
Abstract
Background
The increased availability of patient reported outcome data makes it feasible to provide patients tailored risk information of cancer treatment side effects. However, it is unclear how such information influences patients’ risk interpretations compared to generic population-based risks, and which message format should be used to communicate such individualized statistics.
Methods
A web-based experiment was conducted in which participants (n = 141) read a hypothetical treatment decision-making scenario about four side effect risks of adjuvant chemotherapy for advanced colon cancer. Participants were cancer patients or survivors who were recruited from an online Dutch cancer patient panel. All participants received two tailored risks (of which the reference class was based on their age, gender and tumor stage) and two generic risks conveying the likelihood of experiencing the side effects. The risks were presented either in words-only (‘common’ and ‘very common’), or in a combination of words and corresponding numerical estimates (‘common, 10 out of 100’ and ‘very common, 40 out of 100’). Participants’ estimation of the probability, accuracy of their estimation, and perceived likelihood of occurrence were primary outcomes. Perceived personal relevance and perceived uncertainty were secondary outcomes.
Results
Tailored risks were estimated as higher and less accurate than generic risks, but only when they were presented in words; Such differences were not found in the verbal and numerical combined condition. Although tailoring risks did not impact participants’ perceived likelihood of occurrence, tailored risks were perceived as more personally relevant than generic risks in both message formats. Finally, tailored risks were perceived as less uncertain than generic risks, but only in the verbal-only condition.
Conclusions
Considering current interest in the use of personalized decision aids for improving shared decision-making in oncology, it is important that clinicians consider how tailored risks of treatment side effects should be communicated to patients. We recommend both clinicians who communicate probability information during consultations, and decision aid developers, that verbal descriptors of tailored risks should be supported by numerical estimates of risks levels, to avoid overestimation of risks.
Similar content being viewed by others

Background
After a cancer diagnosis, most patients want to be fully informed about the possible treatment options and the associated risks of side effects to support a well-informed treatment decision-making process [1, 2]. For instance, colorectal cancer patients eligible for chemotherapy should be informed about the chances of experiencing adverse effects such as neuropathy or changes in smell and taste. Such risk statistics are typically communicated by the clinician during a consultation and/or incorporated into tools such as patient decision aids [3], and are therefore an essential part of shared decision-making [4]. However, patients often have difficulty understanding and interpreting risks [5], especially those patients with low numeracy of health literacy skills [6], which can further influence treatment decision-making [7, 8]. Due to advances in artificial intelligence and personalized medicine, there has been rapid growth in the development of tailored risk communication tools in cancer care [9,10,11,12], with the aim to provide patient’s risk information about treatment side effects based on their personal clinical and sociodemographic characteristics. Despite great promise of such individualized data-driven tools [13], it is unclear whether (1) tailored risks influence risk estimates and perceptions and lead to more or less accurate risk estimates compared to generic risks, and (2) which message format should be used to communicate such individualized statistics to patients.
Typically, risk information about possible treatment side effects is generic and mostly based on the “average patient”, such as information presented in randomized controlled trials or patient reported outcome reports [14]. Such average statistics make it hard to relate outcomes to individual patients [15], particularly because they often do not contain a clear description of to whom the risk estimates refer (i.e., the reference class) and may therefore be a factor in the misunderstanding of the risk information about treatment side effects [16]. Tailoring risk information of side effects adjusted to the clinical (e.g., tumor stage) and sociodemographic (e.g., age, gender) characteristics of an individual patient may increase the perceived personal relevance of risk information, thereby increasing the likelihood that patients will process the tailored information with more deliberation, consideration, and evaluation [17, 18]. In fact, several studies have shown that tailored risk estimates may improve the accuracy of patients’ estimations of probabilities and may increase their perceived likelihood of occurrence in both the general health context [19] as well as in the domain of cancer risk and screening [20, 21]. Therefore, tailoring side effect risks may be an effective communication strategy for enhancing the accuracy of patients’ risk estimates and for increasing risk perceptions.
An important consideration for clinicians, health educators and patient tool developers is through which message format they should communicate tailored risk statistics, using for instance verbal and/or numerical formats [15]. Verbal risks can be expressed via descriptions such as rare, likely, or very common. The European Commission provided guidelines on using particular verbal descriptors associated with corresponding numerical estimates (Table 1) [22]. The problem is that such phrases are often interpreted in different ways by different patients, typically causing overestimations of the actual occurrence of the side effect [23,24,25,26]. Another way of communicating risks is through combining verbal information with numerical estimates, such as percentages, probabilities, or natural frequencies [22, 26]. Although experimental studies have consistently shown that a combination of verbal and numerical formats of generic risks are estimated as lower and perceived as less likely to occur than verbal descriptions alone [23,24,25,26,27], it is not known to what extent such results apply to tailored risks. It is important to study this, as recent studies suggest that verbal risk labels without accompanying numerical information are still frequently used by oncologists [28] or incorporated in patient decision aids for communicating tailored risks of treatment side effects [29,30,31].
