
Abstract
A nonparametric method assessing the error and variability margins in solutions depicted in a separated form using experimental results is illustrated in this work. The method assess the total variability of the solution including the modeling error and the truncation error when experimental results are available. The illustrated method is based on the use of the PGD separated form solutions, enriched by transforming a part of the PGD basis vectors into probabilistic one. The constructed probabilistic vectors are restricted to the physical solution’s Stiefel manifold. The result is a real-time parametric PGD solution enhanced with the solution variability and the confidence intervals.
Similar content being viewed by others

Introduction
Nowadays, simulation-based decision making in engineering and sciences is widely accepted and used in predicting material and parts behavior. Many partial differential equation (PDE) models are widely accepted and used in the industry, while constantly being improved to increase their fidelity. On the other hand, many advanced methods for solving PDEs are being designed to improve solution speed, aiming for real-time applications [4, 11, 13, 30, 37]. These techniques are commonly known by model order reduction techniques (or simply model reduction techniques), mainly aiming at constructing a reduced basis for the solution of PDEs [22, 40].
Regarding model order reduction techniques, the methods are divided into two large categories: (i) “a priori” model reduction techniques, which aims at constructing a solution in a reduced basis separated form, before having any knowledge of the full order model or also the high definition model (HDM) solution [21, 27]. (ii) “a posteriori” model reduction techniques, where the reduced order basis of projection is constructed from previous HDM solutions computed using efficient greedy algorithms to construct as accurate as possible reduced order basis [5, 6, 34, 39]. The PGD method appears to be the only “a priori” model reduction technique which is widely used nowadays to compute solutions in a fairly separable domain [10, 25, 26]. Using model reduction techniques or reduced order basis methods lead in general to a good approximation, which tends to the finite element approximation when increasing the size of the projection basis [2, 3, 41]. However, it is known that model reduction techniques in general involve a truncation error (either being an “a priori” or “a posteriori” techniques) as well as modeling errors, inherited from their full-order models counterparts, also known as high definition models (HDM) [18]. Therefore, a margin of improvement of the solution do exist.
On the other hand, with the current development of machine learning and data-driven techniques, fitting data using surrogate models based on regressions, neural network is becoming widely available and increasingly popular [14, 24, 32, 47]. However, these surrogate models do not impose naturally physical conditions like the conservation of mass or energy. Therefore, some other PDE fitting techniques are being developed, based on satisfying thermodynamic constraints, using methods like the GENERIC formalism [20, 29] or the General Equilibrium for Non-Equilibrium Reversible-Irreversible Coupling [31, 38]. However, often engineering applications data is scarce and expensive to generate in sufficient quantities to solely rely on data models. Therefore, to leverage recent developments of artificial intelligence and machine learning algorithms, combinations of model reduction techniques with machine learning are built to address the modeling and truncation errors, either by error correction [1] or by improvement of modal selection using the quantities of interest [33].
Another appealing approach for creating data-driven surrogate models while leveraging previously well-established models is the “Digital Twins” approach [1, 9]. Digital twins are built based on the correction of previously established PDEs using surrogate models, to learn new physics or establish new models quantifying the error [19, 28], but also to incorporate the variability of the experimental results in the HDM or reduced order models solutions [15, 45, 46]. Multiple other works aimed to quantify the errors induced by modeling, either for the HDM solutions [16, 17, 36, 42], or for using model reduction techniques relying on reduced order basis (ROB) [8, 44, 45]. Moreover, a non-parametric probabilistic method (NPM) for error quantification was introduced in [43] and extended to \(\mu \)-parametric ROB methods in [45]. The NPM method has the advantage of quantifying uncertainties independently of their sources, either modeling errors, nonlinear modeling, truncation errors... This is performed by replacing the deterministic reduced basis by a stochastic counterpart [45]. However, to the best knowledge of the authors, non of these techniques where adapted to be used for the Proper Generalized Decomposition (PGD) framework, but are rather used for the Finite elements HDM approach, or for a \(\mu \)-parametric ROB solution [45].
