
Abstract
Background
Hyperkalemia is a common complication of chronic kidney disease (CKD). Hyperkalemia is associated with mortality, CKD progression, hospitalization, and high healthcare costs in patients with CKD. We developed a machine learning model to predict hyperkalemia in patients with advanced CKD at an outpatient clinic.
Methods
This retrospective study included 1,965 advanced CKD patients between January 1, 2010, and December 31, 2020 in Taiwan. We randomly divided all patients into the training (75%) and testing (25%) datasets. The primary outcome was to predict hyperkalemia (K+ > 5.5 mEq/L) in the next clinic vist. Two nephrologists were enrolled in a human-machine competition. The area under the receiver operating characteristic curves (AUCs), sensitivity, specificity, and accuracy were used to evaluate the performance of XGBoost and conventional logistic regression models with that of these physicians.
Results
In a human-machine competition of hyperkalemia prediction, the AUC, PPV, and accuracy of the XGBoost model were 0.867 (95% confidence interval: 0.840–0.894), 0.700, and 0.933, which was significantly better than that of our clinicians. There were four variables that were chosen as high-ranking variables in XGBoost and logistic regression models, including hemoglobin, the serum potassium level in the previous visit, angiotensin receptor blocker use, and calcium polystyrene sulfonate use.
Conclusions
The XGBoost model provided better predictive performance for hyperkalemia than physicians at the outpatient clinic.
Similar content being viewed by others

Introduction
Hyperkalemia is a common complication of chronic kidney disease (CKD). The prevalence rate of hyperkalemia is approximately 9% in CKD patients and one-third of non-dialysis CKD patients under nephrology care [1, 2]. The risk factors for hyperkalemia in CKD patients are congestive heart failure, diabetes, old age, a high potassium diet, and medications like renin-angiotensin-aldosterone system inhibitors, beta-blockers, and others [3,4,5]. Hyperkalemia is associated with mortality, CKD progression, hospitalization, and high healthcare costs [1, 3].
There were some studies about predicting hyperkalemia. A claim study conducted in the U.S. successfully predicted hyperkalemia in CKD patients using logistic regression [6]. Several deep-learning models were performed well to predict hyperkalemia using electrocardiography in CKD patients and at the emergency department [7, 8].
Recently, machine learning have been developed to handle complex and high-dimensional data and increasingly applied in clinical medicine. The eXtreme Gradient Boost (XGBoost) algorithm developed by Chen et al. [9], one of the state-of-the-art gradient boosting machine learning algorithms, performed excellently in a number of medical problems [10,11,12]. In this study, we aimed to develop a machine learning model using the XGBoost algorithm and then assess the model performance in predicting hyperkalemia in patients with advanced CKD at the outpatient clinic in comparison to conventional logistic regression models and two nephrologists.
Materials and methods
Data source
This retrospective study used data retrieved from the pre-end-stage renal disease (pre-ESRD) program every 3 months that was initiated by Taiwan’s National Health Insurance Administration (NHIA) and performed in most of the hospitals in Taiwan to provide high-quality care for patients with CKD of stages 3b, 4, and 5 [13]. From January 1, 2010, to December 31, 2020, we used data collected in a single medical center in central Taiwan. This study was approved by the Institutional Review Board of Changhua Christian Hospital (IRB number-210423). All the data were measured in the laboratory that had been accredited by the College of American Pathologists’ Laboratory Accreditation Program.
Study population
Eligible patients were enrolled to have had at least two outpatient visits in three months between January 1, 2010, and December 31, 2020. We excluded patients who were aged ≤ 20 years and whose estimated glomerular filtration rates (eGFRs) were ≥ 30 mL/min/1.73 m2 because advanced CKD patients with hyperkalemia had higher medical expenses and mortality rates [14, 15]. We also excluded patients who did not have serum potassium values in the t-th clinic visit or the t + 1-th clinic visit. The t-th clinic visit refers to the time when the lab tests were conducted for the development of the prediction models. We randomly divided the study participants into the training (~ 75%) and testing (~ 25%) datasets by patient identification to make sure that the data were totally different between the training and testing datasets.