Present study and hypotheses
In the present study, we will examine the impact of tailoring (tailored vs. generic risks) and message format (verbal-only vs. verbal and numerical combined format) of risks of cancer treatment side effects on cancer patients’ risk interpretations. We will use estimation of probability, accuracy of estimation of probability, and perceived likelihood of occurrence as primary outcome variables. First, regarding the influence of tailoring, we expect that risks that are tailored will be perceived as more likely to occur than generic risks [20, 32].
H1:
Compared to generic risks of treatment side effects, tailored risks will be perceived as more likely to occur.
Second, given the growing importance of replication research in the empirical sciences for improving the reproducibility of earlier study’s results [33], we attempt to conceptually replicate previous findings on the effect of message format on peoples’ risk interpretations. Previous studies have consistently shown that people viewing generic risk information in a verbal-only format estimate the probability as higher and less accurate [23, 25], and perceive these risks as more likely to occur than people viewing risks in a verbal and numerical combined format [23,24,25,26]. We expect this impact of message format to persist for tailored risks as well.
H2:
Compared to risks of treatment side effects presented in a verbal and numerical combined format, risks presented in a verbal-only format will be estimated as (a) higher) and (b) less accurate, and (c) perceived as more likely to occur.
Third, regarding the combined effect of tailoring and message format, we assume that tailored risks expressed as words and numbers combined should improve peoples’ estimated risk accuracy even more compared to generic risk information [19,20,21]. This is because especially in this situation, people should have less reason to deviate from the actual tailored risk statistic being communicated.
H3:
Compared to generic risks of treatment side effects, tailored risks will be estimated as more accurate than generic risks, but only when the risks are presented in a verbal and numerical combined format.
Finally, we will assess perceived personal relevance and perceived uncertainty of the risk information as secondary outcome measures, for which we propose the following two hypotheses:
H4:
Tailored risks of treatment side effects will be perceived as more personally relevant than generic risks, regardless of the message format.
H5:
Tailored risks of treatment side effects will be perceived as less uncertain than generic risks, regardless of the message format.
Methods
Study design
We used a 2 (tailoring: tailored vs. generic) × 2 (message format: verbal-only vs. verbal and numerical combined) × 2 (probability rate: low vs. high) mixed design, with repeated measures on the first and third factor. Participants were randomly assigned to one of the two message format conditions. We included probability rate as a methodological variable to investigate whether the effects of tailoring and message format are similar for high and low probability rates 25. We used estimation of probability, accuracy of estimation of probability, and perceived likelihood of occurrence as primary outcome variables, and perceived personal relevance and perceived uncertainty as secondary outcome variables.
Participants
Native Dutch adults between the ages of 18 and 70 who had been diagnosed with cancer in the past were selected from the scientific panel of the online cancer community platform Kanker.nl to participate in our study. We selected people who had been in a similar health situation before, since they are better able to imagine the given scenarios (compared to, for instance, a student sample), thus enhancing the generalizability of our results [34]. Patients who were diagnosed with colorectal cancer in the past were excluded from participation due to prior personal experience. As part of the pre-registered analysis (https://osf.io/ygchx), power calculations were conducted prior to data collection to determine our sample size using the program G*Power 3.1 [35]. Previous meta-analyses have indicated small effect sizes for tailoring effects on perceived likelihood of occurrence [36], and medium effect sizes for message format effects on estimation of probability and perceived likelihood of occurrence [23]. To detect a small effect (effect size f = 0.10) with a 2 × 2 × 2 mixed design, a sample of 136 participants was needed (power = 0.8, alpha = 0.05). We therefore aimed for a minimum of 136 participants.
Stimulus materials
All participants received two tailored and two generic risk statistics for the occurrence of four possible side effects after adjuvant chemotherapy including fatigue, neuropathy, taste and smell changes, and diarrhea, respectively. Tailoring was established by manipulating the reference class (i.e., denominator) to which the risk statistic applies. More specifically, tailored risks contained a reference class based on participants’ reported gender (male or female), age group (in 5-year bins between 15 and 69 years), and tumor stage (advanced colon cancer as stated in the scenario). For example: ‘This side effect is common (occurs in 10 out 100 men like you, aged between 65 and 69 years with advanced colon cancer)” (Table 2). Generic risks descriptions were fixed and included a reference class that was not tailored toward patient and tumor characteristics. For example: “This side effect is common (occurs in 10 out of 100 people)” (Table 2).
