
Abstract
Background
Numerous epidemiological studies have evaluated the association between the CDH1 -160C/A polymorphism and the risk of breast cancers. However, these studies have yielded conflicting results. To derive a more precise estimation of this association, this meta-analysis was conducted.
Methods
A comprehensive search using the keywords “CDH1,” “E-Cadherin,” “polymorphism,” “SNP,” and “variant” combined with “breast,” “cancer,” “tumor,” or “carcinomas” was conducted. Pooled odds ratios (ORs) with 95 % confidence intervals (CIs) were appropriately calculated using a fixed effect or random effect model. Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2009 checklist was used for this meta-analysis.
Results
Four publications including five studies were identified. It was found that the CDH1 -160C/A polymorphism was significantly associated with breast cancer risk in the dominant model (CA + AA vs. CC: OR = 1.207, 95 % CI = 1.031–1.412, P = 0.019).
Conclusions
Our meta-analysis demonstrated that the -160C/A polymorphism in the CDH1 gene might contribute to breast cancer susceptibility. Further investigations using a much larger sample including different ethnicities are still needed to verify this association.
Similar content being viewed by others

Background
E-cadherin (CDH1), located on chromosome 16q22.1, is one of the most important tumor suppressor genes encoding an adhesion glycoprotein [1, 2]. Studies showed that CDH1 plays a critical role in intercellular adhesion, cell polarity, cell signaling, and maintenance of normal tissue morphology and cellular differentiation, which is expressed in almost all epithelial cells [3–5]. E-cadherin expression loss has been described in gynecological neoplasias, and CDH1 silencing by promoter methylation has been detected in both cervical and endometrial tumors [6, 7].
Several polymorphisms have been identified within the CDH1 gene, and emerging numbers of studies show that genetic variations within the E-cadherin gene are involved in oncogenesis and development [8–11]. The -160C/A (rs16260) is an important functional SNP located in the promoter region that has significant effects on transcriptional activity in transient transfection studies [8–10]. Previous studies have indicated the association of the -160C/A polymorphism with the risk and progression of various human cancers [4]. However, the polymorphism’s genetic effects vary in different cancer types. Recent epidemiologic studies revealed an increased cancer risk for the A (-160) allele carriers [12–15] and a protective role in gastric cancer [16], while the others showed no significant association [17–21]. Researchers report inconsistent breast cancer results; some studies found no association among -160A allele carriers [17, 22], while others found a significantly increased risk [23]. Cattaneo et al. found A allele carriers significantly increased risk for endometrial cancer [24] but not for cervical and ovarian cancer [24, 25]. Thus, these observations raised a controversial question regarding the significance of -160C/A in cancer pathogenesis, especially in breast cancer. Obviously, an individual study’s statistical power could be very limited for efficient assessment of the -160A allele. Integration of these data sets may provide improved statistical power to detect the significance.
Methods
Publication selection
Studies examining the association between the CDH1 -160C/A polymorphism and breast cancer were systematically searched using the following key words: “CDH1,” “E-Cadherin,” “polymorphism,” “SNP,” and “variant” combined with “breast,” “cancer,” “tumor,” or “carcinomas,” and the studies were identified via an electronic search on PubMed, Elsevier, Springer, Wiley, EBSCO, OVID, and Google scholar. Publication titles and abstracts were carefully reviewed. We also manually searched and verified the references of those retrieved articles to obtain other relevant publications. The last search included results up to July 2014.
Inclusion and exclusion criteria
Studies for further meta-analysis were selected based on the following criteria: (1) original epidemiological studies on the association between the CDH1 promoter polymorphsim and breast cancer patients; (2) case-control studies; (3) studies containing at least two comparison groups (cancer group vs. control group); or (4) detailed genotyping data. For duplicated studies, only those with the largest sample size in our present study were included.
The following criteria to exclude studies were used: (1) studies from which genotype frequencies or alleles could not be obtained; (2) studies on family members; (3) systematic reviews or abstracts; (4) animal studies; (5) non-English language; and (6) <50 cases.
