
Abstract
Background
Societal expenditures on work-disability benefits is high in most Western countries. As a precursor of long-term work restrictions, long-term sickness absence (LTSA) is under continuous attention of policy makers. Different healthcare professionals can play a role in identification of persons at risk of LTSA but are not well trained. A risk prediction model can support risk stratification to initiate preventative interventions. Unfortunately, current models lack generalizability or do not include a comprehensive set of potential predictors for LTSA. This study is set out to develop and validate a multivariable risk prediction model for LTSA in the coming year in a working population aged 45–64 years.
Methods
Data from 11,221 working persons included in the prospective Study on Transitions in Employment, Ability and Motivation (STREAM) conducted in the Netherlands were used to develop a multivariable risk prediction model for LTSA lasting ≥28 accumulated working days in the coming year. Missing data were imputed using multiple imputation. A full statistical model including 27 pre-selected predictors was reduced to a practical model using backward stepwise elimination in a logistic regression analysis across all imputed datasets. Predictive performance of the final model was evaluated using the Area Under the Curve (AUC), calibration plots and the Hosmer-Lemeshow (H&L) test. External validation was performed in a second cohort of 5604 newly recruited working persons.
Results
Eleven variables in the final model predicted LTSA: older age, female gender, lower level of education, poor self-rated physical health, low weekly physical activity, high self-rated physical job load, knowledge and skills not matching the job, high number of major life events in the previous year, poor self-rated work ability, high number of sickness absence days in the previous year and being self-employed. The model showed good discrimination (AUC 0.76 (interquartile range 0.75–0.76)) and good calibration in the external validation cohort (H&L test: p = 0.41).
Conclusions
This multivariable risk prediction model distinguishes well between older workers with high- and low-risk for LTSA in the coming year. Being easy to administer, it can support healthcare professionals in determining which persons should be targeted for tailored preventative interventions.
Similar content being viewed by others

Background
Participation in paid work is one of the most important social roles of individuals in our society. Paid work is a source of income, protects against social exclusion and gives meaning to life [1,2,3]. Moreover, restrictions in work participation (e.g. sickness absence or permanent work disability) cause a substantial burden on societal expenditures in most Organisation for Economic Co-operation and Development (OECD) countries [4]. Worker productivity is a continuum, ranging from normal productivity over presenteeism and prolonged sick leave to withdrawal from paid work. It is recognized that return to work is unlikely when individuals have become work disabled [5, 6]. Early recognition and prevention of long-term restrictions in work participation, e.g. long-term sickness absence (LTSA) (usually defined as more than 4–6 weeks of sickness absence), have therefore become an important target in several countries, including the Netherlands [7]. Most healthcare professionals, such as general practitioners who are usually first consulted when a (medical) problem arises, are not well trained in identifying individuals at risk for restrictions in work participation. Risk prediction models could support early identification by those healthcare professionals, and ensure timely initiation of targeted interventions to prevent long-term work restrictions [6, 8, 9].
There are few studies that have published multifactorial risk prediction models that identify working persons at risk of LTSA [10]. However, these models frequently address selected professional groups or work sectors and not a broader general working population [11,12,13,14,15]. Other limitations of those studies were that the risk prediction model was not externally validated [16], was mostly developed in Scandinavian cohorts and likely not generalizable to other countries, or did not include a comprehensive set of variables relevant for sustainable work participation in their available dataset for prediction model development [16,17,18].
The Study on TRansitions in Employment, Ability and Motivation (STREAM) conducted in the Netherlands is suitable for development and external validation of a prediction model for LTSA in a general working population aged 45–64 years. The strength of STREAM is that a wide variety of variables important for sustainable work participation were collected that are not currently included in most occupational health surveys. Therefore, this study set out to develop and externally validate an easy-to-assess multivariable risk prediction model for LTSA in the coming year in a general working population aged 45–64 years.
Methods
Study design and participants
STREAM is an ongoing prospective cohort among persons aged 45 to 64 years in the Netherlands stratified by age and employment status. From the inception of the cohort in 2010 (T1) onwards, participants completed an online questionnaire on topics such as work characteristics, health, employment status and transitions, work ability, and work productivity. A more detailed description of the STREAM study design has been published previously [19]. At the time of the fifth measurement of the STREAM cohort (2015), a second cohort of participants was recruited, consisting of persons aged 45–49 years and employed persons in the other age groups (50–54, 55–59, 60–64).
