
Abstract
Background
The European Organization for research and Treatment of Cancer (EORTC) Core Quality of Life Questionnaire (QLQ-C30) scales are scored on a 4-point response scale, ranging from not at all to very much. Previous studies have shown that the German translation of the response option quite a bit as mäßig violates interval scale assumptions, and that ziemlich is a more appropriate translation. The present studies investigated differences between the two questionnaire versions.
Methods
The first study employed a balanced cross-over design and included 450 patients with different types of cancer from three German-speaking countries. The second study was a representative survey in Germany including 2033 respondents. The main analyses included compared the ziemlich and mäßig version of the questionnaire using analyses of covariance adjusted for sex, age, and health burden.
Results
In accordance with our hypothesis, the adjusted summary score was lower in the mäßig than in the ziemlich version; Study 1: − 4.5 (95% CI − 7.8 to − 1.3), p = 0.006, Study 2: − 3.1 (95% CI − 4.6 to − 1.5), p < 0.001. In both studies, this effect was pronounced in respondents with a higher health burden; Study 1: − 6.8 (95% CI − 12.2 to − 1.4), p = 0.013; Study 2: − 4.5 (95% CI − 7.3 to − 1.7), p = 0.002.
Conclusions
We found subtle but consistent differences between the two questionnaire versions. We recommend to use the optimized response option for the EORTC QLQ-C30 as well as for all other German modules.
Trial registration: The study was retrospectively registered on the German Registry for Clinical Studies (reference number DRKS00012759, 04th August 2017, https://www.drks.de/DRKS00012759).
Similar content being viewed by others

Background
The European Organization for Research and Treatment of Cancer Core Quality of Life Questionnaire (EORTC QLQ-C30) is a 30-item questionnaire and 28 out of 30 items are scored on a 4-point Likert response scale: 1 = not at all, 2 = a little, 3 = quite a bit, and 4 = very much [1]. The German equivalents have been translated as 1 = überhaupt nicht, 2 = wenig, 3 = mäßig, and 4 = sehr [2]. Ideally, multi-item Likert scales should be interval scaled, which assumes equidistance between response options.
Research suggests that the German wording of the EORTC QLQ-C30 response scale, particularly the term mäßig for response category 3 (which in English is supposed to stand for quite a bit), may not be optimal [3, 4]. Based on these findings, we conducted three studies involving students, cancer patients, and adult control subjects (total number of participants N = 334) to investigate the intensity rating of the critical term mäßig relative to intensity ratings of other terms that seemed to be more appropriate for response category 3, such as einigermaßen, überwiegend or ziemlich. The task of the research participants was to rate each term on a 0–100 linear intensity scale (with the anchors 0 = überhaupt nicht [not at all] and 100 = sehr [very much]). The currently used term mäßig yielded an average intensity rating of 42 and thus, was rated substantially lower than the ideal value of 67 (difference − 25). In contrast, ziemlich turned out to be the best choice for response category 3, with mean intensity rating of 71, and it was among the top three terms for response option “3” in each study (see Additional file 1: Appendix Table S1).
Research undertaken by Schwarz and Strack [5, 6] showed that response scales influence respondents’ answers to questions. For example, respondents consistently reported higher frequencies for certain response options on scales with high rather than low frequency response alternatives [5]. Following this logic, we assumed that changes in the current German response format of the EORTC QLQ-C30 items will lead to changes in reported symptom and functioning scores. If mäßig is semantically very close to wenig (in English a little), it does not constitute a reasonable response alternative for patients with a moderate/considerable health problem. They might then tend to skip mäßig and turn to the next higher response alternative sehr (in English very much). Thus, we hypothesized that the current German response scale of the EORTC QLQ-C30 (mäßig version) leads to higher symptom scores and lower functioning scores than an optimized version (ziemlich version) with a category-label 3 that is equidistant between response categories 2 and 4. This effect should be particularly pronounced in patients with considerable health problems. The present pair of studies were designed to test this hypothesis.