Model development
Predictors
Figure 1 shows how to generate parameters used for model development and prediction. The variables for our model consisted of demographics, laboratory tests, medical history based on ICD-9 and ICD-10 (Supplementary Table S1), and medications (Supplementary Table S2). For laboratory tests, missing values were imputed separately for the training and testing sets. We imputed the missing values using the K-Nearest Neighbors approach [16].

Model development and prediction of a single visit
The primary outcome of our study was to predict whether or not hyperkalemia (K > 5.5 mEq/L) would occur during the t + 1-th visit.
Prediction machine learning algorithms
We built a binary prediction model using XGBoost and used a grid search with tenfold cross-validation to find the best hyperparameters. XGBoost is one of the ensemble decision-tree-based learning algorithms based on a gradient descent-boosting process. The core concept of gradient boosting decision tree algorithm is that it iteratively generates many weak classifiers and combines them to obtain a strong classifier, which is implemented by each new decision-tree learning from the errors of the previous decision-tree sequentially [17]. Other advantages of XGBoost are tuning hyperparameters, controlling overfitting, and parallel computation to reduce processing time [9, 12].
Human-machine competition
Two nephrologists participated in our study. They predicted whether or not hyperkalemia would occur in the t + 1-th clinic visit using the data of the t-th clinic visit. We assessed their performance using the testing dataset and compared their results with those of XGBoost and the logistic regression model.
Statistical analyses
We compared baseline characteristics between training and testing datasets. Categorical variables were presented as proportions and continuous variables were presented as mean values with standard deviations. Numerical variables of clinical characteristics were compared using Student’s t-test. The chi-squared test was used to compare differences in categorical variables.
We conducted multivariable logistic regression analyses as a reference model. The overall performance of the models in the testing dataset was assessed by calculating the area under the receiver operating characteristic curve (AUC) and the associated 95% confidence interval (CI). The AUC values were compared using the DeLong test. The net benefit of the XGBoost model was assessed using the decision curve analysis (DCA) and then further using clinical impact curves (CIC) to assess the clinical practicability [18, 19]. Sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and accuracy were calculated to evaluate the model performance. Finally, we used the SHAP (SHapley Additive exPlanations) framework to evaluate the impact of features in our model [20].
Machine learning algorithms and statistical analyses were performed using Python version 3.9.12, scikit-learn version 1.0.2, and R version 4.2.0.
Results
General demographics
The 1,526 patients (6,949 visit numbers) in the training dataset and 439 patients (2,054 visit numbers) in the testing dataset met our inclusion criteria (Fig. 2). Baseline patient characteristics are presented in Table 1. The mean patient age was 69.39 years and 49.2% were female. Patients in the testing dataset were older and more likely to be female, have diabetes, cardiovascular disease, cancer, hypertension, hyperlipidemia, and dementia. Patients in the testing dataset had a higher proportion of prescriptions for angiotensin receptor blocker and lower proportion of calcium polystyrene sulfonate use. The prevalence of hyperkalemia (K > 5.5 mEq/L) during the t + 1-th visit was 6.6% in the training dataset and 6.8% in the testing dataset.

Participant flow diagram. Abbreviations: OPD, outpatient department
Development of the XGBoost Model and comparison of human-machine competition
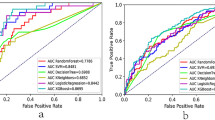
The detailed results of the human-machine competition are shown in Table 2 and Fig. 3. In detecting hyperkalemia, the XGBoost model had the highest AUC, PPV, and accuracy in the human-machine competition. In terms of the AUC, the performance of the XGBoost model was significantly better than that of the two clinicians (0.867, 95% CI 0.840–0.894, vs. 0.745, 95% CI 0.704–0.789, and 0.741, 95% CI 0.700–0.783, respectively); however, its performance did not differ significantly from that of logistic regression. The net benefit for the XGBoost and logistic regression models was better than that of the two clinicians based on DCA (Fig. 4a). Figure 4b shows the XGBoost model also had a better clinical net benefit within a wide range of threshold probabilities and impacted patient outcomes.