For development of the current risk prediction model, data from the first (T1, 2010) and the second (T2, 2011) measurement were used. This cohort comprised 15,118 persons who participated in STREAM of which 82.2% responded at T2 (N = 12,430). Subjects were included in the analyses if they were employed at time of inclusion (including self-employment), but were excluded if they received a fulltime disability pension, or had been on LTSA in the previous year (see definition below).
For external validation, data from the second cohort recruited at the time of the scheduled fifth measurement (T5, 2015) and 1 year follow-up (T6, 2016) were used. This cohort consisted of 6728 persons at T5 and 77.4% responded at T6 (N = 5218).
Definition of long-term sickness absence
LTSA in the year of follow up was defined as ≥28 accumulated working days and was assessed through self-report in the follow-up survey.
Predictor variables of long-term sickness absence
Available predictors
The online questionnaire included a wide variety of variables covering fourteen different domains: demographic characteristics (e.g. age), health and well-being (e.g. perceived health), work-related factors (e.g. working conditions), knowledge and skills (e.g. developmental proactivity), social factors (e.g. work-family balance), financial factors (e.g. household income), motivation to work (e.g. job satisfaction), ability to work (e.g. Work Ability Index (WAI)), opportunity to work (e.g. support by colleagues), productivity at work (e.g. presenteeism), employment status and transitions, mastery (i.e. Pearlin Mastery Scale), job intentions (e.g. to stop working) and coping styles (i.e. Utrecht Coping List). A more detailed description of all (sub) domains and questionnaires included in STREAM has been published previously [19]. Most of the (sub) domains have been shown in previous publications to be important for sustainable employability and cover the different components of the International Classification of Functioning, Disability, and Health (ICF) [1].
Selection of candidate predictors for the model
Variables available at T1 were included as candidate predictors if they had been inquired among working participants, including self-employed participants. This resulted in 141 candidate predictors from 11 different domains. Several steps were undertaken to further reduce the amount of candidate predictors to be included in the full statistical model. First, a literature search was performed to identify previously published prediction models and individual predictors specific for LTSA [11,12,13, 16,17,18, 20]. These predictors were recorded and similar or identical variables in STREAM were identified. Thereafter, an expert consensus group meeting including all authors listed above was organized to reach consensus which variables available in STREAM should be included in the full statistical model. As a guiding principle, it was agreed that (at least) one candidate predictor from each applicable domain should be included in the full statistical model. To inform the expert consensus group, members had insight into all univariate associations between the predictor variables and the outcome as well as results from the literature search (data not shown). If two or more predictors within a domain showed overlap in content or were statistically highly correlated, the most feasible predictor for a clinical setting was selected. For example, the self-rated SF-12 Mental Component Score (MCS) and Center for Epidemiologic Studies Depression scale (CES-D-10) showed great overlap in content, an equally strong association with the outcome and a strong statistical correlation between them. The MCS was eventually chosen because it requires less items to complete (6 vs. 10 items). Finally, it was pre-specified to maintain the variables age, gender and level of education in the model because these predictors were frequently included in previously published models (face validity). This expert meeting resulted in 27 candidate predictors across 11 domains that were included in the full statistical model (description in Additional file 1).
Statistical analysis
Missing data in the development and the validation cohort were imputed using multiple imputation techniques according to the method described by Van Buuren et al. [21] We created m = 30 imputed datasets and used predictive mean matching for imputing continuous predictors, polytomous regression for categorical predictors and logistic regression for dichotomous predictors. All 27 candidate predictors and the outcome LTSA were included in the imputation model.
A logistic regression analysis was performed to estimate regression coefficients of the association between predictors and LTSA during the coming year. First, the ‘full statistical model’ was computed including all 27 candidate predictors in each of the imputed datasets. We then used backward stepwise elimination across all imputed datasets using p > 0.05 as a rule to remove predictors from the model to create a smaller and therefore more practical final prediction model.
The performance of the final prediction model was evaluated using the Area Under the Receiver Operating Characteristic (ROC) Curve (AUC), which reflects how well the model discriminates between those persons with and without LTSA in the coming year. The AUC has a range from 0.5 (i.e. no discriminative ability) to 1.0 (perfect discriminative ability). Calibration of the final prediction model, i.e. the correspondence of the predicted and observed probabilities, was evaluated using calibration plots and the Hosmer-Lemeshow goodness of fit test. To assess the degree of overfitting we used bootstrapping techniques for internal validation with 1000 bootstrap samples in each of the imputed datasets. The estimated shrinkage factor was applied to the regression coefficients to arrive at the final model.
