
Abstract
Background
Car driving is a form of passive transportation associated with higher sedentary behaviour, which is associated with morbidity. The decision to drive a car is likely to be influenced by the ‘drivability’ of the built environment, but there is lack of scientific evidence regarding the relative contribution of environmental characteristics of car driving in Europe, compared to individual characteristics. This study aimed to determine which neighbourhood- and individual-level characteristics were associated with car driving in adults of five urban areas across Europe. Second, the study aimed to determine the percentage of variance in car driving explained by individual- and neighbourhood-level characteristics.
Methods
Neighbourhood environment characteristics potentially related to car use were identified from the literature. These characteristics were subsequently assessed using a Google Street View audit and available GIS databases, in 59 administrative residential neighbourhoods in five European urban areas. Car driving (min/week) and individual level characteristics were self-reported by study participants (analytic sample n = 4258). We used linear multilevel regression analyses to assess cross-sectional associations of individual and neighbourhood-level characteristics with weekly minutes of car driving, and assessed explained variance at each level and for the total model.
Results
Higher residential density (β:-2.61, 95%CI: − 4.99; -0.22) and higher land-use mix (β:-3.73, 95%CI: − 5.61; -1.86) were significantly associated with fewer weekly minutes of car driving. At the individual level, higher age (β: 1.47, 95%CI: 0.60; 2.33), male sex (β: 43.2, 95%CI:24.7; 61.7), being employed (β:80.1, 95%CI: 53.6; 106.5) and ≥ 3 person household composition (β: 47.4, 95%CI: 20.6; 74.2) were associated with higher weekly minutes of car driving. Individual and neighbourhood characteristics contributed about equally to explained variance in minutes of weekly car driving, with 2 and 3% respectively, but total explained variance remained low.
Conclusions
Residential density and land-use mix were neighbourhood characteristics consistently associated with minutes of weekly car driving, besides age, sex, employment and household composition. Although total explained variance was low, both individual- and neighbourhood-level characteristics were similarly important in their associations with car use in five European urban areas. This study suggests that more, higher quality, and longitudinal data are needed to increase our understanding of car use and its effects on determinants of health.
Similar content being viewed by others


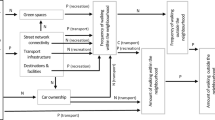
Introduction
Car driving is a form of passive transportation associated with sedentary behaviour, which is in turn associated with morbidity [1]. Recent estimates indicate that 56% of the adult population across 28 European countries use a private car for daily trips whereas only 16% cycle or walk [1].
In previous studies car use has been associated with adverse health outcomes [2,3,4,5]. One study showed that substantial car use (> 10 h per week) was associated with a 50% higher risk of cardiovascular disease mortality [2]. Other studies have found associations between car driving and higher rates of obesity [3,4,5]. Driving to work was associated with 13% higher odds of obesity (95% CI 1.01; 1.27)) [3], and driving > 120 min per day was associated with 78% higher odds of obesity (95%CI: 1.61; 1.97) [4], in Australia. Additionally, a US modelling study indicated a 2.2% increase in obesity prevalence over 6 years, if each licensed driver increased their car travel by a mile per day [5]. Shifting from car use to active transport may therefore improve population health, and the built environment - an important determinant of travel behaviour - play a role in this shift to more active transport and health promotion. For example, a recent meta-analysis of observational studies indicated that highly walkable neighbourhoods – i.e. neighbourhoods featuring characteristics that promote walking – are associated with lower risk of type 2 diabetes [6]. Gaining insight into characteristics related to car driving can help inform transport-policies, and thereby improve health and outcomes such as traffic safety, air quality, congestion and climate change.
Walkability and green space, characteristics of the built environment, are consistently associated with higher levels of active transport in Europe [7,8,9,10]. However, individual and built environment characteristics specifically associated with car use and their relative contributions are less clear, especially across European countries. Car use may be influenced by a combination of individual and environmental characteristics. Previous studies have indicated that at the individual level, higher age, male sex, larger household composition, and being employed were associated with higher car use, and high socioeconomic status was consistently linked with both car ownership and car use [4, 11,12,13,14,15]. Built environmental characteristics were associated with car use include residential density, land-use mix, street network design, distance to destinations, parking availability and cost [13,14,15,16,17,18,19,20,21,22,23,24]. A meta-analysis showed that a 10% increase in road density, intersection density, access to jobs by car, distance to downtown and land-use mix, population density, access to job by transit or distance to transit were associated with 0.5–2.2% lower vehicle miles travelled [11]. Another study observed that a $6 increase in parking cost was associated with 16% lower probability of car use [24]. However, these studies were mainly non-European, and studies on potential determinants of car use in European settings are scarce.
