
Abstract
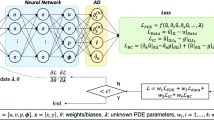
Hamiltonian Monte Carlo is a widely used algorithm for sampling from posterior distributions of complex Bayesian models. It can efficiently explore high-dimensional parameter spaces guided by simulated Hamiltonian flows. However, the algorithm requires repeated gradient calculations, and these computations become increasingly burdensome as data sets scale. We present a method to substantially reduce the computation burden by using a neural network to approximate the gradient. First, we prove that the proposed method still maintains convergence to the true distribution though the approximated gradient no longer comes from a Hamiltonian system. Second, we conduct experiments on synthetic examples and real data to validate the proposed method.










Similar content being viewed by others


References
Baldi P, Sadowski P (2016) A theory of local learning, the learning channel, and the optimality of backpropagation. Neural Netw 83:51–74
Betancourt M (2015) The fundamental incompatibility of Hamiltonian Monte Carlo and data subsampling. arXiv preprint arXiv:1502.01510
Chen T, Fox E, Guestrin C (2014) Stochastic gradient Hamiltonian Monte Carlo. In: International conference on machine learning, pp 1683–1691
Cybenko G (1989) Approximation by superpositions of a sigmoidal function. Math Control Signals Syst (MCSS) 2(4):303–314
Huang GB, Zhu QY, Siew CK (2004) Extreme learning machine: a new learning scheme of feedforward neural networks. In: Proceedings of IEEE international joint conference on neural networks, IEEE, vol 2, pp 985–990
Kingma D, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980
Lan S, Bui-Thanh T, Christie M, Girolami M (2016) Emulation of higher-order tensors in manifold monte carlo methods for bayesian inverse problems. J Comput Phys 308:81–101
Leimkuhler B, Reich S (2004) Simulating Hamiltonian dynamics, vol 14. Cambridge University Press, Cambridge
Neal RM (2012) Bayesian learning for neural networks, vol 118. Springer, New York
Neal RM et al (2011) Mcmc using Hamiltonian dynamics. Handbook Markov Chain Monte Carlo 2:113–162
Rasmussen CE, Bernardo J, Bayarri M, Berger J, Dawid A, Heckerman D, Smith A, West M (2003) Gaussian processes to speed up hybrid monte carlo for expensive bayesian integrals. Bayesian Stat 7:651–659
Welling M, Teh YW (2011) Bayesian learning via stochastic gradient langevin dynamics. In: Proceedings of the 28th international conference on machine learning (ICML-11), pp 681–688
Zhang C, Shahbaba B, Zhao H (2017) Hamiltonian monte carlo acceleration using surrogate functions with random bases. Stat Comput 27:1473. https://doi.org/10.1007/s11222-016-9699-1
Acknowledgements
Babak Shahbaba is supported by NSF Grant DMS1622490 and NIH Grant R01MH115697.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, L., Holbrook, A., Shahbaba, B. et al. Neural network gradient Hamiltonian Monte Carlo. Comput Stat 34, 281–299 (2019). https://doi.org/10.1007/s00180-018-00861-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-018-00861-z