
Abstract
A number of studies have estimated the income elasticity of health care expenditure to identify whether health care is a necessary or luxury product. However, the issue has received less attention in developing countries, especially in Asian economies. The current study for the first time has used the panel data covering 36 Asian countries for the period 1995–2013 for revealing the nature of health care as a product. Along with conventional econometric techniques we have addressed the issue of cross section dependence and used Westerlund (2007) panel cointegration test which is robust against cross section dependence and heterogeneity for detecting the presence of panel cointegration. By applying Fully Modified OLS (FMOLS) and Dynamic OLS (DOLS) it was found that the long run elasticity of Health Care Expenditure (HCE) with Gross Domestic Product (GDP) is less than unit implying that the health care can be regarded as necessary in nature for these countries.
Similar content being viewed by others

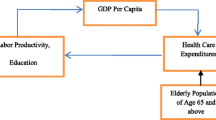
Background
Macro level health spending has significant beneficial effects on health outcomes [1–3]. Data from 47 African countries [4] and 133 low and middle income countries [1] showed that increased health spending led to reduced infant and under-5 child mortality rates. Hence, the share of health expenditure, the determinants of resources a country devotes to medical care, and the relationship between national income and national health care expenditures have drawn attention of health economists worldwide. A large number of studies have estimated the income elasticity of health care expenditure to identify whether health care is a necessary or luxury product, and found varying results. While income elasticity coefficient of health care expenditure was found unity in 21 Organization of Economic Cooperation and Development (OECD) countries reflecting health care not a luxury [5], it was found less than unity in 13 MENA (Middle East and North Africa) countries characterizing health care as a necessary product [6]. However, majority of these studies have focused mainly on developed countries, including OECD countries [5, 7–9], United States [10], Middle East and African countries [6, 11], and European Countries [12, 13].Footnote 1 The issue has been discussed little in developing countries, especially in Asian economies. In recent years only Hassan et. al [14] analysed this relation using South Asian Association for Regional Cooperation (SAARC) countries’ experience. One major limitation of many of the previous studies is that of using a single year of data to obtain cross-country estimates of the natural correlation [11, 15–17], making the regression results spurious. More recently, researchers have used panel data on Health Care Expenditure (HCE) and Gross Domestic Product (GDP) measured across countries and across time [18–23], which offers a number of advantages over cross-sectional study. Using multiple years of data enables researchers to include country-specific fixed effects for each country, thereby controlling for a wide range of time-invariant country characteristics, This avoids potential bias for the estimated relationship between HCE and GDP while retaining the cross sectional dependence and panel heterogeneity as important issues. In addition, the stationarity of the concerned variables are of vital importance when dealing with long panel. Considering these drawbacks of earlier studies, this study examined the impact of income on health care expenditure at macro level using a long panel of 36 Asian countriesFootnote 2 for the period 1995 to 2013 while addressing the issue of heterogeneity and cross sectional dependence.
The paper is organized in the following sections: section 2 describes the source of data and methodological procedures applied in this paper. In Section 3, results of econometric estimations have been discussed and section 4 concludes.
Methods
We aimed to estimate income elasticity of health care expenditure and detect whether health care is a necessary or luxury product in Asian countries. Thus, we estimated the responsiveness of health care expenditure with respect to the change in income while controlling for other variables related to health status improvement. We estimated the following model by using appropriate econometric methods such as Fully Modified OLS (FMOLS) and Dynamic OLS (DOLS):
where, i = 1, 2, −----- N and t = 1, 2, −----- T indexes cross section and time series units respectively. lnHCE i,t is the natural logarithm of health care expenditure (measured in current US $) for country i at time t and lnGDP i,t is the natural logarithm of GDP (measured in current US $) and used as proxy of income. HSI i,t stands for health status improvement of country i at time t which is proxied by using infant mortality and life expectancy for all countries. Finally, ε i,t is the error term with all unobserved factors.
