
Abstract
Background
Handwriting represents one of the major symptom in Parkinson’s Disease (PD) patients. The computer-aided analysis of the handwriting allows for the identification of promising patterns that might be useful in PD detection and rating. In this study, we propose an innovative set of features extracted by geometrical, dynamical and muscle activation signals acquired during handwriting tasks, and evaluate the contribution of such features in detecting and rating PD by means of artificial neural networks.
Methods
Eleven healthy subjects and twenty-one PD patients were enrolled in this study. Each involved subject was asked to write three different patterns on a graphic tablet while wearing the Myo Armband used to collect the muscle activation signals of the main forearm muscles. We have then extracted several features related to the written pattern, the movement of the pen and the pressure exerted with the pen and the muscle activations. The computed features have been used to classify healthy subjects versus PD patients and to discriminate mild PD patients from moderate PD patients by using an artificial neural network (ANN).
Results
After the training and evaluation of different ANN topologies, the obtained results showed that the proposed features have high relevance in PD detection and rating. In particular, we found that our approach both detect and rate (mild and moderate PD) with a classification accuracy higher than 90%.
Conclusions
In this paper we have investigated the representativeness of a set of proposed features related to handwriting tasks in PD detection and rating. In particular, we used an ANN to classify healthy subjects and PD patients (PD detection), and to classify mild and moderate PD patients (PD rating). The implemented and tested methods showed promising results proven by the high level of accuracy, sensitivity and specificity. Such results suggest the usability of the proposed setup in clinical settings to support the medical decision about Parkinson’s Disease.
Similar content being viewed by others


Background
Parkinson’s Disease (PD) is the second most common neurodegenerative disorder after Alzheimer’s disease that leads to several neuro-motor deficits. It is well known that PD patients exhibit problems when the perform movements that are executed sequentially due to the loss of coordination among the motor sequence components [1–5]. As a result, sequential movements are more segmented and characterized by pauses between sub-movements [6].
The handwriting is a task composed of sequential movements that involves fine and complex manual skills relying on a sophisticated mix of cognitive, sensory and motor components [7]. This explains the manifestation of abnormal features in the handwriting of PD patients. The difficulties in the handwriting process affecting PD patients are mainly two:
difficulties related to the control of the movement amplitude, e.g. decreasing the size of the characters (micrographia) and failing in keeping the stroke width of the characters constant as the writing progresses [8–15];
not regular and bradykinetic movements that lead to an increased movement duration, decreased speed and accelerations, and unstable velocity and acceleration [16–21].
Several research groups have investigated the use of handwriting’s features to classify PD patients and healthy subjects.
Helsper et al. published a study that investigated the handwriting differences between preclinical PD patients and healthy controls [22]. The authors analysed two lines of the handwritten text (sampled from a longer written text) and proposed an approach that considers (1) the extraction of 10 features from text segments written by test subjects as a first step, and then (2) the computation of a single resulting feature set based on the mean, the standard deviation and the frequency of the occurrences. The authors statistically proved the existence of features characterizing many years before the diagnosis.
Longstaff and collegues studied the relation between the inclination of PD patients to scale the character size and reduce the speed of drawing movements and the movement variability [23]. The experiment is based on the analysis of several geometrical writing patterns with different shape and size drawn with a pen on a graphics tablet. By analysing the extracted features the authors stated that there is a substantial divergence in the quality of movements between PD patients and healthy people
A different recording set-up has been used by Ünlü et al. [24] that recorded the pressure and the inclination of an electronic pen during writing tasks. Their proposed approach considered the extraction of 8 different features and the use the Receiver Operating Characteristic (ROC) to analyse the diagnostic possibilities both in term of sensitivity and specificity. Their results showed that the most representative feature is based on the difference between the writing pressure and the tremor of the pen tilt angle.
Electronic pen and tablet have been also used by Rosenblum et al. to collect the position, the pressure and the angle of the pen tip during the writing of two main patterns (i.e. the name and fixed address) [25]. The average values of the pressure and velocity acquired during the entire task and other spatial and temporal characteristics of each stroke allowed them to differentiate PD patients from control subjects with a sensitivity of 95.0%.
In our preliminary previous works [26, 27], we proposed a promising method to classify PD patients from healthy subjects by using only 4 features extracted by scanned text (through image processing techniques) and surface ElectroMyoGraphy (sEMG) signals. Recently, we used a graphic tablet and the Myo armband to extract biometric signals related to pen movements (pen tip position, inclination and pressure) and muscle activation [28, 29]. These signals were processed to extract a number of features used as input to two different classifiers.
