
Abstract
While subjective well-being generally decreased in Europe during the Great Recession, some countries fared better than others. We assess how this experience varied across population subgroups and countries according to their labor market policies, specifically two types of unemployment support policies and employment protection legislation. We find both types of unemployment support, income replacement and active labor market policy (which assists the unemployed to find jobs), reduced the negative effects for most of the population (except youth); however, income replacement performed better, reducing the impacts of the Recession to a greater degree. In contrast, stricter employment protection legislation exacerbated the negative effects. This finding may be explained with suggestive evidence that indicates: legislation limiting the dismissal of employees curbed increases in unemployment but this benefit was more than offset, plausibly by perceptions of increased employment insecurity; and legislation limiting the use of temporary contracts may have exacerbated increases in unemployment. Our analysis is based on two-stage least squares regressions using individual subjective well-being data from Eurobarometer surveys and variation in labor market policy across 23 European countries.




Similar content being viewed by others
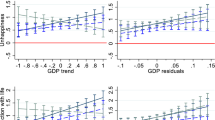

Notes
The term “subjective well-being” is used in this paper to refer to either self-reported measures of life satisfaction or evaluative happiness because both measures typically correlate with the same explanatory variables (Helliwell and Wang 2012), however, in psychology there is an open discussion regarding the relation between the two concepts (e.g., Gamble and Gärling 2012).
We apply post-stratification weights when performing regressions. Provided by Eurobarometer, the weights adjust the sample to be representative of the national population along the dimensions: gender, age, and region.
Omitting Netherlands causes the estimated effects of ALMP to increase; however, the change is not generally statistically significant.
References
Anderson, C. J., & Pontusson, J. (2007). Workers, worries and welfare states: Social protection and job insecurity in 15 OECD countries. European Journal of Political Research, 46(2), 211–235. https://doi.org/10.1111/j.1475-6765.2007.00692.x
Arampatzi, E., Burger, M. J., Ianchovichina, E., Röhricht, T., & Veenhoven, R. (2018). Unhappy development: dissatisfaction with life on the eve of the Arab Spring. Review of Income and Wealth, 64(S1), S80–S113. https://doi.org/10.1111/roiw.12388
Arampatzi, E., Burger, M. J., Stavropoulos, S., & van Oort, F. G. (2019). Subjective well-being and the 2008 recession in European Regions : The moderating role of quality of governance subjective well-Being. International Journal of Community Well-Being, (April). doi:https://doi.org/10.1007/s42413-019-00022-0
Arampatzi, E., Burger, M. J., & Veenhoven, R. (2015). Financial distress and happiness of employees in times of economic crisis. Applied Economics Letters, 22(3), 173–179. https://doi.org/10.1080/13504851.2014.931916
Avdagic, S. (2015). Does Deregulation Work? Reassessing the Unemployment Effects of Employment Protection. British Journal of Industrial Relations, 53(1), 6–26. https://doi.org/10.1111/bjir.12086
Baum, C. F., Lewbel, A., Schaffer, M. E., & Talavera, O. (2013). Instrumental variables estimation using heteroskedasticity-based instruments. Stata Users Group. https://econpapers.repec.org/RePEc:boc:dsug13:05
Baum, C. F., & Schaffer, M. E. (2012). IVREG2H: Stata module to perform instrumental variables estimation using heteroskedasticity-based instruments. Boston College Department of Economics. https://econpapers.repec.org/RePEc:boc:bocode:s457555
Bell, D. N. F., & Blanchflower, D. G. (2011). Young people and the great recession. Oxford Review of Economic Policy, 27(2), 241–267. https://doi.org/10.1093/oxrep/grr011
