
Abstract
Background
Interpreting point-of-care lung ultrasound (LUS) images from intensive care unit (ICU) patients can be challenging, especially in low- and middle- income countries (LMICs) where there is limited training available. Despite recent advances in the use of Artificial Intelligence (AI) to automate many ultrasound imaging analysis tasks, no AI-enabled LUS solutions have been proven to be clinically useful in ICUs, and specifically in LMICs. Therefore, we developed an AI solution that assists LUS practitioners and assessed its usefulness in a low resource ICU.
Methods
This was a three-phase prospective study. In the first phase, the performance of four different clinical user groups in interpreting LUS clips was assessed. In the second phase, the performance of 57 non-expert clinicians with and without the aid of a bespoke AI tool for LUS interpretation was assessed in retrospective offline clips. In the third phase, we conducted a prospective study in the ICU where 14 clinicians were asked to carry out LUS examinations in 7 patients with and without our AI tool and we interviewed the clinicians regarding the usability of the AI tool.
Results
The average accuracy of beginners’ LUS interpretation was 68.7% [95% CI 66.8–70.7%] compared to 72.2% [95% CI 70.0–75.6%] in intermediate, and 73.4% [95% CI 62.2–87.8%] in advanced users. Experts had an average accuracy of 95.0% [95% CI 88.2–100.0%], which was significantly better than beginners, intermediate and advanced users (p < 0.001). When supported by our AI tool for interpreting retrospectively acquired clips, the non-expert clinicians improved their performance from an average of 68.9% [95% CI 65.6–73.9%] to 82.9% [95% CI 79.1–86.7%], (p < 0.001). In prospective real-time testing, non-expert clinicians improved their baseline performance from 68.1% [95% CI 57.9–78.2%] to 93.4% [95% CI 89.0–97.8%], (p < 0.001) when using our AI tool. The time-to-interpret clips improved from a median of 12.1 s (IQR 8.5–20.6) to 5.0 s (IQR 3.5–8.8), (p < 0.001) and clinicians’ median confidence level improved from 3 out of 4 to 4 out of 4 when using our AI tool.
Conclusions
AI-assisted LUS can help non-expert clinicians in an LMIC ICU improve their performance in interpreting LUS features more accurately, more quickly and more confidently.
Similar content being viewed by others

Background
In recent years, point-of-care ultrasound (POCUS) has proved to be a useful bedside imaging technique for the assessment of critically ill patients for both diagnosis and therapeutic management [1,2,3]. LUS does not expose patients to radiation and has been shown to be more sensitive and specific in the diagnosis of many pulmonary pathologies when compared to chest x-ray (CXR) [4], hence the potential for application of LUS in low- and middle-income countries (LMICs) is high [5, 6].
Respiratory failure due to infectious disease is one the most common reasons for ICU admission in LMICs, for example, due to dengue, sepsis, or malaria and more recently Covid-19. In severe cases, progression to Acute Respiratory Distress Syndrome (ARDS) can occur, which has a high mortality, and leaves survivors with significant pulmonary morbidity [7,8,9]. LUS protocols such as the BLUE protocol and the FALLS protocol [10] are designed to assist doctors with the diagnosis and management of pulmonary and cardiac conditions. The Kigali modification of the Berlin ARDS criteria [11] has helped to diagnose ARDS in resource-limited settings by using ultrasound instead of CXR or Computed Tomography (CT) which are often unavailable in these settings. However, LUS is operator-dependent and requires extensive training for image acquisition and interpretation. The lack of qualified ultrasound professionals and the paucity of training programs are significant obstacles to the implementation of LUS in LMIC ICUs.
Artificial intelligence (AI), particularly deep learning, has made substantial advances in ultrasound imaging analysis during the last decade. For LUS, most existing work is limited to AI-recognition of a single artefact (B-lines), or, more recently, multi-class classification for a specific lung disease, focusing on COVID-19 [12,13,14,15,16,17]. Still, the implementation and validation of developed algorithms in clinical settings remains very limited and is focused mainly on fetal and cardiac ultrasound [18,19,20].