Methods
Study 1
Study design and sample size rationale
This study involved patients with different types of cancer. It was a randomized cross-over-design study allowing for within-subject comparisons of the current and updated questionnaire versions. Patients were randomized either to a paper-based or a tablet-based version of the EORTC QLQ-C30 (see Additional file 1: Appendix Figure S1). A commonly accepted rule of thumb recommends a ratio of 10–15 respondents per item [7]. Given that the EORTC QLQ-C30 compromises 30 items, a sample size of 300–450 respondents is adequate. Data were collected between April 2016 and September 2018 at 7 study sites in Germany, Austria, and Switzerland.
Ethical considerations
The study was approved by the Ethical Committee of the University of Regensburg (reference number 14-101-0209) and by local ethical committees of the other study sites. The study was registered on the German Registry for Clinical Studies (reference number DRKS00012759), which is part of the WHO Trial Registration Data Set.
Inclusion and exclusion criteria
Inclusion criteria were histologically confirmed diagnosis of cancer, mentally and physically fit to complete a questionnaire, able to understand German, 18 years of age or above (no upper age limit), and informed consent. Patients who were mentally and physically unfit to complete a questionnaire or denied informed consent were excluded.
Procedure
Patients were approached by a researcher and subsequently informed about the study. After providing written informed consent, patients were randomly assigned to the paper-based or computer-based assessment. The paper version involved the standard two-page EORTC QLQ-C30 questionnaire, in which the response options are numbered from 1 to 4 for each item of the questionnaire, with the appropriate labels appearing at the top of each section. In the electronic version [8], each item is presented separately on screen together with the response options. Regardless of paper version or electronic version, patients were randomly assigned to fill in the questionnaire using conventional German response options (i.e., überhaupt nicht, wenig, mäßig, sehr) of the EORTC QLQ-C30 version 3.0 or using the optimized version in which mäßig was replaced by ziemlich. Patients filled in the questionnaire again at a later point in time, whereby the alternate response option version was presented, and continued with either paper-based or computer-based assessment depending on the assigned study arm. Additionally, patients rated on two anchor variables whether their health/QoL improved, worsened, or remained unchanged between both assessments to ensure that differences between EORTC QLQ-C30 versions within a patient is attributed to questionnaire versions and not real changes in health/QoL.
Study 2
Study design and sample size rationale
The data were collected in 13 European countries, the USA and Canada in the context of an international project to generate European general population norm data for the EORTC QLQ-C30 questionnaire [9, 10]. Sample size per country was based on the following rationale: stratification by sex and age groups (18–39, 40–49, 50–59, 60–69, 70 + years), with a target sample size of each sex x age x country subgroup of n = 100, leading to an anticipated sample size of n = 1000/country. This sampling design was considered sufficient to investigate differential item functioning (DIF) using logistic regression analysis which was at the core of the original study [10]. Data collection was performed by GfK SE (www.gfk.com), a panel research company specialized in representative multinational online surveys. Panel members register voluntarily and generally participate when contacted, resulting in response rates between 75 and 90% [9]. Data were collected in March/April 2017. German respondents were randomly assigned either to the conventional EORTC QLQ-C30 questionnaire version 3.0 (response option 3 = mäßig, n = 1006) or the optimized version (response option 3 = ziemlich, n = 1027).
Ethical considerations
The multinational survey conformed to the common ethical standards by obtaining informed consent from all participants before collecting data completely anonymously. Any identification of the respondents through the authors is impossible. The study thus complies with the EU General Data Protection Regulations as well as with the professional standards of the European Pharmaceutical Market Research Association (EphMRA), which GfK SE is a member of.
Inclusion and exclusion criteria for the present analyses
Respondents were eligible if they provided informed consent. Since these were all registered panel members, all persons contacted were able to read and understand a sufficient level of German and they also had access to a computer, as data collection was done electronically. For the present analyses only respondents from Germany were used.
Procedure
Subjects were contacted by the survey company GfK SE. Samples were stratified with an equal number of men and women, and 5 pre-defined age categories, i.e., 18–39 years, 40–49, 50–59, 60–69, and 70 years and above, resulting in n = 200 per age/sex stratum. As part of the online panel, respondents were asked to complete the 30 items of the EORTC QLQ-C30 [10]. Comparable to study 1, each item was presented separately on screen.