In this work, we improve our recent studies by proposing a larger feature set and testing our classifiers on bigger cohort of subjects. Furthermore, we focused on the selection of the most representative features that better highlight the handwriting differences between (1) mild and moderate PD patients, and (2) PD patients and healthy subjects.
Methods
The proposed model-free technique for the analysis of handwriting is computer-assisted and based on the extraction of features from biometrical signals [30] (i.e., sEMG signals, pen tilt, etc.) related to hand movements during handwriting tasks.
In the following sections, the features selected and used in our technique and the algorithms used for feature selection and classification are presented and described.
Handwriting feature extraction
Handwriting features have been derived from biometric signals obtained during handwriting tasks. In general, the proposed features can be grouped into two groups based on sEMG and pen tip signals:
Features derived from sEMG signals – these features are related to the subject’s muscle activity and are derived from the sEMG signals obtained from the forearm of the subject:
RMS features: for every sEMG channel, Root Mean Square (RMS) is computed. It is determined by Eq. (1), where xi is the sample value at the discrete-time i, and n is the total number of samples acquired.
$$ RMS=\sqrt{\frac{1}{n}\sum^{n}_{i=1}x^{2}_{i}} $$(1)ZC features: Zero Crossing (ZC) is a variance-related index. In detail, it is the number of sign variations between two consecutive samples, and it is only increased if the difference exceeds a predefined tolerance value. Considering two consecutive samples xk and xk+1, the ZC value is increased if and only if the following condition is satisfied: xk>0 and xk+1<0, or xk<0 and xk+1>0 and |xk−xk+1|≥tol. Due to the presence of noisy signals, the tolerance value (tol) is used to prevent ZC increment; it is measured as the average of the standard deviations of all the sEMG channels considered. In addition, its value is divided by the length of the signal to normalize the features among the subjects.
Pen tip related features - these features are extracted during the handwriting task from the signals produced by a graphic tablet:
Cartesian and XY features: these features refer to the pen tip writing kinematics on the graphic tablet and are derived from the orientation of the XY axes. This group of features includes the features extracted from the following signals: Cartesian and XY-velocity, Cartesian and XY-acceleration, Cartesian and XY-jerk. The features are determined as first, second and third derivatives, respectively, starting from the X-Y position. It leads to nine output signals.
Pen tip pressure feature: this is a scalar feature which refers to the pressure applied to the tablet surface by the pen tip.
Azimuth and altitude feature: the azimuth feature is the angle value between a reference direction (e.g., the Y axes of the tablet) and the pen direction projected on the horizontal plane. The altitude feature is the angle value between the pen direction and the horizontal plane.
Pattern specific features: these features are related to the writing size of letter-based patterns and the writing precision of spiral writing ones. In detail, for the letter-based patterns, the pen tip Y coordinate has been processed, and the upper and lower peaks are then determined. The two groups of peak points are then independently used to determine the upper regression line Rup and the lower regression line Rlow using linear regression. Finally, the α angle between the regression lines is computed. The graphical representation of the procedure is shown in Fig. 1. A further feature taken into account is the coefficient of determination (R2) computed according to Eqs. (2).
Fig. 1 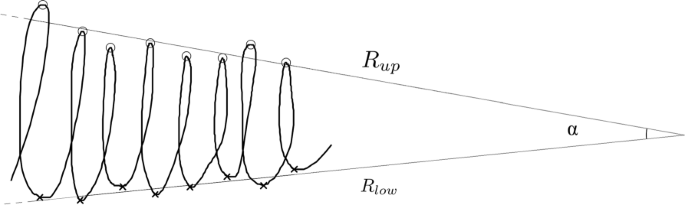
Representation of the regression lines Rup and Rlow and the angle α. Circle and cross marks identifies respectively upper and lower peaks of the Y-coordinate of the pen tip position
$$\begin{array}{@{}rcl@{}} \overline{y}&=&\frac{1}{n}\sum^{n}_{i}y_{i}, \\ SST&=&\sum_{i}(y_{i}-\overline{y})^{2}, \\ SSE&=&\sum_{i}(y_{i}-\widehat{y_{l}})^{2}, \\ R^{2}&=&1-\frac{SSE}{SST}. \end{array} $$(2)The three resulting patterns chosen as descriptors of the variability of the writing size are the α angle between the regression lines and the two coefficients of determination (R2).
For the spiral patterns, instead, the feature is based on the variability of the strokes. We computed the vector \(\overrightarrow {r}\) originating in P with respect to the spiral centroid point C for each point P of the X-Y pen tip position. Then, we calculated the angle β between \(\overrightarrow {r}\) and the direction vector \(\overrightarrow {d}\) tangent to the spiral in P. The visual explanation of the process is depicted in Fig. 2. Lastly, we calculated the standard deviation of the β angles computed for each point P. The standard deviation value is the feature chosen to describe the precision of the spiral.
