
Abstract
Background
Medical scoring systems are potentially useful to make optimal use of available resources. A variety of models have been developed for illness measurement and stratification of patients in Emergency Departments (EDs). This study was aimed to compare the predictive performance of the following six scoring systems: Simple Clinical Score (SCS), Worthing physiological Score (WPS), Rapid Acute Physiology Score (RAPS), Rapid Emergency Medicine Score (REMS), Modified Early Warning Score (MEWS), and Routine Laboratory Data (RLD) to predict in-hospital mortality.
Methods
A prospective single-center observational study was conducted from March 2016 to March 2017 in Edalatian ED in Emam Reza Hospital, located in the northeast of Iran. All variables needed to calculate the models were recorded at the time of admission and logistic regression was used to develop the models’ prediction probabilities. The Area Under the Curve for Receiver Operating Characteristic (AUC-ROC) and Precision-Recall curves (AUC-PR), Brier Score (BS), and calibration plots were used to assess the models’ performance. Internal validation was obtained by 1000 bootstrap samples. Pairwise comparison of AUC-ROC was based on the DeLong test.
Results
A total of 2205 patients participated in this study with a mean age of 61.8 ± 18.5 years. About 19% of the patients died in the hospital. Approximately 53% of the participants were male. The discrimination ability of SCS, WPS, RAPS, REMS, MEWS, and RLD methods were 0.714, 0.727, 0.661, 0.678, 0.698, and 0.656, respectively. Additionally, the AUC-PR of SCS, WPS, RAPS, REMS, EWS, and RLD were 0.39, 0.42, 0.35, 0.34, 0.36, and 0.33 respectively. Moreover, BS was 0.1459 for SCS, 0.1713 for WPS, 0.0908 for RAPS, 0.1044 for REMS, 0.1158 for MEWS, and 0.073 for RLD. Results of pairwise comparison which was performed for all models revealed that there was no significant difference between the SCS and WPS. The calibration plots demonstrated a relatively good concordance between the actual and predicted probability of non-survival for the SCS and WPS models.
Conclusion
Both SCS and WPS demonstrated fair discrimination and good calibration, which were superior to the other models. Further recalibration is however still required to improve the predictive performance of all available models and their use in clinical practice is still unwarranted.
Similar content being viewed by others
Introduction
Emergency Departments (EDs) are considered as frontline in clinical practice to provide critical medical care [1]. A number of models have been developed to classify patients with different acuity levels. Accurate and reliable models with minimum prediction error will help clinicians to prioritize patients correctly [2]. Scoring systems are potentially useful to provide relevant information on the severity of diseases, prioritize patients, determine the prognosis of patients, evaluate the quality of care, and optimize resource allocation [3,4,5]. There is also evidence showing that in a critical care setting, where physicians assess patients at high risk of deterioration, applying scoring systems is a useful mean along with clinical experience to facilitate distinguishing high-risk patients from low-risk ones [6].
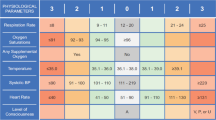
Systems such as Acute Physiology and Chronic Health Evaluation (APACHE) [7], Simplified Acute Physiology Score (SAPS) [8], and Sequential Organ Failure Assessment (SOFA) were first introduced in the intensive care unit (ICU) [9]. Later, several scoring systems have emerged in the emergency department (ED) to risk stratify patients and predict mortality. These later systems includr the Simple Clinical Score (SCS) [10] Worthing Physiological Scoring system (WPS) [11], Rapid Acute Physiology Score (RAPS) [12], Rapid Emergency Medicine Score (REMS) [13], Modified Early Warning Score (MEWS) [14], and Routine Laboratory Data (RLD) [15], which have also been validated as the Biochemistry and Hematology Outcome Model (BHOM) [16]. Table 1 displays these models in terms of their variables and their point assignment scheme. As key variables they primarily include vital signs. Some subjective variables are also used by the SCS, such as ‘abnormal EKG’, ‘Unable to stand unaided or nursing home resident’, ‘underlying diseases’, and ‘spent some part of daytime in bed’ [3]. The RLD, in contrast, mainly includes laboratory parameters. However, The application of these models for outcome estimation on populations presenting to the ED has received much less consideration. Most of the previous studies were focused on just one specific group of disease or considered one or two types of these models. In this paper, we therefore design and perform a study to inspect and compare the performance of the six ED scoring models (SCS, WPS, RAPS, REMS, MEWS, and RLD) to predict in-hospital mortality using a large cohort of patients presented to a general ED.