Statistical analyses
EORTC QLQ-C30 scales were computed according to the EORTC Scoring Manual [11]. In a first step, all scales were linearly transformed (0–100), so that for the five functioning scales, higher scores represent higher functioning and for the nine symptom scales, higher scores represent higher symptom burden. In a second step, a summary score was calculated, consisting of 13 out of the 15 scales, excluding financial difficulties and global health status/quality-of-life. For this summary score, the symptom scales were reversed, so that 0 represents lowest and 100 highest QoL [12].
We employed the following strategy in using and interpreting scale results: we first had a look at the statistically significant difference (p value < 0.05) in the summary score. If a significant difference was obtained, we inspected significant differences with regard to the 14 single symptom or functioning scales. This strategy was chosen in order to address multiplicity issues. To determine clinically meaningful differences we used the conservative 5 point criterion (small difference) [13].
The core analyses related to differences between the conventional EORTC QLQ-C30 version (mäßig) and the optimized EORTC QLQ-C30 version (ziemlich) and included univariable analyses of the unadjusted means (t tests) as well as multivariable analyses. More specifically, two separate analyses were conducted on the cancer patient sample: between-subject and within-subject comparisons. For between-subject comparisons, responses to both questionnaire versions of the first assessment were compared using analyses of covariance (ANCOVAs) adjusted for sex, age, mode of administration (MOA, paper vs. electronic), and health burden. Health burden was defined by the EORTC QLQ-C30 scale global quality-of-life: < 50 (worse QoL) vs. ≥ 50 (better QoL) [14, 15].
For within-subject comparisons, mixed linear models were used: subject as random factor, questionnaire version as repeated factor and the following set of fixed factors: questionnaire version, MOA, order of questionnaire versions, sex, age, and health burden. The mixed linear models included only patients who reported no changes in QoL and health between both assessments on the two anchor questions.
In the German population sample, differences between the two EORTC QLQ-C30 versions were assessed using ANCOVAs adjusted for sex, age, and health burden.
Parametric methods were used for all analyses due to their robustness to violations of non-normality, which is occasionally the case with QoL data [16].
Furthermore, according to classical test theory, basic psychometric performance (internal consistency [17] as well as convergent and discriminant validity [18, 19]) of both EORTC QLQ-C30 versions were explored (see Additional file 1: Appendix Basic psychometric properties and Table S2).
Statistical analyses were carried out using SPSS 25. Statistical tests were two-sided and were done at the 0.05 significance level. Descriptive statistics included the following: frequencies (n), percentages (%), means (m), standard deviations (sd), 95% confidence intervals (CI), medians (med), interquartile ranges (IQR).
Results
Study 1
In total, 467 patients were recruited. Seventeen patients were excluded from analyses due to the following reasons: physically or mentally unfit (n = 10), declined participation during first assessment (n = 5), and study data were overwritten due to technical issues (n = 2). Thus, data of 450 patients (median age = 63 years, 46% females) were available (Table 1). A second assessment could be obtained in 404/450 patients (90%), which is a high completion rate for second assessment [20]. The median gap between the two assessment points was 4 days (IQR = 2/7) (Additional file 1: Appendix Figure S1). Accidently, four patients responded twice to the same questionnaire version and had to be excluded for test–retest analyses.
In the first step, we analyzed differences in EORTC QLQ-C30 scores between patients who received either the mäßig or ziemlich version at the first assessment. As shown in Table 2, the unadjusted analysis showed no significant differences in the summary score between the two questionnaire versions (mean = 70.1, sd = 19.9 vs. m = 73.0, sd = 18.6; p = 0.116). Multivariable analyses adjusted for age, sex, MOA, and health burden, showed a mean difference of − 4.5 (95% CI − 7.8 to − 1.3) in the summary score (p = 0.006), such that the mäßig-version yielded lower scores (poorer QoL) than the ziemlich-version (Table 3). Mean differences for all 14 scale scores were in the expected direction (i.e., higher symptoms and lower functioning in the mäßig- than in the ziemlich-version), with four showing a statistically significant difference (p values < 0.05) (Table 3), and all were > 5 score points.
