
Abstract
In this study the characterisation and separation/discrimination of three sheep breeds (crosses, West African Dwarfs (WAD) and West African Long Legged (WALL)] based on their physical traits (morphological characterisation) was investigated extensively with the application of discriminant analysis. The study’s main objective was specifically based on developing a variable selection criterion that can discriminate best among the three sheep breeds and as well as obtain a reliable mathematical function/equation (discriminant functions) for provision of maximum separation among the three known sheep breeds. Data from College of Education, Mampong animal farms on various breeds of sheep (hybrid/crossed breed, Sahell/WALL and Djallonke/WAD) was used. Factor Analysis was employed as a variable selection criterion for selecting six sheep traits that can discriminate best among the sheep breeds. Canonical discriminant function was derived for the eight variable data set and was compared with the derived quadratic discriminant functions (QDFs) using the six extracted sheep traits. The six variable QDF distance classifier provided maximum separation after cross validation than the 8-variable canonical discriminant functions. The derived mathematical functions (QDFs) were able to provide maximum separation among the three known sheep breeds with a correct classification rate of 0.86.
Similar content being viewed by others
Background
The assignment/allocation of individuals/observations to the various known groups with their respective mean vectors and distinguishing characteristics has been a major concern for years and research is ongoing to obtain the best function to ensure maximum separation. This study considered the separation/classification of sheep into their respective groups [cross breed/hybrid West African Longed legged (WALL) and local breed (WAD)] based on their measured physical characteristics by using two classification functions and the evaluation of the performance of the classification functions using error estimators.
Morphological characterization entails the description and documentation of the physical traits of a breed (Rege 1992). The World Watch List for Domestic Animal Diversity (WWL-DAD) prepared by FAO (2000) defined a breed as either a homogenous, sub-specific group of domestic livestock with definable and identifiable external characteristics that enable it to be separated by visual appraisal from other similarly defined groups within the same species.
Characterization of animal genetic resource (AnGR) encompasses all activities associated with the identification, quantitative and qualitative description of breed populations and the natural habitat and production systems to which they are or not adapted. Food and Agricultural Organisation FAO (2007) estimates that industrial livestock operations are growing twice as fast as traditional mixed farming systems and six times as fast as traditional grazing systems. Sheep seem to have received the least attention in all aspect of management, nutrition breeding and health in spite of the fact that they have many merits over some other classes of livestock and are found in all towns and villages in Ghana (Koney 2004). In Ghana, sheep are often seem to roam about to fend for themselves during the day in many rural areas with animals from different households mixing together of unknown records. Livestock production is a major feature in Ghana’s agriculture and contributes largely towards meetings food needs, providing drought power, manure to maintain soil fertility and structure and cash income, particularly for farmers in the northern part of the country (Oppong-Anane 2006).
Discriminant analysis is used in situations where the clusters are known a priori. The aim of discriminant analysis is to classify an observation, or several observations, into already known groups (Hardel and Simar 2007). The problem of statistical discrimination involving three multivariate normal distributions with known or unknown population centroids and with equal (or unequal) covariance matrices has been considered by many researchers. Some other researchers have applied the concept of discriminant analysis which also serves as a classificatory rule in allocating observations/objects into their known groups. Researchers including Fisher (1936), Lachenbruch (1975), Krzanowski and Hand (1997), Desu and Geisser (1973) have used discriminant analysis extensively in various fields where mostly linear discriminant function (LDF) was the main classification function obtained for classifying the known observations.
A research paper published in the International Journal of Biodiversity and Conservation, volume 5 on Morphometric characterization of Nigerian indigenous sheep using multifactorial discriminant analysis was investigated by Yunusa et al. (2013). Stepwise multifactorial discriminant analysis was employed. Among the eight (8) distinguishing traits found, their length of tail was found to be the most discriminating character. A multivariate analysis of phenotype differentiation in Bunaji and Sokoto Gudali cattle was investigated by Yakubu et al. (2010b). The researcher applied multi-factorial discriminant analyses using ten morphological traits in examining morphometric differentiation in two Nigerian breeds of cattle. The Nearest Neighbour Discriminant Analysis was employed and 85.48 % Bunaji cattle were classified into their source population while 96.55 % of their Sokoto Gudali counterparts were correctly assigned into their source genetic group.
