
Abstract
Background
Diabetes is a highly prevalent chronic disease that places a large burden on individuals and health care systems. Models predicting the risk (also called predictive models) of other conditions often compare people with and without diabetes, which is of little to no relevance for people already living with diabetes (called patients). This review aims to identify and synthesize findings from existing predictive models of physical and mental health diabetes-related conditions.
Methods
We will use the scoping review frameworks developed by the Joanna Briggs Institute and Levac and colleagues. We will perform a comprehensive search for studies from Ovid MEDLINE and Embase databases. Studies involving patients with prediabetes and all types of diabetes will be considered, regardless of age and gender. We will limit the search to studies published between 2000 and 2018. There will be no restriction of studies based on country or publication language. Abstracts, full-text screening, and data extraction will be done independently by two individuals. Data abstraction will be conducted using a standard methodology. We will undertake a narrative synthesis of findings while considering the quality of the selected models according to validated and well-recognized tools and reporting standards.
Discussion
Predictive models are increasingly being recommended for risk assessment in treatment decision-making and clinical guidelines. This scoping review will provide an overview of existing predictive models of diabetes complications and how to apply them. By presenting people at higher risk of specific complications, this overview may help to enhance shared decision-making and preventive strategies concerning diabetes complications. Our anticipated limitation is potentially missing models because we will not search grey literature.
Similar content being viewed by others


Background
The World Health Organization identifies diabetes as one of the four priority non-communicable conditions [1]. In 2017, more than 693 million people were affected by diabetes worldwide and projections point to a sustained rise in its prevalence in the next decades [1]. The burden of diabetes on individuals and health care systems is primarily attributed to complications from diabetes including macrovascular complications (e.g., heart attack, stroke) or microvascular complications (e.g., blindness, amputation, renal failure) [1, 2]. Early identification of people with diabetes at increased risk of complications is an important challenge for clinicians [3]. Models predicting the risk (also called predictive models) of diabetes complications can facilitate the identification of people at higher risk and inform health decision-making regarding preventive actions or treatments to avoid or delay complications [4].
Models that assess the risk of developing diabetes or that use it as a predictor variable for other outcomes are not informative for someone who is already living with diabetes (i.e., patient) [5, 6]. Similarly, predictive models of other conditions in people with diabetes often compare people with and without diabetes, which is of little to no relevance for patients [7,8,9]. A preliminary search for reviews on the topic was conducted in two databases (MEDLINE, Embase), and results suggest that existing reviews of predictive models of diabetes-related complications focus mostly on macrovascular complications [10, 11] and rarely on the range of other diabetes complications [4, 12]. This scoping review will contribute to filling these gaps.
We aim to identify and synthesize existing predictive models of physical and mental health conditions associated with diabetes, in people with prediabetes and any type of diabetes mellitus (hereafter called “patients”). Our objective is to describe the features of selected validated predictive models for risk of diabetes complications.
Methods/design
In this scoping review, we will use well-established scoping review methods, namely the framework developed by the Joanna Briggs Institute [13, 14] and Levac and colleagues [15] while paying attention to the methodological limitations of original studies as often recommended in systematic reviews [16]. In some epidemiological contexts, such as the one we are focusing on, it is important to assess studies’ qualities even if it does not add to the methodological strength of the scoping review itself. For example, in an ongoing scoping review, authors aimed to assess the number of validated prediction rules that exist for spinal cord injury management and to provide evidence of the psychometric properties of these prediction rules, especially with regard to its clinical impact [17]. Although their scoping approach does not aim to assess the overall effectiveness of these prediction rules in their respective settings, their systematic appraisal of data quality will help readers make informed use of their findings. In another ongoing study, authors aimed to “produce a scoping review which in its data analysis will draw on methods typically associated with qualitative systematic reviews” and acknowledged that the diversity of data “presents a potential challenge from the perspective of interrater reliability and consistency in analysis” [18].
