
Abstract
Magnetic resonance imaging (MRI) is an inherently slow imaging modality, since it acquires multi-dimensional k-space data through 1-D free induction decay or echo signals. This often limits the use of MRI, especially for high resolution or dynamic imaging. Accordingly, many investigators has developed various acceleration techniques to allow fast MR imaging. For the last two decades, one of the most important breakthroughs in this direction is the introduction of compressed sensing (CS) that allows accurate reconstruction from sparsely sampled k-space data. The recent FDA approval of compressed sensing products for clinical scans clearly reflect the maturity of this technology. Therefore, this paper reviews the basic idea of CS and how this technology have been evolved for various MR imaging problems.
Similar content being viewed by others


Background
Magnetic resonance imaging (MRI) exploits the nuclear magnetic resonance (NMR) phenomena to enable high contrast imaging. Since the first observation of NMR absorption in a molecular beam in 1938, the main research thrust was to understand and utilize the NMR phenomena for spectroscopy applications. Then, Lauterbur introduced in 1973 the gradient field to encode the spatial origin of the radio waves emitted from the nuclei of the object. This breakthrough allowed for multi- dimensional imaging by NMR physics.
The idea of Lauterbur can be easily understood using k-space interpretation that describes MR sampling as Fourier encoding in 2D or 3D spaces. Specifically, data collected by an MRI scanner are samples of the spatial Fourier transform of an object image. Hence, in order to obtain an image without aliasing artifacts, k-space samples need to satisfy the Nyquist sampling criterion.
Despite this close link to signal sampling theory, until the first demonstration of the sensitivity encoding (SENSE) technique by Prussemann [1], MR imaging was not considered as an important research topic for signal processing. Specifically, Prussemann et al. [1] showed that spatial diversity information from coil sensitivity maps have additional information that can be exploited for fast signal acquisition. Furthermore, Sodickson et al. [2] proposed the simultaneous acquisition of spatial harmonics (SMASH). These works gave a birth of parallel imaging and iterative reconstruction methods, and has resulted in a flurry of novel ideas and algorithms, including Generalized Autocalibrating Partially Parallel Acquisitions (GRAPPA) by Griswold [3] and k-t space method for cardiac imaging such as [4,5,6,7,8,9].
The common theme in these approaches is that the data redundancy can be exploited to reduce the required sampling rate. Because redundant data can be compactly represented in some transform domains, it is also closely related to the concept of “sparsity”. Originally investigated by Bresler and his students for on- the-fly Fourier imaging [10, 11], the sparsity regularization has become the main workhorse in modern accelerated MRI researches thanks to the introduction of the compressed sensing theory [12, 13]. Ever since the first demonstration of compressed sensing MRI by Lustig et al. [14, 15], the compressed sensing MRI has become the essential tools in modern MR imaging researches. In this paper, we will review these ideas in more detail.
Main text
MR forward models
Before we introduce the concept of compressed sensing MR, we begin with the discussion of MR forward model. Mathematically, the forward model for k-space measurement can be described by.
where r ∈ R^d and k ∈ Rd, d = 2, 3 denote the image domain and k-space coordinates, respectively, C is the number of the coil and the i-th coil image γi is given by
Here, ν(r) denotes the contrast weighted bulk magnetization distribution, and si(r) is the corresponding coil sensitivity of the i-th coil. Although the expression may give an impression that the measurement is two- or three- dimensional, this is indeed originated from a 1-D measurement since the k-space trajectory is a function of time, i.e. k:= k(t), and we acquire one k-space sample at each time point t. This makes the MR imaging inherently slow, since we need to scan through a 3-D object via 1-D trajectories.
Dynamic MRI is another important MR technique to monitor dynamic processes such as brain hemodynamics and cardiac motion. Among the various forms of dy- namic MR modeling, here we mainly focus on the k-t formulation. Specifically, consider a discrete imaging equation for cartesian trajectory for simplicity. Because the samples along the readout direction are fully sampled, most of the dynamic MR formulation is applied separably after taking the Fourier transform along the read- out direction. More specifically, let γ(s, t) denote the unknown image content (for example, proton density, T1/T2 weighted image, etc.) on the spatial coordinate s along the phase encoding line at time instance t. Then, the k-t space measurement b(k, t) at time t is given by
where γ(s, t) is the spatio-temporal image which may be weighted by coil sensitivity map for the case of parallel imaging.
Throughout the paper, for simplicity we often use the operator notation for (1):
where [Si] is a diagonal operator comprised of the i-th coil sensitivity. Similarly, we use operator notation for (3).
or
for the case of parallel imaging.
Compressed sensing theory
Performance guarantees
Compressed sensing (CS) theory [12, 16, 17] addresses the accurate recovery of unknown sparse signals from underdetermined linear measurements and has become one of the main research topics in the signal processing area for the last two decades [18,19,20,21,22,23]. Most of the compressed sensing theories have been developed to address the so-called single measurement vector (SMV) problems [12, 16, 17]. More specifically, let m and n be positive integers such that m < n. Then, the SMV compressive sensing problem is given by
where y ∈ R^m, A ∈ R^m\×n, x ∈ R^n, and ϵ denotes the noise level. (P0) implies that the solution favours the sparsest solution.
Since (P0) requires a computationally expensive combinatorial optimization, greedy methods [24], reweighted norm algorithms [25, 26], or convex relaxation using the l1 norm [12, 27] have been widely investigated as alternatives. In particular, the convex relaxation approach addresses the following l1 minimization problem:
One of the important theoretical tools of CS is the so-called restricted isometry property (RIP), which enables us to guarantee the robust recovery of certain input signals [17]. More specifically, a sensing matrix \( \mathrm{A}\in {\mathrm{R}}^{m\times \mathrm{n}} \) is said to have a k- restricted isometry property (RIP) if there is a constant 0 ≤ δk < 1 such that
for all x ∈ R^n with ||x||0 ≤ k. It has been demonstrated that δ2k < \( \sqrt{2}-1 \) is sufficient for l1/l0 equivalence [12]. For many classes of random matrices, the RIP condition is satisfied with high probability if the sampling pattern is incoherent and the number of measurements satisfies m ≥ ck log(n/k) for some constant c > 0 [17].
Optimization approaches
In practice, the following unconstrained form of optimization problem is often used:
where y is noisy measurement, λ is the regularization parameter, and Ψ refers to an analysis transform such that Ψx becomes sparse. Note that for the special case of Ψ = I, (8) is reduced to (P1).
One of the technical issues in solving (8) is that the cost function is not smooth at Ψx = 0, which makes the corresponding gradient ill-defined. This leads to the development of various techniques, which are culminated as the new type of convex optimizaton theory called proximal optimization [28]. For example, the popular op- timization methods such as forward-backward splitting (FBS) [29], split Bregman iteration [30], alternating directional method of multiplier (ADMM) [31], Douglas- Rachford splitting algorithm [32], and primal-dual algorithm [33] have been devel- oped to solve compressed sensing problems. However, the comprehensive coverages of these techniques deserves another review paper, so in this section we mainly review the ADMM algorithms which have been extensively used for compressed sensing MRI ever since its first introduction to compressed sensing MRI [34].
More specifically, we convert the problem (8) to the following constraint problem:
subject to
Then, the associated ADMM is given by
Now, each step of ADMM has a closed-form solution. Algorithm 1 summarises the resulting ADMM iteration, where shrink1 denotes the soft-tresholding:
for the threshold value τ > 0.
In addition to the analysis prior in (8), the total variation (TV) penalty has been also extensively used for imaging applications, because the finite difference operator

can sparsify smooth images. Specifically, the TV minimisation problem assumes the following form:
where T V (x) is given by
where ‖∙‖1, p, p = 1, 2 deotes the l1/lp-mixed norm. In d-dimensional space (e.g. d = 2 for images), the discretized implementation can be defined as
where ∇x(i) ∈ Rd denotes the gradient of x at the i-th coordinate and n denotes the number of discretizated samples.