Fig. 2 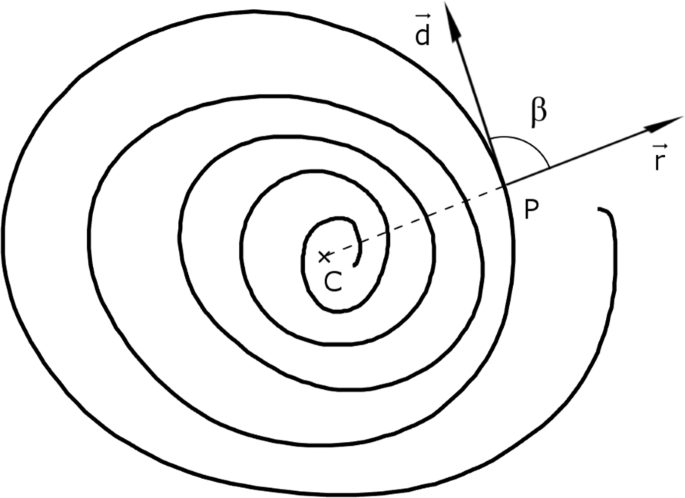
Example of computation of the spiral precision index β


Feature selection and classification
A feature selection procedure has been used to understand the main representative for the subject’s status [31]; we used an approach similar to the entropy criterion (i.e., information gain) and based on a classification decision tree technique with Gini’s diversity index [32].
The classification procedure is based on Artificial Neural Network (ANN) classifier [33–35]. Since designing the topology of neural classifiers is challenging, several works have been proposed dealing with this task [36–38]. In this work, the topology of the classifier was optimised by the evolutionary approach proposed in [39].
We used a Multi-Objective Genetic Algorithm (MOGA) to find the optimal network topology. A genetic algorithm is a powerful optimization technique that reflects the process of natural selection where the fittest individuals are selected for reproduction in order to produce offspring of the next generation, thus explaining its feasibility in several research domains [40, 41]. The MOGA algorithm was configured to find the optimum varying the following network parameters: (i) number of hidden layers (integer interval: 1 to 3), (ii) number of neurons per layer (integer interval: 1 to 256 for the first hidden layer and 0 to 255 for other ones), and (iii) activation functions for each layer (one among: log-sigmoid - logsig, hyperbolic tangent sigmoid -tansig, pure linear - purelin and symmetric saturating linear - satlins).
The overall performances of MOGA algorithm and classification network were evaluated using the confusion matrix reported in Table 1 and the performance indexes reported in Eqs. 3, 4 and 5.
Experiments and results
Participants
32 participants (21 males, 11 females, age: 71.4 ±8.3 years old) were enrolled for the experiment. In detail, the participants were composed of 21 PD subjects (17 males and 4 females, age: 72.1 ±8.3) and 11 healthy ones (4 males and 7 females, age: 70.2 ±10.2 years old); the healthy group was selected to match the age of the PD one. The PD group was subsequently divided into mild and moderate subgroups according to the degree of the disease. The subgroups were composed of 12 mild patients (9 males and 3 females, age: 70.5 ±10.0) and 9 moderate ones (8 males and 1 female, age: 73.8 ±6.0).
System set-up
The data acquisition is based on the system set-up (Fig. 3) presented in a previous work [28]. The set-up is based on two sensors: the Myo™Gesture Control Armband [42] for sEMG signal acquisition and the graphics tablet WACOM Cintiq 13” HD [43] for acquiring handwriting signals and data. In detail, the Myo™Armband allowed us to acquire 8 different sEMG signals of the forearm, whereas the tablet permitted us to acquire the pen tip coordinates and pressure, and the tilt of the pen with respect to the writing surface.

Example of the system set-up used for data acquisition
Experimental description
We used three writing patterns for the experiments leading to as many writing tasks. The patterns selected were as follows:
- 1
Pattern 1 – a five-turn spiral drawn in anticlockwise direction;
- 2
Pattern 2 – a sequence of 8 Latin letter ”l” with a size of 2.5cm;
- 3
Pattern 3 – a sequence of 8 Latin letter ”l” with a size of 5cm.
It is possible to observe that only two writing patterns (Patterns 2 and 3) were size-constrained, and for those, a visual marker has been provided as a size reference.
In the experiment, we asked each subject to perform four repetitions for each writing tasks: the first one was used to familiarise with the task and was discarded, the remaining three were recorded as data for the following processing.