Methods
Study design and settings
This prospective cohort study was performed from March 2016 to March 2017 in the Edalatian ED located in Emam Reza referral university hospital in Mashhad, northeast of Iran. The study was approved by the institutional review board of Mashhad University of Medical Sciences (ID:990106, IR.MUMS.fm.REC.1395.16) and conformed to the Declaration of Helsinki principles. The need for informed consent was waived by the Ethics Committee of Mashhad University of Medical Sciences because of the nature of the study and the analysis used anonymous clinical data.
Inclusion and exclusion criteria
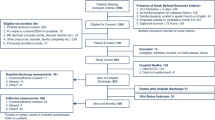
All adult patients (18 years of age or older) with high triage levels (Emergency Severity Index, ESI 1 to 3) were included in this study. The Patients who were discharged within 4 h after admission, readmitted with the same diagnosis, or died upon arrival were excluded. Moreover, patients requiring immediate surgical interventions (e.g. appendectomy), patients admitted due to traumatic or poisoning events, and patients with obstetric or ENT (Ear, Nose, or Throat) disorders were referred to their special wards and were consequently excluded from the study. The information about inclusion and exclusion criteria was reported previously [17].
Study variables
The following variables were recorded at the time of admission: age, gender, vital signs (i.e., systolic and diastolic blood pressure, pulse rate, respiratory rate, temperature, AVPU, GCS score), mechanical ventilation status, oxygen saturation, abnormal electrocardiography findings (diagnosis made by the emergency medicine specialist), history of underlying diseases such as disability to stand without physical support, diabetes, new stroke or current apnea. The study end-point was in-hospital mortality. Moreover, the following laboratory results were measured using the serum which was obtained at the time of admission: serum urea, creatinine, sodium, potassium, albumin, white blood cell, hemoglobin, and platelet. All Collected variables were used to calculate the SCS, WPS, RAPS, REMS, MEWS, and RLD scores.
Statistical analysis
Descriptive statistics were used to summarize characteristics of the study sample (i.e. continuous variables were expressed as Mean ± SD and categorical variables were reported in frequencies and percentages).
Logistic regression was used to develop models including each of the scoring systems. The predicted probability for each particular patient was calculated using the following formula:
(β0: Intercept; β1: Coefficient of the score; X1: score)
Each model was assessed in terms of discrimination, balance between sensitivity and positive prediction value, calibration, and accuracy of the predictions. Discrimination was measured by the area under the receiver operating characteristic curve (AUC-ROC). It is a performance measure which represents the ability of the model to assign higher probability of mortality for those who died than those who survived. The greater the AUC-ROC, the better the model’s performance at distinguishing between survival and non-survival cases. Balance between sensitivity (“recall”) and the positive prediction value (“precision”) was inspected by the Precision-Recall (PR) curve and measured by its corresponding area under the PRC (AUPRC). The lower the PPV the higher the recall. Knowing when the PPV begins to drop sharply may help one to select a suitable threshold on the predicted probability.
Calibration was assessed by calibration graphs (calibration refers to the agreement between the predicted mortality and the observed and mortality (as estimated by the proportion of deceased patients). For example, if one expects a 24% chance of mortality for a sub-group of patients, the observed mortality rate should be about 24 out of 100 patients. Calibration can be visually measured, in a plot with predictions on the x-axis and the proportion of outcome on the y-axis. An ideal calibration implies points on the diagonal (45°) line.
We used 1000 bootstrap replicates to generate smooth calibration plots that represent the degree of agreement between the observed and predicted probabilities. Points on the 45° diagonal line show perfect agreement. The Brier Score (BS) was also measured which is a measure of the accuracy of the predicted probabilities. It is the mean quadratic difference between the predicted probability and the respective observed outcome. The lower the Brier score, the better.