Area under operating characteristic (ROC) curves for XGBoost, logistic regression models, and nephrologists in the testing dataset
Important features of the XGBoost model and results of multivariable logistic regression
As shown in Fig. 5, the top 5 features of the XGBoost model were the potassium level during the t-th visit, blood urea nitrogen, calcium polystyrene sulfonate, angiotensin receptor blocker use, and hemoglobin, in that order. Supplementary Table 3 shows the results of univariate and multivariate logistic regression analysis. In the multivariate logistic regression analysis, the top 5 significant variables by P value for hyperkalemia were potassium level during the t-th visit (OR, 6.96; 95% CI, 6.05–8.02; P < 0.001), ARB (OR, 1.40; 95% CI, 1.19–1.64; P < 0.001), hemoglobin (odds ratio [OR], 0.92; 95% [CI], 0.87–0.97; P = 0.001), CHF (OR, 0.8; 95% CI, 0.68–0.95; P = 0.008), and calcium polystyrene sulfonate (OR, 1.29; 95% CI, 1.06–1.56; P = 0.009) (Table 3).

A. Decision curve analysis (DCA) of the XGBoost, logistic regression (LR) models and nephrologists. XGBoost and LR models demonstrated a larger net benefit compared to nephrologists for the threshold probabilities. B. Clinical impact curve (CIC) of the XGBoost model

Top 5 important features of the XGBoost model by SHAP value
Discussion
In the present study, we developed the XGBoost model to predict hyperkalemia in advanced CKD patients using data from an outpatient clinic. The XGBoost model demonstrated better performance in comparison with two nephrologists; however, the difference in AUC between XGBoost and the logistic models was not statistically significant.
The prevalence and incidence rates of ESRD in Taiwan are the highest in the world [21, 22]. Taiwan’s NHIA developed the pre-ESRD program to reduce the magnitude of the problem of CKD in 2006; as such, nephrologists may often need to attend to more than 20 CKD patients at a clinic. Clinical decision-making tools could help physicians make better decisions in properly caring for patients in Taiwan, especially when they face many CKD patients at a clinic. Hyperkalemia is a frequent complication of CKD due to its limited ability to increase potassium excretion [4, 23]. Hyperkalemia is associated with not only muscle weakness and fatal arrhythmia but also high insurance costs in CKD patients [1, 24]. Thus, we investigated whether the XGBoost model improved hyperkalemia prediction for CKD patients. The XGBoost model performed best in human-machine competition using evaluation metrics such as the AUC, accuracy, NPV, and PPV in this study. In addition, the XGBoost model had a higher bet benefit than the logistic regression model, which would lead to the better clinical outcomes [25].
XGBoost is an efficient and flexible gradient boosting machine learning algorithm and make prediction well in clinical problems. XGBoost achieved a high accuracy in predicting COVID-19 severity in US, excellently predicted kidney outcome in immunoglobulin A nephropathy, and outperformed 2-year dementia risk [11, 26, 27]. In this study, The XGBoost model performed best. However, the differences in evaluation metrics between the XGBoost and logistic regression model were not statistically significant. Evidence has revealed that logistic regression was not inferior to machine learning for clinical prediction models [28]. The possible reason why machine learning does not perform better in clinical problems is the fact that clinical predictions have a poor signal-to-noise ratio, low-dimensional data, and a small sample size [28, 29].