In the above model, β 1 is the coefficient which measures the impact of income on health care expenditure. As the higher the income the higher is the health care expenditure, this coefficient is expected to carry a positive sign. However, its magnitude determines whether health care is a necessary or luxury product. More specifically, as the standard theory of microeconomics suggests if,
Data and statistical software
We have used two secondary data sources to develop the panel data set, namely World Development Indicators (WDI) and Health Nutrition and Population Statistics (HNPS) from World Bank database. A total of 36 Asian countries have been studied for the period of 1995 to 2013. The variables that we have used are, Health Care Expenditure, Gross Domestic Product and Health Status Improvement measured through Infant Mortality (IM) and Life Expectancy (LE). We used EViews 9 and STATA 14 softwares to carry out the econometric analysis.
Cross section dependence test
The existence of common shocks among sample countries could result in creating contemporaneous correlation, popularly known as cross section dependency, among the different countries included in the panel. As the size of the panel unit root test usually becomes distorted because of the presence of cross sectional dependence, it is crucial to diagnose this issue before estimating panel data models. We tested the following null hypothesis: the residuals from the standard panel regression are contemporaneously uncorrelated. Therefore, we diagnosed whether the pair - wise covariance among residuals are zero or not. Symbolically:
In order to test the above hypothesis, we applied four different tests namely Breuch – Pagan Lagrange Multiplier (LM) [24], Pesaran Cross Sectional Dependence (CD), Pesaran Scaled LM [25] and Baltagi, Feng and Kao Bias Corrected Sclaed LM [26]. However, Pesaran CD is regarded as the most general one as it is suitable for stationary and as well as non – stationary panels. It also consists of reasonable small sample properties.
Panel unit root test
Panel based unit root test are more preferred to individual time series ones given the better power properties of the former test. Cross – sectional independence is a crucial assumption for all the readily available panel unit root tests. However, Im, Pesaran and Shin (IPS) panel unit root test by Im et al. [27] relaxes the restrictive assumptions of no serial correlation and panel homogeneity. Im et al. [28] proposed demeaning procedure (subtracting group mean from the data) to denounce the contemporaneous correlation of the data. Therefore, we have used IPS panel unit root test along with Levin, Lin and Chu (LLC) panel unit root test by Levin et al. [29], ADF – Fisher and PP – Fisher panel unit root test by Choi [30] to detect the stationarity of the variables. In order to carry out these tests first for each variable, we estimated an auroregressive (AR) process, and then an Augmented Dickey Fuller (ADF) test regression was fitted for each cross-section unit. For detecting the stationarity of the variables, the statistical significance of the autoregressive coefficient attached with lagged level dependent variable in test regression is tested. Therefore, if the ADF test regression takes the following form:
then the appropriate null hypothesis for testing the panel unit root would be H 0 : α i = 0, for all i. In the above regression y it denotes the variable of concern for which stationary property would be tested and x i,t stands for other control variables.
Panel cointegration test
Several panel cointegration tests are available, including Pedroni [31, 32], McCoskey and Kao [33], Kao [34] and Westerlund [35]. We employed Pedroni [31, 32] and Westerlund [35] panel cointegration test for detecting the existence of cointegrating relationship among the variables. The reason is that the first one allows for heterogeneity while the second one is robust against heterogeneity and cross correlation in panel.
Pedroni panel coinetgration test
The Pedroni [31, 32] is an Engle – Granger based panel cointegration test. Pedroni’s proposed test for panel cointegration considers heterogeneous intercept and trend coefficient across cross country. We estimated the following regression to conduct the test:
where, i = 1, 2, −----- N and t = 1, 2, −----- T, and HCE, GDP and variables i.e. infant mortality and life expectancy under HSI are assumed to be integrated of order one, I(1). We obtained the residuals from the above regression and performed an ADF test on the residuals to estimate whether they are I(1) using the following test regression for each country:
Based on various methods, Pedroni provided a total of eleven statistics in two groups; panel statistic (within dimension) and group statistic (between dimension). The following hypothesis is tested against the alternatives:
In particular panel statistic is concerned with homogeneous alternative while group statistics is concerned with the other. However, all these statistics are distributed as asymptotically normal.
Westerlund panel cointegration test
There are cases where theory suggests existence of long run relationship among variables, panel cointegration tests have failed to reject the null hypothesis of “no cointegration”. It occurs due to the failure of “common – factor restriction” (Banerjee et. al [36]). By depending on structural dynamics (rather than error dynamics) Westrelund [35] have developed a set of panel cointegration test which do not require any common factor restriction. These tests are general enough to be robust against heterogeneity and cross section dependence. The cointegration test assumes the following data generating process:
Where, i = 1, 2, −----- N and t = 1, 2, −----- T indexes cross sectional units and time series. In the above process, x is a vector of independent variables that includes GDP and HSI measured in terms of infant mortality and life expectancy and finally d t contains deterministic components. Here, α i is referred to as error correction parameter. If α i < 0 then there will be error correction and hence cointegration while if α i = 0, reflects that the error correction is absent and consequently there is no cointegration.