Studies on potential determinants of car use in European settings, and especially across European countries, are scarce. Moreover, not many studies compared the contribution of individual characteristics to car use with neighbourhood characteristics. One study investigated the association between demographic and built environment variables with car ownership and daily travel by car, while drawing a comparison between the US and the UK. This study observed overall higher vehicle miles travelled by males, younger adults, employed individuals, and people with higher incomes. Correlates of car use were different for both settings, where socioeconomic status was more strongly associated with car use in the UK, the higher income groups travelled 5.6 vehicle miles more, compared to 2.4 vehicles miles in the highest income category in the US. In the US the highest population density category (10.000 persons/mile2) was associated with 8.0 fewer vehicle miles travelled per day, while in the UK the reduction was 1.6 vehicle miles [12].
Therefore, the aim of this study was to explore correlates of car driving in adults from five urban areas across Europe. We answered the following two research questions:
- 1.
Which individual and neighbourhood characteristics are associated with car driving (in minutes per week), in five urban areas across Europe?
- 2.
What percentage of variance in car driving minutes per week is explained by these individual- and neighbourhood-level characteristics?
Methods
Evidence-derived characteristics
Based on the available literature, a list of candidate variables important for ‘neighbourhood drivability’ was identified, and categorized according to the six D’s classification of Ewing & Cervero [11]. This classification originates from transport research and serves to identify influences in the built environment that potentially moderate travel demand. The classification consists of: density, diversity, design, destination accessibility, distance to transit and demand management [25]. The list of built environment variables was narrowed down to variables for which data sources could reasonably be obtained in a cross-European setting. The resulting selection of built environment characteristics include residential density, population density, car road density, land-use mix, traffic signal density, intersection density, parking at work, distance to destination, distance to transit, parking supply, parking cost, and are summarized and defined in Table 1.
Study design
For this study we used data from the Sustainable Prevention of Obesity Through Integrated Strategies (SPOTLIGHT) study. Details of this study are described elsewhere [31, 32]. In short, a neighbourhood audit and an individual-level survey were conducted in 60 randomly selected urban neighbourhoods from five European countries (Belgium, France, Hungary, the Netherlands and the United Kingdom). The urban areas were: Ghent and suburbs in Belgium; Paris and suburbs in France; Budapest and suburbs in Hungary; the Randstad (a conurbation including Amsterdam, Rotterdam, the Hague and Utrecht) in the Netherlands, and Greater London in the United Kingdom. In each of these urban areas, 12 neighbourhoods were selected, ensuring variety in residential area density (high and low density: > 2/3 and < 1/3 of area covered by residential buildings, respectively) and socioeconomic status (SES) (high and low: third and first tertile of neighbourhood level income, respectively) at neighbourhood level. Details on sampling can be found elsewhere [32]. A random sample of inhabitants (≥18 years) was invited to participate in the online survey, 6037 participants were included in the SPOTLIGHT study (response rate: 10.8%) [32].
For the present study, we excluded participants with missing (n = 530) and extreme values (n = 82) (z-score > 3) on the dependent variable car driving minutes per week and those with missing address or neighbourhood audit variables (n = 838). A complete-case analysis was performed due to the low proportion of missing values in covariates (9%), resulting in an analytical sample for the main analyses of n = 4258 (total sample descriptions are presented in Additional file 1: Table S1).
Neighbourhood environmental characteristics
Environmental characteristics were measured at the neighbourhood level, defined by local administrative boundaries, except for Hungary. Budapest is officially divided into districts and suburbs that are much larger and contain a much more heterogeneous population than the administrative areas in the other study countries. Therefore, to ensure comparability between study areas, neighbourhoods in Budapest and suburbs were defined as 1 km2 areas [32]. On average a neighbourhood consisted a mean population of 2700 inhabitants in an area of 1,5km2. Neighbourhood definitions and characteristics are described in detail in a previously published paper [32].
Neighbourhood characteristics were assessed by the SPOTLIGHT virtual audit tool [33], a virtual street audit, using Google Street View to assess characteristics of physical activity- and food environment. In addition we used open data sources to derive additional characteristics that could be linked to cross-country respondent’s residential postal codes. Using these sources, we obtained a selection of the variables listed in Table 2: residential density, car road density, land-use mix, traffic signal density, and parking supply. The details of collection, calculations and use of these data are described below, according to an adapted version of the Geo-FERN reporting framework (Additional file 2: Table S2).
Density
Car road density was defined as the percentage of area coverage of fast transit and other roads and associated land per neighbourhood [11]. Residential density was defined as percentage of the area coverage of residential buildings per neighbourhood [11]. Data were obtained from the Urban Atlas (European Environment Agency, 2002), a Geographic Information System (GIS) database distributed by the European Environmental Agency, which provided high-resolution satellite image data on land use across Europe [34, 35]. The purpose of the European Environment Agency is to provide high quality data and independent data on the environment (e.g. greenhouse gas emissions, heavy metals in water, land-use). Car road and residential densities were obtained for the five urban areas under study, by intersecting land-use layers with neighbourhood boundaries, in ArcGIS version 10.6, resulting in a percentage of neighbourhood area devoted to car roads or residential area. Density variables ranged from 0 to 100%, with higher values indicating a higher density.