In order to apply ADMM for (12), we need to focus on the primal formulation of the total variation penalty:
Now, we define a splitting variable u(i) = ∇x(i) ∈ Rd. Then, the constraint opti- mization formulation is given by
Then, the associated ADMM is given by
Each step has the closed form expression. Algorithm 2 summarises the TV-ADMM algorithm, where shrinkvec,2(x) for x ∈ Rd denotes the vector shrinkage [34]:
for the threshold value τ > 0.

Basic MR ingredients for compressed sensing
In order to apply compressed sensing theory for specific imaging applications, the unknown signal should be sparse in some transform domain, and the sensing matrix should be sufficiently incoherent. This section shows why these conditions can be readily satisfied in MR imaging, which is one of the main reasons that allows for successful applications of CS theory to MR imaging.
Sparsity of MR images
An MR image is rarely sparse in its own. However, one of the important observations that led to the successful applications of CS to MR is that the sparsity is closely related to signal redundancies. This is because redundant signals can be easily converted to sparse signals using some transforms.
Basically, there are three major directions that have been investigated in com- pressed sensing MRI: 1) the spatial domain redundancy, 2) the temporal domain redundancy, and 3) the coil domain redundancy. For example, as shown in Fig. 1(a), natural images can be sparsely represented in finite difference or wavelet transform domain, although the image is not sparse in its own. This observation is the main idea that allows for total variation (TV) and wavelet transform approaches for image denoising, and reconstruction. Accordingly, TV and wavelets have been the main transforms that have been extensively used in most of the CS MRI researches. On the other hand, dynamic MR images such as cardiac cine, functional MRI, and MR parameter mapping have significant redundancy along the temporal dimension as shown in Fig. 1(b). For example, if the image is perfectly periodic, then temporal Fourier transform may be the optimal transform to sparsify the signal. However, in many dynamic MR problems, the temporal variations are dependent on the MR physics as well as specific motion of organs, so the analytic transform such as Fourier transform may not be an optimal solution, but more data-driven approaches such as PCA or dictionary learning are better options. Indeed, these observation leads to dictionary learning approaches that will be discussed later.

Various types of sparsity in MRI. (a) Sparsity from spatial domain redundancy, (b) Sparsity from temporal redundancy, and (c) sparsity from mu.ti-channel redundancy
On the other hand, the coil redundancy is somewhat distinct compared to the spatial- and temporal- domain redundancy. As shown in Fig. 1(c), the redundancy of the coil image stems from the underlying common images, which results in cross- channel redundancies:
where si denotes the i-th coil sensitivity map and γi is the coil image. The rela- tionship in (18) is easy to show since the coil image is given by (2). The main idea of the classical parallel MRI is to exploit this relationship. Specifically, the sensi- tivity encoding (SENSE) [1] exploits the image domain redundancy described in (18), whereas the k-space domain approaches such as GRAPPA [3] exploits its dual relationship in the k-space:
where ∗ denotes the convolution, and \( {\widehat{s}}^j \), \( {\widehat{\gamma}}^j \)enote the Fourier transform of sjand γjrespectively. Later we will describe how these two expressions of the coil dimensional redundancies have been exploited in compressed sensing MRI.
Incoherent sampling pattern
In compressed sensing MRI, downsampling pattern is very important to impose the incoherence, but its realization is limited by MR physics. For example, in the 2-D acquisition, the readout direction should be fully sampled, so there is only freedom along the phase encoding direction in designing incoherence sampling patterns. Figure 2(a)-(c) shows the examples of realizable sampling patterns that have been exploited in the literature: a) cartesian undersampling, b) radial trajectory, and c) spiral trajectory. In particular, the radial and spiral trajectories, which have been studied even before the advanced of the compressed sensing [35], have more incoherent radial sampling patterns compared to the cartesian undersampling.

Various under-sampling patterns: (a) Cartesian undersampling, (b) radial undersampling, and (c) spiral undersampling
On the other hand, if we deal with 3-D imaging or dynamic imaging, there are more rooms for sampling pattern design, since there are two dimensional degree of freedom. Figure 2(d) shows an example of 2-D random sampling pattern. For the case of wavelet transform-based sparsity imposing prior, Lustig et al. [14] showed that the incoherence can be optimized by generalizing the notion of PSF to Transform Point Spread Function (TPSF). Specifically, TPSF measures how a single transform coefficient of the underlying object ends up influencing other transform coefficients of the measured undersampled object. To calculate the TPSF, a single point in the wavelet transform space at the i-th location is transformed to the image space and then to the Fourier space. Once the corresponding Fourier space data is subsampled by the given downsampling pattern, its influence in the wavelet transform domain can be calculated by taking inverse transform followed by the inverse wavelet trans- form. To have the best incoherence property, the side of TPSF should be as small as possible, such that the side lobe contribution can be removed by shrinkage op- eration. This was used as the main criterion for sampling pattern design.
Historical milestones
The earliest application of the compressed sensing for MRI was done by Lustig and his collaborators [14]. The application of CS to dynamic MRI was pioneered by Jung et al. [18] and Gamper et al. [36], which was later significantly improved by Jung et al. [20]. The positive results of these earlier works have resulted in flurry of new ideas in static and dynamic MRI.
In terms of combining CS with parallel imaging, the first application for static imaging was done by Block et al. [37] by combining total variation penalty and parallel imaging; and by Liang et al. [38] in more general form using SENSE. In dynamic imaging, the works by Jung et al. [18] and Feng et al. [39] are among the first that combine the SENSE type parallel imaging with the k-t domain compressed sensing. Combination with CS and parallel imaging using GRAPPA type constraints was pioneered by Lustig et al. [40]. Coil compression techniques have been also investigated to reduce the number of coils for CS reconstruction [41]. Feng et al. [42] later combined compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI, which has been approved for clinical use.
Aside from the standard l1 and TV penalty, several innovative sparsity inducing penalty have been used for compressed sensing MRI. For example, Trzasko et al. [43, 44] proposed a direct l0 mimimization approaches, whereas Knoll et al. [45, 46] proposed a generalized total variation approaches, and Sung et al. [47] combined the approximate message passing algorithm with parallel imaging. This idea was then extended to the dictionary learning [20, 48, 49] and motion compensation [20, 50]. Then, the idea of low-rank regularization was soon introduced [49, 51,52,53] thanks to the theoretical advances by Candes et al. [54]. The low-rank idea was further ex- tended to structured low-rank approach for parallel imaging [55] and single coil imaging with the finite support [56]. The duality between the compressed sensing and low-rank Hankel matrix approaches were discovered by Jin and his colleagues [57,58,59,60] and Ongie et al. [61]. In particular, the unified framework for compressed sensing and parallel MRI in terms of low-rank Hankel matrix approaches was presented by Jin et al. [57] and its theoretical performance guarantees was also given in [62].
In the following, we provide more detailed reviews of these historical milestones in compressed sensing MRI.
Basic formulation of compressed sensing MRI
Although some MR images such as angiograms are already sparse in the pixel representation, more complicated images are rarely sparse, but only have a sparse representation in some transform domain, for example, in terms of spatial finite- differences or their wavelet coefficients. Based on this observation, Lustig et al. [14] proposed the first compressed sensing MRI using spatial domain wavelet transform as a sparsifying transform. More specifically, the problem is formulated as
where ‖∙‖1 denotes the l1 norm, F is the Fourier transform, γ denotes the 2-D complex image, Ψ is a either finite difference or spatial wavelet transform, D is the downsampling pattern, and y is the downsampled k-space measurement. Eq. (20) was solved using a nonlinear conjugate gradient method.
The resulting optimization algorithms are, however, computational expensive. For cartesian sampling trajectory, this problem can be overcome as follows. Specifically, the image update step for (20) in ADMM implementation can be summarized as
which is computationally expensive due to the matrix inverse to obtain γ. Instead of using a direct matrix inverse, by multiplying the Fourier transform F to both sides, we have
where \( \widehat{\gamma}=F\upgamma \). Note that a diagonal matrix D*D consisting of ones and zeros. The ones are at those diagonal entries that corresponds to the sampled locations in the k-space. Let Ω denote the sampled location. Then,
where PΩ and PΩc denotes the projection on the sampling location Ω and its com- plement Ωc, respectively. Then, the image update γ(k + 1)can be simply done by taking the fast Fourier transform (FFT).
