
Abstract
Background
The exponential spread of coronavirus disease 2019 (COVID-19) causes unexpected economic burdens to worldwide health systems with severe shortages in hospital resources (beds, staff, equipment). Managing patients’ length of stay (LOS) to optimize clinical care and utilization of hospital resources is very challenging. Projecting the future demand requires reliable prediction of patients’ LOS, which can be beneficial for taking appropriate actions. Therefore, the purpose of this research is to develop and validate models using a multilayer perceptron-artificial neural network (MLP-ANN) algorithm based on the best training algorithm for predicting COVID-19 patients' hospital LOS.
Methods
Using a single-center registry, the records of 1225 laboratory-confirmed COVID-19 hospitalized cases from February 9, 2020 to December 20, 2020 were analyzed. In this study, first, the correlation coefficient technique was developed to determine the most significant variables as the input of the ANN models. Only variables with a correlation coefficient at a P-value < 0.2 were used in model construction. Then, the prediction models were developed based on 12 training algorithms according to full and selected feature datasets (90% of the training, with 10% used for model validation). Afterward, the root mean square error (RMSE) was used to assess the models’ performance in order to select the best ANN training algorithm. Finally, a total of 343 patients were used for the external validation of the models.
Results
After implementing feature selection, a total of 20 variables were determined as the contributing factors to COVID-19 patients’ LOS in order to build the models. The conducted experiments indicated that the best performance belongs to a neural network with 20 and 10 neurons in the hidden layer of the Bayesian regularization (BR) training algorithm for whole and selected features with an RMSE of 1.6213 and 2.2332, respectively.
Conclusions
MLP-ANN-based models can reliably predict LOS in hospitalized patients with COVID-19 using readily available data at the time of admission. In this regard, the models developed in our study can help health systems to optimally allocate limited hospital resources and make informed evidence-based decisions.
Similar content being viewed by others

Background
Coronavirus disease 2019 (COVID-19) is a very contagious viral infection that has so far continued to spread rapidly around the world and has become a serious global health problem. The rapid outbreak of COVID-19 exposed healthcare organizations to hospital resource shortages and the exhaustion of frontline healthcare workers [1,2,3,4,5,6]. So far, clinical manifestations have shown substantial heterogeneity among different patients, ranging from asymptomatic or mild flu-like symptoms to severe respiratory illness and pneumonia, intensive care unit (ICU) hospitalization, multi-organ failure (MOF), and ultimately death [7]. The high transmission rates of COVID-19, the emergence of new variants, and unknown clinical patterns put immense pressure on health systems. As a result, there is a drastic increase in the number of patients seeking medical attention and a surge in hospitalizations [8, 9]. This overcrowding raises serious concerns regarding the potential impact of the spread of the virus, especially on health systems with severe resource constraints in low-and middle-income countries (LMICs) [10, 11]. During this pandemic crisis, to make healthcare more affordable and prevent the overwhelming of hospitals, it is crucial to adopt objective and evidence-based interventions for the effective use of medical facilities available in hospitals (e.g., hospital beds and respiratory ventilators, among others) [12].
As the pandemic worsens, identifying the consequent needs of patients and service providers has become essential. It is necessary to anticipate how long each case will need inpatient services [13, 14]. Length of stay (LOS) is an important measure of health services quality and resource utilization, which is often used to decrease health care charges, especially given the increase in health care costs [15, 16]. From clinicians’ perspective, predicting LOS has become significantly critical during the COVID-19 epidemic for reducing the risk of adverse events, such as poor nutritional levels, community spread, adverse drug events, and other clinical problems. Furthermore, from the hospital management point of view, LOS is one of the basic measures to assess the performance of healthcare quality services, care planning, hospital staffing, resource allocation, aid in triaging, and appointment scheduling [17,18,19,20]. Accurate prediction of long LOS of patients hospitalized with COVID-19 as well as the determination of the influencing factors can contribute to optimal management and utilization of limited hospital resources. In addition, by predicting the LOS metrics, policymakers and clinicians can redesign their clinical pathways and recognize the bottlenecks for maximizing the use of medical resources [21,22,23]. However, LOS may be affected by many factors and its prediction can be challenging, especially in complex, novel, and ambiguous medical conditions such as the current COVID-19 crisis [21, 22]. While traditional statistical methods have been employed to forecast hospital LOS, their efficacy is restricted by the high-dimensional, censored, and heterogeneous nature of clinical data [24, 25]. Therefore, in this situation, overwhelmed health systems attempt to improve resource utilization and eliminate bottlenecks of patient hospitalization by adopting data-driven machine learning (ML) solutions [26, 27].
ML is the subarea of artificial intelligence (AI), which can be applied to analysis and inference in a large volume of retrospective datasets in order to extract distinctive relationships or identify unfamiliar patterns with minimal human intervention or any programming design [28, 29]. Furthermore, ML techniques can be employed in medical practice to increase prognostic modeling and reveal new contributing factors related to a specific target outcome to predict future or obscure trends [28, 30]. The ML technique selected in this study is the artificial neural network (ANN), which imitates the tasks of biological human neurons based on a collection of connected nodes (input-hidden-output) called artificial neurons [31, 32]. ANN can be trained to recognize and categorize complex patterns of diseases and related healthcare events through an iterative learning process. To configure the ANN, it must be trained using training patterns by changing their weights through some training algorithms. The training of ANNs can be performed by several proposed algorithms [4, 8]. Various training algorithms have been evaluated in many fields and their advantages and drawbacks have been investigated [33,34,35,36].