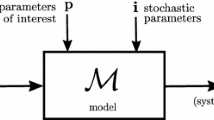
In this work, we aim to extend the NPM method presented in [45] to the PGD framework. The extension results in a stochastic solution based on a stochastic reduced basis, who’s variations are restricted to the Stiefel manifold of the original PGD solution. The variations are controlled by several hyper parameters identified through solving an optimization problem on the fly, as the method do not require any direct solution of the PDE modeling the problem during optimization.
First of all, we will revisit NPM approach in “NPM method for PGD solutions” section of this work. Later on, we introduce the PGD simulation and experimental measurements of the automated tape placement, the application selected for this work, in “The automated tape placement process, simulation and measurements” section. In “NPM method applied for the PGD simulation of the automated tape placement process” section we illustrate the NPM results applied on the PGD solution obtained in “The automated tape placement process, simulation and measurements” section. Finally the article is wrapped up with discussions and conclusions in “Conclusion” section.
NPM method for PGD solutions
Short review of NPM for reduced order basis
Let’s consider for illustration purpose a PDE having the following semi-discrete formulation:
with t being the time domain, and the solution [y] can be projected on a reduced basis [V] such as:
The variable [q(t)] is the solution of the PDE equation depicted in Eq. (1) in the reduced coordinate system, after projection on the reduced order basis, and solving as a function of the time. The NPM method consists of replacing a reduced order basis \([V]\in \mathbb {R}_{(N,n)}\) by a stochastic counterpart \([\mathbf {V}]\in \mathbb {R}_{(N,n)}\), where N is the number of degrees of freedom in the HDM model, and n is the dimension of the built reduced basis. Considering a set of constraints or Dirichlet boundary conditions defined by a matrix \([B] \in \mathbb {R}_{(N,N_{BC})}\), the reduced basis [V] should satisfy the following orthogonality and boundary conditions constraints:
where \([I_n]\) being the identity matrix in a domain having the dimension of the reduced basis n, and \([M]\in [N,N]\) the mass matrix of the problem in question. Therefore, the stochastic reduced basis should satisfy the same constraints as the initial reduced basis:
Using NPM, the stochastic basis \([\mathbf {V}]\) is constructed using the maximum entropy principle, while variation of [V] to construct \([\mathbf {V}]\) should be performed on the tangent vector \(T_v\) space defined by [45]:
with [Z] being therefore the first derivative of [V] using the inner product \(<<V_1,V_2>>=tr\left\{ [V_1]^T [M] [V_2]\right\} \). Therefore, [Z] can be built in the following form:
Defining \([\mathbf {a}]\), \([\mathbf {b}]\) and \([\mathbf {V}_\perp ]\) leads to the following construction algorithm [45]:
with \([\sigma ]\) being an \(n\times n\) upper diagonal matrix of hyper-parameters \(\in \mathsf {R}\) to be identified, \([\mathbf {G}(\beta )]\) is a second order centered random matrix \(\in \mathsf {R}_{(N,n)}\) built from two uniform random distributions as well as the hyper-parameter \(\beta \in [0;1]\), as described in the appendix D in [45]. \(s\in [0;1]\) is also a hyper-parameter to define. The problem hyper-parameters are found using the following minimization problem:
We define \(w\in [0;1]\) as a weight to insure as much as possible a convexity in the cost function. \(E(\cdot )\) defines the mean of a distribution, \(Var(\cdot )\) define the standard deviation of a given distribution. \(E_{exp}\) and \(Var_{exp}\) are the experimental values of the target values of the quantities of interest \(\mathcal {O}([\mathbf {V}],t)\), t being the time domain. The quantities of interest are defined as a function of the solution of the PDE equations of the modeled problem:
with \([p(t)]\in \mathsf {R}[n,m]\) the solution of the PDE in the reduced order basis coordinate system, m being the length of the mesh in the time domain. Computing [p(t)] would require a direct solution of the PDE (1) in the reduced coordinate system, for every variation of the reduced basis \([\mathbf {V}]\). This gets even more time consuming when the derivatives are to be computed numerically during the optimization process. Interested readers are referred to the [15, 45, 46] and their references therein.