Bertrand, M., Duflo, E., & Mullainathan, S. (2004). How much should we trust differences-in-differences estimates? Quarterly Journal of Economics, 119(1), 249–275
Bjørnskov, C. (2014). Do economic reforms alleviate subjective well-being losses of economic crises? Journal of Happiness Studies, 15(1), 163–182. https://doi.org/10.1007/s10902-013-9442-y
Boarini, R., Comola, M., de Keulenaer, F., Manchin, R., & Smith, C. (2013). Can Governments Boost People’s Sense of Well-Being? The impact of selected labour market and health policies on life satisfaction. Social Indicators Research, 114(1), 105–120. https://doi.org/10.1007/s11205-013-0386-8
Böckerman, P., Ilmakunnas, P., & Johansson, E. (2011). Job security and employee well-being: Evidence from matched survey and register data. Labour Economics, 18(4), 547–554. https://doi.org/10.1016/j.labeco.2010.12.011
Bond, T. N., & Lang, K. (2019). The sad truth about happiness scales. Journal of Political Economy, 127(4), 1629–1640. https://doi.org/10.1086/701679
Botero, J. C., Djankov, S., Porta, R. L., Lopez-de-Silanes, F., & Shleifer, A. (2004). The regulation of labor. Quarterly Journal of Economics, 119(4), 1339–1382. https://doi.org/10.1162/0033553042476215
Cameron, A. C., & Miller, D. L. (2015). A Practitioner’s guide to cluster-robust inference. Journal of Human Resources, 50(2), 317–372. https://doi.org/10.3368/jhr.50.2.317
Cantril, H. (1965). The pattern of human concerns. Rutgers University Press.
Carr, E., & Chung, H. (2014). Job insecurity and life satisfaction : The moderating influence of labour market policies across Europe. Journal of European Social Policy, 24(4), 383–399. https://doi.org/10.1177/0958928714538219
Chen, L., Oparina, E., Powdthavee, N., & Srisuma, S. (2019). Have Econometric Analyses of Happiness Data Been Futile? A Simple Truth about Happiness Scales (IZA Discussion Paper No. 12152).
Clark, A. E. (2018). Four decades of the economics of happiness: Where next? Review of Income and Wealth, 64(2), 245–269. https://doi.org/10.1111/roiw.12369
Clark, A. E., Diener, E., Georgellis, Y., & Lucas, R. E. (2008). Lags and leads in life satisfaction : A test of the baseline hypothesis. Economic Journal, 118(529), F222–F243
Clark, A. E., Georgellis, Y., & Sanfey, P. (2001). Scarring: The psychological impact of past unemployment. Economica, 68(270), 221–241. https://doi.org/10.1111/1468-0335.00243
Clark, A. E., & Postel-Vinay, F. (2009). Job security and job protection. Oxford Economic Papers, 61, 207–239. https://doi.org/10.1093/oep/gpn017
Davidson, R., & Mackinnon, J. G. (2010). Wild Bootstrap Tests for IV Regression. Journal of Business and Economics Statistics, 28(1), 128–144. https://doi.org/10.1198/jbes.2009.07221
de Bustillo, R. M., & de Pedraza, P. (2010). Determinants of job insecurity in five European countries. European Journal of Industrial Relations, 16(1), 5–20. https://doi.org/10.1177/0959680109355306
De Neve, J.-E., Ward, G., De Keulenaer, F., Van Landeghem, B., Kavetsos, G., & Norton, M. I. (2018). The asymmetric experience of positive and negative economic growth: Global evidence using subjective well-being data. Review of Economics and Statistics. https://doi.org/10.1162/REST_a_00697
de Pedraza, P., Guzi, M., & Tijdens, K. (2020). Life satisfaction of employees, labour market tightness and matching efficiency. International Journal of Manpower. https://doi.org/10.1108/IJM-07-2019-0323
de Pedraza, P., Tijdens, K., & Visintin, S. (2018). The matching process before and after the crisis in the Netherlands. International Journal of Manpower, 39(8), 1010–1031. https://doi.org/10.1108/IJM-10-2018-0329
de Pedraza, P., Álvarez-Díaz, M., & Domínguez-Torreiro, M. (2019). Sympathy for the devil? Exploring flexicurity win-win promises. IZA Journal of Labor Policy, 9(1), 1–26. https://doi.org/10.2478/izajolp-2019-0009