In the case of LUS there are, to date, no published investigations on real-time deployment of AI-enabled tools to recognise multiple LUS patterns. In addition to improving accuracy, automatic recognition can help improve confidence in, and reduce the time spent by the clinician on, image interpretation, especially where resources are limited [21].
For these reasons, our study aimed to evaluate a real-time AI-ultrasound system designed to detect five common LUS patterns relevant to LMIC ICU clinicians. Building upon our previous AI methodology work, in this study, we evaluated the clinical need and assessed the utility of AI-enabled LUS in an ideal offline scenario followed by real-time clinical practice.
Methods
Our study was carried out in Vietnam in three phases. In the first phase we confirmed the use-case for our tool and set a minimum performance target for the AI system. This was an online interactive survey of participants from multiple hospitals in Vietnam. The second and third phases assessed the use of the AI tool and were carried out at the Hospital for Tropical Diseases (HTD) Ho Chi Minh City. In this study we deliberately chose to focus on the non-expert clinician in phase 2 and 3, as there are currently few experts or advanced users, and inexperienced clinicians are the target users for our tool. The study was approved by the Scientific and Ethical Committee of the Hospital for Tropical Diseases and the Oxford Tropical Research Ethics Committee. All participants gave written informed consent.
Phase 1: baseline characterization of user performance in LUS interpretation without AI support
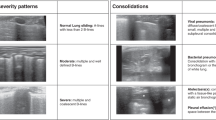
An online survey was completed by 276 participants of an online LUS training course attended by doctors from multiple centres around Vietnam on September 4th, 2021. The level of expertise was self-assessed by clinicians using four pre-defined categories: (1) beginners, defined as “just know about LUS but have not practiced in patients”, (2) intermediate, a clinician who has been carrying out LUS (< 2 times/week) but have not used the findings for clinical assessment, (3) advanced, a clinician who uses LUS in daily practice and its findings are used for clinical assessment, and (4) expert, a clinician who specialised in lung ultrasound and has more than 5 years’ experience. The participants were asked to identify the findings in a series of 10 LUS clips from adult patients hospitalized with dengue shock and septic shock displaying A-lines, B-lines, Confluent B-lines, Consolidation and Pleural Effusion (2 of each) given in a set order (samples are shown in the Additional file 1: Fig. S1). Responses were compared with the expert-defined labels consistent with our data curation process. All clips were sourced and labelled with agreement by three ultrasound-trained clinicians and one expert.
Phase 2: development and clinical validation of the real-time AI-assisted LUS framework (RAILUS) in controlled environment
In this phase, we evaluated the impact of our bespoke LUS AI system on clinicians’ performance in a controlled environment, using a set of images already obtained by LUS experts. Our RAILUS (Real-time AI-assisted LUS) system is described in greater detail in the Additional file 1 (Table S1, Table S2, Fig. S2, Fig. S3) and consists of an AI model integrated into the PRETUS platform (Fig. S4) [22].
Briefly, the system provides continuous real-time prediction through a laptop and can be used in both pre-recorded LUS clips and the real-time clinical environment with clinicians carrying out the LUS examination, with the ultrasound machine’s video output connected to the laptop (Fig. 1). RAILUS also captures the user prediction, model prediction, time-to-interpret, and the confidence of the users, and can be used in any ultrasound machine with a video output port.

Real-time AI-assisted LUS framework (RAILUS)
We evaluated the performance of RAILUS in a controlled environment in workshops for 57 non-expert clinicians in three different clinical settings (tertiary referral centre, COVID-19 field hospital and academic ventilation training course). Participants were given 1 h of training to become familiar with the RAILUS software then asked to interpret LUS videos (as in phase 1) firstly, without the RAILUS tool and then with the RAILUS tool (participants were blinded to the AI-assisted interpretation). Reponses were used to calculate the average accuracy of the interpretation against expert-defined labels.
