
Abstract
Background
In 2015, the Zika virus spread from Brazil throughout the Americas, posing an unprecedented challenge to the public health community. During the epidemic, international public health officials lacked reliable predictions of the outbreak’s expected geographic scale and prevalence of cases, and were therefore unable to plan and allocate surveillance resources in a timely and effective manner.
Methods
In this work, we present a dynamic neural network model to predict the geographic spread of outbreaks in real time. The modeling framework is flexible in three main dimensions (i) selection of the chosen risk indicator, i.e., case counts or incidence rate; (ii) risk classification scheme, which defines the high-risk group based on a relative or absolute threshold; and (iii) prediction forecast window (1 up to 12 weeks). The proposed model can be applied dynamically throughout the course of an outbreak to identify the regions expected to be at greatest risk in the future.
Results
The model is applied to the recent Zika epidemic in the Americas at a weekly temporal resolution and country spatial resolution, using epidemiological data, passenger air travel volumes, and vector habitat suitability, socioeconomic, and population data for all affected countries and territories in the Americas. The model performance is quantitatively evaluated based on the predictive accuracy of the model. We show that the model can accurately predict the geographic expansion of Zika in the Americas with the overall average accuracy remaining above 85% even for prediction windows of up to 12 weeks.
Conclusions
Sensitivity analysis illustrated the model performance to be robust across a range of features. Critically, the model performed consistently well at various stages throughout the course of the outbreak, indicating its potential value at any time during an epidemic. The predictive capability was superior for shorter forecast windows and geographically isolated locations that are predominantly connected via air travel. The highly flexible nature of the proposed modeling framework enables policy makers to develop and plan vector control programs and case surveillance strategies which can be tailored to a range of objectives and resource constraints.
Similar content being viewed by others


Background
The Zika virus, which is primarily transmitted through the bite of infected Aedes aegypti mosquitoes [1], was first discovered in Uganda in 1947 [2] from where it spread to Asia in the 1960s, where it has since caused small outbreaks. In 2007, Zika virus (ZIKV) caused an island-wide outbreak in Yap Island, Micronesia [3], followed by outbreaks in French Polynesia [4] and other Pacific islands between 2013 and 2014, where attack rates were up to 70% [5,6,7]. It reached Latin America between late 2013 and early 2014, but was not detected by public health authorities until May 2015 [8]. It has since affected 48 countries and territories in the Americas [9,10,11]. Since there is no vaccination or treatment available for Zika infections [12, 13], the control of Ae. aegypti mosquito populations remains the most important intervention to contain the spread of the virus [14].
In order to optimally allocate resources to suppress vector populations, it is critical to accurately anticipate the occurrence and arrival time of arboviral infections to detect local transmission [15]. Whereas for dengue, the most common arbovirus infection, prediction has attracted wide attention from researchers employing statistical modeling and machine learning methods to guide vector control [16,17,18,19,20,21], global scale real-time machine learning-based models do not yet exist for Zika virus [22,23,24,25,26,27,28,29]. Specifically for dengue, early warning systems for Thailand, Indonesia, Ecuador, and Pakistan have been introduced and are currently in use [30,31,32,33,34]. Further, in addition to conventional predictions based on epidemiological and meteorological data [20, 35, 36], more recent models have successfully incorporated search engines [37, 38], land use [39], human mobility information [40, 41], spatial dynamics [42,43,44], and various combinations of the above [45] to improve predictions. Whereas local spread may be mediated by overland travel, continent widespread is mostly driven by air passenger travel between climatically synchronous regions [8, 46,47,48,49,50,51].
The aims of our work are to (1) present recurrent neural networks for the time ahead predictive modeling as a highly flexible tool for outbreak prediction and (2) implement and evaluate the model performance for the Zika epidemic in the Americas. The application of neural networks for epidemic risk forecasting has previously been applied to dengue forecasting and risk classification [52,53,54,55,56,57], detection of mosquito presence [58], temporal modeling of the oviposition of Aedes aegypti mosquito [59], Aedes larva identification [60], and epidemiologic time-series modeling through fusion of neural networks, fuzzy systems, and genetic algorithms [61]. Recently, Jian et al. [62] performed a comparison of different machine learning models to map the probability of Zika epidemic outbreak using publically available global Zika case data and other known covariates of transmission risk. Their study provides valuable insight into the potential role of machine learning models for understanding Zika transmission; however, it is static in nature, i.e., it does not account for time-series data and did not account for human mobility, both of which are incorporated in our modeling framework.
Here, we apply a dynamic neural network model for N-week ahead prediction for the 2015–2016 Zika epidemic in the Americas. The model implemented in this work relies on multi-dimensional time-series data at the country (or territory) level, specifically epidemiological data, passenger air travel volumes, vector habitat suitability for the primary spreading vector Ae. aegypti, and socioeconomic and population data. The modeling framework is flexible in three main dimensions: (1) the preferred risk indicator can be chosen by the policy maker, e.g., we consider outbreak size and incidence rate as two primary indicators of risk for a region; (2) five risk classification schemes are defined, where each classification scheme varies in the (relative or absolute) threshold used to determine the set of countries deemed “high risk;” and (3) it can be applied for a range of forecast windows (1–12 weeks). Model performance and robustness are evaluated for various combinations of risk indicator, risk classification level, and forecasting windows. Thus, our work represents the first flexible framework of neural networks for epidemic risk forecasting that allows policy makers to evaluate and weigh the trade-off in prediction accuracy between forecast window and risk classification schemes. Given the availability of the necessary data, the modeling framework proposed here can be applied in real time to future outbreaks of Zika and other similar vector-borne outbreaks.
Materials and methods
Data
The model relies on socioeconomic, population, epidemiological, travel, and mosquito vector suitability data. All data is aggregated to the country level and provided for all countries and territories in the Americas at a weekly temporal resolution. Each data set and corresponding processing is described in detail below and summarized in Table 1. All input data is available as Additional files 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, and 11.
Epidemiological data
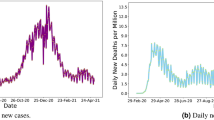
Weekly Zika infected cases for each country and territory in the Americas were extracted from the Pan American Health Organization (PAHO) [63], as described in previous studies [48, 50] (data available: github.com/andersen-lab/Zika-cases-PAHO). The epidemiological weeks 1–78 are labeled herein as EPI weeks, corresponding to the dates 29 Jun 2015 to 19 Dec 2016, respectively. Although Zika cases in Brazil were reported as early as May 2015, no case data is available for all of 2015 from PAHO because the Brazil Ministry of Health did not declare the Zika cases and associated neurological and congenital syndrome as notifiable conditions until 17 Feb 2016 [63]. The missing numbers of cases from July to December 2015 for Brazil were estimated based on the positive correlation between Ae. aegypti abundance (described below) and reported case counts as has been done previously [8, 50]. We used smoothing spline [71] to estimate weekly case counts from the monthly reported counts. The weekly country-level case counts (Fig. 1a) were divided by the total population/100,000, as previously described [50], to compute weekly incidence rates (Fig. 1b).

