
Abstract
Background
GenoLab M is a recently established next-generation sequencing platform from GeneMind Biosciences. Presently, Illumina sequencers are the globally leading sequencing platform in the next-generation sequencing market. Here, we present the first report to compare the transcriptome and LncRNA sequencing data of the GenoLab M sequencer to NovaSeq 6000 platform in various types of analysis.
Results
We tested 16 libraries in three species using various library kits from different companies. We compared the data quality, genes expression, alternatively spliced (AS) events, single nucleotide polymorphism (SNP), and insertions–deletions (InDel) between two sequencing platforms. The data suggested that platforms have comparable sensitivity and accuracy in terms of quantification of gene expression levels with technical compatibility.
Conclusions
Genolab M is a promising next-generation sequencing platform for transcriptomics and LncRNA studies with high performance at low costs.
Similar content being viewed by others

Background
The past dozens of years have witnessed a new era in functional genomics using sequencing technologies [1]. The launch of the Roche 454 sequencer opened the era of next-generation sequencing (NGS) [2]. Compared with the traditional Sanger sequencing technology [3], NGS has significantly higher throughput and reduced costs [1]. Taking advantages of the power of NGS, transcriptome and Long non-coding RNA (LncRNA) sequencing has been accepted as a mainstream profiling technique to reveal gene regulatory networks in both animals and plants [4].
In the short history of NGS era, many sequencing platforms have emerged: Roche 454, Illumina series (GA, HiSeq, NextSeq, NovaSeq, etc.) [5], BGI (BGISEQ-500) [6], Ion Torrent [7], GenapSys [8]. These platforms employ different sequencing chemistry and detection approaches, and each of them has specific advantages and shortcomings [9]. After years of technology evolution and product commercialization, Illumina sequencers become the most widely used platform. However, the high instrument and reagent cost hinders broader applications [10]. In recent years, BGI’s MGI sequencers have received more attention in their cost effectiveness [11], though BGI’s unique DNB (DNA Nanoball) sequencing approach requires complicated library preparation and quality control procedure [12,13,14,15]. As DNA sequencing applications increase in different research fields and clinical settings, there is still a need to develop sequencers that are accurate, flexible, and cost-efficient for applications.
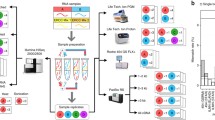
Recently, GeneMind Biosciences Company Limited (GeneMind), launched a new sequencing instrument (GenoLab M™) based on their previous work on GenoCare™ single molecule sequencer [16]. An overview of the mechanism of GenoLab M DNA sequencer is outlined in Fig. 1. The GenoLab M sequencer employs sequencing-by-synthesis (SBS) techniques and applies reversible termination approaches. In a sequencing run, a double-stranded target DNA library is constructed with generic adaptor sequences. The library is denatured to create single-stranded templates, which are captured on the surface of flow cell through hybridization to randomly pre-immobilized complimentary oligonucleotide. Surface-based amplification is performed after target DNA template capture to enhance signal-to-noise ratio of sequencing. The amplified DNA colonies on the flow cell are then hybridized to a sequencing primer, which contains an adaptor-complimentary sequence. Next, Fluorescence-dye labeled nucleotides and a polymerase are applied to start the sequencing cycle. In each cycle, the nucleotides’ terminator structure ensures only one nucleotide is incorporated by the polymerase on each extending primer. Four-color fluorescence signals from the labels are collected by a scanning optical system, and the terminator structure is cleaved to initiate the next sequencing cycle. The fluorescence image data through all cycles are then combined and color-corrected to generate the raw basecall data. Finally, Sequencing quality score are assigned to each base, DNA reads with the corresponding quality scores are combined to produce the final fastq file.

Sequencing Workflow of GenoLab M
NovaSeq 6000, launched in June, 2017, relies on Illumina’s SBS chemistry and two-color reversible terminator-based method. Combined with patterned flow cell technology [17], in excess of 3000 Gb of data can be sequenced on an S4 flow cell.
