
Abstract
Background
Extensive clinical evidence suggests that a preventive screening of coronary heart disease (CHD) at an earlier stage can greatly reduce the mortality rate. We use 64 two-dimensional speckle tracking echocardiography (2D-STE) features and seven clinical features to predict whether one has CHD.
Methods
We develop a machine learning approach that integrates a number of popular classification methods together by model stacking, and generalize the traditional stacking method to a two-step stacking method to improve the diagnostic performance.
Results
By borrowing strengths from multiple classification models through the proposed method, we improve the CHD classification accuracy from around 70–87.7% on the testing set. The sensitivity of the proposed method is 0.903 and the specificity is 0.843, with an AUC of 0.904, which is significantly higher than those of the individual classification models.
Conclusion
Our work lays a foundation for the deployment of speckle tracking echocardiography-based screening tools for coronary heart disease.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Background
Coronary heart disease (CHD) is a global epidemic. It led to around 18 million (roughly one-third of) deaths worldwide in the year 2016 [1,2,3,4]. Preventive screening of CHD at an earlier stage can significantly reduce the mortality rate, improve the prognosis, and provide therapeutic guidance for patients [5]. Despite urgent needs, an efficient and effective screening procedure is still lacking. The majority of CHD diagnostic procedures are radiology-based approaches such as the computed tomography angiography (CTA) and the coronary angiography (CA). These methods can directly visualize the coronary artery and quantify the level of artery occlusion. As a result, these methods are considered the gold standard for diagnosis. Though the radiology-based methods are fairly effective in the CHD diagnosis, their applications in preventive practice are severely limited by the high operational cost, the requirement of expensive and high-maintenance equipment, the need for experienced medical staffs, and potential side effects [6].
A much less explored alternative is the echocardiography-based diagnosis methods, which are commonly used to visualize the movements of the myocardium. In fact, clinical practice suggests that some echocardiology-based techniques, such as the two-dimensional speckle tracking echocardiography (2D-STE) [7], can indeed prognosticate CHD. Accumulating evidence shows that some dynamic features extracted by the 2D-STE, such as the global longitudinal strain [8] and the time-to-peak strain change, differ significantly between CHD patients and non-CHD patients [9]. These observations suggest that the 2D-STE holds a new promise for the CHD screening [10]. However, effective assessment models that can single out early-stage CHD patients with adequate sensitivities and specificities are still lacking. It remains unknown which set of echocardiography-based features can effectively quantify the significance of the myocardial change in response to a minor myocardial anomaly. The requirement of the laboratory-based practice, as opposed to the in-field and real-time analysis, limits their utility for the large-scale population practice.
The rapid development of machine learning (including computer vision) techniques has triggered a medical technology revolution. For example, the first clinical-grade computational pathology algorithm was proposed in [11] for the diagnosis of three types of cancers with an average accuracy of 98%. In recent years, machine learning methods were applied to processing images of echocardiograms. These methods, such as convolutional neural networks (CNNs), can help extract image structures and features that are valuable in diagnosis [12,13,14]. For example, CNNs are trained to automatically classify views of echocardiograms, and to extract features from echocardiograms to detect certain diseases [15, 16]. Besides the applications in image segmentation and interpretation, machine learning methods are also expected to play a pivotal role in assisting highly skilled personnel in disease diagnosis by utilizing a series of quantitative, reproducible, and multiplexed features extracted from large amounts of clinical practice. Machine learning methods can capture the potential connection between the features and the diagnosis. For example, in [17], the majority voting method [18] is applied in distinguishing the hypertrophic cardiomyopathy from physiological hypertrophy in athletes using expert-annotated speckle-tracking echocardiographic features.
In this article, we aim to develop a machine learning method that takes echocardiographic features as input and classifies whether the subject has CHD. There are many machine learning methods that can be employed to develop a classification method. Existing classification methods have various underlying model assumptions, which hold the key to the success of the methods. When the data is highly heterogeneous and noisy, as is the case for the echocardiographic data that we analyze, it is not clear which method is suitable as the underlying assumptions are usually hard to validate. Furthermore, no single classification method provides satisfactory prediction results.
To improve the classification performance, we integrate 14 classification methods together by an ensemble learning method to provide the best prediction. Through the ensemble learning method, we thus aggregate the strength of all 14 individual classifiers to build the final prediction model. In particular, we generalize the traditional stacking method to a two-step stacking method. The first-step stacking can improve the individual prediction by aggregating diversified classifiers; by randomly partitioning the training set multiple times for the second-step stacking, we can reduce the classification errors caused by wrong model aggregation, and weaken the effects of the poor performance of individual classifiers.
Methods
In this section, we first present the data used in our study, then briefly review the machine learning applications in echocardiographic analysis and the ensemble learning methods, and finally propose the two-step stacking method.
Human subjects
Our study was a retrospective study based on the clinical trial (NCT03905200). From March 1, 2019 to August 30, 2019, 555 patients were admitted for coronary angiography as suspicious CHD patients. Patients older than 18 were enrolled with written consents. The documentary evidence can be provided if required. We excluded patients with non-sinus rhythms, severe heart diseases other than CHD, or other extremely severe organ illnesses.
The echocardiograms were recorded by one experienced clinician on a GE Vivid E9 system (GE Medical Systems, Horten, Norway). Patients’ images were stored in the same machine. Images were transported to an offline EchoPac system of version 201 (GE Healthcare, Horten, Norway), and were further analyzed by an experienced investigator. We then excluded patients with low-quality images that EchoPac has troubles in processing.
The study has been performed in accordance with the Declaration of Helsinki, and was approved by the Ethics Committee of the Beijing Hospital.
Data and features
There were 555 patients examined by a CA or a coronary CTA. Among the 555 patients, 424 of them had an echocardiography one day before the angiography was conducted. Patients with vessel stenosis of at least 50% in the major coronary artery or at least one of its main branches were considered as CHD positive patients [19]. Based on such criteria, 217 of those 424 patients are CHD positive.