To evaluate stochastic quantities of interests of the generated stochastic solution \(\mathbf {y}\), derived from the expression of NPM, one may need to repeat the algorithm (7) m times, to construct several solutions for different selection values of \([\mathbf {G}(\beta )]\). In fact, \([\mathbf {G}(\beta )]\) is the only random distribution, generated out of two uniform random distributions as explained in the appendix of [45]. Therefore, one evaluation of the cost function depicted in (8) requires m solutions of the problem depicted in the reduced basis \([\mathbf {V}]\). Such approach can lead to prohibitive calculation times when solving complex PDEs in a large computation domain expressing multiple number of reduced coordinates.
NPM method for PGD solutions
The PGD solutions are computed in a separated form such as [11]:
with \(q_j\) the separated coordinates of the problem, and \(\mathcal {Q}_{ij}(q_j)\) the recurrent solutions in the domain \(q_j\). In a discrete form, \(\mathcal {Q}_{ij}\) becomes a matrix \([Q]_j \in \mathsf {R}[N_j,\mathcal {N}]\), with \(N_j\) the number of degrees of freedom in \(q_j\) domain, and \(\mathcal {N}\) the number of products of functions required to converge the PGD solution of the problem. Using NPM, we choose to enrich some (or all) of the PGD reduced coordinates solution using the same algorithm depicted in Eq. (7). The results for a reduced basis of a domain \([q_j]\) results in the following:
The algorithm illustrated in Eq. (11) represents an enrichment of one dimension in the PGD solution domain. The same algorithm can be designed to enrich as much dimensions as required, by generating the random basis \([\mathbf {G}(\beta )]\) as a higher dimensionality array. The number of hyper-parameters of the problem with increase accordingly.
In the optimization process, evaluating the quantities of interests \(\mathcal {O}([\mathbf {Q}],t)\) do not require any solution of the PDE problem, as the PGD defines a surrogate model replacing the PDE with a product of functions defined in every dimension of the domain. For instance, the evaluation of the quantities of interest for any solution requires only the knowledge of the solution y defined by:
where \(\mathcal {D}_d\) are the deterministic, non-enriched basis, while \(\mathcal {D}_p\) are the probabilistic basis, enriched using NPM. Therefore, one solution and thus one evaluation of the quantities of interests, is computed only by using the product and sum of matrices.
The automated tape placement process, simulation and measurements
The automated tape placement process (ATP) is a one step, out-of-autoclave, composite manufacturing process [12, 35]. It aims a continuous deposit of prepreg tapes, while heating the deposit region and compressing the incoming tape to achieve a certain degree of consolidation, from low cohesion of the tapes to consolidated panels. The process has the potential to achieve in a unique step the manufacturing of composite parts in the final shape.
Experimental process
The studied process is the deposition of prepregs on a heated cylindrical shape substrate, while heating with three external radiative heat source, the \(\mathrm{RHS}_{0}\) controls the temperature Tin and will not be modeled in the rest of this work. The process is illustrated in Fig. 1. The system is also equipped with two infrared camera to measure the temperature fields during deposition. The measurement is performed on 6 selected points as marked in Fig. 2. Figure 2 also illustrates the position of selected probing points. Figure 2a illustrates the top view of the currently deposited prepreg, referred as layer l later on, with 3 selected points 1, 2, and 3. Point 3 is considered as an input to the simulation, the temperature of the incoming prepreg \(T_{in}\). Figure 2b shows a bottom view of the deposited prepreg with point 5 considered as the temperature of the drum unrolling the prepreg, not represented in the simulated region. Points 1, 2, 3 and 4 in Fig. 2b illustrate the top region of the previously deposited layer, referred as layer \(l-1\) later in this manuscript. The used material is prepreg tapes made of unidirectional carbon fibers impregnated with a thermoplastic matrix.

The ATP winding process with the three radiative heat sources marked as \(RHS_1\) and \(RHS_2\), the incoming tape temperature is \(T_{in}\), the cylindrical deposition base has a radius \(R_c=54\, \text {mm}\) and a controlled temperature \(T_b\)

The thermal camera with the control points 1 and 2 from a and 1 to 4 from b
The measurements are performed at a constant time step \(\Delta t=0.5\,\text {s}\). After measurements, the data is formatted and filtered using a moving least squares approach [7, 23]. The experiment will deposit 4 times each of the first ply, then 4 times the second ply and so on, until depositing 6 plies in each experiment. We dispose of experiments with 2 sets of parameters used. The parameters are illustrated in Table 1. The final filtered results from camera 1, for test one, one of the four measurements, are illustrated in Fig. 3. In Fig. 3, we use the deposition velocity and the perimeter to find the deposition time of each of the 6 overlapping layers. The means and standard deviations of the selected points for the parameters set 1 is illustrated in Figs. 6 and 7, while the ones for the set 2 appears in Figs. 8 and 9.