Denny, K., & Oppedisano, V. (2013). The surprising effect of larger class sizes: Evidence using two identification strategies. Labour Economics, 23, 57–65
Di Tella, R., MacCulloch, R. J., & Oswald, A. J. (2003). The Macroeconomics of happiness. The Review of Economics and Statistics, 85(4), 809–827. https://doi.org/10.1162/003465303772815745
Dickerson, A., & Green, F. (2012). Fears and realisations of employment insecurity. Labour Economics, 19(2), 198–210. https://doi.org/10.1016/j.labeco.2011.10.001
Easterlin, R. A. (2013). Happiness, growth, and public policy. Economic Inquiry, 51(1), 1–15. https://doi.org/10.1111/j.1465-7295.2012.00505.x
European Commission. (2006). Employment in Europe 2006. Employment in Europe 2006. Luxembourg: European Communities. http://ec.europa.eu/employment_social/employment_analysis/eie/eie2006_summary_en.pdf
European Commission. (2007). Eurobarometer 68.1: ZA4565 data file version 4.0.1. Cologne: TNS Opinion & Social, Brussels. doi:https://doi.org/10.4232/1.10988
European Commission. (2009). Eurobarometer 71.3: ZA4973 data file version 3.0.0. Cologne: TNS Opinion & Social, Brussels. doi:https://doi.org/10.4232/1.11135
Feldmann, H. (2009). The unemployment effects of labor regulation around the world. Journal of Comparative Economics, 37, 76–90. https://doi.org/10.1016/j.jce.2008.10.001
Ferrer-i-Carbonell, A., & Frijters, P. (2004). How Important is Methodology for the Estimate of the Determinants of Hapiness? The Economic Journal, 114(497), 641–659
Frijters, P., Clark, A. E., Krekel, C., & Layard, R. (2020). A happy choice: Wellbeing as the goal of government. Behavioural Public Policy, pp. 1–40. https://doi.org/10.1017/bpp.2019.39
Fujita, S., & Ramey, G. (2009). The cyclicality of the separation and job finding rates in France. International Economic Review, 50(2), 415–430. https://doi.org/10.1016/j.euroecorev.2015.01.013
Gamble, A., & Gärling, T. (2012). The relationships between life satisfaction, happiness, and current mood. Journal of Happiness Studies, 13(1), 31–45. https://doi.org/10.1007/s10902-011-9248-8
Gonza, G., & Burger, A. (2017). subjective well-being during the 2008 economic crisis: Identification of mediating and moderating factors. Journal of Happiness Studies, 18, 1763–1797. https://doi.org/10.1007/s10902-016-9797-y
Graham, C., Laffan, K., & Pinto, S. (2018). Well-being in metrics and policy. Science, 362(6412), 287–288. https://doi.org/10.1126/science.aau5234
Green, F. (2009). Subjective employment inesurity around the world. Cambridge Journal of Regions, Economy and Society, 2(3), 343–363. https://doi.org/10.1093/cjres/rsp003
Green, F., Felstead, A., & Burchell, B. (2000). Job insecurity and the difficulty of regaining employment: An empirical study of unemployment expectations. Oxford Bulletin of Economics and Statistics, 62, 855–883. https://doi.org/10.1111/1468-0084.0620s1855.
Helliwell, J. F. (2019). Measuring and using happiness to support public policies (NBER Working Paper No. 26529). https://doi.org/10.3386/w26529.
Helliwell, J. F., & Huang, H. (2014). New measures of the costs of unemployment: Evidence from the subjective well-being of 3.3 million americans. Economic Inquiry, 52(4), 1485–1502. https://doi.org/10.1111/ecin.12093
Helliwell, J. F., & Wang, S. (2012). The state of world happiness. In J. F. Helliwell, R. Layard, & J. Sachs (Eds.), World Happiness Report (pp. 10–57). UN Sustainable Development Solutions Network.
Hessami, Z. (2010). The size and composition of government spending in Europe and its impact on well-being. Kyklos, 63(3), 346–382. https://doi.org/10.1111/j.1467-6435.2010.00478.x
Kahneman, D., Krueger, A. B., Schkade, D., Schwarz, N., & Stone, A. A. (2004). Toward national well-being accounts. American Economic Review, 94(2), 429–434
Kaiser, C., & Vendrik, M. C. M. (2019). How threatening are transformations of reported happiness to subjective wellbeing research? SocArXiv. July 19. https://doi.org/10.31235/osf.io/gzt7a.