The first experimental demonstration by Lustig et al. [14] clearly confirmed the efficiency of the compressed sensing algorithm, which has led to many other CS approaches using various sparsifying transform, and optimization algorithms, etc. For example, to deal with several hyperparameters to trade off between sparsity and data fidelity terms. Many research efforts have been made to quantity such trade- off, provide different forms of reconstruction, even to propose hyperparameter free reconstruction method [63,64,65,66,67,68,69,70].
Advanced formulation for compressed sensing MRI
Non-Cartesian compressed sensing MRI
Compressed sensing with non Cartesian sampling has been also extensively stud- ied, since they are really a great combination given the sampling behavior of non Cartesian sampling schemes and the incoherence requirement in compressed sens- ing reconstruction. Aside from the radial and spiral sampling patterns discussed before, the works in [71,72,73,74,75,76,77,78,79,80,81,82,83] have fo- cused on designing better sampling trajectories with good incoherent properties. For example, Haldar et al. [82] and Puy et al. [83] proposed random phase encod- ing scheme to maximize the incoherency of the sensing matrix. However, one of the main technical issues associated with non-cartesian compressed sensing MRI is that the fast reconstruction trick shown in (21) cannot be used, which increases the overall computational time.
Combination of parallel imaging with CS
Recall that parallel MRI (pMRI) [1, 3] exploits the diversity in the receiver coil sen- sitivity maps that are multiplied by an unknown image. This provides additional spatial information for the unknown image, resulting in accelerated MR data acquisition through k-space sample reduction. Because the aim of the parallel imaging and CS approaches is similar, extensive research efforts have been made to syner- gistically combine the two for further acceleration [18, 20, 38, 40, 84].
One of the most simplest approaches can be a SENSE type approach that explic- itly utilizes the estimated coil maps to obtain an augmented compressed sensing problem [18, 20, 38, 84]. More specifically, if the coil sensitivity is known and given by the sensitivity[Si], i = 1, ⋯, C,then the SENSE type compressed sensing MRI problem can be formulated as
The optimization framework is the standard optimization framework under sparsity constraint, so proximal optimization algorithms can be used to solve this problem.
On the other hand, l1-SPIRiT (l1-iTerative Self-consistent Parallel Imaging Re- construction) [40] utilizes the GRAPPA type constraint as an additional constraint for a compressed sensing problem:
where M is an image domain GRAPPA operator. In both approaches, an accurate estimation of coil sensitivity maps or GRAPPA kernel is essential to fully exploit the coil sensitivity diversity. To address this problem, Uecker et al. [85] developed a novel eigen space method to extract the coil sensitivity maps directly from the k-space data, which is one of the most popular methods widely used by MR researchers.
Blind compressed sensing MR using dictionary learning
Blind compressed sensing approaches attempted to simultaneously reconstruct the underlying image as well as the sparsifying transform from highly undersampled measurements. Ravishankar and his colleagues pioneered two distinct approaches - synthesis dictionary learning [48] and analysis transform learning [86] - when the underlying sparsifying transform is unknown a priori.
Synthesis dictionary-based BCS
More specifically, let Pj, j = 1 …, N represents the operator that extracts a m- dimensional patch as a vector Pjx ∈ Cm from the image x, where N denotes the number of patches. Then, dictionary learning is to find the unknown dictionary \( D\in {\mathrm{R}}^{m\times \mathrm{Q}} \) and the corresponding sparse coefficient matrix \( C\in {\mathrm{C}}^{m\times \mathrm{n}} \) such that Y = DC, where Y = [P1x P2x…, PNx]
The synthesis model allows each patch Pjx to be approximated by a linear combina- tion Dcj of a small number of columns from a dictionary \( D\in {\mathrm{C}}^{n\times \mathrm{K}} \), where cj ∈ CK is sparse. The columns of the learnt dictionary (represented by dk, 1 ≤ k ≤ K) in (P0) are additionally constrained to be of unit norm in order to avoid the scaling ambiguity. The dictionary, and the image patch, are assumed to be much smaller than the image. This model can be used as a signal model, and Ravishankar et al. [48] proposed the following patch-based dictionary learning regularizer:
where Cj and dj denotes the j-th column of C and D, respectively. Then, the associated BCS formulation is given by
where A: = DF denotes the downsampled Fourier transform.
To address the optimization problem (P0), Ravishankar et al. [48] employed the following two-step alternating minimization algorithm. First, the following mini- mization problem is solved by fixing x:
The K-SVD algorithm [87] was used to learn the dictionary. For a given dictionary
D, the image update can be done by
These steps are alternated until convergence. The dictionary learning MRI have shown superior image reconstructions for MRI, as compared to non-adaptive compressed sensing schemes.
Sparsifying transform-based BCS
However, the BCS Problem (P0) is both non-convex and NP-hard. Approximate iterative algorithms for (P0) typically solve the synthesis sparse coding problem re- peatedly, which makes them computationally expensive. In order to overcome some of the aforementioned drawbacks of synthesis dictionary-based BCS, Ravishankar et al. [86] proposed to use the sparsifying transform model in this work. Sparsify- ing transform learning has been shown to be effective and efficient in applications, while also enjoying good convergence guarantees. Specifically, they used the follow- ing transform learning regularizer:
where W ∈ C^{m\× m} denotes the unknown transform, the function Q(W) is a regualizer for the transform given by
The − log |detW| penalty eliminates degenerate solutions such as those with repeated rows. The ‖W‖Fpenalty helps remove a scale ambiguity in the solution.
Then, with additional constraint ‖x‖ ≤ E, the overall optimization problem is given by
where A = DF again denotes the downsampled Fourier transform. One of the important advantages of (P1) is that there exists a closed-form update for W, so the computationally expensive dictionary learning step can be avoided.
K-t methods for compressed sensing dynamic MRI
Dynamic MRI is a technique to acquire temporally varying MR sequences such as cardiac cine, perfusion, time-resolved angiography, functional MRI, etc. In dynamic MRI, there exists significant redundancies along the temporal directions, which can be extensively studied in various compressed sensing approaches.
k-t SPARSE
The k-t SPARSE by Lustig et al. [88] is an earliest version of compressed sensing dynamic MRI. Recall that the k-space measurement b(k, t) at time t is given by
Another application of the Fourier transform along the temporal direction
results in the following 2-D Fourier relationship:
where ρ(s, f) denotes the temporal Fourier transform of γ(s, t).
Note that p(s, f) is usually sparse because the periodic motions from heart or slow varying motions from fMRI can be easily sparsified using the temporal Fourier transform. Accordingly, the k-t data can be represented as mapping from the spatial- temporal image:
where A: = DF and D is a k-t downsampling pattern, and F now becomes a 2D Fourier transform. In addition to the temporal Fourier transform, the authors in [88] used the wavelet transform in the spatial dimension to exploit the spatial redundancy. Then, k-t SPARSE is formulated based on the following optimization problem:
where W denotes the spatial wavelet transform, respectively.
K-t FOCUSS
Preliminary CS dynamic MRI approaches [36, 88] were seemingly different from the classical k-t approach such as k-t BLAST/SENSE [5]. One of the most impor- tant contributions of the k-t FOCUSS by Jung et al. [18, 20] was to reveal that the compressed sensing dynamic MRI is not very different from the classical k-t approaches, but rather it can be obtained by a very simple modification of the classical k-t BLAST/SENSE to ensure significant performance improvement.
More specifically, rather than using wavelet transform, k-t FOCUSS exploited the x-f domain sparsity. Then, a standard compressed sensing formulation would be:
to enforce the sparseness in x-f image ρ. However, there exists two additional novel- ties in the k-t FOCUSS. First, rather than directly enforcing the sparseness of the x-f image, the k-t FOCUSS further sparsifies the x-f image using the initial estimate.