Weekly distribution of case and connectivity-risk variables. a Zika cases, b incidence rates, c case-weighted travel risk \( {CR}_{\mathbf{j}}^{\mathbf{t}} \), and d incidence-weighted travel risk \( {IR}_{\mathbf{j}}^{\mathbf{t}} \), for top 10 ranked countries and territories in the Americas for each respective variable
Travel data
Calibrated monthly passenger travel volumes for each airport-to-airport route in the world were provided by the International Air Transport Associate [64], as previously used in [50, 72]. The data includes origin, destination, and stopover airport paths for 84% of global air traffic and includes over 240 airlines and 3400 airports. The airport-level travel was aggregated to a regional level, to compute monthly movements between all countries and territories in the Americas. The incoming and outgoing travel volumes for each country and territory, originally available from IATA at a monthly temporal resolution, were curve fitted, again using smoothing spline method [71] to obtain corresponding weekly volumes to match with the temporal resolution of our model. In this study, travel data from 2015 were also used for 2016, as was done previously [50, 72, 73].
Mosquito suitability data
The monthly vector suitability data sets were based on habitat suitability for the principal Zika virus species Ae. aegypti, previously used in [50], and initially estimated using original high-resolution maps [65] and then enriched to account for seasonal variation in the geographical distribution of Ae. aegypti by using time-varying covariate such as temperature persistence, relative humidity, and precipitation as well as static covariates such as urban versus rural areas. The monthly data was translated into weekly data using a smoothing spline [71].
Socioeconomic and human population data
For a country, to prevent or manage an outbreak depends on their ability to implement a successful surveillance and vector control programs [74]. Due to a lack of global data to quantify vector control at a country level, we utilized alternative economic and health-related country indicators which have previously been revealed to be critical risk factors for Zika spread [50]. A country’s economic development can be measured by the gross domestic product (GDP) per capita at purchasing power parity (PPP), in international dollars. The figures from the World Bank [67] and the US Bureau of Economic Analysis [68] were used to collect GDP data for each country. The number of physicians and the number of hospital beds per 10,000 people were used to indicate the availability of health infrastructure in each country. These figures for the USA and other regions in the Americas were obtained from the Centre of Disease Control and Prevention (CDC) [69], WHO World Health Statistics report [75], and the PAHO [76]. Finally, the human population densities (people per sq. km of land area) for each region were collected from the World Bank [70] and the US Bureau of Economic Analysis [68].
Connectivity-risk variables
In addition to the raw input variables, novel connectivity-risk variables are defined and computed for inclusion in the model. These variables are intended to capture the risk posed by potentially infected travelers arriving at a given destination at a given point in time and, in doing so, explicitly capture the dynamics and heterogeneity of the air-traffic network in combination with real-time outbreak status. Two variables are chosen, hereafter referred to as case-weighted travel risk and incidence-weighted travel risk, as defined in Eqs. (1.a) and (1.b), respectively.
For each region j at time t, \( {CR}_j^t \) and \( {IR}_j^t \) are computed as the sum of product between passenger volume traveling from origin i into destination j at time t (\( {V}_{i,j}^t \)) and the state of the outbreak at origin i at time t, namely reported cases, \( {C}_i^t, \) or reported incidence rate, \( {I}_i^t \). Each of these two variables is computed for all 53 countries or territories for each of the 78 epidemiological weeks. The two dynamic variables, \( {CR}_j^t \) and \( {IR}_j^t \), are illustrated in Fig. 1c and d, below the raw case counts and incidence rates, respectively.
Neural network model
The proposed prediction problem is highly nonlinear and complex; thus, a class of neural architectures based upon Nonlinear AutoRegressive models with eXogenous inputs (NARX) known as NARX neural networks [77,78,79] is employed herein due to its suitability for modeling of a range of nonlinear systems [80]. The NARX networks, as compared to other recurrent neural network architectures, require limited feedback (i.e., feedback from the output neuron rather than from hidden states) and converge much faster with a better generalization [80, 81]. The NARX framework was selected over simpler linear regression frameworks due to both the size and complexity of the set of input variables and the demand for a nonlinear function approximation. Specifically, in addition to the epidemiological, environmental, and sociodemographic variables, there are hundreds of travel-related variables which may contribute to the risk prediction for each region. The NARX model can be formalized as follows [80]:
where x(t) and y(t) denote, respectively, the input and output (or target that should be predicted) of the model at discrete time t, while dx and dy (with dx ≥ 1, dy ≥ 1, and dx ≤ dy) are input and output delays called memory orders (Fig. 2). In this work, a NARX model is implemented to provide N-step ahead prediction of a time series, as defined below:

Schematic of NARX network with dx input and dy output delays: Each neuron produces a single output based on several real-valued inputs to that neuron by forming a linear combination using its input weights and sometimes passing the output through a nonlinear activation function: \( \mathbf{z}=\boldsymbol{\upvarphi} \left(\sum \limits_{\mathbf{i}=\mathbf{1}}^{\mathbf{n}}{\mathbf{w}}_{\mathbf{i}}{\mathbf{u}}_{\mathbf{i}}+\mathbf{b}\right)=\boldsymbol{\upvarphi} \left({\mathbf{w}}^{\mathbf{T}}\mathbf{x}+\mathbf{b}\right) \), where w denotes the vector of weights, u is the vector of inputs, b is the bias, and φ is a linear or nonlinear activation function (e.g., linear, sigmoid, and hyperbolic tangent [82])
Here, yk(t + N) is the risk classification predicted for the kth region N weeks ahead (of present time t), which is estimated as a function of xm(t) inputs from all m = 1, 2, …, M regions for dx previous weeks, and the previous risk classification state, yk(t) for region k for dy previous weeks. The prediction model is applied at time t, to predict for time t + N, and therefore relies on data available up until week t. That is, to predict outbreak risk for epidemiological week X, N-weeks ahead, the model is trained and tested using data available up until week (X–N). For example, 12-week ahead prediction for Epi week 40 is performed using data available up to week 28. The function f(∙) is an unknown nonlinear mapping function that is approximated by a multilayer perceptron (MLP) to form the NARX recurrent neural network [78, 79]. In this work, series-parallel NARX neural network architecture is implemented in Matlab R2018a (The MathWorks, Inc., Natick, MA, USA) [57].
In the context of this work, the desired output, yk(t + N), is a binary risk classifier, i.e., classifying a region k as high or low risk at time t + N, for each region, k, N weeks ahead (of t). The vector of input variables for region m at time t is xm(t) and includes both static and dynamic variables. We consider various relative (R) and absolute (A) thresholds to define the set of “high-risk” countries at any point in time. We define relative risk thresholds that range uniformly between 10 and 50%, where the 10% scheme classifies the 10% of countries reporting the highest number of cases (or highest incidence rate) during a given week as high risk, and the other 90% as low risk, similar to [45]. The relative risk schemes are referred herein as R = 0.1, R = 0.2, R = 0.3, R = 0.4, and R = 0.5. It is worth noting, for a given percentile, e.g., R = 0.1, the relative risk thresholds are dynamic and vary week to week as a function of the scale of the epidemic, while the size of the high-risk group remains fixed over time, e.g., 10% of all countries. We also consider absolute thresholds, which rely on case incidence rates to define the high-risk group. Five absolute thresholds are selected based on the distribution of incidence values over all countries and the entire epidemic. Specifically, the 50th, 60th, 70th, 80th, and 90th percentiles were chosen and are referred herein as A = 50, A = 60, A = 70, A = 80, and A = 90. These five thresholds correspond to weekly case incidence rates of 0.43, 1.47, 4.05, 9.5, and 32.35 (see Additional file 12: Figure S1), respectively. In contrast to the relative risk scheme, under the absolute risk scheme for a given percentile, e.g., A = 90, the threshold remains fixed but the size of the high (and low)-risk group varies week to week based on the scale of the epidemic. The fluctuation in group size for each threshold is illustrated in Additional file 12: Figure S1 for each classification scheme, A = 50 to A = 90. Critically, our prediction approach differs from [45], in that our model is trained to predict the risk level directly, rather than predict the number of cases, which are post-processed into risk categories. The performance of the model is evaluated by comparing the estimated risk level (high or low) to the actual risk level for all locations at a specified time. The actual risk level is simply defined at each time period t during the outbreak by ranking the regions based on the number of reported case counts (or incidence rates) and grouping them into high- and low-risk groups according to the specified threshold and classification scheme.