Westerlund [35] proposed four panel statistics, among which two (Panel Statistic) test the alternative hypothesis that panel is cointegrated as a whole while the other two (Group Statistic) test that at least one is cointegrated. Thus, the null and alternative hypothesis tested is formulated in the following way:
Estimation of cointegrating relationship
In our data GDP and HSI i.e. infant mortality and life expectancy can become endogenous and also the error terms can be serially correlated which would result in the dependence of OLS estimators on nuisance parameters. In order to solve these problems two estimators namely FMOLS and DOLS can be introduced. Phillips and Hansen [37] proposed a semi parametric correction for the problem of long run correlation among cointegrating equation and stochastic regressors innovations resulting in FMOLS estimators. It is asymptotically unbiased. On the other hand Saikkonen [38] and Stock and Watson [39] advanced an asymptotically efficient estimator which eliminates the feedback in the cointegrating system by augmenting the cointegrating regression with lags and leads of independent variables. The resulting estimator is known as DOLS estimator.
With a view to explain the idea of FMOLS estimator consider the following fixed effect model:
Where, i = 1, 2,-----, N and t = 1, 2, −----, T indexes cross section and time series units respectively, HCE i,t is the health care expenditure (an I(1) process), β is (2*1) vector of parameters, α i are intercepts and u i,t are the stationary disturbance terms. Here x i,t are assumed to be (2*1) vector of independent variables (GDP and HSI measured with infant mortality and life expectancy) which are I(1) for all cross section units. It is assumed that it follows an autoregressive process of following form:
Given that w i,t = (u i,t , ε i,t ) ~ I(0) the variables are said to be cointegrated for each members of the panel with cointegrating vector β. The asymptotic distribution of the OLS estimator is condition to the long run covariance matrix of the innovation vector. The FMOLS estimator is derived by making endogeneity correction (by modifying variable HCE i,t ) and serial correlation correction (by modifying long run covariance of innovation vector, w i,t ). The resulting final estimator is expressed as follows:
The cointegrating regression is augmented by lead and lagged differences of GDP and other independent variables in DOLS framework for controlling endogeneity (by following Saikkonen, [38]). For controlling serial correlation, lead and lagged difference of the HCE has also been included in the model (by following Stock and Watson, [39]). Thus, the estimated regression equation under DOLS framework was as follows:
Results
With a view to determining the appropriate estimation method, we need to check the stationary of the variables and also their order of integration. However, cross sectional dependence or cross sectional correlation of the variables is a fact that should be detected for the variables to decide which panel unit root test would be applied.
Table 1 contains the test results for Cross Sectional Dependence of different variables, and suggests that it is possible to reject the null hypothesis for all the variables at 1% level of significance. Therefore, the residuals from the standard panel regression would be contemporaneously correlated and this should be addressed while panel stationarity would be tested.
Therefore, we have used IPS panel unit root test to detect the stationarity of the variables along with some other tests e.g. Levin, Lin and Chu (LLC) test (Levin et al., [29]), ADF - Fisher Test and PP – Fisher test (Choi, [30]).
Table 2 and Tables 7, 8 and 9 in Appendix contain the panel unit root test results for each of the variables. All the tests are concerned with the null hypothesis of “Panels Contain Individual Unit Root” except LLC that tests the null hypothesis of “Panel Contains Common Unit Root”. The tests have been carried out with two different test regression specifications; one with constant and the other with constant and trend. It is evident from the test results that GDP and HCE are difference stationary i.e. I(1) variable according to all tests. With regards to infant mortality, it is also found to be difference stationary in intercept and trend specification under IPS, ADF – Fisher and PP – Fisher test. Thus it can be treated as an I(1) variable. Life expectancy was found to be difference stationary in intercept specification under IPS, in intercept and trend specification under LLC and in both specification under ADF - Fisher test. Since all the variables have been found to be integrated of a unique order we have identified the long run relationship among them by establishing the panel cointegration.