Specifically, let ρ0 be the predictable initial estimate of ρ. Then, the residual
should be much more sparse than the original spatio-temporal image. Second, rather than directly using the l1 minimization, k-t FOCUSS employed the reweighted norm approaches. This results in the following equivalent minimization problem:
Then, the normal equations with respect to x and v are given by
where V is a diagonal matrix whose i-th diagonal element is vi. This result in the following FOCUSS iteration:
where the weighting matrix is given by
One of the most powerful observations in [18, 20] was that the first iteration of (38) has very similar form to the classical k-t BLAST/SENSE algorithm, except the power factor of weighting matrix. This observation led to an innovative idea to con- vert k-t BLAST/SENSE to compressed sensing approach. More specifically, by using incoherence sampling patterns, multiple iterations and correct weighting factor for the diagonal matrix, the authors of k-t FOCUSS [18, 20] clearly demonstrated the performance improvement. This observation suggested that the improvement by the classical k-t algorithms such as k-t BLAST/SENSE [5] was not from the Bayesian perspective as the original authors of [5] had claimed, but indeed is originated from exploiting the sparsity int the spatio-temporal domain [18, 20]. Furthermore, by simply modifying the weight factor and sampling patterns, several additional iter- ation can significantly improve the performance of k-t BLAST/SENSE.
Another powerful aspect of k-t FOCUSS was that the idea can be easily extended to exploit the sparsity in other transform domains. For example, the residual step in (36) can be interpreted as sparsity promoting step by subtracting the temporal mean images. Thus, Jung et al. [20] proposes motion estimated and compensated modification of k-t FOCUSS to make the residual signal much sparser. More specifi- cally, rather than subtracting the temporal mean values, they subtracted the motion estimated frame. Note that motion estimation and compensation (ME/MC) is an essential step in video coding that uses motion vectors to exploit the temporal re- dundancies between frames [89, 90]. In order to employ ME/MC within dynamic MRI, there are several technical issues to address. First, at least one reference frame is required. This issue can be easily resolved if we acquire fully sampled data in one frame as often done in dynamic MRI. The main technical difficulty, however, comes from the existence of the low quality current frame. Fortunately, this issue can be addressed using an additional reconstruction step before the ME/MC [20].
In addition, the spatio-temporal signals can be further sparsified using data-driven transform:
where D denotes the learned temporal dictionary based from the images, whereas c denotes the coefficients. Then, the imaging problem can be formulated as
For example, in order to find the temporal basis that can sparsify ρ, Jung et al. [18, 20] performed the the singular value decomposition (SVD) after the image reconstruction, then the new dictionary is used to estimate the new coefficients. This procedure is closely related to the partial separable function (PSF) [91] and k-t SLR (k-t sparse and low-rank decomposition) [49], which will be reviewed soon.
Partially separable function (PSF) approach
In the PSF model by Liang et al. [91], the k-t samples are assumed to be decomposed in the following form
for some data dependent spectral and temporal basis function \( {\left\{{\Psi}_l(k)\right\}}_{l=1}^L \) and \( {\left\{{\varnothing}_l(t)\right\}}_{l=1}^L \) . Thanks to the partially separable assumption, the so-called Casorati Matrix B for the fully sampled k-t data given by
has at most rank L.
In dynamic CS MRI, many of the k-t samples are missing and we are interested in finding the missing components. Hence, by utilizing the low-rankness of the Ca-sorati matrix, the missing k-t samples can be estimated using a low rank matrix completion algorithm. In particular, the authors in [92, 93] proposed the following matrix factorization approach:
where A denotes the k-t sampling operator that indicates the missing samples by 0, and \( U\in {\mathrm{C}}^{m\times \mathrm{L}} \), \( V\in {\mathrm{C}}^{m\times \mathrm{L}} \) is used for the low rank matrix factorization B = U V H, and the optimization is performed for U and V alternatingly by fixing the other matrix using the previous estimate. Because the exact rank of B is not known, the authors proposed the incremented powerFactorization (IRFP) algorithm [92], where (40) starts with L = 1 by increasing order with the initialization of the power factorization of L + 1 from that of L. To avoid an overfitting, the algorithm is terminated as soon as the data fidelity is below some threshold values.
K-t SLR: K-t sparse and low rank approach
k-t Sparse and Low Rank Approach (k-t SLR) model by Lingala et al. [49] is a more systematic way of learning both basis and sparse coefficients. In this approach, the spatio-temporal signal ρ(x, t) is first rearranged in a matrix form
Then, using the low rank prior, the optimisation problem can be formulated as
\( \underset{\Gamma}{\min }{\left\Vert b-A\left(\Gamma \right)\right\Vert}^2+\uplambda \upvarphi \left(\Gamma \right) \),
where A: = DF is now a downsampled Fourier transform. Here, the rank prior is approximated using the general class of Schatten p-functionals, specified by
where {σi} denotes the singular values of Γ.
In dynamic imaging applications, the images in the time series may have sparse wavelet coefficients or sparse gradients. In addition, if the intensity profiles of the voxels are periodic (e.g., cardiac cine), they may be sparse in the Fourier domain. Based on this observation, Lingala et al. [49] proposed additional sparsity inducing penalty in specified basis sets along with the low-rank property to further improve the recovery rate. Specifically, they chose the 2-D wavelet transform to sparsify each of the images in the time series, while can be a 1-D Fourier transform to exploit the pseudo-periodic nature of motion. Then, the resulting composite minimization problem can be formulated as
K-space structured low-rank approaches
Basic theory
Compared to the standard compressed sensing approaches, k-space structured low- rank approaches such as SAKE [55], LORAKS [56], ALOHA [57, 59, 60] and GIRAF [61] are relatively new, but has significant potentials in MRI imaging. These ap- proaches are all derived by the k-space convolution relationship and can be used for both static and dynamic imaging. So we first discuss a matrix representation of the convolution. For simplicity, we will consider the 1-D notation.
Specifically, consider a fully sampled k-space measurement from the multi-channel coils:
where γi denotes the unknown i-th coil images and yi corresponds to its k-space data. Note that the matrix representation of a k-space convolution of yi with a d-tap filter h is given by
where \( \mathcal{C}\left({y}^i\right) \) denotes the convolution matrix constructed by the vector yi:
and h¯ denotes a vector that reverses the order of the elements. If we extract the n − d-rows of the convolution matrix with n − d > d, we can obtain the following Hankel structured matrix:
By defining Y = [y1, ⋯, yC], we can further defined the extended Hankel matrix
In the following, we will explain how these Hankel structured matrix has been utilised for accelerated MRI.
SAKE
A calibrationless parallel imaging reconstruction method, termed simultaneous au- tocalibrating and k-space estimation (SAKE), is a data-driven, coil-by-coil recon- struction method that does not require a separate calibration step for estimating coil sensitivity information [55]. SAKE is based on the following observation in GRAPPA:
which implies that the i-th k-space measurement can be represented as the linear combination of the filtered k-space data from other coils. In matrix form, this recursive relationship implies the existence of the null space of the Hankel matrix.
In other word, Hd|C(Y) is low-ranked. Therefore, SAKE solves the following low- rank matrix completion problem to interpolate the missing k-space data:
where PΩ(·) denotes the projection on the measured k-space samples on the index set Ω. The problem was solved using the iterative singular value shrinkage method [94].
LORAKS
The low-rank modeling of local-space neighborhoods (LORAKS) [56] was inspired by the finite support condition. More specifically, if the object γ has finite support, we can easily find the function w such that
This results in a convolution relationship in k-space
where y and h denote the Fourier spectrum of γ and w, respectively. Therefore, this gives a single channel version of the low-rank condition, which results in the following rank minimization problem:
ALOHA and GIRAF
Annihilating filter-based low rank Hankel matrix (ALOHA) approach [57,58,59,60, 62] and GIRAF (Generic Iterative Reweighted Annihilating Filter) [61] can be considered as the full generalization of SAKE and LORAKS for general class of signals with the finite rate of innovations (FRI) for MR measurements. Moreover, the approaches have unified the parallel imaging and compressed sensing as a k- space interpolation with performance guarantees [62], and can be used for artifact correction [58]. This section describes the fundamental dual relationship between transform domain sparsity and low rankness in reciprocal domain, which is the key ingredient. For better readability, we provide here a high level description by assuming 1-D signals.