The static variables used in the model include GDP PPP, population density, number of physicians, and the number of hospital beds for each region. The dynamic variables include mosquito vector suitability, outbreak status (both reported case counts and reported incidence rates), total incoming travel volume, total outgoing travel volume, and the two connectivity-risk variables defined as in Eqs. (1.a) and (1.b), again for each region. Before applying to the NARX model, all data values are normalized to the range [0, 1].
A major contribution of this work is the flexible nature of the model, which allows policy makers to be more or less risk-averse in their planning and decision making. Firstly, the risk indicator can be chosen by the modeler; in this work, we consider two regional risk indicators, (i) the number of reported cases and (ii) incidence rate. Second, we consider a range of risk classification schemes, which define the set of high-risk countries based on either a relative or absolute threshold that can be chosen at the discretion of the modeler, i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5, and A = 90, 80, 70, 60, 50. Third, the forecast window, N, is defined to range from N = 1, 2, 4, 8 to 12 weeks. Subsequently, any combination of risk indicator, risk classification scheme, and forecasting window can be modeled.
In initial settings of the series-parallel NARX neural network, multiple numbers of hidden layer neurons and numbers of tapped delay lines (Eq. [2]) were explored for training and testing of the model. Sensitivity analysis revealed a minimal difference in the performance of the model under different settings. Therefore, for all experiments presented in this work, the numbers of neural network hidden layer neurons and tapped delay lines are kept constant as two and four, respectively.
To train and test the model, the actual risk classification for each region at each week during the epidemic, yk(t), was used. For each model run, e.g., a specified risk indicator, risk classification scheme, and forecasting window, the input and target vectors are randomly divided into three sets:
-
1.
Seventy percent for training, to tune model parameters minimizing the mean square error between the outputs and targets
-
2.
Fifteen percent for validation, to measure network generalization and to prevent overfitting, by halting training when generalization stops improving (i.e., mean square error of validation samples starts increasing)
-
3.
Fifteen percent for testing, to provide an independent measure of network performance during and after training
The performance of the model is measured using two metrics: (1) prediction accuracy (ACC) and (2) receiver operating characteristic (ROC) curves. Prediction accuracy is defined as ACC = (TP + TN)/(TP + FP + TN + FN), where true positive (TP) is the number of high-risk locations correctly predicted as high risk, false negative (FN) is the number of high-risk locations incorrectly predicted as low risk, true negative (TN) is the number of low-risk locations correctly predicted as low risk, and false positive (FP) is the number of low-risk locations incorrectly predicted as high risk. The second performance metric, ROC curve [83], explores the effects on TP and FP as the position of an arbitrary decision threshold is varied, which in the context of this prediction problem distinguished low- and high-risk locations. ROC curve can be characterized as a single number using the area under the ROC curve (AUC), with larger areas having an AUC that approaches one indicating a more accurate detection method. In addition to quantifying model performance using these two metrics, we evaluate the robustness of the predictions by comparing the ACC across multiple runs that vary in their selection of testing and training sets (resulting from the randomized sampling).
Results
The model outcome reveals the set of locations expected to be at high risk at a specified date in the future, i.e., N weeks ahead of when the prediction is made. We apply the model for all epidemiological weeks throughout the epidemic and evaluate performance under each combination of (i) risk indicator, (ii) classification scheme, and (iii) forecast window. For each model run, both ACC and ROC AUC are computed.
Model performance
Figures 3 and 4 exemplify the output of the proposed model. Figure 3 illustrates the model predictions at a country level for a 4-week prediction window, specifically for Epi week 40, i.e., using data available up until week 36. Figure 3a illustrates the actual risk percentile each country is assigned to in week 40, based on reported case counts. The results presented in the remaining panels of Fig. 3 reveal the risk level (high or low) predicted for each country under the five relative risk classification schemes, namely (b) R = 0.1, (c) R = 0.2, (d) R = 0.3, (e) R = 0.4, and (f) R = 0.5, and whether or not it was correct. For panels (b)–(e), green indicates a correctly predicted low-risk country (TN), light gray indicates an incorrectly predicted high-risk country (FP), dark gray indicates an incorrectly predicted low-risk country (FN), and the remaining color indicates a correctly predicted high-risk country (TP). The inset highlights the results for the Caribbean islands. The figure also presents the average ACC over all regions and ACC for just the Caribbean region (grouped similar to [10]) for each classification scheme.

Country prediction accuracy by relative risk level. Panel a illustrates the actual relative risk level assigned to each country at Epi week 40 for a fixed forecast window, N = 4. Panels b–e each correspond to a different classification scheme, specifically b R = 0.1, c R = 0.2, d R = 0.3, e R = 0.4, and f R = 0.5. The inset shown by the small rectangle highlights the actual and predicted risk in the Caribbean islands. For panels b–e, green indicates a correctly predicted low-risk country, light gray indicates an incorrectly predicted high-risk country, and dark gray indicates an incorrectly predicted low-risk country. The risk indicator used is case counts

Country prediction accuracy by forecast window. Panel a illustrates the actual relative risk level assigned to each country at Epi week 40 for a fixed classification scheme, R = 0.2. Panels b–e each correspond to different forecast windows, specifically b N = 1, c N = 2, d N = 4, e N = 8, and f N = 12. The inset shown by the small rectangle highlights the actual and predicted risk in the Caribbean islands. For panels b–e, the red indicates a correctly predicted high-risk country and green indicates a correctly predicted low-risk country. Light gray indicates an incorrectly predicted high-risk country, and dark gray indicates an incorrectly predicted low-risk country. The risk indicator used is case counts
Figure 4 illustrates the model predictions at a country level for varying prediction windows, and a fixed classification scheme of R = 0.2, again for Epi week 40. Figure 4a illustrates the actual risk classification (high or low) each country is assigned to in Epi week 40, based on reported case counts. The results presented in the remaining panels of Fig. 4 reveal the risk level (high or low) predicted for each country under the five forecasting windows, specifically (b) N = 1, (c) N = 2, (d) N = 4, (e) N = 8, and (f) N = 12, and whether or not it was correct. For panels (b)–(e), red indicates a correctly predicted high-risk country (TP), green indicates a correctly predicted low-risk country (TN), light gray indicates an incorrectly predicted high-risk country (FP), and dark gray indicates an incorrectly predicted low-risk country (FN). The inset highlights the results for the Caribbean islands. Similar to Fig. 3, for each forecast window, the reported ACC is averaged both over all regions and for just the Caribbean.
