
Abstract
A new variable step-size strategy for the least mean square (LMS) algorithm is presented for distributed estimation in adaptive networks using the diffusion scheme. This approach utilizes the ratio of filtered and windowed versions of the squared instantaneous error for iteratively updating the step-size. The result is that the dependence of the update on the power of the error is reduced. The performance of the algorithm improves even though it is at the cost of added computational complexity. However, the increase in computational complexity can be minimized by careful manipulation of the update equation, resulting in an excellent performance-complexity trade-off. Complete theoretical analysis is presented for the proposed algorithm including stability, transient and steady-state analyses. Extensive experimental analysis is then done to show the performance of the proposed algorithm under various scenarios.
Similar content being viewed by others
1 Introduction
The past decade has seen a lot of research in the area of distributed estimation for wireless sensor networks [1–4]. The diffusion scheme using the least mean square (LMS) algorithm was first introduced by Lopes and Sayed in [2]. The first algorithm to propose a variable step-size for the diffusion LMS algorithm was proposed by Saeed et al. in [5] and extended by Saeed et al. in [6]. Since then, several variable step-size algorithms have been proposed [7–12].
While each algorithm improves in performance, the improvement comes at the cost of increased computational complexity. The variable step-size strategy proposed by Kwong and Johnston in [13] was extended to the distributed network scenario by Saeed et al. in [5, 6]. This work was further expanded by Saeed and Zerguine in [7] by using the distributed nature of the network to improve performance. A noise constraint was introduced by Saeed et al. in [8] for improved performance. An optimal step-size for the distributed scenario was derived by Ghazanfari-Rad and Labeau in [9], based on which they derived a variable step-size for each iteration. A variable step-size as well as combination weights were derived using an upper bound for the mean square deviation (MSD) by Jung et al. in [10]. Lee et al. derived an individual step-size for each sensor by minimizing the local MSD in [11]. Saeed et al. proposed a variable step-size strategy for distributed estimation in a compressible system in [12].
While all these algorithms provide excellent performance, they are all based on the l2-norm, except for the algorithm in [12]. This means that the power of the instantaneous error is the key factor for all these algorithms. This means that the performance of these algorithms suffers significantly in low signal-to-noise ratio (SNR) scenarios. Furthermore, there is significant increase in computational complexity as a trade-off for improved performance.
This work proposes a method where the step-size is varied using a quotient of the filtered error power. The algorithm is inspired from the work of Zhao et al. in [14]. The quotient form combined with the windowing effect reduces the effect of the power of the instantaneous error, making the algorithm more robust to low SNR scenarios. The quotient form of [14] is combined with the diffusion scheme in this work. A theoretical analysis of the algorithm has been presented. The energy conservation approach used for the analysis in this work was not used in [14]. Saeed presented a generalized analysis for variable step-size schemes using the energy conservation approach in [15]. This work was extended to the diffusion scheme by Saeed et al. in [16]. However, the variable step-size using the quotient form was not included in [16]. The analysis presented here utilizes the approach of [16] and gives stability, transient, and steady-state analyses for the proposed algorithm. Simulation comparisons with the variable step-size diffusion LMS (VSSDLMS) algorithm of [6] show that the proposed algorithm achieves significant improvement with a reasonably acceptable increase in computational complexity.
The rest of the paper is divided as follows. Section 2 presents the system model and defines the problem statement. Section 3 proposes the new algorithm. The theoretical analysis is given in Section 4, followed by simulation results in Section 5. Section 6 concludes this work.
2 System model
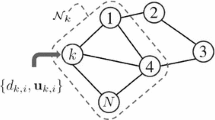
A geographical area of N sensor nodes, each connected to its closest neighbors as shown in Fig. 1, is being considered. The unknown parameters are modeled as a vector, wo, of size (M×1). The input to a node at any given time instant, i, is a (1×M) regressor vector, uk(i), where k∈N is the node index. The resulting observed output for the node is a noise corrupted scalar, dk(i), given by