Each handwriting tasks was interleaved with a rest period of three seconds, and the first pressure point on the tablet has been used as a trigger for the tasks begin.
Each subject generated 41 features for writing task 1 and to 43 features for writing task 2 and 3:
Root Mean Square (RMS) of each sEMG signal (8 RMS features for each subject and for each task);
Zero Crossing (ZC) of each sEMG signal (8 RMS features for each subject and for each task);
mean and standard deviation for each subject and for each task of the following signals:
pen tip Cartesian velocity (two features);
X and Y velocity components of the pen tip (four features);
pen tip Cartesian acceleration (two features);
X and Y acceleration components of the pen tip (four features);
pen tip Cartesian jerk (two features);
X and Y jerk components of the pen tip (four features);
pen tip pressure (two features);
pen azimuth (two features);
pen altitude (two features);
pattern specific features:
index of precision of the spiral drawing (one feature);
size related features for the constrained patterns (three features).
Experimental data processing description
The objectives of the conducted experiments were mainly two:
- 1
the first was to separate PD patients from healthy subjects;
- 2
the second was to correctly classify mild and moderate Parkinson patients.
For each objective, the features extracted during the experiments were grouped according to the following scheme:
creation of three different feature datasets:
dataset A including only the features extracted from writing pattern 1 (41 features);
dataset B including only the features extracted from writing pattern 2 (43 features);
dataset C including only the features extracted from writing pattern 3 (43 features);
application of a feature selection algorithm to reduce the number of the features;
creation of six different new feature datasets:
Case 1. Dataset including all the feature of set A;
Case 2. Dataset including all the feature of set B;
Case 3. Dataset including all the feature of set C
Case 4. Dataset including only the features obtained by the application of the feature selection algorithm on dataset A;
Case 5. Dataset including only the features obtained by the application of the feature selection algorithm on dataset B;
Case 6. Dataset including only the features obtained by the application of the feature selection algorithm on dataset C.
To assess both objectives of the experiments, an Artificial Neural Network (ANN) classifier featuring an optimised topology provided a Multi-Objective Genetic Algorithm (MOGA) was used.
In detail, for each objective and each of the six cases, we estimated the performance indexes of the ANN optimal topology approach, reported in Eqs. 3, 4 and 5, in terms of percentage and standard deviation. Due to the dependence of the ANN performances from both net initialisation and permutation of training-validation datasets, we iterated the assessment over 250 repetitions of the net training procedure. Figure 4 depicts the scheme of the experiments.

Scheme of the experiment. Features are grouped in three sets: A, B and C. The application of the Feature Selection (FS) algorithm leads to 6 cases
Results
Two samples of one repetition of the writing tasks performed respectively by healthy and PD subject are reported (not in real scale) in Figs. 5 (task no.1), 6 (task no.2) and 7 (task no.3).

Example of one repetition of the spiral drawing task performed by a healthy subject (top) and a PD subject (bottom), respectively

Example of one repetition of the letter-based task (sequence of eight "l" with size of 2.5cm) performed by a healthy subject (top) and a PD subject (bottom), respectively

Example of one repetition of the letter-based task (sequence of eight "l" with size of 5cm) performed by a healthy subject (top) and a PD subject (bottom), respectively
Based on the two objectives the presentation and the discussion of the results obtained from the experiments have been subdivided. In particular, for each objective, we have reported the results obtained from both the feature selection and the classification for each of the six cases.
For each case the training procedure was iterated 250 times to assess the stability of the learning process; hence, the confusion matrices and the related results are presented in percentage with the standard deviation reported in brackets.
Objective 1 - separating PD patients and healthy subjects:
-
Feature Selection results: The application of the feature selection algorithm previously reported, led to a significant reduction of the number of considered features for all three datasets of features extracted from the writing patterns. In particular:
-
for dataset A including the 41 features extracted from writing pattern 1, the sEMG RMS value, three sEMG ZC values, the mean Cartesian velocity and the mean acceleration on X axes were the six selected features to be classified in Case 4;
-
for dataset B including the 43 features extracted from writing pattern 2, the mean jerk on Y axes, three sEMG ZC values, the mean Cartesian acceleration and the mean velocity on X axes were the six selected features to be classified in Case 5;
-
for dataset C including the 43 features extracted from writing pattern 3, two sEMG RMS values, a sEMG ZC value, the mean cartesian velocity, the altitude STD, the azimuth RMS and the mean velocity on X axes were the seven selected features to be classified in Case 6.