Diversity
Land-use mix was defined as heterogeneity in land uses in a given area [18]. Land use data were derived from the Urban Atlas, as described above, and four land-use categories were included, according to categories predetermined by the Urban Atlas: 1) Industrial, commercial, public, military and private units, 2) Residential areas, 3) Green urban areas, and 4) Sports and leisure facilities. Land-use mix was measured by means of an entropy index (Eq. 1). This entropy index is normalized using the natural logarithm of the number of land uses, and multiplied by 100 [36]. The entropy index was obtained per administrative neighbourhood and ranged from 0 to 100, with higher values indicating higher diversity.

Design
Traffic signal density was obtained by neighbourhood audit using the validated SPOTLIGHT-Virtual Audit Tool (S-VAT) [33]. The S-VAT enabled a standardised exposure assessment for cross-country comparison, and was based on existing tools [33]. For the current study, two parameters of traffic signal density were available: 1) Traffic calming devices, including speed humps, traffic islands, roundabouts and traffic lights, and 2) Pedestrian crossings, including zebra-paths and traffic lights. The criterion validity of these elements were very high (range: 89.9–96.9%), inter-observer reproducibility was good to excellent (range 68.8–95.3%), intra-observer reproducibility was excellent (89.8–96.9%) [33]. All streets in the residential neighbourhood were audited, as per availability of Google Street View data at the time of the study. The count of traffic calming devices and pedestrian crossings was obtained per street segment during the audit. The proportion of street segments with at least one traffic signal compared to the total number of street segments was calculated within each administrative neighbourhood. The traffic signal density ranged from 0 to 100, with higher values indicating higher traffic signal density.
Demand management
Parking data were obtained in May 2018 from OpenStreetMap (OSM), an open data source where non-commercialised users uploaded data in an online map. The purpose of OSM is to provide a free and editable map at global scale, with local knowledge and expertise. Data collection methods include field audits but also remote sensing, depending on data availability and the choices by the uploader, leading to heterogeneity in data quality. Notwithstanding these limitations, OSM provides data that are not available from traditional GIS sources on a global scale. All available parking facilities identified in OSM were off-street parking facilities. Two variable types were used for parking facilities across the included urban regions: polygons (parking surface in square meter) and point locations (x, y coordinates of parking facilities). To harmonize surfaces and locations across countries, polygons were transformed to centroid point locations, in ArcGIS version 10.6. The proportion of the total number of parking locations to the total surface area was calculated per administrative neighbourhood. Parking density was expressed as the number of parking locations per km2.
Individual characteristics
Age, sex, employment status, household composition, and education were obtained from the SPOTLIGHT survey. Employment was categorized into currently employed, currently not employed or retired. Household composition was categorized into household with 1-person, 2-persons or 3-or-more persons. Education was self-reported in the survey with multiple but differing categories in each country [32]. We combined these categories to classify the education level of participants as either higher (college or university level) or lower (below college level).
Car use
Self-reported car driving minutes per week were assessed in the online SPOTLIGHT survey. The survey collected information on mode of transportation in commuting and non-commuting trips, average duration of commute and non-commute per day and how many days per week these trips were taken. For this study, trip durations per day for commuting and non-commuting trips were summed. The total weekly car minutes were calculated by multiplying the questions ‘the number of days per week commute by car/moped in the last seven days’ and ‘the time spent (minutes/hours) on one of those days’. Car driving minutes per week were included in the analyses as a continuous variable. We performed sensitivity analyses to investigate differences in associations between individual and neighbourhood variables and car use, stratified by commuting and non-commuting travel (Additional file 3: Table S3).
Statistical analysis
Socio-demographic and neighbourhood characteristics were summarized as proportions, means and standard deviations. Characteristics were presented for the total sample and by country.
To assess the associations between individual and neighbourhood environmental characteristics with car driving (min/week), linear mixed model analyses were performed, adjusted for clustering within neighbourhoods by adding a random intercept on neighbourhood level to the models. Non-standardised regression coefficients (β) and 95% Confidence intervals (95%CI) were reported as effect estimates. An intra-class correlation coefficient (ICC) was calculated according to the formula: varianceneighbourhood /(varianceindividual + varianceneighbourhood). For continuous variables deviations from linearity were checked, but none were detected.
To assess the relative contributions of individual- and neighbourhood level characteristics to the variance in car driving minutes per week, we first constructed an unconditional model without predictors to assess the total unexplained variance. Three conditional models were then constructed separately: Model 1 including individual-level variables, Model 2 including neighbourhood environmental-level variables, and Model 3 including both. Explained variance was calculated in these three models relative to the unconditional model, according to methods by Snijders & Bosker [38]. As neighbourhood-level determinants cannot explain variance in an individual level outcome, the variance component is split into individual-level car driving minutes per week (explained by individual level determinants) and neighbourhood level car driving minutes per week (explained by individual and neighbourhood level determinants). To compare the proportion of variance explained by individual characteristics, neighbourhood characteristics and both, we assessed the total model performance by looking at the reduction in unexplained variance for the total model. The total unexplained variance was a sum of the unexplained variance components on individual and neighbourhood level, divided by the total unexplained variance in the unconditional model. This resulted in a percentage variance reduction to compare the model performance when adding individual and neighbourhood characteristics. Second, we compared individual and neighbourhood characteristics in explaining the variation in neighbourhood level car driving. As a sensitivity analyses, the models were stratified by country to identify country specific patterns. Analyses were performed in STATA version 14.