Data extraction
Data were extracted from all eligible studies by two independent reviewers. Discrepancies were resolved by consulting with a third reviewer or the authors’ discussion. For each eligible study, publication details were collected based on the following aspects: name of the first author, year of publication, country of origin, cancer type, sources of control and case groups, genotyping methods for SNP, and the frequency of the genotypes and alleles of the CDH1 -160C/A polymorphism in cases and controls. For studies including subjects of different ethnic groups, data were extracted separately for each ethnic group whenever possible. Finally, PRISMA 2009 checklist (Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med 6(6): e1000097. doi:10.1371/journal.pmed1000097) was used for this meta-analysis.
Statistical analysis
The wild type CC genotype of CDH1 -160C/A SNP was considered as a reference. Pooled effects were calculated for the codominant model (AA vs. CC; CA vs. CC), dominant model (CA + AA vs. CC), and recessive model (AA vs. CC + CA). The Hardy-Weinberg equilibrium (HWE) for each study’s control group was assessed using the goodness-of-fit test (χ 2 or Fisher’s exact test).
The heterogeneity among included studies was evaluated using the Cochran’s Q-test and Higgins’ I 2 statistic. Heterogeneity was defined as low when P ≥ 0.1, according to the Cochran’s Q-test, or when I 2 was less than 50 %, according to the Higgins’ I 2 statistic. A fixed effect model was then applied using the Mantel-Haenszel method. Otherwise, we applied a random effect model using the DerSimonian and Laird method. A pooled odds ratio (OR) with 95 % CI was used to assess the strength of association between the CDH1 -160C/A SNP polymorphism and cancer risk, depending on the heterogeneity of the analysis. A sensitivity analysis was performed to evaluate how robust the pooled effect size was at removing the effects of individual studies. An individual study was suspected to have excessive influence if the point estimate was outside the 95 % CI of the combined effect size after it was removed from the analysis. The potential publication bias among the included studies was assessed using the Egger test and Begg test. Statistical analysis was performed using STATA 11.0 software (Stata Corporation, College Station, TX, USA). All P values were two-sided, with P < 0.05 considered statistically significant.
Results
Literature screening and study selection
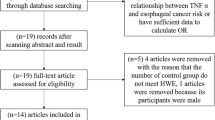
After a preliminary on-line search, 64 potentially relevant articles were identified for further detailed evaluation. Twenty-four articles were selected for full-text review after 40 were excluded by manually screening the titles, abstracts, and key words for review articles, laboratory studies, reduplicated reports, non-English contributions, or those irrelevant to the current analysis. Finally, there were only four papers [17, 23, 24, 26] including five studies (1344 cases and 1569 controls involved) in the pooled analyses (Fig. 1) after 20 studies were excluded because they contained no extractable data, other polymorphism data, or review. Additionally, a list of excluded studies and reasons for exclusions was also provided in Additional file 1.

Flow chart of literature search and selection according to inclusion and exclusion criteria
Study characteristics
The main characteristics and basic information of eligible studies are summarized in Table 1. The studies enrolled 1344 patients from Switzerland, the Czech Republic, Italy, China, and India. Multiple genotyping methods were performed in the studies, including PCR-RFLP, PCR-SSCP, TaqMan PCR, and DNA sequencing. The distribution of genotypes in the controls of all studies was consistent with Hardy-Weinberg equilibrium, except in one study [26]. Then, the association between CDH1 -160C/A SNP and breast cancer risk was analyzed.
Heterogeneity tests
The genotype data for breast cancer in the two studies were homogenous for the codominant genetic model (CA vs. CC: Q-test = 1.55, P = 0.818, I 2 = 0.0 %) and the dominant genetic model (CA + AA vs. CC: Q-test = 2.95, P = 0.566, I 2 = 0.0 %) (Table 2), and the fixed-effects model in these studies was employed. However, heterogeneity was significant for the codominant genetic model (AA vs. CC: Q-test = 8.41, P = 0.078, I 2 = 52.5 %) and the recessive genetic model (AA vs. CC + CA: Q-test = 10.54, P = 0.032, I 2 = 62.0 %) and allele comparison (A vs. C: Q-test = 11.20, P = 0.024, I 2 = 64.3 %), and a random-effects model was performed.
