
Abstract
Discontinuous processes face common tasks when implementing modeling and optimization techniques for process optimization. While domain data may be unequal, knowledge about approaches for each step toward the solution, e.g., data gathering, model reduction, and model optimization, may be useful across different processes. A joint development of methodologies for machine learning methods, among other things, ultimately supports fast advances in cross-domain production technologies. In this work, an overview of common maturation stages of data-intensive modeling approaches for production efficiency enhancement is given. The stages are analyzed and communal challenges are elaborated. The used approaches include both physically motivated surrogate modeling as well as the advanced use of machine learning technologies. Apt research is depicted for each stage based on demonstrator work for diverse production technologies, among them high-pressure die casting, surface engineering, plastics injection molding, open-die forging, and automated tape placement. Finally, a holistic and general framework is illustrated covering the main concepts regarding the transfer of mature models into production environments on the example of laser technologies.
Increasing customer requirements regarding process stability, transparency and product quality as well as desired high production efficiency in diverse manufacturing processes pose high demands on production technologies. The further development of digital support systems for manufacturing technologies can contribute to meet these demands in various production settings. Especially for discontinuous production, such as injection molding and laser cutting, the joint research for different technologies helps to identify common challenges, ranging from problem identification to knowledge perpetuation after successfully installing digital tools. Workstream CRD-B2.II “Discontinuous Production” confronts this research task by use case-based joint development of transferable methods. Based on the joint definition of a standard pipeline to solve problems with digital support, various stages of this pipeline, such as data generation and collection, model training, optimization, and the development and deployment of assistance systems are actively being researched. Regarding data generation, e.g., for the high-pressure die-casting process, data acquisition and extraction approaches for machines and production lines using OPC UA are investigated to get detailed process insights. For diverse discontinuous processes and use cases, relevant production data is not directly available in sufficient quality and needs to be preprocessed. For vision systems, ptychographic methods may improve recorded data by enhancing the picture sharpness to enable the usage of inline or low-cost equipment to detect small defects. Further down the pipeline, several research activities concern the domain-specific model training and optimization tasks. Within the realm of surface technologies, machine learning is applied to predict process behavior, e.g., by predicting the particle properties in plasma spraying process or plasma intensities in the physical vapor deposition process. The injection molding process can also be modeled by data-based approaches. The modeling efficiency based on the used amount of data can furthermore be effectively reduced by using transfer learning to transfer knowledge stored in artificial neural networks from one process to the next. Successful modeling approaches can then be transferred prototypically into production. On the examples of vision-based defect classification in the tape-laying process and a process optimization assistance system in open-die forging, the realization of prototypical support systems is demonstrated. Once mature, research results and consequent digital services must be made available for integrated usage in specific production settings using relevant architecture. By the example of a microservice-based infrastructure for laser technology, a suitable and flexible implementation of a service framework is realized. The connectivity to production assets is guaranteed by state-of-the-art communication protocols. This chapter illustrates the state of research for use-case-driven development of joint approaches.
You have full access to this open access chapter, Download reference work entry PDF
Similar content being viewed by others


1 Introduction
Increasingly higher customer demands and smaller failure tolerances on produced parts challenge manufacturers in high-wage countries and call for innovations to remain competitive on international markets (Brecher et al. 2011). In recent years, digitization and digitalization in various manufacturing domains are being explored as very promising to raise overall production efficiency, may it be due to further automation or deeper understanding of the process. Especially, vast amounts of recorded data may offer great potential for elaborated analysis and improvement. However, in most cases, these data are scattered, often not even within the same databases, or not as numerous as needed for detailed data-based analyses (Schuh et al. 2019). In a so-called “Internet of Production”, these issues shall be resolved by a new approach: Data, models, and methods, even from different domains, are made available by executing a developed ontology to connect these different aspects of knowledge. A new level of cross-domain knowledge exchange and possible collaboration will then be possible.
Discontinuous production processes may benefit from these developments. Discontinuity is on the one hand related to the state of operation: The herein considered processes in accordance with DIN 8580 produce product in batches with planned iterations of process steps, which is the definition of batch production. On the other hand, variables of state involved in the discontinuous process show a time-dependent variation of their values, depending on the state of the production, e.g., cavity pressure curve in injection molding. On the contrary, for thermodynamically continuous processes the variables of state should be kept constant at all times, e.g., extrusion.
A recurring challenge for discontinuous processes is the minimization of non-value-adding activities, e.g., when setting up the process, and the complexity to repeatedly find a balanced process under new circumstances and new production asset configurations. As these minimization tasks can be found similarly in all discontinuous productions, sharing of knowledge between domains may significantly raise the process efficiency and productivity.
In the following, challenges and potentials from the current state of the art for representative discontinuous processes are presented based upon a common procedure when modeling discontinuous processes. Detailed explanations regarding the use-case-driven development are given in subsequent subchapters dealing with the demonstrator processes. Various steps in this procedure are described in detail, and current research toward knowledge sharing is presented to give an understanding about possible method-based cross-domain collaborations.
2 Common Challenges in Modeling and Optimization of Discontinuous Processes
A process may be defined as the entirety of actions in a system that influence each other and which transport, convert, or store information, energy, or matter (N.N. 2013). In the cluster of excellence “Internet of Production”, a variety of discontinuous processes regarding different production technologies are being researched
-
High-pressure die casting
-
Automated tape placement
-
Thermal spraying
-
Physical vapor deposition
-
Injection molding
-
Open-die forging
-
Laser ablation, drilling, and cutting
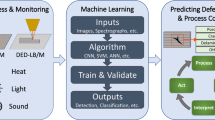
An intermediate objective for every single process is the support of recurring production tasks, e.g., by assistance systems. Some process technologies such as injection molding qualify for an assistance system development due to their high grade of automation and advanced controllability regarding process stability. Less digitally progressed, less widespread, or highly specialized technology facing challenges regarding process understanding and controllability can benefit from methodological exchange for asset connectivity, correlation identification, sensor development, and other support processes on the road to sophisticated assistance systems. However, all processes may benefit from a general approach for digital and data-based methods in terms of Industry 4.0 to improve the processes efficiently as advocated by the “Internet of Production” (Schuh et al. 2019). Successfully probed methods in a specific domain for common tasks such as process setup, quality supervision, or continuous optimization should be considered candidates for a cross-domain knowledge sharing to pool competency and drive intelligent processes. An abstracted and common sequence of tasks for data-based, digital development of discontinuous processes, directly connected to the maturation of assistance system development in respective process technologies, supports the methodological collaboration. This approach is illustrated in Fig. 1.

