
Abstract
Background
Epithelial ovarian cancer is one of the most severe public health threats in women. Since it is still challenging to screen in early stages, identification of core genes that play an essential role in epithelial ovarian cancer initiation and progression is of vital importance.
Results
Seven gene expression datasets (GSE6008, GSE18520, GSE26712, GSE27651, GSE29450, GSE36668, and GSE52037) containing 396 ovarian cancer samples and 54 healthy control samples were analyzed to identify the significant differentially expressed genes (DEGs). We identified 563 DEGs, including 245 upregulated and 318 downregulated genes. Enrichment analysis based on the gene ontology (GO) functions and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways showed that the upregulated genes were significantly enriched in cell division, cell cycle, tight junction, and oocyte meiosis, while the downregulated genes were associated with response to endogenous stimuli, complement and coagulation cascades, the cGMP-PKG signaling pathway, and serotonergic synapse. Two significant modules were identified from a protein-protein interaction network by using the Molecular Complex Detection (MCODE) software. Moreover, 12 hub genes with degree centrality more than 29 were selected from the protein-protein interaction network, and module analysis illustrated that these 12 hub genes belong to module 1. Furthermore, Kaplan-Meier analysis for overall survival indicated that 9 of these hub genes was correlated with poor prognosis of epithelial ovarian cancer patients.
Conclusion
The present study systematically validates the results of previous studies and fills the gap regarding a large-scale meta-analysis in the field of epithelial ovarian cancer. Furthermore, hub genes that could be used as a novel biomarkers to facilitate early diagnosis and therapeutic approaches are evaluated, providing compelling evidence for future genomic-based individualized treatment of epithelial ovarian cancer.
Similar content being viewed by others


Introduction
Ovarian cancer is the most lethal gynecological cancer in the world and a general term which contains some cancers derived from various tissues [1]. Epithelial ovarian cancer is the most common and representative histological types in primary ovarian cancer and is the primary cause of deaths in female cancer patients in North America and over 100,000 deaths every year worldwide [2]. High-grade serous carcinoma (HGSC) is the most lethal subtype in the epithelial ovarian cancer, and most of them are diagnosed in an advanced stage [3]. The standard treatment for ovarian cancer is maximal cytoreductive surgery and platinum-based chemotherapy [4]. Although ovarian cancer actively responds to the initial anticancer therapy, nearly 75% of patients may relapse within two years and cannot be treated with the available chemotherapy drugs [5, 6]. Meanwhile, metastasis within the peritoneal cavity and resistance to chemotherapy are the leading causes of the high mortality rate associated with ovarian cancer, because this cancer is often diagnosed in late clinical stages as what has been mentioned above [5]. Thus, identifying new targets for treatment and seeking effective chemotherapy drugs are crucial for overcoming drug resistance in advanced ovarian cancer [7].
Thus far, many genetic factors, such as BRCA1, BRCA2, P53 (TP53), KRAS, PIK3CA, CTNNB1, and PTEN, have been correlated with ovarian cancer [8]. In recent years, many studies have shown promise for gene-targeted therapies in ovarian cancer [9,10,11]. The poly-ADP-ribose polymerase (PARP) inhibitor olaparib, a targeted therapeutic drug approved by the Food and Drug Administration, is used to treat ovarian cancer patients with BRCA1 and BRCA2 mutations. Olaparib has also been used as maintenance therapy for patients with platinum-sensitive recurrent BRCA-mutated ovarian cancer [12]. Therefore, gene-targeted therapies provide a new possibility for the personalized treatment of ovarian cancer patients.
However, the lack of large-scale studies for the identification of differentially expressed genes (DEGs) in ovarian cancer limits the reliability of previous results and makes it difficult to screen potential targets. DNA microarray analysis is a systematic and global approach to analyze genomic expression profiles and physiological mechanisms in diseases [13, 14]. High-throughput microarray experiments have been used to analyze gene expression patterns and identify potential target genes in ovarian cancer [15].
