
Abstract
Flavihumibacter solisilvae 3-3T (= KACC 17917T = JCM 19891T) represents a type strain of the genus Flavihumibacter within the family Chitinophagaceae. This strain can use various sole carbon sources, making it applicable in industry and bioremediation. In this study, the draft genomic information of F. solisilvae 3-3T is described. F. solisilvae 3-3T owns a genome size of 5.41 Mbp, 47 % GC content and a total of 4,698 genes, including 4,215 protein coding genes, 439 pseudo genes and 44 RNA encoding genes. Analysis of its genome reveals high correlation between the genotypes and the phenotypes.
Similar content being viewed by others


Introduction
The genus Flavihumibacter was established in 2010 [1] and comprises three recognized species, Flavihumibacter petaseus T41T [1], Flavihumibacter cheonanensis WS16T [2] and Flavihumibacter solisilvae 3-3T [3], that were isolated from a subtropical rainforest soil, a shallow stream sediment and a forest soil, respectively. The Flavihumibacter members are Gram-positive, rod-shaped, strictly aerobic, non-motile, yellow-pigmented bacteria. The strains all contain phosphatidylethanolamine (as the major polar lipid, menaquinone-7 as the major respiratory quinine, iso-C15:0 and iso-C15:1 G as the principal fatty acids. In addition, the strains are oxidase- and catalase-positive and with a G + C content range of 45.9-49.5 mol% [1–3].
To the best of our knowledge, the genomic information of Flavihumibacter members still remains unknown. In this study, we present the draft genome information of F. solisilvae 3-3T. A polyphasic taxonomic study revealed that F. solisilvae 3-3T could utilize 33 kinds of sole carbon substrates, including 11 kinds of saccharides and 22 kinds of organic acids and amino acids [3]. Specially, this strain could utilize aromatic compound 4-hydroxyphenylacetic acid as a sole carbon source making it applicable environmental bioremediation [4–6]. In addition, this strain could utilize quinic acid as a sole carbon. Quinic acid is the substrate used to synthesize aromatic amino acids (phenylalanine, tyrosine and tryptophan) via the shikimate pathway. These aromatic amino acids are very useful as food additives, sweetener and pharmaceutical intermediates [6, 7]. The genome analysis of F. solisilvae 3-3T will provide the genomic basis for better understanding these mechanisms and applying the strain to industries and bioremediation more efficiently.
Organism information
Classification and features
F. solisilvae 3-3T was isolated from forest soil of Bac Kan province in Vietnam [3]. The classification and features of F. solisilvae 3-3T are shown in Table 1. A maximum-likelihood tree was constructed based on the 16S rRNA gene sequences using MEGA 5.0 [8]. The bootstrap values were calculated based on 1,000 replications and distances were calculated in accordance with Kimura’s two-parameter method [9]. The phylogenetic tree showed that F. solisilvae 3-3T was clustered with the other Flavihumibacter members (Fig. 1).

A 16S rRNA gene based ML phylogenetic tree showing the phylogenetic position of F. solisilvae 3-3T. Bootstrap values (>50 %) based on 1,000 replications are shown at branch nodes. Bar, 1 substitutions per 100 nucleotide positions. Sphingobacterium alimentarium DSM 22362T is used as the outgroup. The GenBank accession numbers are shown in parentheses
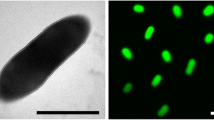
Cells of F. solisilvae 3-3T (Fig. 2) are Gram-positive, aerobic, non-motile, and rod-shaped. Colony is yellow due to the production of flexirubin-type pigments [10]. F. solisilvae 3-3T grows well on NA and R2A agar (optimum), but do not grow on LB or TSA agar [3]. It can hydrolyze aesulin, gelatin, casein and tyrosine [3]. F. solisilvae 3-3T can also utilize various carbohydrate substrates (Table 1) and produces several glycosyl hydrolases, such as β-N-acetylhexosaminidase, α-galactosidase, β-glucosidase, β-galactosidase, α-fucosidase, α-mannosidase and α-glucosidase [3].

A transmission electron micrograph of F. solisilvae 3-3T cell. The bar indicates 0.5 μm
F. solisilvae 3-3T contains iso-C15:0, iso-C15:1 G and summed feature 3 (C16:1 ω6c/C16:1 ω7c) as the principal fatty acids, MK-7 as the major respiratory quinine. The major polar lipids were PE, three unidentified aminolipids and three unidentified lipids [3].