Results
Descriptive statistics are summarized in Table 2. Participants were on average 51.1 ± 15.9 years old, slightly more often female (54.9%) than male and employed (57.4%) than unemployed or retired. The total sample (n = 6.037) was similar to the study population in age, gender distribution, and household composition, but relatively fewer were currently employed, and fewer highly educated. Participants spend approximately 266 (±322) minutes per week in car driving. The ICC was 0.12, indicating clustering of car driving time within neighbourhoods. Descriptive statistics of neighbourhood characteristics per neighbourhood are included in Additional file 4: Table S4.
Individual and neighbourhood characteristic associated with car driving
Each additional year of age (β: 1.47, 95%CI: 0.60; 2.33), male sex (β: 42.4, 95%CI: 24.7; 61.7), employed, compared to unemployed, (β:80.1, 95%CI: 53.6; 106.5) and living in households of ≥3 persons, compared to a one-person household (β: 47.4, 95%CI: 20.6; 74.2) were associated with more minutes of driving per week. Education was not significantly associated with minutes of driving per week (Table 3).
Higher residential density (β: -2.61, 95%CI: − 4.99; −0.22) and higher land use mix (β: -3.73, 95%CI: − 5.61; −1.86) were significantly associated with fewer minutes of driving per week. Road density, parking supply and traffic signal density were not significantly associated with minutes of driving per week (Table 3).
For non-commute trips, the same associations were observed as in all trips, although residential density became just non-significant. For commute trips, we observed that mainly males and those who were employed were likely to drive, while age and household composition were not significantly associated anymore. On the neighbourhood level, the similar associations were observed (Additional file 3: Table S3).
Variance explained by individual and neighbourhood characteristics
All variables in the model reduced the total model unexplained variance by 5%, where individual-level characteristics accounted for 2% and neighbourhood-level characteristics for 3%. Variation in neighbourhood-level car driving was explained for 9% by individual characteristics, whereas 30% was explained by adding neighbourhood characteristics (Table 3). This is an indication that variation in car use across neighbourhoods is for a large part determined by neighbourhood characteristics, rather than individual characteristics.
Sensitivity analyses – per country
Neighbourhood clustering in minutes of driving per week was highest in France (ICC = 0.15), and lowest in Belgium and Hungary (ICC = 0.03). The total model unexplained variance reduction was highest in the UK (18%), and lowest in The Netherlands (4%). In the main analyses we observed that this reduction was about twice as large when neighbourhood variables were included. A sensitivity analyses indicated that this was especially the case in Belgium, Hungary and The Netherlands, while adding neighbourhood characteristics made less of a difference in France and the UK (France: 6 to 8%, UK: 15 to 18%).
Neighbourhood level car driving minutes, the explained variance by individual variables ranged from 9% (Hungary) to 44% in the UK, and ranged from 26% in France to 74% in Belgium by the combination of both individual and neighbourhood characteristics (Additional file 5: Table S5).
Discussion
We studied the association of a range of individual and neighbourhood characteristics with reported car driving time across five urban regions in Europe. We investigated which individual- and neighbourhood level characteristics were associated with car driving minutes per week and explored what percentage of variance in car driving minutes per week was explained by individual- and neighbourhood-level characteristics. First, we found that younger age, female sex, being unemployed, and living in a smaller household were associated with less car driving minutes per week, and at the neighbourhood level higher residential density and land-use mix were associated with less car minutes per week. The total model explained 5% of the model variance when neighbourhood and individual characteristics were combined, and these contributed almost equally. Variation in neighbourhood level car use was explained for 9% by individual characteristics, and 30% by both individual and neighbourhood characteristics, indication that variation in car use across neighbourhoods is for a large part determined by neighbourhood characteristics. Previous research on relations between the built environment and car use has mainly been performed in non-European settings. This study confirms key environmental characteristics across Europe, and provides insights into the importance of studying the ways in which the built environment influences behaviour. To our knowledge, our study was the first attempt to assess the importance of neighbourhood characteristics in comparison to individual characteristics in explaining car driving.