Herrera et al. (1996) studied an application of a multifactorial discriminant analysis in the morpho-structural differentiation of Andalusian caprine breeds in Spain. Yakubu et al. (2010a) conducted a study by applying the concept of discriminant analysis on morphometric differentiation in West African Dwarf and Red Sokoto goats. Aziz and Al-Hur (2013) applied Size-free Canonical Discriminant Analysis in differentiating between three Saudi goat types. They utilised body weight and 16 body measurements randomly selected from the three Saudi goats and was used to discriminate between 188 animals after conducting a size free discriminant analysis on the data.
Traore et al. (2008) investigated into multivariate characterization of morphological traits in Burkina Faso sheep. Their study was based on 6440 female sheep from Burkina Faso and seven body measurements were taken as well as four qualitative morphological traits. Their study sample also included three main environmental areas and sheep breeds of Burkina Faso namely the Sahel area (Burkina-Sahel sheep), the Sudan-Sahel area (Mossi sheep) and the Sudan area (Djallonke sheep). Results from the Canonical analysis showed that, there exist small differences in the recorded body measurements of Sudan and the Sudan-Sahel sheep even though most body traits showed higher average values in the Burkina-Sahel sheep. Ebegbulem et al. (2011) researched into the morphometric differentiation of West African Dwarf Goats in southeastern Nigeria using discriminant Analysis. One hundred and twenty-one (121) West African Dwarf (WAD) goats aged between <1 year and 4 years sampled from local farmers from Nigeria were used for the study. After the application of discriminant analysis, 83.5 % of correct classification of goats was achieved.
Methods
This part of the study explains in details the various methods employed in the analysis of the data. The method of analysis looks at discriminant analysis approach in general and factor analysis as a criterion for variable selection (i.e. data reduction tool).
Data used
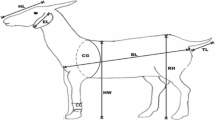
The data used was based on 61 sheep breeds which comprises the crosses, the Djallonke and the West African Longed Legged (WAD) breeds with eight measured morphological traits namely Height at withers (Ht), Body Length (Lt), Ear Length (EL), Weight (Wt), Chest girth (Chst), Hook Length (HL), Tail Length (TL) and Difference between Hook length and Tail length (HL-TL) which was collected from the College of Science Animal farm at Mampong Ashanti.
Allocation rules for known distributions
Discriminant analysis is a set of methods and tools used to distinguish between groups of populations, \(\pi_{i}\) and to determine how to allocate new observations into groups. In general we have populations \(\pi_{j} ,j = 1,2, \ldots ,J\) and we have to allocate an observation x to one of these groups.
Classification with equal covariance matrices (\(\Sigma_{i} = \Sigma_{j} = \Sigma\))
The density of population \(\pi_{i}\), \(i = 1,2\) is given by;
If the populations \(\pi_{1}\) and \(\pi_{2}\) both have multivariate normal densities with equal covariance matrices, then the classification rule corresponding to minimizing Expected Cost of Misclassification (ECM) becomes:
Classify \(x_{0}\) as \(\pi_{1}\) if
The sample estimates for Eq. (2) can be obtained by replacing \(\mu_{1}\), \(\mu_{2}\) and \(\Sigma\) with \(\bar{x}_{1}\), \(\bar{x}_{2}\) and \(S_{pooled}\). For a special case for Eq. (2), when the prior probabilities and the misclassification cost are equal, we assign \(x_{0}\) to \(\pi_{1}\) if:
Denote \(a = S_{pooled}^{ - 1} (\bar{x}_{1} - \bar{x}_{2} ) \in \Re\) and the above equation can be written as
(Johnson and Wichern 2007). Similar approach was applied when three populations were considered in this study.
The quadratic classifier \(\left( \sum_{1} \ne \sum_{2}\right)\)
The regions of minimum ECM and minimum total probability of misclassification (TPM) depends on the ratio of the densities. Hence substituting the normal densities with different covariance matrices in Eq. 1 after taking natural logarithm gives the following classification regions. Allocate x to \(\pi_{1}\) or otherwise to \(\pi_{2}\) if,
where
Classification into several populations
Generalization of classification procedure for more than two discriminating groups (i.e. from 2 to \(g \ge 2\)) is straight forward. However, not much is known about the properties of the corresponding sample classification function, and in particular, their error rates have not been fully investigated. Therefore, we focus only on the Minimum ECM Classification with equal misclassification cost and Minimum Total Probability of Misclassification (TPM) for multivariate normal population with unequal covariance matrices (Quadratic discriminant analysis).