Previously, GenoLab M’s performance on transcriptome and LncRNA has not yet been evaluated by the scientific community. Here, we characterized the performance of GenoLab M on transcriptome and LncRNA by parallel comparison with NovaSeq 6000 from Illumina, Inc. on three different species: mouse, bean, and human. The raw data quality, gene expression level, alternatively spliced (AS) events, single nucleotide polymorphism (SNP), and insertions–deletions (InDel) analysis from the two sequencing platforms are compared. The data suggest that the GenoLab M is a promising sequencing platform for transcriptomics and LncRNA studies in animal, plant and human with comparable performance at lower cost.
Method
Samples preparation and RNA extraction
Mouse testicular tissue, human Lieming Xu-2 cells and bean hairy root tissue were collected for RNA extraction. RNAs were extracted by HiPure Universal RNA Mini Kit (Guangzhou Magen Biotechnology Co., Ltd.). Total RNA concentration and purity and integrity were measured via NanoDrop 2000 (Thermo Fisher Scientific, Wilmington, DE) and RNA Nano 6000 Assay Kit of the Agilent Bioanalyzer 2100 system (Agilent Technologies, CA, USA), respectively.
Transcriptome and LncRNA sequencing
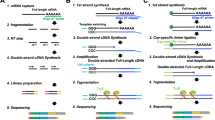
Transcriptome library construction were performed by Hieff NGS Ultima Dual-mode mRNA Library Prep Kit for Illumina (Yeasen Biotechnology (Shanghai) Co., Ltd., China), Fast RNA-seq Lib Prep Module for Illumina (ABclonal Technology Co.,Ltd., China), TIANSeq Stranded RNA-Seq Kit (Illumina) (TIANGEN Biotech (Beijing) Co., Ltd., China) and VAHTS Universal V6 RNA-seq Library Prep Kit for Illumina (Vazyme Biotech Co., Ltd., China). These mRNA libraries were marked as Mouse, Human or Bean_mRNA_YS, AB, TG or VZ. LncRNA library were constructed via Hieff NGS Ultima Dual-mode RNA Library Prep Kit for Illumina and Hieff NGS MaxUp rRNA Depletion Kit (human/mouse/rat) (Yeasen Biotechnology (Shanghai) Co., Ltd., China), VAHTS Universal V6 RNA-seq Library Prep Kit for Illumina and Ribo-off rRNA Depletion Kit (Human/Mouse/Rat) (Vazyme Biotech Co.,Ltd., China), TIANSeq Stranded RNA-Seq Kit (Illumina) and TIANSeq rRNA Depletion Kit (H/M/R) (NR101-TA) (TIANGEN Biotech (Beijing) Co.,Ltd.,China). These libraries were marked as Mouse or Human_LncRNA_YS, VZ or TG. After library QC, they were subjected to NovaSeq 6000 and GenoLab M sequencing in PE150 or PE100 mode.
Cross-platform mRNA and LncRNA sequencing data analysis
Raw sequencing reads in fastq format were processed through a GeneMind in-house perl pipeline. Reads containing adapter, ploy-N or low-quality reads were filtered out to get clean reads. These clean reads were then mapped to the reference genome sequence with a perfect match or one mismatch method via HISAT2 tools software [18]. The corresponding genome references were downloaded from ensemble database by ftp://ftp.ensembl.org/pub/release-101/fasta/homo_sapiens/dna/, ftp://ftp.ensembl.org/pub/release-101/fasta/mus_musculus/dna, and ftp://ftp.ensemblgenomes.org/pub/plants/release-48/fasta/glycine_max/dna/. StringTie [19] was then used for transcript reconstruction. As candidate genes were defined as genes which were mapping to unannotated transcribed region, meanwhile, coding peptide was more than 50 amino acid residues with two or more exons. SNP and InDel calling was carried out by using GATK [20], furthermore, SnpEff [21] was used to annotate these mutations. Raw vcf files were filtered with GATK standard filter method and other parameters (clusterWindowSize:10; MQ0 > = 4 and (MQ0/(1.0*DP)) > 0.1; QUAL < 10; QUAL < 30.0 or QD < 5.0 or HRun > 5), and only SNPs with distance > 5 were retained. Alternative spliced events were identified by ASprofle software [22]. Expression values of candidate genes (FPKM) were calculated by RSEM [23].