Our findings are in line with previous literature reporting that older age, male sex, larger household composition, and being employed are associated with higher car use [4, 11,12,13,14,15]. However, high socioeconomic status was most consistently linked with both car ownership and car use [4, 11,12,13,14,15], while in our study only unemployment was associated with lower car use, but not education. One explanation could be that we lost sensitivity in our education variable, because it was a dichotomous variable. Regarding built environmental characteristics, our study found that higher residential density and land-use mix were statistically significantly associated with lower car use, which is in line with previous research. Compared to elasticities in car use from a meta-analysis including mainly North-American studies (0.9 and 2.2% respectively) [11], this study indicated that a 10% increase in residential density and land use mix were associated with 5.7 and 4.9% lower car use in this cross-European setting. Road density was non-significantly associated with 1.6% lower car use compared to 1.2% in literature [11]. In addition, the findings correspond to studies that observed a positive association between neighbourhood walkability and higher levels of walking or active transport [7,8,9,10]. Walkability indices usually include variables that capture residential density, land-use mix and connectivity, and this study confirms the inverse association for the first two indicators with car use.
The variance explained by the total model (5%) was in line with previous studies. For example, the walkability index explained 8,3% of variation in active transport, whereas individual’s income explained 1.1% [39, 40]. Another study performed in the US and UK found 16% of explained variance in total daily travel distance by individual characteristics, resources for transportation, and neighbourhood characteristics together [12]. No distinction was made between these three variance sources, but the associations for income were stronger for individuals in UK (UK daily vehicle miles β: 5.6, p < 0.05 vs US daily vehicle miles β: 2.4, p < 0.05) and stronger for residential density in US (US daily vehicle miles β: − 8.0, p < 0.05 vs UK daily vehicle miles β: 1.6, p < 0.05). None of these studies made a comparison in variance explained by individual level variables compared to neighbourhood level variables.
The total explained variance of our model was relatively low, which can be explained by two main arguments. First, we included information on residential neighbourhood characteristics, and were not able to include information on the destination characteristics or distance to work in our study, while this may reflect an important incentive of car use [20, 27, 28]. However, despite the additional relevance to study destination environments (such as the working environment), the home environment often is a start and/or end-point, and therefore of importance in transport mode choice. Moreover, the environmental characteristics within the neighbourhood may influence whether individuals use the car for short trips within their neighbourhood. If the neighbourhood environment is supportive to car use, this may enhance car trips for short distances, which could otherwise easily be replaced by active transport forms. Second, exposure misclassification may have led to lower explained variance. In the administrative neighbourhoods that were used for the exposure area, participants could have lived in the middle of their neighbourhood or on the edge [41]. This may have led to exposure misclassification in some individuals. However, because this is likely to be random misclassification across neighbourhoods, associations might have been attenuated, such that in reality associations could be stronger. Also, we may have found a higher variance explained if cost of car use was included. One study in the US included price variables, land use and individual characteristics which resulted in 69% explained variance in transport mode choice [24].
Country specific analyses showed a substantial heterogeneity in explained variance across the five urban areas. The neighbourhood explained variance within countries was much higher than in the overall analyses, probably because the variation between neighbourhoods within the same countries is lower than between countries. Therefore, the percentage of explained variance by neighbourhood characteristics is automatically higher within countries than in the overall analyses. The neighbourhood-level variance component should thus be interpreted to compare between countries, rather than comparing to the overall analyses across countries. In France this variance was low relative to the other countries, which may be an indication of neighbourhood variation being larger in France, and/or of data quality issues, such as the inconsistent OSM data inputs. OSM data is generated by non-commercialised users with varying level of experience and data was potentially entered with varying precision across countries [42]. In addition, parking supply can be defined as on-street parking, off-street parking, or home parking (e.g. households with their own garage or driveway) [43]. Due to limited data availability on private parking spaces, we included only off-street parking, while this may not be a valid reflection of the actual parking supply used at home. Studies demonstrated that the absence of a dedicated parking space at home, and longer walking distance to a parking facility, reduced the probability of car use [17, 44]. On the other hand, households with home parking generally own more cars, tend to make more car trips and are more likely to commute by car [45, 46].
Limitations of this study should be noted. Several potentially relevant environmental characteristics were not available in a harmonised way for all countries under study, such as distance to transit, distance to work, cost of car use, parking cost and parking pressure. Also, destination and route characteristics may be important for car use, which we could not include in our study. As discussed earlier, these factors may have led to a lower explained variance in car driving. Secondly, a potential bias that we could not address is self-selection bias. A recent study suggested that self-selection factors may affect associations between walkability and physical activity (in the residential neighbourhood, but also non-residential areas) [47], and it is likely that this may also apply for drivability. Finally, a study limitation was that our outcome, car minutes per week, was self-reported and the questionnaire item was not validated. However, this measure was available for the large sample and measured in the same way across five countries.
A strength of this study was that it mostly used reliable, high-resolution Europe-wide land use data with uniform standards for all cities, which allowed us to compare land use patterns in different European urban areas [34]. Additionally, generalizability of the results was increased by the assessment of many neighbourhoods, with high- and low density, with high- and low socio-economic status across Europe [32].
