
Abstract
Background
Health systems worldwide struggle to identify, adopt, and implement in a timely and system-wide manner the best—evidence-informed—policy-level practices. Yet, there is still only limited evidence about individual and institutional best practices for fostering the use of scientific evidence in policy-making processes The present project is the first national-level attempt to (1) map and structurally analyze—quantitatively—health-relevant policy-making networks that connect evidence production, synthesis, interpretation, and use; (2) qualitatively investigate the interaction patterns of a subsample of actors with high centrality metrics within these networks to develop an in-depth understanding of evidence circulation processes; and (3) combine these findings in order to assess a policy network’s “absorptive capacity” regarding scientific evidence and integrate them into a conceptually sound and empirically grounded framework.
Methods
The project is divided into two research components. The first component is based on quantitative analysis of ties (relationships) that link nodes (participants) in a network. Network data will be collected through a multi-step snowball sampling strategy. Data will be analyzed structurally using social network mapping and analysis methods. The second component is based on qualitative interviews with a subsample of the Web survey participants having central, bridging, or atypical positions in the network. Interviews will focus on the process through which evidence circulates and enters practice. Results from both components will then be integrated through an assessment of the network’s and subnetwork’s effectiveness in identifying, capturing, interpreting, sharing, reframing, and recodifying scientific evidence in policy-making processes.
Discussion
Knowledge developed from this project has the potential both to strengthen the scientific understanding of how policy-level knowledge transfer and exchange functions and to provide significantly improved advice on how to ensure evidence plays a more prominent role in public policies.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background
New conceptual and methodological developments in the broad field of knowledge transfer and exchange suggest significant improvement in policies and practices could be achieved by shifting the focus of analysis from discrete interventions to broader information exchange networks. This proposal aims to map and analyze health-relevant information exchange networks at the national level in Canada. It will lead to concrete best practice recommendations with the potential to improve the integration of scientific evidence into health-relevant policies and practices and ultimately have a positive impact on the health of Canadians.
Significance and objectives of the research
Health systems worldwide struggle to identify, adopt, and implement in a timely and system-wide manner the best—evidence-informed—policies and practices. This struggle, in turn, has significant implications for resources and population health [1,2,3].
A large body of scholarship has focused on developing interventions to strengthen the influence of scientific evidence on decisions and policies. However, despite significant energy and investments, efforts to do so have proved trickier than initially anticipated [3, 4]. The complexity of policy-levelFootnote 1 knowledge transfer and exchange (KTE) interventions has thwarted attempts to produce strong instrumental evidence on the “how-to” [3, 5, 6]. Part of the problem is rooted in the fact that much of the KTE literature focuses on discrete “interventions.” In practice, policy-making processes take place in complex networks where actors are interdependent and where KTE is neither linear nor discrete. Further inquiry into the composition and functioning of the channels through which information informs practices and decisions is crucial to identify best practices for fostering use of scientific evidence [3, 7,8,9,10,11,12,13,14,15,16].
This project’s main objective is thus to understand how scientific evidence interconnects with health-relevant policy-making processes. Operationally, this will be achieved by focusing on the composition and structure of complex policy networks and then analyzing the processes of information circulation and absorption within these networks. We define health-relevant policies as encompassing both healthcare policies (i.e., policies about healthcare services financing or delivery) and healthy public policies (i.e., intersectoral policies with significant implications for population health and health equity).
More specifically, this project adopts a sequential mixed-methods approach, structured in two components with three specific objectives:
-
1.
To map and structurally analyze—quantitatively—health-relevant policy-making networks that connect evidence production, synthesis, interpretation, and use (component A).
-
2.
To select a subsample of actors with high centrality metrics or interesting structural positions within these networks and qualitatively investigate their communication and interaction patterns, to develop an in-depth understanding of evidence circulation processes and related strategies (component B).
-
3.
To combine these findings in order to assess a policy network’s absorptive capacity regarding scientific evidence and to integrate them into a conceptually sound and empirically grounded framework (integration of components A and B).
Conceptual framework
Conceptually, this project is at the intersection of three fields of research. The first—usually referred to in CanadaFootnote 2 as KTE—is focused on analysis and improvement of the bidirectional linkages between scientific evidence production and policy or practice. The second field—policy-making analysis—is anchored in political science and public administration and is focused on understanding structures and processes that influence public policy development, adoption, and implementation, conceptualized as dependent variables. The third field—network analysis—is transdisciplinary, often very methodologically driven, and focused on network structures as independent variables explaining a diverse range of phenomena.
Although there is a considerable body of literature in each of these fields on the influence and use of scientific evidence in policy formulation and making, their intersection has only been partially explored (e.g., reviews about KTE and networks [17]; policy-making and networks [18,19,20]; KTE and policy-making [4, 5]). Few, if any, studies have tapped into cross-learning from all three. However, developments in those three fields support a redefinition of how policy-related KTE interventions should be conceptualized. More realistic conceptualizations should take into account that information exchanges in policy-making processes involve heterogeneous actors (beyond researchers, civil servants, and managers) and are both collective (rather than involving sovereign autonomous decision-makers) and systemic (rather than step-based, as in linear or circular models).
