
Abstract
In this paper, we generalize two criteria, the determinant-based and trace-based criteria proposed by Saranadasa (J Multivar Anal 46:154–174, 1993), to general populations for high dimensional classification. These two criteria compare some distances between a new observation and several different known groups. The determinant-based criterion performs well for correlated variables by integrating the covariance structure and is competitive to many other existing rules. The criterion however requires the measurement dimension be smaller than the sample size. The trace-based criterion, in contrast, is an independence rule and effective in the “large dimension-small sample size” scenario. An appealing property of these two criteria is that their implementation is straightforward and there is no need for preliminary variable selection or use of turning parameters. Their asymptotic misclassification probabilities are derived using the theory of large dimensional random matrices. Their competitive performances are illustrated by intensive Monte Carlo experiments and a real data analysis.





Similar content being viewed by others

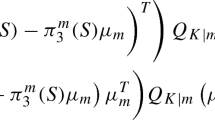

References
Bai Z, Liu H, Wong WK (2009) Enhancement of the applicability of Markowitz’s portfolio optimization by utilizing random matrix theory. Math Financ 19:639–667
Bai Z, Saranadasa H (1996) Effect of high dimension: by an example of a two sample problem. Stat Sin 6:311–329
Bai Z, Silverstein W (2010) Spectral analysis of large dimensional random matrices. Science Press, Beijing
Bickel P, Levina E (2004) Some theory for Fisher’s linear discriminant function ‘naive Bayes’, and some alternatives when there are many more variables than observations. Bernoulli 10:989–1010
Chen SX, Zhang LX, Zhong PS (2010) Tests for high dimensional covariance matrices. J Am Stat Assoc 105:810–819
Cheng Y (2004) Asymptotic probabilities of misclassification of two discriminant functions in cases of high dimensional data. Stat Probab Lett 67:9–17
Fan J, Fan Y (2008) High dimensional classification using features annealed independence rules. Ann Stat 36:2605–2637
Fan J, Feng Y, Tong X (2012) A road to classification in high dimensional space: the regularized optimal affine discriminant. J R Stat Soc Series B 74:745–771
Fisher RA (1936) The use of multiple measurements in taxonomic problems. Ann Eugen 7:179–188
Guo Y, Hastie T, Tibshirani R (2005) Regularized discriminant analysis and its application in microarrays. Biostatistics 1:1–18. R. package downloadable at http://cran.r-project.org/web/packages/ascrda/
Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, Coller H, Loh ML, Downing JR, Caligiuri MA, Bloomfield CD, Lander ES (1999) Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science 286:531–537
Lange T, Mosler K, Mozharovskyi P (2014) Fast nonparametric classification based on data depth. Stat Pap 55:49–69
Leung CY (2001) Error rates in classification consisting of discrete and continuous variables in the presence of covariates. Stat Pap 42:265–273
Li J, Chen SX (2012) Two sample tests for high dimensional covariance matrices. Ann Stat 40:908–940
Krzyśko M, Skorzybut M (2009) Discriminant analysis of multivariate repeated measures data with a Kronecker product structured covariance matrices. Stat Pap 50:817–835
Saranadasa H (1993) Asymptotic expansion of the misclassification probabilities of D- and A-criteria for discrimination from two high dimensional populations using the theory of large dimensional random matrices. J Multivar Anal 46:154–174
Shao J, Wang Y, Deng X, Wang S (2011) Sparse linear discriminant analysis by thresholding for high dimensional data. Ann Stat 39:1241–1265
Srivastava MS, Kollo T, Rosen D (2011) Some tests for the covariance matrix with fewer observations than the dimension under non-normality. J Multivar Anal 102:1090–1103
Tibshirani R, Hastie T, Narasimhan B, Chu G (2002) Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proc Natl Acad Sci USA 99:6567–6572
Vapnik VN (1995) The nature of statistical learning theory. Springer, New York
Acknowledgments
Jianfeng Yao is partly supported by the GRF Grant HKU 705413P.
Author information
Authors and Affiliations
Corresponding author
Appendix Technical proofs
Appendix Technical proofs
1.1 Proof of Theorem 1
We first recall two known results on the Marčenko-Pastur distribution, which can be found in Theorem 3.10 in Bai and Silverstein (2010) and Lemma 3.1 in Bai et al. (2009).