Quantitative data synthesis
In the present study, the relationship between the CDH1 -160C/A polymorphism and breast cancer risk was analyzed. The results revealed significant associations between the CDH1 -160C/A polymorphism and breast cancer in the dominant model (CA + AA vs. CC: OR = 1.207, 95 % CI = 1.031–1.412, P = 0.019) but not in the other four genotype distributions (A vs. C: OR = 1.231, 95 % CI = 0.992–1.528, P = 0.060; AA vs. CC: OR = 1.397, 95 % CI = 0.922–2.116, P = 0.115; CA vs. CC: OR = 1.116, 95 % CI = 0.941–1.325, P = 0.208; AA vs. CC + CA: OR = 1.338, 95 % CI = 0.850–2.105, P = 0.208) (Fig. 2, Table 2).

Forest plots of effect estimates for CDH1 -160 C/A polymorphism in different genetic models. For each of the studies, the boxes and horizontal lines represent the OR and the corresponding 95 % CI; the area of the boxes indicates the weight (inverse of the variance). The diamond corresponds to the summary OR and 95 % CI
Sensitivity analysis
To further reinforce our conclusions, a sensitivity analysis was conducted to assess the results’ stability by sequentially omitting each eligible study. The results showed that no other single study influenced the pooled ORs significantly, indicating that our results were statistically robust (detailed data not shown) (Fig. 3).

Sensitivity analysis by omitting each study to reflect the influence of each study on pooled OR in different genetic models
Publication bias
The studies’ publication biases were assessed using the Begg and Egger tests. The Egger weighted regression method indicated no evidence of publication bias for all genetic models (A vs. C: P = 0.687; AA vs. CC: P = 0.680; CA vs. CC: P = 0.492; AA + CA vs. CC: P = 0.692; AA vs. CC + CA: P = 0.698) (Table 3). This result was confirmed using the Begg rank correlation method (A vs. C: P = 0.462; AA vs. CC: P = 0.806; CA vs. CC: P = 0.221; AA + CA vs. CC: P = 1.000; AA vs. CC + CA: P = 0.806) (Table 3). Hence, there was no obvious publication bias revealed in the current meta-analysis.
Discussion
As a tumor suppressor, E-cadherin expression is frequently reduced or lost in epithelial tumors [3, 5]. This leads to the suboptimal regulation of cell-cell adhesion, loss of cellular polarity, tissue disorganization, tumor progression, and metastasis [3, 4]. Essentially, E-cadherin is the main adhesion molecule of epithelia, its reduced expression being implicated in the epithelial carcinogenic process. Researchers have reported several functional polymorphisms that diminish E-cadherin expression [8–10, 24], among which -160C/A SNP showed transcriptional regulation of the CDH1 gene in different epithelial cell types.
Cattaneo et al. revealed that -160C/A SNP within the CDH1 promoter region is a functional polymorphism that affects transcription efficiency in vitro [24]. By transient transfection experiments, A allele activity was reduced by 54 and 67 % compared to the -160C allele in cervical and in colon cancer cells, respectively [24]. Therefore, the -160A CDH1 promoter variant, associated with reduced gene expression, may be regarded as a possible low penetrance susceptibility allele for epithelial tumors. However, studies about the relation between CDH1 -160C/A polymorphism were various. CDH1 -160A allele carriers have a significantly elevated risk for endometrial cancer [24] but not for cervical cancer and ovarian cancer [24, 25]. Thus, we were interested in resolving the controversial question regarding the significance of CDH1 -160C/A in breast cancer pathogenesis. On this basis, the present meta-analysis study focused on breast cancer.
After critically reviewing the five studies on the CDH1 -160C/A polymorphism (1344 cases total, 1569 control), we performed a comprehensive assessment to investigate the significance of CDH1 -160C/A in breast cancer pathogenesis. The results implied a conspicuously significant relationship between the CDH1 -160C/A polymorphism and breast cancer risk under the dominant genetic model (AA + CA vs. CC, OR = 1.207, P = 0.019).