Half of the participants received the risk only in words (verbal-only condition), and the other half in a combination of words and numbers (verbal and numerical combined condition). Within the verbal-only condition, we selected the verbal descriptors ‘common’ (vaak in Dutch) for representing a low probability rate and ‘very common’ (zeer vaak in Dutch) for representing a high probability rate. Following the recommendations proposed by the European Commission, we used the corresponding natural frequency estimates ‘10 out of 100’ for representing a low probability rate and ‘40 out of 100’ for representing a high probability rate [3, 5, 15, 22]. To exclude the possible effect that a specific side effect could influence higher risk estimates, the combination of tailoring, probability rate and type of side effect was randomized, as well as the order of tailored and generic risks in combination with the probability rate.
Procedure
Data collection took place in May 2019. A representative of Kanker.nl sent a link of our web-based experiment to participants of the cancer patient panel. When entering the online experiment, an introductory text was shown, followed by questions on background and medical characteristics. The reported gender and age group were subsequently used for tailoring the reference class of the tailored risk information. Participants then read a short scenario in which they imagined being diagnosed with advanced colon cancer and discussing adjuvant chemotherapy as a treatment option with their doctor. We chose colon cancer as the disease context because both men and women can be diagnosed with this form of cancer (versus, for example, prostate cancer). This allowed us to include gender as a tailoring factor of the risk information. Participants were told that they were receiving a decision aid from their doctor including information about four possible side effects after adjuvant chemotherapy. Each description consisted of three elements: the name of the side effect, a short description of the side effect, and risk information about the likelihood of experiencing the side effect. This was followed by the assessment of the primary and secondary outcome measures. In the final part of the experiment, we measured participants’ subjective numeracy skills and prior history with chemotherapy and/or one of four mentioned the side effects. Participants were then debriefed about the main purpose of the experiment and thanked for their participation.
Measures
Primary outcome measures
We had three primary outcome measures for measuring risk interpretations, based on the meta-analysis by Büchter and colleagues [23] and the studies by Knapp and colleagues that we attempted to replicate [24, 25]. First, estimation of probability was assessed using the question “What do you think is the probability you will experience this side effect”, measured as a percentage between 0 and 100 [24]. Second, the accuracy of the estimation of probability was determined by computing the absolute difference between the actual risk of each side effect occurring and each participant’s estimated risk of that side effect occurring. Scores closer to zero were therefore more accurate (for similar reasoning, see [21, 25]). Third, perceived likelihood of occurrence was assessed using the question “How likely is it that you will experience this side effect?”, measured on a 6-point scale, with 1 as ‘not likely at all’ and 6 as ‘very likely’ [23, 24].
Secondary outcome measures
We also included two secondary outcome variables. First, perceived personal relevance was assessed using the items “The risk information about the side effect was made personally for me” and “The way how the risk information was being presented was relevant to me” (measured on a 5-point scale, with 1 as ‘strongly disagree’ and 5 as ‘strongly agree’) [32]. Second, perceived uncertainty was assessed by asking the question “How uncertain do you think is this likelihood of experiencing this side effect after chemotherapy?”, measured on a 6-point scale, with 1 as ‘not at all’ and 6 as ‘extremely’ [37].
Individual difference measures
Individual differences in subjective numeracy were assessed by the Subjective Numeracy Scale (SNS [38]), which is an 8-item self-assessment for determining participants’ quantitative ability and preferences for receiving numerical information (measured on a 6-point scale, with 1 as ‘least numerate’ and 6 as ‘most numerate’). The SNS has proven to be a valid and reliable measure, and correlates strongly with objective numeracy measures [39]. For the current study, we used the Dutch version of the SNS [40]. The mean subjective numeracy score was determined by computing the average score of the eight items.
Statistical analyses
We conducted a 2 (within-subjects: tailoring) × 2 (between-subjects: message format) × 2 (within-subjects: probability rate) mixed-model multivariate analysis of variance (MANOVA).Footnote 1 The dependent variables were our three primary outcome measures; estimation of probability, accuracy of estimation of probability, and perceived likelihood of occurrence (see Additional file 1 for full results). If applicable, significant interaction effects were further analyzed by means of simple effect analyses. As an additional exploratory analysis, we controlled for individual differences by conducting a separate mixed-model multivariate analysis of covariance (MANCOVA) with subjective numeracy skills and prior history with chemotherapy and/or one of the side effects as covariates. For this exploratory analysis, only results that deviate from the pre-registered MANOVA analysis were reported (Additional file 1). For our two secondary outcome measures, we conducted two separate mixed-model ANOVAs, with repeated measures on the first and third factor. The dependent variables were perceived personal relevance and perceived uncertainty. Data on patient and tumor characteristics for the two message format conditions were compared using chi-square tests for categorical variables and t-tests for continuous variables. All statistical analyses were performed using SPSS version 24.0 (IBM Corporation, Somers, NY, USA). Tests were two-sided and considered statistically significant at p < .05. The study design, hypotheses, and analysis plan were pre-registered prior to data collection and analysis within the Open Science Framework (https://osf.io/j74dt/). Ethical approval was granted by the Research Ethics and Data Management Committee of the Tilburg School of Humanities and Digital Sciences of Tilburg University (ID REDC.2019.26).