-
Classification results: for each of the six different feature datasets, the MOGA algorithm is applied to provide the optimal ANN topology. The optimal topology results and the confusion matrices are reported in Table 2 and in Tables 3, 4, 5, 6, 7 and 8, respectively; the performances expressed in terms of accuracy, specificity and sensitivity have been summarised in Table 9.
Table 2 Objective 1: results of the application of the MOGA algorithm on each of the six different feature datasets Table 3 Confusion matrix of Case 1 (Objective 1) Table 4 Confusion matrix of Case 2 (Objective 1) Table 5 Confusion matrix of Case 3 (Objective 1) Table 6 Confusion matrix of Case 4 (Objective 1) Table 7 Confusion matrix of Case 5 (Objective 1) Table 8 Confusion matrix of Case 6 (Objective 1) Table 9 Objective 1: performances of the application of the MOGA algorithm on each of the six different feature datasets
Objective 2 - separating mild and moderate PD patients:
-
Feature Selection results: the application of the feature selection algorithm previously reported, led to a significant reduction of the number of considered features for all three datasets of features extracted from writing patterns. In particular:
-
for dataset A including the 41 features extracted from writing pattern 1, two sEMG RMS values, two sEMG ZC values, the mean pressure and the mean altitude were the six selected features to be classified in Case 4;
-
for dataset B including the 43 features extracted from writing pattern 2, two sEMG RMS values, two sEMG ZC values and the mean Cartesian velocity were the five selected features to be classified in Case 5;
-
for dataset C including the 43 features extracted from writing pattern 3, two sEMG RMS values, a sEMG ZC value, the mean Cartesian velocity on X axes and the mean pressure were the five selected features to be classified in Case 6.
-
-
Classification results: for each of the six different feature datasets, the MOGA algorithm is applied to provide the optimal ANN topology. The optimal topology results and the confusion matrices are reported in Table 10 and in Tables 11, 12, 13, 14, 15 and 16, respectively; the performances expressed in terms of accuracy, specificity and sensitivity have been summarised in Table 17.
Table 10 Objective 2: results of the application of the MOGA algorithm on each of the six different feature datasets Table 11 Confusion matrix of Case 1 (Objective 2) Table 12 Confusion matrix of Case 2 (Objective 2) Table 13 Confusion matrix of Case 3 (Objective 2) Table 14 Confusion matrix of Case 4 (Objective 2) Table 15 Confusion matrix of Case 5 (Objective 2) Table 16 Confusion matrix of Case 6 (Objective 2) Table 17 Objective 2: performances of the application of the MOGA algorithm on each of the six different feature datasets
Discussion
For the sake of clarity, we summarised the accuracy of all cases for both objectives in Table 18. As reported in the table, the proposed procedure leads to high accuracy performances; the results for both objectives present accuracy in the range 86<x<97, with a standard deviation lower than 0.09. The low value of the standard deviation allows us to assess the stability of the learning process of the optimal ANN. Similar observations can be stated for both objectives for the classification of the selected features. In detail:
the classification between PD patients and healthy subjects (objective 1) achieves the best accuracy (96.85%) in Case 6 (seven features selected from the dataset of 43 features extracted from writing pattern 3). The feature selection stated that three out of seven features were related to sEMG signals (RMS and ZC), whereas the others to pen tilt and velocity;
Table 18 Summary of the accuracy values obtained for each of the two objectives for each considered case the classification between mild and moderate PD patients (objective 2) achieves the best accuracy (96.00%) in Case 4 (six features selected from the dataset of 41 features extracted from writing pattern 1). The feature selection stated that four out of six features were related to sEMG signals (RMS and ZC), whereas the others to pen tilt and velocity;
Conclusions
In this work, we proposed an innovative methodology for computer-assisted handwriting analysis with the main goal of PD detection (healthy subjects vs. PD patients) and rating (mild vs moderate PD patients). The proposed approach is based on extracting different features from biometric signals collected during handwriting tasks and using such features to detect and rate PD. The developed decision support system (DSS) is based on an artificial neural network whose topology has been optimized with a MOGA.
The results showed that the proposed DSS is able to classify healthy subjects vs PD patients and mild vs moderate PD patients with a high classification accuracy (more than 90.0%). Furthermore, we proved that a limited set of representative feature selected by means of a classification decision tree technique, that uses the Gini’s diversity index, improves the overall accuracy (more than 96.0%).
Future works are needed to investigate the DSS performance with a larger cohort of subjects that includes severe PD patients too. This will allow us to classify PD patients by using more than two PD status classes and to monitor the progress of the disease over time. Furthermore, due to the time-consuming acquisition steps, it is desirable to reduce the required number of pattern tasks; this will be achieved through a proper writing pattern selection among the proposed ones.
