
Abstract
Background
This study sought to develop and validate a nomogram for prediction of gestational diabetes mellitus (GDM) in an urban, Chinese, antenatal population.
Methods
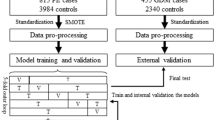
Age, pre-pregnancy body mass index (BMI), fasting plasma glucose (FPG) in the first trimester and diabetes in first degree relatives were incorporated as validated risk factors. A prediction model (nomogram) for GDM was developed using multiple logistic regression analysis, from a retrospective study conducted on 3956 women who underwent their first antenatal visit during 2015 in Shanghai. Performance of the nomogram was assessed through discrimination and calibration. We refined the predicting model with t-distributed stochastic neighbor embedding (t-SNE) to distinguish GDM from non-GDM. The results were validated using bootstrap resampling and a prospective cohort of 6572 women during 2016 at the same institution.
Results
Advanced age, pre-pregnancy BMI, high first-trimester, fasting, plasma glucose, and, a family history of diabetes were positively correlated with the development of GDM. This model had an area under the receiver operating characteristic (ROC) curve of 0.69 [95% CI:0.67–0.72, p < 0.0001]. The calibration curve for probability of GDM showed good consistency between nomogram prediction and actual observation. In the validation cohort, the ROC curve was 0.70 [95% CI: 0.68–0.72, p < 0.0001] and the calibration plot was well calibrated. In exploratory and validation cohorts, the distinct regions of GDM and non-GDM were distinctly separated in the t-SNE, generating transitional boundaries in the image by color difference. Decision curve analysis showed that the model had a positive net benefit at threshold between 0.05 and 0.78.
Conclusions
This study demonstrates the ability of our model to predict the development of GDM in women, during early stage of pregnancy.
Similar content being viewed by others


Background
Gestational diabetes mellitus (GDM) is a glucose intolerance condition that is first detected during pregnancy. Rapid societal transition from traditional foods and lifestyle to an obesogenic environment has exposed the Chinese people to high prevalence of GDM (8.1 to 19.7%) [1,2,3]. GDM caused by varying degrees of insulin resistance to placenta-derived hormones, and, which in turn, increases the maternal adipose tissue [4]. Diagnosis of GDM is usually conducted with an abnormal oral glucose tolerance test (OGTT) at 24-28th week of gestation. Recently, there has been a controversy that skipping glucose on the first prenatal visit, could lead to correct GDM diagnosis [5]. GDM has been reported to increase the risk of adverse fetal outcomes such as fetal macrosomia, and subsequent maternal consequences like metabolic syndrome and cardiovascular morbidity. However, early identification of identifying women at risk of GDM could aid in averting such risks, through early interventions [6, 7]. Various groups have attempted to develop models that can predict an abnormal OGTT occurrence at 24–28 weeks, based on risk factors identified in the first trimester. Methods such as scroring systems, glucose biochemical assays of, and glycosylated haemoglobin (HbA1c) levels have used in different populations with varying degrees of success [8,9,10,11]. Established risk factors of GDM include advanced maternal age, excessive weight gain during pregnancy, overweight or obesity, diabetes in first degree relatives, and giving birth to an infant with a macrosomia, etc [12] However, clinical trials have shown that GDM can be relatively prevented through an intensive lifestyle modification implemented before 20 weeks of gestation [13, 14].
Different populations have different risk profiles for GDM. In Western countries, GDM mainly occurs in obese women (body mass index [BMI] > 30 kg/m2) or women with increasing gestational weight gain [15,16,17]. In Asian countries however, it cuts across the women populations, making it difficult to pinpoint a possible cause. In the present study, our aim was to create a simple and implementable strategy for identifying GDM in pregnant Chinese women living in urban area.