Phase 3: real-time implementation of RAILUS software in critically ill patients
Real-time evaluation was carried out prospectively by a subset of non-expert clinicians from Phase 2 who carried out LUS with and without the AI system in the Emergency Department or on ICU patients at the Hospital for Tropical Diseases Ho Chi Minh City. Eligible patients were adults aged ≥ 18 years with dengue shock admitted between December 2021 to February 2022. Patients who were allergic to ultrasound gel or had open wounds on their chest were excluded. This study was approved by the Oxford Tropical Research Ethics Committee (OxTREC) and the HTD Institutional Review Board. Patients underwent LUS scans by non-expert clinicians who had received 1 h of training similar to above. Participating clinicians were randomly assigned to perform the LUS scans on patients following a standard 12 zone LUS protocol with or without the RAILUS software (Additional file 1: Fig. S5). When assigned to the non-AI group, the AI-assisted interpretation was turned off. A LUS expert then performed the same 12 zone scan on the same patient within 2 h of the non-expert clinicians performing their LUS scans. To assess whether each scan was of adequate diagnostic quality, we performed an independent expert validation (blinded to whether the study was performed using the AI tool or not). To evaluate usability, a questionnaire was administered to the clinicians at the end of the procedure. The full questionnaire can be found in Additional file 1: Table S4 and Table S5.
Results were evaluated to quantify the accuracy of the interpretation against the expert, the time required to interpret single lung zones, and the clinicians’ perceived confidence in their interpretation (from 1 to 4. with 1 = not confident and 4 = very confident).
Statistical analysis
To assess the performance of the clip classification task, we assessed (1) overall accuracy, calculated as the number of correctly classified clips as a fraction of the total number of clips; (2) average accuracy, calculated as the average over all lung pathologies of per-pathology accuracy; (3) F-score; (4) precision and (5) sensitivity (recall). Confusion matrices were calculated and reported. The discriminative variable of demographic information was reported as a percentage. To compare the clinicians’ performance with and without our AI tool, we utilized confusion matrices with the horizontal axis and vertical axis corresponding to predicted label and true label, respectively. The proportion of clips that were accurately classified are reported with 95% confidence intervals (95% CI).
Results
User performance in LUS interpretation without AI support (phase 1)
The demographic information of the clinicians and principal challenges encountered are provided in Additional file 1: Tables S6 and S7. The majority (194/276, 70%) of clinicians identified themselves as beginners, and there were very few experts (4/276, 1%). Most clinicians identified “image interpretation" as the main challenge.
The unassisted video classification results are shown in the confusion matrices in Fig. 2 (showing total count and percentage). Experts showed excellent ability to accurately classify LUS clips. For all other clinician categories, there was more difficulty in differentiating A-lines, B-lines and confluent B-lines, and relative ease in identifying consolidation and pleural effusion.

The results of the manual video classification of clinicians with 4 levels of expertise
Horizontal and vertical axis show predicted label and expert-defined label, respectively. The numbers in each cell indicate total count (percentage of total). Cells are colored by percentage.
Interestingly, although the average accuracy was correlated to the level of expertise (beginners: 68.7% (95% CI 66.8–70.7%), intermediate 72.2% (95% CI 70.0–75.6%), advanced 73.4% (95% CI 62.2–87.8%), and experts 95.0% (95% CI 88.2–100.0%)), (p < 0.001), the difference in performance between beginners, intermediate and advanced users was relatively small (< 5%).
Performance and clinical validation of the real-time AI-assisted LUS framework (RAILUS) in a controlled environment (phase 2)
The performance of the proposed AI model is shown in the Additional file 1: Table S2 and Fig. S3. The demographic information of the 57 non-expert clinicians is provided in the Additional file 1: Tables S6. The performance of clinicians in identifying the LUS clips presented to them was improved using the RAILUS software, with a mean accuracy of 82.9% (95% CI 86.7–79.1%), compared to 68.9% (95% CI 65.6–73.9%), (p < 0.001) (Fig. 3). The accuracy of all classes increased significantly except for the case of B-lines classification, which reduced from 63% to 59% when using RAILUS. The performance of the subset of 14 clinicians who participated in both phase 2 and phase 3 was shown in the Additional file 1: Fig. S6.