Maturation stages in discontinuous process modeling and efficiency improvement
Each approach for a digital and data-based problem resolution (see Fig. 1) starts with a sharp problem identification and the definition of concerning information. In the best case, quantifiable parameters containing this information are already known, measurable, and available. Modern production systems are characterized by their reliance on a multitude of sensors and programmable logic controls. Measurement and input values are processed by the control system and the physical entities of the machinery are actuated accordingly. Technically there is no shortage of process data. However, due to the diversity of discontinuous production processes in different industries with different requirements, full raw process data is often discarded, retained for limited time, reduced to mean values, or isolated in globally inaccessible storage systems with limited capacity. The Internet of Production can only be realized if process data is globally available with sufficient but adequate granularity. A major challenge lies in striking a balance between the required storage for data from one discontinuous production cycle and the ability to retain these cycle data sets over months and years for retrospective analysis. The major challenge is that inquiries about the process may arise much later in time and the scope only becomes clear long after the production process has concluded. Consequently, the granularity of the process data stored cannot be defined beforehand as the objective of later analyses can hardly be predicted. Therefore, initial full retention and global availability of the process data needs to be facilitated to enable in-situ detection of second- and third-order interdependence between sensor and actuator measurements to effectively antedate the retrospectively arising questions relating to the process. By employing such a strategy, the process data can be refined for longer term storage with a reduced overall storage requirement based on the detected correlations and data processing that can be employed right after the sensor values were captured. This strategy relies on three cornerstones: Raw data transfer from the machine to the cloud, data refinement by connecting the full data set of the process including machine and product in an adequate format, and lastly automated analysis of this high granularity data set to detect process interdependencies to facilitate subsequent data reduction where applicable.
When data is defined and readily recorded, the necessary information might need to be extracted for the following model building. Arguably the most important type of data to be considered for data (pre)processing in industrial applications is visual data. In many discontinuous production processes, quality analysis is at least partly done through optical methods (Garcia et al. 2001; Du et al. 2005; Abiodun et al. 2018). Traditionally, this is either realized by simply installing a camera to receive quick information or by measuring the results through more time-consuming methods like microscopy. Both ways have advantages and disadvantages: The information provided by a camera can be obtained easily but is subsequently less detailed than that from microscopes which could lead to missing crucial information in the surface structure. A microscope provides much more detailed information, but it can usually not be used to scan all output products due to the required time or cost. With computational methods, this issue can be addressed to find a compromise between camera and microscope. When the image data is used in quality analysis/prediction, conventionally, various machine learning models are employed for image processing like feature detection (Sankhye and Hu 2020). This can be done with raw image data, but it has been demonstrated that for example in image classification preprocessing of the images leads to far more accurate results (Pal and Sudeep 2016). Similarly, it can be expected that in quality prediction, preprocessing like transforming the images to greyscale, flattening, or using an early edge detection method may improve the accuracy of the models. Both using computational methods for finding the boundary between camera and microscope and using image preprocessing are ways to enhance or enable data used in quality prediction. This can have a bigger impact on machine learning results than modifications of the model itself.
Furthermore, a model should be able to handle a large number of parameters. A great amount of parameters or equations to describe the process, e.g., reduce the computation velocity. This might be harmful considering the subsequent implementation in a control system that aims to be real-time ready. On the other hand, as many input information as possible should be kept for the model design if these effectively contribute to improve the prediction results. In the end, “the reduced order model must characterize the physical system with sufficient fidelity such that performance objectives […] for the controlled physical system can be met by designing control laws with the reduced order model”. (Enns 1984). Therefore, especially for the usage of highly dynamic systems such as laser applications, model order reduction is a many times researched field of interest to improve model quality. Laser manufacturing processes are controlled by multi-dimensional process parameters. To model this process numerically, several multi-physics dynamic equations should be solved. However, the high-order parameter dimension and process complexity make it difficult to conduct a solution and establish a data-driven process design. Model reduction is a way to drive a model focusing on specific quality criteria by neglecting unnecessary complexities. These reductions are based on dimensional and scale analysis, empirical model, or numerical model reduction (e.g., Proper Orthogonal Decomposition method (Li et al. 2011)). The model reduction procedure employs a top-to-down approach that begins with complex multi-physic governing equations, and ends to the approximated ordinary differential equations. The main task of model reduction methods is to omit unnecessary complexity and to reduce the computation time of large-scale dynamical systems in a way that the simplified model generates nearly the same input-output response characteristics. They are capable of generating accurate and dense dataset in an acceptable time. These datasets can be used to enrich the sparse experimental data and also, by employing machine learning models, establish data-driven and meta-models.
Besides physical models, data-based models have been gaining a lot of interest in the past years. This may be due to the facilitated development of sensors, data acquisition methods, less costly data storage options, and generally higher availability of highly educated personnel in the domain of data science. The usage of machine learning may be beneficial for the representation of processes whose behavior contains a significant part of hardly explainable or quantifiable phenomena. Examples of discontinuous processes are physical vapor deposition, thermal spraying, or the thermoplastics injection molding process. An efficient model selection, e.g., by hyper-parameter optimization, model training, and strategies regarding how to use the resulting models are unifying steps in the improvement process across different domains and between different discontinuous processes. One common challenge is that, e.g., especially advanced models such as artificial neural networks require a significant amount of training data to prevent underfitting a modeling task. The generation of manufacturing data of discontinuous processes, however, can be time-consuming and expensive and therefore limited. Lowering this barrier would foster the applicability of machine learning in the manufacturing field in general. To achieve this goal, transfer learning is used as one possible method to demonstrate the potential to reduce the problem of limited training data. In the context of machine learning, “transfer learning“refers to the transfer of knowledge learned from a source domain DS and a source task TS to a new task TT (Weiss et al. 2016). A structured transfer of knowledge is realized through the close relationship of the tasks or domains to each other. The most intuitive approach to transfer learning is induced transfer learning (Woodworth and Thorndike 1901; Pan and Yang 2010; Zhao et al. 2014): Given a source domain DS and a source task TS, the inductive transfer learning attempts to improve the learning of the contexts in the target domain DT with the target task TT. Here, the source and target tasks differ from each other. The approach assumes that a limited amount of labeled data from DT is available. This is usually the case for different processes, e.g., when a new process setting is probed. Therefore, transfer learning is one method for data-based process modeling that should be researched further and individually per process while sharing knowledge about approaches and caveats between the settings, especially between different discontinuous processes.
Once all technical challenges are solved, developed models need to be transferred into production as their ultimate legitimation is the support of respective manufacturing processes. All previously considered challenges to easily implement improvements to the process such as significant parameters with necessary information, small models for fast computation, small datasets for advanced data-based models, and more culminate at this stage. During the deployment stage, it is decided if the model or maybe even resulting assistance system is applicable for the users. Concrete difficulties that may arise at this stage for all discontinuous processes might be of three categories: (1) Social: Users and workers might not approve of the resulting measures for the derived model-based improvements. (2) Technical: Sometimes it may be difficult to conclusively prove a value of the derived measures for the company. E.g., a deeper understanding for the workers of the discontinuous process by displaying aggregated information about the process’ state might not be directly quantifiable but furthers the workers’ domain-specific problem-solving skills. (3) Architectural: Talking about industry 4.0, the resulting improvement involves digital methods significantly. However, companies already use software and usually resent a great variety of different programs and platforms. It is therefore crucial to supply developed models and assistance systems in accordance with the common software integrations in companies to guarantee ergonomic use.
In conclusion, discontinuous processes analogously show similar stages for modeling and when trying to improve process efficiency in its variety of definitions. In particular, problem and data definition, data gathering, data (pre)processing, model order reduction, model design, training and usage, model or assistance system deployment as well as knowledge perpetuation in a final stage which is not extensively considered here are to be named. The following subchapters will give an overview of the stages of research for a variety of discontinuous processes. Significant challenges and possible solutions that may be transferable between processes are highlighted to make the reader acknowledge the previously defined analogies.
3 High Granularity Process Data Collection and Assessments to Recognize Second- and Third-Order Process Interdependencies in a HPDC Process
The high-pressure die casting (HPDC) process is a highly automated discontinuous permanent mold-based production technology to fabricate non-ferrous metal castings from aluminum or magnesium base alloys. Typically, a HPDC cell consists of multiple subsystems that are operated by separate PLCs in order to replicate every production cycle as closely as possible. Current generation data acquisition systems are usually limited to only extract averages or scalars from the process at one point in time of the cycle rather than continuously providing data such as die or coolant temperatures to facilitate in cycle assessments. By reducing the amount of acquisitioned measurement data points information about the process is irreversibly lost which prohibits analysis of high-granularity data in retrospect if needed. While some external measurement systems can measure and store this data, typically via SQL databases, currently there is a lack of cloud infrastructure-compatible data pipelines and storage blueprints to facilitate the transfer and retention of high granularity data available via service-oriented architectures such as OPC UA (Mahnke et al. 2009) for downstream analysis. In order to retain the ability to assess the raw and undiluted data a state-of-the-art architecture based on a data lake derived from the Internet of Production infrastructure research activities was deployed to store the process data and enable its assessment (Rudack et al. 2022). In the following an example of the acquisitioned process data extracted from the data lake are presented to illustrate potential use cases and benefits of granular acquisition and long-term data storage. The presented issue to the plunger cooling flow rate. In the HPDC process, the plunger is usually made from a Copper alloy and has to be water-cooled since it is in direct contact with molten Aluminum. A suitable equilibrium temperature range needs to be maintained in order for the plunger to maintain a suitable gap width between itself and the surrounding tool steel, otherwise excessive wear can occur due to metal penetration in the gap or excessive friction at the interface. Effectively, the water coolant supply is the proxy parameter that governs the plunger operating temperature. The top half of Fig. 2 shows that during 1 h of HPDC production the flow rate exhibits 6 drops of the flow rate from about 16 l/min to 12 l/min, each lasting around 3 min which corresponds to around 4 production cycles. This puts the plunger-chamber system in a different operating condition. The reason for this phenomenon can be determined with high certainty when a visual synchronization with the water temperature at the heat exchanger of the hydraulics system is made. It is visible that the reduction in plunger coolant flow occurs when the heat exchanger of the hydraulics system is active. The initial temperature peak indicates that the hot water that was static in the heat exchanger is being pushed out by colder water which consequently lowers the temperature until the heat exchanger flow is switched off again by the control system. The plunger temperature and the hydraulics system do not seem like directly interdependent entities from a classical engineering point of view. However, as these measurements show they are indirectly linked via the coolant network of the machine.