These results indicated that the -160 AA genotype increased breast cancer risk, which was consistent with results on other cancer types, such as prostate, urothelial, and bladder cancers [27–29]. However, the results were inconsistent with results on colorectal cancer (CRC) [12, 30], which showed that CDH1 -160C/A polymorphisms could reduce CRC risk. These results revealed that the CDH1 -160C/A polymorphism might have different effects on distinct cancers, and this discrepancy may result from different carcinogenesis mechanisms, such as genetic background, environment exposure, dietary habit, race, or family history.
Concerning breast cancer, Yu et al. found that -160A carriers were 30 % more likely to be breast cancer cases than women with -160C carriers [23]. Conversely, Lei et al. genotyped the -160C/A SNP among 576 cases and 348 controls and found no association with breast cancer risk [17]. Our present study revealed that -160A significantly increased breast cancer risk (CA + AA vs CC, OR = 1.207, P = 0.019), which is in good agreement with previous observations on other population samples [17, 31]. However, we enrolled only five studies in the present study. Well-designed, unbiased, and large case-control studies should be performed to acquire a more precise association between the CDH1 -160C/A polymorphism and cancer risk.
As no significant publication bias was revealed in our meta-analysis, sensitivity analysis also revealed that our results were statistically robust. Thus, the results for the association assessed in the present study are relatively convincing since we used a rigorous analytic approach. However, there are still a number of limitations in this meta-analysis.
Firstly, while we identified no publication bias, there is still a possibility that our meta-analysis was biased toward a positive result, since negative results were likely to be unreported. Secondly, our controls were not uniformly defined. Although the healthy population was the main control source, some might be patients with even benign tumors. Thirdly, other factors influencing carcinogenesis should be considered, such as genetic background and environmental and lifestyle factors. Finally, our results had to be interpreted with caution due to unadjusted estimates, so further studies should be conducted to confirm our unadjusted estimates.
Conclusions
In conclusion, these data provided further evidence that the CDH1 -160C/A polymorphism may represent a risk factor for breast cancer development. Further investigations using a much larger sample, with interactions between the environment and genes taken into account, are still needed to elucidate the findings in this meta-analysis.
Abbreviations
PCR-RFLP, polymerase chain reaction-restriction fragment length polymorphism; PCR-SSCP, polymerase chain reaction-single-strand conformation polymorphism; SNP, single nucleotide polymorphisms
References
Kangelaris KN, Gruber SB. Clinical implications of founder and recurrent CDH1 mutations in hereditary diffuse gastric cancer. JAMA. 2007;297:2410–1.
Tamgue O, Chai CS, Hao L, Zambe JC, Huang WW, Zhang B, Lei M, Wei YM. Triptolide inhibits histone methyltransferase EZH2 and modulates the expression of its target genes in prostate cancer cells. Asian Pac J Cancer Prev. 2013;14:5663–9.
Baranwal S, Alahari SK. Molecular mechanisms controlling E-cadherin expression in breast cancer. Biochem Biophys Res Commun. 2009;384:6–11.
Jeanes A, Gottardi CJ, Yap AS. Cadherins and cancer: how does cadherin dysfunction promote tumor progression? Oncogene. 2008;27:6920–9.
van Roy F, Berx G. The cell-cell adhesion molecule E-cadherin. Cell Mol Life Sci. 2008;65:3756–88.
Dong SM, Kim HS, Rha SH, Sidransky D. Promoter hypermethylation of multiple genes in carcinoma of the uterine cervix. Clin Cancer Res. 2001;7:1982–6.
Nishimura M, Saito T, Yamasaki H, Kudo R. Suppression of gap junctional intercellular communication via 5′ CpG island methylation in promoter region of E-cadherin gene in endometrial cancer cells. Carcinogenesis. 2003;24:1615–23.
Li LC, Chui RM, Sasaki M, Nakajima K, Perinchery G, Au HC, Nojima D, Carroll P, Dahiya R. A single nucleotide polymorphism in the E-cadherin gene promoter alters transcriptional activities. Cancer Res. 2000;60:873–6.