So far, most efforts have been focused on the application of ANN for hospital LOS prediction and determining its affecting factors [21, 37,38,39,40,41]. Neto et al. attempted to predict the LOS for stroke patients and reported that the ANN gained the best results with an RMSE and a mean absolute error (MAE) of 5.9451 and 4.6354, respectively [41]. Launay et al. compared two feed-forward ANNs, including multilayer perceptron (MLP) and modified MLP, for predicting prolonged LOS, and modified MLP was reported to have the best performance with a sensitivity of 62.7%, specificity of 96.6%, and an area under the receiver operating characteristic curve (AUROC) of 90.5% [42]. Morton et al. concluded that the most successful results are obtained by using the ANN technique with an RMSE of 5.9451 and MAE of 4.6354 to predict the LOS of hospitalized diabetic patients [40]. Kulkarin et al. designed an MLP-based model for predicting prolonged LOS of coronary patients with an accuracy of 90.87% [39]. Similarly, another work performed by Bacchi et al. showed that the MLP achieved the highest accuracy in the prediction of LOS with an MAE of 0.246, RMSE of 0.369, and AUC of 0.864 [43]. Kabir and Hijjry in their separate studies developed a prediction model to anticipate LOS and the results revealed that the backpropagation neural network with accuracies of 92.58% and 78.29%, respectively, outperformed all the other models in these studies [37, 38]. East et al. reported that the model developed with ANN yielded the best performance in predicting long LOS (AUC of 0.9760%) [44]. However, no studies have been performed on COVID-19 to determine the most effective ANN training algorithm and structure. This study aimed to retrospectively develop and validate ANN-based models for predicting LOS in hospitalized patients with COVID-19 according to routine clinical data available at admission time. To this end, we established and tested 12 ANN training algorithms to select the best algorithm for constructing a prediction model.
Methods
Study design and setting
This is a retrospective, single-center, and cross-sectional study, which was performed in 2021 for predicting LOS in hospitalized patients with COVID-19 by comparing ANN training algorithms. In this study, a COVID-19 hospital-based registry database from Ayatollah Taleghani Hospital was retrospectively analyzed to develop the ANN-based models. Ayatollah Taleghani is a large academic hospital located in Iran, Abadan City, which treats a diverse patient population.
Study population
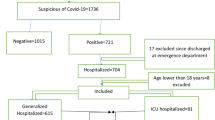
The analysis dataset only includes patients with a positive real-time reverse-transcriptase PCR (RT-PCR) test of throat swabs for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) and hospital admission dates between January 9, 2020 and January 20, 2021. During this period, a total of 12,885 cases suspected of COVID-19 have been referred to Ayatollah Taleghani Hospital ambulatory and emergency departments (EDs). Of those, 3350 cases were confirmed to have COVID-19 via PCR testing. Patients discharged from the ED were excluded because their outcomes were unknown. For patients with multiple hospitalizations related to COVID-19 within the study period, only the first visit was included. Patients under the age of 18 were also excluded (n = 36). These patients should be included in the scope of pediatric exploration. Moreover, patients who died within three days of admission to the hospital were excluded from the analysis (n = 128). Since public health officials such as Centers for Disease Control and Prevention (CDC), European Centre for Disease Prevention and Control (ECDD), and the National Centre for Infectious Disease (NCID) state that three days of symptom resolution, specifically fever and respiratory symptoms, is the cutoff for safe discharge, the LOS cutoff of three days was considered [45].
Data preparation
To overcome the impact of missing data on the models' predictive performance, all records containing missing data (more than 70%) were excluded from the analysis (n = 228). In addition, the remaining missing values were imputed with the mean or mode of each variable. Noisy and abnormal values, errors, duplicates, and meaningless data were assessed by researchers in collaboration with two infectious diseases specialists. For different interpretations of data preprocessing, we contacted the corresponding physicians. After applying the inclusion/exclusion criteria, 1225 records were entered into the study (Fig. 1). A significance level of p < 0.02 was used throughout the study.

Flow chart describing patient selection
Predictor and outcome variables
In the database, a total of 53 variables were obtained for each patient, including demographics (five variables), clinical manifestations (14 variables), comorbidities/risk factors (seven variables), laboratory results (26 variables), and treatment intervention (one variable) (Table 1).
Hospital LOS is considered the outcome variable. This measurement of duration is a continuous variable calculated using the number of days from the time patients were admitted to the hospital until they were either discharged, referred to another hospital, or died while still in the hospital.
Feature selection
Feature selection or variable selection is an effective technique that is used to determine the most meaningful variables, reduce the dimensions of the dataset, and improve the efficiency of ML algorithms [46]. In this study, variables with a correlation coefficient value less than 0.2 (P-value < 0.2) were identified as effective risk factors in predicting the LOS of COVID-19 patients and were included in the ANN models.