Behavior of the coolant system during 1 h of HPDC operation
These two sensor values serve as an example for a correlation derived from data from the data lake and investigated by a manual data assessment by the domain expert. The next research steps will aim to enable continuous automated assessments for over 300 separate sensor values that are stored in the data lake during HPDC operation as semantically integrated sensor data. We will assess how to derive machine and die-specific process signatures that enable the derivation of the processes’ specific digital shadow. By deployment of adequate mathematical methods on the data available through the cloud-native architecture we aim to better understand the second- and third-order consequences of fluctuations in sensor values.
Retention of a full set of process can be beneficial if correlations are initially entirely unknown as outlined above. Generally, vector and scalar data from flow or temperature sensors are not as problematic retain from a storage standpoint as visual data. Surface defects of the casting and die are one defect class where visual data enable an in situ process feedback loop. High-resolution visual data is needed to drive defect detection on both elements: The casting and the die. Imaging systems usually have to find a compromise between slow, high-resolution processes that provide possibly too detailed data for practical usage and fast, low-resolution imaging systems that fail to capture all required details. This can be addressed with computational methods as described in the following.
4 Fourier Ptychography-Based Imaging System for Far-Field Microscope
Fourier ptychography (Zheng et al. 2013) is a method based on wave optics to extract the complex electromagnetic field and thus reconstruct images with higher resolution. It is mainly used in microscopy but it can also be applied in systems with higher working distances (Dong et al. 2014). It requires only a simple camera that can be integrated in many processes and employing computational methods to extract more detailed information than what is conventionally achievable.
TOS designed a macroscopic Fourier Ptychography imaging system which is used to take multiple unique images of a distant target object and iteratively reconstruct the original complex electromagnetic field at a much higher resolution, comparable to that of light microscopes. The imaging system is depicted in Fig. 3. A Helium-Neon laser is used to create the coherent radiation for illuminating a target. The beam of the laser is expanded with a telescope to emulate a plane wave illumination. It is split into two beams with a beam splitter cube to illuminate the target perpendicularly. The reflected beam then incidents on a conventional camera that can be moved with two linear stages for creating the unique images. The recorded images are saved together with the process parameters and can be used for the reconstruction process at any time.

Imaging system
The acquired images are fed into a data lake. With iterative optimization based on Wirtinger Flow (Chen et al. 2019) this large sum of images is reduced to a high-resolution image that combines all the light field information from each separate image while requiring less memory. No information is lost during the process. This is especially advantageous in processes where a camera cannot be placed in the short distance required by microscopes. In this situation, the reconstruction process acts as a digital twin to the measurement by emulating the experiment in a simulative propagation. An initial guess for the complex field is estimated and the propagation and thus resolution reduction through the optical system is simulated. The goal of the optimization is to minimize the difference between the experimental images and the subsequent low-resolution simulated images which can only be accomplished by finding the underlying high-resolution field.
Example reconstructions of a USAF resolution target and an ivy leaf are depicted in Fig. 4. For the resolution target, the achieved resolution with regard to the smallest resolvable structure is increased by roughly 25% but more is expected in future modifications of the setup. Using the reconstructed images for quality prediction based on artificial neural networks was tested in a toy model for high-pressure die casting in a collaboration with Foundry Institute (GI) and the chair of Computer Science 5, RWTH Aachen University (Chakrabarti et al. 2021). This setup may be introduced for all discontinuous processes that need high image resolution without using microscopes. The next research steps are the implementation of a new camera and modifications of the recovery algorithm for faster and more accurate results.

Reconstruction examples
Still, due to high-dimensional and complex physical phenomena, not every process can be fully controlled or optimized experimentally. Also, it is often not possible to do full numerical simulations. A combination of simulations and experiments might be a remedy to this dilemma. One can decrease mathematical complexities by means of model reduction methods, provide solvable equations, and calibrate them by experimental data. Reduced models can simulate the processes in wider ranges of parameters and enrich sparse experimental data. By this potential feature space, more effective feature learning and also feature selection can be established. In addition, by combining the reduced and data-driven models, the applicable boundaries of utilization of reduced models can be specified that can robust the modeling, simultaneously.
5 Integrating Reduced Models and ML to Meta-Modeling Laser Manufacturing Processes
Rising capabilities of production procedures require simultaneous improvement of manufacturing planning steps since processes become more complex. One can reach an optimized production plan through process parameter identification, knowledge extraction, and digitization. Experimental studies are limited to sparse data to investigate and control these complex processes. Full numerical simulations are also computationally costly due to the multidimensional complexity of the governing eqs. A practical solution is to enrich experimental data with reduced model simulations called data-driven models. Model reduction techniques which are based on analytic-algebraic, numerical, or empirical reduction approaches are used to decrease the complexities of the governing equations.
Extended work has been done on the subject of laser drilling (Schulz et al. 2013). A reduced model has been proposed (Wang 2021) to simulate the laser drilling process in the melt expulsion regime and consequently to construct a digital shadow of the process. Through the reduced equations, the laser drilling process at the base of the borehole, the melt flow at the hole wall, and finally, the melt exit at the hole entrance are simulated. A sparse experimental dataset is used to validate the reduced model before generating data to enrich the dataset, as depicted in Fig. 5 (Wang et al. 2017).

Work-flow to enrich sparse data. (Wang et al. 2017)
The generated dense data is interpolated to form a meta-model and is a valuable tool in quality prediction, process design, and optimization. In Fig. 6, the applicable region of laser drilling is shown, which is estimated based on the maximum height of melt flow in the hole. To this goal, a Support Vector Machine (SVM) classifier is used in meta-modeling, and the applicable beam radii under specific radiation intensity are estimated.