Cross validation (CV)
The (leave-one-out) cross-validation or jackknife procedure or the Holdout method which works as follows:
-
1.
Leave one object out of the sample and construct a classification rule based on the remaining \(n - 1\) objects in the sample.
-
2.
Classify the left-out observation using the classification rule obtained in step 1 above.
-
3.
Repeat the two previous steps for each of the objects in the sample.
-
4.
Let \(n_{1M}^{CV}\) and \(n_{2M}^{CV}\) be the number of left out observations misclassified in group 1 and 2 respectively and it’s given by
$$CV = \frac{{n_{1M}^{CV} + n_{2M}^{CV} }}{{n_{1} + n_{2} }}$$(6)
(Johnson and Wichern 2007).
Factor analysis (FA) as a variable selection criterion
The major aim of factor analysis is the orderly simplification of a large number of intercorrelated measures to a few representative constructs or factors. The primary function of factor analysis is to identify these clusters of high inter-correlations as independent factors. The main steps involved in factor analysis are; computation of the correlation matrix, extraction of initial factors, determining the number of factor’s to be extracted and rotation methods.
Orthogonal factor model
The aim of factor analysis is to explain the outcome of p variables in the data matrix X using fewer variables (i.e. the so-called factors). Ideally all the information in X can be reproduced by a smaller number of factors. These factors are interpreted as latent (unobserved) common characteristics of the observed \(x \in \Re^{p}\). The case just described occurs when every observed \(x = (x_{1} , \ldots ,x^{p} )^{'}\) can be written as
where \(f_{l} ,l = 1, \ldots ,k\), denotes the factors, \(q_{jl}\) is the loading of the jth variable on the lth factor, \(\mu_{j}\) is the mean of the variable j. It is therefore expected that, the number of factors k should always be much smaller than p (Hardel and Simar 2007).
Results
This part of the study presents the results of the study as well as extensive discussion.
Preliminary findings
The various traits/characteristics of the various sheep breeds considered were their Height (Ht), Length (Lt), Ear Length (EL), Weight (Wt), Chest Size (Chst), Hook Length (HL), Tail Length (TL) and Difference between Hook length and Tail length (HL-TL). Preliminary findings based on their computed means and their respective standard deviations shows some differences in the measured traits across the three breeds (see Table 1). Test of significance was conducted to test statistically whether there are differences among the group means of the measured traits for the various breeds of sheep. F-test conducted indicated significant differences between the mean measured traits for the three sheep breeds.
First the equality of the three covariance matrices were tested with Box M test of equality of covariance matrices of the three sheep breeds under study. The log determinants of the three covariance matrices for two groups were found from the table as almost equal with the other one slightly apart from the other two (see Table 2). The hypothesis for testing the equality of covariance matrices was stated as:
\(H_{0} :\sum_{1} = \Sigma_{2} = \Sigma_{3}\) Vrs \(H_{1} :\) At least one pair of Sigma’s ( \(\Sigma\) ) is different.
From Box M table, we observed a p value of 0.141 and since the observed p value is greater than the significance (\(\alpha\)) level of 5 %, we fail to reject the null hypothesis of no difference and conclude that, all the three covariance matrices are equal. Based on these results, all discriminant/classification functions will assume a linear approach.
Canonical linear discriminant function (FLDF) for classification
Canonical linear discriminant function (FLDF) was employed using all the eight variate data set after testing for equality of the covariance matrices among the three sheep breeds. The Box M test above as shown in Table 2 was insignificant and hence a linear function was appropriate for classification. An eight variable canonical discriminant functions were derived based on the fact that, the major assumption of discriminant analysis was not violated (equal covariance matrices across the three groups).
First and foremost, in order to determine whether the functions to be derived are significant or not, there is the need for the researcher to know the number of functions needed for the separation purposes. Hence the number of functions equals the number of groups/sheep breeds minus one. In this case, we have three groups (WAD, WALL and hybrid/crosses), thus we have 3 − 1 = 2 possible functions needed for separation purposes. This is evident in Tables 3 and 4 where the first function (function 1) explaining 93.1 % of the variance and has a small lambda (0.166) and it’s significant with p value of 0.000. The second function explains only 6.9 % of the variance in the data, with a recorded p value of 0.066. Therefore, the second function does not contribute much significantly in the discrimination process as compared to that of the first function. In other words, this factor does not help much in discriminating the groups.