Results
Participants
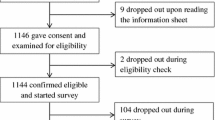
Out of 825 people who were invited to participate, 188 (23%) clicked the link to launch the survey. Of those, 171 (91%) continued beyond the informed consent page, and 141 (75%) fully completed the survey (Fig. 1). All completed cases were analyzed. Completion rates were consistent across experimental conditions (73% in the verbal-only condition, 77% in the verbal and numerical combined condition). The mean age of participants was 57.3 years (SD = 7.4), and the participants in both message format conditions were comparable in terms of sociodemographic and disease-related characteristics (all p values > .10, Table 3).

Flowchart of the data collection process
Effects on primary outcome measures
In both message format conditions, participants’ estimated probabilities strongly correlated with the accuracy of their estimated probabilities (rverbal-only = − .984, p < .001, rverbal+numerical = − .943, p < .001) and perceived likelihood of occurrence (rverbal-only = .820, p < .001, rverbal+numerical = .738, p < .001), which, in turn, strongly correlated with participants’ accuracy of estimated probabilities (rverbal-only = -.813, p < .001, rverbal+numerical = .728, p < .001).
Effects of tailoring
There was a significant main effect of tailoring on the estimation of probabilities and accuracy of estimation of probabilities. Tailored risks were estimated as higher, F(1, 125) = 6.25, p = .023, ηp2 = .04, and less accurate, F(1, 125) = 6.25, p = .014, ηp2 = .05, than generic risks (Tables 4, 5). However, in contrast to our hypothesis (H1), there was no significant main effect of tailoring on the perceived likelihood of occurrence, indicating that tailored risks were not perceived as more likely to occur than generic risks, F(1, 125) = 1.79, p = .183, ηp2 = .01. It should be noted that these tailoring effects were not found when controlling for individual differences in numeracy and prior history with the side effects (Additional file 1). Overall, the effects of tailoring did not depend on the probability rate (all Fs < 1).
Effects of message format
As hypothesized, there was a significant main effect of message format on the estimation of probabilities, F(1, 125) = 69.82, p < .001, ηp2 = .36, accuracy of estimation of probabilities, F(1, 125) = 64.26, p < .001, ηp2 = .34, and perceived likelihood of occurrence, F(1, 125) = 30.27, p < .001, ηp2 = .20. The results therefore suggest that risks presented in a verbal-only format were estimated as higher (H2a), less accurate (H2b), and perceived as more likely to occur (H2c) than risks presented in a verbal and numerical combined format. These message format effects were also found when controlling for individual differences (all ps < .001; Additional file 1), and were more pronounced for low probability rates (all ps < .001).
Interaction effects between tailoring and message format
There was a significant interaction effect between tailoring and message format on the accuracy of estimation of probabilities, F(1, 125) = 7.82, p = .006, ηp2 = .06. Simple effect analysis showed that tailored risks were estimated as less accurate than generic risks in the verbal-only condition, (p < .001), but not in the combined condition (p = .833). This is in contrast to our hypothesis (H3), for which we expected tailored risks to be estimated as more accurate compared to generic risks, but only when expressed as words and numbers combined. There was also a significant interaction effect on the estimation of probabilities, F(1, 125) = 7.21, p = .008, ηp2 = .06. Simple effect analysis revealed that tailored risks were estimated as higher than generic risks in the verbal-only condition (p = .001), but not in the combined condition (p = .789). Overall, these significant interaction effects were found for both probability rates, and when controlling for individual differences (Additional file 1). Finally, there was no significant interaction effect between tailoring and message format on perceived likelihood of occurrence, F(1, 125) = 1.79, p = .183, ηp2 = .01. Figure 2 displays the distribution of estimations of probabilities (and the mean estimates) given by participants for each experimental condition.

