
Abstract
Background
Machine learning (ML) can include more diverse and more complex variables to construct models. This study aimed to develop models based on ML methods to predict the all-cause mortality in coronary artery disease (CAD) patients with atrial fibrillation (AF).
Methods
A total of 2037 CAD patients with AF were included in this study. Three ML methods were used, including the regularization logistic regression, random forest, and support vector machines. The fivefold cross-validation was used to evaluate model performance. The performance was quantified by calculating the area under the curve (AUC) with 95% confidence intervals (CI), sensitivity, specificity, and accuracy.
Results
After univariate analysis, 24 variables with statistical differences were included into the models. The AUC of regularization logistic regression model, random forest model, and support vector machines model was 0.732 (95% CI 0.649–0.816), 0.728 (95% CI 0.642–0.813), and 0.712 (95% CI 0.630–0.794), respectively. The regularization logistic regression model presented the highest AUC value (0.732 vs 0.728 vs 0.712), specificity (0.699 vs 0.663 vs 0.668), and accuracy (0.936 vs 0.935 vs 0.935) among the three models. However, no statistical differences were observed in the receiver operating characteristic (ROC) curve of the three models (all P > 0.05).
Conclusion
Combining the performance of all aspects of the models, the regularization logistic regression model was recommended to be used in clinical practice.
Similar content being viewed by others

Background
Coronary artery disease (CAD) is one of the most common types of cardiovascular diseases [1]. World Health Organization (WHO) declares that approximately 17.9 million people are died of cardiovascular diseases in 2016, accounting for 31% of all mortality [2]. CAD patients are usually complicated with atrial fibrillation (AF), which may be associated with the overlap of common risk factors between CAD and AF [3,4,5]. Furthermore, the occurrence of AF is closely related to the unfavorable outcomes of CAD patients, including heart failure, cerebrovascular events, acute kidney injury, and in-hospital mortality [4, 6, 7]. Even in carefully treated patients, their prognosis can be worsened by the occurrence of AF [8]. Therefore, a tool predicting all-cause mortality in CAD patients with AF is necessary for the intervention and treatment.
Machine learning (ML) is usually used to develop a predictive model to predict various results, and the computer algorithms were applied into ML to identify patterns in large databases with multiple variables [9,10,11,12]. Motwani et al. developed a ML model for the prediction of 5-year all-cause mortality in patients with only CAD [9]. Al’Aref et al. used the random forest method to accurately predict the occurrence of in-hospital death after the percutaneous coronary intervention [13]. However, a prediction model predicting all-cause mortality in CAD patients with AF has not been developed. Furthermore, the performance of different ML method models in predicting the all-cause mortality in CAD patients with AF is unclear. Herein, we aimed to develop prediction models of all-cause mortality in CAD patients with AF based on different ML methods. In addition, the performance of different ML method models was compared to obtain the optimal model.
Methods
Study design and population
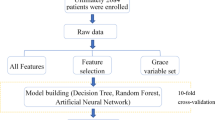
This study was a retrospective cohort study. Patients diagnosed with CAD and AF were collected from Zhengzhou University People’s Hospital between May 2012 and July 2016. The all-cause mortality was set as the outcome indicator. There were 2050 patients recorded, and 2042 patients were complicated with CAD and AF. Among which, 5 patients were excluded due to the lack of information on outcome indicators. Finally, 2037 patients remained in this study. According to the outcome variable, patients were divided into the death group and survival group. This study protocol was approved by the Institutional Review Board of Zhengzhou University People’s Hospital and was performed in accordance with the guidelines and regulations of the Helsinki Declaration. In addition, the informed consent was provided by all participants.
Data collection
A total of 58 patient-related variables were recorded including gender, age, number of hospitalizations, type of AF, type of CAD, diabetes mellitus, hypertension, heart failure, cardiac function, peripheral vascular disease, ischemic stroke, bleeding history, peptic-ulcer disease, drinking history, smoking history, cardioversion, percutaneous coronary intervention (PCI), CHA2DS2VASc score, HAS-BLED score, in-hospital medication (such as aspirin, warfarin, beta-blockers, etc.), in-hospital bleeding, embolization, out-of-hospital medication.
Machine learning models
Variable selection
Univariate analysis was used to select predictor variables. Variables with statistical differences between the death group and the survival group were included in the predictive model.