Lemma 1
Assume \(p/n\rightarrow y\in (0,1)\) as \(n\rightarrow \infty \), for the sample covariance matrix \(\tilde{\mathbf {S}}= \tilde{\mathbf {A}}/n\), we have the following results
-
(1)
$$\begin{aligned} \frac{1}{p}tr(\tilde{\mathbf {S}}^{-1}) \mathop {\longrightarrow }\limits ^{a.s.} a_1, \quad \frac{1}{p}tr(\tilde{\mathbf {S}}^{-2}) \mathop {\longrightarrow }\limits ^{a.s.} a_2, \end{aligned}$$
where \(a_1=\frac{1}{1-y}\) and \(a_2=\frac{1}{(1-y)^3}\);
-
(2)
Moreover,
$$\begin{aligned} \bar{\mathbf {x}}^{*\prime }\tilde{\mathbf {S}}^{-i} \bar{\mathbf {x}}^*\mathop {\longrightarrow }\limits ^{a.s.} a_i,\quad \bar{\mathbf {y}}^{*\prime }\tilde{\mathbf {S}}^{-i} \bar{\mathbf {y}}^*\mathop {\longrightarrow }\limits ^{a.s.} a_i, i=1, 2. \end{aligned}$$
Under the data-generation models (a) and (b), let \(\Omega =(\tilde{\mathbf {A}}, \bar{\mathbf {x}}^*, \bar{\mathbf {y}}^*)\). Conditioned on \(\Omega \), the misclassification probability (7) can be rewritten as
where
Therefore, \(\displaystyle P_\Omega (2|1) =P_\Omega \left( K >0 \right) \) where \(\mathbf {z}\in \Pi _1\) is assumed implicitly.
We evaluate the first two conditional moments of \(K\).
Lemma 2
Let \(\tilde{\mathbf {A}}^{-1}=(b_{ll^\prime })_{l,l^\prime =1, \ldots , p}\). We have
-
(1)
$$\begin{aligned} M_p&= E (K|\Omega )\nonumber \\&= (\alpha _1 -\alpha _2) \text {tr} (\tilde{\mathbf {A}}^{-1}) + \alpha _1 \bar{\mathbf {x}}^{*\prime } \tilde{\mathbf {A}}^{-1}\bar{\mathbf {x}}^*\nonumber \\&-\, \alpha _2 (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }})^\prime \tilde{\mathbf {A}}^{-1} (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }}); \end{aligned}$$(12)
-
(2)
$$\begin{aligned} B_p^2&= Var(K|\Omega ) \nonumber \\&= (\alpha _1 -\alpha _2)^2 (\gamma _x -3) \sum _l b_{ll}^2 + 2(\alpha _1 -\alpha _2)^2 tr(\tilde{\mathbf {A}}^{-2}) + 4\alpha _1^2 \bar{\mathbf {x}}^{*\prime } \tilde{\mathbf {A}}^{-2}\bar{\mathbf {x}}^*\nonumber \\&+ \,4\alpha _2^2 (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }})^\prime \tilde{\mathbf {A}}^{-2} (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }}) + (4\alpha _1\alpha _2 -4\alpha _2^2)\theta _x \sum _l b_{ll}(\tilde{\mathbf {A}}^{-1} (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }}))_l \nonumber \\&-\, 8\,\alpha _1\alpha _2 \sum _{ll^\prime } \bar{x}^*_l b_{ll^\prime }(\tilde{\mathbf {A}}^{-2} (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }}))_l + (4\alpha _1\alpha _2 -4\alpha _1^2) \theta _x \sum _l b_{ll}(\tilde{\mathbf {A}}^{-1} \bar{\mathbf {x}}^*)_l.\nonumber \\ \end{aligned}$$(13)
Proof of Lemma 2
It is easy to obtain the conditional expectation (12). For the conditional variance of \(K\), we first calculate the conditional second moment
Since
we obtain
Finally, by
Eq. (13) follows. The Lemma 2 is proved. \(\square \)
The first step of the proof of Theorem 1 is similar to the one of the proof of Theorem 2 where we ensure that \(K- E (K)\) satisfies the Lyapounov condition. The details are referred to (13). Therefore, conditioned on \(\Omega \), as \(n\rightarrow \infty \), the misclassification probability for the D-criterion satisfies
Next, we look for main terms in \(M_p\) and \(B^2_p\), respectively, using Lemma 2. For \(M_p\), we find the following equivalents for the three terms
-
1.
$$\begin{aligned} (\alpha _1-\alpha _2) \text {tr}(\tilde{\mathbf {A}}^{-1})&= \frac{p}{n} (\alpha _1 -\alpha _2) \times \frac{1}{p} tr(\tilde{\mathbf {S}}^{-1}) \\&= \frac{a_1}{n} \times \left\{ p\left( \frac{1}{n_2+1} -\frac{1}{n_1+1}\right) \right\} + o\Big (\frac{1}{n}\Big ); \end{aligned}$$
-
2.