Model development
An ANN is a set of computing algorithms that emulate the functions of biological neural networks. The components of the models are nodes, weights, and layers (input, hidden, and output layers) (41). MLP-ANN is the simplest and most commonly used ANN architecture due to its structural flexibility, good representational capabilities, and a large number of training algorithms [47, 48]. In this study, in order to develop an MLP-ANN, we used 12 training algorithms, including Levenberg–Marquardt (LM), Bayesian regularization (BR), Broyden-Fletcher-Goldfarb-Shanno (BFGS) Quasi-Newton, resilient backpropagation (RP), scaled conjugate gradient (SGC), conjugate gradient with Powell/ Beale (CGB) restarts, conjugate gradient Fletcher-Powell (CGF), conjugate gradient with Polak-Ribiére (CGP) updates, one step secant (OSS), gradient descent variable learning rate (GDX), gradient descent with momentum (GDM), and gradient descent (GD) backpropagation described in Table 2. Moreover, selecting the optimal number of neurons in the hidden layer is an important and difficult issue due to its effect on the performance and efficiency of ANNs. Therefore, the optimal number of neurons in the hidden layer is determined by constructing ANNs with a different number of neurons in the hidden layer. In this study, it was attempted to consider the basic parameters of the algorithms as the same so that the effect of choosing the learning algorithm on the performance of the network could be thoroughly investigated. All simulations were implemented using the full-featured dataset, including 53 features, and a derived dataset with 20 features after performing feature selection.
Model evaluation
The performance of each model was evaluated based on the RMSE for predicting LOS using a tenfold cross-validation method. This method trains and evaluates ML algorithms by dividing the dataset into a training partition used to train the models and a test partition used to validate the models' performance [49, 50]. In our study, to circumvent probable bias in the presentation order of the sample patterns to the ANN, the dataset was randomly divided into 90% for training and 10% for testing.
After identifying the best neural network training algorithm and the optimal number of neurons in the hidden layer for LOS prediction, in order to perform external validation, we conducted a three-month prospective study in Ayatollah Taleghani Hospital. The best model was applied to predict the LOS of all hospitalized patients confirmed to have COVID-19 via PCR testing and admitted to this hospital from February 1, 2021 to April 30, 2021 (343 patients). The comparison between the output of the selected neural network and the real data as a benchmark was conducted by calculating the RMSE.
Ethical considerations
This study was approved by the Ethical Committee Board, Abadan University of Medical Sciences (code: IR.ABADANUMS.REC.1399.222). To protect patients’ privacy and confidentiality, we concealed the unique identifying information of all patients during the process of data collection and presentation.
Results
Characteristics of COVID-19 patients
In this study, a retrospective analysis was conducted on the medical records of 1225 COVID-19-positive patients evaluated between January 9, 2020 and January 20, 2021 at Ayatollah Taleghani Hospital, and it was revealed that 664 (54.20%) patients were male and 561 (45.80%) were female. The overall mean age was 57.25 (interquartile 18–100) years. A total of 170 (13.87%) patients were hospitalized in the ICU and 1055 (86.13%) were hospitalized in general wards. Descriptive statistics for the 1225 records in this dataset are shown in Table 3.
Variables included in the ANN models
The results of feature selection for determining the most important diagnostic criteria affecting COVID-19 hospital LOS based on the correlation coefficient at P < 0.2 are demonstrated in Table 4.
After feature selection, a total of 20 features acquired the determined correlation coefficient at P < 0.2. Features including age, creatinine, white blood cell (WBC) count, lymphocyte /neutrophil count, blood urea nitrogen (BUN), aspartate aminotransferase (ASP), alanine aminotransferase (ALT), lactate dehydrogenase (LDH), activated partial thromboplastin time (PTT), coughing, hypertension, cardiovascular disease (CVD), diabetes, dyspnea, oxygen therapy, pneumonia, gastrointestinal (GI) complications, erythrocyte sedimentation rate (ESR), and C-reactive protein (CRP) were identified as the most significant factors for predicting hospital LOS.
Determining the appropriate configuration for the MLP
To determine the best predictive model, different MLP networks with multiple configurations were trained and their performance was evaluated using tenfold cross-validation. Tables 5 and 6 list the RMSE rate of each network with different training algorithms and the number of neurons in the hidden layers for both datasets.
According to Tables 5 and 6, using a total of 53 risk factors, the best results were obtained by the neural network with 20 neurons in the hidden layer and the BR training algorithm. The RMSE of this technique was 1.6213, which was the lowest error rate among the designed networks. The results also showed that based on the selected features (n = 20), the neural network with the BR training algorithm and 10 hidden neurons achieved the best result (RMSE = 2.2332). The error histograms for these two models are depicted in Fig. 2.

Error histogram for the best model
According to Fig. 2, although the error rate in the dataset with selected features is higher, the error distribution is better, and for small samples, it indicates an error greater than the CDC threshold (i.e., three days). The network architecture for the BR training algorithm based on the whole dataset is shown in Fig. 3.

The architecture of the BR training algorithm with 20 neurons used for COVID-19 LOS prediction
For external evaluation, the best LOS prediction model was utilized for the prospective study and predicted the LOS of patients with an RMSE of 2.8529. Figure 4 compares the actual and predicted values of LOS for the external validation cases using the MLP with BR as a training function and 20 neurons in the hidden layer.