An illustration of an adaptive network of N nodes
where vk(i) is the zero-mean additive noise.
The generic form of the Adapt-then-Combine (ATC) variable step-size diffusion LMS (VSDLMS) algorithm is given by [16]
where wk(i) is the estimate of the unknown vector at time instant i for node k, bfΨk(i) is the intermediate update for node k, ek(i)=dk(i)−uk(i)wk(i) is the instantaneous error, clk is the combination weight for the data transmitted from node l to node k, \(\mathcal {N}_{k}\) is the neighborhood of node k and (.)T is the transpose operator. The step-size is denoted by μk(i) and f{.} is the function that updates the step-size at every iteration.
The main objective of this work is to propose a new function, f{.}, for the VSDLMS algorithm defined by (2)–(4). The new function is derived in the next section, followed by theoretical analysis and experimental results.
3 Proposed algorithm
The proposed update equation for the step-size is given by
where α and γ are positive parameters such that 0<α<1 and γ>0 and a and b are forgetting factors for the decaying exponential windows in the numerator and denominator and are bounded as 0<a<b<1. Although (6) represents the complete window for both the numerator and denominator, a more suitable and iterative representation is given by
Combining (5) and (9) with (2) and (3) gives the proposed variable step-size diffusion LMS algorithm with a quotient form (VSQDLMS).
4 Theoretical analysis
Recently, the authors of [16] proposed a unified theoretical analysis for VSDLMS algorithms. Following the same procedure as [16], the following global variables are introduced to represent the entire network:
The combination weight matrix is given by {C}lk=clk. When expanded to the entire network, this becomes G=C⊗IM, where ⊗ represents the Kronecker product. The unknown parameters vector wo is expanded for the entire network using w(o)=Qwo, where Q=col{IM,IM,…,IM} is a (MN×M) sized matrix. The resulting global set of equations representing the VSQDLMS algorithm are given by
4.1 Mean analysis
Introducing the global weight-error vector as
Using (15), the update in (2) is rewritten as
where the relation in (15) is extended for Ψk(i). Expanding the error term, ek(i), and rearranging gives
Applying the expectation operator to (17) and using the independence assumption gives, after simplification
where \(\mathbf {R}_{\mathbf {u}_{k}} = {\mathsf {E}} \left [ \mathbf {u}_{k}^{T} (i) \mathbf {u}_{k} (i) \right ]\) is the autocorrelation of the input data at node k.
The algorithm will be stable in the mean sense if the term \(\left [ \mathbf {I}_{M} - {\mathsf {E}} \left [ \mu _{k} (i) \right ] \mathbf {R}_{\mathbf {u}_{k}} \right ]\) is bounded. This means that the algorithm will not diverge if this term is bounded. Thus, for the algorithm to be stable in the mean, the following condition needs to be satisfied:
where λmax(Ru,k) is the maximum eigenvalue of the auto-correlation matrix Ru,k.
4.2 Mean-square analysis
The mean-square analysis in [16] assumes Gaussian input data. The auto-correlation matrix is decomposed into its component eigenvector and eigenvalue matrices as RU=TΛTT, with Λ being the diagonal eigenvalue matrix and T being the eigenvector matrix, such that TTT=I. The eigenvector matrix T is then used to transform the remaining variables as follows:
where Σ and \(\phantom {\dot {i}\!}\boldsymbol {\Sigma }^{'}\) are weighting matrices. The final iterative update equation for the mean-square transient analysis is given by [16]
where
where ⊙ denotes the block Kronecker product, Rv=Λv⊙IM, Λv is a diagonal noise variance matrix for the network and \({\overline {\boldsymbol {\sigma }}} = \text {bvec} \left \{ \overline {\boldsymbol {\Sigma }} \right \}\). The matrix A is given in [2, 16] as A=diag{A1,A2,…,AN}, with each component matrix defined as
where Λk is the diagonal eigenvalue matrix and λk is the corresponding eigenvalue vector for node k.