Karabchuk, T., & Soboleva, N. (2019). Temporary employment, informal work and subjective well—being across Europe: Does labor legislation matter? Journal of Happiness Studies. https://doi.org/10.1007/s10902-019-00152-4
Kim, M.-H., & Do, Y. K. (2013). Effect of husbands’ employment status on their wives’ subjective well-being in Korea. Journal of Marriage and Family, 75(April), 288–299. https://doi.org/10.1111/jomf.12004
Le Moglie, M., Mencarini, L., & Rapallini, C. (2015). Is it just a matter of personality? On the role of subjective well-being in childbearing behavior. Journal of Economic Behavior and Organization, 117, 453–475. https://doi.org/10.1016/j.jebo.2015.07.006
Lewbel, A. (2012). Using heteroscedasticity to identify and estimate mismeasured and endogenous regressor models. Journal of Business and Economics Statistics, 30(1), 67–80. https://doi.org/10.1080/07350015.2012.643126
Lucas, R. E. (1991). Models of business cycles. London: Wiley-Blackwell.
Luechinger, S., Meier, S., & Stutzer, A. (2010). Why does unemployment hurt the employed?: Evidence from the life satisfaction gap between the public and the private sector. Journal of Human Resources, 45(4), 998–1045. https://doi.org/10.3368/jhr.45.4.998
Madsen, P. K. (2002). The Danish model of flexicurity: A paradise—with some snakes. In H. Sarfati & G. Bonoli (Eds.), Labour market and social protection reforms in international perspective (pp. 243–265). London: Ashgate Publishing. doi:https://doi.org/10.4324/9781315251004-14
Matysiak, A., Sobotka, T., & Vignoli, D. (2020). The great recession and fertility in Europe: A sub-national analysis. European Journal of Population. Springer Netherlands. doi:https://doi.org/10.1007/s10680-020-09556-y
Montagnoli, A., & Moro, M. (2018). the cost of banking crises : New evidence from life satisfaction data. Kyklos, 71(2), 279–309. https://doi.org/10.1111/kykl.12170
Ng, Y.-K. (1997). A case for happiness, cardinalism, and interpersonal comparability. Economic Journal, 107, 1848–1858
O’Connor, K. J. (2017a). Who suffered most from the great recession? Happiness in the United States. RSF: The Russell Sage Foundation Journal of the Social Sciences. doi:https://doi.org/10.7758/RSF.2017.3.3.04
O’Connor, K. J. (2017). Happiness and welfare state policy around the world. Review of Behavioral Economics, 4(4), 397–420. https://doi.org/10.1561/105.00000071
O’Connor, K. J. (2020). Life satisfaction and noncognitive skills: Effects on the likelihood of unemployment. Kyklos, 73, 568–604. https://doi.org/10.1111/kykl.12226
O’Connor, K. J., & Graham, C. (2019). Longer, more optimistic, lives: Historic optimism and life expectancy in the United States. Journal of Economic Behavior and Organization, 168, 374–392. https://doi.org/10.1016/j.jebo.2019.10.018
Ochsen, C., & Welsch, H. . (2012). Who benefits from labor market institutions? Evidence from surveys of life satisfaction. Journal of Economic Psychology, 33, 112–124. https://doi.org/10.1016/j.joep.2011.08.007
OECD 2014a. OECD StatExtracts. Quarterly Data. http://stats.oecd.org. Access date: May 2014.
OECD 2014b. Directorate for Employment, Labour and Social Affairs, Benefits and Wages: Statistics. http://www.oecd.org/els/benefitsandwagesstatistics.htm. Access date: January 2013.
OECD 2014c. Dataset: Public expenditure and participant stocks on LMP. Public expenditure as a percentage of GDP (Annual). http://stats.oecd.org. Access date: April 2013.