For each patient, the recorded echocardiography consists of three parasternal short-axis standard sections: the mitral valve section, the papillary muscle section, and the apical section, as well as three standard apical sections: the four-chamber view section, the two-chamber view section, and the longitudinal long-axis view section. The left ventricular wall (LVW) is divided into 17 segments based on the standard American Heart Association (AHA) 17-segment model [20], each of which has been analyzed individually. Peak systolic longitudinal and radial strains are assessed in all 17 segments to quantify the shortening and thickening of the myocardium for each segment, respectively. The epicardium and endocardium of the left ventricle (LV) are traced automatically and adjusted manually if necessary at the end-systole. The mid-myocardial border is determined at the midpoints between the endocardial and the epicardial borders. The regions of interest (ROIs) cover the endocardium, the myocardium, and the epicardium. The ROIs have been locally adjusted if they are off-track.
In the 2D-STE echocardiography, the most important parameter is the strain, which quantifies the deformation of the myocardium by recording the contractions. Since the ventricular contractile dysfunction occurs prior to the electrocardiogram (ECG) change in the sub-endocardium, the diagnostic accuracy based on strains tends to be higher than ECG, troponin, and GRACE score [21]. The longitudinally orientated myocardial fibers are the most susceptible to ischemia [8, 22]. Therefore, the global longitudinal strain has been recommended as the index with the top priority in diagnosing cardiac diseases [23, 24]. It is shown in [25] that the GLPS can successfully predict CHD (AUC=0.92) for patients with non-ST-segment elevation acute coronary syndromes (NSTE-ACS). In the myocardium, micro-vascular communications are network structured. The communication can form some dual arterial perfusion zones. Simply relying on one single index might be inaccurate to decide the etiology. The assessment of myocardium ischemia can be measured by the global longitudinal strain, the global radio strain, the peak systolic strain (PSS), the systolic strain rate (SSR), time to peak (TP), and specific layer strains [26, 27]. The myocardium usually consists of three heterogeneous layers of muscle fibers [28]. Layer-specific strain is associated with coronary artery disease independently[26]. Layer-specific analyses of endocardial, mid-myocardial, and epicardial strains are performed in GLPS as well as the radial strain in the three parasternal short-axis standard sections.
Data pre-processing
As shown in Table 1, we consider 71 features as our predictors for building a machine learning model to predict the risk of CHD, including 64 strain-based numerical features from 2D-STE, age, gender, and five categorical features indicating common risk factors for coronary heart disease. According to [29], obesity is also a common risk factor for coronary heart disease. However, since the study is a retrospective study, obesity has not been recorded when collecting data. Due to the high correlation between obesity, diabetes, hypertension and, hyperlipidemia [30], we include diabetes, hypertension, and hyperlipidemia instead. The other two risk factors we consider are family history and smoking. The summary of the clinical characteristics of the subjects is shown in Table 2, including age, body mass index (BMI), systolic blood pressure (SBP), diastolic blood pressure (DBP), heart rate, gender, hypertension, diabetes, hyperlipidemia, family history, and smoking. From the data summary, we can see that most of the clinical characteristics are balanced between the case group (patients with CHD positive) and the control group (patients with CHD negative). However, we observe a significant increase in the proportion of smoking subjects in the case group when compared with the control group. This observation supports the intuition that smoking is a common risk factor for coronary heart disease. For the 64 numerical features from 2D-STE, we compare the differences of each feature between the case group and the control group through the two-sample t-test [31]. The testing results show how significantly CHD can have impacts on each feature. To reduce the dimension of features, we apply the principal component analysis (PCA) [32] on the 17 segments of PSS, SSR, and TP.
Machine learning in echocardiographic analysis
Machine learning methods have been widely applied in fields of echocardiographic analysis [16, 17, 33,34,35,36,37,38]. Recently, most of the applications of the machine learning methods on echocardiogram focus on image segmentation and interpretation [16, 35, 36]. The methods can learn the shape and size of the region of interest from a labeled training set [39,40,41,42,43,44,45,46]. For example, machine learning methods are applied to analyzing the cardiac structures, such as determining global features that can be used to identify standard views of echocardiograms [15], extracting hidden features to detect heart diseases such as hypertrophic cardiomyopathy [16], identifying certain local structures like pacemaker lead [36], and recognizing the boundaries of ventricle and atrium [35, 36]. Based on the extracted features, [36] shows that the machine learning method can identify severely dilated left atrium and left ventricular hypertrophy, estimate right atrium major axis length and left atrial volume, and predict patient age, gender, weight, and height. These studies support the hypothesis that machine learning methods can play a promising role in accelerating the image-based diagnostic process. The advantage of applying machine learning methods in analyzing medical images lies in the fact that machine learning methods can not only identify features that can be manually recognized, but also extract hidden-layer features that may be difficult to identify [17, 33, 34]. In this paper, we apply machine learning methods on the strain-based local features of the 17 segments as well as the clinical features to link these features to the diagnosis of CHD through the hidden interactions. More specifically, we use machine learning methods to integrate those features through a data-driven diagnostic system built up by classification models and ensemble learning.
Ensemble learning and two-step stacking
When taking echocardiographic features as input to classify whether the patient has CHD, individual classifiers may not provide satisfactory results, as the echocardiographic data is highly heterogeneous and noisy [47]. We thus consider multiple classifiers and apply the ensemble learning method to aggregate the strength of all these classifiers to obtain a more precise result [47]. More specifically, we apply the stacking method in this work, since stacking is particularly popular when the signal-to-noise ratio of the data is low [48, 49]. The general idea of the stacking is similar to the “majority voting” [18]. To illustrate the stacking method, we thus first look at the majority voting method. Suppose there are L pre-trained classifiers. For one testing data, each classifier gives one classification result \(c_l\), for \(l = 1,..., L\). When applying majority voting, one can obtain a final classification result \(c_f\) as follows,
where \(1(\cdot )\) is an indicator function, or a characteristic function, which equals one if the inequality holds and zero otherwise.