Model evaluation
Three ML methods (regularization logistic regression, random forest, and support vector machines) were used to develop predictive model. The model performance was quantified by calculating the area under the curve (AUC) with 95% confidence intervals (CI), sensitivity, specificity, and accuracy.
Model tuning
The ML process was performed using fivefold cross-validation, a common technique in data mining currently [14]. The selection of the optimal model was based on AUC value, and the parameter corresponding to the maximum AUC value was the optimal model parameter. The optimal model parameters were as follows: (1) the regularization logistic regression model, regularization (‘l1’, ‘l2’), regularization strength (0.1, 0.3, 0.5, 1.0, 3.0, 5.0, 10.0); (2) the random forest model, the number of decision trees (10, 20, 50, 100, 200, 500), the depth of decision tree (3, 4, 5, 6); (3) the support vector machines model, kernel function (‘linear’, ‘rbf’), penalty parameter (0.01, 0.05, 0.1, 0.5, 1, 10, 50).
Sample size and reproducibility analysis
Sample size
The purpose of this study was to develop models to predict all-cause mortality in CAD patients with AF. The sample size of this study was not large, therefore, whether the sample size of this study was sufficient to be evaluated by calculating the power of the model performance indicators (AUC, sensitivity, specificity, and accuracy). The power of the AUC, sensitivity, specificity, and accuracy were all 1.000, indicating that the sample size was sufficient (Additional file 1: Fig. S1).
Reproducibility analysis
To evaluate the reproducibility of the study, five different random number seeds were used to obtain five different training sets and test sets (all data sets were divided with a ratio of 7:3). The entire research process was conducted five times using five different training sets and test sets. The results showed that the model parameters obtained from different data sets had little change, indicating that the research was reproducible (Additional file 1: Table S1).
Statistical analysis
All statistical analyses were used the two-side test. Continuous variables were tested by the t-test, and expressed as mean ± SD, or by the Mann–Whitney U-test, and presented as median (interquartile range). Categorical variables were analyzed by the Chi-square test (χ2 test), and displayed as a number (n) and percentage (%). P < 0.05 was considered as statistical significance. All analyses were performed using SAS (version 9.4), Python (version 3.7), and Scikit-learn (version 0.21).
Missing data in variables (such as drinking history, smoking history) were adopted by the random forest filling method. Continuous variables (age, CHA2DS2VASc score, HAS-BLED score, etc.) were processed for data standardization to eliminate dimensional effects. The data set was divided into the training set and test set based on the ratio of 7:3.
Results
Baseline characteristics
A total of 2037 CAD patients with AF were included in this study, with a mean age of 72.26 ± 10.40 years, the median number of hospitalizations was 1.00 (1.00, 2.00), the media CHA2DS2VASc score was 3 (2.00, 5.00), and the mean HAS-BLED score was 2.04 ± 1.14. Of these patients, 1128 (55.38%) were men, only 125 (6.14%) patients were treated with PCI. Among the types of AF, 27 (1.33%) were initial patients, 1115 (54.74%) were paroxysmal patients, 490 (24.05%) were persistent patients, and 405 (19.88%) were permanent patients. In the type of CAD, 555 (27.25%) patients were stable type, 1420 (69.71%) were unstable type, and 62 (3.04%) were acute myocardial infarction. The all-cause mortality of CAD patients with AF was 6.77% (138 cases). Baseline characteristics were shown in Table 1. The study flowchart was displayed in Fig. 1.

The flowchart of the study process
Comparison of the survival group and the death group
The univariate analysis showed that age (t = − 9.804, P < 0.001), CHA2DS2VASc score (Z = 3.457, P = 0.005), HAS-BLED score (t = 3.726, P < 0.001), and the proportion of ischemic stroke (χ2 = 7.101, P = 0.008), bleeding history (χ2 = 10.768, P = 0.001), drinking history (χ2 = 10.744, P = 0.001), smoking history (χ2 = 5.966, P = 0.015), in-hospital bleeding (t = 3.726, P < 0.001), in-hospital medication of fondaparinux sodium (χ2 = 5.021, P = 0.025) of the death group were significantly higher than those of the survival group.