OECD 2014d. OECD Indicators of Employment Protection. http://www.oecd.org/employment/emp/oecdindicatorsofemploymentprotection.htm. Access date: May 2014.
Ono, H., & Lee, K. S. (2013). Welfare states and the redistribution of happiness. Social Forces, 92(2), 789–814. https://doi.org/10.1093/sf/sot094
Origo, F., & Pagani, L. (2009). Flexicurity and job satisfaction in Europe: The importance of perceived and actual job stability for well-being at work. Labour Economics, 16(5), 547–555. https://doi.org/10.1016/j.labeco.2009.02.003
Pacek, A. C., & Radcliff, B. (2008). Welfare policy and subjective well-being across nations: An individual-level assessment. Social Indicators Research, 89(1), 179–191. https://doi.org/10.1007/s11205-007-9232-1
Romer, D. (1996). Advanced Macroeconomics. New York: McGraw Hill.
Roodman, D., MacKinnon, J., Nielsen, M. Ø., & Webb, M. D. (2018). Fast and wild: Bootstrap inference in stata using boottest (Queen's Economics Department Working Paper No. 1406).
Rothstein, B. (2010). Happiness and the welfare state. Social Research, 77(2), 441–469. https://doi.org/10.2307/40972225
Sage, D. (2015). Do active labour market policies promote the subjective well-being of the unemployed? Evidence from the UK national well-being programme. Journal of Happiness Studies, 16, 1281–1298. https://doi.org/10.1007/s10902-014-9549-9
Sarracino, F., & Fumarco, L. (2018). Assessing the Non-financial Outcomes of Social Enterprises in Luxembourg. Journal of Business Ethics. https://doi.org/10.1007/s10551-018-4086-9
Sarracino, F., & Piekalkiewicz, M. (2021). The role of income and social capital for Europeans’ well-being during the 2008 economic crisis. Journal of Happiness Studies, 22, 1583–1610. https://doi.org/10.1007/s10902-020-00285-x.
Scherer, S. (2009). The social consequences of insecure jobs. Social Indicators Research, 93, 527–547. https://doi.org/10.1007/s11205-008-9431-4
Schröder, C., & Yitzhaki, S. (2017). Revisiting the evidence for cardinal treatment of ordinal variables. European Economic Review, 92(January), 337–358. https://doi.org/10.1016/j.euroecorev.2016.12.011
Sechel, C. (2019). Happier Than Them , but More of Them Are Happy: Aggregating Subjective Well-Being (Sheffield Economic Research Paper Series No. 2019008).
Shimer, R. (2005). The cyclical behavior of equilibrium unemployment and vacancies. American Economic Review, 95(1), 25–49. https://doi.org/10.1016/j.euroecorev.2015.09.002
Shimer, R. (2012). Reassessing the ins and outs of unemployment. Review of Economic Dynamics, 15(2), 127–148. https://doi.org/10.1016/j.red.2012.02.001
Silla, I., de Cuyper, N., Gracia, F. J., Peiró, J. M., & de Witte, H. (2009). Job insecurity and well-being: Moderation by employability. Journal of Happiness Studies, 10(6), 739–751. https://doi.org/10.1007/s10902-008-9119-0
Council, T. G. H. (2018). Global Happiness Policy Report 2018. New York: Sustainable Development Solutions Network. happinesscouncil.org.