In order to find the mean square deviation (MSD), the weighting matrix is chosen as \(\overline {\boldsymbol {\Sigma }} = \mathbf {I}_{N^{2} M^{2}}\). To get the excess mean square error (EMSE), the weighting matrix is chosen as \(\overline {\boldsymbol {\Sigma }} = \boldsymbol {\Lambda }\).
4.3 Steady-state analysis
At steady-state, (20) becomes
where
To get the steady-state MSD, we choose \({\overline {\boldsymbol {\sigma }}} = \text {bvec} \left \{ \mathbf {I}_{N^{2} M^{2}} \right \}\), and to get the steady-state EMSE, we choose \({\overline {\boldsymbol {\sigma }}} = \text {bvec} \left \{ \boldsymbol {\Lambda } \right \}\).
4.4 Steady-state step-size analysis
The step-size matrices, Dss=diag{μk,ssIM} and \(\mathbf {D}_{ss}^{2} = \text {diag} \left \{ \mu _{k,ss}^{2} \mathbf {I}_{M} \right \}\), are defined by the individual node values for the steady-state step-size. The step-size update for the proposed algorithm is defined by (5), (7)-(9). Taking the expectation gives
At steady-state, the EMSE value is assumed to go to 0, the expectation operator is removed and after simple manipulations, we get
where the term ss indicates steady-state value. Thus, the steady-state step-size value is given by (36) and the value for \(\mu _{k,ss}^{2}\) is simply the square of (36).
5 Results and discussion
This section presents experimental results for the proposed algorithm. The algorithm is tested in four different scenarios. First, the proposed algorithm is compared with the algorithm from [6] as well with the no cooperation case, in which each sensor applies the variable step-size quotient strategy for estimation without cooperating with any other sensor. The reason for the comparison with only the algorithm of [6] is that the computational complexity for both algorithms is similar. However, it is shown that with a small increase in computational complexity, the proposed algorithm performs much better. Next, the theoretical transient analysis of (20) is compared with simulation results. In the third experiment, the steady-state results from (26) are compared with steady-state simulation results. Finally, the performance of the proposed algorithm is tested in a scenario where the exact value of M is unknown.
5.1 Experiment I
In the first experiment, the proposed VSQDLMS algorithm is compared with the variable step-size diffusion LMS (VSSDLMS) algorithm from [6]. A comparison of computational complexity is given in Table 1. As can be seen, the increase in computations is small. The performance of the two algorithms is compared through simulations. The no cooperation case has been added to compare the performance of the proposed algorithm with the scenario where each sensor operates as if it were acting in a stand-alone environment. The size of wo is chosen as M=5. The size of the network is N = 20. The SNR value is varied from 0 dB to 20 dB. The parameters defining the step-size update equations are shown in Table 2. The values of the parameters are chosen such that the convergence speed is the same for all algorithms and the performance is measured on the basis of the steady-state MSD, as shown in the figures. Results are shown for white Gaussian input regressor data as well as colored input regressor data, with the correlation factor of 0.5. As can be seen from Figs. 2 and 3, the proposed algorithm clearly outperforms the VSSDLMS algorithm from [6]. At low SNR, the performance of the proposed algorithm at 0 dB is even better than the performance of the VSSDLMS algorithm at 10 dB. The steady-state results for these experiments are given in Table 3. As can be seen, the proposed algorithm gives an improvement in performance of almost 10 dB for the case of white input and 5 dB for the case of colored input. This significant improvement in performance clearly justifies the trade-off between complexity and performance.