In (1), the L classifiers have equal weights. One can generalize the majority voting to the weighted voting [50],
where \(w_l\) is the weight for classifier \(l, l=1,\ldots , L\). Stacking is a generalized weighted voting method. In stacking, the weights \(w_1\) through \(w_L\) are trained on a validation set through another layer of learning algorithm, with the predictions of the L classifiers on such validation set as the inputs. For example, the “weights” can be estimated through a linear regression by minimizing the least square errors. Notice that in stacking, the “weights” are estimated by learning algorithms that can be rather complex. As a result, the “weights” may be negative [51]. In this study, we apply the random forest algorithm [52] to estimate the stacking weights.
As illustrated in (1) and (2), we can see that in ensemble learning methods, the basic idea is to combine a number of classifiers or learners. Some of the individual learners may be just slightly better than random guesses, thus the individual learners are also referred to as “weak learners”. Through some combination, the predicting power can be improved, then the ensemble is called a “strong learner” [53, 54]. In ensemble learning, the fundamental issue is the diversity of the “weak learners” [47]. It is expected that we will not gain much from the combination if there are not many differences between the weak learners. In other words, the combination of highly correlated weak learners may still result in a weak learner with little improvement. In ensemble learning, the model diversity plays a more important role than the model accuracy of the individual model. As a result, combining individual models with high accuracy, and those with accuracy relatively low always performs better than only combining the accurate ones [47]. However, if some individual models are quite poor, they may degrade the performance of the combination. Thus how to balance the model diversity and individual accuracy is quite challenging in ensemble learning [47, 54]. In our study, We consider different classes of models vary from traditional parametric model such as logistic regression to the state-of-art learning process such as the neural network. Furthermore, we generalize the classic stacking method to a two-step stacking method to achieve a trade-off between diversity and accuracy. Specifically, in the first step, we train individual classifiers \(c_{l}^{(k)}, l=1,\ldots , L\) and the weights \(w_l^{(k)}, l=1,\ldots , L\) on the kth randomly sampled training data. In this step, we have classifiers with multiple levels of performance included to expand the model diversity. We repeat this process K times, and denote
In the second step, we further stack the K classification results \(c^*_k, k=1,\ldots , K\) through the weights \(w^*_k, k=1,\ldots , K\) trained on the validation data. The second step then can weaken the effects of the poor performance of individual classifiers and reduce the classification errors caused by wrong model aggregation in the first step. We then get the final classifier,
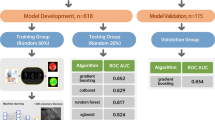
In particular, as shown in Fig. 1, we set \(15\%\) of the 424 subjects as the testing set. Among the remaining \(85\%\) subjects, we then set \(20\%\) as the validation set and the remaining as the training set for the second-step stacking. For the first-step stacking, we also set \(20\%\) of the subjects as the validation set. More specifically, we divide the 424 subjects into a testing set that contains 64 subjects, a training set that contains 288 subjects, and a validation set that contains 72 subjects. For the first step stacking, we repeatedly sample 230 individuals randomly from the training set as the first-step training set to train the classifiers \(c_l^{(k)}\)s in Eq. (3), and use the rest of 58 subjects as the first-step validation set to train the stacking weights \(w_l^{(k)}\)s in Eq. (3). In this paper, we build 14 classifiers using 14 machine learning approaches, i.e. \(L = 14\). We repeat the process 10 times, i.e., \(K = 10\), so that we obtain 10 classifiers for the second step stacking. The second-step stacking weights \(w^*_k\)s in Eq. (4) are trained on the pre-determined validation set of size 72. To avoid the effects brought by the imbalance of labels through random splitting, we apply the stratify splitting to split the dataset based on the labels so that in each sub-sample, the CHD negative-to-positive ratio remains similar.

Flowchart of the two-step stacking method. The testing set of size 64, named “Testing”, is used to evaluate the proposed method. The validation set of size 72, named “Validation 0”, is used to train the second-step stacking weights \(w^*_k, k = 1, ...., 10\) in Eq. (4). The rest set of size 288 is randomly divided into a first-step training set (named “Training 1” through “Training 10”) of size 230 and a first-step validation set (named “Validation 1” through “Validation 10”) of size 58 to train the 14 individual classifiers \(c^{(k)}_l, l = 1, ..., 14\) and first-step stacking weights \(w^{(k)}_l, l = 1, ..., 14\) in Eq. (3) for 10 times
Results
Two-sample t-test on features
We compare the differences of GLPS’s between the case group and the control group in three layers of the myocardium using a two-sample t-test. We record the p values for the testing. Note that a small p value indicates a significant difference. In this study, we use the threshold p value \(\le 0.05\) to determine if the difference is significant. Intuitively, we claim that the CHD has a greater effect on a feature if the difference of such feature between the case group and the control group is more significant. The p values for the two-sample t-test on GLPS’s are shown in Table 3. The results confirm that CHD has significant effects on GLPS values. We also conduct the two-sample t-test on PSS, SSR, and TP. From the testing results, we can see that PSS, SSR, and TP are also important features for CHD prediction. When considering the radial strains, the two-sample test results for the radial strains in the apical section (SAX-AP), the papillary muscle section (SAX-PM), and the mitral valve section (SAX-MV) indicate that the radial strain contributes less than the longitudinal strain in CHD prediction (the p values are all listed in Table 3).
Principal component analysis
We first study the correlations among the numerical features. Panel (A) in Fig. 2 shows the correlations between global longitudinal strains and radial strains. We can see that longitudinal strains are weakly correlated with radial strains. For radial strains, each section is weakly correlated with each other. Panel (B) in Fig. 2 shows the correlations among 17 segments on PSS, SSR and TP. From the correlation matrix, we can see that PSS is correlated with SSR, while TP is weakly correlated with both PSS and SSR. When examining the correlation among the 17 segments for PSS, SSR, and TP, respectively, we divide the 17 segments into apex, apical, mid-cavity, and basal levels based on the AHA 17-segment model, as shown in panel (B) of Fig. 4. We can see that (1) the apex and apical levels are highly correlated; (2) for PSS, six segments in the mid-cavity level are highly correlated with their neighboring segments in the basal level; (3) for SSR, mid-cavity level and basal level are weakly correlated; and (4) for TP, the correlations among all 17 segments are higher than those in PSS and SSR. Based on the results of the correlation study, we choose to conduct PCA on PSS, SSR, and TP, respectively.