Machine learning and logistic regression usually use different variables with divergent ranks to develop prediction models [29]. In addition, machine learning models are regarded as black-box models so that physicians may doubt the results [30]. In this study, we attempted to explore if the XGBoost could use reasonable variables to develop a prediction model. We used SHAP to visualize the five most important features in the XGBoost model and compared the results to that of the logistic regression model. In both models, there were four variables that were chosen as high-ranking variables, including hemoglobin, the serum potassium value during the t-th visit, angiotensin receptor blocker use, and calcium polystyrene sulfonate use. A high potassium value during the t-th visit and calcium polystyrene sulfonate use implies that the baseline potassium level of patients is high. Angiotensin receptor blocker use induced hyperkalemia due to the decline in the serum aldosterone level and decrease in the renal blood flow [31, 32]. Lower hemoglobin levels were associated with hyperkalemia, and possible risk factors include iron-deficiency anemia, sickle cell anemia [33], and gastrointestinal bleeding [34]. From the above results, we believe that the XGBoost algorithm developed a reliable prediction model using the variables that have clinical significance in this study.
We may develop a clinical decision support system which has reasonable clinical performance to help physicians identify high-risk patients with hyperkalemia. The system would alarm the CKD team that patients are in danger of hyperkalemia so that they can prescribe medications to prevent hyperkalemia and inform patients of going back to the clinic for follow-up earlier under the care of multidisciplinary teams. Nevertheless, there are some limitations to the present study. First, this is a single-center study and it may not be able to apply to other hospitals directly (absent external validation). Second, this dataset did not include vital signs, blood gas data, oral sodium bicarbonate, body weights, other nutritional parameters, lifestyles, and physical statuses, all of which may affect the potassium level. Third, the data of the pre-ESRD program in Taiwan were collected every 3 months. We are not able to retrieve the data if patients have data between 2 clinic visits within 3 months. Finally, there were missing values in this dataset; thus, a prospective study in which complete data can be collected is recommended to verify our findings.
In conclusion, the XGBoost model had a better predictive performance for hyperkalemia than physicians in an outpatient clinic. The results indicate that this model may be a decision-making tool to help physicians take better care of patients. Further prospective studies are needed to validate our findings.
Data availability
The dataset supporting the conclusions of this article is included within the article.
Abbreviations
- CHF:
-
congestive heart failure
- CAD:
-
coronary artery disease
- CVA:
-
Cerebrovascular accident
- ACEi:
-
Angiotensin-converting enzyme inhibitors
- ARB:
-
Angiotensin receptor blocker
- CCB:
-
Calcium channel blocker
- ESA:
-
Erythropoiesis stimulating agent
- CPS:
-
Calcium polystyrene sulfonate
- NSAID:
-
Nonsteroidal anti-inflammatory drug
- CKD:
-
Chronic kidney disease
- LR:
-
Logistic regression
- PPV:
-
Positive predicted value
- NPV:
-
Negative predicted value
- ACC:
-
Accuracy
- BUN:
-
blood urea nitrogen
- CIC:
-
Clinical impact curve
- DCA:
-
Decision curve analysis
References
Mu F, Betts KA, Woolley JM, Dua A, Wang Y, Zhong J, Wu EQ. Prevalence and economic burden of hyperkalemia in the United States Medicare population. Curr Med Res Opin. 2020;36(8):1333–41.
Borrelli S, De Nicola L, Minutolo R, Conte G, Chiodini P, Cupisti A, Santoro D, Calabrese V, Giannese D, Garofalo C. Current management of hyperkalemia in non-dialysis CKD: longitudinal study of patients receiving stable nephrology care. Nutrients. 2021;13(3):942.
Palmer BF, Carrero JJ, Clegg DJ, Colbert GB, Emmett M, Fishbane S, Hain DJ, Lerma E, Onuigbo M, Rastogi A. Clinical management of hyperkalemia. In: Mayo Clinic Proceedings: 2021: Elsevier; 2021: 744–762.
Sarafidis PA, Blacklock R, Wood E, Rumjon A, Simmonds S, Fletcher-Rogers J, Ariyanayagam R, Al-Yassin A, Sharpe C, Vinen K. Prevalence and factors associated with hyperkalemia in predialysis patients followed in a low-clearance clinic. Clin J Am Soc Nephrol. 2012;7(8):1234–41.
