
Abstract
Background
The internet is now the first line source of health information for many people worldwide. In the current Coronavirus Disease 2019 (COVID-19) global pandemic, health information is being produced, revised, updated and disseminated at an increasingly rapid rate. The general public are faced with a plethora of misinformation regarding COVID-19 and the readability of online information has an impact on their understanding of the disease. The accessibility of online healthcare information relating to COVID-19 is unknown. We sought to evaluate the readability of online information relating to COVID-19 in four English speaking regions: Ireland, the United Kingdom, Canada and the United States, and compare readability of website source provenance and regional origin.
Methods
The Google® search engine was used to collate the first 20 webpage URLs for three individual searches for ‘COVID’, ‘COVID-19’, and ‘coronavirus’ from Ireland, the United Kingdom, Canada and the United States. The Gunning Fog Index (GFI), Flesch-Kincaid Grade (FKG) Score, Flesch Reading Ease Score (FRES), Simple Measure of Gobbledygook (SMOG) score were calculated to assess the readability.
Results
There were poor levels of readability webpages reviewed, with only 17.2% of webpages at a universally readable level. There was a significant difference in readability between the different webpages based on their information source (p < 0.01). Public Health organisations and Government organisations provided the most readable COVID-19 material, while digital media sources were significantly less readable. There were no significant differences in readability between regions.
Conclusion
Much of the general public have relied on online information during the pandemic. Information on COVID-19 should be made more readable, and those writing webpages and information tools should ensure universal accessibility is considered in their production. Governments and healthcare practitioners should have an awareness of the online sources of information available, and ensure that readability of our own productions is at a universally readable level which will increase understanding and adherence to health guidelines.
Similar content being viewed by others


Background
The Coronavirus Disease 2019 (COVID-19) pandemic has led to an expected increase in the number of online searches on the condition. Internet users are now frequently searching for health related information and as a tool to answer questions about symptoms, diagnoses and treatment [1]. Social distancing, lockdowns and self-isolation policies worldwide have also meant patients’ access to in-person health care advice has decreased and reliance on either telemedicine or online information has increased. This is reflected in the rise of Google® Trends searches for ‘coronavirus’, ‘COVID’ and ‘COVID-19′ in recent months [2].
The internet as a source of health information is unregulated and the quality, reliability, and accessibility to the reader is variable. While there are some quality guidelines available, such as Health on the Net (www.hon.ch/en), which promotes reliable and transparent health information online, there is little guidance for readability of online health information [3]. Many webpages provide inaccurate or questionable information and this can be harmful [4]. A small number of studies have already reported on the quality of COVID-19 related health information [5], and indeed the misinformation that has appeared on webpages and in particular on social media in recent months [4, 6]. The quality of information relating to COVID-19 accessed found that there are often discrepancies between health information issued by public health organisation and general information available on other digital media [7].
Several tools are available to assess the readability of information, such as the Gunning Fox Index (GFI), the Flesch Reading Ease Score (FRES), the Flesch-Kincaid Grade (FKG) and the Simple Measure of Gobbledygook (SMOG) score [8]. These tools are established validated readability tools and are validated in health information studies and the English language, and have defined score levels for universal readability [9]. The readability of health information related to COVID-19 has not been published. We sought to evaluate the readability of online information relating to COVID-19 in four English speaking regions: Ireland, the United Kingdom, Canada and the United States, ranking of websites, and compare readability of website source provenance and regional origin.
Methods
Webpage search and identification
The Google® search engine was used to collate the first 20 webpage URLs for three individual searches for ‘COVID’, ‘COVID-19’, and ‘coronavirus’. When searching for information on the internet users typically will pick one of the first five search results, and will typically rephrase their search criteria instead of proceeding to the second page (or further) [10], as a result we only included results from the first page of search engine results. The searches were conducted from geolocation search engine settings, in web-browser Google Chrome Version 85, to reflect the webpages found in Ireland, the United Kingdom, Canada and the United States. All searches were conducted on 17th April 2020. All previous search history and data caches were cleared before the first search, and between searches. Webpage results are tabulated in Appendix 1. Results were categorised by two researchers (AW and MC) independently based on source provenance of the webpage; ‘government and public health organisations’, ‘educational or scientific institution’, ‘digital media’ or ‘other’. A fifth category of ‘peer-reviewed journals/articles’ was included, but no webpage results fell into this category, and as such we have not included it in results. Source provenance for ‘government and public health organisations’ required that the webpage was supported, funded or hosted on a government, state, county or federal website platform (.gov.us, .gov.nl.ca, hse.ie, nhs.co.uk, as some examples), ‘educational or scientific institutions’ included sources such as Mayo Clinic, Medline, WebMD, etc., ‘digital media’ sources were webpages from news outlets, newspaper digital platforms etc., and ‘other’ captured the remaining webpages that fell out of these categories, similar to previous published categories in readability analyses [11].
