. We use causal directed acyclic graphs and single world intervention graphs to illustrate how to reason about identification conditions for the various causal estimands based on subject matter knowledge. Furthermore, using results on counting processes, we show that our causal estimands and their identification conditions, which are articulated in discrete time, converge to classical continuous time counterparts in the limit of fine discretizations of time. We propose estimators and establish their consistency for the various identifying functionals. Finally, we use the proposed estimators to compute the effect of blood pressure lowering treatment on the recurrence of acute kidney injury using data from the Systolic Blood Pressure Intervention Trial.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Practitioners and researchers are often interested in treatment effects on outcomes that can recur in the same individual over time. Such outcomes include hospitalizations in heart failure patients (Anker and McMurray 2012), fractures in breast cancer patients with skeletal metastases (Chen and Cook 2004) and rejection episodes in recipients of kidney transplants (Cook and Lawless 1997). However, in many studies of recurrent events, individuals may also experience competing events, such as death. These events may substantially complicate causal inference.
For example, in the Systolic Blood Pressure Intervention Trial (SPRINT Research Group 2015), investigators found that intensive blood pressure lowering therapy increased the expected number of acute kidney injury episodes (a possible harmful side effect of blood pressure treatment) compared to standard blood pressure treatment. However, individuals on intensive blood pressure therapy had a lower incidence of all-cause mortality.
In this example, all-cause mortality is a competing event for the outcome of interest (number of recurrences of acute kidney injury) because once an individual dies they cannot subsequently experience the recurrent event.Footnote 1 Due to the randomized design these findings indeed have a “causal” interpretation: the results support an average harmful effect of intensive blood pressure treatment on the number of acute kidney injury recurrences. However, analogous to previous arguments in the case where the outcome of interest is an incident (rather than a recurrent) event subject to competing events (Young et al. 2020; Stensrud et al. 2020), this “protection” is difficult to interpret in light of the finding that mortality risk is lowered by intensive blood pressure treatment. The increased number of acute kidney injury episodes in the intensive treatment arm might only be due to the treatment effect on mortality.
Early works on competing events (Tsiatis 1975; Gail 1975; Prentice et al. 1978) considered the problem of identifying the survival function of the event of interest under elimination of competing events, and concluded that this is often unfeasible as it requires strong independence assumptions between the competing events, as well as a clear conceptualization of how to eliminate a competing event without affecting the risk of the other events. Instead, Prentice et al. (1978) advocated for the cause-specific hazard as an identifiable estimand in the competing event setting. Although these early works are clearly based on an insightful intuition, they are not grounded in a formal framework for characterizing causal effects and their identifying conditions, which makes it difficult to interpret the effect estimates from these procedures and to assess recommendations regarding analytic choices. For example, it has been clarified that cause-specific hazards do not have a desirable causal effect interpretation (Robins 1986; Young et al. 2020; Aalen et al. 2015; Martinussen et al. 2020; Hernán 2010; Stensrud and Hernán 2020; Stensrud et al. 2022).
The importance of characterizing the causal interpretation of statistical estimands is increasingly acknowledged both within and outside of the academic causal inference community (European Medicines Agency 2020). In a series of articles by the Recurrent Event Qualification Opinion Consortium (Schmidli et al. 2021; Wei et al. 2021; Fritsch et al. 2021), six candidate causal estimands were proposed in recurrent event settings with competing events, defined by counterfactual contrasts under different treatment scenarios in the following: (1) the expected number of events in the study population; (2) the expectation over a composite of the recurrent and competing events in the study population; (3) the expected number of events under an intervention which prevents the competing event from occurring in the study population; (4) the expected number of events in a subset of the study population consisting of the principal stratum of individuals that would survive regardless of treatment; (5) the ratio of the expected number of recurrences to the restricted mean survival by the end of follow-up in the study population and (6) the ratio of the expectation over a composite of the recurrent and competing events to the restricted mean survival by the end of follow-up in the study population.
In addition to defining these various counterfactual estimands, Schmidli et al. (2021) considered some aspects of their differences in interpretation, as well as, for some of the estimands, approaches to statistical analysis. However, they did not consider assumptions needed to identify any of these counterfactual estimands in a given study with a function of the observed data. Once a causal estimand is chosen, this identification step is required to justify a choice of approach to statistical analysis. Furthermore, Schmidli et al. (2021) did not consider how underlying questions about treatment mechanism may be important to the choice of estimand in recurrent events studies when treatment has a causal effect on competing events, as illustrated in the example above.
In this work, we formalize the interpretation, identification and estimation of various counterfactual estimands in recurrent event settings with competing events using counterfactual causal models (Robins 1986; Pearl 2009; Richardson and Robins 2013b; Robins and Richardson 2011; Robins et al. 2020). Building on ideas in Young et al. (2020) and Stensrud et al. (2020) for the case where the outcome of interest is an incident event (e.g. diagnosis of prostate cancer), we show that several of these estimands in recurrent event settings can be interpreted as special cases of causal effects from the mediation literature—total, controlled direct, and separable effects—by conceptualizing the competing event as a time-varying “mediator” (Robins and Greenland 1992; Robins and Richardson 2011; Robins et al. 2020). We give identification conditions and derive identification formulas for these estimands and demonstrate how single world intervention graphs (SWIGs) (Richardson and Robins 2013b) can be used to reason about identification conditions with subject matter knowledge. Our results will also formalize the counterfactual interpretation of statistical estimands for recurrent events from the counting process literature (Cook and Lawless 2007; Andersen et al. 2019), which has not adopted a formal causal (counterfactual) framework for motivating results.
The article is organized as follows. In Sect. 2, we present the structure of the observed data, without the complication of loss to follow-up. In Sect. 3, we define and describe several causal estimands for recurrent events in settings with competing events. In Sect. 4 we give our own prescription for choosing an appropriate causal estimand for recurrent outcomes. In Sect. 5, we consider how to treat the censoring of events, including by loss to follow-up. In Sect. 6 we discuss identifiability conditions and give identification formulas for the proposed causal estimands. Furthermore, we demonstrate the convergence of discrete time estimands to continuous time estimands, and establish the correspondence between the discrete time identification conditions and the classical independent censoring assumption in event history analysis.Footnote 2 In Sect. 7, we describe statistical methods for the proposed estimands, and establish conditions for their consistency. In Sect. 8, we illustrate our results using a data example on acute kidney injury under blood pressure treatment. Finally, in Sect. 9, we provide a discussion.
2 Factual data structure
Consider a randomized trial, like SPRINT, where \(i\in \{1,\dots ,n\}\) i.i.d. individuals with elevated risk of cardiovascular disease were randomized to intensive versus standard blood pressure lowering therapy \(A\in \{0,1\}\) (0 indicates assignment to standard treatment, 1 assignment to intensive treatment). Because the individuals are i.i.d., we suppress the subscript i. Let \(k\in \{0,\dots ,K+1\}\) denote \(K+2\) consecutive ordered intervals of time comprising the follow-up (e.g. days, weeks, months) with time interval \(k=0\) corresponding to the interval of treatment assignment (baseline) and \(k=K+1\) corresponding to the last possible follow-up interval, beyond which no information has been recorded. Without loss of generality, we choose a timescale such that all intervals have a duration of 1 unit of time until Sect. 6.4.
Let \(Y_k\in \{0,1,2,\dots \}\) denote the cumulative count of acute kidney injury episodes by the end of interval k and \(D_k\in \{0,1\}\) an indicator of death by the end of interval k. Define \(D_0\equiv Y_0\equiv 0\), that is, individuals are alive and have not yet experienced any post-treatment recurrent events at baseline. Let \(L_0\) be a vector of baseline covariates measured before the treatment assignment A, capturing pre-treatment common causes of acute kidney injury and death. For \(k>0\), let \(L_k\in {\mathcal {L}}\) denote a vector of time-varying covariates measured in interval k, containing the most recent blood pressure measurements.Footnote 3
The history of a random variable through k is denoted by an overbar (i.e. \(\overline{Y}_{k} \equiv (Y_0,\dots ,Y_k)\) and \(\overline{L}_{k} \equiv (L_0,\dots ,L_k)\)) and future events are denoted by underbars (i.e. \(\underline{D}_{k} \equiv (D_k,\dots ,D_{K+1})\)).
We assume no loss to follow-up until Sect. 5, and we assume that variables are temporally (and topologicallyFootnote 4) ordered as \(D_k, Y_k,L_k\) within each follow-up interval. We adopt the notational convention that any variable with a negative time index occurring in a conditioning set is taken to be the empty set \(\emptyset \) (e.g. \(P(A=a|L_{-1},B) = P(A=a|B)\) for an event B).
An individual cannot experience recurrent events after a competing event, such as death, has occurred: if an individual experiences death at time \(k^\dagger \), then \(Y_{j}=Y_{k^\dagger -1}\) and \(D_{j}=1\) for all \(j \ge k^\dagger \). Thus, the type of outcome that is the focus of this manuscript is defined in the factual data after death occurs. This is in contrast to what we will refer to as a ’truncation by death’ setting, where the outcome of interest is undefined after an individual experiences the competing event (Young et al. 2020; Young and Stensrud 2021; Stensrud et al. 2021b, 2022). For example, when the outcome of interest is quality of life in cancer patients, this is only defined for individuals who are alive unless the investigator chooses to assign an arbitrary quality of life value to dead individuals. Ultimately, the true distinction between a “competing event” setting (where outcomes are defined as absent post-death) and a “truncation by death” setting comes down to the estimands that the investigator is willing to consider. When the outcome is undefined after death then certain estimands will not be available that are available when such outcomes are defined (Young and Stensrud 2021). We consider this further in Sect. 3.
In what follows, we will use causal directed acyclic graphs (Pearl 2009) (DAGs) to represent underlying data generating models. We assume that the DAG represents a Finest Fully Randomized Causally Interpreted Structural Tree Graph (FFRCISTG) model (Robins 1986; Richardson and Robins 2013b). Furthermore, we will assume that statistical independencies in the data are faithful to the DAG (see Appendix D for the definition of faithfulness that we adopt here). An example of a DAG, encoding a set of possible assumptions on the data generating model for the trial in the data example described in Sect. 1 is shown in Fig. 1.