Availability of data and materials
The datasets generated and analysed during the current study are not publicly available due to restrictions associated with anonymity of participants but are available from the corresponding author on reasonable request.
Abbreviations
- ANN:
-
Artificial neural network
- AUC:
-
Area under the curve
- FN:
-
False negative
- FP:
-
False positive
- MOGA:
-
Multi-objective genetic algorithm
- PD:
-
Parkinson’s disease
- RMS:
-
Root mean square
- ROC:
-
Receiver operating characteristic
- SEMG:
-
surface electromyography
- TN:
-
True negative
- TP:
-
True positive
- ZC:
-
Zero crossing
References
Bevilacqua V, D’Ambruoso D, Mandolino G, Suma M. A new tool to support diagnosis of neurological disorders by means of facial expressions. In: MeMeA 2011 - 2011 IEEE International Symposium on Medical Measurements and Applications, Proceedings: 2011. p. 544–9. https://doi.org/10.1109/MeMeA.2011.5966766.
Carnimeo L, Trotta GF, Brunetti A, Cascarano GD, Buongiorno D, Loconsole C, Di Sciascio E, Bevilacqua V. Proposal of a health care network based on big data analytics for pds. J Eng. 2019. https://doi.org/10.1049/joe.2018.5141.
Buongiorno D, Trotta GF, Bortone I, Di Gioia N, Avitto F, Losavio G, Bevilacqua V. Assessment and rating of movement impairment in parkinson’s disease using a low-cost vision-based system In: Huang D-S, Gromiha MM, Han K, Hussain A, editors. Intelligent Computing Methodologies. Cham: Springer: 2018. p. 777–88.
Bortone I, Buongiorno D, Lelli G, Di Candia A, Cascarano GD, Trotta GF, Fiore P, Bevilacqua V. Gait analysis and parkinson’s disease: Recent trends on main applications in healthcare In: Masia L, Micera S, Akay M, Pons JL, editors. Converging Clinical and Engineering Research on Neurorehabilitation III. Cham: Springer: 2019. p. 1121–5.
Cascarano GD, Brunetti A, Buongiorno D, Trotta GF, Loconsole C, Bortone I, Bevilacqua V. In: Esposito A, Faundez-Zanuy M, Morabito FC, Pasero E, (eds).A Multi-modal Tool Suite for Parkinson’s Disease Evaluation and Grading. Singapore: Springer; 2020, pp. 257–68. https://doi.org/10.1007/978-981-13-8950-4_24.
Bidet-Ildei C, Pollak P, Kandel S, Fraix V, Orliaguet J-P. Handwriting in patients with Parkinson disease: Effect of L-dopa and stimulation of the sub-thalamic nucleus on motor anticipation. Hum Mov Sci. 2011; 30(4):783–91.
Carmeli E, Patish H, Coleman R. The aging hand. J Gerontol Ser A Biol Sci Med Sci. 2003; 58(2):146–52.
McLennan JE, Nakano K, Tyler HR, Schwab RS. Micrographia in Parkinson’s disease. J Neurol Sci. 1972; 15(2):141–52.
Flash T, Inzelberg R, Schechtman E, Korczyn AD. Kinematic analysis of upper limb trajectories in Parkinson’s disease. Exp Neurol. 1992; 118(2):215–26.
Margolin DI, Wing AM. Agraphia and micrographia: Clinical manifestations of motor programming and performance disorders. Acta Psychol. 1983; 54(1):263–83.
Müller F, Stelmach GE. Prehension movements in Parkinson’s disease. Adv Psychol. 1992; 87:307–19.
Contreras-Vidal JL, Teulings H-L, Stelmach GE. Micrographia in Parkinson’s disease,. Neuroreport. 1995; 6(15):2089–92.
Van Gemmert AWA, Teulings H. -L., Contreras-Vidal JL, Stelmach GE. Parkinsons disease and the control of size and speed in handwriting. Neuropsychologia. 1999; 37(6):685–94.
Van Gemmert AWA, Teulings H-L, Stelmach GE. Parkinsonian patients reduce their stroke size with increased processing demands. Brain Cogn. 2001; 47(3):504–12.
Teulings HL, Contreras-Vidal JL, Stelmach GE, Adler CH. Adaptation of handwriting size under distorted visual feedback in patients with Parkinson’s disease and elderly and young controls. J Neurol Neurosurg Psychiatry. 2002; 72(3):315–24.
Drotar P, Mekyska J, Smekal Z, Rektorova I, Masarova L, Faundez-Zanuy M. Prediction potential of different handwriting tasks for diagnosis of Parkinson’s. In: E-Health and Bioengineering Conference (EHB), 2013. IEEE: 2013. p. 1–4. https://doi.org/10.1109/ehb.2013.6707378.