In order to check the existence of cointegration among the variables along with Pedroni [31, 32] Engle Granger based panel cointegration test, we applied Westerlund [35] error correction based panel cointegration test. The later one is already established in the literature for its robustness against panel with heterogeneity and cross sectional dependence. Hence, application of this test allowed us to check issue of existence of cointegartion among health care expenditure and income while controlling for health status improvement measured with infant mortality and life expectancy in a more comprehensive manner. Both the tests have been performed with three different deterministic specifications.
Table 3 and Table 10 in Appendix contain the test results of panel cointegration. For testing the cointegration among health care expenditure, income and infant mortaility when neither constant nor trend was used as deterministic specification, the null hypothesis of “no cointegration” was rejected by all 11 statistic under Pedroni [31, 32] test. All the 4 statistic of Westerlund [35] test have also found to be significant. In the same specification when cointegration was checked among health care expenditure, income and life expectancy a total of 7 statistic in Pedroni [31, 32] and 2 among 4 statistic of Westerlund [35] was found to be statistically significant. When the deterministic specification was changed to allow the presence of constant, only 7 and 6 of 11 statistic for infant mortality and life expectancy respectively have found to be able to reject the non existence of cointegration under Pedroni [31, 32] test. By using the similar deterministic specification Westerlund [35] test was able to reject the null for both variables under 2 statistic out of 4. The conclusion of Westerlund [35] test has remained the same when the deterministic specification allows for both the constant and trend. While Pedroni [31, 32] test was carried out by using the later deterministic specification, 4 statistic have found to be significant when panel cointegration was checked with infant mortality while the number was 6 if it was tested with life expectancy. Thus, it can be argued that there might exists a long run cointegrating relationship among health expenditure, income and health status improvement which is substituted by using infant mortality and life expectancy.
With a view to estimate the cointegrating vector we have applied two different methods, FMOLS and DOLS. Each of the methods provides three different estimators namely, pooled, pooled weighted and grouped mean. The pooled FMOLS estimator is the extension of Phillips and Hansen [37] FMOLS estimator offered by Phillips and Moon [40] which provides the estimators after correcting deterministic components in regressand and regressors. In order to allow different long run variances across the cross section for heterogeneous panels, Pedroni [41] and Kao and Chiang [42] proposed pooled weighted FMOLS. Finally the grouped mean FMOLS estimator developed by Pedroni [41, 43] is derived by averaging the individual cross section FMOLS estimates. In contrast to FMOLS, augmentation of model with lags and leads of differenced regressand and regressors in DOLS helps it to overcome the problem of asymptotic endogeneity and serial correlation. Kao and Chiang [42], Mark and Sul [44, 45] and Pedroni [43] extended the standard DOLS estimation developed by Saikkonen [38] and Stock and Watson [39]. Kao and Chiang [42] proposed pooled DOLS where the augmented cointegrating regression allows the short run dynamics to be cross section specific. By allowing heterogenous long run variance, Mark and Sul [44, 45] developed pooled weighted DOLS. Finally, Pedroni [43] developed the grouped mean DOLS estimates by averaging the individual cross section DOLS estimates.
Table 4 contains the estimation results of long run relationship between health care expenditure and GDP and infant mortality as a measure of health status improvement. It is evident that the elasticity of health care expenditure with respect to income in Asian countries is less than unit. The elasticity coefficient varies from 0.73 to 0.83 when the model was estimated using FMOLS while the range was found to be 0.67 to 0.80 while estimating using DOLS method. The Wald test was observed to be significant in all cases. Thus, health care in Asian countries can be argued as a necessary and normal product. The elasticity coefficient of infant mortality was found to be negative and significant in almost all cases. Therefore, there is an inverse relationship between health care expenditure and infant mortality in Asian countries. Thus, the higher the health care expenditure, the lower the infant mortality or vice – versa.
Table 5 contains the results of cointegrating relationship between health care expenditure and GDP and another indicator of health status improvement measured by life expectancy. The elasticity coefficient of health care expenditure with respect of income was also found to be less than one. Here the elasticity measure varied in between 0.84 to 0.92 in FMOLS method and 0.77 to 0.91 in DOLS method. The coefficient has been observed to remain positive and significant in all cases. Thus, for Asian countries health care expenditure increases less than proportionately with the increase in income. The coefficient of life expectancy was found to be significant in almost all cases. Therefore, with respect to increase in life expectancy, health care expenditure increases in these countries.