Comparison between the output of the best neural network and the actual data for the external validation sample
The error histogram of the external validation (Fig. 5) showed that the proposed model has a good ability to predict LOS of hospitalized COVID-19 patients, and for small samples, it indicates an error of more than two days.

Error histogram of the LOS prediction model for the external validation sample
Discussion
In this study, we developed and evaluated several MLP neural networks training algorithms to predict the LOS of COVID-19 patients using full and selected feature datasets (53 and 20 features, respectively). The experimental results revealed that BR had the best performance compared to the other techniques in LOS prediction for COVID-19 patients with an RSME of 1.6213 (layer 20) and 2.2332 (layer 10) for the whole and selected feature datasets, respectively. In the present study, the most important variables (n = 20 predictors) were identified through a correlation coefficient at the level of P-value < 0.2. These variables include age, creatinine, WBC, lymphocyte/neutrophil count, BUN, ASP, ALT, LDH, activated PTT, coughing, hypertension, CVD, diabetes, dyspnea, oxygen therapy, pneumonia, GI complications, ESR, and CRP.
Determining the best network training algorithm depends on many factors, including the complexity of the problems, the amount of data in the training set, the number of weights and biases in the network, the error goal, and whether the network is used for pattern recognition or function approximation [51, 52]. In our study, the LM training algorithm also exhibited a satisfactory performance in estimating the functions. If LM is trained with low number weights, it will converge more quickly and have a much lower error rate than other training algorithms. But when it is trained with a high number weight, its efficiency will decrease [53, 54]. Conjugate gradient-based training algorithms (SCG, CGB, CGF, and CGP) identical to LM have a good performance in estimating the functions and recognizing patterns. Furthermore, their efficiency would not reduce significantly with an increase in the weight number [55, 56]. In the present study, algorithms based on LM as well as SCG, CGB, CGF, and CGP had a satisfactory performance. The RP algorithm had undesirable performance in function approximation compared to other training algorithms because it demonstrated better capability for pattern recognition [57, 58]. The BFGS Quasi-Newton does not require as much storage as LM, but the computations required increase geometrically with the size of the ANN because the inverse matrix must be calculated for each iteration. The GDX had a slow convergence and the other two gradient descent algorithms (GDM and GD), as shown in this study, do not perform well in function approximation [59, 60]. The BR training algorithm updates network weights and biases using the LM optimization method. It minimizes the combination of squares error and weights and seeks the right combination that leads to a network with high generalizability [61, 62]. Since BR looks for a network with high generalizability, in our study, the best results were obtained by this training algorithm.
Similarly, Conde-Gutie´rrez et al. used the ANN method in their study to model and predict the cumulative number of deaths from COVID-19 in Mexico. They applied LM, BFGS, and batch GD training algorithms to fit coefficients (weights and biases). The comparison between the real data and those attained by the ANN model when using the training algorithms indicates satisfactory correlations with RMSEs of 0.2290, 0.2165, and 0.7722, respectively. Based on the computation time, the LM algorithm is the most appropriate for modeling the dynamics of deaths from COVID-19. The LM algorithm estimated the coefficients in the shortest probable time (46.23 s) while the BFGS Quasi-Newton algorithm showed better precision fits for the real data. The batch GD algorithm had the least capacity to model the real data and needed more neurons in the hidden layer [63]. Namasudra et al. presented a nonlinear autoregressive (NAR) neural network time series (NAR-NNTS) model for predicting COVID-19 cases. This NAR-NNTS model is trained with SCG, LM, and BR training algorithms. The results showed that the NAR-NNTS model trained with LM performs better than other models for COVID-19 epidemiological data prediction [64]. Sapon et al. used the data of 250 diabetic patients to train the network to identify the disease pattern. They used three training algorithms including BR, BFGS, and LM. The BR algorithm had the best performance in the prediction of diabetes compared to the BFGS Quasi-Newton and LM algorithms. The BFGS Quasi-Newton algorithm possessed 0.86714 correlation coefficients with 578 epochs while the BR algorithm acquired 0.99579 for 37 epochs and LM held 0.6051 for only five epochs. Therefore, according to their study, the BR algorithm presented a good correlation between the estimated targets and actual outputs (i.e., 0.99579) with 88.8% prediction accuracy, confirming the validation that shows the correctness of this algorithm to perform effective diabetes prediction [65]. Narayan et al. compared three training algorithms, including, LM, RP, and GDM, for training the network to estimate clinical gait mechanics. The results of correlation coefficients revealed the significant potential of the LM model over RP and GDM models while estimating the gait mechanics [66]. Using the data of 303 samples to predict heart diseases, Karim et al. compared different training algorithms, including GD, GDM, RP, SCG, CGP, CGF, BFGS Quasi-Newton, and LM. According to their findings, BFGS Quasi-Newton training algorithm is the most suitable for the development of an ANN prediction model for heart diseases because of its optimal speed and accuracy [67].