Genome sequencing information
Genome project history
F. solisilvae 3-3T was selected for sequencing based on its taxonomic representativeness and the potential application in food industry and bioremediation. The genome of F. solisilvae 3-3T was sequenced at Wuhan Bio-Broad Co., Ltd, Hubei, China. This Whole Genome Shotgun project has been deposited at DDBJ/EMBL/GenBank under the accession JSVC00000000. The version described in this paper is version JSVC00000000.1. A summary of the genomic sequencing project information is given in Table 2.
Growth conditions and genomic DNA preparation
F. solisilvae 3-3T was grown aerobically in 50 ml R2A broth at 28 °C for 24 h with 160 r/min shaking. About 20 mg cells were harvested by centrifugation and suspended in normal saline, and then lysed using lysozyme. The DNA was obtained using the QiAamp kit according to the manufacturer’s instruction (Qiagen, Germany).
Genome sequencing and assembly
The genome of F. solisilvae 3-3T was sequenced by Illumina Hiseq 2,000 technology [11] with Paired-End library strategy (300 bp insert size). TruSeq DNA Sample Preparation Kits are used to prepare DNA libraries with insert sizes from 300–500 bp for single, paired-end, and multiplexed sequencing. The protocol supports shearing by either sonication or nebulization of 1 μg of DNA [12]. The genome of F. solisilvae 3-3T generated 7,041,525 reads totaling 1,422,388,050 bp data with an average coverage of 250 ×. Sequence assembly and quality assessment were performed using velvet v.1.2.10 [13] software. Finally, all reads were assembled into 75 contigs (> 200 bp) with a genome size of 5.41 Mbp.
Genome annotation
Genome annotation was performed through the NCBI Prokaryotic Genome Annotation Pipeline which combined the Best-Placed reference protein set and the gene caller GeneMarkS+. WebMGA-server [14] with E-value cutoff 1-e3 was used to assess the COGs. The translated predicted CDSs were also used to search against the Pfam protein families database [15]. TMHMM Server v.2.0 [16], SignalP 4.1 Server [17] and CRISPRfinder program [18] were used to predict transmenbrane helices, signal peptides and CRISPRs in the genome, respectively. The metabolic pathway analysis were constructed using the KEGG (Kyoto Encyclopedia of Genes and Genomes) [19].
Genome properties
The daft genome size of F. solisilvae 3-3T is 5,410,659 bp with 47 % GC content and contains 75 contigs. From a total of 4,698 genes, 4,215 (89.72 %) genes are protein coding genes, 439 (9.34 %) are pseudo genes and 44 (0.94 %) are RNA encoding genes. The genome properties and statistics are shown in Table 3 and Fig. 3. Altogether, 3,137 (74.42 %) protein coding genes are distributed into COG functional categories (Table 4).

A Graphical circular map of F. solisilvae 3-3T genome. From outside to center, ring 1, 4 show protein-coding genes colored by COG categories on forward or reverse strand; ring 2, 3 denote genes on forward or reverse strand; ring 5 shows G + C content plot, and the innermost ring represents GC skew
Insights from the genome sequence
F. solisilvae 3-3T could grow on 33 kinds of sole carbon substrates including saccharides, organic acids and amino acids [3] (Table 1). Analysis of the genome reveals that this strain possesses putative enzymes for central carbohydrate metabolism to assimilate these carbon sources through different metabolic pathways [20]. The putative enzymes that responsible to the utilization of 20 sole carbons were found in the genome (Table 5). All key enzymes in the Embden-Meyerhof-Parnas pathway (glucokinase, pyruvate kinase and 6-phosphofructokinase) and TCA cycle are present in F. solisilvae 3-3T. The key enzymes of Pentose Phosphate pathway (glucose-6-phosphate dehydrogenase, 6-phosphogluconolactonase and 6-phosphogluconate dehydrogenase) were also found.
The presence of 4-hydroxyphenylpyruvate dioxygenase (KIC95062), homogentisate 1,2-dioxygenase (KIC93392) and other related enzymes suggests that 4-hydroxyphenylacetic acid is degradable via homogentisic acid pathway [21]. In addition, the presence of 3-dehydroquinate dehydratase (KIC93382), shikimate dehydrogenase (KIC92987), shikimate kinase (KIC93265), 3-phosphoshikimate 1-carboxyvinyltransferase (KIC94147) and chorismate synthase (KIC94148) indicates that F. solisilvae 3-3T could probably utilize quinic acid to synthesize the three aromatic amino acids (tryptophan, tyrosine and phenylalanine) via shikimate pathway [7].