Performance comparison for the proposed VSQDLMS vs VSSDLMS [6] algorithms for white input

Performance comparison for the proposed VSQDLMS vs VSSDLMS [6] algorithms for correlated input
5.2 Experiment II
In this experiment, the performance of the proposed algorithm is tested for different network sizes with a fixed unknown vector length, M=5. The performance of the proposed algorithm is then tested for a fixed network size, N=20, while the length of the unknown vector, M is varied. Finally, the performance of the algorithm is compared for Gaussian and Uniform input data. The results are shown in Figs. 4, 5, and 6. For varying N and M, the steady-state MSD results are plotted. As expected, performance improves as N increases as each sensor has more neighboring nodes for sharing data and improving its estimate. However, the performance degrades with increase in M as it becomes difficult to obtain an accurate estimate as the number of unknown parameters increases. The results shown use the same control parameters as in Experiment I.

Steady-state results for varying N with M = 5 and SNR 20 dB

Steady-state results for varying M with N = 20 and SNR 20 dB

Performance comparison for Gaussian and uniform input data
5.3 Experiment III
The next experiment compares the transient behavior of the proposed algorithm obtained from (20) with the simulation results. For this experiment, the network size is chosen as N = 5 and N = 10. The length of the unknown parameter vector is taken to be M = 2 and M = 5. The SNR is fixed at 20 dB. The step-size control parameters are set as α=a=0.99, γ=10−3 and b = 1−10−3. The results are shown in Figs. 7 and 8. As can be seen, the theoretical results closely match the simulation results. The mismatch during the transient stage is a result of the assumptions from [16]. However, this is expected, as shown in the results of [16], and is acceptable as the two curves are closely matched at steady-state.

Theory (20) vs simulation for a network of size N = 5

Theory (20) vs simulation for a network of size N=10
5.4 Experiment IV
Next, we compare the steady-state results obtained using (26) with the steady-state results obtained through simulations. The SNR values are varied from 0 dB to 30 dB. The network size is varied from N = 5 to N = 20. The results are shown in Figs. 9, 10, 11, and 12. There is a very close match for all results. For an exact comparison, some of these results have been tabulated in Tables 4 and 5. As can be seen, the results for the theory match closely with those obtained through simulation.

Steady-state theory (26) vs simulation for a network of size N=5

Steady-state theory (26) vs simulation for a network of size N = 10

Steady-state theory (26) vs simulation for a network of size N = 15

Steady-state theory (26) vs simulation for a network of size N = 20
5.5 Experiment V
In the last experiment, the robustness of the proposed algorithm is tested in the case that the exact number of unknown parameters are not known. This means that the exact value for M is unknown. In such a case, there are three possible scenarios. First, an underdetermined case, where the value of M is chosen as less than the actual value. Second, an overdetermined case, where the value of M is chosen as more than the actual value. Finally, the case where the value of M is chosen correctly. For this experiment, the network size is chosen as N = 10 and the unknown parameter vector length as M = 10. The range for M is varied between 5 and 15, and the steady-state results are compared for SNR values of 0 dB, 10 dB, and 20 dB. The results are shown in Fig. 13. It can be seen that for the underdetermined case, the value of SNR does not matter, as the algorithm converges very quickly to give a large error. The best result is achieved for an exact match, as expected. However, the results for the overdetermined case are very close to the best result. As the value of M increases, the value of the steady-state error also increases. However, it is clear from these results that in case of a mismatch, it is better to have an overdetermined system rather than an underdetermined system.