Nakamura A, Shimazaki T, Kaneko K, Shibata M, Matsumura T, Nagai M, Makino R, Mitamura K. Characterization of DNA polymorphisms in the E-cadherin gene (CDH1) promoter region. Mutat Res. 2002;502:19–24.
Shin Y, Kim IJ, Kang HC, Park JH, Park HR, Park HW, Park MA, Lee JS, Yoon KA, Ku JL, Park JG. The E-cadherin -347G- > GA promoter polymorphism and its effect on transcriptional regulation. Carcinogenesis. 2004;25:895–9.
Li Y, Tang Y, Zhou R, Sun D, Duan Y, Wang N, Chen Z, Shen N. Genetic polymorphism in the 3′-untranslated region of the E-cadherin gene is associated with risk of different cancers. Mol Carcinog. 2011;50:857–62.
Geng P, Chen Y, Ou J, Yin X, Sa R, Liang H. The E-cadherin (CDH1) -C160A polymorphism and colorectal cancer susceptibility: a meta-analysis. DNA Cell Biol. 2012;31:1070–7.
Govatati S, Tangudu NK, Deenadayal M, Chakravarty B, Shivaji S, Bhanoori M. Association of E-cadherin single nucleotide polymorphisms with the increased risk of endometriosis in Indian women. Mol Hum Reprod. 2012;18:280–7.
Verhage BA, van Houwelingen K, Ruijter TE, Kiemeney LA, Schalken JA. Single-nucleotide polymorphism in the E-cadherin gene promoter modifies the risk of prostate cancer. Int J Cancer. 2002;100:683–5.
Wang Q, Gu D, Wang M, Zhang Z, Tang J, Chen J. The E-cadherin (CDH1) -160C > A polymorphism associated with gastric cancer among Asians but not Europeans. DNA Cell Biol. 2011;30:395–400.
Wu MS, Huang SP, Chang YT, Lin MT, Shun CT, Chang MC, Wang HP, Chen CJ, Lin JT. Association of the -160 C→ a promoter polymorphism of E-cadherin gene with gastric carcinoma risk. Cancer. 2002;94:1443–8.
Lei H, Sjoberg-Margolin S, Salahshor S, Werelius B, Jandakova E, Hemminki K, Lindblom A, Vorechovsky I. CDH1 mutations are present in both ductal and lobular breast cancer, but promoter allelic variants show no detectable breast cancer risk. Int J Cancer. 2002;98:199–204.
Pan F, Tian J, Zhang Y, Pan Y. Lack of association between CDH1 C-160A genetic polymorphism and gastric cancer risk among Asian population. DNA Cell Biol. 2012;31:275–6. author reply 277-279.
Porter TR, Richards FM, Houlston RS, Evans DG, Jankowski JA, Macdonald F, Norbury G, Payne SJ, Fisher SA, Tomlinson I, Maher ER. Contribution of cyclin d1 (CCND1) and E-cadherin (CDH1) polymorphisms to familial and sporadic colorectal cancer. Oncogene. 2002;21:1928–33.
Tsukino H, Kuroda Y, Nakao H, Imai H, Inatomi H, Kohshi K, Osada Y, Katoh T. E-cadherin gene polymorphism and risk of urothelial cancer. Cancer Lett. 2003;195:53–8.
Zhang XF, Wang YM, Ge H, Cao YY, Chen ZF, Wen DG, Guo W, Wang N, Li Y, Zhang JH. Association of CDH1 single nucleotide polymorphisms with susceptibility to esophageal squamous cell carcinomas and gastric cardia carcinomas. Dis Esophagus. 2008;21:21–9.
Beeghly-Fadiel A, Lu W, Gao YT, Long J, Deming SL, Cai Q, Zheng Y, Shu XO, Zheng W. E-cadherin polymorphisms and breast cancer susceptibility: a report from the Shanghai Breast Cancer Study. Breast Cancer Res Treat. 2010;121:445–52.