Comparisons of distribution of estimations of probabilities between verbal-only (red) and verbal and numerical combined (blue) message formats for a low probability tailored risks and b low probability generic risks, and for c high probability tailored risks and d high probability generic risks. The dotted lines represent the average estimated risks
Effects on secondary outcome measures
As hypothesized (H4), participants perceived tailored risks as more personally relevant than generic risk information about side effects, F(1, 123) = 19.11, p < .001, ηp2 = .13 (Tables 4, 5). This effect of tailoring occurred regardless of message format conditions, F(1, 123) = 2.36, p = .127, ηp2 = .02, and probability rate, F < 1. Regarding perceived uncertainty, there was a significant interaction effect between tailoring and message format, F(1, 113) = 6.23, p = .014, ηp2 = .05. Simple effects analysis showed that tailored risks in the verbal-only condition were perceived as less uncertain than generic risks (p = .007), but not in the verbal and numerical combined condition (p = .436), which partly confirms H5. Finally, risks with low probability rates were perceived as more uncertain than risks with high probability rates, F(1, 113) = 11.01, p < .001, ηp2 = .09.
Discussion
Main findings
The current study demonstrates that message format matters when communicating tailored risk information of treatment side effects. We found that communicating tailored side effect risks leads to higher and less accurate risk estimates compared to generic risks, but only when the risks were communicated using words-only. Such differences were not found in the combined verbal and numerical condition. This suggests that communicating about side effect risks in words-only allows patients to overestimate and even inaccurately estimate their tailored risks [15, 41, 42]. Moreover, patients may take these individualized verbal risk labels as too personal, which in turn may lead to overestimations of the risks. However, these tailoring effects could not be found for perceived likelihood of occurrence, which may underscore that increases in risk estimations do not necessarily translate into increases in perceived likelihood of occurrence. Furthermore, we replicated the message format effect for Dutch verbal risk labels. More specifically, we showed that risks presented in a verbal-only format are estimated as higher and less accurate, and perceived as more likely to occur than risks presented in a combined verbal and numerical format [23, 25, 26].
However, tailored risks in a verbal and numerical combined format did not lead to more accurate risk estimates compared generic numerical risk information [19,20,21]. A possible explanation for this might be that the tailored and generic risks were shown separately and did not contain any comparative risk information. As a result, patients could not see their own risk score for a particular side effect in comparison with scores of other patients, especially for determining whether they were above or below average [43, 44]. Although there is currently a debate about whether comparative risk information should be provided to patients [45, 46], such communication strategy could improve people’s estimations of probabilities and perceived likelihood of occurrence in the context of tailored versus generic risks of side effects [19].
Finally, in both message formats, tailored risks are perceived as more personally relevant than generic risks, which is in line with past studies on tailoring effects in health communication [32]. In addition, this shows that by manipulating the reference class of probability outcomes our manipulation of tailoring was successful. We further found that when risks were presented only by means of verbal descriptors, tailored risks were perceived as less uncertain than generic risks. This suggests that tailored risks in the verbal-only condition were estimated as higher, and therefore perceived as more certain to occur.
Limitations and suggestions for future research
A first limitation is that the research design uses a hypothetical decision-making scenario instead of a real decision-making scenario. To partially compensate for this, our sample consisted of cancer patients and survivors who were recruited from a Dutch cancer patient panel. Often, scenario-based experimental studies on effective risk communication strategies are conducted in student samples (for an overview, see [18]), who may not be familiar with a medical decision-making situation and may have different perceptions of risks and probability information about cancer [23, 47]. Although the use of cancer patients in our experiment contributed to the ecological validity of the results, future research to confirm our findings in a real-world treatment decision-making situation would be advisable.
Another limitation is that we tailored the risks based on a limited number of patient characteristics in a non-interactive way, to keep the experiment manageable and the results generalizable. Clinical prediction models in oncology settings typically utilize a larger variety of patient and tumor characteristics in decision-making (e.g., TNM-stage, the specific use of chemotherapy, or comorbidities) that is more extensive than we have dealt with in our study. Using such an interactive prediction modelling tool in which participants can enter their own personal and disease-related characteristics and see the impact of each characteristic on their personal risk could influence patients’ risk perception [48]. Despite this limitation, the tailored risks in our study were perceived as more personally relevant compared to the generic, population-based risks.
Finally, we only compared risks communicated through words or a combination of words and numbers, and did not consider the potential added value of visual aids as another message format. A plethora of research suggests that visual aids may increase understanding and perception of risk information [3, 15, 42, 49, 50]. For instance, bar charts may help to display the distinction between tailored and generic risks, and pictographs may communicate the number of people with similar characteristics that may experience the side effect compared to the number of people from the general population [15]. Therefore, it is suggested to investigate the impact of tailored risks through visually presented information compared to, for instance, numerical descriptions of risks.