Internal validation of the performance measures was achieved by 1000 bootstrap samples. In each sample a logistic regression model was fit and its performance on both the bootstrap sample itself and on the original dataset was calculated. The mean difference between these two estimates over all bootstrap samples is a measure of optimism. This optimism is subtracted from the apparent performance of the final model that is developed and tested on the original dataset. We report the final model along with its optimism-corrected performance along with its 95% confidence interval. This interval is based on the percentile method in which the highest and lowest 2.5% of the 1000 optimism estimates are discarded. The DeLong test was used to perform pairwise comparison between the AUC-ROCs (to demonstrate that the AUC-ROCs of two models are statistically different).
The Youden Index was used to determine the cut-off point on the predicted probabilities that results in the best trade-off between sensitivity and specificity. Based on this cut-off point sensitivity, specificity, positive predictive value, and the negative predictive values were calculated for all models. We used the R statistical environment (version 3.5.3) with R studio using the following packages: pROC, Hmisc, rms, and Resource Selection. This study is reported in accordance to the TRIPOD reporting statement.
Results
Table 2 shows the baseline characteristics of the included patients. A total of 3604 patients were included during the study period and 2330 patients remained after applying the exclusion criteria. The mean age of the included patients was 61 ± 18 years ranging from 18 to 65. Of the included patients, 53% were male. About 19% of the patients died in hospital.
Significant differences were observed between the survivors and non-survivors in terms of almost all vital signs and laboratory parameters in addition to ED risk scores, abnormal ECG, and recent stroke events. However, gender, temperature, diabetes, ventilation support, sodium, and hemoglobin levels were not significantly different between the groups.
Table 3 specifies the final models of all scoring systems in terms of their linear predictors. The table also shows the optimism-corrected performance measures. The WPS, SCS and MEWS have the highest optimism-corrected discrimination ability compared to the other models (see also Fig. 1). Pairwise comparisons of the AUC-ROCs are presented in Table 4. The SCS, WPS, and MEWS had a higher discrimination for prediction of in-hospital mortality among critically ill patients who are presented to the ED (AUC-ROC of 0.71, 0.73, and 0.70, respectively). The RAPS, REMS, and RLD models showed lower discrimination (AUC-ROCs < 0.68). In terms of discrimination power, the WPS model was significantly better than its counterparts except for SCS (P-value = 0.242). Moreover, the WPS, SCS, and MEWS had higher AUC-PR (0.42, 0.39, 0.36 respectively) which shows their ability to better balance sensitivity and the positive predictive value.

Left: The area under the Precision-Recall (PR) curve represents how a model balances the sensitivity and the positive predictive value. The y-axis represents the precision (positive predictive value in medical terms) and the x-axis represents recall (sensitivity). The AUCPR for SCS, WPS, RAPS, REMS, EWS, and RLD are 0.39, 0.42, 0.35, 0.34, 0.36, and 0.33 respectively. Right: The receiver operating characteristic (ROC) curves graphically represent sensitivity on the y-axis, and 1 - specificity on the x-axis. The area under the curve (AUC) gauges the discriminatory ability of a model. This area was: 0.714 for SCS, 0.727 for WPS, 0.661 for RAPS, REMS 0.678 for REMS, 0.699 for EWS and 0.657 for RLD in the ED.
Figure 2 shows the calibration plots of the six models. It is apparent that the degree of correspondence between the predicted and observed probabilities vary markedly between the models and that the calibration of the SCS, WPS, and REMS show good correspondence.

Calibration plots of the six models. A calibration plot is a measure of goodness-of-fit as a graphical presentation of the actual mortality probability versus the predicted mortality probability. The calibration plots of SCS, WPS and REMS do not deviate much from the diagonal line, which represents perfect calibration
Discussion
Severe overcrowding and shortage of resources (esp. personnel and medical equipment) have remained a concerning issues in any ED setting. The problem seems to be more prominent in developing countries. Accurate assessment and identification of the patients who are in high need of critical care is the most challenging task. Employing scoring systems has been suggested to achieve optimal use of limited resources. Furthermore, several previous studies have suggested the advantage of using scoring systems in improving patient turnover, resource allocation, and benchmarking [3].