Nutt JG, Wooten GF. Diagnosis and initial management of Parkinson’s disease. N Engl J Med. 2005; 353(10):1021–7.
Nutt JG, Lea ES, Van Houten L, Schuff RA, Sexton GJ. Determinants of tapping speed in normal control subjects and subjects with Parkinson’s disease: differing effects of brief and continued practice. Mov Disord. 2000; 15(5):843–9.
Gordon AM. Task-dependent deficits during object release in Parkinson’s disease. Exp Neurol. 1998; 153(2):287–98.
Tresilian JR, Stelmach GE, Adler CH. Stability of reach-to-grasp movement patterns in Parkinson’s disease,. Brain. 1997; 120(11):2093–111.
Rand MK, Stelmach GE, Bloedel JR. Movement accuracy constraints in Parkinson’s disease patients. Neuropsychologia. 2000; 38(2):203–12.
Helsper E, Teulings H-L, Karamat E, Stelmach GE. Preclinical Parkinson features in optically scanned handwriting. In: Handwriting and Drawing Research: Basic and Applied Issues. Amsterdam: IOS Press: 1996. p. 241–50.
Longstaff MG, Mahant PR, Stacy MA, Van Gemmert AWA, Leis BC, Stelmach GE. Discrete and dynamic scaling of the size of continuous graphic movements of parkinsonian patients and elderly controls. J Neurol Neurosurg Psychiatry. 2003; 74(3):299–304.
Ünlü A, Brause R, Krakow K. Handwriting analysis for diagnosis and prognosis of parkinson’s disease. In: International Symposium on Biological and Medical Data Analysis. Springer: 2006. p. 441–50. https://doi.org/10.1007/11946465_40.
Rosenblum S, Samuel M, Zlotnik S, Erikh I, Schlesinger I. Handwriting as an objective tool for Parkinson’s disease diagnosis. J Neurol. 2013; 260(9):2357–61.
Loconsole C, Trotta GF, Brunetti A, Trotta J, Schiavone A, Tatò SI, Losavio G, Bevilacqua V. Computer Vision and EMG-Based Handwriting Analysis for Classification in Parkinson’s Disease In: Huang D-S, Jo K-H, Figueroa-García JC, editors. Intelligent Computing Theories and Application: 13th International Conference, ICIC 2017, Liverpool, UK, August 7-10, 2017, Proceedings, Part II. Cham: Springer: 2017. p. 493–503. https://doi.org/10.1007/978-3-319-63312-1_43. http://link.springer.com/10.1007/978-3-319-63312-1_43.
Loconsole C, Cascarano GD, Lattarulo A, Brunetti A, Trotta GF, Buongiorno D, Bortone I, De Feudis I, Losavio G, Bevilacqua V, Di Sciascio E. A comparison between ann and svm classifiers for parkinson’s disease by using a model-free computer-assisted handwriting analysis based on biometric signals. In: 2018 International Joint Conference on Neural Networks (IJCNN): 2018. p. 1–8. https://doi.org/10.1109/IJCNN.2018.8489293.
Loconsole C, Cascarano GD, Brunetti A, Francesco Trotta G, Losavio G, Bevilacqua V, Di Sciascio E. A model-free technique based on computer vision and sEMG for classification in Parkinson’s disease by using computer-assisted handwriting analysis. Pattern Recogn Lett. 2018. https://doi.org/10.1016/j.patrec.2018.04.006.
Bevilacqua V, Loconsole C, Brunetti A, Cascarano GD, Lattarulo A, Losavio G, Di Sciascio E. A Model-Free Computer-Assisted Handwriting Analysis Exploiting Optimal Topology ANNs on Biometric Signals in Parkinson’s Disease Research. In: Intelligent Computing Theories and Application: 2018. p. 650–5. https://doi.org/10.1007/978-3-319-95933-7_74. http://link.springer.com/10.1007/978-3-319-95933-7_74.
Bevilacqua V, Cariello L, Columbo D, Daleno D, Fabiano MD, Giannini M, Mastronardi G, Castellano M. Retinal fundus biometric analysis for personal identifications. In: Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 5227 LNAI: 2008. p. 1229–37. https://doi.org/10.1007/978-3-540-85984-0_147.
Sun ZL, Huang DS, Cheung YM, Liu J, Huang GB. Using FCMC, FVS, and PCA techniques for feature extraction of multispectral images. IEEE Geosci Remote Sens Lett. 2005; 2(2):108–112. https://doi.org/10.1109/LGRS.2005.844169.