Correlations among features. a Correlation matrix of global longitudinal strains and radial strains of apical level, papillary muscle level and mitral valve level. b Correlation matrix of 17 segments on PSS, SSR and TP
Figure 3 shows the scree-plots of PCs for features in PSS, SSR, and TP. In each plot, we can find obvious “elbows”, based on which we choose the proper number of PCs to retain in the model. Figure 4 shows the heatmaps of the first 3 PC loadings for PSS, SSR, and TP, respectively. From Fig. 4, we can see that (1) for PSS, SSR, and TP, the first PCs roughly represent the overall average of the 17 segments. (2) For PSS, the second PC represents the basal/mid inferoseptal, the basal/mid inferior, and the basal/mid inferolateral; the third PC represents the basal/mid anterior and the basal/mid anterolateral. (3) For SSR, the second PC represents the basal/mid anteroseptal and the basal/mid inferolateral; the third PC represents the basal layer. (4) For TP, the second PC represents the basal/mid anterior, the basal/mid anterolateral, and the basal/mid inferolateral; the third PC is similar to the second PC. Thus we choose the first three PCs for PSS and SSR, and the first two PCs for TP.

Screeplot of PCA on peak systolic strain, systolic strain rate and time-to-peak

a Heatmaps of contributions of 17 segments in first three PCs of peak systolic strain, systolic strain rate and time-to-peak. Column from left to right represents the first PC to the third PC respectively, and the top row represents PSS, the middle row represents SSR and the bottom row represents TP. b Bullseye plot of the AHA 17-segment model
Two-step stacking
We use the R-package caret to build 19 commonly used classifiers. The hyper-parameters for the individual classification model are automatically tuned based on the cross-validation method. After 50 replicates, Table 4 reports the mean accuracy of all individual classifiers on the testing set, with the standard deviation listed in the brackets. We can see that the highest accuracy is \(71\%\). Based on the individual accuracy, we first exclude the five classifiers with the accuracy below \(60\%\). For the remaining 14 classifiers, we conduct the ensemble learning method to improve the classification accuracy. Since there is no significant difference among the performance of the remaining 14 models, the question then is how to balance “model accuracy” and “model diversity” in ensemble learning? To answer this question, we consider the traditional weighted voting method, traditional model stacking, and the proposed two-step stacking on three best-performing individual models with accuracies above \(70\%\), and compare the results with those on all the 14 remaining models. The results of 50 replicates are shown in Table 5, with Fig. 5 showing the ROC curves. In Fig. 5, the purple lines present each individual model, the red lines represent the traditional weighted voting method, the blue lines represent the traditional stacking model, and the black lines represent our two-step stacking model. For the three ensemble learning methods, the solid lines represent the ensemble on all 14 models, and the dashed lines represent the ensemble on the three “best-performing” models. We then interpret the results from the following three aspects.
-
1.
The stacking methods outperform the weighted voting methods. Such an observation indicates that the stacking method can combine the individual results in a more efficient way.
-
2.
The 3-model weighted voting only slightly improves the accuracy compared with the individual models. It indicates that the three models may be highly correlated, i.e., the diversity is not enough for a considerable improvement for the ensemble. The 14-model ensemble methods result in a better performance than the 3-model ensemble methods. The results confirm the importance of model diversity in ensemble learning, especially when models are combined through a more complex way in model stacking.
-
3.
The traditional model stacking improves the classification accuracy from the \(67.3\%\) (the average accuracy for the individual models) to \(72.5\%\). Through the proposed two-step stacking, we further improve the classification accuracy to an average of \(87.7\%\) on the testing set, with a sensitivity of 0.903 and a specificity of 0.843. In fact, the two-step stacking method significantly outperforms all the other methods.
Based on [25], using GLPS can successfully predict CHD for NSTE-ACS patients with an AUC of 0.92. We apply our method on GLPS only to see if the accuracy remains. The results are also listed in Table 5, we can see that the accuracy based on GLPS only drops to \(63.3\%\) with an AUC of 0.67. Such a drop may be caused by the quality of images in the retrospective study. During the retrospective study, the data were collected during real-time medical treatment, where the priority is efficiency. Thus the data quality may become hard to control. In summary, our method shows the best diagnostic performance in identifying CHD patients among all the methods we compared. The codes for the final 14-classifier two-step stacking model prediction are available in the supplementary materials (additional file 1).

ROC curves of 1. the ensemble learning methods on 14 individual models, 2. the ensemble learning methods on the three “best-perform” models, and 3. the three “best-perform” individual models. The ensemble learning methods including the two-step stacking methods, the traditional stacking methods, and the weighted voting methods. The purple lines represent the individual models. The black lines represent the two-step stacking methods, the blue lines represent the traditional stacking methods, and the red lines represent the weighted voting methods, with the solid lines represents ensemble on 14 models, and the dashed lines represent ensemble on 3 models
Discussion
Clinical implication
Imaging techniques have been applied to prognosis and prevention to reduce morbidity and mortality [55]. Among all the imaging techniques, echocardiography is one of the most promising techniques in the cardiovascular field. It is noninvasive, convenient, safe, and effective. 2D-STE as a novel technique has its advantage compared with the conventional echocardiography and other modalities. The sub-endocardial myocardial fibers are oriented longitudinally, so the longitudinal myocardial function is affected primarily when ischemia is onset. The decrease in global longitudinal strain, which suggests the ventricular contractile dysfunction, occurs prior to ECG change. Therefore, the machine learning model based on features with the global longitudinal strain included is more efficient than the ECG. Traditionally, the conventional echocardiographic parameters are mostly estimated by a visual assessment of the ventricular wall contraction in CHD patients. However, subtle abnormalities might be overlooked by human eyes [21]. This clinical practice renders the conventional echocardiography ineffective in the diagnosis of CHD in general and the early stage CHD in particular. Thus, the effectiveness of conventional echocardiography is limited in CHD diagnosis, especially in the early stage. Since the 2D-STE image can detect the tiny abnormalities of the systolic function [25, 56], it is more promising in CHD diagnosis than the conventional echocardiogram.