To fill the gap regarding the identification of DEGs in ovarian cancer, we performed this meta-analysis to identify DEGs between ovarian cancer and healthy control tissues and aimed to provide a powerful tool to investigate microarray datasets by integrating data from multiple studies. An important advantage of this large-scale analysis lies in the reduction of discrepancies among different study conditions; additionally, this analysis combines the results from previous studies to assess an existing problem from a novel perspective [16]. it is worth noting that although ovarian cancer is known as a series of different molecular and histological diseases [17], we aim to uncover those common genes across different molecular subtypes of epithelial ovarian cancer. Genes discovered in meta-analyses generally overlap with genes identified in various studies, indicating increased reliability [18]. The present meta-analysis aimed to identify DEGs between ovarian tissues and control tissues. In addition, we attempted to identify potential core genes associated with epithelial ovarian cancer and to investigate some possible related mechanisms.
Materials and methods
Selection of microarray datasets for the meta-analysis
According to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines published in 2009, we performed a comprehensive search of Gene Expression Omnibus (GEO) databases from the National Center for Biotechnology Information (NCBI, http://www.ncbi.nlm.nih.gov/geo/). The keywords “ovarian neoplasms” and “ovarian cancer” were used in our search. The datasets were required to meet the following criteria: (1) the samples had to be from the Affymetrix Human Genome U133A Array platform or Affymetrix Human Genome U133 Plus 2.0 Array platform; (2) the study organisms had to be Homo sapiens; (3) the datasets had to contain ovarian cancer and normal ovarian tissue samples; and (4) the number of normal ovarian tissue samples had to be greater than three. Studies were excluded if (1) they were cell line studies; (2) they involved dual-channel arrays; (3) they did not have literature traceability; (4) they were DNA methylation studies; (5) they were miRNA-based studies; and (6) they lacked cases and controls. The data from the original studies were selected by two independent analysts. Any disagreement between the two analysts was solved by consultation with a third analyst.
Meta-analysis of multiple microarray datasets
From the GEO database, we downloaded Ovarian files (.CEL) of microarray datasets that met the inclusion criteria. A total of 13,294 common genes were obtained by integrating the genes from seven datasets using the R statistical software (http://www.r-project.org/). Then, we performed a meta-analysis of gene expression profiles of the 13,294 common genes according to combined p-values and Z scores using R statistical software. Combined p-values (pval_test) included the test-statistic and p-value. The meta-analysis of common genes was conducted by the MAMA, mataMA, affyPLM, CLL and RankProd packages. In performing two meta-analysis with R statistical software, combined p-values method (where the threshold was an absolute value more than 5) and Z-scored meta-analysis (where the threshold was an absolute value more than 7) were used as the cutoff criteria, and a list of DEGs (up- or downregulated) was identified.
GO annotations and KEGG pathway enrichment analysis
Identifying the biological characteristics of DEGs is vital. Based on the results of the meta-analysis, the most significant DEGs were evaluated by enrichment analyses. Then, gene ontology (GO) annotations and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses were conducted to identify the most significant DEGs using the WEB-based GEne SeT AnaLysis Toolkit (http://www.webgestalt.org/option.php) with a significance threshold of false-discovery rate (FDR) less than 0.1.
PPI network construction
The Search Tool for the Retrieval of Interacting Genes (STRING) database (http://string-db.org) displays information on protein-protein interactions (PPIs) [19]. We charted a PPI network of DEGs using STRING with confidence score more than 0.7 as the significance cutoff criterion to acquire an in-depth understanding and predict the cellular functions and biological behaviors of the identified DEGs. Further, PPI networks were visualized utilizing the Cytoscape software [19].
Selection of hub genes and modules
CentiScaPe 2.1 was used to calculate the degree, closeness, and betweenness of the PPI network. The degree of a node is the average number of edges (interactions) incident on the node [20]. According to the degree of a node, we identified the hub genes. The Molecular Complex Detection (MCODE) software was employed to select the most important clustering modules of PPI networks in Cytoscape with degree cutoff = 2, node score cutoff = 0.2, k-core = 2, and max. Depth = 100. Furthermore, KEGG pathway enrichment analysis was conducted for DEGs in every module using the WEB-based GEne SeT AnaLysis Toolkit with a significance threshold of FDR less than 0.1.