Many studies have shown that certain characteristics are associated with hospital LOS [8, 13, 14, 18, 19, 68, 69]. The most important clinical variables affecting longer LOS in reviewed studies include age (older age) [13, 18, 19, 69], comorbidities [8, 14, 68, 69] (CVD, hypertension, diabetes, and respiratory diseases, such asthma or chronic obstructive pulmonary disease (COPD)), loss of consciousness [8, 14, 69], increased BUN [8, 14, 18, 19], leukocytosis [8, 68], decreased oxygen saturation (SPO2) [13, 18, 19, 68], mechanical ventilation (oxygen therapy) [8, 14, 69], pleural effusion [13, 19, 68], dry cough [13, 69], and fever [8, 18, 19, 69]. In general, high compliance was observed from the results of classifying and prioritizing variables in reviewed studies with the most common variables selected in the current study. The results of our study indicated that the designed ANN model can effectively predict the COVID-19 patients’ LOS by using clinical variables that are readily available at the first time of admission.
Limitations
Despite the strength of the algorithms presented, the novelty of the approach, and the promising predictive results, the study had some limitations that should be recognized. First, we dealt with a retrospective dataset that might suffer from uneven or imbalanced, noisy, duplicate, and meaningless values, which may skew results. Thus, the dataset was balanced by eliminating confounding factors as much as possible. Second, this study was performed at a single regional center and was only based on 1225 records; therefore, the results may not be generalizable and may confine the model’s applicability to other contexts. Although we only used the ANN algorithm for prediction analyses, other algorithms may perform better. As the analyses were based on a particular cohort of COVID-19 (alpha variant) before the building of vaccines, this limits the applicability for modern usage, especially in terms of delta and omicron variants and a vaccinated population may be limited. Lastly, the model developed in our study is limited to features commonly available at the initial time of admission. Although this is consistent with the aim of our study to predict COVID-19 LOS based on the admission data, the features generated during the hospitalization, such as radiological, imaging, and therapeutic intervention features, may improve the results of the models. The performance of our computational model can be improved in the future, if we examine more ML techniques at prospective, multicenter, and qualitative datasets.
Conclusions
Predicting LOS allows hospitals to assess the overall patient load, which in turn allows improved scheduling of patient admissions, leading to a reduced variation of bed occupancies in hospitals. Estimating the LOS of hospitalized patients with COVID-19 is crucial for effectively planning bed management along with related personnel and facilities requirements. The results showed that MLP with the BR training algorithm has a better performance than the other models. With further validation, our models are expected to serve as objective, measurable, and evidence-based tools to predict COVID-19 LOS and optimize the use of limited hospital resources. While our models are trained using a dataset from one hospital, they can be retrained using a multicentral dataset from different geographic locations, which would improve the generalizability of the models to predict COVID-19 patients’ LOS. For future studies, it is suggested to train the ANN models with multicentral datasets. This would assist in improving the learning capability of the models as the trained dataset will be more diversified, hence providing better predictive performance for the models.
Availability of data and materials
All data generated and analyzed during the current study are not publicly available but are available from the corresponding author on reasonable request and the Student Research Committee of Abadan University of Medical Sciences approval.
References
Liu Y, Wang Z, Ren J, Tian Y, Zhou M, Zhou T, Ye K, Zhao Y, Qiu Y, Li J. A COVID-19 risk assessment decision support system for general practitioners: design and development study. J Med Internet Res. 2020;22(6): e19786.
Alom MZ, Rahman M, Nasrin MS, Taha TM, Asari VK: COVID_MTNet: COVID-19 detection with multi-task deep learning approaches. arXiv preprint arXiv:200403747 2020.
Bansal A, Padappayil RP, Garg C, Singal A, Gupta M, Klein A. Utility of artificial intelligence amidst the COVID 19 pandemic: a review. J Med Syst. 2020. https://doi.org/10.1007/s10916-020-01617-3.
Lai C-C, Shih T-P, Ko W-C, Tang H-J, Hsueh P-R. Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) and coronavirus disease-2019 (COVID-19): the epidemic and the challenges. Int J Antimicrob Agents. 2020;55(3): 105924.
Hussain A, Bhowmik B, et al. COVID-19 and diabetes: knowledge in progress. Diabetes Res Clin Pract. 2020. https://doi.org/10.1016/j.diabres.2020.108142.
Moujaess E, Kourie HR, Ghosn M. Cancer patients and research during COVID-19 pandemic: A systematic review of current evidence. Crit Rev Oncol Hematol. 2020;150: 102972.
Yadaw AS, Li Y-C, Bose S, Iyengar R, Bunyavanich S, Pandey G. Clinical features of COVID-19 mortality: development and validation of a clinical prediction model. Lancet Digital Health. 2020;2(10):e516–25.
Hong Y, Wu X, Qu J, Gao Y, Chen H, Zhang Z. Clinical characteristics of coronavirus disease 2019 and development of a prediction model for prolonged hospital length of stay. Ann Transl Med. 2020. https://doi.org/10.21037/atm.2020.03.147.
Chiam T, Subedi K, Chen D, Best E, Bianco FB, Dobler G, Papas M. Hospital length of stay among COVID-19-positive patients. J Clin Transl Res. 2021;7(3):377.
Rees EM, Nightingale ES, Jafari Y, Waterlow NR, Clifford S, et al. COVID-19 length of hospital stay: a systematic review and data synthesis. BMC Med. 2020;18(1):1–22.
Lucero A, Sokol K, Hyun J, Pan L, Labha J, Donn E, Kahwaji C, Miller G. Worsening of emergency department length of stay during the COVID-19 pandemic. J Am Coll Emerg Physicians Open. 2021;2(3): e12489.