The measurement data performed by thermal camera 1 at control points 1 and 2
PGD simulation
In this part we explain the modeling and simulation performed in the context of the ATP process. The modeling is performed in the cylindrical \((r,\theta ,z)\) coordinate system. When considering the reference as the \(RHS_1\) for example, one can work in a steady state formulation considering the convection-diffusion equation. In cylindrical coordinates, the governing equation becomes:
with U being the temperature, \(\rho \) being the density, \(C_p\) the thermal capacity at constant pressure, \(\mathbf {w}\) the angular velocity, \((K_r,K_\theta ,K_z)\) the diagonal components of the conductivity tensor. One may note that the deposition in the studied process orients the fibers in the tangential direction only, therefore the out-of-diagonal components of the conductivity tensor are all set to zero.
Multiplying Eq. (13) by r first and by a test function \(U^*\), then integrating by part, Eq. (13) will lead to the weak form of the problem:
\(\mathbf {K}\) being the conductivity tensor, \(\mathbf {n}\) the outward normal and \(\Gamma \) the boundary of the domain \(\Omega \). Equation () is therefore the governing equation to be solved, coupled with the boundary conditions depicted in Fig. 4. A boundary condition of symmetry impose the continuity of the temperature between ply l at \(\theta =2\pi \) and ply \(l-1\) at \(\theta =0\). The tip of the very first layer is considered adiabatic. The boundary conditions are reviewed in Eq. 14.
with \(t_l=0.2\,\text {mm}\) the thickness of a prepreg layer, and \(l_\theta \approx 3.55\,\text {rad}\) the angular length between the probe 3 in Fig. 2a and the point of contact between layers l and \(l-1\), \(h_{air}=15\,\text {W}/\text {m}^2\text {k}\) the coefficient of convection with the air at ambient temperature \(T_\infty =25\,^\circ \)C. In the experimental results, \(T_b\) and \(T_{in}\) are constantly changing, therefore they are considered as extra parameters of the problem, varying inside a predefined interval: \(T_{in} \in [25;350]\,^\circ \)C and \(T_{b} \in [25;250]\,^\circ \)C. Moreover, the deposit angular velocity \(\mathbf {w}\) as well as the thermal heat flux generated by the radiatives sources \(RHS_1\) and \(RHS_2\), \(Q_1\) and \(Q_2\) respectively, are also considered as extra parameters of the problem. The solution is therefore obtained in a separated form as:
Readers unfamiliar with the PGD solution in separated form are referred to the following references and their references therein [10, 11].

The modeling of the ATP process
Moreover, a thermal contact resistance is introduced between deposited ply, as described in [12, 18], with a thermal conductance \(h=6000\,\text {W}/\text {m}^2\,\text {K}\). The involved problem parameters are depicted in Table 2.
The simulation results are depicted in Fig. 5 for the deposition of layers 3 and 5. The results show a discontinuity between deposited layers, as induced by the modeled thermal contact resistance. The simulated results are compared to the experimental ones in Figs. 6 and 7. The experimental results show large variability. Only 4 experiments were available to compute the mean and the standard deviation. The results are shown for \(\mathbf {w}=0.0533\) rad/s, \(Q_1=9250\, \text {W}/\text {m}^2\) and \(Q_2=4500\,\text {W}/\text {m}^2\). \(T_{in}\) and \(T_b\) are experimental inputs.