Implications
Despite these limitations, our findings have implications for research and practice. First, in line with guidelines and best practices for communicating complex medical data and risks in daily clinical practice and patient decision aids [3, 15, 42, 51], our results offer support for the recommendation to avoid verbal descriptions without numbers since they may lead to inaccurate risk estimates. Our findings suggest that this recommendation may become even more relevant when the risks are tailored and adjusted to sociodemographic and clinical characteristics of patients. This finding is useful for clinicians who discuss risks, health data, and other probability information during consultations in general with their patients and relatives, and especially for clinicians who are using modern decision-support systems (e.g., clinical prediction models) for estimating and communicating individualized treatment outcomes to patients. In addition, in light of the growing emphasis of personalized medicine [52], shared decision-making [4, 53], and the promising approaches of the delivery of tailored risk information through patient-centered decision aids [9,10,11,12], our results contribute to the empirical evidence on how best to communicate tailored risks to individual patients [54, 55].
Conclusion
When communicating tailored risk information of treatment side effect to patients, using a combination of words and numbers will lead to more accurate risk estimates than when using words only. Although we found no evidence that tailoring of numerical risks leads to even more accurate risk estimates, doing so with verbal labels alone may have a negative impact on patients’ (accuracy) of estimation of risks. Given the strong movements toward personalized medicine and patient-centered healthcare, future research will have to determine whether other ways of presenting tailored risk information, such as comparative risk information or visual aids promote effective communication of tailored risks during cancer treatment decision-making.
Availability of data and materials
The data that support the findings of this study can be accessed via https://osf.io/j74dt/.
Notes
According to our pre-registration (https://osf.io/j74dt/), our main analysis consisted of a 2 (tailoring: tailored, generic) × 2 (message format: verbal-only, verbal and numerical combined) mixed-model multivariate analysis of variance (MANOVA) with repeated measures on the first factor. However, we decided to include probability rate as a methodological variable in our study design, which resulted in a 2 × 2 × 2 mixed-model MANOVA. This MANOVA was initially stated as an exploratory analysis in our pre-registration, but has now become the main analysis in this study.
References
Fletcher C, Flight I, Chapman J, Fennell K, Wilson C. The information needs of adult cancer survivors across the cancer continuum: a scoping review. Patient Educ Couns. 2017;100:383–410.
van Eenbergen MCHJ, Vromans RD, Boll D, Kill PJM, Vos MC, Krahmer EJ, Mols F, van de Poll-Franse LV. Changes in internet use and wishes of cancer survivors: a comparison between 2005 and 2017. Cancer. 2020;126:408–15.
Trevena LJ, Zikmund-Fisher BJ, Edwards A, et al. Presenting quantitative information about decision outcomes: A risk communication primer for patient decision aid developers. BMC Med Inform Decis Mak. 2013;13:S7.
Elwyn G, Durand MA, Song J, et al. A three-talk model for shared decision making: multistage consultation process. BMJ. 2017;359:j4891.
Gigerenzer G, Gaissmaier W, Kurz-Milcke E, Schwartz LM, Woloshin S. Helping doctors and patients make sense of health statistics. Psychol Sci Public Interes. 2008;8:53–96.
Garcia-Retamero R, Galesic M. Who proficts from visual aids: Overcoming challenges in people’s understanding of risks. Soc Sci Med. 2010;70:1019–25.
Amsterlaw J, Zikmund-fisher BJ, Fagerlin A, Ubel PA, Arbor A. Can avoidance of complications lead to biased healthcare decisions ? Judgm Decis Mak. 2006;1:64–75.
Fagerlin A, Zikmund-Fisher BJ, Ubel PA. “If I’m better than average, then I’m ok?”: Comparative information influences beliefs about risk and benefits. Patient Educ Couns. 2007;69:140–4.
Henton M, Gaglio B, Cynkin L, Feuer EJ, Rabin BA. Development, feasibility, and small-scale implementation of a web-based prognostic tool—surveillance, epidemiology, and end results cancer survival calculator. JMIR Cancer. 2017;3:e9.
Hommes S, van der Lee C, Clouth FJ, Verbeek X, Krahmer EJ (2019) A personalized data-to-text support tool for cancer patients. In: International conference natural language generation Tokio, pp 1–6
Lau YK, Caverly TJ, Cao P, Cherng ST, West M, Gaber C, Arenberg D, Meza R. Evaluation of a personalized, web-based decision aid for lung cancer screening. Am J Prev Med. 2015;49:e125–9.
Hakone A, Harrison L, Ottley A, Winters N, Gutheil C, Han PKJ, Chang R. PROACT: iterative design of a patient-centered visualization for effective prostate cancer health risk communication. IEEE Trans Vis Comput Graph. 2017;23:601–10.
Gorini A, Masiero M, Pravettoni G. Patient decision aids for prevention and treatment of cancer diseases: are they really personalised tools? Eur J Cancer Care (Engl). 2016;25:936–60.
Fraenkel L, Fried RF. Individualized medical decision making. Arch Intern Med. 2010;170:566–9.