Thus, unlike many OECD and developed countries such as USA, Canada, Germany and Italy where health care expenditure has been identified as luxury good, for Asian Countries it is revealed to be a necessary one. The findings contradict Hassan et. al [14] but in line with what have been found in Dreger and Reimers [5], Mehrara et. al [6] and Penas et. al [8].
Discussion and conclusion
By exploiting data for the period of 1995 to 2013, the study finds that long run elasticity of health care expenditure in relation to income is less than unit in 36 Asian countries, ensuring that the health care can be treated as a necessary product as a whole for the sample countries. In general the responsiveness was found to be higher when life expectancy was used instead of infant mortality as proxy of health status improvement. Our finding is different from that of Hassan et. al [14] which suggested health care as luxury products for South Asian Association for Regional Cooperation (SAARC) countries. However, the latter study has ignored the issue of cross correlation which may mislead the findings. Moreover, the way the coefficients had been analyzed made the reasoning and policy implications rather weak.
The contribution of this paper to the literature on the relationship between health care expenditure and income is twofold. First, it has covered almost all the countries in Asia, and analyzed the issue in a more rigorous manner in the sense of addressing cross correlation and heterogeneity problem that potentially exists in the panel and brought the findings in front to realize how health care should be treated in those countries. Second, from methodological point of view, as the study has addressed the issue of cross sectional correlation and panel heterogeneity, the findings are more reliable. The current work has examined the existence of long run relationship between health care expenditure and income using a panel cointegration technique which is robust against cross sectional correlation and panel heterogeneity along with conventional panel cointegration test. The estimation technique- FMOLS and as well as DOLS- has been used which is robust against asymptotic endogeneity and serial correlation.
The study has a number of areas to improve. As cross section dependence was detected it would have been better if second generation panel unit root tests were used when identifying the integration order of the variables. However, demeaning of data has taken care of the severity of problem to some extent. Throughout the analysis the parameters have been assumed to be stable, thus should there be any structural instability the findings may vary. Further research is required addressing the above issues.
Notes
A summary of previous studies have presented in Table 6 in Appendix
List of Countries: Bahrain, Bangladesh, Bhutan, Brunei, Cambodia, China, India, Indonesia, Iran, Israel, Japan, Jordan, Kazakhstan, Korea Rep., Kuwait, Kyrgyzstan, Laos, Lebanon, Malaysia, Mongolia, Maldives, Nepal, Oman, Pakistan, Philippines, Qatar, Saudi Arabia, Singapore, Srilanka, Tajikistan, Thailand, Turkmenistan, United Arab Emirates, Uzbekistan, Vietnam and Yemen
References
Farag M, Nandakumar AK, Wallack S, Hodgkin D, Gaumer G, Erbil C. Health expenditures, health outcomes and the role of good governance. Int J Health Care Finance Econ. 2013;13(1):33–52.
Allen S, Badiane O, Sene L, Ulimwengu J. Government expenditures, health outcomes and marginal productivity of agricultural inputs: The case of Tanzania. J Agric Econ. 2014;65(3):637–62.
Elola J, Daponte A, Navarro V. Health indicators and the organization of health care systems in western Europe. Am J Public Health. 1995;85(10):1397–401.
Anyanwu JC, Erhijakpor AE. Health expenditures and health outcomes in Africa. Afr Dev Rev. 2009;21(2):400–33.
Dreger C, Reimers HE. Health care expenditures in OECD countries: a panel unit root and cointegration analysis. 2005.
Mehrara M, Fazaeli AA, Fazaeli AA, Fazaeli AR. The Relationship between Health Expenditures and Economic Growth in Middle East & North Africa (MENA) Countries. Int J Buss Mgt Eco Res. 2012;3(1):2012.
Jewell T, Lee J, Tieslau M, Strazicich MC. Stationarity of health expenditures and GDP: evidence from panel unit root tests with heterogeneous structural breaks. J Health Econ. 2003;22(2):313–23.