Survival analysis using hub genes
The Kaplan-Meier plotter (KM plotter, http://kmplot.com/analysis/) was used to display the relevance of the identified genes regarding patient survival using 1816 ovarian cancer samples. Gene expression data and relapse-free and overall survival (OS) information were downloaded from the GEO (Affymetrix microarrays only), the European Genome-phenome Archive (EGA) and the Cancer Genome Atlas (TCGA) databases. Hazard ratios (HRs) with 95% confidence intervals and log-rank p-value were calculated and displayed on the plot.
Results
Identification of upregulated or downregulated DEGs through the meta-analysis
According to the inclusion criteria, the following seven GEO datasets from the NCBI were obtained: GSE6008, GSE18520, GSE26712, GSE27651, GSE29450, GSE36668, and GSE52037 (see “Materials and Methods”, Fig. 1). A total of 396 ovarian cancer samples and 54 normal ovarian tissue samples were analyzed. The GEO Platform Files (GPLs) from the seven datasets were obtained using Affymetrix gene chips (Table 1).

Selection procession of microarray datasets for meta-analysis
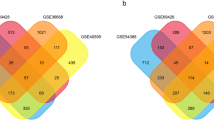
We identified common genes across all datasets and performed a meta-analysis of multiple gene expression profiles using two platforms according to combined p-values and Z scores. According to the combined p-values (the threshold was 5) and Z scores (the limit was 7), 563 DEGs including 245 upregulated and 318 downregulated genes were identified (Additional file 1: Table S1 and Additional file 2: Table S2). The overlapping DEGs based on the combined p-values and Z scores are shown in Fig. 2.

The 563 overlapping DEGs based on |pval_test| < 5 and |Z| > 7 were detected using Venny 2.1.0
GO term and KEGG pathway enrichment analyses
To further investigate the functions of the DEGs, we separately classified the upregulated and downregulated genes into functional GO and KEGG categories and then performed pathway enrichment analyses with a significance threshold less than 0.05. The top five terms enriched in each category were selected according to the p-value.
For biological processes, GO analysis results showed that the upregulated DEGs were separately enriched in ‘cell division’ (GO:0051301), ‘cell-cell junction’ (GO:0005911) and ‘enzyme binding’ (GO:0019899), whereas and the downregulated DEGs were enriched in ‘response to endogenous stimulus’ (GO:0009719), ‘extracellular space’ (GO:0005615) and ‘RNA polymerase II transcription factor activity, and ‘sequence-specific DNA binding’ (GO:0000981, Table 2).
The most enriched KEGG pathway term for the upregulated DEGs was ‘cell cycle’ (KEGG:04110) and for the downregulated DEGs was ‘complement and coagulation cascades’ (KEGG:04610, Table 3).
Hub gene and module screening from the PPI network
First, we determined the PPI network of the DEGs. The PPI network consisted of 275 nodes and 770 edges with a confidence score of more than 0.7 based on the STRING database. The top 12 hubs with degree centrality more than 29 were screened from the PPI network as hub genes. These hub genes included Cyclin-dependent kinase 1 (CDK1), DNA topoisomerase 2-alpha (TOP2A), cell-division cycle protein 2 (CDC20), G2/mitotic-specific cyclin-B2 (CCNB2), baculoviral inhibitor of apoptosis repeat-containing 5 (BIRC5), ubiquitin-conjugating enzyme E2 C2 (UBE2C), budding uninhibited by benzimidazoles 1 (BUB1), non-SMC condensin I complex subunit G (NCAPG), Ribonucleoside-diphosphate reductase subunit M2 (RRM2), Kinesin-like protein (KIF2C), centromere protein A (CENPA), and maternal embryonic leucine zipper kinase (MELK).