An example of a possible causal model describing the Systolic Blood Pressure Intervention Trial (SPRINT Research Group 2015), where individuals are randomized to intensive versus standard blood pressure therapy. The trial outcomes are recurrent episodes of acute kidney injury (\(Y_k\)) and survival (\(D_k\))
3 Counterfactual estimands
In this section, we consider various counterfactual estimands in settings with recurrent and competing events. We propose extensions of previously considered counterfactual estimands that quantify causal effects on incident failure in the face of competing events (Stensrud et al. 2020; Young et al. 2020; Stensrud et al. 2021a) to the recurrent events setting. This includes a new type of separable effect, inspired by the seminal decomposition idea of Robins and Richardson (2011), that may disentangle the treatment effect on recurrent acute kidney injury from its effect on survival. We also discuss additional counterfactual estimands in recurrent event settings.
We denote counterfactual random variables by superscripts, such that \(Y^{a}_k\) is the recurrent event count that would be observed at time k had, possibly contrary to fact, treatment been set to \(A=a\). By causal effect, we mean a contrast of some functional (e.g. the mean) of the counterfactual distribution in the same subset of individuals.
3.1 Total effect
The counterfactual marginal mean number of recurrent events by time k under an intervention that sets A to a is
In turn, the counterfactual contrast
quantifies a causal effect of treatment assignment on the mean number of recurrent events by k. Schmidli et al. (2021) referred to this effect as the ’treatment policy’ estimand. However, in order to understand the interpretational implications of choosing this effect measure when competing events exist, it is important to understand that (1) also coincides with an example of a total effect as historically defined in the causal mediation literature (Robins and Greenland 1992; Young et al. 2020).
In our running example, the total effect quantifies the effect of intensive versus standard blood pressure treatment (A) on recurrent acute kidney injury (\(Y_k\)) through all causal pathways, including pathways through survival (\(D_k\)), as depicted by all directed paths connecting A and Y nodes intersected by D nodes in the causal diagram in Fig. 1 (Young et al. 2020). Therefore, a non-null value of the total effect is not sufficient to conclude that the treatment exerts direct effects on acute kidney injury (outside of death): the total effect may also (or only) be due to an (indirect) effect on survival, keeping individuals at risk of acute kidney injury for a longer (or shorter) period of time.
In addition to the total effect on recurrent acute kidney injury (\(Y_k\)), we might consider the total (marginal) effect of treatment on survival, given by the marginal contrast in cumulative incidences
However, simultaneously considering the total effect of treatment on acute kidney injury and on survival is still insufficient to determine by which mechanisms the treatment affects acute kidney injury and death. For example, suppose that individuals in treatment arm \(A=1\) experience the competing event shortly after treatment initiation. In this case, no recurrent events would be recorded in this treatment arm. Clearly, in this setting it would not be possible for an investigator to draw any conclusions about the mechanism by which treatment acts on the recurrent event outside of the competing event.
3.2 Controlled direct effect
Following Robins and Greenland (1992), consider the counterfactual mean number of events under an intervention that prevents the competing event from occurring and sets treatment to \(A=a\),
where the overline in the superscript denotes an intervention on all respective intervention nodes in the history of the counterfactual, i.e. \(Y_k^{a,\overline{d}=0} \equiv Y_k^{a,\overline{d}_{k}=0}\).
In turn, the counterfactual contrast
quantifies a causal effect of treatment assignment on the mean number of recurrent events by k under an additional intervention that somehow “eliminates competing events”. Schmidli et al. (2021) referred to this effect as the ’hypothetical strategy’ estimand. However, it is useful to notice that the effect (3) coincides with an example of a controlled direct effect as defined in the causal mediation literature (Robins and Greenland 1992; Young et al. 2020). The quantity \(E[Y^{a,\overline{d}=0}_k]\) is closely related to the survival function under the elimination of competing events, as discussed in the early competing events literature by e.g. Tsiatis (1975); Prentice et al. (1978); Putter et al. (2007), although without using a formal causal framework.
In our example, the controlled direct effect isolates direct effects of treatment on recurrent acute kidney injury by considering a (hypothetical) intervention which prevents death from occurring in all individuals. An important reservation against the controlled direct effect is that it is often difficult to conceptualize an intervention which prevents the competing event from occurring (Young et al. 2020). For example, there exists no practically feasible intervention that can eliminate death due to all causes. Without clearly establishing the intervention being targeted, the interpretation of the direct effect is ambiguous and its role in informing decision-making is unclear. The unclear role of the controlled direct effect in decision-making was reiterated by Schmidli et al. (2021) in their discussion of the ’hypothetical strategy’, although the authors did not discuss the role of the estimand in clarifying the mechanism by which treatment affects the outcome.
3.3 Separable effects
Following Robins and Richardson (2011) Robins et al. (2020) and Stensrud et al. (2020, 2022), we will define an actionable notion of direct (indirect) effects that refers to an intervention that might be implemented currently or in the future. These effects require that the investigator pose candidates for modified versions of the study treatment, denoted \(A_Y\) and \(A_D\), with the following properties: let \(M_Y\) and \(M_D\) be two random variables, and suppose that the following conditions hold for the original treatment A and the modified treatments \(A_Y,A_D\):
"Intersection" refers to the paths in the respective causal DAG. Assumption (4) is referred to as the modified treatment assumption and is discussed in Stensrud et al. (2022). According to (4), receiving \(A_Y=A_D=a\) results in the same outcomes as receiving \(A=a\) for \(a\in \{0,1\}\). While a physical treatment decomposition is one way in which assumption (4) may hold, it may also hold for modified treatments that are not a physical decomposition (Stensrud et al. 2021a, 2022). The modified treatment assumption (4) can in principle be falsified in a future six-armed trial where individuals are exposed to \(A,A_Y,A_D\in \{0,1\}\) once the modified treatment becomes available (Stensrud et al. 2022).
In the case of a decomposition, an individual receiving \(A_Y=A_D=0\) has received the same treatment as \(A=0\) (assignment to neither of the treatment components) and an individual receiving \(A_Y=A_D=1\) the same treatment as \(A=1\) (assignment to both treatment components). The marginal mean number of events under a hypothetical intervention where we jointly assign \(A_Y=a_Y\) and \(A_D=a_D\) for any combination of \(a_D\in \{0,1\}\) and \(a_Y\in \{0,1\}\), possibly such that \(a_Y\ne a_D\) is
Contrasts of this estimand for different levels of \(A_Y\) and \(A_D\) constitute particular examples of separable effects (Stensrud et al. 2020, 2021a), a type of interventionist mediation estimand (Robins and Richardson 2011; Robins et al. 2020; Didelez 2019). For example, the separable effect of \(A_Y\) evaluated at \(A_D=0\) is
Expression (5) quantifies the effect of only treating with the \(A_Y\) component versus neither of the components.
These estimands correspond to the effects of joint interventions on candidate modified treatments \(A_Y\) and \(A_D\), even when the modified treatment assumption (4) does not hold. However, the modified treatment assumption (4) is sufficient in order for the separable effects to explain the mechanism by which the original treatment A exerts its effects on the recurrent outcome (Stensrud et al. 2021a, Appendix A).
Returning to the data example, a well-known biological effect of angiotensin converting enzyme inhibitors (ACE) and angiotensin II receptor blockers (ARB) (two common antihypertensive medications) is that they reduce the renal filtration pressure by binding to receptors in the kidneys which dilate efferent glomerular arterioles, which in turn can lead to a substatial drug-induced fall in kidney function (Brunton et al. 2018). In light of this, drug developers and doctors could be interested in the effect of a hypothetical modified version of an antihypertensive drug, which preserves its effects on systemic blood pressure but does not lead to dilation of efferent glomerular arterioles. In principle, such a modified drug might have similar cardioprotective effects as the original antihypertensive agent, but without the harmful side-effect that can lead to acute kidney injury.
This working background knowledge on the mechanisms by which the study treatment affects recurrent acute kidney injury and competing events allows us to pose candidates for \(A_Y\) and \(A_D\) in this example and, as we will discuss further below, interpret separable effects in terms of direct, indirect, or path-specific effects of A. Specifically, the modified treatment assumption is conceivable in this example by defining \(A_Y\) to be the component of blood pressure therapy that binds to efferent arterioles in the kidneys, causing their dilatation (\(M_Y\)), and \(A_D\) as the remaining components of the treatment, including those that exert their effects by lowering systemic blood pressure (\(M_D\)). Thus, \(A_Y\) and \(A_D\) are the treatment levels of these two components under intensive versus standard therapy respectively. A further discussion of this decomposition of blood pressure therapy into the aforementioned \(A_Y\) and \(A_D\) components is given in Stensrud et al. (2021a).
Additional assumptions or isolation conditions (Stensrud et al. 2021a), are then required in order to interpret any given separable effect as a direct, indirect, or otherwise path-specific effect of the original study treatment: if the \(A_Y\) component has no effect on survival, then \(E[Y_k^{a_Y=1,a_D}] \ \text {vs.}\ E[Y_k^{a_Y=0,a_D}]\) captures exclusively the effect of the \(A_Y\) component on acute kidney injury not mediated by survival. We can formalize this statement using the condition of strong \(A_Y\) partial isolation, inspired by Stensrud et al. (2021a):
A treatment decomposition satisfies strong \(A_Y\) partial isolation if
Under strong \(A_Y\) partial isolation, (5) captures only treatment effects on the recurrent event not via treatment effects on competing events, and is therefore a direct effect. In our example on blood pressure treatment, strong \(A_Y\) partial isolation likely fails, as acute kidney injury may in and of itself increase the risk of death, and therefore effects through the path \(A_Y\rightarrow Y_j \rightarrow D_{k>j}\) cannot be ruled out.
Consequently, (5) also captures effects of \(A_Y\) on \(Y_k\) via \(\overline{D}_k\), and therefore cannot be interpreted as a direct effect outside of \(\overline{D}_k\).
Another isolation condition, \(A_D\) partial isolation, allows us to interpret separable effects as indirect effects of treatment on the recurrent outcome via effects on survival. A brief account of the isolation conditions is given in Appendix B, and is discussed in detail for the competing events setting in Stensrud et al. (2021a). If we had access to a four arm randomized trial where individuals are observed under all four treatment combinations \((A_Y,A_D)\in \{0,1\}^2\), and there is no loss to follow-up, these effects could easily be identified and estimated by two-way comparisons of the four different treatment combinations. Such two-way comparisons would also allow the strong \(A_Y\) partial isolation condition (6) to be tested: in particular, a non-null value of the two-way comparison \(E[D_k^{a_Y=1,a_D}]\) vs. \(E[D_k^{a_Y=0,a_D}]\) implies a violation of (6). Conversely, inspection of the contrast \(E[Y_k^{a_Y,a_D=1}]\) vs. \(E[Y_k^{a_Y,a_D=0}]\) can strengthen or weaken our belief in the \(A_D\) partial isolation condition, although cannot be used to falsify the assumption. Because we only observe two of the four treatment combinations in the trial described in Sect. 2, namely \(A_Y=A_D=1\) and \(A_Y=A_D=0\), the separable effects target effects that require identifying assumptions beyond those that hold by design in this two arm trial. We will consider these assumptions in Sect. 6.3.
3.4 Estimands with composite outcomes
Schmidli et al. (2021) proposed the estimands
where \(\mu _k^{a}=\sum _{i=0}^k I(D_i^{a}=0)\) is the counterfactual restricted survival under an intervention that sets treatment to a.Footnote 5 Expressions (7)–(8) differ subtly: (8) is the mean of a ratio and implicitly reflects the association between recurrent and competing events, whereas any information about this association is erased by (7), which is a ratio of means. Schmidli et al. (2021) referred to (7) as the ‘while alive strategy’ estimand. A contrast in (7)–(8) under different levels of a captures both treatment effects on acute kidney injury and on the competing event.
Different types of composite outcomes have also been suggested. For example, Schmidli et al. (2021) described the estimand
which could also be extended by multiplying \(D_k^{a}\) or \(Y_k^{a}\) by a weight. Likewise, Claggett et al. (2018) introduced a reverse counting process, which can be formulated as
for recurrent outcomes. The estimand is the expectation over a counting process which starts at M and decrements in steps of one every time the recurrent event occurs. If the terminating event occurs, the process drops to zero.
There are common limitations to all estimands in this subsection:
-
(I)
Neither can be used to draw formal conclusions about the mechanism by which the treatment affects the recurrent event and the event of interest for the same reason as the total effect (Sect. 3.1).
-
(II)
The estimands (implicitly or explicitly) assign weight to the competing and recurrent events by combining them into a single effect measure. However, the choice of ’weights’ is not obvious and can differ on a case-by-case basis.
-
(III)
The estimands represent a coarsening of the information in the cumulative incidence and mean frequency, and therefore provide less information than simultaneously inspecting the mean frequency of acute kidney injury and the cumulative incidence of death. Inspecting the mean frequency and cumulative incidence curves separately gives the additional advantage of showing the (absolute) magnitude of each estimand separately as functions of time, which is not visible from the composite estimand alone.
Points (I)–(III) also apply to composite estimands in settings with truncation by death.
3.5 Estimands that condition on the event history
The counterfactual intensity of the recurrent event process is defined as
Expression (9) is a discrete time intensity of \(Y_k^a\), conditional on the past history of recurrent events and measured covariates. One could then consider contrasts such as
However, because (9) conditions on the history of the recurrent event process up to time k, (10) generally cannot be interpreted as a causal effect, even though it is a contrast of counterfactual outcomes. This is because it compares different groups of individuals—those with a particular recurrent event and covariate process history under \(a=1\) versus those with that same history under \(a=0\). Thus, a nonnull value of (10) does not imply that A has a nonnull causal effect on Y at time k. This is analogous to the difficulty in causally interpreting contrasts of hazards for survival outcomes, and has already been discussed extensively in the literature (Robins 1986; Young et al. 2020; Martinussen et al. 2020; Hernán 2010; Stensrud and Hernán 2020; Stensrud et al. 2022).
An alternative estimand is the expanded notion of separable effects called conditional separable effects (Stensrud et al. 2022), where consideration of causal effects is restricted to a particular subset of “survivors” (Stensrud et al. 2022). When strong \(A_Y\) partial isolation holds, the conditional separable effect evaluated at \(A_D=a_D\) is defined as the contrast
Unlike (10), the conditional separable effect can be interpreted as a contrast of counterfactual outcomes in the same subset of individuals. Like the marginal separable effects discussed in Sect. 3.3, the conditional separable effects rely on assumptions that are testable in a future randomized trial (Stensrud et al. 2022). However, the conditional separable effects require the assumption of strong \(A_Y\) partial isolation in order to be well-defined, which is not required by the marginal separable effects. The conditional separable effects can be used even if the investigator considers the outcome of interest to be ill-defined after the competing event.
3.6 Principal stratum estimand
Schmidli et al. (2021) also considered the principal stratum estimand
which is closely related to the conditional separable effect. Contrasts of (11), given by
correspond to principal stratum effects, e.g. the survivor average causal effect (Robins 1986; Frangakis and Rubin 2002; Schmidli et al. 2021). Identification of (11) was also considered by Xu et al. (2022) in the semi-competing events setting. The principal stratum estimand targets an unknown subset of the population (Robins 1986; Robins et al. 2007; Joffe 2011; Dawid and Didelez 2012; Stensrud et al. 2020; Stensrud and Dukes 2022). In cases where this subset is small, or non-existent, the principal stratum effects may play an unclear role in decision-making. Integrally linked to the unknown nature of the population to whom a principal stratum effect refers, this estimand depends on cross-world independence assumptions for identification that can not be falsified in any real-world experiment, in contrast to the (conditional) separable effects.
3.7 Natural direct effect
The natural (pure) direct effects, originally described by Robins and Greenland (1992) and later reconsidered by Pearl (2001), give another way of defining treatment effects on the recurrent outcome which do not capture the effect on the competing event. One way of doing so is through the contrast
Like the controlled direct effect, the natural direct effect also requires the conceptualization of an intervention on the competing event.
Recent work has also considered identification of path specific effects which capture direct and indirect effects through longitudinal mediators (Vansteelandt et al. 2019; Mittinty and Vansteelandt 2020) as well as natural effects formulated using random interventions on longitudinal mediators (Zheng and van der Laan 2017).
4 Choosing an estimand
The choice of estimand for a particular problem must be motivated by subject matter arguments. When there is no subject matter support for a causal effect of the treatment on the competing event (i.e. there are no directed arrows from A into \(D_k\) at any k) or when this mechanism does not create ambiguities with regard to mechanisms of the treatment then the total effect may be enough.
However, if treatment effects on the competing event could create mechanisms that lead to an ambiguous interpretation of the total effect, then other estimands may help supplement information quantified by the total effect. Unlike other proposals for effects to quantify treatment mechanism outlined above, strong assumptions are required to even define the separable effects, putting aside even the issue of identifying them in the study data in hand, and to ascribe them a particular mechanistic interpretation. Unfortunately, the alternative estimands provided do not avoid such assumptions but rather bury them: for example, an estimate obtained from a real-world study of a controlled direct effect defined relative to an ill-defined intervention on death, or a natural effect defined relative to setting death to a cross-world unobservable value, can never be refuted in the future without additional assumptions on par with the modified treatment assumption/isolation conditions required to understand a separable effect. The required transparency for proceeding with a separable effects analysis can, and in our view should, be viewed as a benefit of this approach: it shines needed light on the reality that using real-world data to answer mechanistic questions is hard and requires detailed assumptions about how the study treatment works. When an investigator is lacking that knowledge, the solution should not be to revert to untestable questions but to acknowledge the need for more time and thought to sharpen hypotheses. In such cases, one may proceed with a total effect, acknowledging its mechanism is not yet understood. Alternatively, one may proceed with considering separable effects for yet to be elucidated candidates \(A_Y\) and \(A_D\). Such an approach is arguably no more vague than previous (in)direct effect notions but, unlike those former notions, has a hope of being sharpened as more knowledge develops.
Finally, the identifying functions for separable effects coincides with those for certain path specific effects in certain settings, including those where full isolation holds. Thus, numerous advancements in statistics for path specific effects, such as natural effects, can still be leveraged for estimation of separable effects (see for example Zheng and van der Laan 2017; Vansteelandt et al. 2019).
5 Censoring
Define \(C_{k+1}\), \(k\in \{0,\dots ,K\}\) as an indicator of loss to follow-up by \(k+1\) such that, for an individual with \(C_k=0, C_{k+1}=1\), the outcome (and covariate) processes defined in Sect. 2 are only fully observed through interval k. Loss to follow-up (e.g. due to failure to return for study visits) is commonly understood as a form of censoring. We adopt a more general definition of censoring from Young et al. (2020) which captures loss to follow-up but also possibly other events, depending on the choice of estimand.
Definition 1
A censoring event is any event occurring in the study by \(k+1\), for any \(k\in \{0,\dots ,K\}\), that ensures the values of all future counterfactual outcomes of interest under a are unknown even for an individual receiving the intervention a.
Loss to follow-up by time k is always a form of censoring by the above definition. However, other events may or may not be defined as censoring events depending on the choice of causal estimand. For example, competing events are censoring events by the above definition when the controlled direct effect is of interest, but are not censoring events when the total effect is of interest (Young et al. 2020). This is because the occurrence of a competing event at time \(k^\dagger \) prevents knowledge of \(\underline{Y}^{a,\overline{d}=0}_{k^\dagger }\), but does not prevent knowledge of \(\underline{Y}^a_{k^\dagger }\). By similar arguments, competing events are not censoring events when separable effects are of interest because they do not involve counterfactual outcomes indexed by \(\overline{d}=0\) ("elimination of competing events"). When loss to follow-up is present in a study, we will define all effects relative to interventions that include “eliminating loss to follow-up” with the added superscript \(\overline{c}=0\) to denote relevant counterfactual outcomes, e.g. \(Y_k^{\overline{c}=0}\). For example, if loss to follow-up is due to the administrative end of a study, the intervention that eliminates loss to follow-up could be conceived as the hypothetical continuation of the study such that every individual is followed until the end of interval \(K+1\). Contrasts of such effects are examples of controlled direct effects with respect to interventions on loss to follow-up. The identification assumptions outlined below are sufficient for identifying estimands with this additional interpretation. Young et al. (2020) discuss additional assumptions that would allow an interpretation without this additional intervention on loss to follow-up. In Sect. 6.4, we establish the correspondence between the notion of censoring adopted in this article and the classical independent censoring assumption in event history analysis.
6 Identification of the causal estimands
In this section, we give sufficient conditions for identifying the total, controlled direct and the separable effects as functionals of the observed data. Proofs can be found in Appendix C. Identification of estimands in Sects. 3.5–3.7 is beyond the scope of this work.
6.1 Total effect
Consider the following conditions for \(k\in \{0,\dots ,K\}\):
Exchangeability