Daghistani TA, Elshawi R, Sakr S, Ahmed AM, Al-Thwayee A, Al-Mallah MH. Predictors of in-hospital length of stay among cardiac patients: a machine learning approach. Int J Cardiol. 2019;288:140–7.
Jang SY, Seon J-Y, Yoon S-J, Park S-Y, Lee SH, Oh I-H. Comorbidities and factors determining medical expenses and length of stay for admitted COVID-19 patients in Korea. Risk Manag Healthc Policy. 2021. https://doi.org/10.2147/RMHP.S292538.
Thiruvengadam G, Lakshmi M, Ramanujam R. A study of factors affecting the length of hospital stay of COVID-19 patients by cox-proportional hazard model in a South Indian tertiary care hospital. J Prim Care Community Health. 2021;12:21501327211000230.
Saravi B, Zink A, Ülkümen S, Couillard-Despres S, Hassel F, Lang G. Performance of artificial intelligence-based algorithms to predict prolonged length of stay after lumbar decompression surgery. J Clin Med. 2022;11(14):4050.
Tsai PFJ, Chen PC, Chen YY, Song HY, Lin HM, Lin FM, Huang Q-P. Length of hospital stay prediction at the admission stage for cardiology patients using artificial neural network. J Healthc Eng. 2016. https://doi.org/10.1155/2016/7035463.
Lapidus N, Zhou X, Carrat F, Riou B, Zhao Y, Hejblum G. Biased and unbiased estimation of the average length of stay in intensive care units in the Covid-19 pandemic. Ann Intensive Care. 2020;10(1):135.
Alwafi H, Naser AY, Qanash S, Brinji AS, Ghazawi MA, Alotaibi B, Alghamdi A, Alrhmani A, Fatehaldin R, Alelyani A. Predictors of length of hospital stay, mortality, and outcomes among hospitalised covid-19 patients in Saudi Arabia: a cross-sectional study. J Multidiscip Healthc. 2021;14:839.
Wu S, Xue L, Legido-Quigley H, Khan M, Wu H, Peng X, Li X, Li P. Understanding factors influencing the length of hospital stay among non-severe COVID-19 patients: a retrospective cohort study in a Fangcang shelter hospital. PLoS ONE. 2020;15(10): e0240959.
Wen Y, Rahman MF, Zhuang Y, Pokojovy M, Xu H, McCaffrey P, Vo A, Walser E, Moen S. Tseng T-LB: Time-to-event modeling for hospital length of stay prediction for COVID-19 patients. Mach Learn Appl. 2022;9: 100365.
Dan T, Li Y, Zhu Z, Chen X, Quan W, Hu Y, Tao G, Zhu L, Zhu J, Jin Y: Machine Learning to Predict ICU Admission, ICU Mortality and Survivors’ Length of Stay among COVID-19 Patients: Toward Optimal Allocation of ICU Resources. In: 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM): 2020: IEEE; 2020: 555–561.
Wu C, Glass S, Demars S, Tulloch-Palomino LG, Wander PL. Estimated excess acute-care length of stay and extra cost of testing-based versus symptom-based isolation strategies among veterans hospitalized with coronavirus disease 019 (COVID-19) discharging to a congregate setting. Infect Control Hosp Epidemiol. 2020. https://doi.org/10.1017/ice.2020.1295.
Ayyoubzadeh SM, Ghazisaeedi M, Kalhori SRN, Hassaniazad M, Baniasadi T, Maghooli K, Kahnouji K. A study of factors related to patients’ length of stay using data mining techniques in a general hospital in southern Iran. Health Inform Sci Syst. 2020;8(1):1–11.
Bacchi S, Tan Y, Oakden-Rayner L, Jannes J, Kleinig T, Koblar S. Machine learning in the prediction of medical inpatient length of stay. Intern Med J. 2020. https://doi.org/10.1111/imj.14962.
Sherbet GV, Woo WL, Dlay S. Application of artificial intelligence-based technology in cancer management: a commentary on the deployment of artificial neural networks. Anticancer Res. 2018;38(12):6607–13.
Symum H, Zayas-Castro JL. Prediction of chronic disease-related inpatient prolonged length of stay using machine learning algorithms. Healthc Inform Res. 2020;26(1):20–33.
Roimi M, Gutman R, Somer J, Ben Arie A, Calman I, Bar-Lavie Y, Gelbshtein U, Liverant-Taub S, Ziv A, Eytan D, Gorfine M. Development and validation of a machine learning model predicting illness trajectory and hospital utilization of COVID-19 patients: a nationwide study. J Am Med Inform Assoc. 2021;28(6):1188–96.
Shanbehzadeh M, Nopour R, Kazemi-Arpanahi H. Comparison of four data mining algorithms for predicting colorectal cancer risk. J Adv Med Biomed Res. 2021;29(133):100–8.
Nassif AB, Azzeh M, Banitaan S, Neagu D. Guest editorial: special issue on predictive analytics using machine learning. Neural Comput Appl. 2016;27(8):2153–5.
Hernandez-Suarez DF, Ranka S, Kim Y, Latib A, Wiley J, Lopez-Candales A, Pinto DS, Gonzalez MC, Ramakrishna H, Sanina C. Machine-learning-based in-hospital mortality prediction for transcatheter mitral valve repair in the United States. Cardiovasc Revascular Med. 2020. https://doi.org/10.1016/j.carrev.2020.06.017.