Confusion matrices of clinicians with, and without RAILUS in a controlled environment using expert-acquired clips
Real-time implementation of RAILUS software in critically ill patients (phase 3)
In total, seven patients with dengue shock were recruited for real-time testing of the RAILUS software. Additional file 1: Table S3 and Table S6 show the characteristics of the patients and the 14 non-expert clinicians, respectively. Overall, 26 LUS exams were carried out, resulting in 168 LUS videos (4 s each) performed with the AI tool and 144 LUS videos performed without the AI tool. Image quality was acceptable for all scans. No adverse events occurred during scanning.
Accuracy of image identification was higher in those using the RAILUS AI tool than those using the standard LUS technique: 93.4% (95% CI 89.0–97.8%) compared to 68.1% (95% CI 57.9–78.2%), (p < 0.001). Performance was better in all classes for clinicians using our AI tool compared to those without AI assistance as shown in Fig. 4. In particular, A-line detection accuracy rose from 74 to 98%, and Confluent B-line detection accuracy rose from 6 to 92%.

Confusion matrices of clinicians with and without RAILUS in real-time
The time taken to interpret one LUS clip was shorter when using the RAILUS software compared to the standard LUS technique: a median of 5.0 s (IQR 3.5–8.8) compared to 12.1 s (IQR 8.5–20.6) (p < 0.001). In addition, the median confidence level of clinicians improved from 3 out of 4 to 4 out of 4 when scanning patients using the AI tool.
Overall, most operators found the tool usable, useful, and beneficial. Usability questionnaires showed an overall positive impression of the RAILUS tool. Most clinicians (13/14, 93%) found the AI-assisted tool useful in the clinical context and wanted to use the tool in the future (12/14, 86%). 64% (9/14) of clinicians thought the tool was useful for both real-time and post-exam evaluation of LUS imaging while only 7% (1/14) thought it was only useful for post-exam evaluation. Interestingly, 71% (10/14) of clinicians wanted the radiologist/expert to re-evaluate their interpretation with the AI tool. Moreover, 64% (9/14) of clinicians felt more confident when performing LUS with the AI tool, compared to only 7% (1/14) being most confident without the AI tool.
Regarding the concerns of clinicians, the issues of legal responsibility (9/14, 64%) and data privacy (4/14, 28%) were identified. More details about the usability survey can be found in the Additional file 1: Figure S7.
Discussion
In this paper, we have evaluated an AI-assisted LUS system in a resource-limited ICU setting. To this end, we initially assessed the baseline performance of clinicians in a LUS image classification task. Our results show that there is a significant gap between beginners, intermediate, advanced clinicians, and experts in LUS interpretation, particularly in B line interpretation. This is consistent with our survey where the majority of the participants stated that image interpretation was their most significant challenge in performing LUS. This performance gap and the challenging nature of this task may prevent non-expert clinicians from carrying out LUS examinations in practice. In low resource settings like Vietnam, there are very few experts or even advanced clinicians in LUS. As our survey in phase 1 showed, across Vietnam, there were very few advanced users or experts, hence the need for our tool. Even in our setting for phase 3 of this study—a large teaching hospital- there are no experts in LUS. Developing an AI tool that can assist inexperienced users in this setting could be highly beneficial for patient outcomes and improving quality of care.
A crucial aim of our study was to investigate whether operators improved their baseline performance when assisted by our RAILUS AI system. Our study showed that performance improved by 15% when using RAILUS in a controlled environment (with expert-obtained clips), but by 25% when using RAILUS prospectively in real-time. Notably, this represented a level exceeding the baseline set by advanced clinicians in Phase 1. In addition, interpretation was approximately twice as fast when using the AI system. Of note, the clinicians using the tool were those already involved in routine care of these patients (imaging staff, infectious disease doctors and ICU staff) but they still showed a significant improvement in performance with the AI tool in both phases 2 and 3. The performance of clinicians in interpreting B-lines reduced slightly in the second phase. We note that this is mainly due to difficulty distinguishing B lines from confluent B lines. Our User Interface (UI) allowed several possibilities to be simultaneously displayed, and commonly this meant that both B line and confluent B lines were predicted for the same clips (although with varying degrees of certainty as represented by the green line in the UI—Additional File 1: Figure S4). The ultimate decision was left with the clinician, and hence this introduces interesting questions about trust in AI and clinical decision making. In phase 3 there were only 2 loops with B-lines, thus a small sample size from which to make definite conclusions in this sub-sample, and also we cannot exclude other contextual influences on decision making. In future studies, sample size calculations should take the incidence rate of each lung pattern into account and also make efforts to understand better clinicians' reasons for following AI predictions (or not).