Compared to coronary angiography, our echocardiography-based method can be applied to almost all patients. Coronary angiography is the gold standard in the diagnosis of stenosis. However, due to its potential medical risks, angiography is not recommended to all patients, such as elder patients, or patients with other end-stage organ failures. 2D-STE helps rule out patients without coronary heart disease and avoid unnecessary coronary angiography. Compared with the time-consuming tests such as MRI and SPECT, our method can provide the diagnosis result in less time.
The potential clinical applications of the echocardiography-based machine learning method are extensive. Clinicians are always searching for a safer and more effective method for the diagnosis and prognosis of CHD. Studies have shown that the early-stage medical intervention can reduce the mortality and morbidity for CHD [57]. We believe that our method holds a promise to provide a more efficient and noninvasive early screening and diagnosis of CHD, and could bring a revolutionary impact on the diagnosis modality. Moreover, our method based on 2D-STE can also help in re-evaluating the recovery from ischemia after the first hospitalization. It can be recommended as a routine in the physical examination.
Method innovation
Our method is an ensemble learning method. The ensemble learning methods can be divided into three classes: bagging, boosting, and stacking [47]. In particular, bagging aims to reduce variance, boosting decreases bias, and stacking improves the prediction. Since the goal of this study is to improve the prediction power, we use the stacking method to aggregate the strengths of popular machine learning methods [48, 49]. We generalize the traditional stacking method to a two-step stacking method to achieve a trade-off between the model diversity and accuracy in ensemble learning. The first-step stacking aggregates diversified classifiers to improve the individual prediction; the second-step stacking combines multiple first-step stacking classifiers under randomly partitioned training sets to weaken the effects of the wrong model aggregation and the poor performance of individual classifiers.
Limitations
Our study is a single-center study. The data are collected from the same medical system. Different echo-cardiographic inter-vendors and post-processing algorithms were not applied. The single data-collecting system and the relatively small dataset may increase the instability of the models and lead to low generalizability of the results. We have reached an agreement with other hospitals to collect more data from multiple medical centers. There are potential difficulties in analyzing multi-center data, such as the concerns on the data privacy and data heterogeneity. To overcome these two major concerns, we consider applying the decentralized system. Furthermore, with the multi-center data, we can extend the method to an adaptive learning process so that the model can automatically update when bringing in new samples. Another limitation is that the speckle tracking analysis can not be conducted automatically. The subjective effects of different physicians might also affect the final prediction. In addition, when processing low-quality images, EchoPac can not recognize the epicardial or endocardial border. Therefore, it may bring certain biases to the results. We are now developing an automatic image quality-control and tracing technique for analyzing echocardiograms. By reducing the user intervention in both image feature extracting and classification analysis, we can effectively minimize subjective errors.
Future works
With the advantages of machine learning methods in accelerating the image-based diagnostic process, we explore the potential use of machine learning in echocardiographic analysis in the following two aspects.
-
1.
Image quality control The machine learning methods are promising in identifying standard views of echocardiograms [15, 16, 35, 36]. When combining with the statistical hypothesis test, we can apply the machine learning methods in echocardiographic quality control. Specifically, the testing method, especially the non-parametric test, can quantify the differences between individual echocardiograms and the “standard” echocardiograms utilizing the features extracted by machine learning methods [58, 59]. Based on the quantified differences, the quality control method can weed out the low-quality images automatically, thus can improve the accuracy in the image-based diagnosis.
-
2.
Image segmentation and tracing Existing image segmentation methods require a large quantity of annotated training datasets [35]. Labeling images, especially medical images, is super labor-intensive and time-consuming. The application of optimal transport, deformation mapping, and transfer learning can help develop a reference-based image segmentation and tracing method. Such a method can detect certain local structures in echocardiograms through a “transfer” from the typical annotated references [60]. The volume of the training set thus can be reduced to a size that can be processed in practice.
Conclusion
Our method enjoys the following practical advantages in screening CHD. First, our method shows a good diagnostic performance in identifying CHD patients, i.e., 87.7% (accuracy), 90.3% (sensitivity), 84.3% (specificity). Second, compared with some conventional CHD diagnosis technologies, e.g., coronary angiography, our method is noninvasive. Our predictive model only requires the 2D-STE features and some commonly used clinical features. Third, compared with traditional time-consuming tests, e.g., MRI and SPECT, our method can provide diagnosis results in significantly less time. In summary, our method holds a promise to provide a more efficient and noninvasive early screening and diagnosis of CHD.
Availability of data and materials
One testing dataset supporting the conclusions of this article is included in the supplementary materials (additional file 2). Other datasets and the trained stacking models used and analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- 2D-STE:
-
Two-dimensional speckle tracking echocardiography
- AHA:
-
American Heart Association
- CA:
-
Coronary angiography
- CHD:
-
Coronary heart disease
- CTA:
-
Computed tomography angiography
- ECG:
-
Electrocardiogram
- GLPS:
-
Global longitudinal peak strain
- LV:
-
Left ventricle
- LVW:
-
Left ventricular wall
- PCA:
-
Principal component analysis
- PSS:
-
Peak systolic strain
- ROI:
-
Region of interest
- SSR:
-
Systolic strain rate
- TP:
-
Time to peak
References
...Lloyd-Jones DM, Hong Y, Labarthe D, Mozaffarian D, Appel LJ, Van Horn L, Greenlund K, Daniels S, Nichol G, Tomaselli GF, Arnett GK, Fonarow GC, Ho PM, Lauer MS, Masoudi FA, Robertson RM, Roger V, Schwamm LH, Sorlie P, Yancy CW, Rosamond WD. Force American Heart Association Strategic Planning Task, and Committee Statistics. Defining and setting national goals for cardiovascular health promotion and disease reduction: the American Heart Association’s strategic impact goal through 2020 and beyond. Circulation. 2010;121(4):586–613.