Vertical section in the deposited layers during the deposition of the 3rd and 5th layers. Temperatures in \(^\circ \)C

Comparison of the simulated temperature in the middle of the top layer, with experimental measurements, for the 3rd and 5th layer deposition. Temperatures in \(^\circ \)C

Comparison of the simulated temperature in the middle of layer \(l-1\) during the deposition of layer n, with experimental measurements, for \(l=3\) and \(l=5\). Temperatures in C
NPM method applied for the PGD simulation of the automated tape placement process
Once the experimental and simulation results available, the NPM for PGD algorithm can be used to update and correct the simulated results with the experimental data. The experimental data are considered ground truth in this work, despite the large variability shown in some measurements. The cost function to optimize in this problem is given by:
With \(U_{sim}=U\left( r^{exp},\theta ^{exp},z=Z_{max}/2,T_{in}^{exp}, T_b^{exp},\mathbf {w}^{exp},Q_1^{exp},Q_2^{exp}\right) \), the evaluation of the simulation abacus at the points having the same input parametric values as the performed experiments. In Eq. (16), \(\sigma \) refers to the standard deviation.
One may note that evaluating the cost function (16) would require multiple evaluation of the PDE solution, however no extra solution is required in the PGD framework. Only multiplications of vectors and matrices are involved.
The enriched PGD solution with NPM for PGD algorithm are illustrated in Figs. 8 and 9 for the temperature fields in the 3rd and 5th deposited layer respectively. The results are computed after performing \(m=100\) calculation of the enrichment basis. The PGD enrichment is limited to the 5 most energetic PGD product of vectors. Figures 8 and 9 show the results for NPM–PGD enhancement. The results shown an adaptation of the solution to overlap as much as possible with the experimental results, while translating the experimental results’ variability into a simulation confidence interval.

Enrichement of the deposition of the fifth layer using the NPM for PGD algorithm, \(l=3\). Temperatures in C

Enrichement of the deposition of the fifth layer using the NPM for PGD algorithm, \(l=5\). Temperatures in C
Conclusion
In this work, we illustrate the possibility of using the Non-parametric Probabilistic Method (NPM) in the Proper Generalized Decomposition (PGD) framework. The formulation for the PGD framework shows the possibility to enrich the solution and correct it using the NPM, without the need to perform any extra PDE solutions.
The selected application was the ATP, which deposits unidirectional fiber reinforced plastics on a cylindrical shape using a continuous deposition, and radiative heating. The process is modeled using a novel approach and the simulation results are compared to the experimental ones, before and after enrichment. Before enrichment, the results are in good agreement with the experimental ones. The enrichment process induced a large improvement the results and illustrates the experimental variability as reflected on the presented results.
Availability of data and materials
Raw measurement data are available upon request.
References
Ahmed Adel and khaled Salah. Model order reduction using artificial neural networks. In 2016 IEEE International Conference on Electronics, Circuits and Systems (ICECS), pages 89–92. IEEE, 2016.
Ammar Amin, Chinesta Francisco, Diez Pedro, Huerta Antonio. An error estimator for seperated representations of highly multidimensional models. Computer methods in applied mechanics and engineering. 2010;199:1872–80.
Ammar Amin, Chinesta Francisco, Falco Antonio. On the convergence of a greedy rank-one update algorithm for a class of linear systems. Archive of computational methods in engineering. 2010;17(4):473–86.
Amsallem D, Zahr M, Choi Y, Farhat C. Design optimization using hyper-reduced-order models. Structural and Multidisciplinary Optimization. 2015;51(4):919–40.
David Amsallem and Charbel Farhat. Projection-based reduced-order modeling. In Stanford University Reduced Order modelling Course, (2011).
Bernardi Christine, Maday Yvon. Spectral methods. Handbook of Numerical. Analysis. 1997;5:209–485.
Breitkopf Piotr, Rassineux Alain, Villon Pierre. An introduction to moving least squares meshfree methods. Meshfree Computational Mechanics. 2002;11:825–67.
Bui-Thanh T, Willcox K, Ghattas O. Parametric reduced-order models for probabilistic analysis of unsteady aerodynamic applications. American Institute of Aeronautics and Astronautics Journal. 2008;46(10):2520–9.
Chinesta F, Cueto E, Abisset-Chavan E, Duval J-L, Khaldi F. Virtual, digital and hybrid twins: A new paradigm in data-based engineering and engineered data. Archives of Computational Methods in Engineering. 2020;27:105–34.