For LncRNA identification, bioinformatic pipeline was performed according to published methods [24] with minor modifications. The transcriptome was assembled using the StringTie based on the reads mapped to the reference genome. The known LncRNAs from the assembled transcripts are defined using the Cuffcompare program from the Cufflinks package. The remaining transcripts (unknown transcripts) were used to screen for putative LncRNAs. Transcripts of more than 200 nt length and two exons were selected as candidate LncRNA transcripts. Then, CPC [25], CNCI [26], Pfam [27] and CPAT [28] were used to distinguish the protein-coding genes from the non-coding genes, and inter set as putative LncRNA. As well as the different types of LncRNAs including lincRNA, intronic LncRNA, anti-sense LncRNA, sense LncRNA were selected using gffcompare. StringTie (1.3.1) [29] was used to calculate FPKMs of LncRNAs. The FPKM of novel LncRNAs must be ≥0.1.
Results
Base and raw data quality
Following RNA extraction, two aliquots of each extract were constructed as Illumina libraries, respectively, using identical amounts of starting material, and then subsequently sequenced to facilitate bioinformatic comparisons on the data. In addition, to verify the compatibility of the library preparation kit for GenoLab M, we used kits from different manufacturers for testing (Supplemental Table S1). The sequencing strategy was pair-end 100 bp for GenoLab M and paired-end 150 bp for NovaSeq 6000. We initially generated between 23.20 M to 62.87 M clean reads per library in NovaSeq 6000 platform, and 26.86 M to 139.69 M clean reads per library in GenoLab M platform (Table 1). Each individual sample has similar base throughput from both sequencing platforms. The quality of sequencing data was checked using FastQC. For high base quality (over Q20) base percentages, the GenoLab M showed an average of 94.86%, and the NovaSeq 6000 showed an average of 97.50% with a slight preponderance (Table 1). As shown in Fig. 2, the clean reads from GenoLab M reached an average mapping rate of 91.80% and an average unique mapping rate of 88.33%, which are comparable to the mapping rates of reads from the NovaSeq 6000 platform. The two platforms shared fairly consistent reads distribution along genes across species (Fig. 3) and in expression density distribution (Fig. 4). Interestingly, the LncRNA expression level measured using Yeasen LncRNA library kit (YS) is higher than the other kits used in human and mouse. In Fig. 5, the charts showed that accuracy in the quantification of both low and high abundance genes were consistent. They further indicate that LncRNA expression by YS has obviously higher abundancy than the other kits in human and mouse (Fig. 5 A and B), which is consistent with the Fig. 4 B and D. Overall, the sequence quality of the two platforms was similar across various library kits.

Comparison of sequencing quality between GenoLab M and NovaSeq 6000 in genome mapping rate. A Transcriptome of mouse, B LncRNA of mouse, C Transcriptome of human, D LncRNA of human, E Transcriptome of bean. AB_, VZ_, YS_,TG_ means library kits from four companies

Comparison of sequencing quality between GenoLab M and NovaSeq 6000 in Reads distribution along the relative position of genes. A Transcriptome of mouse, B LncRNA of mouse, C Transcriptome of human, D LncRNA of human, E Transcriptome of bean. M_, H_ and B_ means mouse, human and bean, AB_, VZ_, YS, TG_ means library kits from four companies, N and G means Novaseq 6000 and GenoLab M

Repeatability of gene detection and quantifcation between GenoLab M and NovaSeq 6000 in expression density distribution. A Transcriptome of mouse, B LncRNA of mouse, C Transcriptome of human, D LncRNA of human, E Transcriptome of bean. M_, H_ and B_ means mouse, human and bean, AB_, VZ_, YS, TG_ means library kits from four companies, N and G means Novaseq 6000 and GenoLab M