Estimated applicable region by SVM. Red area presents the applicable combination of beam radii and power intensities for laser drilling. (Wang et al. 2017)
The reduced equations of mass and energy conservation are solved in solid, liquid, and gaseous phases in the melt expulsion regime to analyze the laser drilling process (Wang 2021). This reduced model is established by scaling the equations, applying phenomenological facts, and integral method. However, estimating the shape of the drill hole is still computationally costly requiring a higher level of reduction for the model. Through an empirical model reduction, an intensity-threshold model is developed that estimated the borehole shape asymptotically in the long-pulse laser drilling regime (Hermanns 2018). The approximation of the hole’s shape relies on the fact that the material absorbs a specific power intensity after a certain number of pulses and is removed as the absorbed intensity reaches the critical value, named the ablation threshold. Since this asymptotic model is fast and accurate within its applicable region, it could also be used to enrich required data for meta-modeling.
Another application of combining reduced models and ML techniques is inverse solution-finding. This approach was applied to solve a simple trebuchet system through training a deep neural network; it used the Algorithmic Differentiation (AD) technique to embed the trebuchet ODE model in the loss function (Rackauckas et al. 2020). The ANN learns to approximate the inverse solution for a specific hole geometry during training by reproducing the required parameters of the reduced model. The reduced laser drilling model is part of the loss function.
In case the combination of reduced models and sparse or expensive data prove useful for an application, their validity, especially for data-based models, needs to be always critically questioned. Changes in material, machine, surrounding, and many other influencing factors might let the resulting modeling quality to erode. However, working models are the foundation to an automated process optimization, independent of the quality parameters which are chosen to be optimized. Furthermore, complexity of models might not only be measured by the number of input parameters but also the number of connected process steps. A lot of data is, e.g., generated in an Automated Tape Placement (ATP) process including vision-based defect analysis and OPC UA connection to the machine for high granular data. This poses a viable example for the combination of data gathering and enabling steps toward an extensive model for process optimization.
6 Vision-Based Error Detection in Automated Tape Placement for Model-Based Process Optimization
As in many highly integrated discontinuous processes, part defects during manufacturing in ATP processes can have a substantial influence on the resulting mechanical or geometrical part properties and are very costly when discovered at a late process stage (Li et al. 2015). Therefore, multiple defect detection systems are being investigated in industry and research (Brasington et al. 2021). Especially economically competitive sensors such as industrial cameras have shown to be feasible (Atkinson et al. 2021) with certain challenges such as low-contrast environments. Automated defect detection with the possibility to adjust the process settings to reduce part defects is therefore the goal of this research.
Multiple defects can occur during AFP, the most common being gaps, overlaps and positional errors, or other processing defects. Firstly, determining tape geometry and defects for one tape are investigated by an in-situ (integrated into production line) inspection of the parts which permits high productivity and throughput. The observed defects include tape length, width, and the cutting edge angle. To detect and quantify these defects, methods of classical image processing are employed. Acquiring process and machine data based on a process model is necessary to feed back process influences onto the laminate quality and finally enable online quality improvements. However, no generic machine component and parameter models currently exist for ATP machines, especially for the integration of quality data. Such a model is required to enable generic correlation of quality data with parameters. Therefore, a machine model on the basis of OPC UA is developed.
The quality inspection system to gather reliable quality data of single tapes consists of a monochrome industrial camera DMK 33GP2000e mounted behind the tape placement head and a manually controllable RGB lighting system mounted inside the machine housing (see Fig. 7). The camera is further equipped with a polarization filter mounted to the lens to reduce reflections and increase tape detectability due to the carbon fibers polarizing incoming light during the reflection.

Measurement setup
Different algorithms, namely the Sobel, Prewitt, and Canny operators, are used to detect tape edges, with the Canny Edge Detector outperforming Sobel and Prewitt, since it is able to filter out noise induced by, e.g., the tooling background. However, the detected edges from the Canny edge detection are still quite irregular and not necessarily complete. Therefore, a hough line transform is applied on these edges, creating straight lines in accordance with the tape’s geometry.
Figure 8 shows the whole analysis process. Using the created tape contour, the tape’s geometrical features as well as the cutting angle can be accurately extracted from the images with knowledge about the pixel/mm factor and the intersection between the vertical and horizontal hough lines. The latter can give an indication about cutting unit and knife wear, i.e., increasing cutting angle points to dull blades and therefore indicates upcoming maintenance.

Tape geometry analysis
Subsequently, a model using OPC UA to describe the tape placement system by combining machine settings, process, and quality parameters is developed. The model is semantically categorized into different functional groups. One group represents conveying the tooling through the machine. The next group is responsible for orienting the fiber angle. The last group aggregates the functionality to place the tapes, including the required motion for unrolling the tape from the spool, as well as the tape placement head components. The tape placement head is again encapsulating multiple functional components, e.g., cutting unit, feeding unit, heating unit, and pressure application unit.
This model-based approach gives a clear overview of the process parameters, decoupled from the individual machine components. Next, context-aware analysis of process parameters and their interdependencies can be realized, revealing influences of the process as well as the machine system on laminate variations and defects. These interdependencies then can be used to optimize part quality prior to manufacturing as well as online from part to part. The modeling for the ATP process displays the challenges for integrated discontinuous processes and may later be taken as a blueprint for other processes for the combination of process information. Further example for the design and training of data-driven models can be found in the area of surface engineering, e.g., for physical vapor deposition (PVD) and thermal spraying (TS) processes.
7 Understanding Coating Processes Based on ML-Models
Surface engineering enables the separated optimization of the volume and surface properties of materials. In manufacturing technology, this is crucial for increasing performance or lifetime. The main motivation for employing coating technologies such as PVD and TS are resource savings, environmental protection, and increasing demands on safety and efficiency attributes. PVD and TS are associated with numerous process parameters and represent two important discontinuous coating technologies.
TS is a versatile coating technology regarding the wide variety of feedstock materials, which can be introduced into the high-temperature free jet to deposit a coating. The resultant molten or semi-molten particles are accelerated toward a prepared substrate and build a coating by successive impingement. TS offers a wide range of functional features including wear, oxidation and corrosion resistance as well as thermal insulation. Therefore, many industrial sectors benefit from the special characteristics of this coating technology. In the PVD process, a solid target material is transferred into the gaseous phase in a vacuum chamber. Within the gas or plasma phase, interactions take place between the ionized and excited species. Inert gases, such as argon or krypton, are used as process gases or reactive gases, such as nitrogen and oxygen, are added to the gas phase for active participation within the coating formation. The species in the plasma are transported toward the substrate at which the coating grows. Knowledge of particle properties in the TS process or the plasma in the PVD process is necessary for adequate coating development. The understanding of the coating processes and the influence and selection of process parameters can be supported by Machine Learning (ML).
The numerous parameters and their nonlinear interactions influencing TS can lead to a time-consuming and costly endeavor to control and optimize the processes. Simulation and modeling methodologies such as Computational Fluid Dynamics (CFD) are frequently used to represent the associated complicated physical processes. Although CFD has a strong potential for understanding the sub-processes of TS, the balance between model accuracy and computational cost has always been a concern. The modeling of the particle free-jet in a multi-arc plasma spraying process, which is the subject of this work, necessitates a high computing cost without losing model accuracy. The use of ML methods to construct a Digital Shadow is a promising solution for replacing computationally intensive CFD simulations.
Therefore, a Digital Shadow for the plasma spraying process was developed that can predict the average particle properties depending on different sets of process parameters using CFD simulations and Support Vector Machine (SVM) models. The simulation data sets were obtained in form of a 45-sample Latin Hypercube Sampling (LHS) test plan from a former numerical model for the plasma spraying process of a three-cathode plasma generator (Bobzin and Öte 2016). The simulations were also validated experimentally by in-flight particle diagnostic measurements (Bobzin et al. 2016). The feedstock material for the simulations was alumina. The parameters for the LHS, respectively, the inputs of the ML-models are given in Table 1.
Two single-output SVM models for the in-flight particle temperatures Tp [K] and velocities vp [m/s] were developed. Gaussian kernels with different kernel scales were probed as SVM-hyperparameters for the best prediction accuracy. From each of the 45 simulations, 75% of the data were used as training data and the remaining 25% as test data. Figure 9 shows exemplarily the results of the mean particle velocities at the spray distance of y = 100 mm for particle diagnostic experiments, simulations and SVM-models for different sets of process parameters. Although the prediction accuracy is slightly lower for some unconventional process parameters outside the training data range, the developed metamodels have high accuracy in predicting particle properties with average R2 ≈ 0.92 for vp and Tp. Figure 9 shows also good agreement of the experimental measurements with the analytical models.