Uusitalo, R., & Verho, J. (2010). The effect of unemployment benefits on re-employment rates: Evidence from the Finnish unemployment insurance reform. Labour Economics, 17(4), 643–654. https://doi.org/10.1016/j.labeco.2010.02.002
Veenhoven, R. (2000). Well-being in the welfare state: Level not higher, distribution not more equitable. Journal of Comparative Policy Analysis: Research and Practice, 2(1), 91–125. https://doi.org/10.1080/13876980008412637
Vergeer, R., & Kleinknecht, A. (2012). Do flexible labor markets indeed reduce unemployment? A robustness check. Review of Social Economy, 70(4), 451–467. https://doi.org/10.1080/00346764.2012.681113
Winkelmann, L., & Winkelmann, R. (1998). Why are the unemployed so unhappy? Evidence from panel data. Economica, 65(257), 1–15. https://doi.org/10.1111/1468-0335.00111
Wolfers, J. (2003). Is Business cycle volatility costly? Evidence from surveys of subjective well-being. International Finance, 6(1), 1–26. https://doi.org/10.1111/1468-2362.00112
Wulfgramm, M. (2014). Life satisfaction effects of unemployment in Europe: The moderating influence of labour market policy. Journal of European Social Policy, 24(3), 258–272. https://doi.org/10.1177/0958928714525817
Acknowledgements
The authors would like to thank two anonymous referees, Stefano Bartolini, Andrew Clark, Richard A. Easterlin, Francesco Sarracino, Claudia Senik, and the participants at numerous seminars and conferences for helpful comments. Morgan acknowledges financial support from Minerva and the University of Southern California. O’Connor acknowledge financial support of the Observatoire de la Compétitivité, Ministère de l’Economie, DG Compétitivité, Luxembourg, and STATEC. Views and opinions expressed in this article are those of the authors and do not reflect those of Minerva, the University of Southern California, STATEC, or funding partners. Conflict of Interest: The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Assessing Instrument Validity Using Overidentification Tests
The overidentification tests are conducted based on the main analysis using additional instruments, which were generated using the Lewbel (2012) method. The Lewbel (2012) method uses heteroskedasticity in the data and higher order restrictions to generate instruments without introducing external data. While somewhat new, it has been used numerous times now: Lewbel (2012) documents papers as early as 2007, and more recently by (Arampatzi et al. 2018; Denny & Oppedisano, 2013; Le Moglie et al. 2015; O’Connor, 2020; O’Connor & Graham, 2019; Sarracino & Fumarco, 2018).
Using the Lewbel (2012) method, we generate the instruments as follows: (1) run a regression of our endogenous variable, \({group}_{g} X {trough}_{t} X {policy}_{j}\), on the other covariates from Eq. 1 and store the residuals (\({\mu }_{igjt}\)), (2) de-mean the covariates and multiply them by the stored residuals. For example, instrument \({Z}_{igjt}^{*}=\left({Z}_{igjt}-\overline{{Z }_{gjt}}\right)* {\mu }_{igjt}\), where \({Z}_{igjt}\) is any subset of the covariates and \({\mu }_{igjt}\) are the stored residuals. Beyond the standard assumption (all of the covariates are exogenous), the method relies on two key conditions. First, heteroskedasticity, which can be tested using the standard Breusch-Pagan test. The second condition is untestable and relies on an assumption. Specifically, the residual from the first step above (\({\mu }_{igjt}\)) multiplied by the second stage residual of life satisfaction (\({\varepsilon }_{igjt}\)) must be unrelated to the covariates used to generate instruments, formally: \(cov\left({Z}_{igjt},{\varepsilon }_{igjt}*{\mu }_{igjt}\right)=0\). For Z, we only use gender. Gender is chosen as the only additional variable because we only need one additional variable per endogenous variable to test the overidentification restrictions and gender is exogenously determined. Indeed, introducing additional excludable instruments would weaken any findings that suggest peak policy is excludable. Overidentification tests apply to the full set of excluded instruments, and peak policy forms a smaller proportion of the set with more excluded instruments. We use gender instead of age because age is used as one of the groups of interest. In this way, we generate three additional excluded instruments for each 2SLS regression, one for each endogenous variable (policy by group). For a further description of the approach, see Baum et al. (2013) and Lewbel (2012). The user written command ivreg2h (Baum & Schaffer, 2012) can be used to generate the instruments in STATA.
We had to make two further adjustments to the main analysis in order to run the Hansen J overidentification test. First, because the number of clusters (countries) is too small for the Hansen test, we clustered at the country-period level to double the number of clusters. However, the clustered standard errors were quite similar in both cases, providing some reassurance that the change does not affect the overidentification test. Second, we partialed out the country fixed effects (dummies) to reduce the number of variables.