Methods
Study design
This study conducted retrospectively from January 2015 to December 2015, in Shanghai. Dataset was obtained from the International Peace Maternity and Child Care Health Hospital (IPMCH) electronic medical record system. Eligible subjects who underwent first-trimester screening at the IPMCH were recruited in the study. The prospective cohort study was conducted in 2016. Demographic information of the subjects which included; last menstrual period, maternal age, gestational age, pre-pregnancy weight, current height, personal history, educational levels, parity, diabetes in first degree relatives, were obtained through a face-to-face interview questionnaire, at the first prenatal visit (9–13 weeks’ gestation). Pre-pregnancy BMI was calculated by dividing the pre-pregnancy weight (kg) by the height squared (m2) and classified based on the Chinese criteria (underweight, < 18.5 kg/m2; normal weight, < 24.0 kg/m2; overweight, 24.0 kg/m2 ≤ BMI < 28.0 kg/m2; obese, BMI ≥ 28.0 kg/m2) [18]. Venous blood samples were obtained after overnight fasting for analysis of FPG and HbA1c, at the first visit to antenatal clinic.
GDM was diagnosed at 24–28 weeks of gestation according to the American Diabetes Association (ADA) criteria using abnormal plasma glucose values during the 2-h, 75-g OGTT. Abnormal values were defined according to ADA thresholds: a fasting level of 5.1 mmol/l or greater, a 1-h value of 10.0 mmol/l or greater, and, a 2-h value of 8.5 mmol/l or greater.
Exploratory cohort
The hospital-based retrospective cohort study included 4774 women, who underwent their initial prenatal visit (9–13 gestational weeks) at the IPMCH in 2015. Women with pre-existing diabetes (FPG ≥ 7 mmol/L or HbA1c ≥ 6.5% during the first antenatal care or self-reported previous diabetes) (n = 54), multifetal pregnancies (n = 215) and missing data (n = 214 for no FPG tested, n = 178 for no OGTT performed, n = 157 for no records on family history) were excluded from the study. The remaining 3956 eligible women were used in further analysis.
External validation cohort
Eligible participants, who attended prenatal care in the first trimester with single pregnancy, were selected and followed-up until GDM diagnosis in 2016, at the IPMCH. Women with pre-existing diabetes were excluded (n = 292). Therefore, the 6572 OGTT-tested women formed the dependent validation cohort of this study.
Development of an individualized prediction model
Risk factors for GDM include advanced age, high pre-pregnancy BMI, diabetes in first degree relatives and high FPG in the first trimester. In the exploratory cohort, multiple logistic regression analysis was used to estimate the coefficients of each risk factor and mutually-adjusted odds ratio (OR) assigned for GDM. The continuous predictor variables such as age, BMI and FPG were found to be linear with log odds of the outcomes. To provide clinicians with a quantitative tool to visually predict individual probability of GDM, we developed a nomogram based on multivariable logistic analysis in the exploratory cohort. To further quantify the accuracy of the prediction models in discriminating subjects with GDM from subjects without, a receiver operating characteristic (ROC) curve was plotted, and the area under the curve (AUC) was calculated. Calibration was evaluated with the calibration curve. Ideally, the closer the dots are to the 45 degree line the better the model. Internal validation was initially analyzed by bootstrapping with 1000 random samples drawn with replacement. The ROC curve and calibration plot for recalibrated train model were extended to internal and external validation datasets. Decision curve analysis was used to determine the clinical usefulness of the nomogram by quantifying the net benefits at different threshold probabilities in the validation datasets. Spatially mapped t-distributed stochastic neighbor embedding (t-SNE) was used to distinguish non-GDM from GDM, i.e. the ability to screen for a true negative group.
Statistical analysis
Analyses were performed using SPSS version 23.0 (SPSS, Inc., Chicago, IL) and R statistical software version 3.6.1 (packages rms, rmda, and Rtsne). Continuous variables were presented as the means with standard deviations, while categorical data were expressed as counts and percentages. Levene’s test was used to determine the homogeneity of the variances, and, Kolmogorov-Smirnov was used to assess the normal distribution. Summary statistics between both groups were compared using either unpaired Student’s t-test or Mann-Whitney tests for continuous data, and chi-squared tests for categorical data. Crude and mutually adjusted OR with 95% confidence interval (CI) for associations between baseline risk factors and GDM were estimated using the logistical regression model. Nomogram and calibration curve were performed with the “rms” package. The package “rmda” provided tools for evaluating the value of using a risk prediction instrument in deciding treatment or intervention. The “Rtsne” package was used to assess the screening ability based on construction of a low dimensional embedding of high-dimensional data, distances or similarities. A p-value of < 0.05 was considered to indicate statistical significance.