Clase CM, Carrero J-J, Ellison DH, Grams ME, Hemmelgarn BR, Jardine MJ, Kovesdy CP, Kline GA, Lindner G, Obrador GT. Potassium homeostasis and management of dyskalemia in kidney diseases: conclusions from a kidney disease: improving global outcomes (KDIGO) Controversies Conference. Kidney Int. 2020;97(1):42–61.
Sharma A, Alvarez PJ, Woods SD, Dai D. A model to Predict Risk of Hyperkalemia in patients with chronic kidney Disease using a large administrative claims database. ClinicoEconomics and Outcomes Research: CEOR. 2020;12:657.
Lin CS, Lin C, Fang WH, Hsu CJ, Chen SJ, Huang KH, Lin WS, Tsai CS, Kuo CC, Chau T, et al. A deep-learning algorithm (ECG12Net) for detecting hypokalemia and hyperkalemia by Electrocardiography: Algorithm Development. JMIR Med Inform. 2020;8(3):e15931.
Galloway CD, Valys AV, Shreibati JB, Treiman DL, Petterson FL, Gundotra VP, Albert DE, Attia ZI, Carter RE, Asirvatham SJ. Development and validation of a deep-learning model to screen for hyperkalemia from the electrocardiogram. JAMA Cardiol. 2019;4(5):428–36.
Chen T, Guestrin C. Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining: 2016; 2016: 785–794.
Deng YH, Luo XQ, Yan P, Zhang NY, Liu Y, Duan SB. Outcome prediction for acute kidney injury among hospitalized children via eXtreme Gradient boosting algorithm. Sci Rep. 2022;12(1):1–11.
Chen T, Li X, Li Y, Xia E, Qin Y, Liang S, Xu F, Liang D, Zeng C, Liu Z. Prediction and risk stratification of kidney outcomes in IgA nephropathy. Am J Kidney Dis. 2019;74(3):300–9.
Chang W, Liu Y, Xiao Y, Yuan X, Xu X, Zhang S, Zhou S. A machine-learning-based prediction method for hypertension outcomes based on medical data. Diagnostics. 2019;9(4):178.
Hsieh HM, Lin MY, Chiu YW, Wu PH, Cheng LJ, Jian FS, Hsu CC, Hwang SJ. Economic evaluation of a pre-ESRD pay-for-performance programme in advanced chronic kidney disease patients. Nephrol Dial Transplant. 2017;32(7):1184–94.
Einhorn LM, Zhan M, Walker LD, Moen MF, Seliger SL, Weir MR, Fink JC. The frequency of hyperkalemia and its significance in chronic kidney disease. Arch Intern Med. 2009;169(12):1156–62.
Kashihara N, Kohsaka S, Kanda E, Okami S, Yajima T. Hyperkalemia in real-world patients under continuous Medical Care in Japan. Kidney Int Rep. 2019;4(9):1248–60.
Stevens JR, Suyundikov A, Slattery ML. Accounting for missing data in clinical research. JAMA. 2016;315(5):517–8.
Cha G-W, Moon H-J, Kim Y-C. Comparison of Random Forest and Gradient Boosting Machine Models for Predicting demolition Waste based on small datasets and categorical variables. Int J Environ Res Public Health. 2021;18(16):8530.
Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Med Decis Making. 2006;26(6):565–74.
Kerr KF, Brown MD, Zhu K, Janes H. Assessing the clinical impact of risk prediction models with decision curves: guidance for correct interpretation and appropriate use. J Clin Oncol. 2016;34(21):2534.
Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst 2017, 30.
HWANG SJ, TSAI JC. Epidemiology, impact and preventive care of chronic kidney disease in Taiwan. Nephrology. 2010;15:3–9.
Wang JS, Yen FS, Lin KD, Shin SJ, Hsu YH, Hsu CC. China DKDRCotDAotRo: epidemiological characteristics of diabetic kidney disease in Taiwan. J Diabetes Invest. 2021;12(12):2112–23.