Readability assessment tools
Four scores were used to calculate readability of the webpages; the Gunning Fog Index (GFI), the Flesch Kincaid Grade (FKG) Score and Flesch Reading Ease Score (FRES) and the Simple Measure of Gobbledygook (SMOG) Index. To ensure consistency and avoid human error the readability tests were done using an online readability calculator to provide FRES, FKG, GFI and SMOG scores [12]. All webpages were screened by the readability tool and hyperlinks, non-standard text, abbreviations and author names were not included in the analysis to prevent low-skewing of results.
The Flesch Reading Ease Score (FRES)
The FRES is a tool that indicates readability of English text on a 100-point scale. The FRES can be calculated using the following formula: [206.835 – (1.015 x (total words ÷ total sentences)) – (84.6 x (total syllables ÷ total words))]. The higher the score the greater the ease of comprehension, e.g. > 90 scores indicate something that would easily be understood by a 10–11 year old. A recommended score between 60 and 70 represents a suitable readability level for most 13 year olds, which adequately captures most patient cohorts [13].
The Flesch-Kincaid Grade Score
The Flesch-Kincaid Grade (FKG) Score is a readability test used extensively in educational settings, it gives a marker of readability with a weighting on syllables. It can be calculated with the following formula: 0.39 (total words/total sentences) + 11.8 (total syllables/total words) – 15.59. The resulting number gives an estimated United States grade level equivalent. For universal accessibility and readability a suitable score is < 8.
The Gunning Fox Index
The GFI tool is an English language tool measuring readability by estimating years of formal education needed to understand a text on the first time of reading. The GFI can be calculated using the following formula: 0.4 x [(words ÷ sentences) + 100 x (complex words ÷ total words)]. A lower score indicates sample text that is more easily read. The GFI scale runs from 6 to 17; where 6 represents the reading level of an 11–12 year old, 12 is an 18 year old who has completed second level education, and 17 is a university level graduate [13]. Information requiring near universal readability should have a GFI < 8 [14].
The Simple Measure of Gobbledygook Index
The SMOG readability index estimates the number of years of formal education that a reader would need in order to read the material tested. The SMOG formula is: 3 + square root √ [number of polysyllabic words x (30 ÷ number of sentences)]. SMOG is only validated in the English language and is validated in healthcare information studies [15]. A suitable SMOG score for universal readability is 10.
Statistical analysis
Descriptive statistics were calculated for SMOG, FRES, FKG and GFI scores. Shapiro-Wilk test determined parametric or non-parametric data distribution. Mean (SD) were used for normally distributed data, while median (range) were used for non-parametrically distributed data. Spearman’s correlations and Pearson’s correlations were used to assess non-parametric and parametric association between readability scores respectively. ANOVAs and Kruskall-Wallis tests were used to compare differences between the mean or median readability scores for univariate group analysis to determine differences between country, continent and source provenance. A 5% level of significance was used for all statistical tests. All statistical analysis was performed using GraphPad Prism software Version 8 (La Jolla, CA, USA, 2020), SPSS Statistics Version 26 (IBM, 2020) and Microsoft Office Excel Version 16 (USA, 2018).
Results
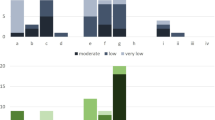
The searches were performed using the keywords: coronavirus, COVID, COVID-19. The first 20 webpages were collated from each search and the search was conducted geolocated to Ireland, the United Kingdom, Canada and the United States, totalling 240 webpages (Appendix 1). Of the 240 webpages analysed 53% (n = 127) were government organisations or public health organisation webpages, 29% (n = 69) were digital or social media webpages, 5% (n = 11) were from scientific or educational institutions and 14% (n = 33) were from other sources (Table 1A). There was a relation by chi squared analysis between country and source type of information in the website results (x2 = 23.69, p < 0.00481). This relationship was investigated for differences between regional spread of webpage sources (ANOVA, p < 0.042), with Canada and the United States having higher numbers of public health and governmental websites than Ireland and the United Kingdom (Table 1A). There was matching inverse correlation between webpage sources between countries (r − 0.172, 95% CI [− 0.2960 to − 0.04293], p < 0.007,) and between continents (r − 0.185, 95% CI [− 0.3084 to − 0.05652], p < 0.0039), both by non-parametric Spearman correlation analysis.
FRES results were parametric, while FKG, GFI and SMOG scores were all non-parametric. Only 17.2% (n = 165) of all the readability scores analysed demonstrated a universally readable level. 19% (n = 45) of FRES scores were at a universally readable level (> 60), 32% (n = 77) of FKG scores (target < 8), 37% (n = 88) of GFI scores (target < 8), and only 30% (n = 73) of SMOG scores were at a universally readable levels (< 10). The mean readability scores for webpages searched from all regions were below the standard universal readability levels, and there were no significant differences comparably between regions (Table 1B).