Moreover, the top 2 significant modules were obtained from the PPI network of DEGs using the MCODE software (Fig. 3). Then, KEGG pathway enrichment analyses of the genes in these two modules were performed using the WEB-based GEne SeT AnaLysis Toolkit (Additional file 3: Table S3). The results demonstrated that the genes in module 1 were mainly associated with cell cycle, oocyte meiosis and the p53 signaling pathway, while the genes in module 2 were primarily in tight junction proteins, leukocyte transendo thelial migration, hepatitis C, and cell adhesion molecules (CAMs). The top 12 hub genes belonged to module 1 and confirmed the critical pathways associated with ovarian cancer. In conclusion, these essential genes provide new ideas for the treatment of ovarian cancer.

2 modules obtained from PPI network of DEGs using the MCODE software. The top 12 hub genes were all in the module 1
KM plots for hub genes
The prognostic information of the 12 hub genes is freely available in http://kmplot.com/analysis/. The results demonstrated that the expression of CDK1 (203213_at, HR 1.27 (1.11–1.46), p = 6 × 10− 4), TOP2A (201291_s_at, HR 1.27 (1.11–1.44), p = 3.9 × 10− 4), CCNB2 (202705_at, HR 1.15 (1.22–1.81), p = 0.049), UBE2C (202954_at, HR 1.28 (1.12–1.47), p = 3.8 × 10− 4), BUB1 (209642_at, HR 1.26 (1.08–1.46), p = 2.9 × 10− 3), NCAPG (218663_at, HR 1.26 (1.09–1.46), p = 1.9 × 10− 3), RRM2 (201890_at, HR 1.17 (1.03–1.34), p = 1.7 × 10− 2), KIF2C (209408_at, HR 1.15 (1.01–1.32), p = 3.8 × 10− 2) and CENPA (204962_s_at, HR 1.23 (1.08–1.41), p = 2.4 × 10− 3) was negatively associated with the OS of epithelial ovarian cancer patients (Fig. 4 and Additional file 4: Figure S1).

Top 3 genes (CDK1, TOP2A and UBE2C) significantly correlates with poor OS of ovarian cancer
Discussion
The problematic diagnosis in an early stage and recurrence and resistance to current chemotherapeutic agents are the leading causes of high mortality in ovarian cancer based on data from The Surveillance, Epidemiology, and End Results (SEER) Program of the National Cancer Institute [21]. Therefore, the development of novel therapies for ovarian cancer is of great urgency. Previous research has proven that ovarian cancer is caused by the activation of oncogenes and the inactivation of cancer suppressor gene [22]. With continued advancements in high-throughput technologies, some genetic alterations associated with ovarian cancer, such as specific mutations in KRAS, loss-of-function mutations in PTEN, mutations in TP53, modifications in BRCA1/2, and changes in homologous recombination genes, have been uncovered [23]. Although a significant amount of data were produced by microarray studies, the sample sizes of most studies are small and may affect the identification of DEGs. However, meta-analysis of multiple microarray datasets makes the identification of DEGs more reliable by increasing the sample size.
In the present study, we performed a meta-analysis to determine the DEGs between ovarian cancer and normal ovarian tissues. We identified 563 DEGs, including 245 upregulated and 318 downregulated DEGs, in ovarian tissues by combining p-values (cutoff value of 5) and Z scores (cutoff value of 7). We classified the DEGs into functional categories based on their GO functions and KEGG pathways. Furthermore, we screened the following top 12 hub nodes with degree centrality more than 29 from the PPI network as hub genes: CDK1, TOP2A, CDC20, CCNB2, BIRC5, UBE2C, BUB1, NCAPG, RRM2, KIF2C, CENPA, and MELK. Additionally, we obtained two top significant modules from PPI networks of DEGs using MCODE analysis. Genes in module 1 were mainly associated with cell cycle, oocyte meiosis and the p53 signaling pathway, while genes in module 2 were primarily enriched in tight junction proteins, leukocyte transendothelial migration, hepatitis C, and CAMs.
Among the top 12 hub genes, nine hub genes were associated with poor OS in epithelial ovarian cancer patients. Based on GO functional analysis, KEGG pathway analysis, and survival analysis, we found that CDK1, TOP2A, and UBE2C might be the core genes contributing to the development of epithelial ovarian cancer at the molecular level.
