Efficiently solving tri-diagonal system by chunked cyclic reduction and single-GPU shared memory Di ZhaoJinhang Yu OriginalPaper 20 September 2014 Pages: 369 - 390
Enabling energy-proportional computing on instruction-level parallel processors Yung-Cheng MaWen-Shih ChaoTse-An Liu OriginalPaper 05 October 2014 Pages: 391 - 447
Energy-efficient adaptive networked datacenters for the QoS support of real-time applications Nicola CordeschiMohammad ShojafarEnzo Baccarelli OriginalPaper 17 October 2014 Pages: 448 - 478
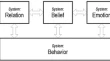
Multicore and FPGA implementations of emotional-based agent architectures Carlos DomínguezHoucine HassanJosé Albaladejo OriginalPaper 17 October 2014 Pages: 479 - 507
Modeling flow information of loops using compositional condition of controls Saeed ParsaMehdi Sakhaei-nia OriginalPaper 18 October 2014 Pages: 508 - 536
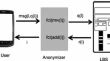
Direct private query in location-based services with GPU run time analysis Charles AsanyaRatan Guha OriginalPaper 30 October 2014 Pages: 537 - 573
A dual speed scheme for dynamic voltage scaling on real-time multiprocessor systems Sangchul HanMinkyu ParkMoonju Park OriginalPaper 11 October 2014 Pages: 574 - 590
H-PC: a cloud computing tool for supervising hypertensive patients Jordi VilaplanaFrancesc SolsonaJosep Rius OriginalPaper 18 October 2014 Pages: 591 - 612
Accelerating HEVC using heterogeneous platforms Gabriel Cebrián-MárquezJosé Luis Hernández-LosadaJiangtao Wen OriginalPaper 18 October 2014 Pages: 613 - 628
Two-stage distributed parallel algorithm with message passing interface for maximum flow problem Jincheng JiangLixin Wu OriginalPaper Open access 31 October 2014 Pages: 629 - 647
A parallel local search in CPU/GPU for scheduling independent tasks on large heterogeneous computing systems Santiago IturriagaSergio NesmachnowEnrique Alba OriginalPaper 26 October 2014 Pages: 648 - 672
Modeling and predicting measured response time of cloud-based web services using long-memory time series Hossein NourikhahMohammad Kazem AkbariMohammad Kalantari OriginalPaper 29 October 2014 Pages: 673 - 696
Scalable crossbar network: a non-blocking interconnection network for large-scale systems Fathollah BistouniMohsen Jahanshahi OriginalPaper 29 October 2014 Pages: 697 - 728
Financial applications on multi-CPU and multi-GPU architectures Emilio CastilloCristóbal CamareroJose Luis Bosque OriginalPaper 05 November 2014 Pages: 729 - 739
Extending lyapack for the solution of band Lyapunov equations on hybrid CPU–GPU platforms Peter BennerAlfredo RemónEnrique S. Quintana-Ortí OriginalPaper 09 November 2014 Pages: 740 - 750
MIMOPack: a high-performance computing library for MIMO communication systems Carla RamiroAntonio M. VidalAlberto Gonzalez OriginalPaper 05 December 2014 Pages: 751 - 760