Lago-Peñas S, Cantarero-Prieto D, Blázquez-Fernández C. On the relationship between GDP and health care expenditure: a new look. Econ Model. 2013;32:124–9.
MacDonald G, Hopkins S. Unit root properties of OECD health care expenditure and GDP data. Health Econ. 2002;11(4):371–6.
Wang Z, Rettenmaier AJ. A note on cointegration of health expenditures and income. Health Econ. 2007;16(6):559–78.
Gbesemete KP, Gerdtham UG. Determinants of health care expenditure in Africa: a cross-sectional study. World Dev. 1992;20(2):303–8.
Hitiris T. Health care expenditure and integration in the countries of the European Union. Appl Econ. 1997;29(1):1–6.
Roberts J. Spurious regression problems in the determinants of health care expenditure: a comment on Hitiris (1997). Appl Econ Lett. 2000;7(5):279–83.
Hassan SA, Zaman K, Zaman S, Shabir M. Measuring health expenditures and outcomes in saarc region: health is a luxury? Qual Quant. 2014;48(3):1421–37.
Abel-Smith B, World Health Organization. An international study of health expenditure and its relevance for health planning. 1967.
Newhouse JP. Medical-care expenditure: a cross-national survey. J Hum Resour. 1977;12(1):115–25.
Parkin D, McGuire A, Yule B. Aggregate health care expenditures and national income: is health care a luxury good? J Health Econ. 1987;6(2):109–27.
Baltagi BH, Moscone F. Health care expenditure and income in the OECD reconsidered: Evidence from panel data. Econ Model. 2010;27(4):804–11.
Chakroun M. Health care expenditure and GDP: An international panel smooth transition approach. Int J Econ. 2010;4(1):189–200.
Gerdtham UG, Søgaard J, Andersson F, Jönsson B. An econometric analysis of health care expenditure: a cross-section study of the OECD countries. J Health Econ. 1992;11(1):63–84.
Hitiris T, Posnett J. The determinants and effects of health expenditure in developed countries. J Health Econ. 1992;11(2):173–81.
Liu D, Li R, Wang Z. Testing for structural breaks in panel varying coefficient models: with an application to OECD health expenditure. Empir Econ. 2011;40(1):95–118.
Sen A. Is health care a luxury? New evidence from OECD data. Int J Health Care Finance Econ. 2005;5(2):147–64.
Breusch TS, Pagan AR. The Lagrange Multiplier Test and Its Applications to Model Specification in Econometrics. Rev Econ Stud. 1980;47(1):239–53.
Pesaran MHHM. General diagnostic tests for cross section dependence in panels. CESifo Working Papers. 2004;1233:255–60.
Baltagi BH, Feng Q, Kao C. A Lagrange Multiplier test for cross-sectional dependence in a fixed effects panel data model. J Econ. 2012;170(1):164–77.
Im KS, Pesaran MH, Shin Y. Testing for unit roots in heterogeneous panels. J Econ. 2003;115(1):53–74.
Im KS, Pesaran MH, Shin Y. Testing for unit roots in heterogeneous panels. Mimeo: Department of Applied Economics, University of Cambridge; 1997.
Levin A, Lin CF, Chu CSJ. Unit root tests in panel data: asymptotic and finite-sample properties. J Econ. 2002;108(1):1–24.
Choi I. Unit root tests for panel data. J Int Money Financ. 2001;20(2):249–72.
Pedroni P. Critical values for cointegration tests in heterogeneous panels with multiple regressors. Oxf Bull Econ Stat. 1999;61(s 1):653–70.
Pedroni P. Panel cointegration: asymptotic and finite sample properties of pooled time series tests with an application to the PPP hypothesis. Economet Theor. 2004;20(03):597–625.
McCoskey S, Kao C. A residual-based test of the null of cointegration in panel data. Econ Rev. 1998;17(1):57–84.
Kao C. Spurious regression and residual-based tests for cointegration in panel data. J Econ. 1999;90(1):1–44.
Westerlund J, Edgerton DL. A panel bootstrap cointegration test. Econ Lett. 2007;97(3):185–90.
Banerjee A, Dolado J, Mestre R. Error‐correction mechanism tests for cointegration in a single‐equation framework. J Time Ser Anal. 1998;19(3):267–83.
Phillips PC, Hansen BE. Statistical inference in instrumental variables regression with I (1) processes. Rev Econ Stud. 1990;57(1):99–125.