To include a diversity of perspectives and ensure that our review focuses on diabetes complications that are relevant to patients [19], our research team include researchers (RN, IF, GN, HW) and stakeholders such as clinicians (CF, BS, CY, NI, SS) and patients with type 1 and type 2 diabetes (DG, DA, HW). Stakeholders were involved in this study as collaborators and co-authors, not participants. Patients in our research team (hereafter called Expert Patients) were recruited through Diabetes Action Canada (DAC), a national Patient-Oriented Research Network that includes patients to bring expertise in diabetes care [20]. Expert Patients were recruited to DAC through professional and personal networks and community-based organizations and from respondents to a national survey [21]. Using a patient-centered approach, the team co-developed the protocol. We integrated patient’ priorities by developing our research questions, search strategy terms, and outcome measures based on what Expert Patients shared concerning what matters to them, and also by building on findings of a recent patient-centered study [21]. Expert Patients (DG, SD) will be involved in each step of the research process, including the definition of the objective, the main analysis, the preliminary and final results, and the discussion. We will discuss preliminary and final results with a broader committee of six to ten Expert Patients. We will use the services of two information specialists to validate our search strategy and selection criteria at least twice before the end of this review.
Eligibility criteria
Population
The population targeted by this scoping review consists of people of all ages, genders, and ethnicities affected by diabetes. We will consider prediabetes and any type of diabetes, including type 1, and type 2 diabetes [22], and data that have been collected at the individual level, not the group level [23]. We will consider both treated and non-treated individuals. Studies mixing people with and without diabetes will not be considered, unless they performed separate stratified analyses for individuals with diabetes and without diabetes. Studies of pregnant women and/or gestational diabetes will be excluded because it is a different clinical condition. Studies that are restricted to people who do not have diabetes will not be considered. Models based on the Framingham Risk Score of cardiovascular conditions will not be considered as this score was originally derived from a general population free of diabetes [24]. Studies involving people not meeting our eligibility criteria will be excluded.
Concept
We will consider both clinically diagnosed and self-reported physical and mental conditions experienced by patients as a consequence of living with diabetes. Studies focusing on social or economic consequences of diabetes will not be included in this review, because findings are likely to be highly dependent on country of residence and health insurance status and thus are unlikely to be modifiable at the individual level. We plan to sort models by diabetes type and by groups (e.g., sub-group) of diabetes complications, physical (e.g., macrovascular and microvascular conditions), and mental (e.g., depression and anxiety) health problems. Death from all causes and death from non-diabetes complications will be analyzed separately. With the collaboration of Expert Patients and researchers, we drafted a preliminary and non-exhaustive list of diabetes complications that were relevant for patients (Table 1).
Context
(1) We will consider evidence coming from all countries and settings and published between 2000 and 2018. We will not consider articles prior to 2000 because both diabetes treatment and modeling approaches have greatly improved in the last two decades. The date of publication will not be included in the search strategy. Rather, we will simply order the results by date of publication and will not consider those outside the period 2000–2018. (2) We will include only full-text peer-reviewed published studies with original results as they are expected to exhibit high-quality models and detailed methodology. For this reason, we will not consider abstracts only or duplicates and do not intend to search the grey literature. (3) No language restrictions will be applied. During the full-text screening, potentially relevant articles written in a language other than English or French will be translated by a member of our team when possible. If we do not have anyone with expertise in that language, we will first use free translation tools (e.g., Google Translate, DeepL) to determine if the publication is likely to meet our inclusion criteria, and if so, we will engage professional translation services. (4) We will only consider studies with a longitudinal design and quantitative data. Specifically, we will consider prospective cohort studies and nested case-control studies [25]. We will not apply restrictions as to the length of follow-up as the time may vary for diverse reasons. Screening tools/studies, retrospective case-control studies, and cross-sectional studies will not be considered. Focusing on predictive models implies that we will not consider explicative ones, that is, those evaluating factors associated with diabetes complications as potential determinants or confounders rather than predictors. We will consider diverse candidate/potential predictors of diabetes complications, including personal characteristics, socioeconomic factors, clinical factors, and environmental factors. (5) We will focus only on prognostic models and not include diagnostic models in this review. We will consider both development and validation studies, as some studies presenting predictive models are focused on derivation and internal validation and others on external validation. The sample size for model validation can come from the same study population, from another study population, or from both. We will exclude partial and full predictive models that were not validated, either internally or externally.