The model’s performance and sensitivity to the complete range of input parameters are summarized in Additional file 13: Table S2. ACC is presented for each combination of risk indicator (case count and incidence rate), classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5 and A = 90, 80, 70, 60, 50) and forecast window (i.e., N = 1, 2, 4, 8, and 12), for selected Epi weeks throughout the epidemic. ROC AUC (averaged over all locations and all EPI weeks) is computed for all combinations of risk indicator (case count and incidence rate), classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5 and A = 90, 80, 70, 60, 50), and forecast window (i.e., N = 1, 2, 4, 8, and 12).
Figures 5 and 6 illustrate trends in the model performance as a function of classification scheme and forecast window, aggregated over space and time. Specifically, Fig. 5 reveals the model performance (ACC, averaged over all locations and all EPI weeks) for each combination of risk classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, and 0.5) and forecast window (i.e., N = 1, 2, 4, 8, and 12). The aggregated ROC curves (averaged over all locations and all epidemiological weeks) for R = 0.4 are presented in Fig. 6 and reveal the (expected) increased accuracy of the model as the forecast window is reduced. The ROC AUC results are consistent with ACC results presented in Fig. 5, highlighting the superior performance of the 1- and 2-week ahead prediction capability of the model. The ROC AUC value remains above 0.91 for N = 1, 2 and above 0.83 for N = 4, both indicating high predictive accuracy of the model. The ROC curves for the other relative risk classification schemes are presented in Additional file 14: Figure S2.

Aggregate model performance measured by ACC (averaged over all locations and all weeks) for all combinations of relative risk classification schemes (i.e., R = 0.1, 0.2, 0.3, 0.4, and 0.5) and forecast windows (i.e., N = 1, 2, 4, 8, and 12), where the risk indicator is case counts

Aggregate model performance measured by ROC AUC (averaged over all locations and all weeks) for a fixed relative risk classification scheme, i.e., R = 0.4, and forecast windows (i.e., N = 1, 2, 4, 8, and 12), where the risk indicator is case counts
Global and regional analysis
We further explore the model’s performance at a regional level by dividing the countries and territories in the Americas into three groups, namely the Caribbean, South America, and Central America, as in [10], and compare with the Global performance, i.e., all countries. For each group, the average performance of the model in terms of ACC was evaluated and presented for each combination of risk indicator (case count and incidence rate), classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5 and A = 90, 80, 70, 60, 50) and forecast window (i.e., N = 1, 2, 4, 8, and 12), aggregated over then entire epidemic period (Table 2).
Model robustness
Figure 7a and b show how the ACC varies over 10 independent runs of the model. This sensitivity analysis was conducted for all combinations’ risk indicator, relative risk classification schemes, and selected epidemiological weeks (i.e., week number/starting date: 30/18 Jan 2016, 40/28 Mar 2016, 50/6 Jun 2016, 60/15 Aug 2016, and 70/24 Oct 2016). This time period represents a highly complex period of the outbreak with country-level rankings fluctuating substantially, as evidenced in Fig. 1. Due to computation time, the sensitivity analysis was evaluated for only the 4-week forecast window. The size of the error bars illustrates the robustness of the proposed modeling framework.

Model performance and robustness. ACC is averaged over all locations for selected epidemiological weeks when risk indicator is a case counts and b incidence rate, and a fixed forecast windows (i.e., N = 4). The error bars represent the variability in expected ACC across ten runs for each combination
NARX feature selection
While the NARX framework does not provide assigned weights for each input feature as output, sensitivity analysis can be conducted to help identify the key predictive features. We tested the performance of the NARX framework under three different combinations of input features, with the particular objective of quantifying the role of travel data in our outbreak prediction model. We considered (i) a simple “baseline” model using only case count and incidence data; (ii) an expanded baseline model that includes case and incidence data, and all non-travel related variables; and (iii) the proposed model which includes all features listed in Table 1. The results comparing the performance of these three models with the detailed list of input features for each is provided in Additional file 15: Table S1. The results reveal the case-related data (regional case counts and incidence rates) to be the dominant explanatory variables for predicting outbreak risk in a region, as would be expected. The inclusion of non-travel-related variables (regional suitability, regional GDP, regional physicians, regional hospital beds, regional population density) is not shown to improve predictive capability over the baseline model and, in fact, sometimes performs worse than the baseline model. In contrast, the inclusion of travel data (weekly case-weighted travel risk, weekly incidence-weighted travel risk, weekly incoming travel volume, weekly outgoing travel volume) is revealed to improve the predictive capability, especially for the shorter prediction windows, with a higher AUC ROC for a majority (20 of the 25) of the scenarios tested. These results support the inclusion of the dynamic travel-related variables, which substantially increase the complexity of the model (inputs) and, thus, justify the use of the NARX framework selected.
Discussion
Our model uses a range of environmental, socio-demographic, and dynamic travel data to predict the spread of Zika in the Americas and the potential for local transmission. Therefore, our model expands on previous work by considering the static and dynamic aspects of Zika virus transmission that were previously done in isolation [48, 67, 84]. Overall, the proposed model is shown to be accurate and robust, especially for shorter prediction windows and higher risk thresholds. As would be expected, the performance of the proposed model decreases as the prediction window increases because of the inherent uncertainty in outbreak evolution over long periods of time. Specifically, the model is almost 80% accurate for 4-week ahead prediction for all classification schemes and almost 90% accurate for all 2-week ahead prediction scenarios, i.e., the correct risk category of 9 out of 10 locations can always be predicted, indicating strong performance. When the objective is to identify the top 10% of at-risk regions, the average accuracy of the model remains above 87% for prediction up to 12 weeks in advance. Generally, the model performance is shown to decrease as the risk threshold is reduced, e.g., the size of the high-risk group is increased, representing a more risk-averse policy. The decrease in performance is likely due to the increased size and fluctuation of the high-risk country set over time for lower thresholds. For example, for the absolute risk threshold of A = 50, the number of countries classified as high risk fluctuates between 1 and 34 throughout the course of the epidemic, compared with A = 90, where the set only ranges from 0 to 12 (see Additional file 12: Figure S1). These results reveal the trade-off between desired forecast window and precision of the high-risk group. The quantifiable trade-off between the two model inputs (classification scheme and forecast window) can be useful for policies which may vary in desired planning objectives.
The results in Figs. 3 and 4, as well as Table 2, reveal a similar trend at the regional level as was seen at the global level, with a decrease in predictive accuracy as the forecast window increases in length, and the high-risk group increases in size. As shown in Fig. 3, the ACC remains above 90% for R < 0.3, indicating superior model performance. For example, at Epi week 40, R = 0.3 and N = 4 (using outbreak data and other model variables up to Epi week 36), there were 16 total regions classified as high risk, of which the model correctly identified 13. Furthermore, of the 16 high-risk regions, 8 were in the Caribbean (i.e., Aruba, Curacao, Dominican Republic, Guadeloupe, Haiti, Jamaica, Martinique, and Puerto Rico), of which the model correctly identified 7. Only Aruba in the Caribbean and Honduras and Panama were the only regions incorrectly predicted as low risk in this scenario; accurately classifying low-risk regions is also important (and assuring the model is not too risk-averse). For the same scenario, i.e., Epi week 40, R = 0.3 and N = 4, all 18 low-risk Caribbean locations and 17 of the 19 low-risk non-Caribbean locations were accurately classified by the model. Paraguay and Suriname were the only regions incorrectly predicted as high risk. These results are consistent with the high reported accuracy of the model, i.e., overall ACC = 90.15%; Caribbean ACC = 96.15%.