Exemplary results of mean particle velocities for experiment, simulation, and SVM for different sets of process parameters
The average computational time of one plasma jet simulation in combination of the corresponding plasma generator simulation is about 3 h, in comparison to roughly 4 s prediction time of the metamodels. The developed ML-models drastically reduce the computational cost while preserving high prediction accuracy. The conducted work serves as basis for the creation of the complementary concept of Digital Twin for plasma spraying.
In PVD, the process parameters are usually selected by the operator based on experience and analysis results. Nonlinear interactions and influences between individual process parameters are difficult to determine by algebraic methods and require improvement of the process monitoring to reduce the time of coating development. During the coating process, different interactions of gas and metal species take place in the gas and plasma phase. Among other things, the ionized and excited state and the energies of the species are decisive for the resulting formation and the properties of the coatings. Knowledge of these processes is important for the understanding of the PVD coating process and the selection of process parameters during coating development. Methods of plasma diagnostics offer various possibilities for the investigation of the plasma processes. However, the installation of special diagnostics is necessary, time-consuming, and cost-intensive. Machine learning methods can be used to support coating development. They can be applied to predict and identify high ionization and excitation states and to assist the operator in time and cost-effective selection of process parameters.
To achieve high prediction accuracies, a large database is required for modeling and training of machine learning models, such as artificial neural networks. In this study, measured process and plasma data were used to develop a neural network to support the understanding of the phenomena in the PVD process. For dynamic time-dependent prediction, a recurrent neural network (RNN) is suitable (Abiodun et al. 2018). The model was trained with the process and plasma data of 41 data sets for the deposition of CrAlON coatings using the Levenberg-Marquardt algorithm. 70% of the dataset served for training, 15% for validation, and 15% for testing. All coating processes were performed by hybrid direct current magnetron sputtering/high power pulsed magnetron sputtering (dcMS/HPPMS) using an industrial coating unit CC800/9 HPPMS, CemeCon AG, Würselen, Germany. Within the processes, the cathode powers PdcMS and PHPPMS and gas flows j(N2) and j(O2) were varied over the deposition time. Substrate bias voltage UB and argon gas flow j(Ar) were kept constant. Resolved over the deposition time, the intensities of the excited “I” and singly ionized “II” species in the plasma were recorded by optical emission spectroscopy. The intensities were measured at six positions distributed in the chamber, each at the substrate position opposite of a cathode. The II/I ratios were calculated for the species in the plasma. For each ratio of the species in the plasma, the optimized number of hidden layers for the model was determined. As result, a range between five and 20 hidden layers indicated that separate models should be trained for the different species to achieve the highest possible accuracy. As an example, for Al II/Al I an amount of 20 hidden layers was identified as suitable, for N II/N I ten hidden layers were chosen. The RNNs were trained and used to predict the ion intensities at different timestamps of a new data set in which the oxygen gas flow was varied. After the prediction the same process was performed and measured. Figure 10 shows the predicted and subsequently measured intensity ratios N II/N I (red) and Al II/Al I (blue) at different timestamps of the exemplary process. At the timestamps t = 50 s, t = 250 s and t = 850 s different gas flows were present. The predicted results showed an equal range of values, equal tendencies, and a good agreement with the measured values over the process time within the data set. With increasing oxygen gas flow and process time, the normalized intensity ratio N II/N I decreased. A decrease of the normalized intensity ratio Al II/Al I was also seen from t = 250 s with j(O2) = 15 sccm to t = 850 s with j(O2) = 30 sccm. This indicates an increasing poisoning state of the target used. To evaluate the prediction accuracy, the Mean Square Error MSE was calculated, which is close to zero at a high accuracy. The prediction showed for Al II/Al I a MSE = 0.361 and for N II/N I a MSE = 0.031. The RNN provides insight into the behavior of the species in the plasma and supports the operator during parameter selection.

Intensity ratios measured and predicted using RNN at different time steps and oxygen gas flows for Al II/Al I (blue) and N II/N I (red)
The diverse data sets of coating technologies offer great potential to gain new insights into these complicated processes and to develop and improve the processes in a fast manner. ML methods may help to obtain the added value of this data. The developed models for TS and PVD can be used to advance Industry 4.0 in the field of surface technology and beyond in general for discontinuous processes. Furthermore, industrial transfer learning can be implemented to use the collected data source in this study for other process variants or different production domains. As a result, new accurate and data-efficient models can be created or the generalization capability of the used models can be improved. A currently active research for the transfer of knowledge between machine learning models describing discontinuous processes can be seen for injection molding.

Results of transfer learning experiments (left axis) and model generalization capability for supplied source dataset (right axis) according to. (Lockner and Hopmann 2021)
8 Transfer Learning in Injection Molding for Process Model Training
In injection molding, one of the most complex tasks for shop floor personnel is the definition of suitable machine parameters for an unknown process. Machine learning models have proven to be applicable to be used as surrogate model for the real process to perform process optimization. A main disadvantage is the requirement of extensive process data for model training. Transfer learning (TL) is used together with simulation data here to investigate if the necessary data for the model training can be reduced to ultimately find suitable setting parameters. Based on different simulation datasets with varying materials and geometries, TL experiments have been conducted (Lockner and Hopmann 2021; Lockner et al. 2022). In both works, induced TL (Pan and Yang 2010) by parameter-based transfer was implemented: Artificial neural networks (ANN) have been pretrained with datasets of injection molding processes, each sampled in a 77-point central composite design of experiments (DoE), and then retrained with limited data from a target process (one-one-transfer, OOT). The values of the independent variables injection volume flow, cooling time, packing pressure, packing pressure time, melt, and mold temperature have been varied, and the resulting part weight was observed as a quality parameter.
TL can significantly improve the generalization capability of an ANN if only a few process samples of the target process are available for training (comp. Figure 11). On average, this lowers the necessary experimental data amount to find suitable machine parameter settings for an unknown process. Consequently, this accelerates the setup process for manufacturing companies. However, depending on the transferred parameters, the model’s generalization capability may vary significantly which may impair the prediction accuracy. The geometry of the produced part and its belonging process model can have a significant impact: For the depicted results, 60 different geometries for toy brick were sampled, e.g., “4 × 2” for 2 rows of 4 studs and “Doubled” for doubled shoulder height of the toy brick relatively to the “Original” geometry, which was used as target domain. For source datasets “4 × 2 Doubled” and “4 × 2 Halved” the ANN achieve the best result for the data availability between 4 and 12 target process samples. However, the source domain “4 × 2 x3” should not be used: The inferior TL results may stem from the geometrical dissimilarities between “4 × 2 x3” and “4 × 2 Original”: All dimensions, including the wall thickness, are tripled for “4 × 2 x3” in comparison to “4 × 2 Original” which strongly influences the filling, packing, and cooling phase of the process (Johannaber and Michaeli 2004). Therefore, it is necessary to identify a priori which source model is most suitable to be used as a parameter base for the target process in a transfer learning approach.
For that, a high-level modeling approach has been designed, using the transfer learning results for 12 target process samples (compare Fig. 11) of the bespoken experiments in (Lockner and Hopmann 2021) as training data. The transfer learning success measured by R2 served as a quality parameter. Twenty-five geometrical parameters describing the parts of the injection molding processes and whose values are known before production have been identified. Among them are, e.g., the part length, width and height, maximal wall thickness, flow path length, volume, and surface of the part. Each of the 60 parts has been valued by these parameters. As the training data stems from the OOT transfer learning results, the absolute differences in each geometrical dimension were calculated and served as input data for the modeling.
Different model strategies were evaluated in a nested six-fold hyperparameter optimization: Lasso Regression, Random Forest Regression, Polynomial Regression, Support Vector Regression, AdaBoost, and GradientBoost (Freund and Schapire 1997; Breiman 2001; Hastie et al. 2008; Pardoe and Stone 2010). AdaBoost with Support Vector Regression as base model achieved the lowest mean squared error with 0.0032 and a standard deviation of 0.0055 and was therefore chosen as modeling strategy for the given task. To determine the generalization capability on unseen data, a leave-one-out cross-validation (LOOCV) has been performed with the AdaBoost algorithm, using Support Vector Regression as base model. AdaBoost yielded an average model quality of 0.805 for R2. The predictions and true values are depicted in Fig. 12. One anomaly in the training dataset resulted in a great error, compared to the rest of the predictions. In total, suitable OOT source processes for transfer learning could be predicted by the presented approach. Being able to determine good source models for induced transfer learning may effectively contribute to the reuse of collected manufacturing process data within the Internet of Production and beyond to reduce the costs for generating training data.