Finally, these quantitative results were supported by the post-experiment surveys, which revealed that the AI-assisted tool was felt to be useful in the clinical context and most clinicians confirmed they were keen to use the tool in the future. However, the concerns raised about data privacy and legal responsibility when using an AI-assisted tool are valid. As the application of AI in ultrasound is in its infancy, there are relatively few regulations on how to legally implement it in routine healthcare practice or who will be response for AI derived medical errors, particularly in low resource settings. By improving the accuracy, speed and confidence of bedside LUS, it might help clinicians in ICUs in LMICs to better manage critically ill patients with various lung pathologies. This could especially benefit the monitoring of patients during fluid resuscitation where fluid balance is critical to achieve a stable haemodynamic status without causing fluid overload e.g., pulmonary oedema.
We believe our study represents an important step towards real-time implementation of AI in LMIC ICUs, but nevertheless has some limitations. The dataset used is from patients with severe dengue or sepsis so it remains to be seen how these results would translate to patients with other diseases. Furthermore, while we have designed our system to be agnostic to ultrasound devices, clinical validation of the tool on other types of device (such as portable devices) is yet to be performed. Our study focused on the individual findings of LUS. Clinical practice requires a more nuanced interpretation of these findings for optimal benefit, for example, whether the confluent B-lines and consolidations are focal or non-focal to discriminate between pneumonia or pulmonary edema. For the first phase, the order of questions in the survey was not randomized but it was distributed electronically to a pool of participants distributed across Vietnam who could not share the survey with each other. In terms of clinical validation, the study did not randomize the patients to either use the AI tool or not. Future studies should explore the potential benefits of AI tools for advanced or expert users, the regulatory, ethical and cultural issues of the clinical use of AI methods in different healthcare settings. In addition, further technical development including but not limited to AI interpretability, AI fairness, quantification of pleural effusion, or more complex LUS patterns such as pneumothorax can be attractive fields of research.
Conclusions
This is the first study of real-time implementation of AI-assisted LUS interpretation in critically ill patients, demonstrating the feasibility of our system for non-expert clinicians, with limited LUS experience, to acquire and interpret lung ultrasound in critically ill patients.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request. The codes and model weights needed to deploy the RAILUS tool for the study are available at https://github.com/vital-ultrasound/public-lung.
References
Volpicelli G, Mayo P, Rovida S. Focus on ultrasound in intensive care. Intensive Care Med. 2020;46:1258–60.
Zieleskiewicz L, Lopez A, Hraiech S, Baumstarck K, Pastene B, Di Bisceglie M, et al. Bedside POCUS during ward emergencies is associated with improved diagnosis and outcome: an observational, prospective, controlled study. Crit Care. 2021;25:1–12.
Shrestha GS, Weeratunga D, Baker K. Point-of-care lung ultrasound in critically ill patients. Rev Recent Clin Trials. 2018;13:15–26.
Brogi E, Bignami E, Sidoti A, Shawar M, Gargani L, Vetrugno L, et al. Could the use of bedside lung ultrasound reduce the number of chest x-rays in the intensive care unit? Cardiovasc Ultrasound. 2017;15:1–5.
Buonsenso D, De Rose C. Implementation of lung ultrasound in low- to middle-income countries: a new challenge global health? Eur J Pediatr. 2022;181:1–8.
Riaz A, Cambaco O, Ellington LE, Lenahan JL, Munguambe K, Mehmood U, et al. Feasibility, usability and acceptability of paediatric lung ultrasound among healthcare providers and caregivers for the diagnosis of childhood pneumonia in resource-constrained settings: a qualitative study. BMJ Open. 2021;11:e042547.