Figure 4 reveals that the performance of the model, expectedly, deteriorates as the forecast window increases; however, the average accuracy remains above 80% for prediction up to 8 weeks ahead and well about 90% for up to 4 weeks ahead. The prediction accuracy for the Caribbean slightly lags the average performance in the Americas. Specifically, for R = 0.2, 5 of the 11 Caribbean regions were designated as high-risk locations at Epi week 40, i.e., Dominican Republic, Guadeloupe, Jamaica, Martinique, and Puerto Rico. For a 1-week prediction window, N = 1, the model was able to correctly predict 3 of the high-risk regions (i.e., Jamaica, Martinique, Puerto Rico); for N = 2, it correctly identified two (i.e., Martinique, Puerto Rico); and for N = 4, it again correctly identified three (i.e., Guadeloupe, Martinique, Puerto Rico). However, the model did not correctly predict any high-risk locations in the Caribbean at N = 8 and N = 12 window lengths. This error is due to the low and sporadic reporting of Zika cases in the region around week 30 and the high variability of the outbreak over the 8- and 12-week period. Similar prediction capability is illustrated for R = 0.5 (not shown in the figure), in which case out of the 13 Caribbean high-risk locations, the model correctly identifies all locations at N = 1, 2, and 4; 10 of the 13 locations at N = 8; and only 1 of the 13 at N = 12.
When comparing performance across regions (see Table 2), results reveal the predictive accuracy is best for the Caribbean region, while predictions for Central America were consistently the worst; the discrepancy in performance between these groups increases as the forecast window increases. The difference in performance across regions can be attributed to the high spatial heterogeneity of the outbreak patterns, the relative ability of air travel to accurately capture connectivity between locations, and errors in case reporting that may vary by region. For example, the Caribbean, which consists of more than twice as many locations as any other group, first reported cases around week 25 and remained affected throughout the epidemic. In contrast, Central America experienced a slow start to the outbreak (at least according to case reports) with two exceptions, namely Honduras and El Salvador. The large number of affected region in the Caribbean, with more reported cases distributed over a longer time period, contributed to the training of the model, thus improving the predictive capability for these regions. Additionally, the geographically isolated nature of Caribbean islands enables air travel to more accurately capture incoming travel risk, unlike countries in Central and South America, where individuals can also move about using alternative modes, which are not accounted for in this study. These factors combined explain the higher predictive accuracy of the model for the Caribbean region and, importantly, help to identify the critical features and types of settings under which this model is expected to perform best.
Finally, the robustness of the model predictions is illustrated by the short error bars in Fig. 7. The model is also demonstrated to perform consistently throughout the course of the epidemic, with the exception of week 30, at which time there was limited information available to train the model, e.g., the outbreak was not yet reported in a majority of the affected countries. Comparing Fig. 7a and b reveals relatively similar performance for both risk indicators, and Additional file 13: Table S2 demonstrates the model’s flexibility and adaptability with respect to both the risk scheme chosen, i.e., relative or absolute, and the metric used to classify outbreak risk, i.e., number of cases or incidence rate in a region.
Limitations
There are several limitations in this work. The underlying data on case reporting vary by country and may not represent the true transmission patterns [85]. However, the framework presented was flexible enough to account for these biases, and we anticipate this will only be improved as data become more robust. Additionally, 2015 travel data was used in place of 2016 data, as has been done previously [50, 65, 66], which may not be fully representative of travel behavior. Furthermore, air travel is the only mode of travel accounted for; thus, additional person movements between country pairs that share land borders are unaccounted for, and as a result, the model likely underestimates the risk posed to some regions. This limitation may partially explain the increased model performance for the geographically isolated Caribbean Islands, which represent a large proportion of ZIKV-affected regions. This study does not account for species of mosquitos other than Ae. Aegypti, such as Ae. Albopictus, which can also spread ZIKV; however, Ae. Aegypti are known to be the primary spreading vector and responsible for the majority of the ZIKV epidemic in the Americas [66]. Additionally, alternative non-vector-borne mechanisms of transmission are ignored. Lastly, due to the lack of spatial resolution of case reports, we were limited to make country to country spread estimates. Our work neglects the vast heterogeneity in mosquito presence particularly in countries like Brazil. We do however appreciate that there is considerable spatial variation within countries that will bias our estimates (i.e., northern vs. southern Brazil) and that this may influence the weekly covariates used in this study. We again hypothesize that models will become better as the spatial resolution of available data increases.
Conclusions
We have introduced a flexible, predictive modeling framework to forecast outbreak risk in real time that can be scaled and readily applied in future outbreaks. An application of the model was applied to the Zika epidemic in the Americas at a weekly temporal resolution and country-level spatial resolution, using a combination of population, socioeconomic, epidemiological, travel pattern, and vector suitability data. The model performance was evaluated for various risk classification schemes, forecast windows, and risk indicators and illustrated to be accurate and robust across a broad range of these features. First, the model is more accurate for shorter prediction windows and restrictive risk classification schemes. Secondly, regional analysis reveals superior predictive accuracy for the Caribbean, suggesting the model to be best suited to geographically isolated locations that are predominantly connected via air travel. Predicting the spread to areas that are relatively isolated has previously been shown to be difficult due to the stochastic nature of infectious disease spread [86]. Thirdly, the model performed consistently well at various stages throughout the course of the outbreak, indicating its potential value at the early stages of an epidemic. The model performance was not evaluated against simpler alternative statistical models such as linear regression, which was not the aim of this work. We do, however, encourage rigorous model comparisons in future work. The outcomes from the model can be used to better guide outbreak resource allocation decisions and can be easily adapted to model other vector-borne epidemics.
Availability of data and materials
All data used in this study is provided as Additional files.
Abbreviations
- ACC:
-
Prediction accuracy
- AUC:
-
Area under the curve
- CDC:
-
Centers for Disease Control and Prevention
- FN:
-
False negative
- FP:
-
False positive
- GDP:
-
Gross domestic product
- IATA:
-
International Air Transport Association
- MLP:
-
Multilayer perceptron
- NARX:
-
Nonlinear autoregressive models with exogenous inputs
- PAHO:
-
Pan American Health Organization
- PPP:
-
Purchasing power parity
- ROC:
-
Receiver operating characteristic
- TN:
-
True negative
- TP:
-
True positive
- ZIKV:
-
Zika virus
References
Chouin-Carneiro T, Vega-Rua A, Vazeille M, Yebakima A, Girod R, Goindin D, et al. Differential susceptibilities of Aedes aegypti and Aedes albopictus from the Americas to Zika virus. PLoS Negl Trop Dis. 2016;10(3):1–11.