Steady-state results for a mismatch in the value of M for a network of size N = 10
6 Conclusion
This work proposes a new variable step-size diffusion least mean square algorithm, based on the quotient form, for distributed estimation in adaptive networks. The mean, mean-square, and steady-state analyses have presented. The proposed algorithm has been compared with the algorithm from [6], and a computational complexity analysis has been shown to justify this comparison. It has been shown that the proposed algorithm easily outperforms the algorithm from [6] and provides a much better trade-off between complexity and performance. Results show an improvement in steady-state MSD of almost 10 dB for white input data and almost 5 dB for correlated input. Results are also shown for different network sizes as well as for different sizes of the unknown vector. A comparison between theoretical and simulation results has been shown and the two were found to be closely matched, as shown by the figures as well as the tables. Finally, the performance of the algorithm has been tested in case of a mismatch in the value of M. The proposed algorithm has been shown to perform well in a Gaussian noise environment. However, for non Gaussian environments, a variable step-size algorithm based on the least mean fourth algorithm be developed.
References
A. H. Sayed, Adaptive Networks. Proc. IEEE. 102(4), 460–497 (2014).
C. G. Lopes, A. H. Sayed, Diffusion least-mean squares over adaptive networks: Formulation and performance analysis. IEEE Trans. Sig. Process.56(7), 3122–3136 (2008).
I. D. Schizas, G. Mateos, G. B. Giannakis, Distributed LMS for consensus-based in-network adaptive processing. IEEE Trans. Sig. Process.57(6), 2365–2382 (2009).
F. Cattivelli, A. H. Sayed, Diffusion LMS strategies for distributed estimation. IEEE Trans. Sig. Process.58(3), 1035–1048 (2010).
M. O. B. Saeed, A. Zerguine, S. A. Zummo, Variable step-size least mean square algorithms over adaptive networks, in Proc. Of 10th International Conference on Information Sciences Signal Processing and their Applications (ISSPA), 381–384 (2010).
M. O. B. Saeed, A. Zerguine, S. A. Zummo, A variable step-size strategy for distributed estimation over adaptive networks. EURASIP J. Adv. Sig. Process.2013:, 2013:135 (2013).
M. O. B. Saeed, A. Zerguine, A new variable step-size strategy for adaptive networks, in Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers, 312–315 (2011).
M. O. B. Saeed, A. Zerguine, S. A. Zummo, A noise-constrained algorithm for estimation over distributed networks. Intl. J. Adap. Cont. Sig. Process.27(10), 827–845 (2013).
S. Ghazanfari-Rad, F. Labeau, Optimal variable step-size diffusion LMS algorithms, in Proc. of IEEE Workshop on Statistical Signal Processing (SSP), 464–467 (2014).
S. M. Jung, J. -H. Sea, P. G. Park, A variable step-size diffusion normalized least-mean-square algorithm with a combination method based on mean-square deviation. Circ. Syst. Sig. Process.34(10), 3291–3304 (2015).
H. S. Lee, S. E. Kim, J. W. Lee, W. J. Song, A variable step-size diffusion LMS algorithm for distributed estimation. IEEE Trans. Sig. Process.63(7), 1808–1820 (2015).
M. O. B. Saeed, A. Zerguine, M. S. Sohail, S. Rehman, W. Ejaz, A. Anpalagan, A variable step-size strategy for distributed estimation of compressible systems in wireless sensor networks, in Proc. of IEEE CAMAD, 1–5 (2016).
R. H. Kwong, E. W. Johnston, A variable step-size LMS algorithm. IEEE Trans. Sig. Process.40(7), 1633–1642 (1992).
S. Zhao, Z. Man, S. Khoo, H. R. Wu, Variable step-size LMS algorithm with a quotient form. Sig. Process.89(1), 67–76 (2009).
M. O. B. Saeed, LMS-based variable step-size algorithms: a unified analysis approach. Arab. J. Sci. Eng.42(7), 2809–2816 (2017).
M. O. B. Saeed, W. Ejaz, S. Rehman, A. Zerguine, A. Anpalagan, H. Song, A unified analytical framework for distributed variable step size LMS algorithms in sensor networks. Telecom. Syst. (2018). https://doi.org/10.1007/s11235-018-0447-z.
Acknowledgments
The authors acknowledge the support provided by the Deanship of Scientific Research at KFUPM under Research Grant SB181016. Also, the authors would like to acknowledge the support provided by the National Plan for Science, Technology and Innovation (MAARIFAH)–King Abdulaziz City for Science and Technology through the Science & Technology Unit at King Fahd University of Petroleum & Minerals (KFUPM), the Kingdom of Saudi Arabia under award 12-ELE3006-04.
Author information
Authors and Affiliations
Contributions
The authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Azzedine Zerguine is a EURASIP member
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bin Saeed, M.O., Zerguine, A. A variable step-size diffusion LMS algorithm with a quotient form. EURASIP J. Adv. Signal Process. 2020, 12 (2020). https://doi.org/10.1186/s13634-020-00672-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-020-00672-9