Search strategy and information source
Our diverse team co-built the search strategy of this scoping review. A predefined list of potential predictors and complications [4] was established in collaboration with six Expert Patients who were not members of our research team in order to better capture what matters to diverse patients. This list will be used as a starting point for study selection and will be revised during the full-text screening process (Table 2). The search strategy will combine groups of keywords customized to each database (i.e., MeSH terms where appropriate) pertaining to (1) population (treated and untreated patients affected by prediabetes and diabetes), (2) concept (diabetes complications, potential predictors), and (3) context (prediction modeling features). Prediction models seldom report the individual predictors included in the final model as the central message is about accuracy (discrimination and calibration). However, knowing which, how, and what candidate predictors have been assessed can help explore potential bias (e.g., selection bias) in data that may, in turn, influence the features of predictive models [26, 27]. For this reason, we will add potential predictors in our search strategy. Search terms are selected to capture international terminology. We intend to run a search at the start and again just before final data extraction to identify studies published after our baseline search date and before we write the article for possible inclusion in our review. As mentioned in eligibility criteria, there will be no restrictions in terms of date, language, age, or design.
We will search for eligible studies in two electronic scientific databases: Ovid MEDLINE and Embase. In addition, we will perform snowballing of reference lists of selected papers at the full-text screening stage [28]. To complement these sources, we will contact experts in the field to ask if they know about any published work we may have missed. We tested our search strategy for MEDLINE (Ovid) in June 2018 and for Embase in October 2018 (see Appendixes 1, 2, and 3). We had the search appraised by a second librarian using PRESS in October 2018 [29].
Data management
The detailed references and abstracts identified will be pooled in EndNote, a reference management software [30]. We will use EndNote to remove duplicates and store references before moving to another tool to screen references and extract data. Duplicates will be removed using the automatic function in EndNote and manually during screening. Screening by title, abstract, and full text will be conducted using Microsoft Excel [31] to provide a comprehensive step-by-step record of the selection process based on our selection criteria. A detailed screening form with the inclusion and exclusion criteria will be developed and tested (see Appendixes 1 and 2, Tables 4 and 5). All members of the screening team will be trained on how to use Microsoft Excel and the screening form before we start.
Selection process
Articles will be excluded if at least one of the criteria was clearly not met. We will retain any article that cannot be excluded solely based on abstract review. We will set aside all articles that are systematic or narrative literature reviews whose subject clearly relates to our objective to consult at a later stage, as mentioned previously.
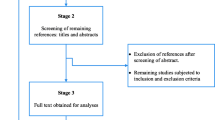
Given that reviewers have diverse research backgrounds and levels of experience, we plan to screen titles and abstracts in two different steps to make sure that they have a similar understanding of the eligibility criteria. A preliminary convenience sample of 50 titles will be screened by all reviewers, and we will assess the degree of agreement among raters, discuss any disagreement in groups, and only proceed above a predetermined threshold of interrater agreement (such as 70%). Then, pairs of reviewers from among the seven team members (CF, IF, JC, SC, SRB, JM, YY) will independently screen a subset of titles based on the Population-Concept-Context (PCC) criteria. After titles are screened independently by two reviewers, the results will be pooled and agreement will be calculated for each pair. If agreement is optimal, all titles retained by at least one reviewer will be considered for abstract screening. If agreement is not optimal, title screening will be repeated by independent reviewers until we meet the target of 0.7 or higher. Reviewers will meet at the beginning, midpoint, and final stages of the abstract review process to discuss discrepancies related to study selection and refine the search strategy if needed [15]. Once abstract screening has been completed by two independent reviewers, the results will be pooled and agreement will be calculated for each pair of reviewers. When agreement is optimal, all remaining disagreements will be discussed between the two reviewers. If agreement is not optimal, two independent reviewers will screen abstracts until we meet the target agreement of 0.7 or higher. A third reviewer will screen abstracts where there are discrepancies and discuss all remaining disagreements in meetings with the two initial reviewers. Full-text copies of articles selected based on abstracts will be retrieved and translated if needed. Two independent reviewers from our team (RN, CRB, TP) will screen the full text of all selected references. Each pair of reviewers will compare their results and discuss any disagreement. If there are too many disagreements, a third reviewer will repeat the full-text screening. Differences and disagreements between reviewers will be discussed in group meetings to reach a consensus. All remaining discrepancies will be resolved by one researcher (GN, HW).
Data collection process
The team will collectively build a standardized extraction grid with all relevant data items to guide data extraction. Three independent reviewers (RN, TP, CRB) will pilot test the grid using a subset of five to twenty full-text articles selected for extraction. They will then meet to determine whether data are missing from the form or not needed. Data extraction will be performed in duplicate by two independent reviewers from our team (RN, TP, CRB). The corresponding authors of retained articles may be contacted to request any information missing in the extraction grid. The three reviewers will resolve discrepancies through discussion and with input from two members of our team (RN, HW) when necessary.