$$\begin{aligned} \alpha _1 \bar{\mathbf {x}}^{*\prime } \tilde{\mathbf {A}}^{-1}\bar{\mathbf {x}}^{*}&= \frac{\alpha _1}{n} \big |\big |\bar{\mathbf {x}}^*\big |\big |^2 \times \left( \frac{\bar{\mathbf {x}}^*}{\big |\big | \bar{\mathbf {x}}^*\big |\big |} \right) ^\prime \tilde{\mathbf {S}}^{-1} \left( \frac{\bar{\mathbf {x}}^*}{\big |\big | \bar{\mathbf {x}}^*\big |\big |} \right) \\&= \frac{a_1}{n} \times \alpha _1 \big |\big |\bar{\mathbf {x}}^*\big |\big |^2+o\Big (\frac{1}{n}\Big ); \end{aligned}$$
-
3.
$$\begin{aligned} \alpha _2 (\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }})^\prime \tilde{\mathbf {A}}^{-1}(\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }})= \frac{a_1}{n} \times \alpha _2 \big |\big |\bar{\mathbf {y}}^*+ \tilde{\varvec{\mu }}\big |\big |^2 + o\Big (\frac{1}{n}\Big ). \end{aligned}$$
Finally,
As for \(B_p^2\), we find the following equivalents for the seven terms
-
1.
$$\begin{aligned}&\left| (\alpha _1-\alpha _2)^2 (\gamma _x -3)\sum _l b_{ll}^2\right| \\&\le \frac{1}{n^2}\left( \frac{1}{n_2+1} -\frac{1}{n_1+1}\right) ^2 \big |\gamma _x -3\big | \times \text {tr}(\tilde{\mathbf {S}}^{-2})\\&= \frac{ya_2}{n^3} \big |\gamma _x -3\big | + o\Big (\frac{1}{n^3}\Big ) = O\Big (\frac{1}{n^3}\Big ); \end{aligned}$$
-
2.
$$\begin{aligned}&2(\alpha _1-\alpha _2)^2 \text {tr}(\tilde{\mathbf {A}}^{-2})\\&= \frac{2}{n^2}\left( \frac{1}{n_2+1} -\frac{1}{n_1+1}\right) ^2 \times \text {tr}(\tilde{\mathbf {S}}^{-2}) \\&= \frac{2ya_2}{n^3} +o\Big (\frac{1}{n^3}\Big )= O\Big (\frac{1}{n^3}\Big ); \end{aligned}$$
-
3.
$$\begin{aligned} 4\alpha _1^2 \bar{\mathbf {x}}^{*\prime } \tilde{\mathbf {A}}^{-2}\bar{\mathbf {x}}^{*} = 4\alpha _1^2\frac{a_2 ||\bar{\mathbf {x}}^{*}||^2}{n^2} +o\Big (\frac{1}{n^2}\Big ); \end{aligned}$$
-
4.
$$\begin{aligned} 4\alpha _2^2 (\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }})^\prime \tilde{\mathbf {A}}^{-2} (\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}) = 4\alpha _2^2 \frac{a_2\big |\big |\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}\big |\big |^2}{n_2}+o\Big (\frac{1}{n^2}\Big ); \end{aligned}$$
-
5.
$$\begin{aligned}&4\alpha _2\big |\alpha _1-\alpha _2\big | \theta _x \sum _l b_{ll} (\tilde{\mathbf {A}}^{-1}(\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}))_l \\&= \frac{4\alpha _2}{n^2}\left| \frac{1}{n_2+1} -\frac{1}{n_1+1}\right| \sum _l c_{ll} (\tilde{\mathbf {S}}^{-1}(\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}))_l \\&\le \frac{4\alpha _2}{n^2}\left| \frac{1}{n_2+1} -\frac{1}{n_1+1}\right| \left( \sum _l c_{ll}^2\right) ^{\frac{1}{2}} \times \left( \sum _l \left( \tilde{\mathbf {S}}^{-1}(\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }})\right) _l^2\right) ^{\frac{1}{2}}\\&\le \frac{4\alpha _2}{n^3} \sqrt{p} \times \big |\big |\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}\big |\big |\sqrt{a_2} + o(\frac{1}{n^2\sqrt{n}}); \end{aligned}$$
-
6.
$$\begin{aligned} 8\alpha _1\alpha _2\sum _{ll^\prime } \bar{x}_l^*b_{ll^\prime } (\tilde{\mathbf {A}}^{-2} (\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}))_l \le \frac{8\alpha _1\alpha _2}{n^3}\sqrt{p} \times \big |\big |\bar{\mathbf {y}}^*+\tilde{\varvec{\mu }}\big |\big |\sqrt{a_2}+o\Big (\frac{1}{n^2\sqrt{n}}\Big ); \end{aligned}$$
-
7.
$$\begin{aligned} \Big (4\alpha _1\alpha _2-\alpha _1^2\Big )\theta _x\sum _l b_{ll}(\tilde{\mathbf {A}}^{-1}\bar{\mathbf {x}}^*)_l \le \frac{4\alpha _1}{n^3}\sqrt{p} \times ||\bar{\mathbf {x}}^*||\sqrt{a_2}+o\Big (\frac{1}{n^2\sqrt{n}}\Big ). \end{aligned}$$
It can be proved that almost surely,
Then the terms 2 and 3 are of order \(O\left( \frac{1}{n^2}\right) \) and 5–7 are of order \(o\left( \frac{1}{n^2}\right) \). Finally,
Since \(n_1/n \rightarrow \lambda \), we have
Finally, it holds almost surely,
This ends the proof of Theorem 1.