Lipkus IM. Numeric, verbal, and visual formats of conveying health risks: suggested best practices and future recommendations. Med Decis Mak. 2007;27:696–713.
van Stam M-A, van der Poel HG, van der Voort van Zyp JRN, Tillier CN, Horenblas S, Aaronson NK, Ruud Bosch JLH. The accuracy of patients’ perceptions of the risks associated with localised prostate cancer treatments. BJU Int. 2018;121:405–14.
Petty RE, Cacioppo JT. The elaboration likelihood model of persuasion. Adv Exp Soc Psychol. 1986;19:123–205.
Visschers VHM, Meertens RM, Passchier WWF, De VNNK. Probability information in risk communication: a review of the research literature. Risk Anal. 2009;29:267–87.
Greening L, Chandler CC, Stoppelbein L, Robison LJ. Risk perception: using conditional versus general base rates for risk communication. J Appl Soc Psychol. 2005;35:2094–122.
Albada A, Ausems MGEM, Bensing JM, van Dulmen S. Tailored information about cancer risk and screening: a systematic review. Patient Educ Couns. 2009;77:155–71.
Emmons KM, Wong M, Puleo E, Weinstein N, Fletcher R, Colditz G. Tailored computer-based cancer risk communication: correcting colorectal cancer risk perception. J Health Commun. 2004;9:127–41.
European Commission (2009) Guideline on the readability of the label and package leaflet of medicinal products for human use. 1–27
Büchter RB, Fechtelpeter D, Knelangen M, Ehrlich M, Waltering A. Words or numbers? Communicating risk of adverse effects in written consumer health information: a systematic review and meta-analysis. BMC Med Inform Decis Mak. 2014;14:76.
Knapp P, Raynor DK, Berry DC. Comparison of two methods of presenting risk information to patients about the side effects of medicines. Qual Saf Heal Care. 2004;13:176–80.
Knapp P, Gardner PH, Raynor DK, Woolf E, McMillan B. Perceived risk of tamoxifen side effects: a study of the use of absolute frequencies or frequency bands, with or without verbal descriptors. Patient Educ Couns. 2010;79:267–71.
Knapp P, Gardner PH, Woolf E. Combined verbal and numerical expressions increase perceived risk of medicine side-effects: a randomized controlled trial of EMA recommendations. Heal Expect. 2016;19:264–74.
Sawant R, Sansgiry S. Communicating risk of medication side-effects: role of communication format on risk perception. Pharm Pract (Granada). 2018;16:1174.
Kunneman M, Stiggelbout AM, Marijnen CAM, Pieterse AH. Probabilities of benefit and harms of preoperative radiotherapy for rectal cancer: what do radiation oncologists tell and what do patients understand? Patient Educ Couns. 2015;98:1092–8.
Vromans RD, van Eenbergen MC, Pauws SC, Geleijnse G, van der Poel HG, van de Poll-Franse LV, Krahmer EJ. Communicative aspects of decision aids for localized prostate cancer treatment—a systematic review. Urol Oncol Semin Orig Investig. 2019;37:409–29.
Vromans R, Tenfelde K, Pauws S, Van EM, Mares I, Velikova G, Van de Poll-Franse LV, Krahmer EJ. Assessing the quality and communicative aspects of patient decision aids for early-stage breast cancer treatment: a systematic review. Breast Cancer Res Treat. 2019;178:1–15.
Hommes S, Vromans RD, Clouth FJ, Verbeek X, de Hingh I, Krahmer EJ. Communication in decision aids for stage I-III colorectal cancer patients: a systematic review (submitted). Manuscript
Lustria MLA, Cortese J, Gerend MA, Schmitt K, Kung YM, Mclaughlin C. A model of tailoring effects: a randomized controlled trial examining the meachanisms of tailoring in a web-based STD screening intervention. Heal Psychol. 2016;35:1214–24.
Zwaan RA, Etz A, Lucas RE. Making replication mainstream. Behav Brain Sci. 2018;41:1–61.
Schmiege S, Klein W, Bryan A. The effect of peer comparison information in the context of expert recommendations on risk perceptions and subsequent behavior. Eur J Soc Psychol. 2010;40:747–59.
Faul F, Erdfelder E, Lang A-G, Buchner A. G * Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav Res Methods. 2007;39:175–91.
Lustria MLA, Noar SM, Cortese J, Van Stee SK, Glueckauf RL, Lee J. A meta-analysis of web-delivered tailored health behavior change interventions. J Health Commun. 2013;18:1039–69.
Witteman HO, Zikmund-Fisher BJ, Waters EA, Gavaruzzi T, Fagerlin A. Risk estimates from an online risk calculator are more believable and recalled better when expressed as integers. J Med Internet Res. 2011;13:e54.