Sensitivity analyses included: 1) complete case analyses (i.e. participants with no missing values on any of the predictor variables or outcome), for both model development and validation, and 2) stratified analyses for employed and self-employed participants. To externally validate the final prediction model, we assessed its predictive performance and calibration in the validation cohort. All analyses were performed with R version 3.4.4. in RStudio 1.1.442 (RStudio Inc., Boston, MA) using the following packages: mice, rms and psfmi.
Results
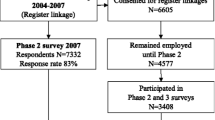
After exclusion of participants currently not working, receiving a fulltime disability pension or with LTSA in the previous year, 11,221 of the 15,118 participants at T1 (74.2%) were included in the development cohort. Similarly, 5604 of the 6728 participants at T5 (83.3%) were included in the validation cohort (see Fig. 1). Participants in the validation cohort were on average younger, less frequently male, and reported a somewhat better physical health (see Table 1). After 1 year of follow-up, 495 participants (5.7%) in the development cohort and 238 participants (5.7%) in the validation cohort reported LTSA.

Flow chart of the development and validation cohort used for the analyses in this study. *More than one reason can apply to one participant. **Long-term sickness absence (LTSA) was defined as ≥28 accumulated work days of sick leave during 1 year of follow-up
Numbers of missing values were low for all candidate predictor variables (less than 3% for each variable, see Additional file 1). Follow-up data for the outcome variable were missing from 2540 of the 11,221 participants (22.6%) in the development cohort and from 1432 of the 5604 participants (25.6%) in the validation cohort. To examine possible selective loss to follow-up, we compared baseline characteristics of participants missing at the follow-up measurement with participants that were not missing. Table 3 in Additional file 1 shows some statistically significant differences which are not clinically relevant. All candidate predictors and the outcome in both the development and validation cohort were imputed using the methods described above.
Development of the prediction model
Eleven of the 27 predictors were retained in the final prediction model: age (continuous), gender (male vs. female), education (low vs. medium; low vs. high), self-rated physical health (SF-12 Physical Component Score (PCS)), quartiles of increasing good health, lowest/poorest quartile is reference), being physically fit (at least 3 days of intensive physical exercise for more than 20 min or more, no vs. yes), amount of physical job load (average of 6 items, lowest three quartiles combined vs. highest quartile), knowledge and skills matching the job (bad/mediocre vs. reasonable/good), self-rated work ability (first item of the WAI, good (score 8–10) vs. average (6/7), good vs. poor (0–5)), the number of sickness absence days in the previous year (none vs. 1–5 days, none vs. 6–10 days, none vs. 11–27 days), being self-employed (no vs. yes) and the number of major life events in the previous year (none vs. 1 event, none vs. 2 or more events). Good self-rated physical health (odds ratio (OR) 0.46 (95%-confidence interval (CI) 0.36–0.59), lowest quartile vs. highest quartile), with poor self-rated work ability (OR 4.70 (95%-CI 3.50–6.30), good vs. poor) and a high number of sickness absence days in the previous year (OR 4.68 (95%-CI 3.77–5.80), none vs. 11–27 days) showed the strongest univariate associations with LTSA in the development cohort (see Table 2). Sensitivity analyses using the complete cases resulted in the same predictor variables retained in the final prediction model and similar univariate associations with LTSA (see Additional file 1, table 4). We found similar results for employed and self-employed persons and therefore decided to develop one prediction model that included both groups and with self-employment as one of the predictor variables (data not shown).
Validation of the prediction model
Internal validation of the prediction model using bootstrapping across m = 30 imputed datasets showed good discriminative ability: pooled median AUC 0.73 (interquartile range (IQR) 0.73–0.74) for predicting LTSA in the coming year. In the validation cohort, discrimination remained similar as observed in the development cohort: pooled median AUC 0.76 (IQR 0.75–0.76). The prediction model showed good calibration (predicted LTSA risks by the model plotted against the observed LTSA frequencies) in the validation cohort (see Fig. 2, H&L test: p = 0.41). No further updating of the prediction model was necessary. Sensitivity analyses using the complete cases in the validation cohort yielded similar results (see Additional file 1, table 4 and Fig. 1).