Data extraction
Since there are no checklists of items to consider in data extraction for scoping reviews on risk prediction models, we considered aspects of a well-known checklist for systematic reviews [32] that aligns with the scoping review methodology to design (and, in future, report) our data extraction process [15]. Full-text data extraction will be done by two independent reviewers (TP, CRB) using an Excel spreadsheet. A third reviewer (RN, GN) will review any studies where there is a discrepancy between the two independent reviewers that they are not able to resolve. Although scoping reviews do not usually include quality assessment, when dealing with epidemiological models, it is important to pay attention to the methodology and the design of original studies [17]. Two independent reviewers trained in epidemiology (RN, IF, GN) will be involved in assessing potential selection and information bias in selected studies and will discuss the potential impact of bias on the features and accuracy of selected models. Final selection of articles will be undertaken in duplicate following data extraction to confirm relevance of the chosen articles. Any study selected by only one reviewer will be discussed to reach mutual agreement. We will record the reasons for which each article is excluded. Here again, a third reviewer will review each study when there are discrepancies that cannot be resolved by the two independent reviewers.
We will use the pre-publication version of the PROBAST [33], which includes a template and a detailed user guide to identify five domains in which methodological limitations might exist in studies using risk prediction models. These domains are as follows: (1) participant selection (e.g., selection bias caused by exclusion of eligible participants or loss at follow-up); (2) predictors (e.g., differential or non-differential misclassification of predictors, change in predictor for some participants over time); (3) outcomes (e.g., outcome definition and standardized classification of all participants); (4) sample size and participation flow (e.g., inappropriate time interval between predictor and outcome measurements, handling of missing data); and (5) analyses (e.g., evaluation of performance measures such as calibration, discrimination, (re)classification, and net benefit [34,35,36]; handling of non-binary predictors) (Table 3). Other methodological issues will also be considered (e.g., duration and timing of exposure, selective reporting of results in a way that depends on the findings) [37]. Also, if both predictors and outcomes were measured using self-report methods, we will evaluate potential common method bias [25].We will use the same spreadsheet for data abstraction and for quality assessment. We will make sure that we adequately capture all relevant content and methods from selected papers and summarize information on the internal and external validity of each selected model from each selected study. Consistent with the PROBAST tool, we will sort studies in three groups: high quality, moderate/acceptable quality, and low quality. These data will help assess data quality during data analysis and interpretation.
Analysis and synthesis
This protocol adheres to the Preferred Reporting Items in Systematic Reviews and Meta-analyses extension for protocols (PRISMA-P) [38] and scoping reviews (PRISMA-ScR) [39] (see the Additional file 1). After data from included studies are summarized in an extraction table, we will follow three distinct steps: analysis (models features, discrimination, calibration and validation), reporting (synthesizing characteristics of included studies), and discussion (comparison with previous reviews) [15, 40]. The analysis and synthesis will focus on diabetes complications and the methodological features of selected models [11]. We will use qualitative approaches to evaluate and synthesize quantitative estimates accurately. When relevant, we will provide in-depth analyses of potential explanations for data inconsistencies (i.e., study design, selection/participation, data measurements, etc.). Finally, we will propose how to consistently report the risk of diabetes complications in predictive models in ways that will be helpful for patients and clinicians.
Discussion and conclusion
The current review may not provide meta-analytical estimates because we expect to retrieve a highly diverse set of risk prediction models. This may preclude a quantitative synthesis if the available data do not meet the criteria for homogeneity in methods used to measure predictors and outcomes and assess biases potentially affecting internal validity. Heterogeneity is one of the main reasons for skepticism about meta-analyses of non-experimental studies [25, 41], which represent the great majority of studies on our topic [4, 6]. To partly circumvent the pitfalls of heterogeneity, we will attempt to calculate a meta-analytical estimate of experimental studies if there are enough high-quality data with comparable methodological characteristics in our final set of models (N > 5). However, preliminary search results and consultation with experts revealed that predictive models of diabetes complications often consider some complications as predictors of other complications [4]. Merging such models during analysis may lead to a highly correlated data and inflation in the estimates of variance [42, 43]. In such cases, qualitative approaches are often alternatives used to evaluate and synthesize estimates accurately.