Fagerlin A, Zikmund-Fisher BJ, Ubel PA, Jankovic A, Derry HA, Smith DM. Measuring numeracy without a math test: development of the subjective numeracy scale. Med Decis Mak. 2007;27:672–80.
Zikmund-Fisher BJ, Smith DM, Ubel PA, Fagerlin A. Validation of the subjective numeracy scale: effects of low numeracy on comprehension of risk communications and utility elicitations. Med Decis Mak. 2007;27:663–71.
Heringa M, Floor-Schreudering A, Wouters H, De Smet PAGM, Bouvy ML. Preferences of patients and pharmacists with regard to the management of drug–drug interactions: a choice-based conjoint analysis. Drug Saf. 2018;41:179–89.
Kunneman M, Stiggelbout AM, Pieterse AH. Do clinicians convey what they intend? Lay interpretation of verbal risk labels used in decision encounters. Patient Educ Couns. 2020;103:418–22.
Spiegelhalter D. Risk and uncertainty communication. Annu Rev Stat Appl. 2017;4:31–60.
Oerlemans S, Arts LP, Horevoorts NJ, Van De Poll-Franse LV. “Am I normal?” The wishes of patients with lymphoma to compare their patient-reported outcomes with those of their peers. J Med Internet Res. 2017;19:e288.
Jensen RE, Bjorner JB. Applying PRO reference values to communicate clinically relevant information at the point-of-care. Med Care. 2019;57:S24–30.
Fagerlin A, Zikmund-Fisher BJ, Smith DM, et al. Women’s decisions regarding tamoxifen for breast cancer prevention: responses to a tailored decision aid. Breast Cancer Res Treat. 2010;119:613–20.
Schwartz PH. Disclosure and rationality: Comparative risk information and decision-making about prevention. Theor Med Bioeth. 2009;30:199–213.
Timmermans DRM, Ockhuysen-Vermey CF, Henneman L. Presenting health risk information in different formats: the effect on participants’ cognitive and emotional evaluation and decisions. Patient Educ Couns. 2008;73:443–7.
Harle CA, Downs JS, Padman R. Effectiveness of personalized and interactive health risk calculators: a randomized trial. Med Decis Mak. 2012;32:594–605.
Garcia-Retamero R, Cokely ET. Desiging visual aids that promote risk literacy: a systematic review of health research and evidence-based design heuristics. Hum Factors J Hum Factors Ergon Soc. 2017;59:582–627.
Fagerlin A, Zikmund-Fisher BJ, Ubel PA. Helping patients decide: ten steps to better risk communication. J Natl Cancer Inst. 2011;103:1436–43.
Freeman ALJ. How to communicate evidence to patients. Drug Ther Bull. 2019;57:119–24.
Schilsky RL. Personalized medicine in oncology: the future is now. Nat Rev Drug Discov. 2010;9:363–6.
Elwyn G, Frosch D, Thomson R, et al. Shared decision making: a model for clinical practice. J Gen Intern Med. 2012;27:1361–7.
Han PKJ, Klein WMP, Lehman T, Killam B, Massett H, Freedman AN. Communication of uncertainty regarding individualized cancer risk estimates: effects and influential factors. Med Decis Mak. 2011;31:354–66.
Han PKJ, Hootsmans N, Neilson M, Roy B, Kungel T, Gutheil C, Diefenbach M, Hansen M. The value of personalised risk information: a qualitative study of the perceptions of patients with prostate cancer. BMJ Open. 2013;3:e003226.
Acknowledgements
We would like to thank Lonneke Scheper for her help with designing the experiment, Kanker.nl for distributing our experimental survey to members of their scientific panel, and all cancer patients and survivors for their participation in our experiment.
Funding
Financial support was provided in part provided by the Data Science Center Tilburg (DSC/t) and by a grant from the Netherlands Organisation for Scientific Research (NWO) (Grant No. 628.001.030). Both DSC/t and NWO had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
RV, SP, NB, LvdP and EK participated in the design of the study and contributed to the interpretation of the findings. RV developed the web-based experiment and enabled contact to study participants. RV analyzed the data. RV wrote the manuscript and SP, NB, LvdP and EK made major contributions in writing of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Ethical approval was granted by the Research Ethics and Data Management Committee of the Tilburg School of Humanities and Digital Sciences of Tilburg University (ID REDC.2019.26). All participants gave their digital consent to participate, and the ethics board approved the use of digital signatures.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1:
MANOVA and MANCOVA outcomes.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Vromans, R.D., Pauws, S.C., Bol, N. et al. Communicating tailored risk information of cancer treatment side effects: Only words or also numbers?. BMC Med Inform Decis Mak 20, 277 (2020). https://doi.org/10.1186/s12911-020-01296-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-020-01296-7