Main findings
We performed a comparison of six scoring systems, in terms of their predictive performance. We found that the WPS had superior discrimination than the other models except for SCS (p = 0.242). The WPS had higher AUC-PR as well, which means this model provides a better balance between the positive predictive value and sensitivity across the graph. With respect to the overall performance of the accuracy of the predicted probabilities as measured by the Brier score, the RLD had the lowest value while the WPS has the highest. The Brier score indicates the errors between the predictions and actual outcomes. In general, the WPS and RAPS models had the highest accuracy compared with the other models. RAPS, RLD, and WPS showed the highest specificity values, and REMS showed the highest sensitivity value. However, in comparison with other models, REMS had the lowest specificity value. A model with high sensitivity but low specificity could be suitable for preliminary screening. On the other hand, a model with high specificity but relatively low sensitivity, could be more suitable for assigning individuals to a high-risk intervention. In the latter case, it is appropriate for assigning patients with high priority for CPR or the ICU where it is fully equipped with high-tech devices for resuscitation. Such a model is useful for individuals with high risk. The expected benefit is then proportional to the prevalence.
The WPS and SCS and REMS models showed good agreement between observed and predicted probabilities of in-hospital mortality during the entire range of predicted probabilities. The other models showed worse deviation from the diagonal line indicating their tendency to underestimate or overestimate the in-hospital mortality rate (Fig. 2). MEWS and RLD overestimate the mortality rate for the probabilities larger than 0.40. In contrast, RAPS underestimate the mortality rate in that range.
Furthermore, an NPV value greater than 0.86 for all models indicate that these models predict alive patients better than the deceased ones. This implies that in this population, more than 86% of the patients predicted to survive, have indeed survived. Since the PPV and NPV are ratios that includes both alive and deceased subjects, the predictive values are affected by the prevalence of the deceased cases and can differ between settings. The lower the prevalence of the deceased cases, the higher its NPV. On the other hand, the higher the prevalence of the deceased cases, the higher the PPV.
A potential important reason for the relatively low AUROC compared to its value for the original models, is that the original models are based on western populations and we now apply them on an Asian population. In addition, there might be differences in the type of equipment, the care methods, and treatment policies.
Generally, in clinical applications practicality and clinical sensibility are important, necessitating the use of a clear and interpretable clinical decision method. The need for a concise decision method could be much more pressing in the ED, where physicians often have no time to review patients due to the stressful environment. Models with more variables and complex non-linear functions of continuous predictors have the potential to perform better and provide more accurate predictions in general. Some researchers contend that reducing the complexity of models by categorizing continuous predictors or omitting predictors from a model is inappropriate since these techniques may have a negative impact on the model’s predictive performance. The aim of developing a prediction model is to provide a reliable model that can be transportable and adopted in clinical practice; therefore, it is important to settle on a relatively parsimonious model that does not forfeit significant predictive performance. Interestingly, our present study indicated that models with fewer variables such as the WPS and the MEWS performed similarly to or even better than models with more variables such as the SCS and the RLD.
Comparison to similar studies
Emergency models have been previously evaluated in different EDs around the world. However, to the best of our knowledge, this is the most comprehensive study comparing the predictive performance of the models based on six scoring systems (SCS, WPS, RAPS, REMS, MEWS, and RLD) to predict in-hospital mortality in a large sample of patients admitted to the emergency department. Table 5 lists and compares various studies performed in the ED settings.
As shown in Table 5, the lowest and highest mortality rates in similar studies were 3 and 57%, respectively. Moreover, the largest sample size belongs to the study on RLD (BHOM) with 24,696 participants with a 4.69% mortality rate. The median sample size of the similar studies was 1746 (IQR: 234–4857, min-max: 66–24,696). In 14 out of 17 studies, males formed the majority of participants.