Strengths and limitations of this study
The major strengths of this review will be the inclusion of predictive models of diverse diabetes complications and the combination of multiple and diverse perspectives of patients, clinicians, and researchers. Considering the fact that diabetes complications often vary by diabetes types, we invited one patient partner with type 2 diabetes (DG) and one patient partner with type 1 diabetes (SD) as co-authors to complement the perspective of our senior researcher (HW) who lives with type 1 diabetes. All six Expert Partners that we consulted agreed that all complications considered in this review were equally important. We plan to actively collaborate with a committee of Expert Patients, caregivers, and clinicians in diabetes care. By including a consultation exercise in this scoping review, we intend to “enhance the results, making them more useful to policy makers, practitioners and service users” [44]. Limitations include using two databases, restricting publication date to 2000–2018, and not searching the grey literature. Also, we will not consider the social and economic outcomes of diabetes.
Dissemination
Ethical approval is not required for this scoping review study since we will only be using secondary data sources. Our findings will be disseminated through peer-reviewed publication and presentation at conferences. Because predictive models are increasingly being appraised and recommended for formal risk assessment in treatment decision-making and clinical guidelines, the proposed scoping review may contribute to support research and risk communication in diabetes care. For example, it may help clinicians better identify people who are at higher risk of diabetes complications and researchers design customizable risk prediction tools for use in diabetes care [45]. To ensure that our findings about diabetes complications reach patients, we will also circulate them through clinical and patient networks.
Availability of data and materials
Data are available by requesting to the corresponding author.
Abbreviations
- PRISMA-P:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for protocols
- PRISMA-ScR:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews
- PROBAST:
-
Prediction study Risk of Bias Assessment Tool
References
World Health Organization. Global report on diabetes. 2016.
International Diabetes Federation. IDF Diabetes Atlas. 8th ed; 2017.
Nickerson HD, Dutta S. Diabetic complications: current challenges and opportunities. J Cardiovasc Transl Res. 2012;5:375–9.
Lagani V, Koumakis L, Chiarugi F, Lakasing E, Tsamardinos I. A systematic review of predictive risk models for diabetes complications based on large scale clinical studies. J Diabetes Complications. 2013;27:407–13.
Kahn R. Risk prediction models in diabetes prevention. Lancet Diabetes Endocrinol. 2014;2(1):2–3.
Abbasi A, Peelen LM, Corpeleijn E, van der Schouw YT, Stolk RP, Spijkerman AMW, et al. Prediction models for risk of developing type 2 diabetes: systematic literature search and independent external validation study. BMJ. 2012;345:e5900.
Lee ET, Howard BV, Wang W, Welty TK, Galloway JM, Best LG, et al. Prediction of coronary heart disease in a population with high prevalence of diabetes and albuminuria: the Strong Heart Study. Circulation. 2006;113:2897–905.
Siervo M, Bunn D, Prado CM, Hooper L. Accuracy of prediction equations for serum osmolarity in frail older people with and without diabetes. Am J Clin Nutr. 2014;100:867–76.
Huffman FG, Zarini GG, McNamara E, Nagarajan A. The Healthy Eating Index and the Alternate Healthy Eating Index as predictors of 10-year CHD risk in Cuban Americans with and without type 2 diabetes. Public Health Nutr. 2011;14:2006–14.
van Dieren S, Beulens JWJ, Kengne AP, Peelen LM, Rutten GEHM, Woodward M, et al. Prediction models for the risk of cardiovascular disease in patients with type 2 diabetes: a systematic review. Heart. 2012;98:360–9.
Harding JL, Pavkov ME, Magliano DJ, Shaw JE, Gregg EW. Global trends in diabetes complications: a review of current evidence. Diabetologia. 2019;62:3–16.
Rawshani A, Rawshani A, Franzén S, Sattar N, Eliasson B, Svensson A-M, et al. Risk factors, mortality, and cardiovascular outcomes in patients with type 2 diabetes. N Engl J Med. 2018;379:633–44.
Aromataris E, Munn Z, editors. Joanna Briggs Institute Reviewer's Manual. The Joanna Briggs Institute, 2017. Available from https://reviewersmanual.joannabriggs.org/.
Peters MDJ, Godfrey C, McInerney P, Munn Z, Tricco AC, Khalil, H. Chapter 11: Scoping Reviews (2020 version). In: Aromataris E, Munn Z, editors. Joanna Briggs Institute Reviewer's Manual, JBI, 2020. Available from https://reviewersmanual.joannabriggs.org/.
Levac D, Colquhoun H, O’Brien KK. Scoping studies: advancing the methodology. Implement Sci. 2010;5:69.