Calibration plot visualizing the mean predicted LTSA by the model against observed frequencies per decile of predicted risk in the validation cohort. Hosmer-Lemeshow test: p = 0.41
Discussion
We developed and externally validated a model to predict LTSA of 28 or more work days in the coming year in a general working population aged 45–64 years. The following eleven easy to assess predictors were retained in the final multivariable model: older age, female gender, lower level of education, poor self-rated physical health, low weekly physical activity, high self-rated physical job load, knowledge and skills not matching the job, high number of major life events in the previous year, poor self-rated work ability, high number of sickness absence days in the previous year and not being self-employed. The prediction model discriminates well between working persons with and without LTSA and showed good calibration in the external validation cohort.
Previously published prediction models, mostly developed within routinely collected occupational health datasets, found that low physical health, prior (long-term) sickness absences and having mental health issues are important predictors of future LTSA [11, 13, 16, 17]. However, mental health was not a predictor of LTSA in our model, possibly due to some collinearity with other variables in the full multivariable model (e.g. major life events, emotional job demands) or due to the constitution of the cohort which included only older working persons and diverse professional sectors and different contract types. Also, mental health issues may be more important in certain working populations or sectors (e.g. younger persons, white collar workers) but this should be confirmed in future studies updating this prediction model. Our model confirms the role of previous sickness absence and self-reported physical health in predicting future LTSA. It is of note that the level of perceived limitations in physical functioning predict future LTSA better than the health condition possibly underlying these limitations, such as musculoskeletal disease or multi-morbidity, which were eliminated from the full multivariable model that included self-reported physical health and physical job load. Predictors assessing social and financial factors, emotional job demands and autonomy were eliminated from the full multivariable model, although some of these have been shown to be predictors of LTSA in a few previous studies [11, 16, 17]. Possibly the broader professional background but also older age of this cohort might account for these differences. We found that other factors are important for predicting LTSA which were not included in previous studies. Knowledge and skills matching the current job, the number of major life events in the previous year, and not being self-employment proved to be strong predictors of future LTSA. We found no important effect modification by employment status (employee vs. self-employed) and therefore decided to develop one prediction model that included both groups. However, not being self-employed was an important predictor for future LTSA and was therefore included in our final multivariable model.
One of the strengths of the present study is that the STREAM cohort includes a number of new candidate predictors for LTSA not previously addressed in occupational health surveys. Secondly, this large and prospective population-based study provides sufficient statistical power to develop and validate an accurate prediction model. Another strength was that the feasibility of candidate predictors, i.e. how easily can the information be collected by a healthcare professional, was regarded as important to ensure future practical purposes. All methods used for model development and validation in this study are in accordance with the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) statement [24].
One limitation of this study was that loss to follow-up was present in both the development and validation cohort which could have introduced attrition bias. However, the participants that were lost to follow-up did not differ importantly from participants that were not lost to follow-up, we used multiple imputation techniques to deal with the missing values and sensitivity analysis on complete cases yielded similar results. The impact of the social security system or the working culture within a nation on the risk of sickness absence and disability pension has been shown to be different in the Netherlands compared to other European countries [25,26,27]. This prediction model was developed and validated in a cohort of working persons aged 45 to 64 years and therefore potentially not generalizable to younger age-groups because other factors may also be relevant in younger working persons (e.g. family-work balance, job security) [28]. It is possible that this prediction model needs to be adjusted (e.g. adjusting regression coefficients/intercept, adding or removing predictors) for use in other countries and transferability can be an interesting topic for future research.
Practical implications and directions for future research
This prediction model was developed to support healthcare professionals, such as general practitioners, public health workers and occupational specialists, in identifying working persons of 45 years or older at high risk of LTSA in the coming year. After identification, supportive interventions should be considered, ranging from raising awareness or providing simple advice for modifying lifestyle or working conditions, referral to a medical or occupational specialist, or a preventative rehabilitation program in case of a complex problem. Given the low prevalence of LTSA in the working population, and thus the risk for a high false-positive rate, it is essential to have a simple screening tool and low cost interventions for the persons at risk [10]. The impact of the proposed prediction model on clinical decision making and short- and long-term patient outcome and cost-effectiveness should be studied in a (cluster) randomized design. Before such a study is designed some facilitators and barriers to further improve the ease of use of this prediction model should be taken into account [29]. Firstly, automated calculations (e.g. in a web-based format or integration in the electronic patient records) will ease the use for healthcare professionals. Secondly, an optimal cut-off point needs to be determined (i.e. balance between the harm of a false-positive classification and the benefit of a true-positive classification) while also taking into account the availability of resources after referral of high-risk persons. Finally, our model has not only the promise to target persons at risk, but could also serve to identify new and potentially modifiable risk factors at the level of companies or workplaces (e.g. physical fitness) [10, 30].