Roth GA, Johnson C, Abajobir A, Abd-Allah F, Abera SF, Abyu G, Ahmed M, Aksut B, Alam T, Alam K, Alla F, Alvis-Guzman N, Amrock S, Ansari H, Arnlov J, Asayesh H, Atey TM, Avila-Burgos L, Awasthi A, Banerjee A, Barac A, Barnighausen T, Barregard L, Bedi N, Belay Ketema E, Bennett D, Berhe G, Bhutta Z, Bitew S, Carapetis J, Carrero JJ, Malta DC, Castaneda-Orjuela CA, Castillo-Rivas J, Catala-Lopez F, Choi JY, Christensen H, Cirillo M, Cooper L Jr, Criqui M, Cundiff D, Damasceno A, Dandona L, Dandona R, Davletov K, Dharmaratne S, Dorairaj P, Dubey M, Ehrenkranz R, El Sayed ZM, Faraon EJA, Esteghamati A, Farid T, Farvid M, Feigin V, Ding EL, Fowkes G, Gebrehiwot T, Gillum R, Gold A, Gona P, Gupta R, Habtewold TD, Hafezi-Nejad N, Hailu T, Hailu GB, Hankey G, Hassen HY, Abate KH, Havmoeller R, Hay SI, Horino M, Hotez PJ, Jacobsen K, James S, Javanbakht M, Jeemon P, John D, Jonas J, Kalkonde Y, Karimkhani C, Kasaeian A, Khader Y, Khan A, Khang YH, Khera S, Khoja AT, Khubchandani J, Kim D, Kolte D, Kosen S, Krohn KJ, Kumar GA, Kwan GF, Lal DK, Larsson A, Linn S, Lopez A, Lotufo PA, El Razek HMA, et al. Global, regional, and national burden of cardiovascular diseases for 10 causes, 1990 to 2015. J Am Coll Cardiol. 2017;70(1):1–25.
Turco JV, Inal-Veith A, Fuster V. Cardiovascular health promotion: an issue that can no longer wait. J Am Coll Cardiol. 2018;72(8):908–13.
Arnett DK, Blumenthal RS, Albert MA, Buroker AB, Goldberger ZD, Hahn EJ, Himmelfarb CD, Khera A, Lloyd-Jones D, McEvoy JW, Michos ED, Miedema MD, Munoz D, Smith Jr.SC, Virani SS, Sr. Williams KA, Yeboah J, and Ziaeian B. 2019 acc/aha guideline on the primary prevention of cardiovascular disease: A report of the American College of Cardiology/American Heart Association task force on clinical practice guidelines. J Am Coll Cardiol. 2019.
Thomas H, Diamond J, Vieco A, Chaudhuri S, Shinnar E, Cromer S, Perel P, Mensah GA, Narula J, Johnson CO, Roth GA, Moran AE. Global atlas of cardiovascular disease 2000–2016: the path to prevention and control. Glob Heart. 2018;13(3):143–63.
Nicholls M. Cardiologists and the burnout scenario. Eur Heart J. 2019;40:5–6.
Blessberger H, Binder T. Two dimensional speckle tracking echocardiography: basic principles. Heart. 2010;96(9):716–22.
Skaarup KG, Iversen A, Jorgensen PG, Olsen FJ, Grove GL, Jensen JS, Biering-Sorensen T. Association between layer-specific global longitudinal strain and adverse outcomes following acute coronary syndrome. Eur Heart J Cardiovasc Imaging. 2018;19(12):1334–42.
Yang B, Daimon M, Ishii K, Kawata T, Miyazaki S, Hirose K, Ichikawa R, Chiang SJ, Suzuki H, Miyauchi K, Daida H. Prediction of coronary artery stenosis at rest in patients with normal left ventricular wall motion. Segmental analyses using strain imaging diastolic index. Int Heart J. 2013;54(5):266–72.
Blessberger H, Binder T. Two dimensional speckle tracking echocardiography: clinical applications. Heart. 2010;96(24):2032–40.
Campanella G, Hanna MG, Geneslaw L, Miraflor A, Silva VWK, Busam KJ, Brogi E, Reuter VE, Klimstra DS, Fuchs TJ. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nature Med. 2019;25(8):1301–9.
Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, Venugopalan S, Widner K, Madams T, Cuadros J, et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 2016;316(22):2402–10.
Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, Thrun S. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 2017;542(7639):115–8.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, Van Der Laak JA, Van Ginneken B, Sánchez CI. A survey on deep learning in medical image analysis. Med Image Analysis. 2017;42:60–88.
Madani A, Arnaout R, Mofrad M, Arnaout R. Fast and accurate view classification of echocardiograms using deep learning. NPJ Digit Med. 2018;1(1):6.
Zhang J, Gajjala S, Agrawal P, Tison GH, Hallock LA, Beussink-Nelson L, Lassen MH, Fan E, Aras MA, Jordan C, Fleischmann KE, Melisko M, Qasim A, Shah SJ, Bajcsy R, Deo RC. Fully automated echocardiogram interpretation in clinical practice: feasibility and diagnostic accuracy. Circulation. 2018;138(16):1623–35.
Narula S, Shameer K, Omar AMS, Dudley JT, Sengupta PP. Machine-learning algorithms to automate morphological and functional assessments in 2d echocardiography. J Am College Cardiol. 2016;68(21):2287–95.
James G. Majority vote classifiers: theory and applications. 1998.
Roffi M, Patrono C, Collet J-P, Mueller C, Valgimigli M, Andreotti F, Bax JJ, Borger MA, Brotons C, Chew DP, et al. 2015 esc guidelines for the management of acute coronary syndromes in patients presenting without persistent st-segment elevation: Task force for the management of acute coronary syndromes in patients presenting without persistent st-segment elevation of the European Society of Cardiology (esc). Eur Heart J. 2016;37(3):267–315.