In addition, compared with the death group, the proportion of cardioversion (χ2 = 10.676, P = 0.001), PCI treatment (χ2 = 5.646, P = 0.018), in-hospital medication (such as aspirin (χ2 = 9.499, P = 0.002), warfarin (χ2 = 6.279, P = 0.012), beta-blockers (χ2 = 12.093, P < 0.001), lipid-lowering drugs (χ2 = 17.522, P < 0.001), and low-molecular-weight heparin (χ2 = 10.591, P = 0.001)), and out-of-hospital medication (such as aspirin (χ2 = 8.295, P = 0.004), clopidogrel (χ2 = 6.174, P = 0.013), warfarin (χ2 = 5.724, P = 0.017), ACEI/ARB (χ2 = 4.185, P = 0.041), beta-blockers (χ2 = 20.436, P < 0.001), statins (χ2 = 27.907, P < 0.001), nitrates (χ2 = 4.213, P = 0.040), and amiodarone (χ2 = 4.672, P = 0.031)) were higher in the survival group (Table 1).
Variable importance
After univariate analysis, 24 variables with statistical differences were included in the predictive model. The model coefficient was used to evaluate the importance of variables in the regularization logistic regression model and support vector machines model, while the Gini importance index was used for evaluation in the random forest model. The importance of variables based on the regularization logistic regression model was shown in Fig. 2. The main predictors for the regularization logistic regression model were as follows: out-of-hospital medication (statins, beta-blockers, nitrates, aspirin, and warfarin), bleeding history, in-hospital medication (low-molecular-weight heparin and warfarin), cardioversion, ischemic stroke, CHA2DS2VASc score, HAS-BLED score, and age, etc. The important variables for the random forest model were age, CHA2DS2VASc score, HAS-BLED score, out-of-hospital medication (statins and beta-blockers), in-hospital medication (lipid-lowering drugs, beta-blockers, and warfarin), and bleeding history, etc. (Fig. 3). Patient’s in-hospital bleeding, in-hospital medication (fondaparinux sodium, warfarin, and low-molecular-weight heparin), cardioversion, bleeding history, out-of-hospital medication (warfarin, nitrates, amiodarone, and statins), and drinking history, etc. were the important variables for the support vector machines model (Fig. 4).

The importance of variables based on the regularization logistic regression model

The importance of variables in the random forest model

The importance of variables based on the support vector machines model
Model performance comparison
The performance of the three models in the training set was summarized (Table 2). The regularization logistic regression model had the highest AUC (0.788; 95% CI 0.743–0.833) and specificity (0.708; 95% CI 0.683–0.733). The AUC of the random forest model and support vector machines model was 0.744 (95% CI 0.693–0.795) and 0.689 (95% CI 0.635–0.744), respectively. The performance of the three models in the test set shown in Table 3, the AUC of regularization logistic regression model, random forest model, and support vector machines model was 0.732 (95% CI 0.649–0.816), 0.728 (95% CI 0.642–0.813), and 0.712 (95% CI 0.630–0.794), respectively. The results of the models on the test set showed that the three models fit well.
According to the result of the DeLong test [15], the receiver operating characteristic (ROC) curve of the three models was analyzed for differences. As demonstrated in Fig. 5, no statistical difference was observed in the ROC curve (regularization logistic regression model vs. random forest model, P = 0.888; regularization logistic regression model vs. support vector machines model, P = 0.554; random forest model vs. support vector machines model, P = 0.724).

The difference of the receiver operating characteristic (ROC) curves among the three models
Discussion
In this study, three ML methods were used to predict the all-cause mortality in CAD patients with AF. The AUC of the regularization logistic regression model, random forest model, and support vector machines model was 0.732, 0.728, and 0.712, respectively. The regularization logistic regression model had the highest AUC value, specificity, and accuracy among the three models. However, the ROC curve of the three models had no significant difference. Although the three models had similar predictive capabilities, the regularization logistic regression model was recommended to be used in clinical practice, because it was simpler and more interpretable.