Chinesta F, Keunings R, Leygue A. The proper generalized decomposition for advanced numerical simulations. Springer; 2014.
Chinesta Francisco, Ammar Amine, Cueto Elias. Recent advances in the use of the proper generalized decomposition for solving multidimensional models. Archives of Computational Methods in Engineering. 2010;17(4):327–50.
Chinesta Francisco, Leygue Adrien, Bognet Brice, Ghnatios Chady, Poulahon Fabien, Bordeu Felipe, Barasinski Anais, Poitou Aranud, Chatel Sylvain, Maison-Le-Poec Sebastien. First steps towards an advanced simulation of composites manufacturing by automated tape placement. International journal of material forming. 2014;7(1):81–92.
Cueto Elias, Ghnatios Chady, Chinesta Francisco, Monte Nicolas, Sanchez Fernando, Falco Antonio. Improving computational efficiency in lcm by using computational geometry and model reduction techniques. Key Engineering Materials. 2014;611:339–43.
B.P. Van de Weg, L. Greve, M. Andres, T.K. Eller, and B. Rosic. Neural network-based surrogate model for a bifurcating structural fracture response. Engineering Fracture Mechanics, 241:107424, January 2021.
Farhat C, Bos A, Avery P, Soize C. Modeling and quantification of model-form uncertainties in eigenvalue computations using a stochastic reduced model. American Institute of Aeronautics and Astronautics Journal. 2017;56(3):1–22.
Ghanem R, Spanos PD. Stochastic Finite Elements: A spectral approach. New York: Springer Verlag; 1991.
R. Ghanem and P.D. Spanos. Stochastic Finite Elements: A spectral approach (revised edition). Dover publications, New York, 2003.
C. Ghnatios. Simulation avancée des problemes thermiques rencontrés lors de la mise en forme des composites. PhD thesis, Ecole Centrale Nantes, October (2012).
C. Ghnatios. A hybrid modeling combining the proper generalized decomposition (pgd) approach to data-driven model learners, with application to non-linear biphasic materials. Comptes rendus mécanique, In Press, 2021.
Ghnatios C, Alfaro I, Gonzalez D, Chinesta F, Cueto E. Data-driven generic modeling of poroviscoelastic materials. Entropy. 2019;21(12):1165.
C. Ghnatios, A. Ammar, A. Cimetiere, A. Hamdouni, A. Leygue, and F. Chinesta. First steps in the space separated representation of models defined in complex domains. In ASME 2012 11th Biennial Conference on Engineering Systems Design and Analysis, ESDA 2012, pages 37–42. ASME, 2012.
C. Ghnatios, G. Asmar, E. Chakar, and C. Bou Mosleh. A reduced-order model manifold technique for automated structural defects judging using the pgd with analytical validation. Comptes rendus mecanique, 34(2):101–113, February 2019.
C. Ghnatios, I. Hage, and N. Metni. Knee joint injury risk assessment bymeans of experimental measurements and proper generalized decomposition. Comptes rendus mécanique, 1, 2021.
Ghnatios C, Hage R-M, Hage I. An efficient tabu-search optimized regression for data-driven modeling. Compte rendu mecanique. 2019;347(11):806–16.
Chady Ghnatios, Emmanuelle Abisset, Amine Ammar, Elias Cueto, Jean-Louis Duval, and Francisco Chinesta. Advanced separated spatial representations for hardly separable domains. Computer methods in applied mechanics and engineering, 354:802–819, September 2019.
Chady Ghnatios, Elias Cueto, Antonio Falco, Jean-Louis Duval, and Francisco Chinesta. Spurious-free interpolations for non-intrusive pgd-based parametric solutions: Application to composites forming processes. International Journal of material forming, 2020.
Ghnatios Chady, Mathis Christian H, Simic Rok, Spencer Nicholas D, Chinesta Francisco. Modeling soft permeable matter with the proper generalized decomposition (pgd) approach, and verification by means of nanoindentation. Soft Matter. 2017;13:4482–93.
Gonzlez D, Chinesta F, Cueto E. Learning corrections for hyperelastic models from data. Front Mater. 2019;6(14):1–12.
Gonzlez D, Chinesta F, Cueto E. Thermodynamically consistent data-driven computational mechanics. Contin Mech Thermodyn. 2019;31:239–53.