Saikkonen P. Estimation and testing of cointegrated systems by an autoregressive approximation. Economet Theor. 1992;8(01):1–27.
Stock JH, Watson MW. A simple estimator of cointegrating vectors in higher order integrated systems. Econometrica. 1993;61(4):783–820.
Phillips PC, Moon HR. Linear regression limit theory for nonstationary panel data. Econometrica. 1999;67(5):1057–111.
Pedroni P. Fully Modified OLS for Heterogeneous Cointegrated Panels. 2000.
Kao C, Chiang MH. On The Estimation and Inference of A Cointegrated Regression In Panel Data. 2000.
Pedroni P. Purchasing power parity tests in cointegrated panels. Rev Econ Stat. 2001;83(4):727–31.
Mark N, Sul D. A computationally simple cointegration vector estimator for panel data, Ohio State University manuscript. 1999.
Mark NC, Sul D. Cointegration Vector Estimation by Panel DOLS and Long‐run Money Demand. Oxf Bull Econ Stat. 2003;65(5):655–80.
Getzen TE. Health care is an individual necessity and a national luxury: applying multilevel decision models to the analysis of health care expenditures. J Health Econ. 2000;19(2):259–70.
Fogel RW. Catching up with the economy. The American Economic Review. 1999;89(1):1–21.
Gertler P, & Van der Gaag J. The willingness to pay for medical care: evidence from two developing countries. Baltimore, Maryland, Johns Hospital University Press. 1990. ix, 139 p.
Getzen TE. Macro forecasting of national health expenditures. Advances in health economics and health services research. 1990;11:27–48.
Getzen TE, & Poullier JP. International health spending forecasts: concepts and evaluation. Social Science & Medicine. 1992;34(9):1057–1068.
Kleiman E. The determinants of national outlay on health. In: Perlman, M. (Ed.), The Economics of Health and Medical Care. Macmillan, London. 1974.
Maxwell RJ. Health and wealth: An international study of health-care spending. Lexington Books, MA. 1981.
Schieber GJ. Health expenditures in major industrialized countries. Health care financing review. 1990;11(4):159–169.
Chakroun M. Health care expenditure and GDP: An international panel smooth transition approach (No. 14322). University Library of Munich, Germany. 2009.
Hansen P, & King A. The determinants of health care expenditure: a cointegration approach. Journal of health economics. 1996;15(1):127–137.
Okunade AA, & Murthy VN. Technology as a ‘major driver’of health care costs: a cointegration analysis of the Newhouse conjecture. Journal of health economics. 2002;21(1):147–159.
Clemente J, Marcuello C, Montañés A, & Pueyo F. On the international stability of health care expenditure functions: are government and private functions similar?. Journal of Health Economics. 2004;23(3):589–613.
Blomqvist ÅG, & Carter RA. Is health care really a luxury?. Journal of Health Economics. 1997;16(2):207–229.
Bhat R, & Jain N. Analysis of public expenditure on health using state level data. Indian Institute of Management: Ahmedabad (India). 2004.
Leu RE. The public-private mix and international health care costs. Public and private health services. 1986;(7):41.
Wang Z, & Rettenmaier AJ. A note on cointegration of health expenditures and income. Health Economics. 2007;16(6):559–578.
Acknowledgement
Authors of the paper are greatly indebted to Professor Joakim Westerlund and Dr. Damiaan Persyn for sharing their codes to perform econometric exercise which made the journey of completion of the work easier.
Authors’ contributions
All the authors in the current work have contributed uniformly. SMA developed the research problem formulated the model design and performed the econometric exercise. SS took the responsibility to do the survey of existing literature and finding the research gap and contributed to the result explanations. RH synthesized research gap with the methodology and have given effort to bring the issue into perspective and contributed to prepare the draft. All authors have read and approved the manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Abdullah, S.M., Siddiqua, S. & Huque, R. Is health care a necessary or luxury product for Asian countries? An answer using panel approach. Health Econ Rev 7, 4 (2017). https://doi.org/10.1186/s13561-017-0144-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13561-017-0144-8
Keywords
- Income elasticity
- Health care expenditure
- Panel cointegration
- Panel unit root
- Cross section dependence
- FMOLS
- DOLS