Conclusion
To the best of our knowledge, this report provides the first genomic information of the genus Flavihumibacter . Analysis of the genome shows high correlation between the genotypes and the phenotypes. The genome possesses many key proteins of central carbohydrate metabolism which provides the genomic basis to utilize the various carbon sources. In addition, analyzing its genome indicates that this strain has potential application for the production of aromatic amino acids and for environmental bioremediation.
Abbreviations
- TCA:
-
Tricarboxylic acid cycle
- PE:
-
Phosphatidylethanolamine
- MK-7:
-
Menaquinone-7
- PGAP:
-
Prokaryotic genome annotation pipeline
References
Zhang NN, Qu JH, Yuan HL, Sun YM, Yang JS. Flavihumibacter petaseus gen. nov., sp. nov., isolated from soil of a subtropical rainforest. Int J Syst Evol Microbiol. 2010;60:1609–12. doi:10.1099/ijs.0.011957-0.
Kim WH, Lee S, Ahn TY. Flavihumibacter cheonanensis sp. nov., isolated from sediment of a shallow stream. Int J Syst Evol Microbiol. 2014;64:3235–9. doi:10.1099/ijs.0.063370-0.
Lee HJ, Jeong SE, Cho MS, Kim SH, Lee SS, Lee BH, et al. Flavihumibacter solisilvae sp. nov., isolated from forest soil. Int J Syst Evol Microbiol. 2014;64:2897–901. doi:10.1099/ijs.0.063669-0.
Martin M, Cibello A, Fernandez J, Ferrer E, Garrido-Pertierra A. Catabolism of 3- and 4-hydroxyphenylacetic acid by Kelbsiella pneumoniae. J Gen Microbiol. 1991;137:621–8. doi:10.1099/00221287-137-3-621.
Méndez V, Agulló L, González M, Seeger M. The homogentisate and homoprotocatechuate central pathways are involved in 3- and 4-hydroxyphenylacetate degradation by Burkholderia xenovorans LB400. PLoS One. 2011;6:e17583. doi:10.1371/journal.pone.0017583.
Koma D, Yamanaka H, Moriyoshi K, Ohmoto T, Sakai K. Production of aromatic compounds by metabolically engineered Escherichia coli with an expanded shikimate pathway. Appl Environ Microbiol. 2012;78:6203–16. doi:10.1128/AEM.01148-12.
Guo J, Carrington Y, Alber A, Ehlting J. Molecular characterization of quinate and shikimate metabolism in Populus trichocarpa. J Biol Chem. 2014;289:23846–58. doi:10.1074/jbc.M114.558536.
Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S. MEGA5: molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol. 2011;28:2731–9. doi:10.1093/molbev/msr121.
Kimura M. A simple method for estimating evolutionary rates of base substitutions through comparative studies of nucleotide sequences. J Mol Evol. 1980;16:111–20.
Bernardet JF, Nakagawa Y, Holmes B. Proposed minimal standards for describing new taxa of the family Flavobacteriaceae and emended description of the family. Int J Syst Evol Microbiol. 2002;52:1049–70.doi:10.1099/ijs.0.02136-0.
Bennett S. Solexa Ltd. Pharmacogenomics. 2004;5:433–8. doi:10.1517/14622416.5.4.433.
Illumina official website. [www.illumina.com.cn]
Zerbino DR, Birney E. Velvet: algorithms for de novo short read assembly using de Bruijn graphs. Genome Res. 2008;18:821–9. doi:10.1101/gr.074492.107.
Wu S, Zhu ZW, Fu L, Niu BF, Li WZ. WebMGA: a customizable web server for fast metagenomic sequence analysis. BMC Genomics. 2011;12:444. doi:10.1186/1471-2164-12-444.
The Pfam protein families database. [http://pfam.xfam.org/search]
Krogh A, Larsson B, Heijne GV, Sonnhammer ELL. Predicting transmembrane protein topology with a hidden Markov model: application to complete genomes. J Mol Biol. 2001;305:567–80. doi:10.1006/jmbi.2000.4315.