When taking a closer look at patients with considerable health burden (global QoL < 50 points, n = 144), the differences between the mäßig and ziemlich versions became particularly pronounced, i.e., the mean difference in the summary score was − 6.8 (95% CI − 12.2 to − 1.4, p = 0.013), whereas it was only − 2.3 (95% CI − 5.9 to 1.4, p = 0.226) in patients with lower/no health burden (global QoL ≥ 50 score points, n = 306; Table 3). In addition, four of the 14 single scales of patients with higher health burden yielded statistically significant differences. The four single scales as well as the total score were > 5 score points.
The next step were within-group comparisons in patients who did not indicate a change in their health and QoL between assessments (n = 229). Univariable analyses showed a lower summary score in the mäßig (m = 75.1, sd = 18.3) than ziemlich version (m = 77.4, sd = 16.8; p < 0.001, Table 2). Furthermore, we observed corresponding statistically significant mean differences in four of the 14 single scales (p values < 0.05); however, none was > 5 points.
In multivariable analyses (Table 3), we again found a larger difference in the summary score between both versions in the group of patients with considerable health burden (− 4.8, 95% CI − 6.9 to − 2.8, p < 0.001, global QoL < 50, n = 57) compared to patients with lower/no health burden (− 1.4, 95% CI − 2.6 to − 0.2, p = 0.022, global QoL ≥ 50, n = 172). Furthermore, 7 out of 14 scale differences in the higher health burden group were statistically significant and all differences exceeded the 5 score point criterion.
In addition to the comparison of the two EORTC QLQ-C30 versions, the study design further allows for the comparison between paper-based and computer-based assessment of the questionnaire. Subgroup analyses revealed that differences between the both versions were more pronounced in the computer-based version than in the paper-based version (Table 3). However, the 5 score point criterion was only exceeded in the between-group comparison within the computer-based assessment.
Study 2
German respondents were randomly assigned either to the conventional EORTC QLQ-C30 questionnaire version 3.0 (response option 3 = mäßig, n = 1006) or the optimized version (response option 3 = ziemlich, n = 1027).
Participants in study 2 comprised of a representative sample of the German general population surveyed in the context of a large-scale international online norm data survey [9]. As shown in Table 4, the median age was 54 years, 50% were female and most participants (58%) reported at least one disease.
As shown in Table 2, the unadjusted analysis showed a significantly higher summary score for the optimized EORTC QLQ-C30 version compared with the conventional EORTC QLQ-C30 version (m = 83.6, sd = 15.9 vs. m = 82.0, sd = 17.7; p = 0.038). Multivariable analyses adjusted for age, sex, and health burden yielded even stronger effects: the mean difference of the summary score was − 3.1 (95% CI − 4.6 to − 1.5; p < 0.001, Table 3), and 9 out of 14 single scales showed statistically significant differences, i.e., p values < 0.05. None of the observed differences reached 5 points or more (Table 3).
When taking a closer look at respondents with considerable health burden (n = 370, global QoL < 50) versus those with lower/no health burden (n = 1663, global QoL ≥ 50), the difference in the summary score between both versions was more pronounced in the high burden group (− 4.5, 95% CI − 7.3 to − 0.17, p = 0.002) than in the low burden group (− 1.6, 95% CI − 2.9 to − 0.3, p = 0.016, Table 3). In the higher health burden group, 8 out of 14 differences in single scales were statistically significant, and 7 of these differences exceeded the 5 point criterion.
Significant and minimally important differences between conventional and optimized EORTC QLQ-C30 versions are summarized up in Additional file 1: Appendix Table S3.
Choice of response options in the mäßig and in the ziemlich questionnaire versions (Studies 1 and 2)
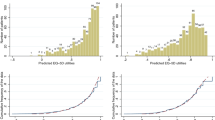
We collapsed the total number of responses for response options 1, 2, 3 and 4 across the 27 items that made up the summary score and compared their distributions between the questionnaire versions in studies 1 and 2 (Fig. 1 and Table 5).