LOOCV results for 59 OOT transfer learning results and AdaBoost modeling
Optimized models can then, e.g., be used together with evolutionary algorithms to determine suitable machine setting parameters (Tsai and Luo 2014; Sedighi et al. 2017; Cao et al. 2020). Further validation needs to be done with experimental datasets. Once validated, models need to be transferred into industrial use for a competitive advantage for applying companies. Apt examples are, e.g., assistance systems or modules for simulation software that extend state-of-the-art commercially available software either by raising accuracy or unlocking different fields of applications. Other examples are actively being developed for the open-die forging and laser cutting process.
9 Assistance System for Open-Die Forging Using Fast Models
For the specific adjustment of material properties, during forging a certain temperature window must be maintained and a sufficiently large deformation must be uniformly introduced into the entire workpiece. Therefore, an assistance system was developed at the IBF, which measures the workpiece’s geometry, calculates the component properties, and adjusts the pass-schedule based on these calculations.
Over the last decades, several approaches for assistance systems for open-die forging have been developed. Grisse (Grisse et al. 1997) and Heischeid (Heischeid et al. 2000) presented the software “Forge to Limit”, which can be used to design a process time-optimized pass-schedule. The online capability was demonstrated via the integration of this pass-schedule calculation with a manipulator control. The commercially available system “LaCam” (Kirchhoff et al. 2003; Kirchhoff 2007) from “Minteq Ferrotron Division” measures the current geometry with several lasers and calculates the core consolidation for each stroke. The press operator is given the position of the next stroke with the aim of achieving a homogeneous core consolidation.
In the system shown in Fig. 13, the current geometry is determined with the aid of the current position of the manipulator gripper and cameras, then transferred to a program for calculating the workpiece properties. After comparing actual and target geometry, the program calculates a new pass-schedule, so that process deviations can be corrected continuing the process. The new pass-schedule is transferred to an SQL database developed by “GLAMA Maschinenbau GmbH” on the manipulator’s control computer, which contains the manipulator positions for each stroke of the remaining forging and passes this information to the press operator via a GUI. Therefore, this system architecture thus enables automatic adjustment of the pass-schedule during forging.

Structure of the assistance system for open-die forging
The basis of the assistance system is the knowledge of the current geometry and the current position of the part relative to the open-die forging press. The position of the gripped end of the workpiece corresponds to the position of the manipulator gripper. This is calculated using the inverse kinematics from the measured angles of rotation and cylinder strokes of the 6 axes of the manipulator. However, the position of the free end of the workpiece cannot be obtained from machine data. For this purpose, two HD thermographic cameras by “InfraTec” were positioned laterally and frontally to the forging dies. Edge detection can be used to determine the position of the free end of the part, which, together with the position of the gripped end, provides a very accurate estimate of the touchdown point of the press relative to the forged part. In addition to the workpiece’s position in space, its current geometry is also determined from the camera data. Following the calculation, the detected geometry is drawn in green dashed in the live image, so that the quality of the geometry detection can be checked at any time in the process. Despite the large amount of computation required for the live display, a calculation run in MATLAB takes only 50 ms, so that the measurement frequency is 20 Hz.
The geometry data is passed to models for temperature (Rosenstock et al. 2014), deformation (Recker et al. 2011), and grain size (Karhausen and Kopp 1992) with short calculation times, so that these properties can be calculated and displayed live during the process (Rosenstock et al. 2013). The process can now be optimized on the basis of these results, in this case, using the MATLAB-based algorithm “pattern search”. Figure 14, left, shows the equivalent strain distribution after optimization by the stroke wizard and for a comparative process with bite ratio 0.5 and 50% bite shift after every second pass. The optimization adjusts the bite ratio between 0.45 and 0.55 for each stroke to enable a homogeneous distribution of the equivalent strain without pronounced minima and without fundamentally changing the process parameters. Overall, the minimum equivalent strain can thus be increased from 0.95 to 1.27 while maintaining the same process time. This optimized process planning is transferred to the press operator via a GUI, see Fig. 14, right. There, the current position of the workpiece relative to the dies and the distance to the position of the next stroke are displayed to the press operator to evaluate the program’s suggestion and, if judged necessary, implement it.

Equivalent strain distribution for a normal process and with punch assistant (left) and GUI (right)
10 Development of a Predictive Model for the Burr Formation During Laser Fusion Cutting of Metals
Most laser-based manufacturing processes are characterized by a significant number of processing parameters that directly or indirectly influence the quality of the final product. To help better understand physical sub-processes, optimize process parameters for a specific task or correctly predict product quality, process simulations often must include phase changes, multi-physical interactions as well as largely varying space and time magnitudes (Niessen 2006). Here we present the development of a numerical model for laser cutting, specifically for predicting the formation of burr, a major quality issue for the process. The approach builds on existing software to construct a useful digital model, that can be integrated in meta-modeling methods and used to derive and validate digital shadows of the process.
Laser cutting utilizes multi-kilowatt high-brilliance lasers to cut sheet metal ranging in thickness from 50 μm to over 100 mm. In the interaction zone between laser and metal, a continuous melt flow is produced, driven by a high-pressure co-axial gas jet (e.g., N2). A cut kerf is formed when the laser beam and the gas jet are moved relative to the work piece (see Fig. 15). The melt flows along the cutting front and the cut flanks toward the bottom of the sheet where it is expelled. On the bottom edge of the cut flanks, adhesive capillary forces act against the separation of the melt and can lead to a melt attachment and recrystallization. A residue-free cut is produced when the kinetic energy of the melt flow is sufficiently greater than the adhesion energy on the bottom of the flank. Otherwise, even the adhesion of a small portion of the melt can act as a seed for the formation of long burrs (Stoyanov et al. 2020). Thus, the relation of kinetic and adhesion energies along the separation line, expressed by the Weber number of the flow, can be used to describe the tendency of the process to produce a burr (Schulz et al. 1998).

Laser cutting overview, cross-section through gas nozzle and cut kerf
Apart from the material parameters, the Weber number depends on only two process variables: velocity and depth of the melt flow. To determine their values, a three-step approach proved to be efficient. In the first step, CALCut is used, a laser cutting simulation and process optimization software (Petring 1995). The software is based on a 3D steady-state model of the process. In a self-contained formulation, the model links the sub-processes of laser beam absorption, heat conduction, phase transformations as well as momentum transfer from the gas jet. However, the spatial domain of CALCut includes only the semi-cylindrical cutting front and does not consider melt flow along the cut flank or burr formation. Here, it is used to mainly calculate the geometry of the cutting front and the melt surface temperature as a function of the processing parameters. In the second step, a numerical model is created in the Ansys Fluent simulation environment to extend the numerical domain to include the cut flank and the gas nozzle geometry. We use a two-phase volume-of-fluid model in a pseudo-transient time formulation to simulate the distribution of the supersonic compressible gas flow and its interaction with the melt in the kerf. The melt flows into the simulation domain through an inlet with the shape and temperature as calculated in CALCut. In the third step, the numerical model was experimentally calibrated. The pressure gradients of the gas jet were visualized using a schlieren optical system. This allowed, for instance, a more accurate adjustment of the turbulence and viscosity sub-models as well as the near-wall treatment. The distribution and velocity of the simulated melt flow were experimentally tested using an in-situ high-speed videography. As shown in Fig. 16, the simulation results already show good agreement with experimental investigations.