Dick GW. Zika virus. II. Pathogenicity and physical properties. Trans R Soc Trop Med Hyg. 1952;46(5):521–34.
Duffy MR, Chen TH, Hancock WT, Powers AM, Kool JL, Lanciotti RS, et al. Zika virus outbreak on Yap Island, Federated States of Micronesia. N Engl J Med. 2009;360(24):2536–43.
Hancock WT, Marfel M, Bel M. Zika virus, French Polynesia, South Pacific, 2013. Emerg Infect Dis. 2014;20(11):1960.
Dupont-Rouzeyrol M, O'Connor O, Calvez E, Daures M, John M, Grangeon JP, et al. Co-infection with Zika and dengue viruses in 2 patients, New Caledonia, 2014. Emerg Infect Dis. 2015;21(2):381–2.
Musso D, Nilles EJ, Cao-Lormeau VM. Rapid spread of emerging Zika virus in the Pacific area. Clin Microbiol Infect. 2014;20(10):O595–6.
Tognarelli J, Ulloa S, Villagra E, Lagos J, Aguayo C, Fasce R, et al. A report on the outbreak of Zika virus on Easter Island, South Pacific, 2014. Arch Virol. 2016;161(3):665–8.
Faria NR, Azevedo R, Kraemer MUG, Souza R, Cunha MS, Hill SC, et al. Zika virus in the Americas: early epidemiological and genetic findings. Science. 2016;352(6283):345–9.
Campos GS, Bandeira AC, Sardi SI. Zika virus outbreak, Bahia, Brazil. Emerg Infect Dis. 2015;21(10):1885–6.
Pan American Health Organization / World Health Organization. Regional Zika epidemiological update (Americas) August 25, 2017. Washington, D.C.: PAHO/WHO; 2017.
Zanluca C, Melo VC, Mosimann AL, Santos GI, Santos CN, Luz K. First report of autochthonous transmission of Zika virus in Brazil. Mem Inst Oswaldo Cruz. 2015;110(4):569–72.
Scott TW, Morrison AC. Vector dynamics and transmission of dengue virus: implications for dengue surveillance and prevention strategies: vector dynamics and dengue prevention. Curr Top Microbiol Immunol. 2010;338:115–28.
Achee NL, Gould F, Perkins TA, Reiner RC Jr, Morrison AC, Ritchie SA, et al. A critical assessment of vector control for dengue prevention. PLoS Negl Trop Dis. 2015;9(5):e0003655.
European Centre for Disease Prevention and Control. Vector control with a focus on Aedes aegypti and Aedes albopictus mosquitoes: literature review and analysis of information. Stockholm: ECDC; 2017.
McGough SF, Brownstein JS, Hawkins JB, Santillana M. Forecasting Zika incidence in the 2016 Latin America outbreak combining traditional disease surveillance with search, social media, and news report data. PLoS Negl Trop Dis. 2017;11(1):e0005295.
Martínez-Bello DA, López-Quílez A, Torres-Prieto A. Bayesian dynamic modeling of time series of dengue disease case counts. PLoS Negl Trop Dis. 2017;11(7):e0005696.
Guo P, Liu T, Zhang Q, Wang L, Xiao J, Zhang Q, et al. Developing a dengue forecast model using machine learning: a case study in China. PLoS Negl Trop Dis. 2017;11(10):e0005973.
Johansson MA, Reich NG, Hota A, Brownstein JS, Santillana M. Evaluating the performance of infectious disease forecasts: a comparison of climate-driven and seasonal dengue forecasts for Mexico. Sci Rep. 2016;6:33707.
Earnest A, Tan SB, Wilder-Smith A, Machin D. Comparing statistical models to predict dengue fever notifications. Comput Math Methods Med. 2012;2012:6.
Hii YL, Zhu H, Ng N, Ng LC, Rocklöv J. Forecast of dengue incidence using temperature and rainfall. PLoS Negl Trop Dis. 2012;6(11):e1908.
Shi Y, Liu X, Kok SY, Rajarethinam J, Liang S, Yap G, et al. Three-month real-time dengue forecast models: an early warning system for outbreak alerts and policy decision support in Singapore. Environ Health Perspect. 2016;124(9):1369–75.
Teng Y, Bi D, Xie G, Jin Y, Huang Y, Lin B, et al. Dynamic forecasting of Zika epidemics using Google trends. PLoS One. 2017;12(1):e0165085.
Althouse BM, Ng YY, Cummings DAT. Prediction of dengue incidence using search query surveillance. PLoS Negl Trop Dis. 2011;5(8):e1258.
Morsy S, Dang TN, Kamel MG, Zayan AH, Makram OM, Elhady M, et al. Prediction of Zika-confirmed cases in Brazil and Colombia using Google Trends. Epidemiol Infect. 2018;146(13):1625–7.
Kraemer MUG, Faria NR, Reiner RC Jr, Golding N, Nikolay B, Stasse S, et al. Spread of yellow fever virus outbreak in Angola and the Democratic Republic of the Congo 2015-16: a modelling study. Lancet Infect Dis. 2017;17(3):330–8.
Zhang Q, Sun K, Chinazzi M, Pastore YPA, Dean NE, Rojas DP, et al. Spread of Zika virus in the Americas. Proc Natl Acad Sci U S A. 2017;114(22):E4334–E43.
Ahmadi S, Bempong N-E, De Santis O, Sheath D, Flahault A. The role of digital technologies in tackling the Zika outbreak: a scoping review. J Public Health Emerg. 2018;2(20):1–15.
Majumder MS, Santillana M, Mekaru SR, McGinnis DP, Khan K, Brownstein JS. Utilizing nontraditional data sources for near real-time estimation of transmission dynamics during the 2015-2016 Colombian Zika virus disease outbreak. JMIR Public Health Surveill. 2016;2(1):e30.
Beltr JD, Boscor A, WPd S, Massoni T, Kostkova P. ZIKA: a new system to empower health workers and local communities to improve surveillance protocols by E-learning and to forecast Zika virus in real time in Brazil. In: Proceedings of the 2018 International Conference on Digital Health, vol. 3194683. Lyon: ACM; 2018. p. 90–4.
Cortes F, Turchi Martelli CM, Arraes de Alencar Ximenes R, Montarroyos UR, Siqueira Junior JB, Goncalves Cruz O, et al. Time series analysis of dengue surveillance data in two Brazilian cities. Acta Trop. 2018;182:190–7.
Abdur Rehman N, Kalyanaraman S, Ahmad T, Pervaiz F, Saif U, Subramanian L. Fine-grained dengue forecasting using telephone triage services. Sci Adv. 2016;2(7):e1501215.
Lowe R, Stewart-Ibarra AM, Petrova D, Garcia-Diez M, Borbor-Cordova MJ, Mejia R, et al. Climate services for health: predicting the evolution of the 2016 dengue season in Machala, Ecuador. Lancet Planet Health. 2017;1(4):e142–e51.
Ramadona AL, Lazuardi L, Hii YL, Holmner A, Kusnanto H, Rocklov J. Prediction of dengue outbreaks based on disease surveillance and meteorological data. PLoS One. 2016;11(3):e0152688.