Streun GL, Elmiger MP, Dobay A, Ebert L, Kraemer T. A machine learning approach for handling big data produced by high resolution mass spectrometry after data independent acquisition of small molecules - Proof of concept study using an artificial neural network for sample classification. Drug Test Anal. 2020;12(6):836–45.
Yang H, Zhang Z, Zhang J, Zeng XC. Machine learning and artificial neural network prediction of interfacial thermal resistance between graphene and hexagonal boron nitride. Nanoscale. 2018;10(40):19092–9.
Sharma B, Venugopalan K. Comparison of neural network training functions for hematoma classification in brain CT images. IOSR J Comp Eng. 2014;16(1):31–5.
Bowen WR, Jones MG, Yousef HN. Dynamic ultrafiltration of proteins–a neural network approach. J Membr Sci. 1998;146(2):225–35.
Zhou L, Yang X. Training algorithm performance for image classification by neural networks. Photogramm Eng Remote Sens. 2010;76(8):945–51.
Aggarwal K, Singh Y, Chandra P, Puri M. Evaluation of various training algorithms in a neural network model for software engineering applications. ACM SIGSOFT Softw Eng Notes. 2005;30(4):1–4.
Hijry H, Olawoyin R: Application of Machine Learning Algorithms for Patient Length of Stay Prediction in Emergency Department During Hajj. In: 2020 IEEE International Conference on Prognostics and Health Management (ICPHM): 2020: IEEE; 2020: 1–8.
Kabir S, Farrokhvar L: Non-Linear Feature Selection for Prediction of Hospital Length of Stay. In: 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA): 2019: IEEE; 2019: 945–950.
Kulkarni H, Thangam M, Amin AP. Artificial neural network-based prediction of prolonged length of stay and need for post-acute care in acute coronary syndrome patients undergoing percutaneous coronary intervention. Eur J Clin Invest. 2021;51(3): e13406.
Morton A, Marzban E, Giannoulis G, Patel A, Aparasu R, Kakadiaris IA: A comparison of supervised machine learning techniques for predicting short-term in-hospital length of stay among diabetic patients. In: 2014 13th International Conference on Machine Learning and Applications: 2014: IEEE; 2014: 428–431.
Neto C, Brito M, Peixoto H, Lopes V, Abelha A, Machado J: Prediction of length of stay for stroke patients using artificial neural networks. In: World Conference on Information Systems and Technologies: 2020: Springer; 2020: 212–221.
Launay C, Rivière H, Kabeshova A, Beauchet O. Predicting prolonged length of hospital stay in older emergency department users: use of a novel analysis method, the Artificial Neural Network. Eur J Intern Med. 2015;26(7):478–82.
Bacchi S, Gluck S, Tan Y, Chim I, Cheng J, Gilbert T, Menon DK, Jannes J, Kleinig T, Koblar S. Prediction of general medical admission length of stay with natural language processing and deep learning: a pilot study. Intern Emerg Med. 2020;15(6):989–95.
East A, Ray S, Pope R, Cortina-Borja M, Sebire NJ: 45 Predicting long length of stay in a paediatric intensive care unit using machine learning. In.: BMJ Publishing Group Ltd; 2020.
El Halabi M, Feghali J, Bahk J, de Lara PT, Narasimhan B, Ho K, Sehmbhi M, Saabiye J, Huang J, Osorio G, Mathew J. A novel evidence-based predictor tool for hospitalization and length of stay: insights from COVID-19 patients in New York city. Intern Emerg Med. 2022;17(7):1879–89. https://doi.org/10.1007/s11739-022-03014-9.
Karegowda AG, Manjunath A, Jayaram M. Comparative study of attribute selection using gain ratio and correlation based feature selection. Int J Inform Technol Knowl Manag. 2010;2(2):271–7.
Fazlollahi P, Afarineshkhaki A, Nikbakhsh R. Predicting the medals of the countries participating in the Tokyo 2020 olympic games using the test of networks of multilayer perceptron (MLP). Ann Appl Sport Sci. 2020;8(4):1–12.
Theerthagiri P, Gopala Krishnan C, Nishan AH. Prognostic analysis of hyponatremia for diseased patients using multilayer perceptron classification technique. EAI Endorsed Trans Pervasive Health Technol. 2021. https://doi.org/10.4108/eai.17-3-2021.169032.
Abujaber A, Fadlalla A, Nashwan A, El-Menyar A, Al-Thani H. Predicting prolonged length of stay in patients with traumatic brain injury: a machine learning approach. Intell Based Med. 2022;6: 100052.
Das A, Ben-Menachem T, Cooper GS, Chak A, Sivak MV Jr, Gonet JA, Wong RC. Prediction of outcome in acute lower-gastrointestinal haemorrhage based on an artificial neural network: internal and external validation of a predictive model. Lancet. 2003;362(9392):1261–6.
Nouir Z, Sayrac B, Fourestié B, Tabbara W, Brouaye F: Comparison of neural network learning algorithms for prediction enhancement of a planning tool. In: 13th European Wireless Conference, Paris, France: 2007; 2007
Mohebbi A, Taheri M, Soltani A. A neural network for predicting saturated liquid density using genetic algorithm for pure and mixed refrigerants. Int J Refrig. 2008;31(8):1317–27.