The Fourier CS problem of our interest is to recover the unknown signal x(t) from the Fourier measurement:
In classical Nyquist sampling, to avoid aliasing artefacts, the grid size should be at most:
when the support of the time domain signal x(t) is τ. Then, discrete Fourier data at the Nyquist rate is defined by:
We also define a length (r + 1)-annihilating filter hˆ[k] for xˆ[k] that satisfies
The existence of the minimum length finite length annihilating filter has been ex- tensively studied for FRI signals [95,96,97]. Let r + 1 denotes the minimum size of annihilating filters that annihilates discrete Fourier data \( \widehat{\mathrm{x}}\left[\mathrm{k}\right] \). Then, a d-tap anni- hilating filter h with d > r + 1 can be easily obtained by convolving an appropriate size FIR filter with the minimum length annihilating filter. In matrix form, this is equivalent to
where the Hankel structure matrix \( {\mathcal{H}}_{\mathrm{d}}\left(\hat{x}\right) \) is constructed as
Assume that min(n − d + 1, d) > r. Then, we can show the following low rank property [62]:
Thanks to the low-rankness of the associated Hankel matrix, the missing k-space data can be easily interpolated using the following low-rank matrix completion [62]:
where PΩ is the projection operator on the sampling location Ω. Moreover, as shown in [62], the low-rank matrix completion approach (55) does not compromise any optimality compared to the standard Fourier CS.
Note that signals may not be sparse in the image domain, but can be sparsified in a transform domain. In fact, this was the main idea of the compressed sensing. Specifically, the signal x of our interest is a non-uniform spline that can be represented by:
where L denotes a constant coefficient linear differential equation that is often called the continuous domain whitening operator in [98, 99]:
and w is a continuous sparse innovation:
For example, if the underlying signal is piecewise constant, we can set L as the first differentiation. In this case, x corresponds to the total variation signal model. Then,
by taking the Fourier transform of (56), we have
where
Accordingly, the Hankel matrix \( \mathcal{H}\left(\hat{z}\right) \) from the weighted spectrum zˆ(ω) satisfies the following rank condition:
Thanks to the low-rankness, the missing Fourier data can be interpolated using the following matrix completion problem:
or, for noisy Fourier measurements \( \widehat{\mathrm{y}} \),
where ⊙ denotes the Hadamard product, \( \widehat{\mathrm{l}} \) and \( \widehat{\mathrm{x}} \) denotes the vectors composed of full samples of \( \widehat{\mathrm{l}} \)(ω) and \( \widehat{\mathrm{x}} \)(ω), respectively. After solving (Pw), the missing spec- tral data xˆ(ω) can be obtained by dividing by the weight, i.e. \( \widehat{x}\left(\omega \right)=\mathrm{m}\left(\upomega \right)/\widehat{l}\left(\omega \right) \) assuming that \( \widehat{l}\left(\omega \right)\ne 0 \).
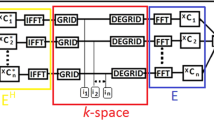
The idea can be generalized for any transform domain sparse signals as long as the transform can be represented using shift-invariant filters. Wavelet domain sparse signal belongs to this class. In this case, the weight kernel in the Fourier domain is obtained as the spectrum of the subband filters [57,58,59,60, 62]. For example, Fig. 3 showed the construction of the Hankel matrix for the MR parameter mapping, where the k-space weighting from wavelet weighting is applied only along the phase encoding direction, whereas no weighing is applied along the t-domain since the correspond temporal spectrum is already sparse [59].

Construction of Hankel matrix for MR parameter mapping [59]
The idea can be also easily generalised to the parallel imaging by exploiting (19). Specifically, (19) can be equivalently represented using the matrix representation:
This implies that an exten^ded Hankel matrix \( {\mathcal{H}}_{\mathrm{d}\mid \mathrm{C}}\left(\left[{\widehat{\gamma}}^1\cdots {\widehat{\gamma}}^C\right]\right) \) in (46) is low ranked.
For example, the multi-channel construction of Hankel matrix for MR parameter mapping [59] is shown in Fig. 4.

Construction of Hankel matrix for multi-channel filter data for the case of MR parameter mapping [59]
One of the most important advantages of the Hankel matrix formulation is that the coil diversity can be readily exploited in addition to the image domain redundancy in a unified framework. This makes the separate coil sensitivity estimation unnecessary.
Clinical applications
Since the compressed sensing MRI allows significant acceleration of MR acquisition, it has been extensively applied for various clinical applications such as fast cardiac MRI, whole heart MRI, dynamic contrast enhanced (DCE)-MRI, diffusion MRI, spectroscopic, etc., that usually require significant acquisition time using standard methods.
For example, Otazo et al. [84] applied the CS method to the first pass cardiac perfusion MRI and demonstrated feasibility of 8-fold acceleration in vivo imaging using standard coil arrays. They showed that CS method results in similar temporal fidelity and image quality to GRAPPA with 2-fold acceleration [84]. Hsiao et al. [100] applied combined parallel imaging and compressed sensing to achieve 4D phase contrast for the quantification of cardiac flow and ventricular volumes pediatric patients during congenital heart MRI examinations. Vincent et al. [101] employed CS to evaluate LV function and volumes and found that CS strategy with the single breath hold provided similar results to multi breathhold imaging protocols.
For free-breathing contrast-enhanced multiphase liver MRI, Chandarana et al. [102] showed that a combination of compressed sensing, parallel imaging, and radial k-space sampling demonstrated the feasibility of breath-hold cartesian T1 weighted imaging. Espagnet et al. [103] employed golden-angle radial sparse parallel technique for DCE-MRI to evaluate the permeability characteristics of the pituitary gland.
For diffusion MRI, Landman et al. [104] showed that CS reconstruction using standard data can resolve crossing fibers similar to a standard q-ball approach using much richer data with longer acquisition time. Kuhnt et al. [105] showed that High Angular Resolution Diffusion Imaging (HARDI) + CS is a promising approach for fiber tractography in clinical practice.
Finally, for the spectroscopic imaging, Larson et al. [106] developed a CS method for acquiring hyperpolarized 13C data using multiband excitation pulses and achieved 2 s temporal resolution with full volumetric coverage of a mouse. Geethanath et al. [107] demonstrated a potential reduction in acquisition time by up to 80% or more for hydrogen 1 MR spectroscopic imaging using CS, with negligible loss of clinical information.
With the commercially available CS reconstruction methods, we expect to see more clinical applications of CS in the near future.
Conclusions
Nowdays, compressed sensing has become an mature technology, as reflected by recent approval by FDA. Major vendors have started to sell the compressed sensing reconstruction softwares, and many clinical researchers have been evaluating its clinical usefulness.
Despite of this maturity, some of the main technical issues of the compressed sensing are 1) the computational complexity of the algorithm is relative high, and at high acceleration, image quality degradation is still reported. Although the recent state-of-the art CS techniques such as structured Hankel matrix approach can address the quality degradation problems, it also increases the computational complexity, which may interfere the clinical workflow.
Fortunately, for the last two years, the MR image reconstruction field have been rapidly changed thanks to the successful demonstration of of the deep learning- based MR reconstruction technologies [108,109,110,111,112,113]. The sudden popularity of deep learning approaches can be attributed to the real-time reconstruction in spite of the significant improvement of the image quality. Thus, when originally presented, these techniques were regarded as totally different technology that is nothing to do with the compressed sensing. However, recent theoretical analysis [114] showed that the deep convolutional neural network is closely related to the Hankel matrix decomposition. Therefore, we can still argue that the compressed sensing MRI has renewed interests in the form of deep learning, and it will be interesting to see how this exciting and rapidly evolving field will develop for the coming decades.