CDK1 plays a vital role in the regulation of the cell cycle by modulating the centrosome. CDK1 not only promotes G2-M transition but also regulates G1 progression and G1-S transition by binding with multiple interphase cyclins [24, 25] In ovarian cancer, the expression of CDK1 is significantly associated with survival status, histological grade, FIGO stage, lymph node metastasis, and metastasis in epithelial ovarian cancer patients [26].
TOP2A is a nuclear enzyme involved involved in cell division and the cell cycle. TOP2A controls topological states of DNA by transiently breaking and subsequently rejoining of DNA strands [27]. Additionally, TOP2A is a direct molecular target of topoisomerase inhibitor, and its upregulation has been reported in several cancers including lung, nasopharyngeal, esophageal, gallbladder, hepatocellular, colorectal, breast, endometrial, pancreatic and ovarian cancer [28,29,30,31].
UBE2C, an essential factor of the anaphase-promoting complex/cyclosome (APC/C), is required for the destruction of mitotic cyclins and cell cycle progression [32]. The N-terminal extension of UBE2C contributes to the regulation of APC/C activity for substrate selection and checkpoint control [33]. UBE2C, the exclusive partner of APC/C, participates in the degradation of the APC/C target protein family by initiating the formation of a Lys11-linked ubiquitin chain. Thus, UBE2C plays a vital role in the destruction of mitotic cyclins and other mitosis-related substrates. During early mitosis, the APC is activated through cyclin B/Cdk1-dependent phosphorylation and binding of its activator CDC20. During metaphase, UBE2C degrades securin and cyclin B by APC/CCDC20 to promote progression to anaphase [34]. UBE2C is significantly upregulated in several types of cancer including bladder, breast, brain, cervical, esophageal, colorectal, liver, lung, nasopharyngeal, prostate (late-stage), pancreatic, thyroid, stomach, and ovarian cancer [33]. UBE2C is associated with tumor progression. I. van Ree et al. identified UBE2C as a prominent proto-oncogene that contributes to whole chromosome instability and tumor formation over a wide range of overexpression levels [35].
In our study, in addition to UBE2C upregulation, CDC20, CDK1, and CCNB2 are overexpressed. Combined with the above results, it is logic to assume that the interaction among UBE2C, CDC20, CDK1, and CCNB2 may play a vital role in the formation and development of ovarian cancer. Overexpression of UBE2C was associated with poor OS for ovarian cancer patients, and thus UBE2C might be a promising prognostic molecular biomarker and therapeutic target for ovarian cancer. It is worth to emphasize that though a series of distinct molecular and histologic subtypes of ovarian cancer exists and each subtype has different tumor microenvironment. The present research mainly focuses on those common pathways of epithelial ovarian cancer. Yet we have analyzed the corresponding gene expression data acquired from GSE9891 and the results shows that 11 out of 12 hub genes (expression data of CDK1 cannot be found in the datasets GSE9891) are significantly up-regulated (Additional file 5: Figure S2, Additional file 6: Figure S3, Additional file 7: Figure S4, Additional file 8: Figure S5, Additional file 9: Figure S6, Additional file 10: Figure S7, Additional file 11: Figure S8, Additional file 12: Figure S9, Additional file 13: Figure S10, Additional file 14: Figure S11 and Additional file 15: S12, Additional file 16: Table S4) in all of the molecular subtypes (differential, immunoreacted, proliferation and mesenchymal) comparing to control group. Subsequent researches will be conducted to investigate the role each hub gene played in each subtype of ovarian cancer,
Besides, we consider the protein expression of these hub genes might be instructive to the further study. The protein expression data of hub genes is acquired from the Human Protein Atlas for evaluation. The protein expressions of 5 hub genes (CDK1, TOP2A, CDC20, NCAPG, and MELK) are significantly up-regulated in ovarian cancer compared to normal tissues (Additional file 17: Table S5.). Also, we have done a chi-square analysis to explore the relationship between the expression of 12 hub genes and the metastasis of ovarian cancer. The results show none of these genes has connections to the cancer metastasis (P > 0.05). Overall, the present study was designed to identify DEGs through integrated bioinformatics analysis to find potential biomarkers and predict the development and prognosis of ovarian cancer. However, to obtain more accurate correlation results, we need to performed a series of validation experiments. In conclusion, this study provides robust evidence for future genomic-based individualized treatment of ovarian cancer.