The majority of the studies were single-centered studies. Some included patients with specific diseases such as Hepatic portal venous gas (HPVG), splenic abscess, and trauma from different centers [20, 25, 27, 31]. Findings of three studies showed that WPS was superior to REMS [3, 27, 33] which is consistent with the results of the current study. Moreover, Mirbaha et al. reported similar predictive performance for the WPS and a short version of REMS (RAPS) [30].
The Rapid Acute Physiology Score was developed in a different setting and patient population than the rest of the scoring systems. This system takes those elements of APACHE-II that can be obtained reliably on all patients in a hospital emergency department. It is still meaningful to compare this model to the other scoring systems, as has been done for example in [23,24,25].
As shown in Table 5, REMS is the most commonly evaluated model in the previously published studies. Of these studies, the REMS has excellent discrimination among patients who suffer from HPVG and trauma (AUC-ROC > = 0.90) while among most of studies inspecting the REMS on heterogeneous patients, the discrimination ability was in the fair range (AUC-ROC between 0.7 and 0.8).
Several studies have reported that REMS was superior to MEWS (2011 to 2019 in Israel, Taiwan, China, and Turkey) [20, 23, 24, 31], which is in contrast to the results of the current study and other evidence presented in Table 5 [3, 22, 27]. Consistent with our findings, researches from the United States and Turkey indicate that the performance of these two models is similar to each other [2, 3]. As demonstrated in Table 5, MEWS was associated with fair discrimination in five studies, besides the current study [2, 3, 21, 22, 27]. However, in contrast four studies reported poor AUC-ROCs [20, 23, 24, 29]. There weren’t any significant differences between the SCS and MEWS in terms of discriminatory ability which is in contrast to studies performed in China and Israel [24, 28].
In respect of calibration as presented in Table 5, WPS and REMS had fair calibration in four studies [2, 18, 25, 27, 31]. The RLD model was also associated with fair calibration in one study [16]. In contrast, one study reported inadequate calibration for REMS, RAPS, and MEWS [23]. It should be noted that the majority of studies used the Hosmer-Lemeshow goodness-of-fit test to evaluate the calibration. However, this test has some disadvantages, including sensitivity to the sample size (the larger the sample size the more the test tends to show significant deviations from the ideal calibration). Moreover, the test provides no information about the range of predicted probabilities where the model overestimates or underestimates the outcome variable [34].
This study has also limitations. First, we conducted a single center study which limits the generalizability of the results. However, this center was considered as the largest referral emergency department in the northeast of the country and included a wide spectrum of diseases. Second, exclusion of the patients who were referred to the special EDs (e.g. trauma, obstetrics, and etc.) results in the inapplicability of the models for these groups of patients.
Conclusions
In comparison to other models, the SCS and WPS revealed more successful discrimination in prediction in-hospital mortality. Moreover, SCS and WPS calibration plots showed good agreement between the predicted and observed mortality probabilities. There was no significant difference between the AUC-ROC of the SCS and WPS models. All models may benefit from recalibration on the external datasets and further validation studies are needed before warranting routine clinical use. Aside from the potential benefit from recalibration on the external datasets, and further validation studies, future studies should also attempt to develop more sensitive scoring systems before warranting routine clinical use.
Availability of data and materials
The datasets generated and/or analyzed during the current study are not publicly available due [REASON WHY DATA ARE NOT PUBLIC] but are available from the corresponding author on reasonable request.
References
Kellermann AL, Martinez R. The ER, 50 years on. New Engl J Med. 2011;364(24):2278–9.
Moseson EM, et al. Intensive care unit scoring systems outperform emergency department scoring systems for mortality prediction in critically ill patients: a prospective cohort study. J Intensive Care. 2014;2(1):40.
Gök RGY, Gök A, Bulut M. Assessing prognosis with modified early warning score, rapid emergency medicine score and worthing physiological scoring system in patients admitted to intensive care unit from emergency department. Int Emerg Nurs. 2019;43:9–14.
Sameera B. Comparative study of scoring systems in ICU and emergency department in predicting mortality of critically ill. Int J Res Med Sci. 2017;5(4):1352.