Conclusions
We developed and validated a prediction model for long-term sickness absence in the coming year that showed good discrimination and calibration in a general population of working persons aged 45–64 years in the Netherlands. Future studies should investigate the transferability of this prediction model to other settings, age-groups and countries as well as the effects on clinical decision making and patient outcome.
Availability of data and materials
The data that support the findings of this study are available from TNO Healthy Living (Leiden, the Netherlands) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of TNO Healthy Living (Leiden, the Netherlands).
Abbreviations
- AUC:
-
Area Under the Curve
- CES-D-10:
-
Center for Epidemiologic Studies Depression scale
- CI:
-
Confidence Interval
- H&L:
-
Hosmer-Lemeshow test
- ICF:
-
International Classification of Functioning, Disability, and Health
- IQR:
-
InterQuartile Range
- MCS:
-
Mental Component Score of the 12-item Short Form Health Survey
- OR:
-
Odds Ratio
- PCS:
-
Physical Component Score of the 12-item Short Form Health Survey
- ROC:
-
Receiver Operating Characteristic
- SD:
-
Standard Deviation
- SF-12:
-
12-item Short Form Health Survey
- STREAM:
-
Study on Transitions in Employment, Ability and Motivation
- LTSA:
-
Long-Term Sickness Absence
- WAI:
-
Work Ability Index
References
World Health Organization. International classification of functioning, disability and health : ICF. World Health Organization. 2001. https://apps.who.int/iris/handle/10665/42407.
Fryers T. Work, identity and health. Clin Pract Epidemiol Ment Health. 2006;2:12.
Katz P, Morris A, Gregorich S, Yazdany J, Eisner M, Yelin E, et al. Valued life activity disability played a significant role in self-rated health among adults with chronic health conditions. J Clin Epidemiol. 2009;62(2):158–66.
OECD. Social Expenditure Update 2019, Public social spending is high in many OECD countries. Paris: OECD Publishing; 2019. https://www.oecd.org/els/soc/OECD2019-Social-Expenditure-Update.pdf.
van Vilsteren M, van Oostrom SH, de Vet HCW, Franche RL, Boot CRL, Anema JR. Workplace interventions to prevent work disability in workers on sick leave. Cochrane Database Syst Rev. 2015;10:1465–858.
Vooijs M, Leensen MCJ, Hoving JL, Wind H, Frings-Dresen MHW. Interventions to enhance work participation of workers with a chronic disease: a systematic review of reviews. Occup Environ Med. 2015;72(11):820–6.
Organization for Economic Cooperation and Development. Sickness, disability and work: breaking the barriers. Paris: OECD Publishing; 2010.
Kant I, Jansen NW, van Amelsvoort LG, van Leusden R, Berkouwer A. Structured early consultation with the occupational physician reduces sickness absence among office workers at high risk for long-term sickness absence: a randomized controlled trial. J Occup Rehabil. 2008;18(1):79–86.
Taimela S, Malmivaara A, Justen S, Laara E, Sintonen H, Tiekso J, et al. The effectiveness of two occupational health intervention programmes in reducing sickness absence among employees at risk. Two randomised controlled trials. Occup Environ Med. 2008;65(4):236–41.
Burdorf A. Prevention strategies for sickness absence: sick individuals or sick populations? Scand J Work Environ Health. 2019;45(2):101–2.
Kant I, Jansen NW, van Amelsvoort LGPM, Swaen GMH, van Leusden R, Berkouwer A. Screening questionnaire Balansmeter proved successful in predicting future long-term sickness absence in office workers; 1878–5921 (Electronic.
Koopmans PC, Roelen CAM, Groothoff JW. Frequent and long-term absence as a risk factor for work disability and job termination among employees in the private sector. Occup Environ Med. 2008;65(7):494–9.
Roelen CA, Bultmann U, van Rhenen W, van der Klink JJL, Twisk JWR, Heymans MW. External validation of two prediction models identifying employees at risk of high sickness absence: cohort study with 1-year follow-up. BMC Public Health. 2013;13:105.
Boot CR, van Drongelen A, Wolbers I, Hlobil H, van der Beek AJ, Smid T. Prediction of long-term and frequent sickness absence using company data. Occup Med (London). 2017;67(3):176–81.