Conclusion
Until now, a large-scale meta-analysis identifying DEGs was absent from the ovarian cancer literature. Our study systematically validated previous studies and filled the gap regarding a large-scale meta-analysis in the field of ovarian cancer. Moreover, our meta-analysis identified three specific genes, namely, CDK1, TOP2A and UBE2C, which may be potential targets of ovarian cancer. Thus, this study provides convincing evidence for future genomic individualized treatment of epithelial ovarian cancer.
Abbreviations
- APC/C:
-
Anaphase-promoting complex/cyclosome
- BIRC5:
-
Baculoviral inhibitor of apoptosis repeat-containing 5
- BUB1:
-
Budding uninhibited by benzimidazoles 1
- CAMs:
-
Cell adhesion molecules
- CCNB2:
-
G2/mitotic-specific cyclin-B2
- CDC20:
-
Cell-division cycle protein 2
- CDK1:
-
Cyclin-dependent kinase 1
- CENPA:
-
Centromere protein A
- DEGs:
-
Differentially expressed genes
- EGA:
-
The European Genome-phenome Archive
- FDR:
-
False-discovery rate
- GEO:
-
Gene Expression Omnibus
- GO:
-
Gene ontology
- GPLs:
-
The GEO Platform Files
- HGSC:
-
High-grade serous carcinoma
- HRs:
-
Hazard ratios
- KEGG:
-
Kyoto Encyclopedia of Genes and Genomes
- KIF2C:
-
Kinesin-like protein
- KM plotter:
-
Kaplan-Meier plotter
- MCODE:
-
Molecular Complex Detection
- MELK:
-
Maternal embryonic leucine zipper kinase
- NCAPG:
-
Non-SMC condensin I complex subunit G
- NCBI:
-
National Center for Biotechnology Information
- OS:
-
Overall survival
- PARP:
-
Poly-ADP-ribose polymerase
- PPIs:
-
Protein-protein interactions
- PRISMA:
-
Systematic Reviews and Meta-Analyses
- RRM2:
-
Ribonucleoside-diphosphate reductase subunit M2
- SEER:
-
The Surveillance, Epidemiology, and End Results
- TCGA:
-
The Cancer Genome Atlas
- TOP2A:
-
DNA topoisomerase 2-alpha
- UBE2C:
-
Ubiquitin-conjugating enzyme E2 C2
References
Desai A, Xu J, Aysola K, et al. Epithelial ovarian cancer: an overview. World J Transl Med. 2014;3(1):1-8.
Ferlay J, Soerjomataram I, Dikshit R, et al. Cancer incidence and mortality worldwide: sources, methods and major patterns in GLOBOCAN 2012. Int J Cancer. 2015;136(5):E359–86.
Bast RC Jr, Hennessy B, Mills GB. The biology of ovarian cancer: new opportunities for translation. Nat Rev Cancer. 2009;9(6):415.
Cortez AJ, Tudrej P, Kujawa KA, Lisowska KM. Advances in ovarian cancer therapy. Cancer Chemother Pharmacol. 2018;81:17–38.
Banno K, Yanokura M, Iida M, et al. Application of MicroRNA in diagnosis and treatment of ovarian cancer. Biomed Res Int. 2014;2014(3):232817.
Agarwal R, Kaye SB. Ovarian cancer: Strategies for overcoming resistance to chemotherapy. Nat Rev Cancer. 2003;3:502–16.
Norouzi-Barough L, Sarookhani MR, Sharifi M, Moghbelinejad S, Jangjoo S, Salehi R. Molecular mechanisms of drug resistance in ovarian cancer. J Cell Physiol. 2018;233:4546–62.
Lech A, Daneva T, Pashova S, Gagov H, Crayton R, Kukwa W, et al. Ovarian cancer as a genetic disease. Front Biosci. 2013;18:543–63.
An J, Lv W, Zhang Y. LncRNA NEATI contributes to paclitaxel resistance of ovarian cancer cells by regulating ZEBI expression via miR-194. Onco Targets Ther. 2017;10:5377–90.