Abbreviations
- ALOHA:
-
Annihliating filter-based low-rank Hankel matrix approach
- CS:
-
Compressed sensing
- FOCUSS:
-
FOCal Underdetermined System Solver
- GRAPPA:
-
Generalized Autocalibrating Partially Parallel Acquisitions
- l1-SPiRIT:
-
l1-iTerative Self-consistent Parallel Imaging Reconstruction
- LORAKS:
-
Low-rank modeling of local-space neighborhoods
- MRI:
-
Magnetic resonance imaging
- SAKE:
-
Simultaneous autocalibrating and k-space estimation
- SENSE:
-
Sensitivity encoding
References
Pruessmann KP, Weigher M, Scheidegger MB, Boesiger P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. 1999;42(5):952–62.
Sodickson DK, Manning WJ. Simultaneous acquisition of spatial harmonics (SMASH): fast imaging with radiofrequency coil arrays. Magn Reson Med. 1997;38(4):591–603.
Griswold MA, Jakob PM, Heidemann RM, Nittka M, Jellus V, Wang J, Kiefer B, Haase A. Generalized autocalibrating partially parallel acquisitions(GRAPPA). Magn. Reson. Med. 2002;47(6):1202–10.
Madore B, Glover GH, Pelc NJ. Unaliasing by Fourier-encoding the overlaps using the temporal dimension(UNFOLD), applied to cardiac imaging and fMRI. Magn. Reson. Med. 1999;42(5):813–28.
Tsao J, Boesiger P, Pruessmann KP. k-t BLAST and k-t SENSE: Dynamic MRI with high frame rate exploiting spatiotemporal correlations. Magn Reson Med. 2003;50(5):1031–42.
Kozerke S, Tsao J, Razavi R, Boesiger P. Accelerating cardiac cine 3D imaging using k-t BLAST. Magn. Reson. Med. 2004;52:19–26.
Sharif B, Derbyshire JA, Faranesh AZ, Bresler Y. Patient-adaptive reconstruction and acquisition in dynamic imaging with sensitivity encoding (paradise). Magn Reson Med. 2010;64(2):501–13.
Tsao J, Kozerke S, Boesiger P, Pruessmann KP. Optimizing spatiotemporal sampling for k-t BLAST and k-t SENSE: Application to high-resolution real-time cardiac steady-state free precession. Magn. Reson. Med. 2005;53:1372–82.
Hansen MS, Kozerke S, Pruessman KP, Boesiger P, Pedersen EM, Tsao J. One the influence of training data quality in k-t BLAST reconstruction. Magn. Reson. Med. 2004;52:1175–83.
Bresler, Y., Gastpar, M., Venkataramani, R.: Image compression on-the-fly by universal sampling in fourier imaging systems. In: Proc. 1999 IEEE Information Theory Workshop on Detection, Estimation, Classification, and Imaging, pp. 48 (1999)
Ye, J.C., Bresler, Y., Moulin, P.: A self-refencing level-set method for image reconstruction from sparse Fourier samples. In: to Appear in Proc. IEEE Workshop in Variational and Level Set Methods in Computer Vision, Vancouver, Canada (2001)
Candes E, Romberg J, Tao T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory. 2006;52(2):489–509.
Donoho DL. Compressed sensing. IEEE Trans. Inf. Theory. 2006;52(4):1289–306.
Lustig M, Donoho D, Pauly JM. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn Reson Med. 2007;58(6):1182–95.
Lustig M, Donoho DL, Santos JM, Pauly JM. Compressed sensing MRI. IEEE Signal Process Mag. 2008;25(2):72–82.
Candes EJ, Romberg JK, Tao T. Stable signal recovery from incomplete and inaccurate measurements. Commun Pure Appl Math. 2006;59(8):1207–23.
Candes E, Tao T. Decoding by linear programming. IEEE Trans. Info. Theory. 2005;51(12):4203–15.
Jung H, Ye JC, Kim EY. Improved k–t BLAST and k–t SENSE using FOCUSS. Phys. Med. Biol. 2007;52:3201–26.
Ye JC, Tak S, Han Y, Park HW. Projection reconstruction MR imaging using FOCUSS. Magn Reson Med. 2007;57(4):764–75.
Jung H, Sung K, Nayak KS, Kim EY, Ye JC. k-t FOCUSS: a general compressed sensing framework for high resolution dynamic MRI. Magn Reson Med. 2009;61(1):103–16.
Chen GH, Tang J, Leng S. Prior image constrained compressed sensing (PICCS): a method to accurately reconstruct dynamic CT images from highly undersampled projection data sets. Med. Phys. 2008;35:660.
Cotter SF, Rao BD. Sparse channel estimation via matching pursuit with application to equalization. IEEE Trans. Commun. 2002;50:374–7.
Wagadarikar A, John R, Willett R, Brady D. Single disperser design for coded aperture snapshot spectral imaging. Applied Optics. 2008;47(10):44–51.
Tropp JA. Just Relax: convex programming methods for identifying sparse signals in noise. IEEE Trans. Inf Theory. 2006;52(3):1030–51.
Gorodnitsky IF, Rao BD. Sparse signal reconstruction from limited data using FOCUSS: A re-weighted minimum norm algorithm. IEEE Trans Signal Process. 1997;45(3):600–16.
Candes EJ, Wakin MB, Boyd SP. Enhancing sparsity by reweighted l1 minimization. J Fourier Anal Appl. 2008;14(5):877–905.
Chen SS, Donoho DL, Saunders MA. Atomic decomposition by basis pursuit. SIAM J Sci Comput. 1999;20(1):33–61.
Bauschke HH, Combettes PL. Convex analysis and monotone operator theory in Hilbert spaces. Vol. 408. New York: Springer; 2011.
Combettes PL, Wajs VR, et al. Signal recovery by proximal forward-backward splitting. Multiscale Model Simul. 2006;4(4):1168–200.
Goldstein T, Osher S. The split Bregman method for L1 regularized problems. SIAM J Imag Sci. 2009;2(2):323–43.
Wang Y, Yang J, Yin W, Zhang Y. A new alternating minimization algorithm for total variation image reconstruction. SIAM J Imag Sci. 2008;1(3):248–72.
Combettes PL, Pesquet JC. A Douglas–Rachford splitting approach to nonsmooth convex variational signal recovery. IEEE J. Sel. Top. Sign. Proces. 2007;1(4):564–74.
Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vision. 2011;40(1):120–45.
Ramani S, Fessler JA. Parallel MR image reconstruction using augmented Lagrangian methods. IEEE Trans. Med. Imaging. 2011;30(3):694–706.
Meyer CH, Hu BS, Nishimura DG, Macovski A. Fast spiral coronary artery imaging. Magn Reson Med. 1992;28(2):202–13.
Gamper U, Boesiger P, Kozerke S. Compressed sensing in dynamic MRI. Magn Reson Med. 2008;59(2):365–73.
Block KT, Uecker M, Frahm J. Undersampled radial MRI with multiple coils. Iterative image reconstruction using a total variation constraint. Magn Reson Med. 2007;57(6):1086–98.
Liang D, Liu B, Wang J, Ying L. Accelerating SENSE using compressed sensing. Magn. Reson. Med. 2009;62(6):1574–84.
Feng L, Srichai MB, Lim RP, Harrison A, King W, Adluru G, Dibella EV, Sodickson DK, Otazo R, Kim D. Highly accelerated real-time cardiac cine MRI using k–t SPARSE-SENSE. Magn Reson Med. 2013;70(1):64–74.
Lustig M, Pauly JM. SPIRiT: Iterative self-consistent parallel imaging reconstruction from arbitrary k-space. Magn Reson Med. 2010;64(2):457–71.
Zhang T, Pauly JM, Vasanawala SS, Lustig M. Coil compression for accelerated imaging with Cartesian sampling. Magn Reson Med. 2013;69(2):571–82.