We broadly define policy networks here as the structures and processes of interaction among individuals and organizations engaged in a policy field [21,22,23]. This definition highlights the heterogeneity of policy actors and arenas. Policy networks are not confined to government authorities and formal decision-makers but also include all other actors who work on policies or seek to influence, transform, or shape policies, such as non-governmental organizations, activists, industries, interest groups, or the media [24, 25]. In this perspective, networks do not have formal boundaries; they are informal, self-organizing, and in continual transformation [26,27,28,29].
By collective, we mean that policy processes occur in systems with a high level of interdependency and interconnectedness among participants [17, 18, 30]. Interdependency here refers to the fact that usually none of the participants dispose of enough autonomy or power to translate the information into practices on their own [31,32,33,34,35,36,37,38,39]. In such contexts, individuals are embedded within systemic relations, where knowledge use depends on processes such as sense-making [40,41,42], coalition-building [8, 43, 44], developing trustworthiness [45, 46], and rhetoric and persuasion [42, 47,48,49].
Such a view calls for a broader conceptualization of policy-making, in both the processes and the actors involved. Although the fields of policy analysis and KTE have been very much influenced by the concepts of “decision” and “decision-making,” operationalizing those concepts in collective systems [37, 50] can be highly problematic [51,52,53]. In contrast, policy processes are systemic, in that they involve a slowly evolving set of participants interacting over long periods [31, 39, 50, 54,55,56,57,58,59,60]. Discrete decisions or events are never the end of an identifiable process, but rather steps in a broader game [26, 61,62,63,64].
The sophistication of the policy-making concept summarized above highlights the importance of understanding how the structure formed by policy actors’ interactions with each other influences the circulation and absorption of scientific evidence. Converging evidence suggests the connection between scientific results and policy-makers’ practices is strengthened in policy networks/subnetworks in which scientific evidence “sources” or “producers” occupy, on average, a more central position. Based on social network analysis methods and theories, there is strong conceptual [65,66,67,68,69] and empirical [17, 18, 21, 56, 70,71,72,73,74,75] evidence to support the hypothesis that actors in bridging positions and/or with high centrality wield more influence. Sandström and Carlsson’s work [18, 30, 55], for example, demonstrates that subnetworks with high actor heterogeneity, high density, and high whole-network centrality are more desirable for effective KTE.
Accordingly, our aim in this proposal is to shift the focus of KTE analysis to (1) the structure of the interconnections between actors and (2) behaviors and communication processes (ties) as core determinants of the influence of scientific evidence in policy-making processes.
Such a focus prompts a shift in effect attribution. Most KTE literature is based on causal attribution models, in which intervention effectiveness is seen as attributable to characteristics of the strategy, users, or producers. However, if the structure of interconnections between actors is indeed a core determinant of KTE effectiveness, those attribution models are inappropriate [17, 30, 75]. What becomes crucial is understanding the network structure and its functioning. As described in more detail below, this project combines quantitative structural analysis of actors’ positions with qualitative analysis of their behaviors and communication processes from a network perspective.
Methods
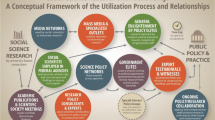
As highlighted in the previous section, understanding policy-related KTE processes implies shifting the focus of analysis in two ways: first, by relying on a more realistic conceptualization in which KTE is seen as the product of collective and systemic exchange networks of heterogeneous actors, and second, by combining structural network analysis with information about actors’ behaviors, resources, and skills in communication processes and actors’ perceptions of their capacity to act upon/influence policy-making processes [17]. For this reason, the present project will use a mixed-methods approach [76,77,78] with two components: (A) mapping and structurally analyzing Canadian health-relevant policy networks through multi-step snowball sampling and (B) qualitatively analyzing the processes through which scientific evidence circulates, based on interviews with a purposeful sample of significant actors in the network. Results from both components will then be integrated into a unified, conceptually sound, and empirically grounded framework (see Fig. 1 for a visual summary of the research design and Fig. 2 for a visual summary of the timeline of research activities).

Example of a sociogram

Four-year project timeline
Component A: network mapping and structural analysis
This component is aimed at identifying the actors involved in health-relevant policy networks in Canada and analyzing their structural position within these networks (objective 1). This method is based on quantitative analysis of relations (ties) that link nodes (here, individual actors) in a network.
Data collection and research participants
Network data will be collected through a multi-step snowball sampling strategy. The first challenge in implementing such an approach is to set conceptually sound and operationally manageable boundaries for the network being sampled. For this, we will apply two typologies. The first is a typology of actors and spheres of action based on the policy network literature [45, 79]:
-
Political sphere: Elected decision-makers at the federal, provincial, and municipal levels;
-
Public administration: Civil servants at the federal, provincial, and para-governmental institutional levels;
-
Academia: Researchers/professors in universities and other, mostly publicly funded, research institutions;
-
Media: Journalists and other news producers in broadcast, print, and electronic media;
-
Civil society: Interest groups, advocacy coalitions, unions, nongovernmental organizations, foundations, transnational agencies, and professional associations;
-
Private sector: Private corporations and industries.