Assumption (12) states that the baseline treatment is unconfounded given \(L_0\). This holds by design with \(L_0=\emptyset \) when treatment assignment A is (unconditionally) randomized, such as in the blood pressure trial considered in our running example. Assumption (13) states that the censoring is unconfounded. As we will discuss in Sect. 6.4, this assumption is closely related to the independent censoring assumption in survival analysis.
Positivity
Assumption (14) states that for every level of the baseline covariates, there are some individuals that receive either treatment. Once again, this will hold by design in a trial where A is assigned by randomization, such as in the data example. The second assumption requires that, for any possible observed level of treatment and covariate history amongst those remaining alive and uncensored through k, some individuals continue to remain uncensored through \(k+1\) with positive probability.
Consistency
Let \(\Delta X_k=X_{k}-X_{k-1}\) denote an increment of the process X. In Appendix C we show that, under assumptions (12)–(16),
for intervals \(i\in \{0,\dots ,K+1\}\). Expression (17) is an example of a g-formula (Robins 1986). Another equivalent formulation is
where
Expression (18) is an example of an inverse probability weighted (IPW) identification formula (Robins and Rotnitzky 1992; Rotnitzky and Robins 1995; Hernán et al. 2000). In turn, the total effect defined in (1) under an additional intervention that “eliminates loss to follow-up” can be expressed as contrasts of
for different levels of a with \(E[\Delta Y_i^{a,\overline{c}=0}]\) identified by (17) or (18). In the survival setting, with support \(Y_k\in \{0,1\}\), (17) corresponds to Expression (30) in Young et al. (2020). A key difference from the survival setting is that the conditional probability of new recurrent events now depends on the history of the recurrent event process, which may take many possible levels, whereas in the survival setting considered by Young et al. (2020), the terms of the relevant g-formula are restricted to those with fixed event history consistent with no failure (\(\overline{Y}_k=0\)). The identification formula for the total effect on the competing event (2) is shown in Appendix C.
6.1.1 Graphical evaluation of the exchangeability conditions

Identification of total effect. Unmeasured variables are denoted by \(U_\bullet \). a shows unmeasured confounders (common causes of treatment, loss to follow-up, and outcomes), which violate the exchangeability conditions (12)–(13) through the red paths: \(U_{AY}\) violates (12) and \(U_{CY}\) violates (13). b shows examples of unmeasured effect modifiers, which are common in practice (arrows from \(U_{DY}\) to \(Y_k^{a,\overline{c}=0}\) and \( D_k^{a,\overline{c}=0}\) are not shown to reduce clutter). In the data example, common causes of D and Y could for example be the previous history of cardiovascular disease and blood pressure history. The action of such unmeasured effect modifiers, shown by blue paths, does not violate any of the exchangeability conditions (12)–(13)
In Fig. 2 we show a single world intervention graph (SWIG) for the intervention considered under the total effect. This is a transformation (Richardson and Robins 2013b, a) of the causal DAG in Fig. 1, which also includes unmeasured variables illustrating sufficient data generating models under which exchangeability conditions (12)–(13) would be violated. In particular, (12)–(13) can be violated by the presence of unmeasured confounders (common causes of treatment, loss to follow-up, and outcomes) such as \(U_{AY}\) or \(U_{CY}\) in Fig. 2a. This is well-known from before, and demonstrates how SWIGs can be used to reason about the identification conditions.
However, (12)–(13) are not violated by unmeasured common causes of the outcomes \(Y_k\) and \(D_k\) such as \(U_Y, U_{DY}\) and \(U_{D}\) in Fig. 2b, which we often expect to be present in practice. Examples of common causes of recurrent events and death in the data example include prognostic factors related to disease progression such as previous cardiovascular disease history and blood pressure history, many of which are measured in the observed data. In contrast, the controlled direct effect and separable effects are not identified in the presence of open backdoor paths between recurrent events and death, as we will see next.
6.2 Controlled direct effects
The identification of the (controlled) direct effect (3) proceeds analogously to the total effect, with the main difference being that we also intervene to remove the occurrence of the competing event. This amounts to re-defining the censoring event as a composite of loss to follow-up and the competing event. The identification conditions then take the following form for \(k\in \{1,\dots ,K\}\):
Exchangeability


Positivity
We also assume the positivity assumption (14), and a modified version of the consistency assumption in (16) which requires us to conceptualize an intervention on the competing event (see Appendix C for further details).
Under assumptions (20)–(21), an identification formula is given by
or equivalently by the IPW formula
where we have defined
For survival outcomes (\(Y_k\in \{0,1\}\)), (22) reduces to Expression (23) in Young et al. (2020). In the absence of death and loss to follow-up and for randomized treatment assignment, both the total effect (18) and controlled direct effect (23) reduce to \(E[\Delta Y_i\mid A=a]\).
6.2.1 Graphical evaluation of the exchangeability conditions
Examples of unmeasured variables which violate the exchangeability conditions (19)–(20) are shown in Fig. 3. Importantly, (20) is violated by open backdoor paths between D and Y, such as the path \(D_{k+1}^{a,\overline{c}=0,\overline{d}=0}\leftarrow U_{DY} \rightarrow Y_{k+1}^{a,\overline{c}=0,\overline{d}=0}\) through the unmeasured common cause \(U_{DY}\). Therefore, the exchangeability assumption for the controlled direct effect (20) is stronger than the exchangeability assumption for the total effect (13). In the data example, we have measured several important common causes of acute kidney injury and death, as we will see in Sect. 8.