Frequencies of chosen response option—German population and cancer patients’ first assessment. The EORTC QLQ-C30 questionnaire was presented in two versions. The conventional questionnaire used mäßig and the optimized version used ziemlich as response option 3 (quite a bit) of the 4-point Likert scale. Responses to each response option (1–4) are presented for the total sample and are further separated for (1) subjects with QoL < 50 and QoL ≥ 50 as well as for (2) questionnaire version with response option mäßig and questionnaire version with response option ziemlich. German population: A total of N = 54,891 responses were given from N = 2033 respondents to items 1–27 (no missing responses). Cancer patients: At first assessment, a total of N = 12 089 responses were given from N = 450 patients to items 1–27 (missing responses n = 61 [0.5%])
Looking at Study 2 and analyzing responses (N = 54,891) of all respondents (N = 2033) (Fig. 1), it appeared that frequencies in response option 1 (überhaupt nicht [not at all]) were practically identical in the mäßig and ziemlich versions (61.9% and 62.3%, respectively). However, the introduction of the term ziemlich modified the meaning of the entire scale and consequently the choice of the remaining response options 2, 3, and 4. Firstly, as expected, the response option 4 (very much) was used more frequently in the mäßig version than in the ziemlich version 5.1% versus 3.2%. Secondly, the difference between the percentage of respondents choosing options 2 and 3 was 12.9% in the mäßig version, and 15.9% in the ziemlich version.
These two effects were particularly pronounced in respondents with a poor general health status (global QoL < 50). While 19% percent of these respondents chose the highest response option 4 (very much) in the mäßig condition, only 11.3% chose this response option in the ziemlich condition. Furthermore, in the ziemlich version, response options 2 and 3 were more distinct (6.0% difference) than in the mäßig condition, showing a 2.4% difference.
Comparable effects were obtained in the first assessment sample of study 1 (Fig. 1).
Further analyses included cancer patients who answered both versions consecutively and reported no health changes between the two assessments (n = 229, Table 5). While there was a high overlap of 83.6% in choosing response option 1 (not at all) across the two versions, overlap for the other 3 response options was considerably lower, i.e., 60.1%, 45.2%, 44.6%, respectively.
That is, 39.3% of respondents who chose response option 4 (very much) in the mäßig-version switched to option 3 (= quite a bit) in the ziemlich-version (Table 5). This effect was particularly pronounced in patients with good health (QoL ≥ 50) who switched in 43.5% of the cases, whereas this percentage was only 37.0% in patients with higher health burden (QoL < 50) (data not shown).
Discussion
Based on the observation that response options are not equidistant in the German version of the EORTC QLQ-C30, the main aim of this research was to test the hypothesis that the current German response option 3 is suboptimal and may bias results towards the worse end of the scale, i.e., worse/lower functioning and higher symptoms.
As hypothesized, the main finding of the present studies is that the optimized EORTC QLQ-C30 version yielded slightly lower symptom and higher functioning scores. The magnitude of mean differences in adjusted multivariable analyses was 4.5 (cancer patients, between-group comparison, n = 450), 3.1 (cancer patients, within-group comparison, n = 229), and 3.1 (German reference sample, n = 2033). This effect became particularly pronounced when we had a closer look at respondents with a high health burden: 6.8, 4.8, and 4.5 mean difference in score points, respectively. These values are at the lower end of Osoba’s widely cited 5–10 point difference criterion for minimal important clinical changes on the EORTC QoL scales [13]. These effects were not only obtained for the summary scale, but also for numerous of the single scales of the EORTC QLQ-C30. The scale that showed the highest proportion of significant differences was physical functioning, followed by appetite loss, role functioning, emotional functioning, and fatigue.