Feng L, Grimm R, Block KT, Chandarana H, Kim S, Xu J, Axel L, Sodickson DK, Otazo R. Golden-angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI. Magn Reson Med. 2014;72(3):707–17.
Trzasko J, Manduca A. Fast spiral coronary artery imaging. IEEE Trans. Med. Imaging. 2009;28(1):106–21.
Trzasko JD, Haider CR, Borisch EA, Campeau NG, Glockner JF, Riederer SJ, Manduca A. Sparse-CAPR: highly accelerated 4D CE-MRA with parallel imaging and nonconvex compressive sensing. Magn Reson Med. 2011;66(4):1019–32.
Knoll F, Bredies K, Pock T, Stollberger R. Second order total generalized variation (TGV) for MRI. Magn Reson Med. 2011;65(2):480–91.
Knoll F, Clason C, Bredies K, Uecker M, Stollberger R. Parallel imaging with nonlinear reconstruction using variational penalties. Magn Reson Med. 2012;67(1):34–41.
Sung K, Daniel BL, Hargreaves BA. Location constrained approximate message passing for compressed sensing MRI. Magn Reson Med. 2013;70(2):370–81.
Ravishankar S, Bresler Y. MR image reconstruction from highly undersampled k-space data by dictionary learning. IEEE Trans. Med. Imaging. 2011;30(5):1028–41.
Lingala SG, Hu Y, DiBella E, Jacob M. Accelerated dynamic MRI exploiting sparsity and low-rank structure: kt SLR. IEEE Trans. Med. Imaging. 2011;30(5):1042–54.
Asif MS, Hamilton L, Brummer M, Romberg J. Motion-adaptive spatio-temporal regularization for accelerated dynamic MRI. Magn Reson Med. 2012;7:800–12.
Ak Cakaya M, Basha TA, Goddu B, Goepfert LA, Kissinger KV, Tarokh V, Manning WJ, Nezafat R. Low-dimensional-structure self-learning and thresholding: Regularization beyond compressed sensing for MRI Reconstruction. Magn Reson Med. 2011;66(3):756–67.
Trzasko JD, Manduca A. Calibrationless parallel MRI using CLEAR. In: IEEE Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR); 2011. p. 75–9.
Yoon H, Kim KS, Kim D, Bresler Y, Ye JC. Motion adaptive patch-based low-rank approach for compressed sensing cardiac cine MRI. IEEE Trans. Med. Imaging. 2014;33(11):2069–85.
Cand’es EJ, Recht B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009;9(6):717–72.
Shin PJ, Larson PE, Ohliger MA, Elad M, Pauly JM, Vigneron DB, Lustig M. Calibrationless parallel imaging reconstruction based on structured low-rank matrix completion. Magn Reson Med. 2014;72(4):959–70.
Haldar JP. Low-rank modeling of local-space neighborhoods (LORAKS) for constrained MRI. IEEE Trans. Med. Imaging. 2014;33(3):668–81.
Jin KH, Lee D, Ye JC. A general framework for compressed sensing and parallel MRI using annihilating filter based low-rank Hankel matrix. IEEE Trans Computational Imag. 2016;2(4):480–95.
Jin KH, Um J-Y, Lee D, Lee J, Park S-H, Ye JC. MRI artifact correction using sparse+ low-rank decomposition of annihilating filter-based Hankel matrix. Magnetic Reson Med. 2017;78(1):327–40.
Lee D, Jin KH, Kim EY, Park S-H, Ye JC. Acceleration of MR parameter mapping using annihilating filter-based low rank hankel matrix (ALOHA). Magn Reson Med. 2016;76(6):1848–68.
Lee J, Jin KH, Ye JC. Reference-free single-pass EPI Nyquist ghost correction using annihilating filter-based low rank Hankel matrix (ALOHA). Magn Reson Med. 2016;76(8):1775–89.
Ongie G, Jacob M. Off-the-grid recovery of piecewise constant images from few fourier samples. SIAM J Imaging Sci. 2016;9(3):1004–41.
Ye JC, Kim JM, Jin KH, Lee K. Compressive sampling using annihilating filter-based low-rank interpolation. IEEE Trans Inf Theory. 2017;63(2):777–801.
Bauer S, Markl M, Honal M, Jung B. The effect of reconstruction and acquisition parameters for GRAPPA-based parallel imaging on the image quality. Magn Reson Med. 2011;66(2):402–9.
Huang F, Lin W, Duensing GR, Reykowski A. A hybrid method for more efficient channel-by-channel reconstruction with many channels. Magn Reson Med. 2012;67(3):835–43.
Trzasko JD, Bao Z, Manduca A, McGee KP, Bernstein MA. Sparsity and low-contrast object detectability. Magn Reson Med. 2012;67(4):1022–32.
Johnson KM, Block WF, Reeder SB, Samsonov A. Improved least squares MR image reconstruction using estimates of k-space data consistency. Magn Reson Med. 2012;67(6):1600–8.
Park S, Park J. Adaptive self-calibrating iterative GRAPPA reconstruction. Magn Reson Med. 2012;67(6):1721–9.
Liang D, DiBella EV, Chen R-R, Ying L. k-t ISD: dynamic cardiac MR imaging using compressed sensing with iterative support detection. Magn Reson Med. 2012;68(1):41–53.
Chang Y, Liang D, Ying L. Nonlinear GRAPPA: A kernel approach to parallel MRI reconstruction. Magn Reson Med. 2012;68(3):730–40.
Huang F, Lin W, Duensing GR, Reykowski A. k-t sparse GROWL: Sequential combination of partially parallel imaging and compressed sensing in k-t space using flexible virtual coil. Magn Reson Med. 2012;68(3):772–82.
Jung B, Stalder AF, Bauer S, Markl M. On the undersampling strategies to accelerate time-resolved 3D imaging using k-t-GRAPPA. Magn Reson Med. 2011;66(4):966–75.
Piccini D, Littmann A, Nielles-Vallespin S, Zenge MO. Spiral phyllotaxis: the natural way to construct a 3D radial trajectory in MRI. Magn Reson Med. 2011;66(4):1049–56.
Lin W, B¨ornert P, Huang F, Duensing GR, Reykowski A. Generalized GRAPPA operators for wider spiral bands: Rapid self-calibrated parallel reconstruction for variable density spiral MRI. Magn Reson Med. 2011;66(4):1067–78.
Pipe JG, Zwart NR, Aboussouan EA, Robison RK, Devaraj A, Johnson KO. A new design and rationale for 3d orthogonally oversampled k-space trajectories. Magn Reson Med. 2011;66(5):1303–11.
Pang Y, Vigneron DB, Zhang X. Parallel traveling-wave MRI: A feasibility study. Magn Reson Med. 2012;67(4):965–78.
Wang H, Liang D, King KF, Nagarsekar G, Chang Y, Ying L. Improving GRAPPA using cross-sampled autocalibration data. Magn Reson Med. 2012;67(4):1042–53.
Witschey WR, Cocosco CA, Gallichan D, Schultz G, Weber H, Welz A, Hennig J, Zaitsev M. Localization by nonlinear phase preparation and k-space trajectory design. Magn Reson Med. 2012;67(6):1620–32.
Addy NO, Wu HH, Nishimura DG. Simple method for MR gradient system characterization and k-space trajectory estimation. Magn Reson Med. 2012;68(1):120–9.
Zahneisen, B., Hugger, T., Lee, K.J., LeVan, P., Reisert, M., Lee, H.-L., Assl¨ander, J., Zaitsev, M., Hennig, J.: Single shot concentric shells trajectories for ultra fast fMRI. Magn Reson Med 68(2), 484–494 (2012)
Turley DC, Pipe JG. Distributed spirals: a new class of three-dimensional k-space trajectories. Magn Reson Med. 2013;70(2):413–9.