Simulated (left) and experimentally acquired (right) distribution of the melt outflow
The presented workflow of gathering simulative and experimental data is currently used to produce a multidimensional meta-model of the flow regime dependence to the process parameter. The collected data set will be utilized to create a data-driven reduced model and subsequently a digital shadow of the process, according to the model described in chapter “Integrating Reduced Models and ML to Meta-Modeling Laser Manufacturing Processes”.
Even though assistance systems might be ready to use, the manyfold of solutions from single silos will add up complexity that could confuse the end-users. Thus, a variety of different systems and models may ultimately be agglomerated into a central register or platform. The digital shadow for the previously described service is intended to be designed in such a way that it can be easily integrated into an IOP microservice software infrastructure. On the example of manufacturing process implementing laser technology and based on some previously described research, such a microservice infrastructure is described in the following subchapter.
11 Individualized Production by the Use of Microservices: A Holistic Approach
Many digital shadows for discontinuous processes ranging from simulation over machine learning models as well as data-driven methods were introduced. From a software engineering perspective, these digital shadows can be seen as services or microservices in a discontinuous production process which can be consumed on demand in order to fulfill specific tasks. To this date, the lack of integration of these services has been holding back the possible agility of discontinuous production processes. We propose a holistic approach which exemplarily shows the opportunities of centralized services for laser technology by a software architecture design which allows the quick integration and monitoring of these services.
A main advantage of laser-based manufacturing is that light can be influenced directly and very precisely. In the case of scanner-based manufacturing systems like Ultra Short Pulse Ablation, Laser Powder Bed Fusion, or Laser Battery Welding this advantage becomes apparent since a rise in geometry complexity does not necessarily yield a rise in production costs (Merkt et al. 2012). This “complexity for free” effect could be enhanced further by the integration of pre-validation, simulation, and quality assurance algorithms. The described methods in Chaps. “Fourier Ptychography-Based Imaging System for Far-Field Microscope”, “Integrating Reduced Models and ML to Meta-Modeling Laser Manufacturing Processes”, and Development of a Predictive Model forthe Burr Formation During Laser FusionCutting of Metals are respective examples for these types of algorithms which could potentially be integrated as support services into a laser production process. Transferred to an exemplary digital laser-based manufacturing system, the process would consist of the following steps.
Before running a production process, the usage of one or multiple services which queries previously attained experiments done with specialized monitoring equipment and sensors can be used to define a possible process parameter window for the production setting. The window greatly reduces the possible number of process parameters combination for a defined quality. A typical example for such a service is explained in Chap. 10 where schlieren pictures could be used and pre-analyzed to define a burst rate for USP Lasers or a gas pressure for laser cutting. Afterward, this process window can be reduced to a single parameter set for the manufacturing machine by using simulation services. Here, the process-specific moving path of the laser would be considered as well, leading to more accurate process parameters. Again Chap. 5 contains a detailed description of such a service. The generated process parameters are sent to the machine which is implemented as microservice reachable inside a manufacturing network and the production of the part starts. After the process, an image for quality assurance is generated by calling the quality evaluation service, which connects again to the actuators and sensors of the machine and evaluates and saves the image for further inspection. One of the inspection systems that may be used is described in Chap. 4.
To combine the single services to a joint manufacturing system, a logical job controller has to be introduced which holds the logic of the manufacturing process and organizes data flow. This chapter holds an example architectural overview of such an approach (Fig. 17). The job controller gathers and adapts information delivered by support services (simulation, path generation, process parameter generator) and sends them to the sensor actuator system.
Service-oriented architectures and microservices have been a vital and successful architecture pattern in recent years which allowed large web corporations like Netflix or Google to build and especially run scalable and flexible software systems (Dragoni et al. 2017). This style of architecture is used by industry standards like OPC UA which provide the underlying standardized interfaces for communication, like request/reply communication, service discovery, and some communication security (Jammes et al. 2014). However, these standards do not provide proficient Know-How on the whole service life cycle like deployment, scheduling, updating, access management, etc., which needs to be solved to build a truly adaptable manufacturing machine.
In the Internet of Production, the microservice architecture, dominated by the web industry standards Kubernetes and Docker (Carter et al. 2019) has been evaluated in order to schedule, deploy, update, and monitor manufacturing services. In this architecture, the actual process logic is shifted inside a jobcontroller remotely controlling machines from a data center. In case of resource shortage, new machining edge nodes are added flexibly to the system. One of the main aims of this lab setup is to evaluate the use of Kubernetes and other open source technologies for the use as a shop floor management system. In this scenario, multiple USP Machining Edge Nodes have been connected to a datacenter.
The usage of Kubernetes as a control plane for the USP Machining Edge Nodes and Datacenter Nodes allowed a transparent scheduling and supervision of hardware and support service with the same underlying infrastructure reducing the cognitive load when working with these systems in parallel. However, introducing these architectural patterns through an orchestration system made the system more complex but reduced the effort of adding additional components to the system. Due to the scalability effects, a manufacturing cluster like this could easily be deployed in a manufacturing plant. It poses a suitable foundation for a manufacturing control plane for multiple hundreds of single manufacturing system services. While the initial cost of the infrastructure set up and operation is raised through the use of microservices, the monetary gains from the centralized control plane when building larger system compensate these initial costs (Esposito et al. 2016).