Gibson PG, Qin L, Puah SH. COVID-19 acute respiratory distress syndrome (ARDS): clinical features and differences from typical pre-COVID-19 ARDS. Med J Aust. 2020;213:54–6.
Graça L, Abreu IG, Santos AS, Graça L, Dias PF, Santos ML. Descriptive Acute Respiratory Distress Syndrome (ARDS) in adults with imported severe Plasmodium falciparum malaria: a 10 year-study in a Portuguese tertiary care hospital. PLoS ONE. 2020;15:e0235437.
Kwizera A, Dünser MW. A global perspective on acute respiratory distress syndrome and the truth about hypoxia in resource-limited settings. Am J Respir Crit Care Med. 2016;193:5–7.
Lichtenstein DA. BLUE-protocol and FALLS-protocol: two applications of lung ultrasound in the critically ill. Chest. 2015;147:1659–70.
Riviello ED, Buregeya E, Twagirumugabe T. Diagnosing acute respiratory distress syndrome in resource limited settings: the Kigali modification of the Berlin definition. Curr Opin Crit Care. 2017;23:18–23.
Diaz-Escobar J, Ordóñez-Guillén NE, Villarreal-Reyes S, Galaviz-Mosqueda A, Kober V, Rivera-Rodriguez R, et al. Deep-learning based detection of COVID-19 using lung ultrasound imagery. PLoS ONE. 2021;16:e0255886.
Liu L, Lei W, Wan X, Liu L, Luo Y, Feng C. Semi-supervised active learning for COVID-19 lung ultrasound multi-symptom classification. In: 2020 IEEE 32nd international conference on tools with artificial intelligence (ICTAI). IEEE; 2020. pp. 1268–1273.
Mento F, Perrone T, Fiengo A, Smargiassi A, Inchingolo R, Soldati G, et al. Deep learning applied to lung ultrasound videos for scoring COVID-19 patients: a multicenter study. J Acoust Soc Am. 2021;149:3626–34.
Roy S, Menapace W, Oei S, Luijten B, Fini E, Saltori C, et al. Deep learning for classification and localization of COVID-19 markers in point-of-care lung ultrasound. IEEE Trans Med Imaging. 2020;39:2676–87.
Arntfield R, Wu D, Tschirhart J, Vanberlo B, Ford A, Ho J, et al. Automation of lung ultrasound interpretation via deep learning for the classification of normal versus abnormal lung parenchyma: a multicenter study. Diagnostics. 2021;11:2049.
Kerdegari H, Phung NTH, McBride A, Pisani L, Van Nguyen H, Duong TB, et al. B-line detection and localization in lung ultrasound videos using spatiotemporal attention. Appl Sci. 2021;11:11697.
Narang A, Bae R, Hong H, Thomas Y, Surette S, Cadieu C, et al. Utility of a deep-learning algorithm to guide novices to acquire echocardiograms for limited diagnostic use. JAMA Cardiol. 2021;6:624–32.
Østvik A, Smistad E, Aase SA, Haugen BO, Lovstakken L. Real-time standard view classification in transthoracic echocardiography using convolutional neural networks. Ultrasound Med Biol. 2019;45:374–84.
Baumgartner CF, Kamnitsas K, Matthew J, Fletcher TP, Smith S, Koch LM, et al. SonoNet: real-time detection and localisation of fetal standard scan planes in freehand ultrasound. IEEE Trans Med Imaging. 2017;36:2204–15.
Tschandl P, Rinner C, Apalla Z, Argenziano G, Codella N, Halpern A, et al. Human-computer collaboration for skin cancer recognition. Nat Med. 2020;26:1229–34.
Gomez A, Zimmer VA, Wheeler G, Toussaint N, Deng S, Wright R, et al. PRETUS: a plug-in based platform for real-time ultrasound imaging research. SoftwareX. 2022;17:100959.
Acknowledgements
We thank all the patients, nurses and clinicians who generously donated their time during the study.