The second typology is focused on the operational definition of what we have described as health-relevant policies. Healthcare policies and healthy public policies include a wide range of complex interventions which often share few similarities aside from their ultimate goal of positively impacting the health of individuals and populations [6]. To structure the delimitation of the field, we integrated and adapted the OECD typology of health policies with the WHO typology of healthy policies [80,81,82]. The end result is a heuristic classification with no pretension of exhaustively listing all subfields. Its role is to help in the inductive identification of informants in each sphere’s fields and subfields.
These two typologies are the starting point of our snowball strategy. They will be used to build and structure an initial list of actors and organizations considered to be involved in shaping or trying to influence health-relevant policies in Canada. Sources used to compile an initial list of names and contact information in each of these spheres, per province, will consist of publicly available directories and institutional websites, social media platforms, and reference lists provided by each of the team’s co-applicants and collaborators based on each Canadian region. The health-relevant policy fields and subfields provided in Table 1 will be used as a structure both to generate keywords for online searches and to define the boundaries of the data collection effort. Pilot testing of the approach suggests we will be able to compile initial lists of hundreds of contacts per category. We aim to launch the approach with between 2000 and 5000 initial contacts.
Potential respondents will be contacted by mail, email, and phone (details below) and invited to complete a short bilingual online survey structured around four themes: (1) provide informed consent, (2) answer a few descriptive questions on personal characteristics (specifically professional occupation [the sampling category]; perceived KTE role(s) [along the producer/broker/user division]; institutional affiliation; hierarchical position held in the institution; and geographic location), (3) identify the health-relevant policies in which they are involved (closed questions built from Table 1 as a starting point and finalized after pilot testing; respondents will also be able to identify other policy themes on which they are working by selecting the option “other”), and (4) nominate up to ten people with whom they are in contact regarding their involvement in policy-relevant processes. Previous work by the team with this method suggests saturation occurs before ten responses [83].
Participant eligibility will be based on self-perception, in that any individuals who consider themselves actively involved in health-relevant policy processes at the institutional, provincial, or federal levels will be eligible. For every element in the survey, an operational definition will be displayed onscreen using a mouse-over function (e.g., for question 4: “Being in contact with is here defined as a regular or irregular form of personal communication, either face-to-face or via email, phone, or social media”). The survey is expected to take around 5 min to complete. We will use the Polinode platform (www.polinode.com), an online tool specializing in relationship-based surveys and network analysis.
Respondents identified through this peer-nomination process will, in turn, be invited to fill out the survey and identify their own network of contacts. This multi-step snowballing process is a common way to identify actors in unbounded networks, such as policy networks, and has been used in other studies to identify policy-makers and/or influential actors in policy-making [21, 79]. This method reduces initial sampling bias, since single-step sampling is generally restricted to actors assumed to be the most active in formal settings and/or publicly visible. By including other meaningful contacts who are not necessarily the most visible or expected actors, the recursive name generation of contacts-of-contacts expands the network and captures its heterogeneity.
The main challenge of this data collection process is to obtain a satisfactory response rate. Following Dillman’s tailored design best practices [84], we will use a sequential multiple contact strategy to stimulate participation. Potential participants will receive both personalized email and mail invitations, with a token incentive [85]. Mail and email reminders will be sent 2 weeks later, followed by a phone call to nonrespondents a week later during which they will be given the possibility to respond to the survey by phone. The project involves partners, co-investigators, and collaborators with extensive contact lists in all provinces. These contacts will be used to personalize mail and email invitations in order to increase the response rate.
The snowball data collection period will run for 1 year of active follow-up, with the objective of obtaining 20 to 50% response rates in each policy actor sphere. As there are no reliable estimates of the number of potential participants in each of these categories, we will use the Cormack-Jolly-Seber “capture–mark–recapture” model [86], as implemented in the Program MARK software (http://www.phidot.org/software/mark/background/), to calculate the estimated whole population of actors in each subgroup. Each person identified as pertaining to one of the categories of actors we aim to sample will be considered “captured.” Each person already on our list whose name emerges through the snowball name-generator question will be considered “recaptured.” Using this method, total population estimates per policy actor sphere will be computed during data collection. At the end of data collection, the model will also provide reliable estimates of the proportion of the overall network for which we have data. This is a crucial issue for social network analysis (SNA) ego-based snowball sampling, as the networks obtained are always only a bounded extraction from a, practically, limitless network [21, 87, 88].