6.3 Separable effects
We begin by assuming the following three identification conditions.
Exchangeability


Expressions (24)–(25) imply the exchangeability conditions for total effect (12)–(13) due to the decomposition rule of conditional independence.
Positivity
for all \(a\in \{0,1\}\), \(k\in \{0,\dots ,K\}\) and \(L_k\in {\mathcal {L}}\). We also assume the positivity and consistency assumptions (14)–(15) and (16). Expression (26) requires that for any possibly observed level of measured time-varying covariate history amongst those who remain uncensored through each follow-up time, there are individuals with \(A=0\) and \(A=1\).
Consider a setting where the \(A_Y\) and \(A_D\) components are assigned independently one at a time. We require the following dismissible component conditions to hold for all \(k\in \{0,\dots ,K\}\):




where we have supposed that \(L_k=(L_{Y,k},L_{D,k})\) consists of components \(L_{Y,k}\) and \(L_{D,k}\) satisfying (29)–(30) respectively. Assumptions (27)–(30) express independencies between quantities that are observable in a future four armed trial without loss to follow-up, and can therefore be tested in such a trial. These conditions require that \(\overline{L}_{D,k}\) captures all effects of \(A_D\) on \(\underline{Y}^{\overline{c}=0}_{k+1}\), whereas \(\overline{L}_{Y,k}\) captures all effects of \(A_Y\) on \(\underline{D}_{k+1}^{\overline{c}=0}\). In the example on acute kidney injury discussed in Sect. 8, we suppose that (27)–(30) hold with a set of baseline covariates \(L_0\), \(L_{Y,k}=\emptyset \) and \(L_{D,k}\) given by the latest blood pressure measurement by time k, which influences the cardiac risk and also the perfusion of the kidneys. The implications and plausibility of this assumption in the context of the data example are discussed in Sect. 7.4. Furthermore, Stensrud et al. (2021a) describes a sensitivity analysis strategy for the dismissible component conditions.
Under the identification conditions for separable effects and the modified treatment assumption (4), we have
Expression (31) can also be written on IPW weighted form as
or
Here, we have defined
with \(z=a_D,a_Y\) and \({\mathcal {H}}_{X_j}^{C,L,Y,D}\) being the history of C, L, Y, D prior to \(X_j\) (i.e. the subset containing all variables in \(\{C_{k},L_k,Y_k,D_k:k=0,\dots ,K+1\}\) that are ordered topologically prior to \(X_j\)).
The identification formula for separable effects on the competing event with time-varying covariates was first shown in Stensrud et al. (2021a) and can also be found in Appendix C.
When full isolation holds, the identification formulas for separable effects are equal to identification formulas derived for certain path-specific effects (Stensrud et al. 2022; Robins and Richardson 2011; Robins et al. 2020). Otherwise, natural direct and indirect effects are not identified because time-varying blood pressure measurements \(L_k\), which are themselves affected by treatment, act as a recanting witness.
6.3.1 Graphical evaluation of the identification conditions
The exchangeability conditions (24)–(25) can be evaluated in a similar way as for the total effect in Fig. 2. However, identification of the separable effects also require the dismissible component conditions to hold. These conditions can be evaluated in a DAG representing a four armed trial where the \(A_D\) and \(A_Y\) components can be assigned different values (Stensrud et al. 2021a), shown in Fig. 4. Like for the controlled direct effect, \(L_k\) must contain sufficient variables to block all backdoor paths between D and Y in order for the dismissible component conditions to hold. In particular, unmeasured common causes of D and Y such as \(U_{DY}\) in Fig. 4 can violate the dismissible component conditions.

Graphical evaluation of the dismissible component conditions (27)–(28) when only baseline covariates are measured. Examples of violations of the conditions are shown as red paths. a Dismissible component conditions can be violated by unmeasured mediators such as \(M_{A_Y}\) and \(M_{A_D}\): (27) is violated by the path \(A_D\rightarrow M_{A_D}\rightarrow Y_{k+1}^{\overline{c}=0}\) and (28) is violated by the path \(A_Y\rightarrow M_{A_Y} \rightarrow D_{k+1}^{\overline{c}=0}\). However, if \(M_{A_Y}\) and \(M_{A_D}\) were measured and included in \(L_Y\) and \(L_D\) respectively, the dismissble conditions conditions would hold. b Assumption (27) is violated by open backdoor paths between Y and D, such as the path \(A_D\rightarrow D_{k+1}^{\overline{c}=0} \leftarrow U_{DY} \rightarrow Y_{k+1}^{\overline{c}=0}\), a collider path which opens when conditioning on \(D_{k+1}^{\overline{c}=0}\). Likewise, (28) is violated by the path \(A_Y\rightarrow Y_k^{\overline{c}=0}\leftarrow W_{DY}\rightarrow D_{k+1}^{\overline{c}=0}\)
6.4 Correspondence with continuous time estimands
Up to this section, we have considered a fixed time grid where the duration of each interval is 1 unit of time. In this section we will consider limiting cases of the identification results where we allow the grid-spacing to become arbitrarily small. Let the endpoints of the intervals \(k\in \{0,\dots ,K+1\}\) correspond to times \(\{0,t_1,\dots ,t_{K+1}\}\subseteq [0,\infty )\). As before, we assume the duration of all intervals is equal, and denote this by \(\Delta t\).
We can associate the counterfactual quantities considered thus far in discrete time with corresponding quantities in the counting process literature. An overview of the corresponding quantities is presented in Table 1. Here, we use the term ’factual quantities’ to denote variables that take their natural values, i.e. quantities that are not subject to any counterfactual intervention (see Richardson and Robins (2013b) for a formal definition of natural value). These are different from observed quantities, which only contain the factual events that have been recorded in subjects that are under follow-up.
Importantly, quantities indexed by the superscript \(\overline{c}=0\) are controlled direct effects with respect to an intervention which eliminates loss to follow-up, and do not have an analog in the existing counting process literature. This includes the quantity \(C_k^{\overline{c}=0}\), which is the counterfactual value of the censoring indicator for interval k under an intervention that eliminates censoring in previous intervals.
6.4.1 Correspondence of identification conditions
In the counting process literature, it is usual (see e.g. Aalen et al. 2008 and Cook and Lawless 2007, Expression 7.22) to identify the intensity of the complete (i.e. uncensored) counting process as a function of the intensity of the observed (i.e. censored) counting process, using the independent censoring assumption
where
A corresponding formulation of (35) within the discrete time framework is
We assume that the possibility of experiencing more than one recurrent event during a single interval becomes negligible, i.e. \(\Delta Y_j\in \{0,1\}\), for fine discretizations. Thus, for small \(\Delta t\), (36) is closely related to
We show in Appendix D that when the random variables in (37) are generated under an FFRCISTG model, and when consistency (16) and faithfulness hold, then exchangeability with respect to censoring (13) is implied by (37). In plain English, this result states that a discrete time analog of the independent censoring assumption implies the absence of backdoor paths between \(C_i^{a,\overline{c}=0}\) and \(Y_{j}^{a,\overline{c}=0}\) for all \(i\le j\) in Fig. 2. However, the reverse implication does not follow, as effects of \(C_i\) on future \(\Delta Y_j\) (i.e. the presence of a path \(C_i\rightarrow \Delta Y_j\) for \(i\le j\) in a DAG) violates (37) without violating (13). The path \(C_i\rightarrow \Delta Y_j\) for \(i\le j\) could represent the presence of concomitant care which affects the recurrent outcome, and the consequences of such a path for the interpretation of discrete versus continuous time estimands are clarified in Sect. 6.4.3. A similar correspondence of identification conditions exists for the competing event (Robins and Finkelstein 2000), and is stated in Appendix D.
6.4.2 Correspondence of identification formulas
In this section, we consider identifying functionals in the limit of fine discretizations of time. Justifications for the results are given in Appendix C.
In the limit of fine discretizations, \(E[Y_k^{a,\overline{c}=0}]\) can be formulated as

where

\(dA_t^D(a) = P( T^D \in [t,t+dt)| T^D \ge t, C \ge t, A=a)\) and \(W_A=\frac{P(A=a)}{\pi _A(A)}\). In this setting, \(\Lambda _t^C\) and \(\Lambda _t^{C|{\mathcal {F}}}\) are the compensators of \(N^C\) with respect to \({\mathcal {F}}_{t}^{C,D,A}\) and \({\mathcal {F}}_{t}^{L,Y,C,D,A}\), which heuristically means that
Here, \({\mathcal {F}}_{t}^{B}\) denotes the filtration generated by the collection of variables and processes B. Expression (38) is equivalent to

The product-integral terms are covariate-specific survival functions with respect to the censoring event. Expression (42) corresponds to Expression (7.29) in Cook and Lawless (2007) and targets a setting commonly called ’dependent censoring’ in the counting process literature.
Under the strengthened independent censoring assumption

which implies (35) without any covariates (\(L_t=\emptyset \)), we have that \({\mathcal {W}}_{C,t}=1\) with \(L_t=\emptyset \). Furthermore, in settings where treatment A is assigned by randomization, we have that \(W_A=1\). Consequently, (38) reduces to

Expression (44) corresponds to Expression (13) in Cook and Lawless (1997).
The controlled direct effect (with respect to interventions on the competing event) can be viewed as a special case of the total effect, where 1) we re-define the censoring event as a composite of loss to follow-up and the competing event, hence the censoring indicator takes the form \(I(C\wedge T^D \le t)\), and 2) we re-define the "competing" event as an event that never occurs. Under 1) and 2), Expression (43) becomes

and (44) reduces further to
Expression (46) is the continuous time limit of the controlled direct effect (23) if (45) is satisfied for fine discretizations. It corresponds to the quantity R(t) in Andersen et al. (2019) and is described by Cook and Lawless (1997) as a measure of the expected number of events for subjects at risk over the entire observation period, under the condition that the recurrent event is independent of the competing event.
The continuous time limit of the identification formula for separable effects (32) is given by

and

The weights \({\mathcal {W}}_D(a_Y,a_D)\) and \({\mathcal {W}}_Y(a_Y,a_D)\) take the form

where the compensators \(\Lambda ^{D|{\mathcal {F}}}\) and \(\Lambda ^{Y|{\mathcal {F}}}\) are defined analogously to (41). \(\Lambda _u^{D\mid {\mathcal {F}}}(a)\) is understood as the random function \(\Lambda _u^{D\mid {\mathcal {F}}}\) evaluated in the argument \(A=a\) (and likewise for \(\Lambda _u^{Y|{\mathcal {F}}}(a)\)). Furthermore, \(\theta _t^D = \Big ( \frac{d \Lambda _t^{D\mid {\mathcal {F}}}(a_D)}{ d \Lambda _t^{D\mid {\mathcal {F}}}(a_Y) }\Big )^{I(T^D \le t)}\) and \(\theta _t^Y = \Big ( \frac{d \Lambda _t^{Y\mid {\mathcal {F}}}(a_Y)}{ d \Lambda _t^{Y\mid {\mathcal {F}}}(a_D) }\Big )^{N_t-N_{t-}}\).
The mathematical characterization of the limit \({\mathcal {W}}_{L_{D},t}(a_Y,a_D)\) of \(\prod _{j=0}^i \pi _{L_{D,j}}^{a_D}/\prod _{k=0}^i \pi _{L_{D,k}}^{a_Y}\), where \(\pi _{L_{D,j}}^{\bullet }\) is defined in (34), depends on what type of process \(L_{D}\) is. Many applications are covered when \(L_{D}\) is a marked point process on a finite mark space. That is, \(L_{D}\) takes values in a finite number of marks but can jump between marks over time. We will assume \(L_{D}\) is such a process in Sect. 7. The same considerations also apply to the limit \({\mathcal {W}}_{L_{Y},t}(a_Y,a_D)\) of \(\prod _{j=0}^i \pi _{L_{Y,j}}^{a_Y}/\prod _{k=0}^i \pi _{L_{Y,k}}^{a_D}\). These weights are closely related to the mediation weights considered by Zheng and van der Laan (2017); Mittinty and Vansteelandt (2020); Tchetgen Tchetgen (2013).
Finally, a product integral representation of the total effect on the competing event is given in Appendix C.
In Table 2, we show an overview of the correspondence between the causal estimands discussed in Sect. 6 and common estimands that appear in the statistical literature.
6.4.3 Differences in interpretation
In the counting process formalism of recurrent events, \(N^c_t\) is interpreted as the count of events that would be measured if we somehow could observe every individual’s future outcomes (for example by implanting a ’tracker device’), even if they withdraw from study participation or otherwise discontinue follow-up. This is a factual (as opposed to a counterfactual) quantity, because it is not subject to any counterfactual intervention to eliminate censoring. Next, the observed counting process \(N_t\) is interpreted as the number of events that were recorded while the subject was alive and under follow-up, i.e. \(N_t=\int _0^t I(T^D\ge s, C\ge s)dN^c_s\).
If study participants receive concomitant care by virtue of being under follow-up (e.g. additional medical exams that can lead to discovery of new conditions which trigger initiation of additional, supportive treatments), then individuals who are lost to follow-up may have different outcomes \(N^c_t\) compared to subjects under follow-up due to the termination of such concomitant care. This violates the independent censoring condition (35). Therefore, \(E[N_t^c]\) is not identified when concomitant care under follow-up affects future outcomes \(N^c_t\) without additional strong assumptions. In other words, one cannot make inference on individuals who are censored (who do not receive concomitant care) by only observing uncensored individuals (who do receive concomitant care).
In contrast to \(N^c_t\), the counterfactual quantity \(Y^{\overline{c}=0}_k\) is often interpreted as the number of recurrent events that would be observed by time k under an intervention which prevented individuals from being lost to follow-up, i.e. in a pseudopopulation where all individuals receive the same level of the primary intervention (A) and concomitant care. \(E[Y^{\overline{c}=0}_k]\) is still identified under effects of concomitant care on the recurrent event, i.e. the arrows \(c_k=0\rightarrow Y_k^{a,\overline{c}=0}\) in Fig. 2 do not violate the exchangeability condition (13). In the special case where concomitant care does not affect future recurrent events, the interpretations of \(E[Y^{\overline{c}=0}_k]\) and \(E[N^c_{t_k}]\) coincide. Similar arguments are given by Young et al. (2020), Sect. 5, for the incident event setting.
7 Estimation
The identification formulas in Sect. 6 motivate a variety of estimators that have been presented in the literature; examples can be found in Young et al. (2020); Stensrud et al. (2021a); Martinussen and Stensrud (2021).
In survival and event history analysis, researchers have traditionally been accustomed to estimands and estimators defined in continuous time. We mapped out correspondences between the discrete time identification formulas and their continuous time limits in Sect. 6.4.2. Next, we will considerFootnote 6 the following general estimator in continuous time, applicable to several of the estimands considered above,
Here, \(\hat{Y}_t\) is an estimator of a counterfactual mean frequency function under interventions of interest and \(\hat{S}_t\) is an auxiliary quantity used to define the system in (47). Finally, \(\hat{D}_t\) is an estimator of a counterfactual competing event process under interventions of interest.
The stochastic differential equation (47) is uniquely determined by the integrators. Thus, presenting different estimators on this form amounts to presenting different integrators. We restrict the focus to the case with no tied event times in the remainder of this section for ease of presentation.
7.1 Risk set estimators
Identification formulas of the form (38), where the integrator conditions on the at-risk event \(\{ T^D \ge t, C \ge t \}\), motivate the risk set estimators
where \(Z^i_t=I(T^{D,i}\ge t, C^i \ge t)\) is the at-risk process. Here, \(N_t^i=N_{t\wedge C_i}^{c,i}\) is the observed counting process for the recurrent event, \(N^{D,i}_t = I(T^{D,i} \le t, T^{D,i} < C^i)\) is the observed counting process for death, and \(\hat{R}^i, \hat{R}^{i,D}\) are estimated weight processes of individual i (see Table 3). The \(\hat{\bar{\theta }}^i\) terms, specified in Table 3, are needed when the driving counting processes share jump times with the weights, which is the case for some separable effects estimands, as seen in Sect. 6.4.2.
7.2 Horvitz–Thompson and Hajek estimators
Identification formulas of the form (42) (which coincides with the discrete time formulas (18) in the case of the total effect, (23) for the controlled direct effect and (32)–(33) for the separable effect) motivate Hajek estimators (Hajek 1971) and Horwitz–Thompson estimators (Horvitz and Thompson 1952), which give the integrators
In the above expression, \(H_{t} =\frac{1}{n} \sum _{j=1}^n \hat{ \overline{R}}_{t}^j I(A_j=a)\) gives Hajek estimators, and \(H_{t}=1\) gives Horvitz–Thompson estimators. \(\hat{ \overline{R}}^i\) is an estimated weight processes for individual i (see Table 3). These estimators are closely related to previously studied inverse probability weighted estimators (Robins and Rotnitzky 1992; Rotnitzky and Robins 1995; Hernán et al. 2000) and proportional odds estimators (Zheng and van der Laan 2017; Mittinty and Vansteelandt 2020; Tchetgen Tchetgen 2013).
The estimator defined by (47) may be unfamiliar to some practitioners, but it has the following properties:
-
The estimator is generic in the sense that, given weight estimators it can be used to estimate the total effect, the controlled direct effect, and the separable effect, and other composite estimands (e.g. the ‘while alive’ strategy) as defined in Sect. 3.
-
Expression (47) is easy to solve on a computer, as it defines a recursive equation that can be solved using e.g. a for loop. General software that can be used to solve systems like (47) is available for anyone to use at github.com/palryalen/.
In Theorem 1 in Appendix E we provide convergence results for the estimators in (47)–(48) for the case when the true weights are not known, but estimated. Convergence is guaranteed when the weight estimators \(\hat{R}_t\), \(\hat{R}_t^D\), and \(\hat{ \overline{R}}_t\) converge in probability to the true weights for each fixed t, which is established for the additive hazard weight estimator we will consider in Sect. 7.3 (Ryalen et al. 2019, Theorem 2).
In Table 3 we present pairs of weights \(R^i, R^{i,D}\), and \({{\bar{R}}}^i\) as well as the parameter \(\bar{\theta }^{i}_t \) that can be used in (47)–(48) to estimate the total effect, the direct effect, and the separable effects as defined in Sect. 3. Define \({\mathcal {W}}_{D}\), the weights associated with the intervention that prevents death from other causes, similarly to the censoring weights in (39),