1.2 Proof of Theorem 2
By the assumption 2 in Theorem 2, the covariance matrix is \(\varvec{\Sigma }=\text {diag}(\sigma _{ll})_{1\le l \le p}\). Under the data-generation models (a) and (b), the misclassification probability (10) can be rewritten as
where
We firstly evaluate the first two moments of \(\sum _{l=1}^p k_l\).
Lemma 3
Under the data-generation models (a) and (b), we have
-
(1)
$$\begin{aligned} E (k_l)=-\alpha _2 \sigma _{ll} \tilde{\mu }_l^2, \end{aligned}$$
and
$$\begin{aligned} M_p=\sum _{l=1}^p E (k_l)=-\alpha _2||\varvec{\delta }||^2; \end{aligned}$$(17) -
(2)
$$\begin{aligned} Var(k_l)=\sigma _{ll}^2\left\{ \beta _0 +\beta _1(\gamma ) + \beta _2(\theta )\tilde{\mu }_l + 4\alpha _2\tilde{\mu }_l^2\right\} , \end{aligned}$$
and
$$\begin{aligned} B_p^2=\sum _{l=1}^p Var(k_l) = \left[ \beta _0 +\beta _1(\gamma )\right] \text {tr}(\varvec{\Sigma }^2) +\beta _2(\theta ) \mathbf {I}^\prime \Gamma ^3\varvec{\delta } +4\alpha _2\varvec{\delta }^\prime \varvec{\Sigma }\varvec{\delta }, \end{aligned}$$(18)where
$$\begin{aligned} \beta _0&= \alpha _1^2\frac{6n_1^2+3n_1-3}{n_1^3}+\,\alpha _2^2\frac{6n_2^2+3n_2-3}{n_2^3}+\,2(\alpha _1\alpha _2-1),\\ \beta _1(\gamma )&= \gamma _x\left( \frac{\alpha _1^2}{n_1^3}+(\alpha _1-\alpha _2)^2 \right) +\,\frac{\alpha _2^2}{n_2^3}\gamma _y, \beta _2(\theta ) = 4\alpha _2(\alpha _1 -\alpha _2)\theta _x +\,\frac{4}{n_2^2}\theta _y. \end{aligned}$$If removing the small terms with order \(O(p/n_*^2)\), then the formula of \(B_p^2\) in Theorem 2 is obtained.
Proof of Lemma 3
Since \(\mathbf {z}^*, (\mathbf {x}^*_l)\) and \((\mathbf {y}^*_l)\) are independent, the variables \((k_l)_{l=1,\ldots ,p}\) are also independent. For the expectation of \(k_l\), we have
Eq. (17) follows.
For the variance, we have
Moreover,
and
Finally, we obtain
Eq. (18) follows. Then \(B_p^2\) can be rewritten as
Only keep the terms with order \(O(p)\) and \(O(p/n_*)\) we can get the formula of \(B_p^2\) in Theorem 2. The Lemma 3 is proved. \(\square \)
We know that \(\left[ k_l- E (k_l)\right] _{1\le l \le p}\) are independent variables with zero mean. We use the Lyapounov criterion to establish a CLT for \(\sum _l \left[ k_l- E (k_l)\right] \), that is, there is a constant \(b>0\) such that
Since
the \((2+b)-\)norm of \(\left[ k_l- E (k_l)\right] \) is
Then
where \(c_d\) is some constant depending on \(b\). Therefore, as \(B_p^2 \approx 4\varvec{\delta }^\prime \varvec{\Sigma }\varvec{\delta }=4 \sum _{l=1}^p \tilde{\mu }_l^2 \sigma _{ll}^2\),
by the assumption 4 in Theorem 2. Finally, we have
This ends of the proof of Theorem 2.
Rights and permissions
About this article

Cite this article
Li, Z., Yao, J. On two simple and effective procedures for high dimensional classification of general populations. Stat Papers 57, 381–405 (2016). https://doi.org/10.1007/s00362-015-0660-8
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-015-0660-8
Keywords
- High dimensional classification
- Large sample covariance matrix
- Delocalization
- Determinant-based criterion
- Trace-based criterion