Montford JR, Linas S. How dangerous is hyperkalemia? J Am Soc Nephrol. 2017;28(11):3155–65.
Luo J, Brunelli SM, Jensen DE, Yang A. Association between serum potassium and outcomes in patients with reduced kidney function. Clin J Am Soc Nephrol. 2016;11(1):90–100.
Vickers AJ, Holland F. Decision curve analysis to evaluate the clinical benefit of prediction models. Spine J. 2021;21(10):1643–8.
James C, Ranson JM, Everson R, Llewellyn DJ. Performance of machine learning algorithms for predicting progression to dementia in memory clinic patients. JAMA Netw open. 2021;4(12):e2136553–3.
Bennett TD, Moffitt RA, Hajagos JG, Amor B, Anand A, Bissell MM, Bradwell KR, Bremer C, Byrd JB, Denham A. Clinical characterization and prediction of clinical severity of SARS-CoV-2 infection among US adults using data from the US National COVID Cohort Collaborative. JAMA Netw open. 2021;4(7):e2116901–1.
Christodoulou E, Ma J, Collins GS, Steyerberg EW, Verbakel JY, Van Calster B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J Clin Epidemiol. 2019;110:12–22.
Ij H. Statistics versus machine learning. Nat Methods. 2018;15(4):233.
London AJ. Artificial intelligence and black-box medical decisions: accuracy versus explainability. Hastings Cent Rep. 2019;49(1):15–21.
Weir MR, Rolfe M. Potassium homeostasis and renin-angiotensin-aldosterone system inhibitors. Clin J Am Soc Nephrol. 2010;5(3):531–48.
Raebel MA. Hyperkalemia associated with use of angiotensin-converting enzyme inhibitors and angiotensin receptor blockers. Cardiovasc Ther. 2012;30(3):e156–66.
Mansoor F, Bai P, Kaur N, Sultan S, Sharma S, Dilip A, Kammawal Y, Shahid S, Rizwan A. Evaluation of serum electrolyte levels in patients with Anemia. Cureus 2021, 13(10).
Dewey J, Mastenbrook J, Bauler LD. Differentiating pseudohyperkalemia from true hyperkalemia in a patient with chronic lymphocytic leukemia and diverticulitis. Cureus 2020, 12(8).
Acknowledgements
None.
Funding
This research work was supported in part by the Ministry of Science and Technology Research Grant MOST 110-2634-F-006 -021.
Author information
Authors and Affiliations
Contributions
Conceptualization, Hsin-Hsiung Chang; Data curation, Hsin-Hsiung Chang and Chun-Chieh Tsai; Formal analysis, Hsin-Hsiung Chang and Ping-Fang Chiu; Funding acquisition, Jung-Hsien Chiang; Methodology, Hsin-Hsiung Chang and Chun-Chieh Tsai; Validation, Ping-Fang Chiu; Writing – original draft, Hsin-Hsiung Chang, Chun-Chieh Tsai, and Ping-Fang Chiu; Writing – review & editing, Jung-Hsien Chiang. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Institutional Review Board of Changhua Christian Hospital (IRB number-210423). Because we used database records (anonymized) for analysis, the requirement for the acquisition of informed consent from patients was waived at the Institutional Review Board of Changhua Christian Hospital. All methods were carried out in accordance with relevant guidelines and regulations.
Consent for publication
Not applicable.
Competing interests
The authors have no conflict of interest to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Materials: Table S1
. ICD-9 and ICD-10 diagnostic codes used to identify comorbidities. Table S2. Medications used in this study. Table S3. Logistic regression analyses yielding odds ratios for factors associated with hyperkalemia in patients with advanced chronic kidney disease
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Chang, HH., Chiang, JH., Tsai, CC. et al. Predicting hyperkalemia in patients with advanced chronic kidney disease using the XGBoost model. BMC Nephrol 24, 169 (2023). https://doi.org/10.1186/s12882-023-03227-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12882-023-03227-w