There were significant differences between the readability of webpages depending on the information source for all readability scores FRES (p < 0.0196), FKG (p < 0.04), GFI (p < 0.0003), and SMOG (p < 0.0009) by ANOVA analyses (Table 1C). From this analysis the most readable sources across the majority of the scores were webpages issued by government and public health organisations. All four readability scores (FRES, FKG, GFI and SMOG) correlated with each other significantly (Spearman’s correlations, r values, p values and 95% CI available in Appendix 2). There was a positive association between source of information category and ranking of the webpage on the search engine results by Spearman correlation (r 0.184, 95% CI [0.05525 to 0.3072], p < 0.004).
Discussion
Health literacy is an important barrier for communication by health professionals, public health bodies and government institutions with the public [9]. The COVID-19 pandemic presents a number of health literacy obstacles which include the rapid publication of information, the frequently evolving and fluctuating nature of public guidelines and health information, the lack of specific treatments, with an evidence base, for COVID-19 pneumonia, and the inconsistent and sometimes dangerous information and misinformation that is occurring online, in particular on social media [16]. Basic access to reliable, high quality and readable online information is an economic and social privilege, and the COVID-19 pandemic has highlighted this digital inequality [17]. Indeed, readability of online health information related to other epidemics such as Zika virus, and Ebola virus disease also found the majority of health information, including governmental and public health sources to be beyond basic readability levels [18, 19]. A fundamental necessity to understanding and engaging with health information is the accessibility and readability of the information and while there is a pressure and immediacy to publish information at short notice, readability should be considered when producing health literature and information [16].
The webpages analysed were mostly higher than an acceptable universal level for readability. The universal level of readability is generally accepted to be that of a child, aged 10–11 that has attended primary school or junior school [13]. The best performing readability score found only 37% of webpages readable to a universal audience, this does not reflect well for the health information produced and disseminated online. Similar studies of quality and readability of online health information also often report poor readability levels including in vascular surgery [20], respiratory medicine [11], and genitourinary medicine [21]. This poor readability level affects understanding of the health information; resulting in poor adherence to hygiene measures, social-distancing measures, and further public health recommendations [6].
Webpages most likely to be viewed are webpages on the first page of search results [10], making website rankings an important factor for consideration [22]. Our analysis included only webpages from the first page of search engine results and the moderately positive correlation between source type and ranking of webpages on the search results is reassuring as the majority of webpages were published by public health organisations or government bodies, and they tended to be both ranked higher on the results list and have better readability scores.
Search engines have the ability to manipulate ranking settings, and sponsored search results can often tamper with what audiences see first [22]. Google®, has been making corporate decisions to artificially rank high-profile health information from respectable prevalence such as the World Health Organisation since early March 2020 [23]. This might explain why Government and Public Health bodies account for 53% (n = 127) of search results, and while this is reassuring because readability tends to be higher from information from those origins, the mean readability scores in this study remain poor. These differences seen between countries and continents in both the type of source information available is worth considering, given that there is a clear difference in readability between sources.
The correlations between the various readability scores was reassuring and showed that while there are some differences that the trend in detecting poor readability was similar between tests (Appendix 2). While much has been published in the last few weeks on the quality of health information and the misinformation relating to COVID-19, this is the first assessment of readability of online information on COVID-19 with comparisons between four English speaking countries.
We acknowledge the limitations of this study. There are a number of weaknesses associated with each of the readability scores [14, 24]. The tests rely on numbers of words in sentences, or syllables in words, which may not always reflect the reading level. The scores do not consider layout, infographics or figures that often help accessibility and understanding of accompanying literature. Like all infodemiology research the nature of researching online health information is limited by the constantly changing, revising and updating of online material. This study may have different results if repeated at another time.
Conclusion
The majority of webpages relating to COVID-19 are not at a universal reading level in four major English speaking regions. However, reassuringly most webpages originated from public health organisations and government bodies. While there is an urgency in a global pandemic to publish guidance and health information, there is an onus on publishers from all information sources to publish information that is readable for all levels of comprehension, which will in turn lead to better levels of education and adherence to guidance.
Availability of data and materials
The datasets used and analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- ANOVA:
-
Analysis of variance
- COVID-19:
-
Coronavirus Disease 2019
- FKG:
-
Flesch Kinaid Grade
- FRES:
-
Flesch Reading Ease Score
- GFI:
-
Gunning Fox Index
- SD:
-
Standard Deviation
- SMOG:
-
Simple Measure of Gobbledygook
References
Hesse BW, Nelson DE, Kreps GL, Croyle RT, Arora NK, Rimer BK, et al. Trust and sources of health information. Arch Intern Med. 2005;165(22):2618.