Results
Baseline characteristics for two cohorts
In the retrospective cohort of 3956 women, 662 developed GDM (16.7% incidence). The median ± SD pregnancy week for the first prenatal visit was 10.2 ± 3.5. Their mean age was 30.61 years, mean pre-pregnancy BMI (21.45 kg/m2), median FPG value (4.45 mmol/L), and presence of diabetes in first degree relatives (27.4%). In the external validation cohort of 6572 women, 739 developed GDM (11.2% incidence). The median ± SD pregnancy week for the first prenatal visit was 10.4 ± 3.3. Their mean age was 30.84 years, mean pre-pregnancy BMI was (21.20 kg/m2), median FPG (4.40 mmol/L), and presence of diabetes in first degree relatives (16.5%). Comparison of baseline characteristics between GDM and non-GDM in the two cohorts is shown in Table 1. In both cohorts, women who developed GDM had a relatively higher prevalence of family history of diabetes, advanced age, increased pre-pregnancy BMI, FPG, and multipara. However, education levels of the two groups was similar (p > 0.05), as was fetal sex. Significant differences were observed in the clinical characteristics between the exploratory dataset and the validation dataset (p = 0.04 for age, 0.24 for BMI, 0.001 for family history and 0.03 for FPG). However, the key difference between the two cohorts was in the GDM incidence (16.7% v 11.2%, p < 0.001). Even though many factors could contribute to this difference in incidence, we attributed the scenario to an antenatal education program that teaching pregnant women to manage their diets and weight during pregnancy.
Logistic regression results
Table 2 shows the incidence of risk factors for GDM with OR from a multiple logistic regression model in the exploratory cohort (n = 3956). Increasing age, pre-pregnancy BMI, FPG and a family history of diabetes were confirmed as independent risks for GDM.
The projected GDM risk was estimated with the equation:
Development of GDM-predicting nomogram
A nomogram incorporating age, pre-pregnancy BMI, FPG in the first trimester and a family history of diabetes was developed and presented as shown in Fig. 1.

Nomogram to estimate the risk of GDM. Each predictor is assigned a score on each axis. Compute the sum of points for all predictors and denote this value as the total points. The corresponding “risk of GDM” of “total point” was converted to a predicted probability of GDM
Discrimination results
We depicted ROC curves with 3956 subjects from the exploratory cohort. The AUC for the prediction nomogram was 0.69 [95% CI:0.67–0.72, p < 0.0001], while the corrected c-index was 0.69 in the internal bootstrap validation. Applying the exploratory set estimates to the validation set yielded a similar AUC of 0.70 [95% CI: 0.68–0.72, p < 0.0001].
Calibration results
The probability of GDM occurrence in the exploratory and validation cohorts was accurately predicted form the calibration curve (Fig. 2a-c).

Calibration results. Nomogram-predicted probability of GDM is plotted on the x-axis; actual probability of GDM is plotted on the y-axis. The ideal calibration line means an intercept of 0 and a slope of 1 for the calibration plot. Exploratory cohort (a); Internal validation cohort (b); External validation cohort (c)
Clinical use
For predicted probability thresholds between 0.05 and 0.78, our model showed a positive net benefit, without increasing the number of false positives (Fig. 3).