Lauer SA, Sakrejda K, Ray EL, Keegan LT, Bi Q, Suangtho P, et al. Prospective forecasts of annual dengue hemorrhagic fever incidence in Thailand, 2010-2014. Proc Natl Acad Sci U S A. 2018;115(10):E2175–E82.
Baquero OS, Santana LMR, Chiaravalloti-Neto F. Dengue forecasting in Sao Paulo city with generalized additive models, artificial neural networks and seasonal autoregressive integrated moving average models. PLoS One. 2018;13(4):e0195065.
Sirisena P, Noordeen F, Kurukulasuriya H, Romesh TA, Fernando L. Effect of climatic factors and population density on the distribution of dengue in Sri Lanka: a GIS based evaluation for prediction of outbreaks. PLoS One. 2017;12(1):e0166806.
Anggraeni W, Aristiani L. Using Google Trend data in forecasting number of dengue fever cases with ARIMAX method case study: Surabaya, Indonesia. In: 2016 International Conference on Information & Communication Technology and Systems (ICTS); 2016. 12–12 Oct. 2016.
Marques-Toledo CA, Degener CM, Vinhal L, Coelho G, Meira W, Codeco CT, et al. Dengue prediction by the web: tweets are a useful tool for estimating and forecasting dengue at country and city level. PLoS Negl Trop Dis. 2017;11(7):e0005729.
Cheong YL, Leitão PJ, Lakes T. Assessment of land use factors associated with dengue cases in Malaysia using boosted regression trees. Spat Spatiotemporal Epidemiol. 2014;10:75–84.
Wesolowski A, Qureshi T, Boni MF, Sundsoy PR, Johansson MA, Rasheed SB, et al. Impact of human mobility on the emergence of dengue epidemics in Pakistan. Proc Natl Acad Sci U S A. 2015;112(38):11887–92.
Zhu G, Liu J, Tan Q, Shi B. Inferring the spatio-temporal patterns of dengue transmission from surveillance data in Guangzhou, China. PLoS Negl Trop Dis. 2016;10(4):e0004633.
Zhu G, Xiao J, Zhang B, Liu T, Lin H, Li X, et al. The spatiotemporal transmission of dengue and its driving mechanism: a case study on the 2014 dengue outbreak in Guangdong, China. Sci Total Environ. 2018;622–623:252–9.
Liu K, Zhu Y, Xia Y, Zhang Y, Huang X, Huang J, et al. Dynamic spatiotemporal analysis of indigenous dengue fever at street-level in Guangzhou city, China. PloS Negl Trop Dis. 2018;12(3):e0006318.
Li Q, Cao W, Ren H, Ji Z, Jiang H. Spatiotemporal responses of dengue fever transmission to the road network in an urban area. Acta Trop. 2018;183:8–13.
Chen Y, Ong JHY, Rajarethinam J, Yap G, Ng LC, Cook AR. Neighbourhood level real-time forecasting of dengue cases in tropical urban Singapore. BMC Med. 2018;16(1):129.
Gardner L, Sarkar S. A global airport-based risk model for the spread of dengue infection via the air transport network. PLoS One. 2013;8(8):e72129.
Gardner L, Fajardo D, Waller ST, Wang O, Sarkar S. A predictive spatial model to quantify the risk of air-travel-associated dengue importation into the United States and Europe. J Trop Med. 2012;2012:ID 103679 11pages.
Grubaugh ND, Ladner JT, Kraemer MUG, Dudas G, Tan AL, Gangavarapu K, et al. Genomic epidemiology reveals multiple introductions of Zika virus into the United States. Nature. 2017;546:401.
Wilder-Smith A, Gubler DJ. Geographic expansion of dengue: the impact of international travel. Med Clin North Am. 2008;92(6):1377–90 x.
Gardner LM, Bota A, Gangavarapu K, Kraemer MUG, Grubaugh ND. Inferring the risk factors behind the geographical spread and transmission of Zika in the Americas. PLoS Negl Trop Dis. 2018;12(1):e0006194.
Tatem AJ, Hay SI. Climatic similarity and biological exchange in the worldwide airline transportation network. Proc R Soc B Biol Sci. 2007;274(1617):1489.
Siriyasatien P, Phumee A, Ongruk P, Jampachaisri K, Kesorn K. Analysis of significant factors for dengue fever incidence prediction. BMC Bioinformatics. 2016;17(1):166.
Nishanthi PHM, Perera AAI, Wijekoon HP. Prediction of dengue outbreaks in Sri Lanka using artificial neural networks. Int J Comput Appl. 2014;101(15):1–5.
Aburas HM, Cetiner BG, Sari M. Dengue confirmed-cases prediction: a neural network model. Expert Syst Appl. 2010;37(6):4256–60.
Baquero OS, Santana LMR, Chiaravalloti-Neto F. Dengue forecasting in São Paulo city with generalized additive models, artificial neural networks and seasonal autoregressive integrated moving average models. PLoS One. 2018;13(4):e0195065.
Faisal T, Taib MN, Ibrahim F. Neural network diagnostic system for dengue patients risk classification. J Med Syst. 2012;36(2):661–76.
Laureano-Rosario EA, Duncan PA, Mendez-Lazaro AP, Garcia-Rejon EJ, Gomez-Carro S, Farfan-Ale J, et al. Application of artificial neural networks for dengue fever outbreak predictions in the northwest coast of Yucatan, Mexico and San Juan, Puerto Rico. Trop Med Infect Dis. 2018;3(1):5.
Kiskin IOB, Windebank T, Zilli D, Sinka M, Willis K, Roberts S. Mosquito detection with neural networks: the buzz of deep learning. arXiv:1705.05180.
Scavuzzo JM, Trucco FC, Tauro CB, German A, Espinosa M, Abril M. Modeling the temporal pattern of dengue, Chicungunya and Zika vector using satellite data and neural networks. In: 2017 XVII Workshop on Information Processing and Control (RPIC); 2017. 20–22 Sept. 2017.
Sanchez-Ortiz A, Fierro-Radilla A, Arista-Jalife A, Cedillo-Hernandez M, Nakano-Miyatake M, Robles-Camarillo D, et al. Mosquito larva classification method based on convolutional neural networks. In: 2017 International Conference on Electronics, Communications and Computers (CONIELECOMP); 2017. 22–24 Feb. 2017.
Nguyen T, Khosravi A, Creighton D, Nahavandi S. Epidemiological dynamics modeling by fusion of soft computing techniques. In: The 2013 International Joint Conference on Neural Networks (IJCNN); 2013. 4–9 Aug. 2013.
Jiang D, Hao M, Ding F, Fu J, Li M. Mapping the transmission risk of Zika virus using machine learning models. Acta Trop. 2018;185:391–9.
Wahba G. Spline models for observational data: Society for Industrial and Applied Mathematics; 1990. p. 177.
PAHO. Countries and territories with autochthonous transmission in the Americas reported in 2015-2017. Washington DC: World Health Organization, Pan American Health Organization; 2017. Available from: http://www.paho.org/hq/index.php?option=com_content&view=article&id=11603&Itemid=41696&lang=en
Gardner L, Chen N, Sarkar S. Vector status of Aedes species determines geographical risk of autochthonous Zika virus establishment. PLoS Negl Trop Dis. 2017;11(3):e0005487.
Gardner LM, Chen N, Sarkar S. Global risk of Zika virus depends critically on vector status of Aedes albopictus. Lancet Infect Dis. 2016;16(5):522–3.