Data analysis and interpretation
The data obtained through the multi-step snowball sampling (names of participants and of the people with whom they are in contact) will be transposed into a symmetric matrix where each row/column corresponds to a node (actor) and where values correspond to ties (relations between actors). From such a matrix, it is possible to produce a network map (sociogram) and to compute network-, cluster-, and node-level metrics [68, 87,88,89,90,91,92]. To do this, the data will be imported into and analyzed with UCINET 6 software. Sociogram visual optimization will be done on Cytoscape 3.3.0 software through force-directed algorithms (see Fig. 1). The data will then be analyzed structurally using SNA and graph theory [65, 68, 87,88,89,90,91,92]. To identify central actors, actors in bridging positions, and actors with atypical connectivity [65, 68, 91] in the networks, node (degree, closeness, betweenness, and eigenvector centralities) and network (density, clustering, and structural holes) structural metrics will be computed. Actors’ personal characteristics will be plotted on the graph to identify shared attribute patterns (homophily) [93]. We will also use multiple regression models (in SPSS 23.0) to test the statistical association between actors’ characteristics and structural node metrics. Finally, community detection algorithms will be used to understand underlying clustering factors. Conceptually coherent clusters (i.e., based on node homophily, policy issues, or geographic proximity) will be identified and treated as policy subnetworks. We will also measure the interconnectedness of these health-relevant policy subnetworks.
Results from this structural analysis will be interpreted at three levels. First, we will assess the whole-network connectivity of actors labeled as scientific evidence “sources/producers” in health-relevant policy networks in Canada. Then, we will compare policy subnetworks based on the assessment criterion that policy subnetworks in which scientific evidence sources are, on average, more central are more desirable. Finally, we will compare the KTE potential of subnetworks, based on Sandström and Carlsson’s work [18, 30, 55] showing that subnetworks with high actor heterogeneity, high density, and high whole-network centrality are more desirable.
Component B: qualitative analysis of communication processes and perceived influence
As stated earlier, structural position alone does not explain how knowledge can be efficiently circulated and transferred in health policy networks; factors such as conceptual capacity and political clout must also be taken into consideration. For example, an actor may be in a structural position that enhances his/her exposure to relevant information but be ill-equipped, in practical terms, to make sense of this information [5, 94, 95] or to use it to influence others [5, 14, 47, 96]. Conversely, an actor could have low structural connectivity, and thus limited exposure to relevant information, but still have significant conceptual capacity. We will rely on the concept of absorptive capacity to bridge these two notions of structural position and conceptual capacity. An actor with high absorptive capacity [95, 97] has both the opportunities (high structural exposure to new knowledge [18, 56, 67, 68, 71, 73]) and the means (prior knowledge and practical capacity [8, 23, 41, 46, 94]) to foster use.
To understand actors’ behaviors and information processing strategies through which structural network connectivity are operationalized, we will conduct qualitative semi-structured interviews with a purposeful subsample of the Web survey participants. This will allow us to understand both how actors end up in a particular structural position and whether actors’ views on their capacity to access evidence, transfer information, and ultimately influence policy-making correspond to the theoretical advantages that specific network positions and structures are assumed to provide (e.g., central and bridging positions).
Data collection
Informant selection will be based on the actor-level and cluster-level structural metrics obtained from structural analysis (component A). For each actor type and subnetwork, we will invite a combination of actors (maximum-variation sampling strategy) with high prestige (degree centrality and eigenvector centrality), high bridging (betweenness centrality and structural-hole position), and atypical connectivity [65, 68, 91] in the whole network and within subgroups/clusters to participate in in-depth semi-structured interviews of approximately 60 min. Clusters identified through component A—including data about each node’s real name/organizational affiliation—will be discussed with all co-investigators and collaborators to look for ideological or interest-based clustering effect [23, 98, 99]. We plan to conduct between 40 and 60 such interviews. As informants will be spread throughout Canada, interviews will be conducted either by phone or Skype depending on informants’ preferences. Interviews will be conducted in the informant’s preferred language and will be recorded (with informed consent), transcribed, proofread, and imported into ATLAS.ti 7 qualitative data analysis software for coding and analysis.
For each participant, the main themes covered will be
-
Themes/issues/policies in which he/she is involved in the network.
-
Role played in the network and modes through which this role is enacted (public media appearances, advocacy, participation in public or stakeholder forums, membership in government committees or advisory groups, provision of direct advice or assistance in policy-making processes, collaborative research, and/or personal communications with official policy- and decision-makers).
-
Networking motives and practices (how did the participant come in contact with the people listed in the name generator survey, how does the participant create new contacts, for what reasons, what are the participant’s needs/expectations when seeking new contacts).
-
Advantages/limitations of network positions (are current network relations useful, which are most useful and why, level of difficulty in establishing/finding necessary contacts).
-
Perceived influence in the network (personal assessment and opinion on which type of actor has more influence on policy-making and why, modes of participation in the network that seem more efficient for using and disseminating scientific evidence, and external factors that facilitate or limit individual capacity to play an effective role in the network, e.g., organizational affiliation, professional occupation, and hierarchical position).
Data analysis and interpretation
Transcript coding will be based on systematic identification of recurring themes [100, 101]. Codes will be developed inductively as the analysis unfolds, but the starting point will be anchored in the complementary dimensions put forward in the works of C Phelps, et al. [17], Sandström and Carlsson [18], and Sabatier and Jenkins-Smith [60]. Discourse analysis approaches [100,101,102] will be used. Each coded interview will first be analyzed independently and then transversally, by comparing similarities and differences between policy subnetworks and actors’ characteristics. We will use investigator triangulation (n = 2) to ensure coding reliability [103, 104]. Codebook definitions and analysis will be scrutinized and discussed in group meetings with all co-investigators and research assistants. The research team has extensive experience successfully using similar qualitative data analysis.