Decision curve analysis for gestational diabetes mellitus. Solid black line = net benefit when no one is at risk for gestational diabetes mellitus (GDM); grey line = net benefit when all are at risk for GDM. The y-axis measures the net benefit. The red line represents the nomogram. The decision curve showed that if the threshold probability is between 0.05–0.78, using the nomogram in the current study to predict GDM adds more benefit than the intervention-all-patients scheme or the intervention-none scheme
Screening ability
To assess the suitability of linking the structure revealed by t-SNE to clinical outcome, and thereby discriminating subpopulations, we converted the t-SNE space to a*b color space. In the resulting t-SNE image obtained by density-based analysis, each pixel was colored according to its property (Orange for GDM and blue for non-GDM). In both cohorts (Fig. 4a-b), the distinct regions of GDM and non-GDM outlined by t-SNE were separated, hence generating transitional boundaries that could be highlighted by two different colors. This demonstrated the ability to distinguish GDM from non-GDM women.

Screening ability of this model. Orange color represented for GDM women, blue point represented for non-GDM women. t-SNE result showed the majority of non-GDM women were separated from GDM women by an obvious boundary in the retrospective cohort (a). t-SNE showed the similar result in the prospective cohort (b). GDM: gestational diabetes mellitus
Discussion
In this study, we developed and validated a diagnostic nomogram for the prediction of GDM. The nomogram incorporated four risk factors including age, pre-pregnancy BMI, FPG in the first trimester and history of diabetes in first-degree relatives. Earlier in pregnancy, the nomogram successfully stratified the women according to their risk of developing GDM. Its prediction was supported by the AUC (0.69 and 0.70 for the exploratory and validation cohorts, respectively) and the calibration curve. Incorporation of the easily accessible risk factors into our nomogram enhanced the process individualized prediction of GDM.
Heterogeneity of physiological processes underlying hyperglycemia has been reported among women with GDM [19]. Therefore, an integrated approach that combines multiple risk indicators, could accurately predict the women who should be screened further for GDM. FPG widely used as a screening test for GDM through detection of preexisting diabetes (FPG ≥ 7 mmol/L) in the first trimester. High pre-pregnancy BMI or normal upper range of FPG was associated with insulin sensitivity defect, condition which could be involved in the onset of GDM [5, 19]. In China, it is traditional for women to increase their calorie consumption and sedentary habit from the onset of pregnancy though this is clearly responsible for increasing diabetogenic burden in high risk women [20]. It should be emphasized that our study was conducted at a time when early identification and targeted interventions are available for those women .
Various first-trimester prediction models for GDM have been proposed [21,22,23]. However, these models are not commonly used in routine clinical care. First, this could be partly attributed to poor external validation of these models since clinical use was not considered during their development. Secondly, indicators, such as high molecular weight adiponectin, omentin-1 and interleukin-6, yield a high AUC, but also increase the psychological and economic burden [24]. We generated a decision curve analysis to quantify the clinical usefulness, and a key finding was that a single probability threshold could be used both to categorize patients as positive or negative, and to weight false positive and false negative classifications [25]. In our model, the use of a 0.05–0.78 threshold to identify individuals with high risk of GDM always had a positive net benefit.
HbA1c showed a high sensitivity but insufficient power to diagnose GDM [26]. Sumaiya Adam et al. [22] reported that adding a HbA1c did not significantly improve the predictive value of prediction model for GDM. In addition, HbA1c levels vary with gestational hemodilution, hemoglobin disease, and/or anemia. Therefore, we did not consider it as risk factor, in our model.
To assess its predictive performance, we validated our model both internally and externally. Its main advantage is the ability to integrate information that is routinely obtained at the first antenatal visit into a graphical nomogram. Heterogeneity was observed between the demographic characteristics of the train set and external validation set. Therefore, heterogeneity could be used to reflect and evaluate the applicability of the model in external population, and improve the overall application value of the model. Inclusion of both first and second degree relatives with diabetes in the retrospective cohort could have over-estimated the contribution of family history with some measurement bias. Hence, in the prospective cohort we only considered the first degree relatives with diabetes.