ML method is a form of artificial intelligence, and does not make a priori assumptions about causality, which distinguishes it from regression-based methods. ML had been widely used in the diagnosis and prognosis of CAD [12, 16, 17]. However, no studies developed a ML prediction model that can be used to predict all-cause mortality in CAD patients with AF. Our study provided three ML models to predict all-cause mortality in patients with CAD and AF. The AUC of the regularization logistic regression model was 0.732, which was the best among the three models. The study of Reeh et al. provided a more accurate model to predict the possibility of CAD based on the Diamon–Forrester prediction model [18]. Motwani et al. performed a ML model to predict 5-year all-cause mortality in patients with CAD. Their studies showed that ML combining clinical and coronary computed tomographic angiography data to predict 5-year all-cause mortality was found to be significantly better than existing clinical or coronary computed tomographic angiography metrics alone [9]. Existing studies have suggested that some biomarkers may predict the death of patients with CAD. Wada et al. presented that levels of vascular endothelial growth factor-C (VEGF-C) were inversely associated with all-cause mortality of CAD patients, and a low VEGF-C value may independently predict all-cause mortality [19]. In the study of Song et al., the increased risk of incident all-cause mortality was associated with higher baseline circulating 7-Ketocholesterol levels among CAD patients with stable conditions [20]. In the second prevention settings of CAD, Karakas et al. indicated that the single miRNAs derived from peripheral blood can be used as a biomarker to predict the mortality of CAD patients [21]. In future studies, researchers may try to incorporate some important biomarkers into the prediction model to obtain a better model.
In our three predictive models, the important variables of each model were different. For the regularization logistic regression model, out-of-hospital medication (statins, beta-blockers), bleeding history, etc. were more important. However, the important variables in the random forest model were patient’s age, CHA2DS2VASc score, HAS-BLED score, etc. The important variables in the support vector machines model were in-hospital bleeding, in-hospital medication of fondaparinux sodium and warfarin, etc. The difference in important variables among the three models was caused by the limitation of ML. More and more variables and interactions were used in ML to predict risk, but specific treatment goals that can reduce the risk may be difficult to determine [9]. However, some important variables in the three models were consistent, such as medication (statins, beta-blockers, warfarin, and low-molecular-weight heparin), bleeding history, and cardioversion. These variables should be noticed in clinical practice. A systematic meta-analysis showed that statin therapy was beneficial for the prevention of AF in CAD patients [22]. Joseph et al. conducted a systematic review that beta-blockers had important values in reducing the mortality and morbidity of myocardial infarction in CAD patients [23].
To the best of our knowledge, this was the first ML model to predict all-cause mortality of CAD patients with AF. In addition, we provided three prediction models based on three ML methods. The regularization logistic regression model had good predictive ability and was recommended to be used. The regularization logistic regression model may provide a tool to predict the all-cause mortality of CAD patients with AF, and provide clinicians with early intervention for patients who may be at high risk of mortality, which has important clinical significance for improving the prognosis of patients. However, this study had some limitations. First, the randomness of the selection of different model variables in ML cannot derive consistent important variables, which will bring difficulties in the prevention and treatment of disease. Second, the model of internal validation fit well, but external validation of the prediction models was necessary. Third, the sample size of this study was not larger, and future studies may require larger sample sizes to provide more reliable results.
Conclusion
This study used three models to predict the all-cause mortality of CAD patients with AF based on ML methods. No significant difference was observed in the three models. Combining the performance of all aspects of the models, the regularization logistic regression model was recommended to be used in clinical practice. A better model based on large samples and multiple centers will be needed in future studies.
Availability of data and materials
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- ML:
-
Machine learning
- CAD:
-
Coronary artery disease
- AF:
-
Atrial fibrillation
- AUC:
-
Area under the curve
- CI:
-
Confidence intervals
- WHO:
-
World Health Organization
- PCI:
-
Percutaneous coronary intervention
References
Mastoi Q, Wah T, Gopal Raj R, Iqbal U. Automated diagnosis of coronary artery disease: a review and workflow. Cardiol Res Pract. 2018;2018:2016282.
Cardiovascular Diseases. World Health Organization. https://www.who.int/en/newsroom/fact-sheets/detail/cardiovascular-diseases-(cvds).
Liang F, Wang Y. Coronary heart disease and atrial fibrillation: a vicious cycle. Am J Physiol Heart Circ Physiol. 2021;320(1):H1-h12.
Sutton N, Seth M, Ruwende C, Gurm H. Outcomes of patients with atrial fibrillation undergoing percutaneous coronary intervention. J Am Coll Cardiol. 2016;68(9):895–904.
Kralev S, Schneider K, Lang S, Süselbeck T, Borggrefe M. Incidence and severity of coronary artery disease in patients with atrial fibrillation undergoing first-time coronary angiography. PLoS ONE. 2011;6(9):e24964.
Chan W, Ajani AE, Clark DJ, Stub D, Andrianopoulos N, Brennan AL, et al. Impact of periprocedural atrial fibrillation on short-term clinical outcomes following percutaneous coronary intervention. Am J Cardiol. 2012;109(4):471–7.