Amellas Y, Djebli A, Echchelh A. Levenberg-marquardt training function using on mlp, rnn and elman neural network to optimize hourly forecasting in tetouan city (Northern Morocco). J Eng Sci Technol Rev. 2020;13(1):67–71.
Miaoli M, Xiaolong W, Honggui H: Accelerated Levenberg-Marquardt Algorithm for Radial Basis Function Neural Network. In: Proceedings - 2020 Chinese Automation Congress, CAC 2020: 2020; 2020: 6804–6809.
ColaÇo MJ, Orlande HRB. Comparison of different versions of the conjugate gradient method of function estimation. Numer Heat Transf Appl. 1999;36(2):229–49.
Jeong SB, Lee SJ, Park GJ. Improvement of the convergence capability of a single loop single vector approach using conjugate gradient for a concave function. Trans Korean Soc Mech Eng A. 2012;36(7):805–11.
Dutta M, Chatterjee A, Rakshit A: A resilient backpropagation neural network based phase correction system for automatic digital AC bridges. In: CPEM Digest (Conference on Precision Electromagnetic Measurements): 2004; 2004: 374–375.
Wang X, Wang H, Dai G, Tang Z: A reliable resilient backpropagation method with gradient ascent. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). vol. 4114 LNAI - II; 2006: 236–244.
Sotirov S, Atanassov K, Krawczak M: Generalized net model for parallel optimization of feed-forward neural network with variable learning rate backpropagation algorithm with time limit. In: Studies in Computational Intelligence. vol. 299; 2010: 361–371.
Yu F, Hu Z: Variable weighted learning algorithm and its convergence rate. In: 5th International Conference on Natural Computation, ICNC 2009: 2009; 2009: 373–377.
Khan I, Raja MAZ, Shoaib M, Kumam P, Alrabaiah H, Shah Z, Islam S. Design of neural network with levenberg-marquardt and bayesian regularization backpropagation for solving pantograph delay differential equations. IEEE Access. 2020;8:137918–33.
Priya A, Garg S: A comparison of prediction capabilities of bayesian regularization and levenberg–marquardt training algorithms for cryptocurrencies. In: Smart Innovation, Systems and Technologies. vol. 159; 2020: 657–664.
Conde-Gutiérrez R, Colorado D, Hernández-Bautista S. Comparison of an artificial neural network and Gompertz model for predicting the dynamics of deaths from COVID-19 in México. Nonlinear Dyn. 2021;104(4):4655–69.
Namasudra S, Dhamodharavadhani S, Rathipriya R. Nonlinear neural network based forecasting model for predicting COVID-19 cases. Neural Process Lett. 2021. https://doi.org/10.1007/s11063-021-10495-w.
Sapon MA, Ismail K, Zainudin S: Prediction of diabetes by using artificial neural network. In: Proceedings of the 2011 International Conference on Circuits, System and Simulation, Singapore: 2011; 2011: 299303.
Narayan J, Jhunjhunwala S, Mishra S, Dwivedy SK: A comparative performance analysis of backpropagation training optimizers to estimate clinical gait mechanics. In: Predictive Modeling in Biomedical Data Mining and Analysis. Elsevier; 2022: 83–104.
Karim H, Niakan SR, Safdari R. Comparison of neural network training algorithms for classification of heart diseases. IAES Int J Artif Intell. 2018;7(4):185–9. https://doi.org/10.11591/ijai.v7.i4.pp185-189
Çetin Ş, Ulgen A, Şivgin H, Wentian L. A study on factors impacting length of hospital stay of COVID-19 inpatients. J Complement Med. 2021;11:396–404.
Guo A, Lu J, Tan H, Kuang Z, Luo Y, Yang T, Xu J, Yu J, Wen C, Shen A. Risk factors on admission associated with hospital length of stay in patients with COVID-19: a retrospective cohort study. Sci Rep. 2021;11(1):1–7.
Acknowledgements
We thank the Research Deputy of the Abadan University of Medical Sciences for financially supporting this project.
Funding
There was no funding for this research project.
Author information
Authors and Affiliations
Contributions
HK-A, MS: Conceptualization; Data curation; Formal analysis; Investigation; Software; Roles/Writing—original draft. AO, EM, HK-A: Conceptualization; Formal analysis; Investigation; Software; Roles/Writing-original draft; Funding acquisition; Methodology; Project administration; Resources; Supervision; Writing—review & editing. AO, MS, HK-A: Conceptualization; Investigation; Methodology; Validation; Writing—review & editing. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This article is extracted from a research project supported by the Abadan University of Medical Sciences. Informed consent was obtained from all subjects participating in the data collection under the approved protocol. Secondary data analysis of these data was approved by Ethical Committee and Institutional Review Board of Abadan University of Medical Sciences (IR.ABADANUMS.REC.1399.222).
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Orooji, A., Shanbehzadeh, M., Mirbagheri, E. et al. Comparing artificial neural network training algorithms to predict length of stay in hospitalized patients with COVID-19. BMC Infect Dis 22, 923 (2022). https://doi.org/10.1186/s12879-022-07921-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12879-022-07921-2