In conducting discriminant analysis, the entire data was standardised due to different measurement scales used for the various breed traits to assume a unit variance or dispersion, under the standard normal distribution. The two derived canonical discriminant functions are
After computing the discriminant scores using the above two equations, the following proportion of correct classification and misclassifications were recorded and are presented in Table 5. Observations were classified into their desired group under unequal group prior probabilities.
From Table 5, 65.2 % of the original observations from the Djallonke/WAD sheep group were correctly classified, with the remaining 34.8 % being misclassified into the sheep crosses group. Also 88.9 % of the Sahel/WALL sheep breeds were correctly classified into their respective group, only one (1) representing 11.1 % being misclassified into the crosses sheep breed. The functions derived were able to separate the cross sheep breed form the other breeds with 82.8 % correct classification of the cross breed into their desired group with the remaining 17.2 % being misclassified into the Djallonke/WAD sheep breed. In all, approximately 77.0 % correct classification of the sheep breeds using the linear discriminant functions with eight variables/traits was achieved. Also the correct classification rate for the cross validated results was 75.4 %.
A six variable discriminant function using quadratic discriminant function (QDF)
Factor analysis was employed as a variable selection criterion for selecting the major variables/traits for the provision of maximum separation among the three known sheep breeds. All the four main steps in factor analysis were followed and out of the eight morphological traits, six traits including Length (Lt), Ear length (EL), Weight (Wt), Chest (Wt), Hook Length (HL), Hook Length and Tail Length (HL-TL) were extracted after VARIMAX rotation method as shown in Table 6.
In checking the equality of the covariance matrices for the three groups using the new data (six variate data), Box M test was employed and the three covariance matrices of the sheep breeds were found to be unequal or at least one of the covariance matrices is not equal to the other. Hence, since the covariance matrices are not equal, the appropriate discriminant function to be derived for classification of the sheep breeds using the six variate data is the Quadratic Discriminant Function (QDF).
In this case, two discriminant functions were derived to classify the sheep breeds into their respective groups under unequal prior probability and equal misclassification cost. The two functions derived are as follows;
Based on the above quadratic discriminant functions, the various probabilities of correct classifications and misclassifications were obtained and are presented in Table 7.
From Table 7, three (3) Djallonke sheep breeds were misclassified into the cross sheep breeds, six (6) observations were also misclassified from the cross breed to Djallonke sheep breed. In all nine (9) sheep breeds were misclassified from either Djallonke or crosses sheep breed. None of the Sahel/WAD sheep breeds were misclassified into either Djallonke or crosses breed. In summary, out of the total sixty-one (61) sheep breeds, 52 of them were correctly classified into their respective sheep breed representing approximately 85 % with only nine being misclassified. The summaries of classification and misclassification rates are presented in the confusion matrix table as shown in Table 8.
From Table 8, 82.61 % of correct classifications of Djallonke/WAD sheep breeds were recorded, with a misclassification rate of 0.1739 into the crosses sheep breed. Also none of the Sahel/WALL sheep breeds were misclassified and a 100 % correct classification was achieved. For the crosses breed, results from Table 8 shows 75.86 correct classification with only 24.14 % of them being misclassified into the Djallonke/WAD sheep breed. The table also summarises the results of cross validated results. In all, approximately 82.0 % correct classification of sheep breed was achieved under classification with QDF as well as 86.9 % correct classification rate under the cross validated results. This study therefore conforms with the research based study by Traore’ et al. (2008), Aziz and Al-Hur (2013), Yakubu et al. (2010b), Ebegbulem et al. (2011) and Agavierzor et al. (2012) where all these researchers applied discriminant analysis in separating the known breeds of animals using significant morphological traits as the main variables for maximizing separation.
Conclusion
The study was aimed at establishing a separator/discriminating function for separating the three known sheep breeds (hybrid/crosses, WAD and WALL sheep breeds). The derived discriminant functions provided maximum (canonical linear discriminant function) separation among the three known breeds with an overall classification rate of 78.9 %. However, factor analysis extracted six (6) traits out of the eight variables and the derived discriminant functions with the six variables provided better separation than the eight variate discriminant equation (Canonical discriminant function). Quadratic discriminant functions were derived from the six variate data and 86.2 % correct classification of sheep breeds were achieved. The study can therefore conclude that sheep breeds can be clearly separated based on the physical traits with minimum rate of misclassification without concentrating on only their genotypic features.