Cross validation of our findings in different datasets and on different populations is recommended. Future studies should also consider investigating the addition of other environmental measures such as walkability, and exploring the relation with other outcomes such as passive/active transport ratio, sedentary behaviour, non-communicable diseases, air quality, traffic injuries, and traffic congestions. In addition, studies could focus on a broader conceptualization of drivability by including more or other potential characteristics that may influence drivability, such as distance to transit, distance to work, or assess the drivability at both the home, commuting and the work environment [18], parking pressure [43, 44] and safety.
Conclusion
Younger adults, those unemployed, women and those in smaller households drove less. On the neighbourhood level, higher residential density and land-use-mix were associated with less car driving. Although a large proportion of the model variance remained unexplained, individual and neighbourhood characteristics were similarly important for driving in five European urban areas. This study demonstrates that reducing car use might require a built environment that reduces car dependency by ensuring that relevant destinations are within a reasonable range for people using active transport.
Availability of data and materials
The data is not deposited in publicly available repositories due to the rules of the SPOTLIGHT consortium. The data -or parts of the data- are available to be used by others, but under conditions as specified within the SPOTLIGHT data access committee. For more information, please contact Jeroen Lakerveld (j.lakerveld@amsterdamumc.nl).
Abbreviations
- CVD:
-
Cardiovascular diseases
- GIS:
-
Geographic information systems
- ICC:
-
Intraclass correlation coefficient
- OSM:
-
Open street map
- SES:
-
Socio-economic status
- SPOTLIGHT:
-
Sustainable prevention of obesity through integrated strategies
- S-VAT:
-
SPOTLIGHT virtual audit tool
References
Fiorello D, Martino A, Zani L, Christidis P, Navajas-Cawood E. Mobility data across the EU 28 member states: results from an extensive CAWI survey. Transp Res Procedia [Internet] 2016;14:1104–1113. Available from: http://dx.doi.org/https://doi.org/10.1016/j.trpro.2016.05.181
Warren TY, Barry V, Hooker SP, Sui X, Church TS, Blair SN. Sedentary behaviors increase risk of cardiovascular disease mortality in men. Med Sci Sports Exerc. 2010;42(5):879–85.
Wen LM, Orr N, Millett C, Rissel C. Driving to work and overweight and obesity: findings from the 2003 New South Wales health survey. Australia Int J Obes. 2006;30:782–6.
Ding D, Gebel K, Phongsavan P, Bauman AE, Merom D. Driving: a road to unhealthy lifestyles and poor health outcomes. PLoS One. 2014;9(6):1–5.
Jacobson SH, King DM, Yuan R. A note on the relationship between obesity and driving. Transp Policy [Internet]. 2011;18(5):772–6 Available from: https://doi.org/10.1016/j.tranpol.2011.03.008.
den Braver NR, Lakerveld J, Rutters F, Schoonmade LJ, Brug J, Beulens JWJ. Built environmental characteristics and diabetes: A systematic review and meta-analysis. BMC Med. 2018;16(1).
Sundquist K, Eriksson U, Kawakami N, Skog L, Ohlsson H, Arvidsson D. Social Science & Medicine Neighborhood walkability , physical activity , and walking behavior. Swed Neighborhood Phys Activ ( SNAP ) Study. 2011;72:1266–73.
Reyer M, Fina S, Siedentop S, Schlicht W. Walkability is only part of the story : walking for transportation in Stuttgart. Germany. 2014:5849–65.
Hajna S, Ross NA, Brazeau A, Bélisle P, Joseph L. Associations between neighbourhood walkability and daily steps in adults : a systematic review and meta-analysis; 2015.
Dyck V, Cardon G, Deforche B, Sallis JF, Owen N. Bourdeaudhuij I De. Neighborhood SES Walkability Relat Phys Activ Behav Belgian Adults. 2010;50:74–9.
Ewing R, Cervero R. Travel and the built environment: a meta-analysis. J Am Plan Assoc. 2010;76(3):265–94.
Giuliano G, Dargay J. Car ownership, travel and land use: a comparison of the US and Great Britain. Transp Res Part A Policy Pract. 2006;40(2):106–24.
Bento AM, Cropper ML, Mobarak AM, Vinha K. The effects of urban spation structure on travel demand in the United States. Proc SPIE - Int Soc Opt Eng. 2005;87(3):466–78.
Kuzmyak JR, Pratt R, Douglas GB, Spielberg F. Traveler response to transportation system changes handbook, third edition: chapter 15, land use and site design [internet]. 2003. Available from: https://www.nap.edu/catalog/24727
Ewing R, Cervero R. Travel and the built environment. Transp Res Rec. 1780;2001:87–114.
Schimek P. Household motor vehicle ownership and use : how much does residential density matter ? Transp Res Rec J Transp Res Board. 1990;1552:120–5.