This effect can be interpreted through a psychological theory which posits that scaling labels are of informational value for respondents, guiding them to understand the question and to elicit the most “appropriate” answer in a given context [5, 6]. In the mäßig-version, mäßig (response option 3) is semantically very close to response option 2 (wenig = a little), but considerably far apart from response option 4 (sehr = very much). Therefore, respondents may have problems to differentiate between wenig and mäßig and have an inclination to choose sehr (very much), particularly when they suffer from an impaired health status. Introducing ziemlich changed the entire response environment, as it lies more equally balanced between response options 2 (a little) and 4 (very much). Thus, the response options have a clearer meaning, now rendering ziemlich (quite a bit) a worthwhile option in the case of health problems and making sehr (very much) less attractive.
This interpretation is in line with the pooled frequencies of each of the four response options across 27 questionnaire items. We saw that the differences in frequencies between mäßig and wenig are less pronounced than between wenig and ziemlich. Furthermore, for respondents with high health burden, sehr (very much) was regularly an appropriate response option in the mäßig-version, and much more so than in the ziemlich-version where ziemlich was still considered an adequate reflection of their perceived health status.
Furthermore, we investigated the possibility of potential differences between the paper-based and the computer-based assessment. In the computer-based assessment each item is presented individually at the screen together with the response labels, whereas in the paper version the response labels are shown only at the very beginning of the questionnaire. There is reason to believe that these differences in the presentation format may amplify the wording effect, and this effect becomes more pronounced in the computer-based assessment. We found some indication for this sort of amplification, but it was not as strong and as consistent as one might expect.
Adopting a broader perspective outside the peculiarities of response labels in specific language versions (in this case German), the implications of this project are twofold.
Firstly, this project is a good example of how quality assurance can be done in the field of patient-reported outcomes instruments. To date, only few examples have been published in this area. Quality assurance projects have focused on paper-based versus electronic assessment (particularly migration of the former to the latter) [21], translation and linguistic validation [2], or compliance with regulators’ (FDA, EMA) perspectives on outcome assessment [22, 23]. We are not aware of a study like this that systematically called into question existing response options and made a head-to-head comparison between two questionnaire versions.
Secondly, this project is also a timely reminder that psychological processes play a crucial role in QoL assessment. QoL research is preoccupied with psychometrics, statistical models, and technical details, at the expense of analyzing the dynamics underlying the interplay between the responder and the questionnaire. In order to understand and interpret answers to questionnaires correctly, a thorough analysis of the cognitive and emotional underpinnings is essential. Ultimately, questionnaires are communication tools that are of value only if the questionnaire developer, the sender (i.e., the patient) and the receiver (i.e., the researcher or clinician) of the information are on the same page.
Limitations of the study may relate to the use of the EORTC QLQ-C30 summary score. An argument can be reasonably made, that this summary score is composed of many and diverse QoL aspects rendering it difficult to interprete and thus, meaningless for use in clinical studies. In fact, many clinical studies are often based on well-defined hypotheses and therefore focus on specific QoL scales or side effects. A strength of the summary score comes into play, when a hypothesis with regard to a specific scale is not at the core: it avoids problems connected with exploratory multiple statistical testing of numerous QoL scales (“p-hacking”). This property motivated the creation of the summary score in the first place and this was also a reason why we made use of it. We expected to see differences between the two questionnaire versions without being able to specify beforehand which of the available 14 single scales would show the hypothesized effects. Therefore, our analysis strategy was to have a look at the summary scale first, and only in case of a significant effect, the single scales were explored further. It should be noted that the EORTC Quality of Life Group is in the process of exploring the potential of the summary score and is about to prepare a guideline on its use.
A further limitation of the present analyses lies in their exclusive use of methods of classical test theory. We acknowledge the conceptual and statistical superiority of item response theory (IRT), which is used by the EORTC Quality of Life Group particularly in the construction of item sets for computer adaptive testing [24]. To obtain reliable results, IRT analyses require larger sample sizes than were available here. Additional studies focusing on the measurement properties of the updated questionnaire including a wider range of methodological approaches are desirable.