This study had the following limitations. First, our study was based on the hospital cohort, and the homogeneity of the cohort increased the internal validity while wakening the confidence of representation of the Chinese population. A prospective, multicenter, trial could therefore be required to test our prediction model. Second, we did not incorporate excessive gestational weight gain though it was a key factor in GDM development. Third, the sample size of the retrospective cohort was smaller than the prospective cohort, due to some women returning to their home towns to deliver, while others refused to participate in the study in 2015. However, the final sample size (n = 3956) was sufficient for establishing the prediction model, indicating that these attritional features did not result in a type I error. Finally, the AUC value in our model did not show high prediction accuracy. However, since AUC metric solely focuses on the predictive accuracy. It cannot be used to identify a preferable model. A model with a greater specificity but slightly lower sensitivity would have a higher AUC, but would be a poorer choice for clinical use. We therefore further used Decision-analytic methods, which incorporated our results and theory to determine the worthiness of a model or alternatives.
Conclusions
In conclusion, we have developed a simple nomogram for pregnant Chinese women that can be used to estimate the probability of developing GDM at the first antenatal visit. This prediction model could identify women at risk for GDM early in pregnancy, allowing for timely intervention to improve maternal outcome. However, further studies should be carried out in other cities to improve the prediction accuracy of GDM risk in the Chinese, or even Asian populations.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- ADA:
-
American Diabetes Association
- AUC:
-
Area under the curve
- BMI:
-
Body mass index
- CI:
-
Confidence interval
- FPG:
-
Fasting plasma glucose
- GDM:
-
Gestational of diabetes
- HbA1c:
-
Glycated hemoglobin
- IPMCH:
-
International Peace Maternity and Child Care Health Hospital
- OGTT:
-
Oral glucose tolerance test
- OR:
-
Odds ratio
- ROC:
-
Receiver operating characteristic
- t-SNE:
-
t-distributed stochastic neighbor embedding
References
Zhu WW, Yang HX, Wang C, et al. High prevalence of gestational diabetes mellitus in Beijing: effect of maternal birth weight and other risk factors. Chin Med J. 2017;130:1019–25.
Chan JC, Zhang Y, Ning G. Diabetes in China: a societal solution for a personal challenge. Lancet Diabetes Endocrinol. 2014;2:969–79.
Leng J, Shao P, Zhang C, et al. Prevalence of gestational diabetes mellitus and its risk factors in Chinese pregnant women: a prospective population-based study in Tianjin, China. PLoS One. 2015;10:e0121029.
McCabe CF, Perng W. Metabolomics of diabetes in pregnancy. Curr Diab Rep. 2017;17:12.
Cosson E, Carbillon L, Valensi P. High fasting plasma glucose during early pregnancy: a review about early gestational diabetes mellitus. J Diabetes Res. 2017;2017:8921712.
Burlina S, Dalfra MG, Chilelli NC, Lapolla A. Gestational diabetes mellitus and future cardiovascular risk: an update. Int J Endocrinol. 2016;2016:2070926.
Mohammadbeigi A, Farhadifar F, Soufi Zadeh N, et al. Fetal macrosomia: risk factors, maternal, and perinatal outcome. Ann Med Health Sci Res. 2013;3:546–50.
Sweeting AN, Appelblom H, Ross GP, et al. First trimester prediction of gestational diabetes mellitus: a clinical model based on maternal demographic parameters. Diabetes Res Clin Pract. 2017;127:44–50.
Theriault S, Giguere Y, Masse J, Girouard J, Forest J-C. Early prediction of gestational diabetes: a practical model combining clinical and biochemical markers. Clin Chem Lab Med. 2016;54:509–18.
Eleftheriades M, Papastefanou I, Lambrinoudaki I, et al. Elevated placental growth factor concentrations at 11–14 weeks of gestation to predict gestational diabetes mellitus. Metabolism. 2014;63:1419–25.
van Leeuwen M, Opmeer BC, Zweers EJK, et al. External validation of a clinical scoring system for the risk of gestational diabetes mellitus. Diabetes Res Clin Pract. 2009;85:96–101.
Kjos SL, Buchanan TA. Current concepts: gestational diabetes mellitus. N Engl J Med. 1999;341:1749–56.