Christiansen P, Engebretsen Ø, Fearnley N, Usterud Hanssen J. Parking facilities and the built environment: impacts on travel behaviour. Transp Res Part A Policy Pract [Internet] 2017;95:198–206. Available from: http://dx.doi.org/https://doi.org/10.1016/j.tra.2016.10.025
Litman T, Steele R. Land Use Impacts on Transport, How Land Use Factors Affect Travel Behavior. Victoria Transp Policy Inst [Internet]. 2017;88 Available from: http://www.vtpi.org/landtravel.pdf.
Zegras C. The built environment and motor vehicle ownership and use: evidence from Santiago de Chile. Urban Stud. 2010;47(8):1793–817.
Yang L, Griffin S, Khaw KT, Wareham N, Panter J. Longitudinal associations between built environment characteristics and changes in active commuting. BMC Public Health. 2017;17:1–8.
van der Heijden R, Molin E, Bos D. Parking at a distance: option for reducing traffic and parking pressure in urban areas? Urban Transp VI. 2000;3.
McCahill CT, Garrick N, Atkinson-Palombo C, Polinski A. Effects of Parking Provision on Automobile Use in Cities. Transp Res Rec J Transp Res Board [Internet]. 2016;2543:159–165. Available from: http://trrjournalonline.trb.org/doi/https://doi.org/10.3141/2543-19
Hamre A, Buehler R. Commuter mode choice and free Car parking, public transportation benefits, showers/lockers, and bike parking at work: evidence from the Washington, DC region. J Public Transp [Internet]. 2014;17(2):67–91 Available from: http://scholarcommons.usf.edu/jpt/vol17/iss2/4/.
Hess DB. Effect of free parking on commuter mode choice: evidence from travel diary data. Transp Res Rec J Transp Res Board. 2007;1753(1):35–42.
Ewing R, Cervero R. Travel and the built environment. J Am Plan Assoc. 2010;76(3):265–94.
Frank LD, Andresen MA, Schmid TL. Obesity relationships with community design, physical activity, and time spent in cars. Am J Prev Med. 2004;27(2):87–96.
Badland HM, Garrett N, Schofield GM. How does car parking availability and public transport accessibility influence work-related travel behaviors? Sustainability. 2010;2(2):576–90.
Mackett RL. Why do people use their cars for short trips? Transportation (Amst). 2003;30(3):329–49.
Park K, Ewing R, Scheer BC, Tian G. The impacts of built environment characteristics of rail station areas on household travel behavior. Cities [internet]. 2018;74(November 2017):277–283. Available from: https://doi.org/https://doi.org/10.1016/j.cities.2017.12.015.
Vasconcelos AS, Farias TL. The effect of parking in local accessibility indicators: application to two different neighborhoods in the city of Lisbon. Int J Sustain Built Environ [Internet] 2017;6(1):133–142. Available from: http://dx.doi.org/https://doi.org/10.1016/j.ijsbe.2017.02.006
Lakerveld J, Brug J, Bot S, Teixeira PJ, Rutter H, Woodward E, et al. Sustainable prevention of obesity through integrated strategies: The SPOTLIGHT projects conceptual framework and design. BMC Public Health. 2012;12(1).
Lakerveld J, Ben Rebah M, Mackenbach JD, Charreire H, Compernolle S, Glonti K, et al. Obesity-related behaviours and BMI in five urban regions across Europe: Sampling design and results from the SPOTLIGHT cross-sectional survey. BMJ Open. 2015;5(10).
Bethlehem JR, Mackenbach JD, Ben-Rebah M, Compernolle S, Glonti K, Bárdos H, et al. The SPOTLIGHT virtual audit tool: a valid and reliable tool to assess obesogenic characteristics of the built environment. Int J Health Geogr [Internet] 2014;13(52):1–8. Available from: https://ij-healthgeographics.biomedcentral.com/track/pdf/https://doi.org/10.1186/1476-072X-13-52?site=ij-healthgeographics.biomedcentral.com
Agency. EE. Towards an urban atlas: Assessment of spatial data on 25 European cities and urban areas. Environmental Issue Report No 30. 2002.
Urban Atlas [Internet]. Available from: http://www.eea.europe.eu/data-and-maps/data/urban-atlas
Bordoloi R, Mote A, Sarkar PP, Mallikarjuna C. Quantification of Land Use Diversity in The Context of Mixed Land Use. Procedia - Soc Behav Sci [Internet]. 2013;104:563–72 Available from: http://linkinghub.elsevier.com/retrieve/pii/S1877042813045412. Accessed May 2018.
Cervero R. Land-use mixing and suburban mobility. Transp Q. 1988;42(3).
Snijders TAB, Bosker RJ. Modeled variance in two-level models. Sociol Methods Res. 1994;22(3):342–63.
Frank LD, Schmid TL, Sallis JF, Chapman J, Saelens BE. Linking objectively measured physical activity with objectively measured urban form: Findings from SMARTRAQ. Am J Prev Med. 2005;28(2 SUPPL. 2):117–25.