Conclusion
Our starting point was that the German translation of the quite a bit response category was not located at the right place according to the assumption of equidistance. This pair of studies tested a revised response option, confirming that the revised version solves the problem, and should therefore be used in the future.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- ANCOVA:
-
Analysis of covariance
- EORTC QLQ-C30:
-
European Organization for Research and Treatment of Cancer Quality of Life Questionnaire-Core
- Fig:
-
Figure
- GfK SE:
-
Growth from Knowledge Societas Europaea
- IQR:
-
Interquartile range
- MOA:
-
Mode of assessment
- QoL:
-
Quality of life
- 95% CI:
-
95% Confidence interval
References
Aaronson NK, Ahmedzai S, Bergman B, Bullinger M, Cull A, Duez NJ, et al. The European Organization for Research and Treatment of Cancer QLQ-C30: a quality-of-life instrument for use in international clinical trials in oncology. J Natl Cancer Inst. 1993;85(5):365–76.
Kuliś D, Bottomley A, Velikova G, Greimel E, Koller M. EORTC quality of life group translation procedure; 2017. https://www.eortc.org/app/uploads/sites/2/2018/02/translation_manual_2017.pdf.
Rohrmann B. Empirische Studien zur Entwicklung von Antwortskalen für die sozialwissenschaftliche Forschung [Empirical studies on the development of response scales for social science research]. Zeitschrift für Sozialpsychologie. 1978;9:222–45.
Scott NW, Etta JA, Aaronson NK, Bottomley A, Fayers PM, Groenvold M, et al. An evaluation of the response category translations of the EORTC QLQ-C30 questionnaire. Qual Life Res. 2013;22(6):1483–90.
Schwarz N. What respondents learn from scales: the informative functions of response alternatives. Int J Public Opin Res. 1990;2(3):274–85.
Schwarz N, Strack F. Evaluating one's life: a judgment model of subjective well-being; 1988 [cited 2021 Mar 12]. https://nbn-resolving.org/urn:nbn:de:0168-ssoar-66552.
Tabachnick BG, Fidell LS. Using multivariate statistics. 5th ed. Boston: Pearson/Allyn and Bacon; 2010.
Holzner B, Giesinger JM, Pinggera J, Zugal S, Schöpf F, Oberguggenberger AS, et al. The Computer-based Health Evaluation Software (CHES): a software for electronic patient-reported outcome monitoring. BMC Med Inform Decis Mak. 2012;12(126):1–11.
Nolte S, Liegl G, Petersen MA, Aaronson NK, Costantini A, Fayers PM, et al. General population normative data for the EORTC QLQ-C30 health-related quality of life questionnaire based on 15,386 persons across 13 European countries, Canada and the Unites States. Eur J Cancer. 2019;107:153–63.
Liegl G, Petersen MA, Groenvold M, Aaronson NK, Costantini A, Fayers PM, et al. Establishing the European Norm for the health-related quality of life domains of the computer-adaptive test EORTC CAT Core. Eur J Cancer. 2019;107:133–41.
Fayers PM, Aaronson NK, Bjordal K, Groenvold M, Bottomley A. The EORTC QLQ-C30 scoring manual. 3rd ed. Brussels: EORTC Quality of Life Group; 2001.
Giesinger JM, Kieffer JM, Fayers PM, Groenvold M, Petersen MA, Scott NW, et al. Replication and validation of higher order models demonstrated that a summary score for the EORTC QLQ-C30 is robust. J Clin Epidemiol. 2016;69:79–88.
Osoba D, Rodrigues G, Myles J, Zee B, Pater J. Interpreting the significance of changes in health-related quality-of-life scores. J Clin Oncol. 1998;16(1):139–44.
Koller M, Lorenz W. Quality of life: a deconstruction for clinicians. J R Soc Med. 2002;95(10):481–8.
Klinkhammer-Schalke M, Koller M, Steinger B, Ehret C, Ernst B, Wyatt JC, et al. Direct improvement of quality of life using a tailored quality of life diagnosis and therapy pathway: randomised trial in 200 women with breast cancer. Br J Cancer. 2012;106(5):826–38.