Gene and lncRNA detection and quantifcation between GenoLab M and NovaSeq 6000 in boxplot graph of A human, B mouse, C bean. AB_, VZ_, YS_,TG_ means library kits from four companies, N and G means Novaseq 6000 and GenoLab M
Inter-platforms comparison of gene detection and quantification
In transcriptome and LncRNA analysis, the identification of genes is very important for the majority of research projects. Therefore, we further compared the capacity of GenoLab M and NovaSeq 6000 platforms on gene detection and quantification. Totally over 42,000, 16,000 and 26,000 genes were identified in bean, human, and mouse, respectively, via two sequencing platforms (Fig. 6A, Fig.S1A&B). For transcriptome, we observed a small fraction of different genes between the GenoLab M and NovaSeq 6000 platforms. Over 92% of genes were commonly detected by both sequencing platforms. However, for LncRNA, only 71% of genes were shared between the two sequencing platforms (Fig. 6B, Fig. S1C). This difference most likely stemmed from analysis using the method StringTie as novel LncRNAs judgment and the different read length of the sequence [19]. StringTie (1.3.1) was used to calculate FPKMs of LncRNAs and novel LncRNA was set at least 0.1. We checked the Pearson correlation coefficient of the transcriptome and LncRNA data produced by the two platforms using the same methods and found that all one pairs of samples showed high correlation coefficients, ranging from 0.972 to 0.992 in transcriptome, and ranging from 0.691 to 0.793 in LncRNA (Fig. 7). There is still a slight gap in the correlation between LncRNA and the two platforms. In all, GenoLab M has remarkable inter-platforms concordance with NovaSeq 6000, suggesting that GenoLab M could substitute NovaSeq 6000 in many application fields where transcriptome and LncRNA are the primary focus.

Venn diagram of genes expression FPKM between GenoLab M and NovaSeq 6000 in mouse. A Transcriptome, B LncRNA. AB_, VZ_, YS_,TG_ means library kits from four companies, N and G means Novaseq 6000 and GenoLab M

Scatter plots of gene expression values of the four pairs of samples produced using the NovaSeq 6000 and GenoLab M sequencers. Gene expression values are represented as the base 2 logarithm of FPKM. The Pearson correlation coefficients of the 16 samples were between 0.69 and 0.99. A Transcriptome of bean, B Transcriptome of human, C Transcriptome of mouse, D LncRNA of human, E LncRNA of mouse
Detection of alternative splicing
As one of the major mechanisms to generate transcriptome diversity, alternative splicing (AS) is gaining more and more attention in recent years. In this context, the ability of each sequencing platform under comparison to detect splicing junctions and corresponding alternative splicing patterns were subsequently analyzed across transcriptomes. In mouse, 53,557, 59,709 and 53,014, 56,741, 64,105 and 48,089 AS events could be detected by GenoLab M and NovaSeq 6000, respectively. Top three AS events in all libraries were TSS: Alternative 5′ first exon (transcription start site), TTS: Alternative 3′ last exon (transcription terminal site) and AE: Alternative exon ends (5′, 3′, or both) cross two platforms (Fig. 8 A). In mouse LncRNA data, the AS events component in mRNA presented similarly to transcriptome (Fig. 8 B). For human sample, AS events component in transcriptome and mRNA of LncRNA data were of the same pattern and Top 3 AS were TSS, TTS and SKIP:Skipped exon (SKIP_ON,SKIP_OFF pair) as showed in Fig. 8 C and D. In beans, 78,137, 82,558 and 105,038, 83,072, 84,526 and 90,580 AS events could be detected by GenoLab M and NovaSeq 6000, respectively. Top three AS events in all libraries were TSS, TTS and AE (Fig. 8 E). As for both the number and the type of different AS events, we found that there was no significant difference between the three species in the two platforms.