Bramlage P, Cuneo A, Zeymer U, Hochadel M, Richardt G, Silber S, et al. Prognosis of patients with atrial fibrillation undergoing percutaneous coronary intervention receiving drug eluting stents. Clin Res Cardiol. 2013;102(4):289–97.
Michniewicz E, Mlodawska E, Lopatowska P, Tomaszuk-Kazberuk A, Malyszko J. Patients with atrial fibrillation and coronary artery disease—double trouble. Adv Med Sci. 2018;63(1):30–5.
Motwani M, Dey D, Berman DS, Germano G, Achenbach S, Al-Mallah MH, et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur Heart J. 2017;38(7):500–7.
Deo RC. Machine learning in medicine. Circulation. 2015;132(20):1920–30.
Arsanjani R, Xu Y, Dey D, Vahistha V, Shalev A, Nakanishi R, et al. Improved accuracy of myocardial perfusion SPECT for detection of coronary artery disease by machine learning in a large population. J Nucl Cardiol. 2013;20(4):553–62.
Nakanishi R, Slomka PJ, Rios R, Betancur J, Blaha MJ, Nasir K, et al. Machine learning adds to clinical and cac assessments in predicting 10-year CHD and CVD deaths. JACC Cardiovasc Imaging. 2020;14(3):615–25.
Al’Aref SJ, Singh G, van Rosendael AR, Kolli KK, Ma X, Maliakal G, et al. Determinants of in-hospital mortality after percutaneous coronary intervention: a machine learning approach. J Am Heart Assoc. 2019;8(5):e011160.
Witten IH, Frank E, Hall MA. Data mining: practical machine learning tools and techniques, 3rd edn; 2011. 1–629.
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44(3):837–45.
Johnson KM, Johnson HE, Zhao Y, Dowe DA, Staib LH. Scoring of coronary artery disease characteristics on coronary CT angiograms by using machine learning. Radiology. 2019;292(2):354–62.
Abdar M, Książek W, Acharya UR, Tan RS, Makarenkov V, Pławiak P. A new machine learning technique for an accurate diagnosis of coronary artery disease. Comput Methods Programs Biomed. 2019;179:104992.
Genders TS, Steyerberg EW, Alkadhi H, Leschka S, Desbiolles L, Nieman K, et al. A clinical prediction rule for the diagnosis of coronary artery disease: validation, updating, and extension. Eur Heart J. 2011;32(11):1316–30.
Wada H, Suzuki M, Matsuda M, Ajiro Y, Shinozaki T, Sakagami S, et al. VEGF-C and mortality in patients with suspected or known coronary artery disease. J Am Heart Assoc. 2018;7(21):e010355.
Song J, Wang D, Chen H, Huang X, Zhong Y, Jiang N, et al. Association of plasma 7-ketocholesterol with cardiovascular outcomes and total mortality in patients with coronary artery disease. Circ Res. 2017;120(10):1622–31.
Karakas M, Schulte C, Appelbaum S, Ojeda F, Lackner KJ, Münzel T, et al. Circulating microRNAs strongly predict cardiovascular death in patients with coronary artery disease-results from the large AtheroGene study. Eur Heart J. 2017;38(7):516–23.
Zhou X, Du JL, Yuan J, Chen YQ. Statin therapy is beneficial for the prevention of atrial fibrillation in patients with coronary artery disease: a meta-analysis. Eur J Pharmacol. 2013;707(1–3):104–11.
Joseph P, Swedberg K, Leong DP, Yusuf S. The evolution of β-blockers in coronary artery disease and heart failure (part 1/5). J Am Coll Cardiol. 2019;74(5):672–82.
Acknowledgements
We thank the participants included in our study for their contributions.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
X.Y.L. J.C.J., W.L.X. performed statistical analysis. L.L.W., H.L.S., and G.A.L. acquired the data. X.Y.L. and F.L. conceived and designed the research. X.Y.L. and F.L. drafted the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Institutional Review Board of Zhengzhou University People’s Hospital, and all participants provided informed consent.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Sample size and reproducibility analysis.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Liu, X., Jiang, J., Wei, L. et al. Prediction of all-cause mortality in coronary artery disease patients with atrial fibrillation based on machine learning models. BMC Cardiovasc Disord 21, 499 (2021). https://doi.org/10.1186/s12872-021-02314-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12872-021-02314-w