where \(\Lambda _t^D\) is the compensator of \(N^D\) with respect to \({\mathcal {F}}_{t}^{C,D,A}\), defined analogously to (40). \(\overline{{\mathcal {W}}}_{C}\) and \(\overline{{\mathcal {W}}}_{D}\) are the unstabilized versions of these weights, defined as

7.3 Estimating the weights
Suppose we have a consistent estimator of the propensity score \(\pi _A\), which will allow us to estimate the treatment weights in Table 3.
The time-varying weights in Table 3 solve the Doléans–Dade equation
where \(W^i\) is the weight of interest, \({\bar{N}}^i\) is a counting process, \(\alpha ^i\) and \(\alpha ^{*,i}\) are hazards, and \(\theta ^i = \alpha ^{*,i}/ \alpha ^i\). In Table 4, we present \(\alpha ^i\), \(\alpha ^{*,i}\), and \({\bar{N}}^i\)’s corresponding to the different weights in Table 3. We consider a weight estimator that is defined via plug-in of cumulative hazard estimates,
where \(\hat{A}^i\) and \(\hat{ A}^{*,i}\) are cumulative hazard estimates of \( A_t^i = \int _0^t \alpha _s^i ds\) and \( A_t^{*,i} = \int _0^t \alpha _s^{*,i} ds\) and \(\hat{\theta }_t^i = \frac{\hat{A}^{*,i}_t - \hat{ A}^{*,i}_{t-b}}{\hat{ A}^i_t - \hat{ A}^i_{t-b}}\), where b is a smoothing parameter used to obtain the hazard ratio \(\hat{\theta }_t^i\). The solution to (51) is determined by the cumulative hazard estimates and the counting process. Thus, the smoothing parameter b contributes to the estimator only when \({\bar{N}}^i\) jumps, which will not happen for the weights \({\mathcal {W}}_C^i, \overline{{\mathcal {W}}}_C^i, {\mathcal {W}}_D^i,\) and \(\overline{{\mathcal {W}}}_D^i\) in the examples we consider in Table 3. The counting process term in (51) can therefore be neglected for the upper four weights in Table 4. For the other time-varying weights, choosing b requires a trade-off between bias and variance, see Ryalen et al. (2019) for a discussion.
To estimate \({ {\mathcal {W}}}_{L_{D},t}^i\), the weights associated with \(L_{D}\), we suppose that there are m marks. We consider the counting processes \(\{N_h^i\}_{h=1}^m\) that "counts" the occurrence of each mark of individual i, having intensity \(Z_t^i \cdot \alpha _{h,t}^idt = E[dN^i_{h,t}| \sigma (L_s^i,N_s^i,N_s^{D,i},C_s^i,A; s < t )]\). Then,
where \({\mathcal {W}}_{L_{D},h,t}^i\) solves (50) with \(\alpha _t^i = \alpha _{h,t}^i|_{A=a_Y}\), \(\alpha _t^{*,i} = \alpha _{h,t}^{*,i}|_{A=a_D}\) and \({\bar{N}}^i = N_h^i\). We thus obtain an estimator of \({\mathcal {W}}_{L_{D},t}^i\) by multiplying the estimators \(W_{L_{D},h,t}^i\), each of which solve (51). A corresponding procedure can be used to estimate the weights \({\mathcal {W}}_{L_Y,t}^i\). We present the choices of \(\alpha ^i\) and \(\alpha ^{*,i}\) for the different weights in Table 4. For high-dimensional covariates \(L_k\), these weight estimators may give rise to erratic behavior (this is also described for the related mediation weights in Mittinty and Vansteelandt 2020). In future work, one could also consider estimators motivated by the alternative odds representation of the covariate weights, given in Appendix C, along the lines of Zheng and van der Laan (2017) and Stensrud et al. (2021a), but this is beyond the scope of the current work.
In summary, we suggest the following strategy for estimating the causal effects of interest:
-
Identify the requisite weights from Table 3 and specify hazard models \(\alpha ^i\), \(\alpha ^{*,i}\) from Table 4.
-
Solve (51) to obtain estimates of the weight processes.
-
Obtain \(\hat{R}^i, \hat{R}^{D,i}, \hat{\overline{R}}^i\), and \(\hat{\bar{\theta }}^i\) from (48) or (49) by multiplying together the weight estimates of individual i according to Table 3.
-
Solve (47) to obtain \(\hat{Y}_t\) (and/or \(\hat{D}_t\)), which estimates the expected number of events under the chosen intervention at t.
-
Repeat the previous steps with a contrasting intervention on treatment to obtain the targeted causal contrast.
-
Evaluate the uncertainty of the estimators using non-parametric bootstrap.
We use this estimation method in Sect. 8, assuming additive hazard models for the different \(\alpha ^i\)’s and \(\alpha ^{*,i}\)’s. The estimators are implemented in the R packages \(\texttt {transform.hazards}\) and ahw (available at github.com/palryalen/). The code is found in the online supplementary material.
7.4 Estimators under assumptions on \(L_k\)
There exist two important settings where we do not need to model the densities of the covariate process \(L_t\). Firstly, if the dismissible component conditions are satisfied with \(L_{Y,k} \equiv L_k\) and \(L_{D,k}=\emptyset \), then \({\mathcal {W}}_{L_{D},t}=1\) (a further elaboration on this point is found in Appendix C). The assumption that \(L_{D,k}=\emptyset \) implies that \(A_D\) partial isolation holds (see Appendix B for a definition of \(A_D\) partial isolation and Lemma 6 of Stensrud et al. (2021a) for a proof of this result). This is unlikely to hold in the trial considered in Sect. 8, because we expect that the \(A_D\) component of treatment can cause acute kidney injury by lowering systemic blood pressure, i.e. through the pathway \(A_D\rightarrow L_j \rightarrow Y_{k>j}\), which is not intersected by any \(D_{i\le k}\).
Secondly, if the dismissible component conditions are satisfied under \(L_{D,k} \equiv L_k\) and \(L_{Y,k}=\emptyset \), we have that \({\mathcal {W}}_{L_{Y},t}=1\). In the trial in Sect. 8, this assumption implies that the component that binds to receptors in the kidneys (\(A_Y\)) has no effect on blood pressure outside of its possible effect on the risk of acute kidney injury (see Lemma 5 of Stensrud et al. 2021a). This is plausible and serves as a sanity check of the dismissible component conditions in this example. However, in practice we have intermittent blood pressure measurements \(L_k\), and therefore the dismissible component conditions under \(L_{D,k} \equiv L_k\) and \(L_{Y,k}=\emptyset \) hold at best approximately.
Even in these two simplified settings, the natural direct effect is not identified as the measured covariates \(L_{Y,k}\) (or \(L_{D,k}\)) act as a recanting witness (see Sect. 6.3).
8 Example: blood pressure treatment and acute kidney injury
In Sect. 3.3 we described a hypothetical modified version of antihypertensive therapy that preserves the effect of existing treatments on systemic blood pressure but does not lead to dilation of efferent arterioles in the kidneys, thereby potentially avoiding a detrimental side effect of treatment which can give risk to acute kidney injury. In this section, we apply the estimators proposed in the Sect. 7 to compute the effect of such a modified blood pressure therapy on the recurrence of acute kidney injury, as well as the total and controlled direct effect, using data from the Systolic Blood Pressure Intervention Trial (SPRINT Research Group 2015). The illustrative example considered in this section builds on Stensrud et al. (2021a), but now considers the case where acute kidney injury (\(Y_k\)) is a recurrent outcome as opposed to the (first) incident event. Another, simulated example from a hypothetical trial on treatment discontinuation is given in Appendix A along with R code in the Supplementary Material.
In the SPRINT trial, individuals were randomized to standard (\(A=0\)) or intensive (\(A=1\)) blood pressure (BP) lowering therapy. We consider the effect of intensive versus standard treatment on the recurrence of acute kidney injury by time t during the first 1000 days of follow-up.
We have restricted our analysis to subjects aged over 75 years of age. Furthermore, we have only considered individuals with complete baseline covariates. This led to 1312 individuals under standard treatment and 1311 individuals under intensive treatment. By the end of 1000 days, a total of 73 deaths were recorded in the standard treatment group, versus 52 in the intensive treatment group. In total, 668 individuals were lost to follow-up before day 1000. The frequencies of recorded AKI events by treatment group are given in Table 5.
We estimated total, controlled direct and separable effect using (49) with additive regression models for the hazards, specified in Table 6.
Following Stensrud et al. (2021a), we included the following baseline covariates (\(L_0\)): smoking status, history of clinical or subclinical cardiovascular disease, clinical or subclinical chronic kidney disease, statin use and sex. Additionally, we adjusted for the most recent measurements of mean arterial pressure (\(L_{k}\)). We truncated the stabilized weights \({\mathcal {W}}_{C,t},{\mathcal {W}}_{D,t}\) and \({\mathcal {W}}_{Y,t}\) outside of the interval [0.2-5]. A smoothing parameter of \(b=250\) was used (analyses with parameters \(b\in \{100,200,500\}\) gave similar results).
The analysis relies on the identification assumptions in Sect. 6. The assumptions of exchangebility of baseline treatment, positivity and consistency hold by design because blood pressure treatment is assigned by randomization in a controlled experiment. We have further assumed that the measured covariates \((L_0,L_k)\) are sufficient for identification. In particular, exchangeability (20) for the controlled direct effect and the dismissible component conditions (27)–(28) would be violated if there are unmeasured common causes of death and recurrent AKI, such as \(U_{DY}\) in Figs. 3 and 4, that are not captured by \((L_0,L_k)\), or causal paths such as \(A_Y \rightarrow M_{A_Y} \rightarrow D_{k+1}^{\overline{c}=0}\) or \(A_D\rightarrow M_{A_D}\rightarrow Y_{k+1}^{\overline{c}=0}\) in Fig. 4 that are not intersected by \(L_k\).
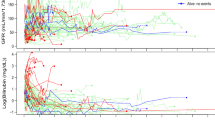
The resulting estimates are shown in Fig. 5. At 1000 days, we found a total effect of \(0.017[-0.001,0.037]\) and a controlled direct effect of \(0.017[-0.003,0.037]\) (95% confidence intervals, obtained using 500 non-parametric bootstrap samples, are reported in square brackets). Thus, the total effect for individuals over 75 years old is (borderline) consistent with an increased occurrence of acute kidney injury under intensive treatment, as reported by SPRINT Research Group (2015) for the full trial population. However, there were more deaths in the standard group compared to the intensive group (see Fig. 9a in Stensrud et al. 2021a). Thus, it is not clear whether the increased occurrence of acute kidney injury in the intensive group is due to a protective effect on survival or a direct effect on the recurrent outcome.
To quantify the mechanism by which treatment leads to increased risk of acute kidney injury, we studied separable effects. The direct separable effect evaluated at \(a_D=1\) is equal to \(0.011[-0.005,0.034]\) at 1000 days, which is consistent with no reduction in the recurrence of acute kidney injury by eliminating the \(A_Y\) component of treatment. This finding is also consistent with Stensrud et al. (2021a), who only studied the incidence of the first kidney failure event. To conclude, the analysis of separable effects does not provide evidence in favor of a reduction in the expected number of acute kidney injury episodes in a modified blood pressure treatment that does not dilate efferent glomerular arterioles. If a non-null effect had been found, this would strengthen the hypothesis that we could change the number of acute kidney injury occurrences by intervening on the treatment component that dilates efferent arterioles, and thereby make it more attractive to test such a hypothesis in a future randomized trial if such a treatment is developed.