M.A. Grepl, Y. Maday, N.C. Nguyen, and A. Patera. A. efficient reduced-basis treatment of nonaffine and nonlinear partial differential equations. ESAIM: Mathematical Modelling and Numerical Analysis, 41(30):575–605, 2007.
Grmela M. Multiscale thermodynamics Enthropy. 2021;23(165):1–46.
Hage R-M, Hage I, Ghnatios C, Jawahir IS, Hamade R. Optimized tabu search estimation of wear characteristics and cutting forces in compact core drilling of basalt rock using pcd tool inserts. Computers & industrial engineering. 2019;136(10):477–93.
David Hartman and Lalit K. Mestha. A deep learning framework for model reduction of dynamical systems. In 2017 IEEE Conference on Control Technology and Applications (CCTA), pages 1917–1922, Hawai, USA, 2017. IEEE.
Leonenko GM, Phillips TN. On the resolution of the fokker-planck equation using a high-order reduced basis approximation. Computer Methods in Applied Mechanics and Engineering. 2009;199(1–4):58–168.
Arthur Levy, Dirk Heider, John Tierney, and John W. Gillespie Jr. Simulation and optimization of the thermoplastic automated tape placement (atp) process. In SAMPLE Conference, Baltimore, May 2012.
Le Maitre OP, Knio OM. Spectral Methods for Uncerainty Quantification with Applications to Computational Fluid Dynamics. Heidelberg: Springer; 2010.
Nguyen N, Peraire J. An efficient reduced-order modeling approach for nonlinear parametrized partial differential equations. International Journal for Numerical Methods in Engineering. 2008;76(1):27–55.
Ottinger HC. Beyond Equilibrium Thermodynamics. Wiley-Interscience; 2005.
Patera Anthony T, Ronquist Einar M. Reduced basis approximation and a posteriori error estimation for a boltzmann model. Computer Methods in Applied Mechanics and Engineering. 2007;196:2925–42.
Perez M, Barasinski A, Courtemanche B, Ghnatios C, Chinesta F. Sensitivity thermal analysis in the laser-assisted tape placement process. AIMS Materials Science. 2018;5(6):1053–72.
Porsching TA. Estimation of the error in reduced basis method solution of nonlinear equations. Mathematical and Computer Modelling. 1985;45(172):487–96.
Schueller GI. Computational methods in stochastic mechanics and reliability analysis. Computer methods in applied mechanics and engineering. 2005;194(12–16):1251–795.
Soize C. A nonparametric model of random uncertainties for reduced matrix models in structural dynamics. Probabilistic Engineering Mechanics. 2000;15(3):277–94.
Soize C. Stochastic modeling of uncertainties in computational structural dynamics - recent theoretical advances. Journal of Sound and Vibration. 2013;332(10):2379–95.
Soize C, Farhat C. A nonparametric probabilistic approach for quantifying uncertainties in low- and high-dimensional nonlinear models. International Journal for Numerical methods in engineering. 2016;109:837–88.
Soize C, Farhat C. Probabilistic learning for modeling and quantifying model-form uncertainties in nonlinear computational mechanics. International Journal for Numerical methods in engineering. 2019;117:819–43.
R. Xu, N. Wang, and D. Zhang. Solution of diffusivity equations with local sources/sinks and surrogate modeling using weak form theory-guided neural network. Advances in water resources, In press, 2021.
Acknowledgements
The authors acknowledge the contribution of CANOE for data production.
Funding
This work is made possible by the financial support of the Chair partners (E2S UPPA, ARKEMA and CANOE) AWESOME. The authors would like to thank the aforementioned Chair partners (E2S UPPA, ARKEMA and CANOE) for funding their work.
Author information
Authors and Affiliations
Contributions
CG contributed to the theoretical, coding and writing parts. AB contributed to the theoretical, data collection and writing parts. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghnatios, C., Barasinski, A. A nonparametric probabilistic method to enhance PGD solutions with data-driven approach, application to the automated tape placement process. Adv. Model. and Simul. in Eng. Sci. 8, 20 (2021). https://doi.org/10.1186/s40323-021-00205-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40323-021-00205-5