Google. Google Trends. Google Trends. 2020 [cited 2020 Apr 12]. Available from: https://trends.google.com/trends/.
Team Hon. Health on the Net. 2020. Available from: www.hon.ch/en.
Europarl. Disinformation: How to recognise and tackle Covid-19 myths. European Parliament. 2020.
Song P, Karako T. COVID-19: real-time dissemination of scientific information to fight a public health emergency of international concern. Biosci Trends. 2020;14(1):1–2.
Kouzy R, Abi Jaoude J, Kraitem A, El Alam MB, Karam B, Adib E, et al. Coronavirus Goes viral: quantifying the COVID-19 misinformation epidemic on twitter. Cureus. 2020;12(3):e7255.
Hernández-García I, Giménez-Júlvez T. Assessment of health information about COVID-19 prevention on the internet: Infodemiological study. JMIR Public Heal Surveill. 2020;6(2):e18717.
Garner M, Ning Z, Francis J. A framework for the evaluation of patient information leaflets. Health Expect. 2012;15(3):283–94.
Mcinnes N, Haglund BJA. Readability of online health information: implications for health literacy. Informatics Heal Soc Care. 2011;36(4):173–89.
Eysenbach G. How do consumers search for and appraise health information on the world wide web? Qualitative study using focus groups, usability tests, and in-depth interviews. BMJ. 2002;324(7337):573–7.
San Giorgi MRM, de Groot OSD. Dikkers FG. Laryngoscope: Quality and readability assessment of websites related to recurrent respiratory papillomatosis; 2017.
Added Bytes. Readable. How Readable Is Your Writing? Brighton; 2020. Retrieved from https://readable.com.
Hansberry DR, Agarwal N, Baker SR. Health literacy and online educational resources: an opportunity to educate patients. Am J Roentgenol. 2015;204(1):111–6.
Keogh CJ, McHugh SM, Clarke Moloney M, Hannigan A, Healy DA, Burke PE, et al. Assessing the quality of online information for patients with carotid disease. Int J Surg. 2014;12(3):205–8.
Fitzsimmons P, Michael B, Hulley J, Scott G. A readability assessment of online Parkinson’s disease information. J R Coll Physicians Edinb. 2010;40(4):292–6.
Abel T, McQueen D. Critical health literacy and the COVID-19 crisis. Health Promot Int. 2020.
Beaunoyer E, Dupéré S, Guitton MJ. COVID-19 and digital inequalities: reciprocal impacts and mitigation strategies. Comput Human Behav. 2020.
Basch CH, Fera J, Garcia BSP. Information regarding Zika virus on the internet: a cross-sectional study of readability. Am J Infect Control. 2020.
Castro-Sánchez E, Spanoudakis E, Holmes AH. Readability of Ebola information on websites of public health agencies, United States, United Kingdom, Canada, Australia, and Europe. Emerg Infect Dis. 2015;21(7):1217.
Bresler RM, Lynch NP, Connolly M, Keelan S, Richter L, McHugh SM, et al. Arteriovenous fistula for dialysis – Let’s Google it. Readability and quality of online information. Surgeon. 2020;S1479-666X(20):30043–3. https://doi.org/10.1016/j.surge.2020.02.009. PMID: 32340801.
Fong P, Tong HHY, Cheong HL, Choi KH, Ieong KK, Lam LK, et al. Quality of online information about sexually transmitted diseases: which websites should patients read? Online Inf Rev. 2014;38(5):650–60. https://doi.org/10.1108/OIR-03-2014-0054.
Fu LY, Zook K, Spoehr-Labutta Z, Hu P, Joseph JG. Search engine ranking, quality, and content of web pages that are critical versus noncritical of human papillomavirus vaccine. J Adolesc Health. 2016;58(1):33–9.
Google. Google Company Announcement: Coronavirus: How we’re helping [Internet]. Google Blog. 2020. Available from: https://www.blog.google/inside-google/company-announcements/coronavirus-covid19-response/.
Walsh TM, Volsko TA. Readability assessment of internet-based consumer health information. Respir Care. 2008;53(10):1310–5.
Acknowledgements
Not Applicable.
Funding
The authors declare that there was no funding or sponsorship received for this research.
Author information
Authors and Affiliations
Contributions
APW conducted data collection, data analysis, manuscript writing and contributed to study design. MJC conducted data analysis and paper writing, AO’N and MO’D were involved with manuscript writing, KPT did data analysis and collection, CM, SJM and EdB conceived study design and wrote the manuscript, with final oversight. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not Applicable.
Consent for publication
Not Applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Appendix 2
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Worrall, A.P., Connolly, M.J., O’Neill, A. et al. Readability of online COVID-19 health information: a comparison between four English speaking countries. BMC Public Health 20, 1635 (2020). https://doi.org/10.1186/s12889-020-09710-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12889-020-09710-5