Knief U, Forstmeier W. Violating the normality assumption may be the lesser of two evils. Behav Res Methods. 2021. https://doi.org/10.3758/s13428-021-01587-5.
Nunnally JC. An overview of psychological measurement. In: Wolman BB, editor. Clinical diagnosis of mental disorders. Boston: Springer; 1979. p. 97–146.
Hays RD, Hayashi T, Carson S, Ware JE. User’s guide for the Multitrait Analysis Program (MAP). Santa Monica: RAND Corporation; 1988.
Hays RD, Hayashi T. Beyond internal consistency reliability: rationale and user’s guide for Multitrait Analysis Program on the microcomputer. Behav Res Methods Instrum Comput. 1990;22(2):167–75.
Fayers PM, Machin D. Quality of life: the assessment, analysis, and reporting of patient-reported outcomes, 3rd edn. Chichester, West Sussex, UK, Hoboken, NJ: John Wiley & Sons Inc; 2016. http://search.ebscohost.com/login.aspx?direct=true&scope=site&db=nlebk&AN=1103660.
Kuliś D, Holzner B, Koller M, Ruyskart P, Itani A, Williams P et al. Guidance on the implementation and management of EORTC quality of life instruments in electronic applications; 2018 [cited 2021 Mar 12]. https://qol.eortc.org/app/uploads/sites/2/2018/03/ePRO-guidelines.pdf.
Food and Drug Administration. Guidance for industry patient reported outcome measures: use in medical product development to support labeling claims: FDA-2006-D-0362; 2009 [cited 2021 Mar 12]. https://www.fda.gov/regulatory-information/search-fda-guidance-documents/patient-reported-outcome-measures-use-medical-product-development-support-labeling-claims.
European Medicines Agency. Reflection paper on the regulatory guidance for the use of health-related quality of life (HRQL) measures in the evaluation in medicinal products; 2005 [cited 2021 Mar 12]. https://www.ema.europa.eu/en/documents/scientific-guideline/reflection-paper-regulatory-guidance-use-healthrelated-quality-life-hrql-measures-evaluation_en.pdf.
Petersen MA, Aaronson NK, Conroy T, Costantini A, Giesinger JM, Hammerlid E, et al. International validation of the EORTC CAT Core: a new adaptive instrument for measuring core quality of life domains in cancer. Qual Life Res. 2020;29(5):1405–17.
Acknowledgements
We are grateful to Monika Schöll for her linguistic editing of this article.
Funding
Open Access funding enabled and organized by Projekt DEAL. Funding was provided by the EORTC Quality of Life Group to the first author (Response scales v3 009 2012).
Author information
Authors and Affiliations
Consortia
Contributions
MK, KM, BH and AB made substantial contributions to the conception and design of the work. HS, CH, UM, AB, DE, JM, MS, SN, and KM contributed to data acquisition. MK and KM analyzed and interpreted the analyses and were the major contributor in writing the manuscript. SN, BH, MG, DK, and AB interpreted data and revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics and consent to participate
Study 1 was approved by the Ethical Committee of the University of Regensburg (reference number 14-101-0209) and by local ethical committees of the other study sites. Cancer patients were included after obtaining written informed consent. Study 2 was based on data from a norm data survey conducted by GfK SE (www.gfk.com). Panel members registered voluntarily and consented to be involved. The study complied with the EU General Data Protection Regulations as well as with the professional standards of the European Pharmaceutical Market Research Association (EphMRA).
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. Appendix Table S1. Summary of the main results of the experimental response option studies. Appendix Basic psychometric properties. Appendix Table S2. Internal consistency, convergent and discriminant validity for multi-item scales of the EORTC QLQ-C30 conventional and optimized questionnaire version. Appendix Table S3. Summary of significant and minimally important differences between QLQ-C30 versions across all analyses. Appendix Figure S1. Design of study 1.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Koller, M., Müller, K., Nolte, S. et al. Investigating the response scale of the EORTC QLQ-C30 in German cancer patients and a population survey. Health Qual Life Outcomes 19, 235 (2021). https://doi.org/10.1186/s12955-021-01866-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12955-021-01866-x