Rao M, Marella P, Kath B. Assessment of severity and outcome of critical illness. Indian J Anaesth. 2008;52(5):652–62.
McClish DK, Powell SH. How well can physicians estimate mortality in a medical intensive care unit? Med Decis Mak. 1989;9(2):125–32.
Knaus WA, et al. The APACHE III prognostic system: risk prediction of hospital mortality for critically III hospitalized adults. Chest. 1991;100(6):1619–36.
Le Gall J-R, et al. A simplified acute physiology score for ICU patients. Crit Care Med. 1984;12(11):975–7.
Maccariello E. Effects of early changes in organ dysfunctions on the outcomes of critically ill patients in need of renal replacement therapy. Clinics [online]. 2008;63(n. 3. ISSN, 1980. 5322):343–50.
Kellett J, Deane B. The simple clinical score predicts mortality for 30 days after admission to an acute medical unit. J Assoc Phys. 2006;99(11):771–81.
Duckitt R, et al. Worthing physiological scoring system: derivation and validation of a physiological early-warning system for medical admissions. An observational, population-based single-centre study. British J Anaesth. 2007;98(6):769–74.
Rhee KJ, Fisher CJ Jr, Willitis NH. The rapid acute physiology score. Ame J Emerg Med. 1987;5(4):278–82.
Olsson T, Terént A, Lind L. Rapid emergency medicine score: a new prognostic tool for in-hospital mortality in nonsurgical emergency department patients. J Intern Med. 2004;255(5):579–87.
Subbe C, et al. Validation of a modified early warning score in medical admissions. Qjm. 2001;94(10):521–6.
Prytherch D, et al. The use of routine laboratory data to predict in-hospital death in medical admissions. Resuscitation. 2005;66(2):203–7.
Faisal M, et al. Using routine blood test results to predict the risk of death for emergency medical admissions to hospital: an external model validation study. QJM Int J Med. 2016;110(1):27–31.
Rahmatinejad Z, Tohidinezhad F, Reihani H, Rahmatinejad F, Pourmand A, Abu-Hanna A, Eslami S. Prognostic utilization of models based on the APACHE II, APACHE IV, and SAPS II scores for predicting in-hospital mortality in emergency department. Am J Emerg Med. 2020;38(9):1841–6. https://doi.org/10.1016/j.ajem.2020.05.053. Epub 2020.
Rahmatinejad Z, Reihani H, Tohidinezhad F, Rahmatinejad F, Peyravi S, Pourmand A, Abu-Hanna A, Eslami S. Predictive performance of the SOFA and mSOFA scoring systems for predicting in-hospital mortality in the emergency department. Am J Emerg Med. 2019;37(7):1237–41. https://doi.org/10.1016/j.ajem.2018.09.011. Epub 2018.
Bulut M, et al. The comparison of modified early warning score with rapid emergency medicine score: a prospective multicentre observational cohort study on medical and surgical patients presenting to emergency department. Emerg Med J. 2014;31(6):476–81.
Imhoff BF, et al. Rapid emergency medicine score (REMS) in the trauma population: a retrospective study. BMJ Open. 2014;4(5):e004738.
Geier F, et al. Severity illness scoring systems for early identification and prediction of in-hospital mortality in patients with suspected sepsis presenting to the emergency department. Wien Klin Wochenschr. 2013;125(17–18):508–15.
Eick C, et al. Autonomic nervous system activity as risk predictor in the medical emergency department: a prospective cohort study. Crit Care Med. 2015;43(5):1079–86.
Wei X, Ma H, Liu R, Zhao Y. Comparing the effectiveness of three scoring systems in predicting adult patient outcomes in the emergency department. Medicine (Baltimore). 2019;98(5):e14289. https://doi.org/10.1097/MD.0000000000014289.
Cattermole G, et al. THERM: the resuscitation management score. A prognostic tool to identify critically ill patients in the emergency department. Emerg Med J. 2014;31(10):803–7.
Brabrand M, et al. Using scores to identify patients at risk of short term mortality at arrival to the acute medical unit: a validation study of six existing scores. Eur J Intern Med. 2017;45:32–6.