Peters MDJ, Godfrey CM, Khalil H, McInerney P, Parker D, Soares CB. Guidance for conducting systematic scoping reviews. Int J Evid Based Healthc. 2015;13:141–6.
Boggenpoel B, Madasa V, Jeftha T, Joseph C. Systematic scoping review protocol for clinical prediction rules (CPRs) in the management of patients with spinal cord injuries. BMJ Open. 2019;9:e025076.
Dewar B, Fedyk M, Jurkovic L, Chevrier S, Rodriguez R, Kitto SC, et al. Protocol for a systematic scoping review of reasons given to justify the performance of randomised controlled trials. BMJ Open. 2019;9:e027575.
Bergold J, Thomas S. Participatory research methods: a methodological approach in motion. Forum Qual Soc Res. 2012;13 [cited 2018 Feb 26]. Available from: http://www.qualitative-research.net/index.php/fqs/article/view/1801/3334.
Diabetes Action Canada - SPOR Network [Internet]. SPOR Network. [cited 2018 May 14]. Available from: https://diabetesaction.ca/.
Dogba MJ, Dipankui MT, Chipenda Dansokho S, Légaré F, Witteman HO. Diabetes-related complications: which research topics matter to diverse patients and caregivers? Health Expect [Internet]; 2017; Available from:. https://doi.org/10.1111/hex.12649.
Brannick B, Wynn A, Dagogo-Jack S. Prediabetes as a toxic environment for the initiation of microvascular and macrovascular complications. Exp Biol Med. 2016;241:1323–31.
Haneuse S, Bartell S. Designs for the combination of group- and individual-level data. Epidemiology. 2011;22:382–9.
Framingham Heart Study [Internet]. [cited 2019 Apr 3]. Available from: https://www.framinghamheartstudy.org/fhs-risk-functions/hard-coronary-heart-disease-10-year-risk/.
Rothman KJ, Greenland S, Lash TL. Others. Modern epidemiology. Philadelphia: Wolters Kluwer Health/Lippincott Williams & Wilkins; 2008. Available from: https://www.annemergmed.com/article/S0196-0644(08)01394-2/abstract.
Dastin J. Amazon scraps secret AI recruiting tool that showed bias against women. Reuters [Internet]. Reuters; 2018 Oct 10 [cited 2020 Mar 27]; Available from: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G.
Cahan EM, Hernandez-Boussard T, Thadaney-Israni S, Rubin DL. Putting the data before the algorithm in big data addressing personalized healthcare. NPJ Digit Med. 2019;2:78.
Wohlin C. Guidelines for snowballing in systematic literature studies and a replication in software engineering. In: Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering. EASE. 2014;38:1–10. https://doi.org/10.1145/2601248.2601268.
McGowan J, Sampson M, Salzwedel DM, Cogo E, Foerster V, Lefebvre C. PRESS peer review of electronic search strategies: 2015 guideline statement. J Clin Epidemiol. 2016;75:40–6.
EndNote | Clarivate Analytics [Internet]. EndNote. [cited 2018 Sep 17]. Available from: https://endnote.com/.
Excel 2016 - Microsoft Store Canada. Financial times [Internet]. [cited 2018 Sepe 17]; Available from: https://www.microsoft.com/en-ca/store/b/excel-2016.
Moons KGM, de Groot JAH, Bouwmeester W, Vergouwe Y, Mallett S, Altman DG, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLoS Med. 2014;11:e1001744.
PROBAST: a risk of bias tool for prediction modelling studies | The 23rd Cochrane Colloquium [Internet]. [cited 2018 Aug 22]. Available from: http://2015.colloquium.cochrane.org/abstracts/probast-risk-bias-tool-prediction-modelling-studies.
Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. 2010;21:128–38.
Holmberg L, Vickers A. Evaluation of prediction models for decision-making: beyond calibration and discrimination. PLoS Med. 2013;10(7):e1001491.
Altman DG, Royston P. What do we mean by validating a prognostic model? Stat Med. 2000;19:453–73.
Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Med Decis Making. 2006;26:565–74.
Shamseer L, Moher D, Clarke M, Ghersi D, Liberati A, Petticrew M, et al. Preferred reporting items for seystematic review and meta-analysis protocols (PRISMA-P) 20e15: elaboration and explanation. BMJ. 2015;349:g7647.