Shows estimates of the total effect, controlled direct effect and separable effect on recurrence of acute kidney injury up to 1000 days. The superscript \(\overline{c}=0\), denoting an intervention to prevent loss to follow-up, has been suppressed in plot legends to reduce clutter
9 Discussion
We have used a formal causal framework to define estimands for recurrent outcomes that differ in the way they treat competing events. The controlled direct effect is a contrast of counterfactual outcomes which implies that competing events are considered to be a form of censoring. The total effect captures all causal pathways between treatment and the recurrent event, and the separable effect quantifies contrasts in expected outcomes under independent prescription of treatment components.
Further, we have given formal conditions for identifying these effects, and demonstrated how to evaluate the identification conditions in causal graphs. This allowed us to formally describe how the causal estimands map to classical statistical estimands for recurrent events based on counting processes in the limit of fine discretizations of time.
In settings with competing events, it is often of interest to disentangle the effect on the recurrent event from the effect on the competing event. The controlled direct effect often fails to do so in a scientifically insightful way, because it is not clear which intervention, if any, eliminates the occurrence of the competing event. The interpretation of the direct effect is therefore unclear. The separable effect corresponds (by design) to interventions on components of the original treatment, which are assigned independently of each other. The practical relevance of the estimand relies on the plausibility of modified treatments. The process of conceptualizing modified treatments can motivate future treatment development and sharpen research questions about mechanisms (Robins and Richardson 2011; Robins et al. 2020; Stensrud et al. 2020).
Stronger assumptions are needed to identify the (controlled) direct effect and separable effects compared to the total effect. For example, these estimands require the investigator to measure common causes of the recurrent event and failure time, even in an ideal randomized trial such as in Sect. 2. The need for stronger assumptions is far from unique to our setting, and it is analogous to the task of identifying per-protocol effects in settings with imperfect adherence and mediation effects.
The use of a formal (counterfactual) framework to define causal effects elucidates analytic choices regarding treatment recommendations. The formal causal framework makes it possible to define effects with respect to explicit interventions, and to explicitly state the conditions under which such effects can be identified from observed data. This also makes it possible to transparently assess the strength and validity of the identifying assumptions in practice.
Change history
09 July 2023
Missing ESM has been added
Notes
What we define as a competing event is often called a terminating event in the recurrent events literature.
While these results are shown for recurrent event outcomes, they also apply to the more classical competing event setting described in Young et al. (2020), which constitutes a special case of the current work.
Our presentation focuses on intention-to-treat effects by defining A as an indicator of baseline assignment to a particular treatment arm. Our results trivially extend to accommodate effects of adherence to a particular protocol at baseline by instead taking A to be the actual treatment strategy followed at baseline and by including common causes of treatment adherence, acute kidney injury and death in \(L_0\). In either case, indicators of time-varying adherence to the protocol may be important to include in \(L_k\), \(k>0\), for the purposes of identification to be discussed in later sections.
A topological order is a linear ordering of nodes in a graph from first to last.
In continuous time, the restricted survival can be written as \(\int _0^t I(T^D\ge s)ds\), where \(T^D\) is the time of the competing event. Taking the expectation gives \(\int _0^t S(s)ds\) for survival function S(t), which is the restricted mean survival in continuous time (Aalen et al. 2008).
The reverse implications do not hold. A counterexample is given by partial exchangeability (Sarvet et al. 2020).
References
Aalen OO, Ørnulf Borgan, Gjessing HK (2008) Survival and event history analysis. Statistics for biology and health. Springer, New York
Aalen OO, Cook RJ, Røysland K (2015) Does cox analysis of a randomized survival study yield a causal treatment effect? Lifetime Data Anal 21(4):579–593
Andersen PK, Angst J, Ravn H (2019) Modeling marginal features in studies of recurrent events in the presence of a terminal event. Lifetime Data Anal 25(4):681–695
Anker SD, McMurray JJV (2012) Time to move on from ‘time-to-first’: should all events be included in the analysis of clinical trials? Eur Heart J 33(22):2764–2765
Brunton LL, Knollmann BC, Hilal-Dandan R (2018) Goodman and Gilman’s: the pharmacological basis of therapeutics. McGraw-Hill’s Access Medicine, 13th edn. McGraw-Hill Education LLC, New York
Chen BE, Cook RJ (2004) Tests for multivariate recurrent events in the presence of a terminal event. Biostatistics 5(1):129–143
Brian Claggett L, Tian HF, Solomon SD, Wei L-J (2018) Quantifying the totality of treatment effect with multiple event-time observations in the presence of a terminal event from a comparative clinical study. Stat Med 37(25):3589–3598
Cook RJ, Lawless JF (1997) Marginal analysis of recurrent events and a terminating event. Stat Med 16(8):911–924
Cook RJ, Lawless JF (2007) The statistical analysis of recurrent events. Statistics for biology and health. Springer, New York
Dawid P, Didelez V (2012) Imagine a can opener-the magic of principal stratum analysis. Int J Biostat 8:1
Didelez V (2019) Defining causal mediation with a longitudinal mediator and a survival outcome. Lifetime Data Anal 25(4):593–610
European Medicines Agency (2020) Qualification opinion of clinically interpretable treatment effect measures based on recurrent event endpoints that allow for efficient statistical analysis
Frangakis CE, Rubin DB (2002) Principal stratification in causal inference. Biometrics 58(1):21–29
Fritsch A, Schlömer P, Mendolia F, Mütze T, Jahn-Eimermacher A (2021) Efficiency comparison of analysis methods for recurrent event and time-to-first event endpoints in the presence of terminal events–application to clinical trials in chronic heart failure. Stat Biopharm Res 0(0):1–12
Gail M (1975) A review and critique of some models used in competing risk analysis. Biometrics 31(1):209
Ghosh D, Lin DY (2000) Nonparametric analysis of recurrent events and death. Biometrics 56(2):554–562
Hajek J (1971) Comment on “An essay on the logical foundations of survey sampling by D. Basu’’. In: Godambe VP, Sprott DA (eds) Foundations of statistical inference. Holt, Rinehart and Winston of Canada, Toronto
Hernán MA (2010) The hazards of hazard ratios. Epidemiology (Cambridge, Mass.) 21(1):13–15
Hernán MA, Brumback B, Robins JM (2000) Marginal structural models to estimate the causal effect of zidovudine on the survival of HIV-positive men. Epidemiology 11(5):561–570
Horvitz DG, Thompson DJ (1952) A generalization of sampling without replacement from a finite universe. J Am Stat Assoc 47(260):663–685
Jacod J, Shiryaev AN (2003) Limit theorems for stochastic processes, volume 288 of Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences], 2nd edn. Springer, Berlin
Joffe M (2011) Principal stratification and attribution prohibition: good ideas taken too far. Int J Biostat 7(1):1–22
Martinussen T, Stensrud MJ (2021) Estimation of separable direct and indirect effects in continuous time. Biometrics
Martinussen T, Vansteelandt S, Andersen PK (2020) Subtleties in the interpretation of hazard contrasts. Lifetime Data Anal 26(4):833–855
Mittinty MN, Vansteelandt S (2020) Longitudinal mediation analysis using natural effect models. Am J Epidemiol 189(11):1427–1435
Pearl J (2001) Direct and indirect effects. In: Proceedings of the seventeenth conference on uncertainty in artificial intelligence, pp 411–20
Pearl J (2009) Causality: models, reasoning, and inference, 2nd edn. Cambridge University Press, Cambridge
Prentice RL, Kalbfleisch JD, Peterson JAV, Flournoy N, Farewell VT, Breslow NE (1978) The analysis of failure times in the presence of competing risks. Biometrics 541–554
Putter H, Fiocco M, Geskus RB (2007) Tutorial in biostatistics: competing risks and multi-state models. Stat Med 26(11):2389–2430
Reeve E, Jordan V, Thompson W, Sawan M, Todd A, Gammie TM, Hopper I, Hilmer SN, Gnjidic D (2020) Withdrawal of antihypertensive drugs in older people. Cochrane Datab Syst Rev 6
Richardson TS, Robins JM (2013a) Single world intervention graphs: a primer
Richardson TS, Robins JM (2013b) Single world intervention graphs (SWIGs): a unification of the counterfactual and graphical approaches to causality
Robins J (1986) A new approach to causal inference in mortality studies with a sustained exposure period-application to control of the healthy worker survivor effect. Math Model 7(9):1393–1512
Robins JM, Finkelstein DM (2000) Correcting for noncompliance and dependent censoring in an AIDS clinical trial with inverse probability of censoring weighted (IPCW) log-rank tests. Biometrics 56(3):779–788
Robins JM, Greenland S (1992) Identifiability and exchangeability for direct and indirect effects. Epidemiology 143–155
Robins JM, Richardson TS (2011) Alternative graphical causal models and the identification of direct effects. In: Causality and psychopathology. Oxford University Press, Oxford
Robins JM, Rotnitzky A (1992) Recovery of information and adjustment for dependent censoring using surrogate markers. In: Jewell NP, Dietz K, Farewell VT (eds) AIDS epidemiology: methodological issues. Birkhäuser, Boston, pp 297–331
Rotnitzky A, Robins JM (1995) Semiparametric regression estimation in the presence of dependent censoring. Biometrika 82(4):805–820
Robins J, Rotnitzky A, Vansteelandt S, Ten Have T, Xie Yu, Murphy S (2007) Discussions on “Principal stratification designs to estimate input data missing due to death". Biometrics 63(3):650–658
Robins JM, Richardson TS, Shpitser I (2020) An interventionist approach to mediation analysis. arXiv:2008.06019
Ryalen PC, Stensrud MJ, Røysland K (2018) Transforming cumulative hazard estimates. Biometrika 105:905–916
Ryalen PC, Stensrud MJ, Røysland K (2019) The additive hazard estimator is consistent for continuous-time marginal structural models. Lifetime Data Anal 25(4):611–638
Sarvet AL, Wanis KN, Stensrud MJ, Hernán MA (2020) A graphical description of partial exchangeability. Epidemiology 31(3):365–368
Schmidli H, Roger JH, Akacha M (2021) On behalf of the recurrent event qualification opinion consortium. Estimands for recurrent event endpoints in the presence of a terminal event. Stat Biopharma Res 1–29
Spirtes P, Glymour CN, Scheines R (2000) Causation, prediction, and search. Adaptive computation and machine learning, 2nd edn. MIT Press, Cambridge
SPRINT Research Group (2015) A randomized trial of intensive versus standard blood-pressure control. N Engl J Med 373(22):2103–2116
Stensrud MJ, Dukes O (2022) Translating questions to estimands in randomized clinical trials with intercurrent events. Stat Med 41(16):3211–3228
Stensrud MJ, Hernán MA (2020) Why test for proportional hazards? JAMA 323(14):1401–1402
Stensrud MJ, Young JG, Didelez V, Robins JM, Hernán MA (2020) Separable effects for causal inference in the presence of competing events. J Am Stat Assoc 1–9
Stensrud MJ, Hernán MA, Tchetgen Tchetgen EJ, Robins JM, Didelez V, Young JG (2021a) A generalized theory of separable effects in competing event settings. Lifetime Data Anal
Stensrud MJ, Young JG, Martinussen T (2021b) Discussion on “causal mediation of semicompeting risks’’ by Yen-Tsung Huang. Biometrics 77(4):1160–1164
Stensrud MJ, Robins JM, Sarvet A, Tchetgen Tchetgen EJ, Young JG (2022) Conditional separable effects. J Am J Am Stat Assoc 1–13
Tchetgen Tchetgen EJ (2013) Inverse odds ratio-weighted estimation for causal mediation analysis. Stat Med 32(26):4567–4580
Tsiatis A (1975) A nonidentifiability aspect of the problem of competing risks. Proc Natl Acad Sci 72(1):20–22
Vansteelandt S, Linder M, Vandenberghe S, Steen J, Madsen J (2019) Mediation analysis of time-to-event endpoints accounting for repeatedly measured mediators subject to time-varying confounding. Stat Med 38(24):4828–4840
Wei J , Mütze T, Jahn-Eimermacher A, Roger J (2021) Properties of two while-alive estimands for recurrent events and their potential estimators. Stat Biopharm Res 0(0):1–11
Yanxun X, Scharfstein D, Müller P, Daniels M (2022) A Bayesian nonparametric approach for evaluating the causal effect of treatment in randomized trials with semi-competing risks. Biostatistics 23(1):34–49
Young JG, Stensrud MJ (2021) Identified versus interesting causal effects in fertility trials and other settings with competing or truncation events. Epidemiology 32(4):569–572
Young JG, Stensrud MJ, Tchetgen Tchetgen EJ, Hernán MA (2020) A causal framework for classical statistical estimands in failure-time settings with competing events. Stat Med 39(8):1199–1236
Zheng W, van der Laan M (2017) Longitudinal mediation analysis with time-varying mediators and exposures, with application to survival outcomes. J Causal Inference 5:2
Acknowledgements
This manuscript was prepared using SPRINT Research Materials obtained from the NHLBI Biologic Specimen and Data Repository Information Coordinating Center and does not necessarily reflect the opinions or views of the SPRINT or the NHLBI.
Funding
Open access funding provided by EPFL Lausanne. Matias Janvin and Mats J. Stensrud were supported by the Swiss National Science Foundation under grant 200021_207436.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
Appendix A: Illustrative example: a simulated trial on treatment discontinuation
In this section, we illustrate an application of the concepts and estimators outlined in Secs. 6-7 for the total effect, controlled direct effect and separable effect, using a simulated data example. Consider investigators concerned with the effects of over-treatment of older adults with antihypertensive agents (\(A_Y\)) and aspirin (\(A_D\)). Over-treatment might lead to episodes (\(Y_k\)) of syncope (dizziness) caused by blood pressure becoming too low (in turn, possibly leading to injurious falls), with all-cause mortality (\(D_k\)) as a competing risk. Suppose these investigators conduct a randomized controlled trial in a sample of patients admitted to nursing homes with a history of cardiovascular disease and currently taking antihypertensives and aspirin. Patients are then randomly assigned to either discontinue or to continue both treatments (\(A=0\) indicates assignment to discontinuation of both aspirin and antihypertensives, \(A=1\) denotes assignment to continuing both medications). A similar intervention is considered in Reeve et al. (2020). Thus, \((A_Y,A_D)\) is a physical decomposition of treatment A such that receiving both components, i.e. \(A_Y=A_D=1\), is equivalent to receiving \(A=1\) (and conversely receiving neither component, \(A_Y=A_D=0\), is equivalent to \(A=0\)), and therefore satisfies the modified treatment assumption (4).
We consider a simplified setting where there is one binary pre-treatment and post-treatment common cause of future events (syncope and death), denoted by \(L_0\) (old age at baseline) and \(L_1\) (binarized blood pressure after treatment initiation) respectively.
In the data generating model, we first sampled \(L_0,L_1\) according to
Next, we generated the processes \((Y_k,D_k,C_k)\) on a discrete time grid using the hazards
The data generating model is constructed such that it satisfies all of the identification conditions for total effect, controlled direct effect and separable effect, and is consistent with the causal DAGs in Fig. 6. The implementation of the data generating model is shown in the online Supplementary Material.