Shen H, Liu X, Chen Y, He B, Cheng W. Associations of lipid levels during gestation with hypertensive disorders of pregnancy and gestational diabetes mellitus: a prospective longitudinal cohort study. BMJ Open. 2016;6:e013509.
Leng J, Liu G, Zhang C, et al. Physical activity, sedentary behaviors and risk of gestational diabetes mellitus: a population-based cross-sectional study in Tianjin, China. Eur J Endocrinol. 2016;174:763–73.
Hedderson MM, Gunderson EP, Ferrara A. Gestational weight gain and risk of gestational diabetes mellitus. Obstet Gynecol. 2010;115:597–604.
Catalano PM, McIntyre HD, Cruickshank JK, et al. The hyperglycemia and adverse pregnancy outcome study associations of GDM and obesity with pregnancy outcomes. Diabetes Care. 2012;35:780–6.
Huvinen E, Eriksson JG, Stach-Lempinen B, Tiitinen A, Koivusalo SB. Heterogeneity of gestational diabetes (GDM) and challenges in developing a GDM risk score. Acta Diabetol. 2018;55:1251–9.
Wang Y, Mi J, Shan XY, Wang QJ, Ge KY. Is China facing an obesity epidemic and the consequences? The trends in obesity and chronic disease in China. Int J Obes. 2007;31:177–88.
Powe CE, Allard C, Battista MC, et al. Heterogeneous contribution of insulin sensitivity and secretion defects to gestational diabetes mellitus. Diabetes Care. 2016;39:1052–5.
Ma RCW, Tsoi KY, Tam WH, Wong CKC. Developmental origins of type 2 diabetes: a perspective from China. Eur J Clin Nutr. 2017;71:870–80.
van Leeuwen M, Opmeer BC, Zweers EJ, et al. Estimating the risk of gestational diabetes mellitus: a clinical prediction model based on patient characteristics and medical history. BJOG. 2010;117:69–75.
Adam S, Rheeder P. Selective screening strategies for gestational diabetes: a prospective cohort observational study. J Diabetes Res. 2017;2017:2849346.
Schaefer KK, Xiao W, Chen Q, et al. Prediction of gestational diabetes mellitus in the born in Guangzhou cohort study, China. Int J Gynaecol Obstet. 2018;143:164–71.
Abell SK, Shorakae S, Boyle JA, et al. Role of serum biomarkers to optimise a validated clinical risk prediction tool for gestational diabetes. Aust N Z J Obstet Gynaecol. 2019;59:251–7.
Peirce CS. The numerical measure of the success of predictions. Science. 1884;4:453–4.
Benaiges D, Flores-Le Roux JA, Marcelo I, et al. Is first-trimester HbA1c useful in the diagnosis of gestational diabetes? Diabetes Res Clin Pract. 2017;133:85–91.
Acknowledgments
The authors thank the staff at the International Peace Maternity and Child Health Hospital for their technic supports. The contribution of the children and parents is highly appreciated.
Funding
This work was supported by the Shanghai Municipal Commissions of Health and Family Planning Program [grant number 15GWZK0701]. The funding body played no role in study design, data collection, analysis or interpretation and writing of the manuscript.
Author information
Authors and Affiliations
Contributions
All the authors contributed to the work and approved the final version of this manuscript. This study was designed by JXF, FG and SY. CZ and FG performed the statistical analysis and wrote the manuscript. YZ and XY compiled data. JXF reviewed and edited manuscript. All authors read and approved the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
The study was approved by the Ethics Committee of the International Peace Maternity and Child Health Hospital, School of Medicine, Shanghai Jiaotong University (no. GKLW2012–49). The data analysis procedures conformed to the guidelines in the Declaration of Helsinki. All participants provided written informed consent.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Guo, F., Yang, S., Zhang, Y. et al. Nomogram for prediction of gestational diabetes mellitus in urban, Chinese, pregnant women. BMC Pregnancy Childbirth 20, 43 (2020). https://doi.org/10.1186/s12884-019-2703-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12884-019-2703-y