Morgan RD, Clamp AR, Evans DGR, Edmondson RJ, Jayson GC. PARP inhibitors in platinum-sensitive high-grade serous ovarian cancer. Cancer Chemother Pharmacol. 2018;81:647–58.
Vetter MH, Hays JL. Use of targeted therapeutics in epithelial ovarian cancer: a review of current literature and future directions. Clin Ther. 2018;40:361–71.
Johnson N, Liao JB. Novel therapeutics for ovarian cancer: the 11th Biennial Rivkin Center Ovarian cancer Research Symposium. Int J Gynecol Cancer. 2017;27(9S):S14–9.
Spies M, Dasu MRK, Svrakic N, Nesic O, Barrow RE, Perez-Polo JR, et al. Gene expression analysis in burn wounds of rats. Am J Physiol Regul Integr Comp Physiol. 2002;283(4):R918–30.
Guo QM. DNA microarray and cancer. Curr Opin Oncol. 2003;15:36–43.
Cheung HW, Cowley GS, Weir BA, Boehm JS, Rusin S, Scott JA, et al. Systematic investigation of genetic vulnerabilities across cancer cell lines reveals lineage-specific dependencies in ovarian cancer. Proc Natl Acad Sci. 2011;108(30):12372–7.
Chee M, Yang R, Hubbell E, et al. Accessing genetic information with high-density DNA arrays. Science. 1996;274(5287):610–4.
Vaughan S, Coward JI, Bast RC Jr, et al. Rethinking ovarian cancer: recommendations for improving outcomes. Nat Rev Cancer. 2011;11(10):719.
Hong F, Breitling R, McEntee CW, Wittner BS, Nemhauser JL, Chory J. RankProd: a bioconductor package for detecting differentially expressed genes in meta-analysis. Bioinformatics. 2006;22(22):2825–7.
Szklarczyk D, Franceschini A, Wyder S, Forslund K, Heller D, Huerta-Cepas J, et al. STRING v10: protein-protein interaction networks, integrated over the tree of life. Nucleic Acids Res. 2015;43(D1):D447–52.
Scardoni G, Tosadori G, Faizan M, et al. Biological network analysis with CentiScaPe: centralities and experimental dataset integration. F1000Res. 2015;139(3):1-9.
Cronin KA, Lake AJ, Scott S, Sherman RL, Noone AM, Howlader N, et al. Annual report to the nation on the Status of Cancer, part I: National cancer statistics. Cancer. 2018;124(13):2785-800.
Di Men C, Liu QN, Ren Q. A prognostic 11 genes expression model for ovarian cancer. J Cell Biochem. 2018;119(2):1971–8.
Previs RA, Sood AK, Mills GB, Westin SN. The rise of genomic profiling in ovarian cancer. Expert Rev Mol Diagn. 2016;16:1337–51.
Lindqvist A, Rodríguez-Bravo V, Medema RH. The decision to enter mitosis: feedback and redundancy in the mitotic entry network. J Cell Biol. 2009;185:193–202.
Diril MK, Ratnacaram CK, Padmakumar VC, Du T, Wasser M, Coppola V, et al. Cyclin-dependent kinase 1 (Cdk1) is essential for cell division and suppression of DNA re-replication but not for liver regeneration. Proc Natl Acad Sci. 2012;109(10):3826–31.
Xi Q, Huang M, Wang Y, Zhong J, Liu R, Xu G, et al. The expression of CDK1 is associated with proliferation and can be a prognostic factor in epithelial ovarian cancer. Tumor Biol. 2015;36(7):4939–48.
Md AS, Md S, Mazharol HM, et al. Inhibition of DNA topoisomerase type IIα(TOP2A) by mitoxantrone and its halogenated derivatives: a combined density functional and molecular docking study. Biomed Res Int. 2016;2016(5):12.
Zhou Z, Liu S, Zhang M, Zhou R, Liu J, Chang Y, et al. Overexpression of topoisomerase 2-alpha confers a poor prognosis i pancreatic adenocarcinoma identified by co-expression analysis. Dig Dis Sci. 2017;62(10):2790–800.