Yu JC, Hsu HM, Chen ST, Hsu GC, Huang CS, Hou MF, Fu YP, Cheng TC, Wu PE, Shen CY. Breast cancer risk associated with genotypic polymorphism of the genes involved in the estrogen-receptor-signaling pathway: a multigenic study on cancer susceptibility. J Biomed Sci. 2006;13:419–32.
Cattaneo F, Venesio T, Molatore S, Russo A, Fiocca R, Frattini M, Scovassi AI, Ottini L, Bertario L, Ranzani GN. Functional analysis and case-control study of -160C/A polymorphism in the E-cadherin gene promoter: association with cancer risk. Anticancer Res. 2006;26:4627–32.
Li Y, Liang J, Kang S, Dong Z, Wang N, Xing H, Zhou R, Li X, Zhao X. E-cadherin gene polymorphisms and haplotype associated with the occurrence of epithelial ovarian cancer in Chinese. Gynecol Oncol. 2008;108:409–14.
Tipirisetti NR, Govatati S, Govatati S, Kandukuri LR, Cingeetham A, Singh L, Digumarti RR, Bhanoori M, Satti V. Association of E-cadherin single-nucleotide polymorphisms with the increased risk of breast cancer: a study in South Indian women. Genet Test Mol Biomarkers. 2013;17:494–500.
Qiu LX, Li RT, Zhang JB, Zhong WZ, Bai JL, Liu BR, Zheng MH, Qian XP. The E-cadherin (CDH1) -160 C/A polymorphism and prostate cancer risk: a meta-analysis. Eur J Hum Genet. 2009;17:244–9.
Wang L, Wang G, Lu C, Feng B, Kang J. Contribution of the -160C/A polymorphism in the E-cadherin promoter to cancer risk: a meta-analysis of 47 case-control studies. PLoS One. 2012;7:e40219.
Wang Y, Kong CZ, Zhang Z, Yang CM, Li J. Role of CDH1 promoter polymorphism and DNA methylation in bladder carcinogenesis: a meta-analysis. DNA Cell Biol. 2014;33:205–16.
Wang Y, Yang H, Li L, Wang H, Zhang C, Xia X. E-cadherin (CDH1) gene promoter polymorphism and the risk of colorectal cancer: a meta-analysis. Int J Colorectal Dis. 2012;27:151–8.
Sarrio D, Moreno-Bueno G, Hardisson D, Sanchez-Estevez C, Guo M, Herman JG, Gamallo C, Esteller M, Palacios J. Epigenetic and genetic alterations of APC and CDH1 genes in lobular breast cancer: relationships with abnormal E-cadherin and catenin expression and microsatellite instability. Int J Cancer. 2003;106:208–15.
Acknowledgements
The authors declare that no acknowledgements have to be done.
Funding
This work is supported by the National Natural Science Foundation of China (No.81071991, No.81372598), the Natural Science Foundation of Zhejiang Province (No. LZ12H16004, LY14H160039), the Project of Science and Technology of Zhejiang Province (No. 2015C33153), and the Medicine and Health Research Foundation of Zhejiang Province (No. 2013KYA011, 2013KYB022).
Availability of data and materials
The datasets supporting the conclusions of this article are included within the article and its additional files.
Authors’ contributions
YM participated in the design of the study, performed the statistical analysis, and drafted the manuscript. HT conceived of the study and helped to draft the manuscript. DH participated in its design and coordination and helped to draft the manuscript. WW and ZL were responsible for document retrieval. KG and QH participated in data extraction. SJ helped to the statistical analysis. QS performed the manuscript revision. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Not applicable.
Ethics approval and consent to participate
Not applicable.
Author information
Authors and Affiliations
Corresponding authors
Additional file
Additional file 1:
The excluded articles and the reasons for exclusion of the articles. (DOC 46 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Ma, YY., Wu, WQ., Liu, ZC. et al. The CDH1 -160C/A polymorphism is associated with breast cancer: evidence from a meta-analysis. World J Surg Onc 14, 169 (2016). https://doi.org/10.1186/s12957-016-0927-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12957-016-0927-0