References
Agaviezor B, Peters SO, Adefenwa MA, Yakubu A, Adebambo OA, Ozoje MO, Ikeobi CO, Wheto M, Ajayi OO, Amusan SA, Oludotun Ekundayo, Sanni TM, Okpeku M, Onasanya GO, Donato MD, Ilori BM, Kizilkaya K, Imumorin IG (2012) Morphological and microsatellite DNA diversity of Nigerian indigenous sheep. J Anim Sci Biotechnol 3(38):2–16
Aziz MMA, Al-Hur FS (2013) Differentiation between three Saudi goat types using size-free canonical discriminant analysis. Emir J Food Agric 25(9):723–735. doi:10.9755/ejfa.v25i9.15827
Desu MM, Geisser S (1973) Methods and applications of equal-mean discrimination. In: Cacoullos T (ed) Discriminant analysis and applications. Academic Press, New York, pp 139–161
Ebegbulem VN, Ibe SN, Asuquo BO (2011) Morphometric differentiation of West African dwarf goats in Southeastern Nigeria using discriminant analysis. J Agric Vet Sci 3:29–34
Fisher RA (1936) The use of multiple measurements in taxonomic problems. Annal Eugen 7:179–188
FAO (2000) World watch list for domestic animal diversity, 3rd edn (edited by Scherf BD), Rome, p 726
Food and Agriculture Organization (FAO) (2007) State of the art in the management of animal genetic resources: method for characterization. In: Rischkowsky B, Pilling D (eds) The state of the world’s animal genetic resources for food and agriculture. Commission on Genetic Resources for Food and Agriculture, Rome, Italy. http://ftp.fao.org/docrep/fao/010/a1260e/a1260e07.pdf. Retrieved 27 Mar 2011
Hardel WK, Simar L (2007) Applied multivariate statistical analysis, 2nd edn. Springer, Heidelberg
Herrera M, Rodero E, Gutierrez MJ, Pea F, Rodero JM (1996) Application of multifactorial discriminant analysis in the morphostructural differentiation of Andalusian caprine breeds. Small Rumin Res 22:39–47
Johnson RA, Wichern DW (2007) Applied multivariate statistical analysis. Pearson Education Inc, Upper Saddle River, pp 575–621
Koney EBM (2004) Livestock production and health. Advent Press, Accra
Krzanowski WJ, Hand DJ (1997) Assessing error rate estimators: the leave-one-out reconsidered. Aust J Stat 39(1):35–46
Lachenbruch PA (1975) Zero-mean difference discrimination and the absolute linear discriminant function. Biometrika 62(2):397–401
Oppong-Anane K (2006) Country Pasture/Forage Resources Pro_le. In: Suttie JM, Reynolds SG (eds) Ministry of food and agriculture (MoFA), animal production directorate, Ministry of Food and Agriculture (MoFA), Accra, Ghana. Ministry of Food and Agriculture (MoFA)
Rege JE (1992) Animal genetic resources their characterization, conservation and utilization. Research planning workshop, pp 55–59
Traore A, Tambouraa HH, Kaborea Royob LJ, Fernandezb I, Alvarezb I, Sangarec M, Boucheld D, Poiveye JP, Francoisf D, Toguyenic A, Sawadogog L, Goyache F (2008) Multivariate characterization of morphological traits in burkina faso sheep. Small Rumin Res 80:62–67
Yakubu A, Salako AE, Imumorin IG, Ige AO, Akinyemi MO (2010a) Discriminant analysis of morphometricdi_erentiation in the West African dwarf and red sokoto goats. S Afr J Anim Sci 40(4):381–387
Yakubu A, Idahor KO, Haruna HS, Wheto M, Amusan S (2010b) Multivariate analysis of phenotypic differentiation in bunaji and sokoto gudali cattle. Acta Argic Slov 96(2):76–80. doi:10.2478/v10014-010-0018-9
Yunusa AJ, Salako AE, Oladejo OA (2013) Morphometric characterization of Nigerian indigenous sheep using multifactorial discriminant analysis. Int J Biodivers Conserv 5(10):661–665
Authors’ contributions
MAB carried out the data analyses including the application of discriminant analysis as well as the Interpretation/discussion of the results and drafted the manuscript. EKS worked on the introductory part of the study including review of literature in the related study. And also explained most of the terms in breeds of sheep. Both authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Asamoah-Boaheng, M., Sam, E.K. Morphological characterization of breeds of sheep: a discriminant analysis approach. SpringerPlus 5, 69 (2016). https://doi.org/10.1186/s40064-016-1669-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40064-016-1669-8