American Heart Association Writing Group on Myocardial Segmentation, Registration for Cardiac Imaging:, MD Cerqueira, NJ Weissman, V Dilsizian, AK Jacobs, S Kaul, WK Laskey, DJ Pennell, JA Rumberger, T Ryan, et al. Standardized myocardial segmentation and nomenclature for tomographic imaging of the heart: a statement for healthcare professionals from the cardiac imaging committee of the council on clinical cardiology of the American Heart Association. Circulation 2002;105(4):539–542.
Caspar T, Samet H, Ohana M, Germain P, El Ghannudi S, Talha S, Morel O, Ohlmann P. Longitudinal 2d strain can help diagnose coronary artery disease in patients with suspected non-st-elevation acute coronary syndrome but apparent normal global and segmental systolic function. Int J Cardiol. 2017;236:91–4.
Reimer KA, Lowe JE, Rasmussen MM, Jennings RB. The wavefront phenomenon of ischemic cell death. 1. myocardial infarct size vs duration of coronary occlusion in dogs. Circulation. 1977;56(5):786–94.
Nagueh SF, Smiseth OA, Appleton CP. 3rd Byrd BF, Dokainish H, Edvardsen T, Flachskampf FA, Gillebert TC, Klein AL, Lancellotti P, Marino P, Oh JK, Alexandru Popescu B, Waggoner AD, Houston Texas, Oslo Norway, Phoenix Arizona, Nashville Tennessee, Canada Hamilton Ontario, Uppsala Sweden, Ghent, Liege Belgium, Cleveland Ohio, Novara Italy, Rochester Minnesota, Bucharest Romania, and St Louis Missouri Recommendations for the evaluation of left ventricular diastolic function by echocardiography: An update from the american society of echocardiography and the european association of cardiovascular imaging. Eur Heart J Cardiovasc Imaging. 2016;17(12):1321–60.
Nauta JF, Hummel YM, van der Meer P, Lam CSP, Voors AA, van Melle JP. Correlation with invasive left ventricular filling pressures and prognostic relevance of the echocardiographic diastolic parameters used in the 2016 esc heart failure guidelines and in the 2016 ase/eacvi recommendations: a systematic review in patients with heart failure with preserved ejection fraction. Eur J Heart Fail. 2018;20(9):1303–11.
Delgado V, Ypenburg C, van Bommel RJ, Tops LF, Mollema SA, Marsan NA, Bleeker, Schalij MJ, Bax JJ. Assessment of left ventricular dyssynchrony by speckle tracking strain imaging comparison between longitudinal, circumferential, and radial strain in cardiac resynchronization therapy. J Am Coll Cardiol. 2008;51(20):1944–52.
Zhang L, Wu WC, Ma H, Wang H. Usefulness of layer-specific strain for identifying complex cad and predicting the severity of coronary lesions in patients with non-st-segment elevation acute coronary syndrome: Compared with syntax score. Int J Cardiol. 2016;223:1045–52.
Gjesdal O, Hopp E, Vartdal T, Lunde K, Helle-Valle T, Aakhus S, Smith HJ, Ihlen H, Edvardsen T. Global longitudinal strain measured by two-dimensional speckle tracking echocardiography is closely related to myocardial infarct size in chronic ischaemic heart disease. Clin Sci (Lond). 2007;113(6):287–96.
Vendelin M, Bovendeerd PH, Engelbrecht J, Arts T. Optimizing ventricular fibers: uniform strain or stress, but not atp consumption, leads to high efficiency. Am J Physiol Heart Circ Physiol. 2002;283(3):H1072-81.
Torpy JM, Burke AE, Glass RM. Coronary heart disease risk factors. JAMA. 2009;302(21):2388–2388.
Sullivan PW, Ghushchyan VH, Ben-Joseph R. The impact of obesity on diabetes, hyperlipidemia and hypertension in the united states. Qual Life Res. 2008;17(8):1063–71.
Cressie NAC, Whitford HJ. How to use the two sample t-test. Biometrical J. 1986;28(2):131–48.
Wold S, Esbensen K, Geladi P. Principal component analysis. Chemometr Intell Lab Syst. 1987;2(1–3):37–52.
Gandhi S, Mosleh W, Shen J, Chow C-M. Automation, machine learning, and artificial intelligence in echocardiography: a brave new world. Echocardiography. 2018;35(9):1402–18.
Kwon J, Kim K-H, Jeon K-H, Park J. Deep learning for predicting in-hospital mortality among heart disease patients based on echocardiography. Echocardiography. 2019;36(2):213–8.
Sihong Chen, Kai Ma, and Yefeng Zheng. Tan: temporal affine network for real-time left ventricle anatomical structure analysis based on 2d ultrasound videos. arXiv preprint arXiv:1904.00631, 2019.
Ghorbani A, Ouyang D, Abid A, He B, Chen JH, Harrington RA, Liang DH, Ashley EA, Zou JY. Deep learning interpretation of echocardiograms. NPJ Digit Med. 2020;3(1):1–10.
Seetharam K, Raina S, Sengupta PP. The role of artificial intelligence in echocardiography. Curr Cardiol Rep. 2020;22(9):1–8.
Chang A, Cadaret LM, Liu K. Machine learning in electrocardiography and echocardiography: technological advances in clinical cardiology. Curr Cardiol Rep. 2020;22(12):1–7.
Carneiro G, Nascimento JC, Freitas A. The segmentation of the left ventricle of the heart from ultrasound data using deep learning architectures and derivative-based search methods. IEEE Trans Image Process. 2011;21(3):968–82.
X Zhen, A Islam, M Bhaduri, I Chan, and S Li. Direct and simultaneous four-chamber volume estimation by multi-output regression. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015; p. 669–76. Springer.
Chen H, Zheng Y, Park J-H, Heng P-A, Kevin Zhou v. Iterative multi-domain regularized deep learning for anatomical structure detection and segmentation from ultrasound images. In: International Conference on Medical image computing and computer-assisted intervention,2016; pp. 487–95. Springer.