Discussion
Results integration and impact
As stated in previous sections, the project’s main objective is to provide a conceptually sound and empirically grounded understanding of the way by which scientific evidence interconnects with decision-making at policy levels in Canada. To achieve this (ambitious) goal, the project relies on a mixed-method design with two components. Conceptually, the integration of both components’ results will involve extending the notion of absorptive capacity to the subnetwork level. Absorptive capacity is conceived here as both a property of subnetworks’ structural properties and the optimization of actors’ communicative strategies within a given structural arrangement. This extension tallies with existing evidence on collective effects in innovation adoption [75, 97] and knowledge use [51, 105]. The results will shed light on the relative structural position of individuals and institutions within subnetworks, the communications strategies they use, and the factors (interests and ideologies) that explain them.
This project is based on cutting-edge, interdisciplinary conceptual developments [17, 18, 20, 24, 55, 79] and innovative large-scale data collection methods. Conceptually, it addresses some of the main challenges that have vexed collective-level knowledge transfer and exchange (KTE) literature. Knowledge developed from this project has the potential both to strengthen the scientific understanding of how collective KTE functions and to generate significantly improved practical advice on how to strengthen the role of evidence in organizational practices and public policies. Ultimately, this can lead to more effective integration of scientific evidence into practices and to decisions that can have a beneficial impact on the health of Canadians.
Dissemination of results
The KTE plan for this project is threefold. First, this project is conceptually innovative and relies on a data collection approach that has, to the best of our knowledge, never been used at the national level. We believe the results will lead to high-impact scientific articles with potential to influence the field.
Second, the project involves three key partner organizations that will be actively involved in both the use of the project’s results (user role) and their dissemination to other potential users (vector role): the National Collaborating Centre for Healthy Public Policy (NCCHPP), the Canadian Nurses Association (CNA), and the Ontario Tobacco Research Unit (OTRU).
Partnerships with our three main partner organizations will be paramount in helping the research team contextualize the findings, adapt them to the needs of users involved in organizational decision-making and policy-making, and disseminate them to relevant stakeholders. Adapted and summarized findings will be formatted both in a 1:3:25 report and as an interactive website. Beyond the three core partners identified above, we will also mobilize collaborations with the Evidence Network and the six National Collaborating Centres for Public Health to disseminate results to potential users. In the same way, our team is truly pan-Canadian in scope, and co-investigators’ and collaborators’ connections with other significant actors in Canada will be used to foster more such collaborations as the project unfolds.
The third element of the plan is that a fundamental product of this project will be the development of a nominal map of thousands of actors involved in health-relevant policies across Canada. This map in itself will represent a KTE instrument of remarkable possibilities. All individuals identified through the project’s data collection efforts will receive an email link to the report and interactive website results. The network map will be uploaded to the website, and participants will be able to log in and locate their exact position (node), interconnections in the network, and personal centrality metrics. This sharing of results with participants also has the potential to play an important role in disseminating results. Active traffic monitoring strategies and social media will also be used to foster access. Team expertise and resources will also be mobilized for that purpose, especially to attract mass media attention as a part of the end-of-grant KTE plan.
Expertise, experience, and resources
This project is ambitiously integrative at both the conceptual and methodological levels. Essential to its success is a team of researchers with complementary individual expertise and, collectively, a truly outstanding track record. The pan-Canadian composition of the team is also a key strength, as team members’ knowledge of health-relevant policies and policy actors in their respective provinces will be essential for designing research tools, identifying and reaching out to participants, disseminating findings and results, and adapting them to local needs.
Notes
We define policy-level interventions broadly to include federal, provincial, and para-governmental institutional-level interventions. A more operational definition is provided in the next pages.
The phenomenon we label knowledge transfer and exchange here is described under a variety of terms depending on the country and discipline. Common terms include knowledge translation, knowledge exchange, and implementation research.
Abbreviations
- CNA:
-
Canadian Nurses Association
- KTE:
-
Knowledge transfer and exchange
- NCCHPP:
-
National Collaborating Centre for Healthy Public Policy
- OECD:
-
Organisation for Economic Co-operation and Development
- OTRU:
-
Ontario Tobacco Research Unit
- SNA:
-
Social network analysis
- WHO:
-
World Health Organization
References
Fisher ES, Bynum JP, Skinner JS. Slowing the growth of health care costs—lessons from regional variation. N Engl J Med. 2009;360(9):849–52.
Haines A, Kuruvilla S, Borchert M. Bridging the implementation gap between knowledge and action for health. Bull World Health Organ. 2004;82(10):724–32.
Prewitt K, Schwandt TA, Miron L. Straf: using science as evidence in public policy. Washington: Committee on the Use of Social Science, Knowledge in Public Policy, National Research Council of the National Academies; 2012.