Breiman L. Classification and Regression Trees: Routledge; 2017.
Huang D-S. Systematic theory of neural networks for pattern recognition, vol. 201. Beijing: Publishing House of Electronic Industry of China; 1996.
Huang D-S, Ma S-D. Linear and nonlinear feedforward neural network classifiers: A comprehensive understanding. J Intell Syst. 1999; 9(1):1–38.
Bevilacqua V, Carnimeo L, Mastronardi G, Santarcangelo V, Scaramuzzi R. On the comparison of nn-based architectures for diabetic damage detection in retinal images. J Circ Syst Comput. 2009; 18(08):1369–80.
Bevilacqua V, Mastronardi G, Menolascina F, Pannarale P, Pedone A. A novel multi-objective genetic algorithm approach to artificial neural network topology optimisation: The breast cancer classification problem. In: The 2006 IEEE International Joint Conference on Neural Network Proceedings: 2006. p. 1958–1965. https://doi.org/10.1109/IJCNN.2006.246940.
Bevilacqua V, Mastronardi G, Piscopo G. Evolutionary approach to inverse planning in coplanar radiotherapy. Image Vis Comput. 2007; 25(2):196–203. https://doi.org/10.1016/j.imavis.2006.01.027.
Menolascina F, Bellomo D, Maiwald T, Bevilacqua V, Ciminelli C, Paradiso A, Tommasi S. Developing optimal input design strategies in cancer systems biology with applications to microfluidic device engineering. BMC Bioinformatics. 2009; 10(SUPPL. 12):4. https://doi.org/10.1186/1471-2105-10-S12-S4.
Bevilacqua V, Brunetti A, Triggiani M, Magaletti D, Telegrafo M, Moschetta M. An Optimized Feed-forward Artificial Neural Network Topology to Support Radiologists in Breast Lesions Classification. In: Proceedings of the 2016 on Genetic and Evolutionary Computation Conference Companion - GECCO ’16 Companion. New York: ACM Press: 2016. p. 1385–92. https://doi.org/10.1145/2908961.2931733. http://dl.acm.org/citation.cfm?doid=2908961.2931733.
Buongiorno D, Barsotti M, Barone F, Bevilacqua V, Frisoli A. A linear approach to optimize an emg-driven neuromusculoskeletal model for movement intention detection in myo-control: A case study on shoulder and elbow joints. Front Neurorobotics. 2018; 12:74. https://doi.org/10.3389/fnbot.2018.00074.
Buongiorno D, Barsotti M, Sotgiu E, Loconsole C, Solazzi M, Bevilacqua V, Frisoli A. A neuromusculoskeletal model of the human upper limb for a myoelectric exoskeleton control using a reduced number of muscles. In: 2015 IEEE World Haptics Conference (WHC): 2015. p. 273–9. https://doi.org/10.1109/WHC.2015.7177725.
Myo™Gesture Control Armband. www.myo.com. Accessed Mar 2018.
WACOM Cintiq 13” HD. www.wacom.com/en-ch/products/pen-displays/cintiq-13-hdwww.wacom.com/en-ch/products/pen-displays/cintiq-13-hd. Accessed Mar 2018.
Acknowledgements
We would like to thank all the health professionals in Medica Sud S.r.l. for their support and all the voluntary patients that participate to the study.
About this supplement
This article has been published as part of BMC Medical Informatics and Decision Making Volume 19 Supplement 9, 2019: Proceedings of the 2018 International Conference on Intelligent Computing (ICIC 2018) and Intelligent Computing and Biomedical Informatics (ICBI) 2018 conference: medical informatics and decision making. The full contents of the supplement are available online at https://bmcmedinformdecismak.biomedcentral.com/articles/supplements/volume-19-supplement-9.
Funding
Publication costs are funded by the Italian Apulian Region project "RECALL" (Innolabs n. QIRYKE8).
Author information
Authors and Affiliations
Contributions
VB and CL conceived of the study and participated in its design and coordination. GDC, AL, AB and DB carried out the data analysis. GL and VB organized the enrollment of the patients and the acquisition of the data and then validated the final results. VB, CL, GDC, AL, DB and ED drafted the manuscript and then all the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The experimental procedures were conducted in accordance with the Declaration of Helsinki. All participants provided written informed consent.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver(http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Cascarano, G.D., Loconsole, C., Brunetti, A. et al. Biometric handwriting analysis to support Parkinson’s Disease assessment and grading. BMC Med Inform Decis Mak 19 (Suppl 9), 252 (2019). https://doi.org/10.1186/s12911-019-0989-3
Published:
DOI: https://doi.org/10.1186/s12911-019-0989-3