A holistic approach for flexible laser control
12 Conclusion
Efficiency and productivity increase is most relevant in many manufacturing environments. Changing customer demands and tendencies toward smaller tolerances and higher process transparency force companies to adapt their own production. A deeper understanding of the specific processes and therefore the possibility to succeed in a continuous improvement process may be significantly influenced by the change introduced by Industry 4.0: Increased data availability due to new sensors, efficient data transfer protocols or easy cloud-based data storage guides much research interest toward the integration and pairing of digital methods with traditional manufacturing processes to achieve the mentioned objectives.
For a variety of discontinuous processes, a common procedure toward achieving higher production efficiency and productivity has been described. Shared challenges in the stages like problem definition, parameter and data definition and gathering, model design and order reduction, model training and usage as well as deployment of mature assistance systems were identified. Based on different manufacturing technologies, possible solutions and their general applicability for similar process technologies are shown. Especially the application of machine learning methods for an accurate representation of complex manufacturing processes across different domains appears to be a promising approach toward productivity increase. Once mature, bespoken models and approaches need to be transferred into production.
While successful use cases and process-specific solutions, e.g., for data acquisition and processing or model order reduction, for process modeling can be found across manufacturing technologies, an abstract, holistic procedure for process optimization for discontinuous processes as well as a common data structure has not yet been described. Future research in the Internet of Production will focus on the transferability of the previously described solutions for easy integrability in other discontinuous process technology and therefore increase future innovation potential.
References
Abiodun OI, Jantan A, Omolara AE, Dada KV, Mohamed NA, Arshad H (2018) State-of-the-art in artificial neural network applications: a survey. Heliyon 4:e00938
Atkinson G, O’Hara Nash S, Smith L (2021) Precision fibre angle inspection for carbon fibre composite structures using polarisation vision. Electronics 10(22):Article 2765
Bobzin K, Öte M (2016) Modeling multi-arc spraying systems. J Therm Spray Technol 25(5):920–932
Bobzin K, Öte M, Schein J, Zimmermann S, Möhwald K, Lummer C (2016) Modelling the plasma jet in multi-arc plasma spraying. J Therm Spray Technol 25:1111–1126
Brasington A, Sacco C, Halbritter J, Wehbe R, Harik R (2021) Automated fiber placement: a review of history, current technologies, and future paths forward. Composites Part C: Open Access 6:Article 100182
Brecher C, Jeschke S, Schuh G, Aghassi S, Arnoscht J, Bauhoff F, Fuchs S, Jooß C, Karmann O, Kozielski S, Orilski S, Richert A, Roderburg A, Schiffer M, Schubert J, Stiller S, Tönissen S, Welter F (2011) Integrative Produktionstechnik für Hochlohnländer. In: Brecher C (ed) Integrative Produktionstechnik für Hochlohnländer. Springer Verlag, Berlin/Heidelberg
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Cao Y, Fan X, Guo Y, Li S, Huang H (2020) Multi-objective optimization of injection-molded plastic parts using entropy weight, random forest, and genetic algorithm methods. J Polym Eng 40(4):360–371
Carter E, Hernadi F, Vaughan-Nichols SJ, Ramanathan K, Ongaro D, Ousterhout J, Verma A, Pedros L, Korupolu MR, Oppenheimer D (2019) Sysdig 2019 container usage report: new kubernetes and security insights. Sysdig, Inc., San Francisco, USA
Chakrabarti A, Sukumar R, Jarke M, Rudack M, Buske P, Holly C (2021) Efficient modeling of digital shadows for production processes: a case study for quality prediction in high pressure die casting processes. In: 2021 IEEE international conference on data science and advanced analytics: DSAA 2020, Porto, Portugal
Chen S, Xu T, Zhang J, Wang X, Zhang Y (2019) Optimized denoising method for fourier ptychographic microscopy based on wirtinger flow. IEEE Photon J 11(1):1–14
Dong S, Horstmeyer R, Shiradkar R, Guo K, Ou X, Bian Z, Xin H, Zheng G (2014) Aperture-scanning Fourier ptychography for 3D refocusing and super-resolution macroscopic imaging. Opt Express 22(6):13586–13599
Dragoni N, Giallorenzo S, Lafuente AL, Mazzara M, Montesi F, Mustafin R, Safina L (2017) In: Mazzara M, Meyer B (eds) Microservices: yesterday, today, and tomorrow. Present and ulterior software engineering. Springer International Publishing, New York, pp 195–216
Du H, Lee S, Shin J (2005) Study on porosity of plasma-sprayed coatings by digital image analysis method. J Therm Spray Technol 14(12):453–461
Enns D (1984) Model reduction for control system design, NASA contractor report NASA CR-170417. Stanford Universität
Esposito C, Castiglione A, Choo K-KR (2016) Challenges in delivering software in the cloud as microservices. IEEE Cloud Comput 3(5):10–14
Freund Y, Schapire RE (1997) A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55:119–139
Garcia D, Courbebaisse G, Jourlin M (2001) Image analysis dedicated to polymer injection molding. Image Anal Stereol 20(11):143–158
Grisse H-J, Betz H, Dango R (1997) Computer optimized integrated forging. In: 13th international forgemasters meeting: advances in heavy forgings, University of Park, Pusan, Korea
Hastie T, Tibshirani R, Friedman J (2008) Boosting and additive trees. The elements of statistical learning. Springer, New York, pp 337–387
Heischeid C, Betz H, Dango R (2000) Computerised optimisation of the forging on a 3300 tons open die forging press. In: 14th international forgemasters meeting. V. D. Eisenhüttenleute, Wiesbaden, pp 132–136
Hermanns T (2018) Interaktive Prozesssimulation fur das industrielle Umfeld am Beispiel des Bohrens mit Laserstrahlung
Jammes F, Karnouskos S, Bony B, Nappey P, Colombo A, Delsing J, Eliasson J, Kyusakov R, Stluka P, Tilly M, Bangemann T (2014) Promising technologies for SOA-based industrial automation systems. In: Colombo A, Bangemann T, Karnouskos S et al (eds) Industrial cloud-based cyber-physical systems: the IMC-AESOP approach. Springer Interntional Publishing, New York
Johannaber F, Michaeli W (2004) Handbuch Spritzgießen. Carl Hanser Verlag, München
Karhausen K, Kopp R (1992) Model for integrated process and microstructure simulation in hot forming. Steel Res 63(6):247–256
Kirchhoff S (2007) Patent US 7,281,402 B2
Kirchhoff S, Lamm R, Müller N, Rech R (2003) Laser measurement on large open die forging (LaCam Forge). In: 15th international forgemasters meeting. Steel Castings and Forgings Association of Japan. Kobe, Japan
Li H, Luo Z, Chen J (2011) Numerical simulation based on POD for two-dimensional solute transport problems. Appl Math Model 35(5):2498–2589
Li X, Hallett SR, Wisnom MR (2015) Modelling the effect of gaps and overlaps in automated fibre placement (AFP)-manufactured laminates. Sci Eng Compos Mater 22(5):115–129
Lockner Y, Hopmann C (2021) Induced network-based transfer learning in injection molding for process modelling and optimization with artificial neural networks. Int J Adv Manuf Technol 112(11–12):3501–3513
Lockner Y, Hopmann C, Zhao W (2022) Transfer learning with artificial neural networks between injection molding processes and different polymer materials. J Manuf Process 73:395–408
Mahnke W, Leitner S-H, Damm M (2009) OPC unified architecture. Springer, Berlin/Heidelberg
Merkt S, Hinke C, Schleifenbaum H, Voswinckel H (2012) Geometric complexity analysis in an integrative technology evaluation model (ITEM) for selective laser melting (SLM). S Afr J Ind Eng 23(10):97–105
N.N (2013) International electrotechnical vocabulary – part 351: control technology, IEC 60050–351:2013. Beuth, Berlin
Niessen M (2006) Numerische Modellierung freier Randwertaufgaben und ihre Anwendung in der Lasermaterialbearbeitung
Öte M (2016) Understanding multi-arc plasma spraying. Shaker Verlag
Pal KK, Sudeep KS (2016) Preprocessing for image classification by convolutional neural networks. In: 2016 IEEE international conference on recent trends in electronics, information communication technology (RTEICT). IEEE, New York
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22:1345–1359
Pardoe D, Stone P (2010) Boosting for regression transfer. In: 27th international conference on machine learning, Haifa, Israel
Petring D (1995) Anwendungsorientierte Modellierung des Laserstrahlschneidens zur rechnergestützten Prozeßoptimierung
Rackauckas C, Edelman A, Fischer K, Innes M, Saba E, Shah VB, Tebbutt W (2020) Generalized physics-informed learning through language-wide differentiable programming. CEUR Workshop Proc 2587:Article 8
Recker D, Franzke M, Hirt G (2011) Fast models for online-optimization during open die forging. CIRP Ann Manuf Technol 60:295–298
Rosenstock D, Recker D, Hirt G, Steingeißer K-J, Rech R, Gehrmann B, Lamm R (2013) Application of fast calculation model for the process monitoring of open die forging processes. Key Eng Mater 554–557:248–263
Rosenstock D, Recker D, Hirt G (2014) Online analysis of cogging processes – evaluation of the equivalent strain. Temperature and grain size distribution. In: 19th international forgemasters meeting. Steel Castings and Forgings Association of Japan. Tokyo Bay Area, Japan, pp 507–512
Rudack MR, Rath M, Vroomen U, Bührig-Polaczek A (2022) Towards a data lake for high pressure die casting. Metals 349(12):1–11
Sankhye S, Hu G (2020) Machine learning methods for quality prediction in production. Logistics 4(12):35
Schuh G, Prote JP, Gützlaff A, Thomas K, Sauermann F, Rodemann N (2019) In: Wulfsberg JP, Hintze W, Behrens BA (eds) Internet of production: rethinking production management. Production at the leading edge of technology. Springer Vieweg, Berlin/Heidelberg, pp 533–542
Schulz W, Kostrykin V, Niessen M, Michel J, Petring D, Kreutz EW, Poprawe R (1998) Dynamics of ripple formation and melt flow in laser beam cutting. J Phys D Appl Phys 32(11):1219–1228
Schulz W, Eppelt U, Popraw R (2013) Review on laser drilling I. Fundamentals, modeling, and simulation. J Laser Appl 25:012006
Sedighi R, Meiabadi MS, Sedighi M (2017) Optimisation of gate location based on weld line in plastic injection moulding using computer-aided engineering, artificial neural network, and genetic algorithm. Int J Automot Mech Eng 14(3):4419–4431
Stoyanov S, Petring D, Arntz-Schroeder D, Günder M, Gillner A, Poprawe R (2020) Investigation on the melt ejection and burr formation during laser fusion cutting of stainless steel. J Laser Appl 32:022068
Tsai K-M, Luo H-J (2014) An inverse model for injection molding of optical lens using artificial neural network coupled with genetic algorithm. J Intell Manuf 28(2):473–487
Wang Y (2021) Reduced modelling for laser drilling process in melt expulsion regime. Apprimus Verlag, Aachen
Wang Y, Tercan H, Thiele T, Meisen T, Jeschke S, Schulz W (2017) Advanced data enrichment and data analysis in manufacturing industry by an example of laser drilling process. In: Challenges for a data-driven society. ITU Kaleidoscope Academic Conference 2017, Proceedings. IEEE, Piscataway
Weiss K, Khoshgoftaar TM, Wang D (2016) A survey of transfer learning. J Big Data 3(9):1–40
Woodworth RS, Thorndike EL (1901) The influence of improvement in one mental function upon the efficiency of other functions. Psychol Rev 8(3):247–261
Zhao P, Hoi SCH, Wang J, Li B (2014) Online transfer learning. Artif Intell 216:76–102
Zheng G, Horstmeyer R, Yang C (2013) Wide-field, high-resolution Fourier ptychographic microscopy. Nat Photonics 7(9):739–745
Acknowledgments
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2023 Internet of Production – 390621612.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this entry

Cite this entry
Lockner, Y. et al. (2023). Improving Manufacturing Efficiency for Discontinuous Processes by Methodological Cross-Domain Knowledge Transfer. In: Brecher, C., Schuh, G., van der Aalst, W., Jarke, M., Piller, F.T., Padberg, M. (eds) Internet of Production. Interdisciplinary Excellence Accelerator Series. Springer, Cham. https://doi.org/10.1007/978-3-030-98062-7_8-1
Download citation
DOI: https://doi.org/10.1007/978-3-030-98062-7_8-1
Received:
Accepted:
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-98062-7
Online ISBN: 978-3-030-98062-7
eBook Packages: Springer Reference EngineeringReference Module Computer Science and Engineering