Alternative splicing events of mRNA and lncRNA FPKM between GenoLab M and NovaSeq 6000. A Transcriptome of bean, B Transcriptome of human, C Transcriptome of mouse, D LncRNA of human, E LncRNA of mouse. TSS: Alternative 5′ first exon (transcription start site), TTS: Alternative 3′ last exon (transcription terminal site), SKIP: Skipped exon (SKIP_ON,SKIP_OFF pair), XSKIP: Approximate SKIP (XSKIP_ON,XSKIP_OFF pair), MSKIP: Multi-exon SKIP (MSKIP_ON,MSKIP_OFF pair), XMSKIP: Approximate MSKIP (XMSKIP_ON,XMSKIP_OFF pair), IR: Intron retention (IR_ON, IR_OFF pair), XIR: Approximate IR (XIR_ON,XIR_OFF pair), MIR: Multi-IR (MIR_ON, MIR_OFF pair), XMIR: Approximate MIR (XMIR_ON, XMIR_OFF pair), AE: Alternative exon ends (5′, 3′, or both), XAE: Approximate AE
Identification of SNP and InDel mutation
SNP and InDel are crucial genomic features to reveal genetic variation. High throughput transcriptome analysis contributes to how these DNA variations can be transcribed into RNA messengers to affect subsequent protein function. Therefore, we examined the competency of the GenoLab M sequencing platform to detect SNP and InDel variations at the mRNA level. Regarding SNP detection, we found that SNPs called from the two sequencing platforms (Table 2) were highly similar in both variety and quantity. The largest difference is that the GenoLab M platform identified slightly more SNP events in mice than NovaSeq 6000 on average.
For InDel events, GenoLab M detected less of them than the NovaSeq 6000 in bean, human and mouse (Table 3). The closest InDel number was in bean sample prepared with Vazyme Biotech (VZ) transcriptome library kit, while significant difference was observed in mouse via Yeasen Biotechnology (YS) transcriptome library kit. These results suggest that GenoLab M has slightly inferior in InDel detection, probably due to shorter read length in this study.
Discussion
With the advantages of high-throughput and low cost, NGS is becoming a powerful tool for scientific and clinical research. Increased sequencing accessibility and flexibility have not only broadened NGS applications, but also led to the development of novel sequencing platforms and sequencing methods in turn [30]. Currently, Illumina’s sequencers are the globally leading sequencing platform. The NovaSeq 6000, its most powerful instrument, has prominent properties of lower error rate and less variation compared to other sequencers in the Illumina series [31]. It is able to generate 6 TB of sequencing data in a single run with a running cost between 12 and 18 USD/Gb [32]. GenoLab M, the new sequencer of GeneMind, can generate 300 Gb of sequence data in a single run with price per Gb cost less than half of that. In this study, we generated large transcript and LncRNA datasets from the two sequencing platforms across three model species (human: 4 mRNA, 3 LncRNA; mouse: 3 mRNA, 3 LncRNA; bean: 3 mRNA). Next, we compared the datasets obtained from the two platforms. To make our study as comprehensive as possible, we compared the quality of data, distribution of reads, gene expression, AS, SNP and InDel of the two platforms.
Our analysis of the data generated from two platforms showed that sequences from both instruments were of comparable quality with the exception that NovaSeq 6000 reads showed slightly higher Q20 percentage than GenoLab M. We are confident that higher quality data from GenoLab M are attainable through instrument hardware, software and reagent kit updates, given that the instrument was launched just last year [33, 34].
Gene expression has always been an important part of the research on transcriptome and LncRNA [34]. In the comparison of transcriptome genes expression, we found that there was no significant quality difference between the two platforms, and the correlation analysis showed high consistency. This indicates that GenoLab M can achieve a similar level of mRNA detection as NovaSeq 6000 and is suitable for use with the same library kits designed for Illumina sequencing. This compatibility enables users to test the sequencing platform with minimum transition cost and generate high quality sequencing data. We believe that this would make transcriptome sequencing more accessible for researchers. However, in the LncRNA area, we found that GenoLab M’s performance had a small gap compared to NovaSeq 6000 in terms of gene expression correlation. We think sequencing read length may impact the LncRNA detection rate [35]. We plan to conduct further laboratory tests to determine the cause of this difference.
Our experimental results proved that GenoLab M could obtain equivalent data quality as NovaSeq 6000, in both mRNA and LncRNA level with 7 library preparation kits from 4 companies. This suggests that GenoLab M can be a viable substitute for NovaSeq 6000 in the RNA sequencing. However, our study does lack biological repeats, which could be supplemented in further work. We also realize that we still need to increase the number of samples and species to further demonstrate the reliability of the GenoLab M platform. In the future, we plan to work with more researchers in broader application areas to verify the capability and stability of the platform.