Tricco AC, Lillie E, Zarin W, O’Brien KK, Colquhoun H, Levac D, et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med. 2018; Available from:. https://doi.org/10.7326/M18-0850.
Colquhoun HL, Levac D, O’Brien KK, Straus S, Tricco AC, Perrier L, et al. Scoping reviews: time for clarity in definition, methods, and reporting. J Clin Epidemiol. 2014;67:1291–4.
Spitzer WO. Meta-meta-analysis: unanswered questions about aggregating data. J Clin Epidemiol. 1991;44(2):103–7.
Zidek JV, Wong H, Le ND, Burnett R. Causality, measurement error and multicollinearity in epidemiology. Environmetrics. 1996;7:441–51.
Yoo W, Mayberry R, Bae S, Singh K, Peter He Q, Lillard JW Jr. A study of effects of multicollinearity in the multivariable analysis. Int J Appl Sci Technol. 2014;4:9–19.
Arksey H, O’Malley L. Scoping studies: towards a methodological framework. Int J Soc Res Methodol. 2005;8:19–32.
Koumakis L, Chiarugi F, Lagani V, Kouroubali A, Tsamardinos I. Risk assessment models for diabetes complications: a survey of available online tools. International Conference on Wireless Mobile Communication and Healthcare; 2012. p. 46–53.
Acknowledgements
The authors gratefully acknowledge the contributions of Jimmy Chau, Sandrine Comeau, Jean Mardenli, Olivia Drescher, Thierry Provencher, Charlotte Rochefort-Brihay, and Yihong Yu to this project as research assistants; of information experts Frédéric Bergeron and William Witteman, for assistance with search strategy, screening, and selection of articles for the systematic review; and of patients partners Gloria Lourido, André Gaudreau, Jaime Borja, Pascual Delgado, and Patrice Bleau who contributed greatly to this research project as a whole but who were not able to accept the invitation to participate on this particular paper as co-authors due to time constraints. We thank all authors of the original articles who generously gave their time to validate the data we had extracted from their papers. Finally, we thank all study participants for helping us identify ways to improve diabetes care.
Funding
Funding for this study comes from two grants from the Canadian Institutes of Health Research (CIHR) FDN-148426 (Foundation grant, PI: Witteman) and SCA-145101 (SPOR chronic disease network grant funding Diabetes Action Canada, PI: Lewis). The CIHR had no role in determining the study design, the plans for data collection or analysis, the decision to publish, nor the preparation of this manuscript. HW is funded by a Research Scholar Junior 2 Career Development Award by the Fonds de Recherche du Québec—Santé. RN holds a postdoctoral fellowship from Diabetes Action Canada and a Fellowship in Medical Decision Making from the Gordon and Betty Moore Foundation and the Society for Medical Decision Making.
Author information
Authors and Affiliations
Contributions
HW originally conceptualized the study, which was then led by RN as principal investigator. RN, IF, and CF closely contributed to the design of the study. RN, IF, and CF drafted the first version of the article with early revision by HW and GN. CF, HW, DG, and SS brought expertise in the definition of the search strategy for predictors. CF, HW, and SS brought expertise in the definition of the search strategy for diabetes complications. RN, IF, GN, and BS brought expertise in predictive models. RN, GN, IN, SS, CY, and HW brought methodological expertise in study selection and risk bias assessment. HW, DG, and CY prepared the dissemination plan. RN and SS brought expertise in gender differences. RN, IF, CF, and GN collaborated to draft the grid for extraction data and do pilot screening. All the co-authors critically revised the article and approved the final version for submission for publication. RN and HW had full access to all the data in the study and had final responsibility for the decision to submit for publication.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
As this study will be based only on published studies, ethics approval is not required.
Consent for publication
The result will be published in a peer-review journal.
Competing interests
RN is funded by Diabetes Action Canada, a strategic patient-oriented research (SPOR) network in diabetes and its related complications, part of the Canadian Institutes of Health Research (CIHR) SPOR Program in Chronic Disease. Expert Patients were recruited through Diabetes Action Canada, and some co-authors also collaborate with Diabetes Action Canada.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
PRISMA-P 2015 checklist.
Appendices
Appendix 1
Appendix 2
Appendix 3
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Ndjaboue, R., Farhat, I., Ferlatte, CA. et al. Predictive models of diabetes complications: protocol for a scoping review. Syst Rev 9, 137 (2020). https://doi.org/10.1186/s13643-020-01391-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-020-01391-w