a Causal graph illustrating a hypothetical four armed trial where \(A_Y\) (antihypertensive agents) and \(A_D\) (aspirin) are assigned freely. b Shows the observed two armed trial where \(A_Y\) and \(A_D\) are assigned jointly (\(A_Y\equiv A_D\equiv A\)). Censoring nodes \(C_k\) are not shown because they are not connected to any other nodes under the chosen data generating model
Figure 6 encodes the assumption that only the \(A_Y\) component (antihypertensive treatment) affects \(L_1\) and does not directly affect death while the \(A_D\) component (aspirin) acts directly on survival and has no effect on the recurrence of syncope except through pathways intersected by survival (\(D_k\)). The parameters of the data generating model were chosen such that antihypertensive treatment (\(A_Y=1\)) increases the risk of death through the pathway \(A_Y\rightarrow L_1\rightarrow Y_k\rightarrow D_{k+1}\), i.e. by lowering blood pressure, which in turn may lead to syncope and subsequent injurious falls. This is seen in Fig. 7a, as individuals who received antihypertensives (\(A_Y=1\)), shown by the black and red curves, experience a larger number of syncope episodes. Next, treatment with aspirin decreases the risk of death through cardiovascular protection via the pathway \(A_D\rightarrow D_{k+1}\). As illustrated by the crossing of the black and blue curves in Fig. 7b, the decreased risk of death due to aspirin through pathway \(A_D\rightarrow D_{k+1}\) is compensated by the increased risk of death under antihypertensive treatment through \(A_Y\rightarrow L_1\rightarrow Y_k\rightarrow D_{k+1}\). Therefore, discontinuation of antihypertensives only, i.e. \((A_Y=0,A_D=1)\), gives the highest survival in this example. This illustrates the role and interpretation of the separable effect; even though a trial investigator only observes individuals in treatment levels \(A\in \{0,1\}\), the separable effects allows us to make inference under the hypothetical decomposed intervention \((A_Y=0,A_D=1)\), which is not possible using conventional estimands such as the total effect or controlled direct effect.
By transforming the graphs in Fig. 6 to single world intervention graphs (Richardson and Robins 2013b) corresponding to Figs. 2, 3 and 4, it is straightforward to verify that the exchangeability (12)–(13), (19)–(20) and (24)–(25) and dismissible component conditions (27)–(30) are satisfied by the causal model. Because all positivity and consistency conditions also hold by construction in the data generating model, the total, controlled direct and separable effects are identified by the respective functionals given in Secs. 6.1–6.3. Furthermore, we can see from Fig. 6 that strong \(A_Y\) partial isolation (6) is violated by the path \(A_Y\rightarrow Y_k \rightarrow D_{k+1}\), and thus the effect of antihypertensives (\(A_Y\)) on recurrent syncope (\(Y_k\)) cannot be interpreted as a direct effect outside of pathways intersected by survival (\(D_k\)).
1.1 A.1. Estimates
Figure 7c and d present estimates of \(E[Y_k^{a,\overline{c}=0}]\) for \(a=a_Y=a_D\in \{0,1\}\) and \(E[Y_k^{a_Y,a_D,\overline{c}=0}]\) for \(a_Y\ne a_D\) using the estimators described in Sect. 7 for 500 simulated individuals in each of the treatment groups \(A=0\) and \(A=1\). It follows from the data generating model defined in the beginning of Appendix A and Table 7 that the assumed hazard models are correctly specified. In principle, we could allow for a more involved data generating model with time-varying coefficients. The assumed hazard models would still provide consistent estimates if the additive structure is correctly specified. Thus, an investigator can adapt the estimators in the supplementary R material to other recurrent event problems.

Different effects of treatment (dis)continuation of antihypertensives (\(A_Y\)) and aspirin (\(A_D\)) on recurrent syncope and survival are shown in a and b, under a hypothetical data generating model. The superscript \(\overline{c}=0\), denoting an intervention to prevent loss to follow-up, has been suppressed in plot legends to reduce clutter. Estimates using the risk set estimator in (48) with a sample size of 500 individuals in each treatment arm are shown in c and d
Appendix B. Isolation conditions
Following Stensrud et al. (2021a), we define the \(A_Y\) separable effect on \(Y_k\) as
Likewise, we define the \(A_D\) separable effect on \(Y_k\) as
Next, following Stensrud et al. (2021a), we define two isolation conditions:
Definition 2
A treatment decomposition satisfies strong \(A_Y\) partial isolation if
Definition 3
A treatment decomposition satisfies \(A_D\) partial isolation if
Under strong \(A_Y\) partial isolation, the \(A_Y\) separable effects only capture direct effects of \(A_Y\) on \(Y_k\), i.e. only pathways from \(A_Y\) to \(Y_k\) not intersected by D. Under \(A_D\) partial isolation, the \(A_D\) separable effects only capture indirect effects of \(A_D\) on \(Y_k\), that is only pathways from \(A_D\) to \(Y_k\) that are intersected by D.
If a treatment decomposition satisfies both (54) and (55), it is said to satisfy full isolation. Under full isolation, (52)–(53) are the separable direct and indirect effects on \(Y_k\) respectively. In this case, (52) captures all pathways from A to \(Y_k\) not intersected by D, and (53) captures all pathways from A to \(Y_k\) intersected by D.
Appendix C. Proof of identification results
1.1 C.1. Total effect
Assume the following identification conditions hold for \(k\in \{0,\dots ,K\}\).
Exchangeability

Positivity
Consistency
Next, we use the identification conditions and the law of total probability (LOTP) to add variables sequentially to the conditioning set in temporal order. We have that \(P(\Delta Y_k^{a,\overline{c}=0}=\Delta y_k)\) is given by

The conditional independence relation in the third line follows because \(C_0\equiv 0\) deterministically. Iterating this procedures for time indices \(k^\prime \in \{1,\dots , k\}\) gives
Positivity ensures that the conditioning sets on RHS have a non-zero probability. During the iterative procedure, we have use exchangeability with respect to censoring (13) to add the censoring indicator to the conditioning set. Finally, by consistency we have that
Next, we derive (18). By the presence of the indicator functions in (18) and by consistency (16) we have that
Next, using the law of total expectation, the above is equal to
The numerator and denominator of the fraction in the final line differ only by the time index of \(\overline{Y}^{a,\overline{c}=0}\) in the conditioning set. Using the fact that

(which follows from 13) we have that the fraction is equal to 1, and thus by consistency (16),
Iterating this procedure from \(j=i-1\) to \(j=0\) gives
Using the law of total expectation again, RHS is equal to

Another IPW representation also exists. We have that
Arguing iteratively from \(j=i-1\) to \(j=0\), the RHS is equal to
Putting everything together, we have that
To conclude, we remark that the exchangeability conditions (12)–(13) and identification formulas (17)–(18) follow directly from a general identification result, Theorem 31 of Richardson and Robins (2013b), by choosing outcome \(Y^*_{k}\equiv (Y_{k}, D_{K+1})\), intervention set \(\overline{A}^*_k\equiv (A,C_k)\) for \(k\in \{0,\dots ,K+1\}\) and time-varying covariates \(\overline{L}^*_k\equiv (\overline{L}_k, L)\) for \(k\in \{0,\dots ,K\}\).
1.1.1 C.1.1. Limit of fine discretizations
We begin by noting that \(\Delta Y_k\) in (56) can only be non-zero if the individual has not experienced the competing event by the beginning of time interval \(k-1\). Therefore,
where we have used the laws of probability in the second line. Using Bayes’ law sequentially, we have that
To proceed, we define modified intensities of the recurrent event process
Next, let \(\pi (\bullet )=P(A=\bullet )\) and consider the stabilized weights
The weight \(W_{C,i}\) is a ratio of Kaplan-Meier survival terms with the respect to the censoring event. Let us also define the hazard of the competing event by
Putting everything together, we have that
Expression (57) enables us to establish a correspondence with estimands in the counting process literature, as discussed in Sect. 6.4.2, and also motivates estimators that we described in Sect. 7. The product term in (57) is a survival term with respect to the competing event, and the expectation is over weighted increments of recurrent acute kidney injury. In the limit of fine discretization of time, (57) converges to