Kraemer MU, Sinka ME, Duda KA, Mylne AQ, Shearer FM, Barker CM, et al. The global distribution of the arbovirus vectors Aedes aegypti and Ae. albopictus. Elife. 2015;4:e08347.
Theze J, Li T, du Plessis L, Bouquet J, Kraemer MUG, Somasekar S, et al. Genomic epidemiology reconstructs the introduction and spread of Zika virus in Central America and Mexico. Cell Host Microbe. 2018;23(6):855–64 e7.
WorldBank. International Comparison Program database. GDP per capita, PPP 2016. Available from: https://data.worldbank.org/indicator/NY.GDP.PCAP.PP.CD.
U.S. Bureau of Economic Analysis. GDP by State. Available from: https://www.bea.gov/data/gdp/gdp-state.
U.S. Department of Health and Human Services. Health, United States. 2015. Available from: https://www.cdc.gov/nchs/data/hus/hus15.pdf.
World Health Organization (WHO). WHO World Health Statistics. Available from: http://www.who.int/gho/publications/world_health_statistics/2015/en/.
World Health Organization (WHO)/Pan American Health Organization (PAHO). PLISA Health Indication Platform for the Americas. 2017. Available from: http://www.paho.org/data/index.php/en/.
World Bank Open Data. Population density (people per sq. km of land area). 2016. Available from: http://data.worldbank.org/indicator/EN.POP.DNST.
International Air Travel Association (IATA)- Passenger Intelligence Services (PaxIS): http://www.iata.org/services/statistics/intelligence/paxis/Pages/index.aspx.
Pigott D, Deshpande A, Letourneau I, Morozoff C, Reiner R Jr, Kraemer M, et al. Local, national, and regional viral haemorrhagic fever pandemic potential in Africa: a multistage analysis. Lancet. 2017;390(10113):2662–72.
Leontaritis IJ, Billings SA. Input-output parametric models for non-linear systems part I: deterministic non-linear systems. Int J Control. 1985;41(2):303–28.
Narendra KS, Parthasarathy K. Identification and control of dynamical systems using neural networks. IEEE Trans Neural Netw. 1990;1(1):4–27.
Chen S, Billings SA, Grant PM. Non-linear system identification using neural networks. Int J Control. 1990;51(6):1191–214.
Siegelmann HT, Horne BG, Giles CL. Computational capabilities of recurrent NARX neural networks. IEEE Trans Syst Man Cybern B Cybern. 1997;27(2):208–15.
Tsungnan L, Bill GH, Peter T, Giles CL. Learning long-term dependencies is not as difficult with NARX recurrent neural networks. College Park: University of Maryland; 1995. p. 23.
Boussaada Z, Curea O, Remaci A, Camblong H, Mrabet Bellaaj N. A nonlinear autoregressive exogenous (NARX) neural network model for the prediction of the daily direct solar radiation. Energies. 2018;11(3):620.
Fawcett T. ROC graphs: notes and practical considerations for researchers. Mach Learn. 2004;31:1–38.
Bogoch II, Brady OJ, Kraemer MUG, German M, Creatore MI, Kulkarni MA, et al. Anticipating the international spread of Zika virus from Brazil. Lancet. 2016;387(10016):335–6.
Faria NR, Quick J, Claro IM, Thézé J, de Jesus JG, Giovanetti M, et al. Establishment and cryptic transmission of Zika virus in Brazil and the Americas. Nature. 2017;546:406.
Brockmann D, Helbing D. The hidden geometry of complex, network-driven contagion phenomena. Science. 2013;342:1337–42.
Acknowledgements
We thank Raja Jurdak and Dean Paini for their inputs and discussion on the model.
Funding
We received no funding for this work.
Author information
Authors and Affiliations
Contributions
LG and MA conceived the study, designed the experiments, analyzed the model results, and drafted the original manuscript. MA developed the model and performed the computational analysis. MUGK contributed vector distribution data. All authors contributed to the data curation and editing of the manuscript. LG supervised the study. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Data (cases). Country- or territory-level weekly Zika cases. (XLSX 30 kb)
Additional file 2:
Data (incidence). Country- or territory-level weekly Zika incidence rates. (XLSX 40 kb)
Additional file 3:
Data (incoming_travel). Country- or territory-level weekly incoming travel volume. (XLSX 68 kb)
Additional file 4:
Data (outgoing_travel). Country- or territory-level weekly outgoing travel volume. (XLSX 68 kb)
Additional file 5:
Data (suitability). Country- or territory-level weekly Aedes vector suitability. (XLSX 68 kb)
Additional file 6:
Data (gdp). Country- or territory-level GDP per capita. (XLSX 9 kb)
Additional file 7:
Data (physicians). Country- or territory-level physicians per 1000 people. (XLSX 9 kb)
Additional file 8:
Data (beds). Country- or territory-level beds per 1000 people. (XLSX 9 kb)
Additional file 9:
Data (pop_density). Country- or territory-level population densities (people per sq. km of land area). (XLSX 10 kb)
Additional file 10:
Data (case_weighted_travel_risk). Country- or territory-level weekly case-weighted travel risk. (XLSX 66 kb)
Additional file 11:
Data (incidence_weighted_travel_risk). Country- or territory-level weekly incidence-weighted travel risk. (XLSX 67 kb)
Additional file 12:
Figure S1. Number of high-risk countries each week under all absolute risk classification schemes. The number of countries classified as high risk each week for each absolute case incidence threshold, ranging from A = 50 to A = 90. In parentheses is the weekly incidence rate defining the high-risk threshold based on the percentile (A) specified. (EMF 45 kb)
Additional file 13:
Table S2. Summary of model performance. ACC is presented for each combination of risk indicator (case count and incidence rate), classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5, and A = 90, 80, 70, 60, 50) and forecast window (i.e., N = 1, 2, 4, 8, and 12), for selected Epi weeks throughout the epidemic. ROC AUC (averaged over all locations and all EPI weeks) is computed for all combinations of risk indicator (case count and incidence rate), classification scheme (i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5 and A = 90, 80, 70, 60, 50) and forecast window (i.e., N = 1, 2, 4, 8 and 12). (DOCX 21 kb)
Additional file 14:
Figure S2. Aggregate model performance measured by ROC AUC. The ROC AUC is averaged over all locations and all weeks, for each relative risk classification scheme, i.e., R = 0.1, 0.2, 0.3, 0.4, 0.5 and forecast window i.e., N = 1, 2, 4, 8, and 12. For the results shown the risk indicator is case counts. (DOCX 212 kb)
Additional file 15:
Table S1. Summary of model sensitivity to feature selection. The ACC and ROC AUC performance of the model is computed and presented under different combinations of input data features. The proposed model is compared against two baseline models; one includes only case (and incidence) data, and the second includes case and all non-travel related data, while the final proposed model includes all features. The results presented are for the absolute risk classification scheme, where the risk indicator is incidence rate. (DOCX 21 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Akhtar, M., Kraemer, M.U.G. & Gardner, L.M. A dynamic neural network model for predicting risk of Zika in real time. BMC Med 17, 171 (2019). https://doi.org/10.1186/s12916-019-1389-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12916-019-1389-3