Table 6 presents the results using the Lewbel generated instruments. They read the same as in Tables 1 and 2, with the addition of the Hansen J p-value, which reports the overidentification test results. As noted in the main text, the overidentification tests support the validity of our instruments. We fail to reject that the instruments are valid across each column. What is more, the coefficient estimates are nearly identical to the main results, consistent with expectations. We expected the coefficients to be similar because in the main analysis our instrument, peak policy, strongly predicts trough policy. This strength means that adding additional instruments should not greatly affect the first and second stage results. Across Tables 1 and 2, the lowest F-stat was nearly 24, more than double the often-used cut off value of 10 for weak instruments.
1.2 Ordinal Treatment of Life Satisfaction
Life satisfaction is inherently ordinal, yet the main analysis treats it cardinally. More generally, there are a few papers which critique inference based on subjective well-being, stating limitations based on the way it is reported or assumptions necessary to operationalize it (e.g., Bond & Lang, 2019; Schröder & Yitzhaki, 2017). Relatively early work has addressed the ordinal versus cardinal treatment of subjective well-being. For instance, Ng (1997) argues subjective well-being should conceptually be treated as cardinal, and Ferrer-i-Carbonell and Frijters (2004) find little difference between estimates when using cardinal versus ordinal models. However, the debate continues today, recently with responses to Bond and Lang (2019) and Schröder and Yitzhaki (2017) such as Chen et al. (2019) and Kaiser and Vendrik (2019). Cardinal treatment is often preferred because ordinal treatment has some limitations, for instance individual fixed effects are not possible in standard ordered choice models and instrumental variable methods would require using different models for each stage (linear and nonlinear). To address these issues, practitioners sometimes use both methods.
As mentioned in Sect. 5.3, we use two additional analyses that treat life satisfaction ordinally, ordered probit and linear probability. For the ordered probit model, we do not use an instrumental variable approach because we prefer to maintain the same treatment, linear or nonlinear, for each stage. To conduct the linear probability model, we compress life satisfaction into a binary outcome, coded: 1 if the respondent responds in the top two categories, very or fairly satisfied; and 0 if they respond not very or not at all satisfied. This variable has an intuitive description, the probability that someone is more satisfied than not. See Sechel (2019) for a description of how this approach addresses measurement issues in subjective well-being (e.g., Bond & Lang, 2019). Given both stages are linear, we use instrumental variables like the main analysis.
The results are presented in Table 7. For each policy variable there are two columns, one for each method. Two panels present the results separately by education and cohort. The estimates are consistent in significance and direction (magnitudes are not directly comparable) with the main results, with two exceptions. For ALMP, two estimates according to the linear probability model are inconsistent; the most important change is for those with at least college education. Indeed, the effect changed direction. While the ordered probit and the results by cohort using both models are consistent, this change should be considered when interpreting the impacts of ALMP. For EPL, the estimate for the high school group was statistically significant but is no longer when using the linear probability model. This change does not pose much of a limitation however. It may be due to lower variability in the binary measure of life satisfaction, and the other estimates are consistent with the main results.
1.3 Nonlinear Specification of Job Situation Worse
According to theory, Job Situation Worse should be specified using a nonlinear model because it is a binary variable. To test the sensitivity of our two-stage least squares estimates, performed in Table 4, we replicate the analysis instead using a probit model. However, once again the nonlinear model precludes the use of two-stage least squares, meaning the relations should not be interpreted as causal. Nonetheless, the results are solely intended to supplement Table 4, and the analysis in which is free from many concerns; it is only limited in the linear treatment of Job Situation Worse.
The results presented in Table 8 are qualitatively similar to those of Table 4. With stricter employment protection, the at least college and eldest age groups perceive statistically significantly worse job situations, while the other groups do not. There are some differences between EPL and EPL-T however. In Table 4, EPL affects both groups (at least college and eldest) while EPL-T does not affect either. Here EPL does not affect the eldest age group and EPL-T affects both groups.
Rights and permissions
About this article

Cite this article
Morgan, R., O’Connor, K.J. Labor Market Policy and Subjective Well-Being During the Great Recession. J Happiness Stud 23, 391–422 (2022). https://doi.org/10.1007/s10902-021-00403-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10902-021-00403-3