Pace DF, Dalca AV, Brosch T, Geva T, Powell AJ, Weese J, Moghari MH, Golland P. Iterative segmentation from limited training data: applications to congenital heart disease. In: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support,2018; pp. 334–342. Springer.
Dangi S, Yaniv Z, Linte CA. Left ventricle segmentation and quantification from cardiac cine MR images via multi-task learning. In; International Workshop on Statistical Atlases and Computational Models of the Heart,2018; pp. 21–31. Springer.
Giacomo Tarroni, Ozan Oktay, Matthew Sinclair, Wenjia Bai, Andreas Schuh, Hideaki Suzuki, Antonio de Marvao, Declan O’Regan, Stuart Cook, and Daniel Rueckert. A comprehensive approach for learning-based fully-automated inter-slice motion correction for short-axis cine cardiac MR image stacks. In International Conference on Medical Image Computing and Computer-Assisted Intervention,2018; pages 268–276. Springer.
Suyu Dong, Gongning Luo, Kuanquan Wang, Shaodong Cao, Ashley Mercado, Olga Shmuilovich, Henggui Zhang, and Shuo Li. Voxelatlasgan: 3d left ventricle segmentation on echocardiography with atlas guided generation and voxel-to-voxel discrimination. In International Conference on Medical Image Computing and Computer-Assisted Intervention,2018; pages 622–629. Springer.
Vigneault DM, Xie W, Ho CY, Bluemke DA, Noble JA. ω-net (omega-net): fully automatic, multi-view cardiac MR detection, orientation, and segmentation with deep neural networks. Med Image Anal. 2018;48:95–106.
Zhi-Hua Z. Ensemble Methods: Foundations and Algorithms. Chapman and Hall/CRC, 2012.
Wolpert DH. Stacked generalization. Neural Networks. 1992;5(2):241–59.
Breiman L. Stacked regressions. Mach Learn. 1996;24(1):49–64.
Zico KJ, Maloof MA. Dynamic weighted majority: an ensemble method for drifting concepts. J Mach Learn Res. 2007;8:2755–90.
Funda G, Russ W, Pei-Yi T. Stacked ensemble models for improved prediction accuracy. In: Proceedings of Static Analysis Symposium, 2017; pp. 1–19.
Kam Ho T. Random decision forests. In: Proceedings of 3rd international conference on document analysis and recognition, 1995;volume 1, pp. 278–282. IEEE.
Hansen LK, Salamon P. Neural network ensembles. IEEE Trans Pattern Anal Mach Intell. 1990;12(10):993–1001.
Schapire RE. The strength of weak learnability. Mach Learn. 1990;5(2):197–227.
Gomez-Pardo E, Fernandez-Alvira JM, Vilanova M, Haro D, Martinez R, Carvajal I, Carral V, Rodriguez C, de Miguel M, Bodega P, Santos-Beneit G, Penalvo JL, Marina I, Perez-Farinos N, Dal Re M, Villar C, Robledo T, Vedanthan R, Bansilal S, Fuster V. A comprehensive lifestyle peer group-based intervention on cardiovascular risk factors: the randomized controlled fifty-fifty program. J Am Coll Cardiol. 2016;67(5):476–85.
Di Bella G, Pizzino F, Minutoli F, Zito C, Donato R, Dattilo G, Oreto G, Baldari S, Vita G, Khandheria BK, Carerj S. The mosaic of the cardiac amyloidosis diagnosis: role of imaging in subtypes and stages of the disease. Eur Heart J Cardiovasc Imaging. 2014;15(12):1307–15.
Gaye B, Canonico M, Perier MC, Samieri C, Berr C, Dartigues JF, Tzourio C, Elbaz A, Empana JP. Ideal cardiovascular health, mortality, and vascular events in elderly subjects: the three-city study. J Am Coll Cardiol. 2017;69(25):3015–26.
Zhang J, Jin H, Wang Y, Sun X, Ma P, Zhong W. Smoothing spline ANOVA models and their applications in complex and massive datasets. Top Splines Appl. 2018;63.
Xing X, Liu M, Ma P, Zhong W. Minimax nonparametric parallelism test. J Mach Learn Res. 2020;21(94):1–47.
Zhang J, Zhong W, Ma P. A review on modern computational optimal transport methods with applications in biomedical research. arXiv preprint arXiv:2008.02995, 2020.
Funding
Fang Wang is supported by Beijing Municipal Science and Technology Commission for Scientific Research (Z161100000516053). The grant supports the study on the value of speckle tracking technique in the diagnosis and follow-up of coronary heart disease. Fang Wang is also supported by grants from Capital Health Development Research Project (BH2016-071) and the 13th Five-year National Science and Technology Major Project (2017ZX09304026). The fundings had no role in the design of the study, data collection, analysis, or writing of the manuscript.
Author information
Authors and Affiliations
Contributions
JZ and HC proposed the two-step stacking method and constructed the predictive model. JZ and YC wrote the code and analyzed the results. CY recruited the patients in the clinical trial and the designed experiment. YL summarized the echocardiographic features and reviewed the angiography data. HZ managed and completed the experiment. JZ contributed in the method and analysis parts of the manuscript, and HZ contributed in the clinical part. FW and WZ conceived the project. All authors contributed to the preparation of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. Written informed consent was obtained from all individual participants included in the study. The study was approved by Beijing Hospital Ethics Committee (1100000185432).
Consent to participate
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. Written informed consent was obtained from all individual participants included in the study. The study was approved by Beijing Hospital Ethics Committee (1100000185432).
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
stackingModelCode.R; Codes for the final 14-classifier two-step stacking model prediction.
Additional file 2.
TestingDATA.csv; One testing dataset of size 64.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhang, J., Zhu, H., Chen, Y. et al. Ensemble machine learning approach for screening of coronary heart disease based on echocardiography and risk factors. BMC Med Inform Decis Mak 21, 187 (2021). https://doi.org/10.1186/s12911-021-01535-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-021-01535-5