Lexis MA, Jansen NW, van Amelsvoort LGPM, Huibers MJH, Berkouwer A, Tjin A, Ton G, et al. Prediction of long-term sickness absence among employees with depressive complaints. J Occup Rehabil. 2012;22(2):262–9.
Roelen C, Thorsen S, Heymans M, Twisk J, Bultmann U, Bjorner J. Development and validation of a prediction model for long-term sickness absence based on occupational health survey variables. Disabil Rehabil. 2018;40(2):168–75.
Airaksinen J, Jokela M, Virtanen M, Oksanen T, Koskenvuo M, Pentti J, et al. Prediction of long-term absence due to sickness in employees: development and validation of a multifactorial risk score in two cohort studies. Scand J Work Environ Health. 2018;44(3):274–82.
Roelen CA, Bultmann U, Stapelfeldt CM, Jensen C, Heymans MW. Multicentre validation of frequent sickness absence predictions. Occup Med (Lond). 2016;66(1):69–71.
Ybema JF, Geuskens GA, van den Heuvel SG, de Wind A, Leijten FRM, Joling C, et al. Study on transitions in employment, ability and motivation (STREAM): the Design of a Four-year Longitudinal Cohort Study among 15,118 persons aged 45 to 64 years. British J Med Med Res. 2014;4(6):1383–99.
Duijts SF, Kant IJ, Landeweerd JA, Swaen GM. Prediction of sickness absence: development of a screening instrument. Occup Environ Med. 2006;63(8):564–9.
van Buuren S, Groothuis-Oudshoorn K. mice: Multivariate Imputation by Chained Equations in R. J Stat Softw. 2011;1:3.
Hildebrandt VH, Bongers PM, van Dijk FJH, Kemper HCG, Dul J. Dutch Musculoskeletal Questionnaire: description and basic qualities. Ergonomics. 2001;44(12):1038–55.
Ilmarinen J. Work ability--a comprehensive concept for occupational health research and prevention. Scand J Work Environ Health. 2009;35(1):1–5.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ. 2015;350:g7594.
Knies S, Candel MJJM, Boonen A, Bevers SMAA, Ament AJHA, Severens JL. Lost productivity in four European countries among patients with rheumatic disorders: are absenteeism and presenteeism transferable? Pharmacoeconomics. 2012;30(9):795–807.
Howarth A, Quesada J, Mills PR. A global, cross cultural study examining the relationship between employee health risk status and work performance metrics. Ann Occup Environ Med. 2017;29:17.
Knies S, Boonen A, Candel MJJM, Evers SMAA, Severens JL. Compensation mechanisms for lost productivity: a comparison between four European countries. Value Health. 2013;16(5):740–4.
Donders NC, Bos JT, van der Velden K, van der Gulden JW. Age differences in the associations between sick leave and aspects of health, psychosocial workload and family life: a cross-sectional study. BMJ Open. 2012;2(4):e000960.
Kappen TH, van Klei WA, van Wolfswinkel L, Kalkman CJ, Vergouwe Y, Moons KGM. Evaluating the impact of prediction models: lessons learned, challenges, and recommendations. Diagn Prognostic Res. 2018;2:11.
Rose G. Sick individuals and sick populations. Int J Epidemiol. 1985;14(1):32–8.
Acknowledgements
Not applicable.
Funding
The Study on Transitions in Employment, Ability and Motivation (STREAM) was conducted with financial support from the Dutch Ministry of Social Affairs and Employment.
Author information
Authors and Affiliations
Contributions
LB designed the study, carried out the analyses and wrote the paper. MW, RO, GJD and AB designed the study. SK, MW and MH provided input for the analyses. GG contributed substantially to the acquisition of the data and AR contributed substantially to the interpretation of the data. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The Medical Ethical Committee of the VU University Medical Center (Amsterdam, the Netherlands) declared that the Medical Research Involving Human Subjects Act does not apply to the STREAM study, and indicated to have no objection to the execution of this research under the condition all data would be treated confidentially and stored in secured computer systems.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
ONLINE SUPPLEMENTARY INFORMATION. Online Supplementary Table 1, Online Supplementary Table 2, Online Supplementary Table 3, Online Supplementary Table 4, Online Supplementary Figure 1.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
van der Burg, L.R.A., van Kuijk, S.M.J., ter Wee, M.M. et al. Long-term sickness absence in a working population: development and validation of a risk prediction model in a large Dutch prospective cohort. BMC Public Health 20, 699 (2020). https://doi.org/10.1186/s12889-020-08843-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12889-020-08843-x