Frank LD, Sallis JF, Conway TL, Chapman JE, Saelens BE, Bachman W. Many pathways from land use to health: associations between neighborhood walkability and active transportation, body mass index, and air quality. J Am Plan Assoc. 2006;72(1):75–87.
Duncan DT, Kawachi I, Subramanian SV, Aldstadt J, Melly SJ, Williams DR. Practice of epidemiology examination of how neighborhood definition influences measurements of youths ’ access to tobacco retailers : a methodological note on spatial misclassification. Am J Epidemiol. 2014;179(3):373–81.
Singh SS, Singh J, Singh RH. Assessment of OpenStreetMap data - a review. Int J Comput Appl [Internet]. 2013;76(16):17–20 Available from: http://research.ijcaonline.org/volume76/number16/pxc3890888.pdf.
Guo Z. Home parking convenience, household car usage, and implications to residential parking policies. Transp Policy [Internet]. 2013;29:97–106. Available from: http://dx.doi.org/https://doi.org/10.1016/j.tranpol.2013.04.005. Accessed May 2018.
Golias J, Yannis G, Harvatis M. Off-street parking choice sensitivity. Transp Plan Technol. 2002;25(4):333–48.
Sherman AB. The effects of residential off-street parking availability on travel behavior in San Francisco. J Urban Reg Plan. 2010;1(5):47–58.
Weinberger R. Death by a thousand curb-cuts: evidence on the effect of minimum parking requirements on the choice to drive. Transp Policy [Internet]. 2012;20:93–102. Available from: https://doi.org/10.1016/j.tranpol.2011.08.002.
Howell NA, Farber S, Widener MJ, Allen J, Booth GL. Association between residential self-selection and non-residential built environment exposures. Heal Place. 2018;54(May):149–54.
Acknowledgements
The authors would like to thank all participants who took part in the SPOTLIGHT study and the whole WP3 SPOTLIGHT study group. This study group consists of: Ketevan Glonti, Harry Rutter, Martin McKee (The Centre for Health and Social Change, London School of Hygiene and Tropical Medicine), Helga Bardos, Roza Adany (Department of Preventive Medicine, University of Debrecen), Jean-Michel Oppert, Hélène Charreire, Célina Roda, Thierry Feuillet, Maher Ben-Rebah (Equipe de Recherche en Epidémiologie Nutritionnelle, Université Paris 13), Jeroen Lakerveld, Joreintje Mackenbach (Department of Epidemiology and Biostatistics, EMGO Institute for Health and Care Research, VU Medical Center, Amsterdam), and Ilse De Bourdeaudhuij, Greet Cardon, Sofie Compernolle (Department of Movement and Sport Sciences, Ghent University). The coordinator of the WP3 SPOTLIGHT group is Harry Rutter (Harry.Rutter@lshtm.ac.uk). Coordinator of the SPOTLIGHT project is Jeroen Lakerveld (j.lakerveld@amsterdamumc.nl).
Funding
This work is part of the SPOTLIGHT project funded by the Seventh Framework Programme (CORDISFP7) of the European Commission, HEALTH (FP7-HEALTH-2011-two-stage), Grant agreement No.278186. The content of this article reflects only the authors’ views and the European Commission is not liable for any use that may be made of the information contained therein. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
NdB and JK performed the analyses, interpreted the data and drafted the manuscript. JL, JB, JBe and NdB conceived the idea for the manuscript. The WP3 SPOTLIGHT group (JDM, HR, JMO, SC, JB, JL) developed the questionnaire, research protocol and conducted the data collection. JWRT provided advice on statistical analyses. JL is the guarantor of this work, had full access to all data in the study, and takes responsibility for the integrity of the data and the accuracy of the data analyses. All authors read, provided major revisions and approved the final submitted version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
All participants provided informed consent before the start of the study. The study was approved by the corresponding local ethics committees of participating countries. In Belgium, the study was approved by the ethics committee of Ghent University Hospital, in France by the Commission Nationale de l’Informatique et des Libertés, in Hungary by the Health Science Council, Scientific Research Ethic Committee, in The Netherlands by the Medical Ethics Committee of the VU University Medical Center in Amsterdam, and in the United Kingdom by The London School of Hygiene & Tropical Medicine Ethics Committee.
Consent for publication
N.A.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: Table S1.
Descriptive statistics of total SPOTLIGHT population (n = 6037)
Additional file 2: Table S2.
Geo-FERN framework
Additional file 3: Table S3.
Associations between individual- and neighbourhood environmental characteristics with car driving for commuting and non-commuting (min/week)
Additional file 4: Table S4.
Environmental characteristics per neighbourhood
Additional file 5: Table S5.
Associations between individual and environmental characteristics with car driving (min/week), stratified by country
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
den Braver, N.R., Kok, J.G., Mackenbach, J.D. et al. Neighbourhood drivability: environmental and individual characteristics associated with car use across Europe. Int J Behav Nutr Phys Act 17, 8 (2020). https://doi.org/10.1186/s12966-019-0906-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12966-019-0906-2