Mitton C, Adair CE, Mckenzie E, Patten SB, Perry BW. Knowledge transfer and exchange: review and synthesis of the literature. Milbank Q. 2007;85(4):729–68.
Contandriopoulos D, Lemire M, Denis J-L, Tremblay É. Knowledge exchange processes in organizations and policy arenas: a narative systematic review of the literature. Milbank Q. 2010;88(4):444–83.
Hawe P. Lessons from complex interventions to improve health. Annu Rev Public Health. 2015;307–23:307–23.
Beyer JM, Trice HM. The utilization process: a conceptual framework and synthesis of empirical findings. Admin Sci Q. 1982;27(4):591–622.
Salisbury RH, Heinz JP, Laumann EO, Nelson RL. Who works with whom? Interest group alliances and opposition. Am Polit Sci Rev. 1987;81(4):1217–34.
Dunn WN. Measuring knowledge use. Knowledge. 1983;5(1):120.
Henry GT, Mark MM. Beyond use: understanding evaluation’s influence on attitudes and actions. Am J Eval. 2003;24(3):293–314.
Huberman M. Research utilization: the state of the art. Knowledge Technol Policy. 1994;7(4):13–33.
Johnson RB. Toward a theoretical model of evaluation utilization. Eval Program Plann. 1998;21(1):93–110.
Knott J, Wildavsky A. If dissemination is the solution, what is the problem? Knowledge. 1980;1(4):537–78.
Peterson MA. How health policy information is used in Congress. In: Mann TE, Ornstein NJ, editors. Intensive care: how Congress shapes health policy. Washington, D.C: American Enterprise Institute; 1995. p. 79–125.
Rich RF, Oh CH. Rationality and use of information in policy decisions—a search for alternatives. Sci Commun. 2000;22(2):173–211.
Straus SE, Tetroe J, Graham ID, Zwarenstein M, Bhattacharyya O, Shepperd S. Monitoring use of knowledge and evaluating outcomes. CMAJ. 2010;182(2):E94–8.
Phelps C, Heidl R, Wadhwa A. Knowledge, networks, and knowledge networks: a review and research agenda. J Manag. 2012;38(4):1115–66.
Sandström A, Carlsson L. The performance of policy networks: the relation between network structure and network performance. Policy Stud J. 2008;36(4):497–523.
Valente TW, Dyal SR, Chu K-H, Wipfli H, Fujimoto K. Diffusion of innovations theory applied to global tobacco control treaty ratification. Soc Sci Med. 2015;145:89–97.
Molin MD, Masella C. Networks in policy, management and governance: a comparative literature review to stimulate future research avenues. JMG. 2015;20(4):1–27.
Lewis JM. Being around and knowing the players: networks of influence in health policy. Soc Sci Med. 2006;62(9):2125–36.
Rhodes RAWD. Marsh: new directions in the study of policy networks. Eur J Polit Res. 1992;21(1):181.
Heinz JP. The hollow core: private interests in national policy making. Cambrige: Harvard University Press; 1993.
Bowen K, Alexander D, Miller F, Dany V. Using social network analysis to evaluate health-related adaptation decision-making in Cambodia. Int J Environ Res Public Health. 2014;11(2):1605.
Shore C, Wright S, Però D. Policy worlds: anthropology and the analysis of contemporary power: Berghahn Books; 2011.
Matland RE. Synthesizing the implementation literature: the ambiguity-conflict model of policy implementation. J Public Adm Res Theory. 1995;5(2):145–74.
Mazmanian DA, Sabatier PA. Implementation and public policy. Lanham: University Press of America; 1989.
Contandriopoulos D, Denis J-L. Leading transformation in public delivery systems: a political perspective. In: Dent M, Ferlie E, Teelken C, editors. Leadership in the public sector: promises and pitfalls. London: Routledge; 2012. p. 44–61.
Nakamura RT, Smallwood F. The politics of policy implementation. New-York: St. Martin; 1980.
Sandström A, Rova C. Adaptive co-management networks: a comparative analysis of two fishery conservation areas in Sweden. Ecol Soc. 2010;15(3):14.
Jordan G, Maloney WA. Accounting for subgovernments—explaining the persistence of policy communities. Adm Soc. 1997;29(5):557–83.
Havelock RG. Planning for innovation through dissemination and utilization of knowledge. Ann Arbor: Institute for Social Research (University of Michigan); 1969.
Lynn LE: Knowledge and policy: the uncertain connection; 1978.
Kickert WJM, Klijn E-H, Koppenjan JFM. Managing complex networks. London: SAGE; 1999.
Pressman J, Wildavsky A. Implementation. Berkeley: University of California Press; 1973.
Rhodes R. Policy networks: a British perspective. J Theor Polit. 1990;2(3):293–317.
March JG, Olsen JP: Ambiguity and choice in organizations; 1976.
Leviton LC. Evaluation use: advances, challenges and applications. Am J Eval. 2003;24(4):525–35.
March JG. Decisions and organizations. New York: Blackwell; 1988.
Weick KE. Sensemaking in organizations. SAGE: Thousand Oaks; 1995.