Petersen TN, Brunak S, Heijine GV, Nielsen H. SignalP 4.0: discriminating signal peptides from transmembrane regions. Nat Methods. 2011;8:785–6. doi:10.1038/nmeth.1701.
Grissa I, Vergnaud G, Pourcel C. CRISPRFinder: a web tool to identify clustered regularly interspaced short palindromic repeats. Nucleic Acids Res. 2007;35:52–7. doi:10.1093/nar/gkm360.
Kanehisa M, Goto S, Sato Y, Kawashima M, Furumichi M, Tanabe M. Data, information, knowledge and principle: back to metabolism in KEGG. Nucleic Acids Res. 2014;42:D199–205. doi:10.1093/nar/gkt1076.
Justice NB, Norman A, Brown CT, Singh A, Thomas BC, Banfield JF. Comparison of environmental and isolate Sulfobacillus genomes reveals diverse carbon, sulfur, nitrogen, and hydrogen metabolisms. BMC Genomics. 2014;15:1107. doi:10.1186/1471-2164-15-1107.
van den Tweel WJJ, Smits JP, de Bont JAM. Catabolism of dl-α-phenylhydracrylic, phenylacetic and 3- and 4-hydroxyphenylacetic acid via homogentisic acid in a Flavobacterium sp. Arch Microbiol. 1988;149:207–13. doi:10.1007/BF00422006.
Field D, Garrity G, Gray T, Morrison N, Selengut J, Sterk P, et al. The minimum information about a genome sequence (MIGS) specification. Nat Biotechnol. 2008;26:541–7. doi:10.1038/nbt1360.
Woese CR, Kandler O, Weelis ML. Towards a natural system of organisms. Proposal for the domains Archaea, Bacteria and Eucarya. Proc Natl Acad Sci U S A. 1990;87:4576–4579. doi:10.1073/pnas.87.12.4576 [PubMed].
Krieg NR, Ludwig W, Euzéby J, Whitman WB. Phylum XIV. Bacteroidetes phyl. nov. In: Krieg NR, Staley JT, Brown DR, Hedlund BP, Paster BJ, Ward NL, Ludwig W, Whitman WB (eds), Bergey's Manual of Systematic Bacteriology, Volume 4, 2nd ed. Springer, New York, 2011, p. 25.
List Editor. Validation List No. 143. Int J Syst Evol Microbiol 2012; 62:1-4. doi:10.1099/ijs.0.039487-0 [PubMed].
Kämpfer P. Class III. Sphingobacteriia class. nov. In: Krieg NR, Stately JT, Brown DR, Hedlund BP, Paster BJ, Ward NL, Ludwing W, Whitman WB (eds), Bergey’s Manual of Systematic Bacteriology, Volume 4, 2nd ed. New York: Springer; 2011. p. 330.
Kämpfer P. Order I. Sphingobacteriales ord. nov. In: Krieg NR, Staley JT, Brown DR, Hedlund BP, Paster BJ, Ward NL, Ludwig W, Whitman WB (eds), Bergey's Manual of Systematic Bacteriology, Volume 4, 2nd ed. New York: Springer; 2011. p. 330
Kämpfer P, Lodders N, Falsen E. Hydrotalea flava gen. nov., sp. nov., a new member of the phylum Bacteroidetes and allocation of the genera Chitinophaga, Sediminibacterium, Lacibacter, Flavihumibacter, Flavisolibacter, Niabella, Niastella, Segetibacter, Parasegetibacter, Terrimonas, Ferruginibacter, Filimonas and Hydrotalea to the family Chitinophagaceae fam. nov. Int J Syst Evol Microbiol 2011; 61:518-523. doi:10.1099/ijs.0.023002-0 [PubMed].
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, et al. Gene ontology: tool for the unification of biology. The Gene Ontology Con-sortium. Nat Genet. 2000;25:25–9. doi:10.1038/75556.
Acknowledgment
This work was supported by the National Natural Science Foundation of China (31470227).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
GZ performed laboratory experiments, analyzed the data and wrote the draft manuscript. CC and COJ cultured samples, analyzed the data and revised the manuscript. ML performed the genome comparison and revised the manuscript. GW organized the study and revised the manuscript. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Zhou, G., Chen, C., Jeon, C.O. et al. High quality draft genomic sequence of Flavihumibacter solisilvae 3-3T . Stand in Genomic Sci 10, 66 (2015). https://doi.org/10.1186/s40793-015-0037-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40793-015-0037-6