VITAL Consortium
Dang Phuong Thao1, Dang Trung Kien1, Doan Bui Xuan Thy1, Dong Huu Khanh Trinh1,5, Du Hong Duc1, Ronald Geskus1, Ho Bich Hai1, Ho Quang Chanh1, Ho Van Hien1, Huynh Trung Trieu1, Evelyne Kestelyn1, Lam Minh Yen1, Le Dinh Van Khoa1, Le Thanh Phuong1, Le Thuy Thuy Khanh1, Luu Hoai Bao Tran1, Luu Phuoc An1, Angela Mcbride1, Nguyen Lam Vuong1, Nguyen Quang Huy1, Nguyen Than Ha Quyen1, Nguyen Thanh Ngoc1, Nguyen Thi Giang1, Nguyen Thi Diem Trinh1, Nguyen Thi Le Thanh1, Nguyen Thi Phuong Dung1, Nguyen Thi Phuong Thao1, Ninh Thi Thanh Van1, Pham Tieu Kieu1, Phan Nguyen Quoc Khanh1, Phung Khanh Lam1, Phung Tran Huy Nhat1,5, Guy Thwaites1,3, Louise Thwaites1,3, Tran Minh Duc1, Trinh Manh Hung1, Hugo Turner1, Jennifer Ilo Van Nuil1, Vo Tan Hoang1, Vu Ngo Thanh Huyen1, Sophie Yacoub1,3, Cao Thi Tam2, Duong Bich Thuy2, Ha Thi Hai Duong2, Ho Dang Trung Nghia2, Le Buu Chau2, Le Mau Toan2, Le Ngoc Minh Thu2, Le Thi Mai Thao2, Luong Thi Hue Tai2, Nguyen Hoan Phu2, Nguyen Quoc Viet2, Nguyen Thanh Dung2, Nguyen Thanh Nguyen2, Nguyen Thanh Phong2, Nguyen Thi Kim Anh2, Nguyen Van Hao2, Nguyen Van Thanh Duoc2, Pham Kieu Nguyet Oanh2, Phan Thi Hong Van2, Phan Tu Qui2, Phan Vinh Tho2, Truong Thi Phuong Thao2, Natasha Ali3, David Clifton3, Mike English3, Jannis Hagenah3, Ping Lu3, Jacob McKnight3, Chris Paton3, Tingting Zhu3, Pantelis Georgiou4, Bernard Hernandez Perez4, Kerri Hill-Cawthorne4, Alison Holmes4, Stefan Karolcik4, Damien Ming4, Nicolas Moser4, Jesus Rodriguez Manzano4, Liane Canas5, Alberto Gomez5, Hamideh Kerdegari5, Andrew King5, Marc Modat5, Reza Razavi5, Miguel Xochicale5, Walter Karlen6, Linda Denehy7, Thomas Rollinson7, Luigi Pisani8, Marcus Schultz8.
1Oxford University Clinical Research Unit; 2Hospital for Tropical Diseases, Ho Chi Minh City; 3University of Oxford; 4Imperial College London; 5King’s College London; 6University of Ulm; 7The University of Melbourne;8Mahidol Oxford Tropical Medicine Research Unit.
Funding
This work was supported by the Wellcome Trust under grant 217650/Z/19/Z.
Author information
Authors and Affiliations
Consortia
Contributions
P.T.H.N., A.G., L.T., S.Y., A.K., L.P., R.Z. and N.V.H. conceptualised the study. Implementation was by P.T.H.N., L.T.P., L.N.M.T., H.T.H.D., D.B.T., P.V.T. with support from H.K., L.P., M.S., N.V.V.C. and R.R., A.M. Statistical analysis was performed by P.T.H.N. and A.G. Initial manuscript drafting was by P.T.H.N., A.G., L.T. with support from S.Y, L.P. and M.S.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Oxford Tropical Research Ethics Committee (OxTREC) and the HTD Institutional Review Boards.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
: . Model development and evaluation, description of RAILUS software and usability questionnaire.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Nhat, P.T.H., Van Hao, N., Tho, P.V. et al. Clinical benefit of AI-assisted lung ultrasound in a resource-limited intensive care unit. Crit Care 27, 257 (2023). https://doi.org/10.1186/s13054-023-04548-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13054-023-04548-w