Hung S-K, et al. Comparison of the mortality in emergency department sepsis score, modified early warning score, rapid emergency medicine score and rapid acute physiology score for predicting the outcomes of adult splenic abscess patients in the emergency department. PLoS One. 2017;12(11):e0187495.
Seak C-J, et al. Rapid emergency medicine score: a novel prognostic tool for predicting the outcomes of adult patients with hepatic portal venous gas in the emergency department. PLoS One. 2017;12(9):e0184813.
Ghanem-Zoubi NO, et al. Assessment of disease-severity scoring systems for patients with sepsis in general internal medicine departments. Crit Care. 2011;15(2):R95.
Emmanuel A, Ismail A, Kellett J. Assessing the need for hospital admission by the cape triage discriminator presentations and the simple clinical score. Emerg Med J. 2010;27(11):852–5.
Park HO, Kim JW, Kim SH, Moon SH, Byun JH, Kim KN, Yang JH, Lee CE, Jang IS, Kang DH, Kim SC, Kang C, Choi JY. Usability verification of the Emergency Trauma Score (EMTRAS) and Rapid Emergency Medicine Score (REMS) in patients with trauma: A retrospective cohort study. Medicine (Baltimore). 2017;96(44):e8449. https://doi.org/10.1097/MD.0000000000008449.
Nakhjavan-Shahraki B, Baikpour M, Yousefifard M, Nikseresht ZS, Abiri S, Mirzay Razaz J, Faridaalaee G, Pouraghae M, Shirzadegan S, Hosseini M. Rapid Acute Physiology Score versus Rapid Emergency Medicine Score in Trauma Outcome Prediction; a Comparative Study. Emerg (Tehran). 2017;5(1):e30. Epub 2017.
Mirbaha S, Baratloo A, Karimi P. Value of physiological scoring systems in prediction of long-term mortality in traumatic brain injury patients. Hamara J. 2016;1(2):67–71.
Mirbaha S, Baratloo A, Karimi P. Value of physiological scoring systems in prediction of long-term mortality in traumatic brain injury patients. J Med Physiol. 2016;1(2):67–71.
Guffey D. Hosmer-lemeshow goodness-of-fit test: translations to the cox proportional hazards model; 2013.
Acknowledgments
This study was part of the first author PhD thesis and the authors would like to acknowledge Mashhad University of Medical Sciences for financial support.
Ethical issues
The permission was obtained from the Ethics Committee of Mashhad University of Medical Sciences.
Funding
This study was part of the first author thesis and the authors would like to acknowledge Mashhad University of Medical Sciences, Mashhad, Iran, for financial support.
Author information
Authors and Affiliations
Contributions
Zahra Rahmatinejad: Conceptualization, Methodology, Investigation, Formal analysis, Writing - original draft, review & editing. Fariba Tohidinezhad: Conceptualization, Methodology, review & editing. Fatemeh Rahmatinejad: Conceptualization, Methodology, Investigation, Writing - review & editing. Saeid Eslami: Conceptualization, Methodology, Formal analysis, Writing - review & editing; Ali Pourmand: Conceptualization, Methodology, Investigation, Writing - review & editing. Ameen Abu-Hanna: Conceptualization, Methodology, Formal analysis, Writing, review & editing. Hamidreza Reihani: Conceptualization, Methodology, Investigation, Writing - review & editing. The author(s) read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
The study was approved by the institutional review board of Mashhad University of Medical Sciences (Number: R.MUMS.REC.1398.011) and conformed to the Declaration of Helsinki principles. The need for informed consent was waived because of the nature of the study and the analysis used anonymous clinical data.
Consent for publication
Not applicable.
Competing interests
There is no conflict of interest to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Rahmatinejad, Z., Tohidinezhad, F., Rahmatinejad, F. et al. Internal validation and comparison of the prognostic performance of models based on six emergency scoring systems to predict in-hospital mortality in the emergency department. BMC Emerg Med 21, 68 (2021). https://doi.org/10.1186/s12873-021-00459-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12873-021-00459-7