Nonaka I. A dynamic theory of organizational knowledge creation. Org Sci. 1994;5(1):14–37.
Russell J, Greenhalgh T, Byrne E, McDonnell J. Recognizing rhetoric in health care policy analysis. J Health Serv Res Policy. 2008;13(1):40–6.
Heaney MT. Brokering health policy: coalitions, parties, and interest group influence. J Health Polit Policy Law. 2006;31(5):887–944.
Lemieux V. Les coalitions: Liens, transactions et contrôles. Paris: P.U.F; 1998.
Haynes AS, Derrick GE, Redman S, Hall WD, Gillespie JA, Chapman S, Sturk H. Identifying trustworthy experts: how do policymakers find and assess public health researchers worth consulting or collaborating with? PLoS One. 2012;7(3):e32665.
Milbrath LW. Lobbying as a communication process. Public Opin Q. 1960;24(1):32–53.
Majone G. Evidence, argument and persuasion in the policy process. New Haven: Yale University Press; 1989.
Van de Ven AH, Schomaker MS. The rhetoric of evidence-based medicine. Health Care Manage Rev. 2002;27(3):89–91.
Perelman C, Olbrechts-Tyteca L. The new rhetoric: a treatise on argumentation. Notre Dame: University of Notre Dame Press; 1969.
Sabatier PA, Jenkins-Smith HC. Theories of the policy process. Westview: Boulder; 1999.
Langley A, Mintzberg H, Pitcher P, Posada E, Saint-Macary J. Opening up decision making: the view from the black stool. Org Sci. 1995;6(3):260–79.
Weiss CH. Using social research in public policy making. Lexington: Lexington Books; 1977.
Weiss CH, Bucuvalas MJ: Social science research and decision-making; 1980.
Atkinson MM, Coleman WD. Policy networks, policy communities and the problems of governance. Governance. 1992;5(2):154–80.
Carlsson L. Policy networks as collective action. Policy Stud J. 2000;28(3):502–20.
Carpenter DP, Esterling KM, Lazer DMJ. Friends, brokers, and transitivity: who informs whom in Washington politics? J Polit. 2004;66(1):224–46.
Considine M, Lewis JM. Networks and interactivity: making sense of front-line governance in the United Kingdom, the Netherlands and Australia. J Eur Public Policy. 2003;10(1):46–58.
Klijn E-H. Policy networks: an overview. In: WJM K, Klijn E-H, JFM K, editors. Managing complex networks. London: SAGE; 1999. p. 14–61.
Sabatier PA, Jenkins-Smith HC. Policy change and learning: an advocacy coalition approach. Boulder: Westview; 1993.
Sabatier PA, Jenkins-Smith HC. The advocacy coalition framework. In: Sabatier PA, editor. Theories of the policy process: theoretical lenses on public policy. Boulder: Westview; 1999. p. 117–66.
Bardach E. The implementation game. Cambridge: MIT; 1977.
Hjern B. Review: Implementation research: the link gone missing. J Public Policy. 1982;2(3):301–8.
Klijn EH. Analyzing and managing policy processes in complex networks: a theoretical examination of the concept policy network and its problems. Adm Soc. 1996;28(1):90–119.
O’Toole LJ Jr, Hanf KI, Hupe PL. Managing implementation processes in networks. In: WJM K, Klijn E-H, JFM K, editors. Managing complex networks. London: SAGE; 1999. p. 137–51.
Burt RS. Structural holes: the social structure of competition. Cambridge: Harvard University Press; 1992.
Carpenter DP, Esterling KM, Lazer DMJ. The strength of weak ties in lobbying networks: evidence from health-care. J Theor Polit. 1998;10(4):417.
Granovetter M. The strength of weak ties: a network theory revisited. Sociol Theory. 1983;1:201–33.
Borgatti SP. Centrality and network flow. Soc Networks. 2005;27:55–71.
Granovetter M. Economic action and social structure: the problem of embeddedness. Am J Sociol. 1985;91(3):481–510.
Berardo R. Processing complexity in networks: a study of informal collaboration and its effect on organizational success. Policy Stud J. 2009;37(3):521–39.
Beyers J, Braun C. Ties that count: explaining interest group access to policymakers. J Public Policy. 2014;34(01):93–121.
Bodin Ö, Crona BI. The role of social networks in natural resource governance: what relational patterns make a difference? Glob Environ Chang. 2009;19(3):366–74.
Brass DJ. Being in the right place: a structural analysis of individual influence in an organization. Admin Sci Q. 1984;29(4):518–39.
Cross R, Parker A. The hidden power of social networks: understanding how work really gets done in organizations. Boston: Harvard Business School Press; 2004.
Valente TW. Network models of the diffusion of innovations. Hampton; 1995.
Domínguez S, Hollstein B. Mixed methods social networks research: design and applications: Cambridge: Cambridge University Press; 2014.
Crossley N: The social world of the network. combining qualitative and quantitative elements in social network analysis. Sociologica 2010, 4(1):0–0.
Bellotti E. Qualitative networks: mixed methods in sociological research. New York: Taylor & Francis; 2014.