1.1.2 C.1.2. Competing event
In order to identify \(E[D_k^{a,\overline{c}=0}]\) from the observed data, we require the following two exchangeability assumptions instead of (12) and (13)


Using analogous arguments as for the recurrent event Y, identification of \(E[D_k^{a,\overline{c}=0}]\) is achieved under (58)–(59) and (14)–(16) by
Likewise, in the limit of fine discretizations of time, the cumulative incidence of the competing event is given by

When treatment A is randomly assigned and (90) holds with \(L(t)= N^c(t)= \emptyset \) (which is the usual independent censoring condition in survival analysis without any covariates (Aalen et al. 2008)), then \(W_A={\mathcal {W}}_{C,t}=1\) and (61) reduces to

This demonstrates sufficient conditions under which the discrete time identification formula given by Expression (29) in Young et al. (2020) converges to the usual representation of the cumulative incidence function in survival analysis.
1.2 C.2. Controlled direct effect
The identification conditions and identification formulas for the controlled direct effect are a special case of the identification results for total effect, redefining the censoring indicator as \(\max (C_i,D_i)\) (i.e. the first occurrence of the competing event and loss to follow-up), and re-defining the competing event as an event that almost surely does not occur. This gives us
Next, we define
to be modified intensities of the competing event process. This allows us to re-write (62) as
where
Under randomization of A and under the strong independent censoring assumption (43), \(W_A=W_{C,i}=W_{D,i}=1\) and thus (63) converges to
in the limit of fine discretizations of time.
1.3 C.3. Separable effects
We begin by assuming the modified treatment assumption (4) and the following identification conditions for all \(a\in \{0,1\}\), \(k\in \{0,\dots ,K+1\}\).
Exchangeability

Positivity
Consistency
Consider a four armed trial where the \(A_Y\) and \(A_D\) are randomly assigned, independently of each other. We require the following dismissible component conditions to hold in the four armed trial

To proceed, we introduce the following lemmas:
Lemma 1
Under a FFRCISTG model, the dismissible component conditions (27)–(30) imply the following equalities for \(a_Y,a_D\in \{0,1\}\)
Proof
We show the equality of Expression (69), as (70)–(72) follow from analogous arguments, using (28)–(30) instead of (27).
The second and fourth line hold by consistency and by randomization of \(A_Y\) and \(A_D\) in the four armed trial. \(\square \)
Lemma 2
Suppose the exchangeability and positivity conditions (24)–(25) and (65)–(67) hold. Define \(\overline{A}=(A_Y,A_D)\) and \(\overline{a}=(a_Y,a_D)\). We then have for all \(j\in \{0,\dots ,K+1\}\) that
Proof
We show the equality for Expression (73), as (74)–(76) follow from analogous arguments, using (28)–(30) instead of (27). We have that
where we have used Bayes’ law in the first line, (24) and (65) in the second line (expression (65) ensures that the conditioning sets have non-zero probability) and the fact that all individuals are uncensored at time \(k=0\) in the third line. Next, using Bayes’ law again, we have that the above is equal to
Using (25), the above is equal to
The conditioning set has non-zero probability by positivity (67). After iterating this procedure, we obtain
Finally, using Bayes law again, the above is equal to
The final result follows because the above equality holds for any choice of \(\Delta \overline{y}_j,\overline{d}_j,\overline{c}_j,\overline{l}_{j-1}, \overline{a}\). \(\square \)
Lemma 3
Suppose that the identification conditions for separable effects (24)–(25), (27)–(30), (65)–(68) and the modified treatment assumption (4) hold. We then have that
The quantities on the LHS are identified in the four armed trial, whereas the quantities on the RHS are identified in the two armed trial.
Proof
We show the equality for (77), as (78)–(80) follow from analogous arguments using (28)–(30) instead of (27). We have that
\(\square \)
To derive the identification formula for separable effects, we proceed by sequential application of Bayes’ theorem
Using Lemma 2 and (68), the above is equal to
The quantities on RHS of (81) are identified in the four armed trial. The final identification formula for separable effects, which is a function of observed quantities in the two armed trial, follows directly from application of Lemma 3, which gives
1.3.1 C.3.1. IPW representation
Next, we will show that
To begin, we use Bayes’ theorem sequentially to write out the joint density
Writing out RHS of (83) as a discrete sum over the density in (84), we have that RHS of (83) is equal to
1.3.2 C.3.2. Limit of fine discretizations
To proceed, we define the weights
and
Using the laws of probability, we may write (83) as
Using analogous arguments where we start from (84) and replace \(\Delta Y_k\) by \(\Delta D_k\), we have that \(E[D_k^{a_Y,a_D,\overline{c}=0}]\) is identified by
As expected, we recover the identification formulas for total effect when choosing \(a_Y=a_D=a\) in (87) and (88).
1.3.3 C.3.3. An alternative IPW representation
Through analogous arguments that we used to derive (83), it follows that
Next, we define the weights
By close analogy with the argument found in Appendix D of Stensrud et al. (2021a), we can re-express the covariate weights as
and
Thus, when the dismissible component conditions holds with \(L_{Y,k}=L_k\) and \(L_{D,k}=\emptyset \), it follows that \(W_{L_{D},k}(a_Y,a_D)=1\). Conversely, when the dismissible component conditions hold with \(L_{D,k}=L_k\) and \(L_{Y,k}=\emptyset \), it follows that \(W_{L_{Y},k}(a_Y,a_D)=1\).
Appendix D. Correspondence of the independent censoring assumption
We begin by introducing the notion of faithfulness, following Spirtes et al. (2000).
Definition 4
A law P is faithful to a causal directed acyclic graph \({\mathcal {G}}\) if for any disjoint set of nodes A, B, C we have that  under P implies
under P implies  , where \((\bullet )_{\mathcal {G}}\) is used to denote graphical d-separation.
, where \((\bullet )_{\mathcal {G}}\) is used to denote graphical d-separation.
In the following result, we establish a correspondence between the exchangeability assumption and the classical independent censoring assumption in event history analysis.
Proposition 1
Let the factual data in Sect. 2 be generated by an FFRCISTG model, and assume consistency (16) and faithfulness (Definition 4) hold. Then, (37) implies exchangeability with respect to censoring (13).
Proof
Expression (37) is equivalent to the statement

Under faithfulness, a violation of (89) is equivalent to the existence of one of the three paths
-
(1)
\(\overline{C}_k \leftarrow U \rightarrow Y_k\)
-
(2)
\(\overline{C}_k \leftarrow U_1 \rightarrow X \leftarrow U_2 \rightarrow Y_k\)
-
(3)
\(\overline{C}_k\rightarrow Y_k\)
for some \(k\in \{1,\dots ,K+1\}\), where \(X\in \{\overline{L}_k,\overline{Y}_{k-1},\overline{D}_k,A\}\). Likewise, the violation of (13) is equivalent to the existence of one of the paths
-
(1’)
\(\overline{C}_k^{a,\overline{c}=0} \leftarrow U \rightarrow Y_k^{a,\overline{c}=0}\)
-
(2’)
\(\overline{C}_k^{a,\overline{c}=0} \leftarrow U_1 \rightarrow X^*\leftarrow U_2 \rightarrow Y_k^{a,\overline{c}=0}\)
for some \(k\in \{1,\dots ,K+1\}\), where \(X^*\in \{\overline{L}_{k-1}^{a,\overline{c}=0},\overline{Y}_{k-1}^{a,\overline{c}=0},\overline{D}_k^{a,\overline{c}=0},A\}\).
By the properties of transforming a DAG into a SWIG (Richardson and Robins 2013a), and by consistency (16), the existence of (1’) implies the existence of (1), and the existence of (2’) implies the existence of (2).Footnote 7 It follows that violation of (13) implies violation of (89), and consequently of (37).
\(\square \)
An analogous relation exists between identification conditions for the competing event. The classical independent censoring assumption for the competing event takes the form
where
A corresponding relation to (90) in discrete time is
Since \(\Delta D_j\in \{0,1\}\), this can be written as
Under faithfulness, exchangeability (59) is implied by (91). The contrast of Expressions (2) and (4) in Robins and Finkelstein (2000) is similar to this correspondence.
Appendix E. Estimation
Theorem 1
Suppose \(P(Z_{t_{K+1}}=1) >0\). We let \(\hat{R}^{(n,i)}\) be as in (51) (originally defined in Ryalen et al. (2019)); an estimator of the weights \(R^i\) based on additive hazard models with finite third moments on the covariates (see Ryalen et al. (2019, Theorem 2)). Suppose \(R^{(n,i)}, R^i\) are uniformly bounded and that the \({\mathcal {F}}^{N,N^D,L,A}\)-intensity of \(N^i\) satisfies \(E[\int _0^{t_{K+1}}\lambda _s ds]<\infty \). Then,
-
the estimator defined by (48)–(49) are consistent and predictably uniformly tight (P-UT).
-
the estimator defined by the system (47) is consistent.
Proof
We show the result for the integrators in (48); the result for (49) follows by similar arguments. Assume first that \(R^i, R^{(n,i)}\) are orthogonal to \(N^i\). Define \(X^{(n)} = \frac{1}{n} \sum _{i=1}^n R^{(n,i)} N^i, Y^{(n)} = \frac{n}{\sum _{j=1}^n Z^j}\). Then, Ryalen et al. (2019, Lemma 2) and the law of large numbers imply that \(X^{(n)}\) converges to \(E[ R^i N^i ] = E[\int R_{s-}^i dN_s^i]\). \(Y^{(n)}\) converges to \(1/E[Z^1]\) by the law of large numbers. Furthermore,
is PUT (see Jacod and Shiryaev (2003, VI, 6.6.a)), as it is a sum of two processes that are P-UT. The first term is P-UT from Ryalen et al. (2019, Proposition 1). The latter term is P-UT because \(R^{(n,i)}\) is driven by a P-UT process \(K^{(n,i)}\) (see Ryalen et al. (2019)) and \(N_{-}^i\) is predictable, by Jacod and Shiryaev (2003, Corollary VI.6.20). The estimator of interest is \( \int _0^\cdot Y^{(n)}_{s-} d{\tilde{X}}^{(n)}_s\), where \({\tilde{X}}^{(n)} = X^{(n)}- \frac{1}{n}\sum _{i=1}^n \int _0^t N_{s-}^i dR_{s}^{(n,i)}\). Now, the last term on the right hand side has the following decomposition:
By Ryalen et al. (2019, Lemma 2), the first term on the right hand side converges to zero, while the third term converges to zero by the law of large numbers as it is a mean zero martingale. Finally,
The first term on the right hand side converges to zero by the law of large numbers, while the second term converges to zero by dominated convergence, as \(R^{(n,i)}_t - R_t^i\) converges in probability to zero for each t.
Thus, \({\tilde{X}}^{(n)}\) and \(X^{(n)}\) converge to the same limit. Because \(E[Z^1]\) is continuous, Jacod and Shiryaev (2003, Corollary VI 3.33) implies that \(({\tilde{X}}^{(n)}, Y^{(n)})\) converges weakly (with respect to the Skorohod metric), and Jacod and Shiryaev (2003, Theorem VI 6.22) implies that also \( \int _0^\cdot Y_{s-}^{(n)} d{\tilde{X}}_s^{(n)} \) converges weakly to the deterministic limit \(\int _0^\cdot E[R_s^1 dN_s^1| Z_s^1 > 0]\).
If \(N^i\) is not orthogonal to \(R^i\) and \(R^{(n,i)}\), we have
and likewise
where the last term on the right-hand side can be neglected. We can then build on the argument above, replacing \(R^i\) and \(R^{(n,i)}\) with \(\theta ^i R^i\) and \(\hat{\theta }^{i} R^{(n,i)}\) when necessary, to show the convergence.
The consistency of (47) follows from Ryalen et al. (2018, Theorem 1) because \(\int _0^{\cdot } Y_{s-}^{(n)} d{\tilde{X}}_s^{(n)}\) is consistent and P-UT. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Janvin, M., Young, J.G., Ryalen, P.C. et al. Causal inference with recurrent and competing events. Lifetime Data Anal 30, 59–118 (2024). https://doi.org/10.1007/s10985-023-09594-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10985-023-09594-8