Ito F, Furukawa N, Nakai T. Evaluation of TOP2A as a predictive marker for endometrial cancer with taxane-containing adjuvant chemotherapy. Int J Gynecol Cancer. 2016;26(2):325–30.
Erriquez J, Becco P, Olivero M, Ponzone R, Maggiorotto F, Ferrero A, et al. TOP2A gene copy gain predicts response of epithelial ovarian cancers to pegylated liposomal doxorubicin. Gynecol Oncol. 2015;138(3):627–33.
Chen T, Sun Y, Ji P, Kopetz S, Zhang W. Topoisomerase IIalpha in chromosome instability and personalized cancer therapy. Oncogene. 2015;34(31):4019–31.
Yamaguchi M, VanderLinden R, Weissmann F, Qiao R, Dube P, Brown NG, et al. Cryo-EM of mitotic checkpoint complex-bound APC/C reveals reciprocal and conformational regulation of ubiquitin ligation. Mol Cell. 2016;63(4):593–607.
Xie C, Powell C, Yao M, et al. Ubiquitin-conjugating enzyme E2C: a potential cancer biomarker. Int J Biochem Cell Biol. 2014;47:113–7.
Rape M, Reddy SK, Kirschner MW. The processivity of multiubiquitination by the APC determines the order of substrate degradation. Cell. 2006;124(1):89–103.
Van Ree JH, Jeganathan KB, Malureanu L, Van Deursen JM. Overexpression of the E2 ubiquitin-conjugating enzyme UbcH10 causes chromosome missegregation and tumor formation. J Cell Biol. 2010;188(1):83–100.
Acknowledgements
Thanks to Prof. Deng Libin for providing the technical help and writing assistance.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. #81760504 to F Fu) and the Natural Science Foundation of Jiangxi Province (Grant No. #20171BAB205109 to X. Tang).
Availability of data and materials
All data generated or analyzed during this study are included in this published article and its additional file.
Author information
Authors and Affiliations
Contributions
FF and XT conceived of the concept. WLi, ZL and BL made substantial contributions to data collection and interpretation of results; WLou, SC, XZ, XT and LL analyzed the data; ZL and BL wrote the manuscript. WLi assisted with manuscript preparation. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Table S1. Information of 245 upregulated DEGs. (XLSX 49 kb)
Additional file 2:
Table S2. Information of 318 downregulated DEGs. (XLSX 59 kb)
Additional file 3:
Table S3. KEGG pathway enrichment analyses of the genes in the two modules using the WEB-based GEne SeT AnaLysis Toolkit. (XLSX 13 kb)
Additional file 4:
Figure S1. The Kaplan-Meier plots of 9 hub gene selected from PPI network are associated with poor prognosis of ovarian cancer patients. (TIF 893 kb)
Additional file 5:
Figure S2. The difference of BIRC5 expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 6:
Figure S3. The difference of BUB1 expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 7:
Figure S4. The difference of CCNB2 expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 4 kb)
Additional file 8:
Figure S5. The difference of CDC20 expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 9:
Figure S6. The difference of CENPA expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 10:
Figure S7. The difference of KIF2C expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 11:
Figure S8. The difference of MELK expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 4 kb)
Additional file 12:
Figure S9. The difference of NCAPG expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 13:
Figure S10. The difference of RRM2 expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 14:
Figure S11. The difference of TOP2A expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 15:
Figure S12. The difference of UBE2C expression level in four molecular subtypes of epithelial ovarian cancer to control group. (PDF 5 kb)
Additional file 16:
Table S4. The difference of 11 hub genes expression changes in four molecular subtypes of epithelial ovarian cancer to normal tissues. (XLSX 9 kb)
Additional file 17:
Table S5. The protein expression changes of hub genes in the ovarian cancer. (XLSX 9 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Li, W., Liu, Z., Liang, B. et al. Identification of core genes in ovarian cancer by an integrative meta-analysis. J Ovarian Res 11, 94 (2018). https://doi.org/10.1186/s13048-018-0467-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13048-018-0467-z