Oliver K, de Vocht F, Money A, Everett M. Who runs public health? A mixed-methods study combining qualitative and network analyses. J Public Health. 2013;35(3):453–9.
Health policies. [http://www.oecd.org/els/health-systems/policy.htm]. Accessed 9 Aug 2017.
Adelaide recommendations on healthy public policy. [http://www.who.int/healthpromotion/conferences/previous/adelaide/en/index3.html]. Accessed 9 Aug 2017.
NCCHPP: a framework for analyzing public policies: practical guide. National Collaborating Centre for Healthy Public Policy; 2012. http://www.ncchpp.ca/docs/Guide_framework_analyzing_policies_En.pdf:. Accessed 9 Aug 2017.
Contandriopoulos D, Hanusaik N, Maximova K, Paradis G, O’Loughlin JL. Mapping collaborative relations among Canada’s chronic disease prevention organizations. Healthcare Policy. 2016;12(1):101–15.
Dillman DA, Smyth JD, Christian LM. Internet, mail, and mixed-mode surveys: the tailored design method. Hoboken: John Wiley & Sons; 2009.
Sauermann H, Roach M. Increasing web survey response rates in innovation research: an experimental study of static and dynamic contact design features. Res Policy. 2013;42(1):273–86.
Seber GAF. Estimation of animal abundance. New York: MacMillan; 1982.
Scott J. Social network analysis: a handbook. 2nd ed. SAGE: Thousand Oaks; 2000.
Wasserman S, Faust K. Social network analysis: methods and applications. Cambridge: Cambridge University Press; 1994.
Borgatti SP, Mehra A, Brass DJ, Labianca G. Network analysis in the social sciences. Science. 2009;323(5916):892–5.
Doreian P, Batagelj V, Ferligoj A. Positional analysis of sociometric data. In: Carrington PJ, Scott J, Wasserman S, editors. Models and methods in social network analysis. New York: Cambridge University Press; 2005. p. 77–97.
Everett MG, Borgatti SP. Extending Centrality. In: Carrington PJ, Scott J, Wasserman S, editors. Models and methods in social network analysis. New York: Cambridge University Press; 2005. p. 57–76.
Scott J, Carrington PJ. The SAGE handbook of social network analysis. London: SAGE; 2011.
McPherson M, Smith-Lovin L, Cook JM. Birds of a feather: homophily in social networks. Annu Rev Sociol. 2001;27(1):415–44.
Polanyi M. Personal knowledge. Chicago: The University of Chicago Press; 1974. p. 18–65.
Tsai W. Knowledge transfer in intraorganizational networks: effects of network position and absorptive capacity on business unit innovation and performance. Acad Manag J. 2001;44(5):996–1004.
Ainsworth S, Sened I. The role of lobbyists: entrepreneurs with two audiences. Am J Polit Sci. 1993;37(3):834–66.
Greenhalgh T, Robert G, Macfarlane F, Bate P, Kyriakidou O. Diffusion of innovations in service organizations: systematic review and recommendations. Milbank Q. 2004;82(4):581–629.
Hall PA. The role of interests, institutions, and ideas in the comparative political economy of the industrialized nations. In: Lichbach MI, Zuckerman AS, editors. Comparative politics: rationality, culture, and structure. Cambridge: Cambridge University Press; 1997. p. 174–207.
NCCHPP: understanding policy developments and choices through the “3-i” framework: interests, ideas and institutions. National Collaborating Center on Healthy Public Policies; 2004. http://www.ncchpp.ca/docs/2014_ProcPP_3iFramework_EN.pdf:. Accessed 9 Aug 2017.
Denzin NK, Lincoln YS. The SAGE handbook of qualitative research. Los Angeles: SAGE; 2011.
Fairclough N. Critical discourse analysis: the critical study of language. New York: Routledge; 2013.
Bourdieu P. Ce que parler veut dire: l’économie des échanges linguistiques. Paris: Fayard; 1982.
Patton MQ. Qualitative research & evaluation methods. 3rd ed. Thousand Oaks: SAGE; 2002.
Denzin NK. The research act: a theoretical introduction to sociological methods. New York: McGraw-Hill; 1978.
Weiss CH. Knowledge creep and decision accretion. Knowledge. 1980;1(3):381–404.
Acknowledgements
Not applicable
Funding
Based on this proposal, the project was awarded a 1-year bridge funding from the Canadian Institutes for Health Research to run a pilot of the data collection approach (application no. 376601).
Availability of data and materials
Please contact author for data requests.
Author information
Authors and Affiliations
Contributions
DC, MP, AL, and CL have coordinated the writing of the research proposal. All authors have played a key role in conceptualizing research, adapting design for better feasibility, and writing protocol according to their field of expertise. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The ethics committee of the University of Montreal has approved this research project (17-106-CERES-D).
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Contandriopoulos, D., Benoît, F., Bryant-Lukosius, D. et al. Structural analysis of health-relevant policy-making information exchange networks in Canada. Implementation Sci 12, 116 (2017). https://doi.org/10.1186/s13012-017-0642-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13012-017-0642-4