Layton KJ, Gallichan D, Testud F, Cocosco CA, Welz AM, Barmet C, Pruessmann KP, Hennig J, Zaitsev M. Single shot trajectory design for region-specific imaging using linear and nonlinear magnetic encoding fields. Magn Reson Med. 2013;70(3):684–96.
Haldar JP, Hernando D, Liang Z-P. Compressed-sensing MRI with random encoding. IEEE Trans Med Imag. 2011;30(4):893–903.
Puy G, Marques JP, Gruetter R, Thiran J-P, Ville DVD, Vandergheynst P, Wiaux Y. Spread spectrum magnetic resonance imaging. IEEE Trans Med Imag. 2012;31(3):586–98.
Otazo R, Kim D, Axel L, Sodickson DK. Combination of compressed sensing and parallel imaging for highly accelerated first-pass cardiac perfusion MRI. Magn Reson Med. 2010;64(3):767–76.
Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, Vasanawala SS, Lustig M. ESPIRiT–an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med. 2014;71(3):990–1001.
Ravishankar S, Bresler Y. Efficient blind compressed sensing using sparsifying transforms with convergence guarantees and application to magnetic resonance imaging. SIAM J Imag Sci. 2015;8(4):2519–57.
Aharon M, Elad M, Bruckstein A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans Signal Process. 2006;54(11):4311–22.
Lustig M, Santos JM, Donoho DL, Pauly JM. kt SPARSE: High frame rate dynamic MRI exploiting spatio-temporal sparsity. In: Proceedings of the 13th Annual Meeting of ISMRM, Seattle, vol. 2420; 2006.
Le Gall D. MPEG: A video compression standard for multimedia applications. Commun ACM. 1991;34(4):46–58.
Jung H, Ye JC. Motion estimated and compensated compressed sensing dynamic magnetic resonance imaging: What we can learn from video compression techniques. Int J Imag Syst Technol. 2010;20(2):81–98.
Haldar, J.P., Liang, Z.-P.: Spatiotemporal imaging with partially separable functions: a matrix recovery approach. In: IEEE International Symposium on Biomedical Imaging, pp. 716–719 (2010). IEEE
Haldar JP, Hernando D. Rank-constrained solutions to linear matrix equations using powerfactorization. IEEE Signal Process Letters. 2009;16(7):584–7.
Zhao B, Haldar JP, Christodoulou AG, Liang Z-P. Image reconstruction from highly undersampled-space data with joint partial separability and sparsity constraints. IEEE Trans Med Imag. 2012;31(9):1809–20.
Cai J-F, Cand’es EJ, Shen Z. A singular value thresholding algorithm for matrix completion. SIAM J Optimization. 2010;20(4):1956–82.
Vetterli M, Marziliano P, Blu T. Sampling signals with finite rate of innovation. IEEE Trans Signal Process. 2002;50(6):1417–28.
Dragotti PL, Vetterli M, Blu T. Sampling moments and reconstructing signals of finite rate of innovation: Shannon meets Strang–Fix. IEEE Trans Signal Process. 2007;55(5):1741–57.
Maravic I, Vetterli M. Sampling and reconstruction of signals with finite rate of innovation in the presence of noise. IEEE Trans Signal Process. 2005;53(8):2788–805.
Unser M, Tafti PD, Sun Q. A unified formulation of Gaussian versus sparse stochastic processes–Part I: Continuous-domain theory. IEEE Trans Inf Theory. 2014;60(3):1945–62.
Unser M, Tafti PD, Amini A, Kirshner H. A unified formulation of Gaussian versus sparse stochastic processes–Part II: Discrete-domain theory. IEEE Trans Inf Theory. 2014;60(5):3036–51.
Hsiao A, Lustig M, Alley MT, Murphy M, Chan FP, Herfkens RJ, Vasanawala SS. Rapid pediatric cardiac assessment of flow and ventricular volume with compressed sensing parallel imaging volumetric cine phase-contrast MRI. Am J Roentgenol. 2012;198(3):250–9.
Vincenti G, Monney P, Chaptinel J, Rutz T, Coppo S, Zenge MO, Schmidt M, Nadar MS, Piccini D, Ch’evre P, et al. Compressed sensing single–breath-hold CMR for fast quantification of LV function, volumes, and mass. JACC: Cardiovasc Imag. 2014;7(9):882–92.
Chandarana H, Feng L, Block TK, Rosenkrantz AB, Lim RP, Babb JS, Sodickson DK, Otazo R. Free-breathing contrast-enhanced multiphase MRI of the liver using a combination of compressed sensing, parallel imaging, and golden-angle radial sampling. Investigative Radiol. 2013;48(1):10–16.
Espagnet MR, Bangiyev L, Haber M, Block K, Babb J, Ruggiero V, Boada F, Gonen O, Fatterpekar G. High-resolution DCE-MRI of the pituitary gland using radial k-space acquisition with compressed sensing reconstruction. Am J Neuroradiol. 2015;36(8):1444–9.
Landman BA, Bogovic JA, Wan H, ElShahaby FEZ, Bazin P-L, Prince JL. Resolution of crossing fibers with constrained compressed sensing using diffusion tensor MRI. NeuroImage. 2012;59(3):2175–86.
Kuhnt D, Bauer MH, Egger J, Richter M, Kapur T, Sommer J, Merhof D, Nimsky C. Fiber tractography based on diffusion tensor imaging compared with high-angular-resolution diffusion imaging with compressed sensing: initial experience. Neurosurgery. 2013;72(0 1):165.
Larson PE, Hu S, Lustig M, Kerr AB, Nelson SJ, Kurhanewicz J, Pauly JM, Vigneron DB. Fast dynamic 3D MR spectroscopic imaging with compressed sensing and multiband excitation pulses for hyperpolarized 13C studies. Magn Reson Med. 2011;65(3):610–9.
Geethanath S, Baek H-M, Ganji SK, Ding Y, Maher EA, Sims RD, Choi C, Lewis MA, Kodibagkar VD. Compressive sensing could accelerate 1H MR metabolic imaging in the clinic. Radiology. 2012;262(3):985–94.
Hammernik K, Klatzer T, Kobler E, Recht MP, Sodickson DK, Pock T, Knoll F. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018;79(6):3055–71.
Han Y, Yoo J, Kim HH, Shin HJ, Sung K, Ye JC. Deep learning with domain adaptation for accelerated projection-reconstruction mr. Magn Reson Med. 2018;80(3):1189–205.
Zhu B, Liu JZ, Cauley SF, Rosen BR, Rosen MS. Image reconstruction by domain-transform manifold learning. Nature. 2018;555(7697):487.
Schlemper J, Caballero J, Hajnal JV, Price AN, Rueckert D. A deep cascade of convolutional neural networks for dynamic mr image reconstruction. IEEE Trans Med Imag. 2018;37(2):491–503.
Wang, S., Su, Z., Ying, L., Peng, X., Zhu, S., Liang, F., Feng, D., Liang, D.: Accelerating magnetic resonance imaging via deep learning. In: Biomedical Imaging (ISBI), 2016 IEEE 13th International Symposium On, pp. 514–517 (2016). IEEE
Kwon K, Kim D, Park H. A parallel MR imaging method using multilayer perceptron. Med Phys. 2017;44(12):6209–24.
Ye JC, Han Y, Cha E. Deep convolutional framelets: A general deep learning framework for inverse problems. SIAM J Imag Sci. 2018;11(2):991–1048.
Acknowledgements
The author would like to thank his students, Yoseob Han and Dongwook Lee, for providing figures. The author also like to thank two anonymous reviewers who comments have significantly improve the quality of the paper.
Funding
This work is supported by National Research Foundation of Korea, Grant number NRF-2016R1A2B3008104.
Availability of data and materials
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Author information
Authors and Affiliations
Contributions
The author has read and approved this article.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent for publication
Not applicable
Competing interests
The author declares that he has no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Ye, J.C. Compressed sensing MRI: a review from signal processing perspective. BMC biomed eng 1, 8 (2019). https://doi.org/10.1186/s42490-019-0006-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42490-019-0006-z