Conclusions
In summary, we highlight that both GenoLab M and NovaSeq 6000 sequencing platforms have similar and comparable performance metrics (sensitivity and accuracy) and can capture genes, AS, and SNP at transcriptome and LncRNA levels. The GenoLab M offers a cost-effective alternative to the NovaSeq 6000 platform with similar data quality.
Availability of data and materials
The transcriptome and LncRNA data are in available at SRA database with SUB10177917 and SUB10176628, and can be downloaded by extract Code GMData in https://e-share.obs-website.cn-north-1.myhuaweicloud.com?token=qWLThbSnZgWWLy6t2a4fclhufssdkZDe/3/fC3VlxxVMb566Lbq4r+BTnK09LdfBGM7oGcHDf7zTbsEslDLqt15oyX4jumktMD5vQWxNtSeFF4qb2g1tvvZ02xi49VXUV2VcMW5MjekUW86kgWa4XaF0wAhw1fmDnUMGoI3MMb/iPkwj7gOaFNQ0RvRNBQbO0l1xVdor34j4jspNoiPfjI845l8MOe6nWbasiSUpWW6fpfLsTKWZxk30fnaWZe3Q9oMOu8h2abZbXyyhf4DhtYLZvjTM9K5jCGrERBA5LWjjyEYaZTx9/4QKf0Gy1iXGk9w/61Ub20trdgeliFgGrYN/jr9QOngRpdZWJ/sYaLSsAgWuU94R7SdjygvdZV4hViwlltsRcHUGArhnVqMe+uUg5Eb7O6X4fUCTz2AUdhMxsZBmuF2xjHAaV5EcvRZPkvw7+2EZ+nmfefxYCRBJgyP5Rfr7wMpUiuf/NsOIynyXxbJlHcN/ByYdkRdkWywk9/2w1YCpv4kNYHchhvC+gXB+NbRMByg3bQxT24G9jw430ynyN3P4+z9G/e78/XEEqJXK/9Z/BNbA56sOiT6RsA==. The transcriptome and LncRNA data are deposited at the CNGB Sequence Archive (https://db.cngb.org/cnsa/) under project accession number CNP0002262.
Change history
26 January 2022
A Correction to this paper has been published: https://doi.org/10.1186/s12864-022-08307-z
References
Zheng J, Zhang H, Banerjee S, Li Y, Zhou J, Yang Q, et al. A comprehensive assessment of next-generation sequencing variants validation using a secondary technology. Mol Genet Genom Med. 2019;7(7):e00748. https://doi.org/10.1002/mgg3.748.
Margulies M, Egholm M, Altman WE, Attiya S, Bader JS, Bemben LA, et al. Genome sequencing in microfabricated high-density picolitre reactors. Nature. 2005;437(7057):376–80. https://doi.org/10.1038/nature03959.
Sanger F, Nicklen S, Coulson AR. DNA sequencing with chain-terminating inhibitors. Proc Natl Acad Sci U S A. 1977;74(12):5463–7. https://doi.org/10.1073/pnas.74.12.5463.
Xu Y, Lin Z, Tang C, Tang Y, Gao Q. A new massively parallel nanoball sequencing platform for whole exome research. BMC Bioinformatics. 2019;20(1):1-9.
Bentley DR, Balasubramanian S, Swerdlow HP, Smith GP, Milton J, Brown CG, et al. Accurate whole human genome sequencing using reversible terminator chemistry. Nature. 2008;456(7218):53–9. https://doi.org/10.1038/nature07517.
Huang J, Liang X, Xuan Y, Geng C, Li Y, Lu H, et al. A reference human genome dataset of the BGISEQ-500 sequencer. Gigascience. 2017;6(5):gix024.
Rothberg JM, Hinz W, Rearick TM, Schultz J, Mileski W, Davey M, et al. An integrated semiconductor device enabling non-optical genome sequencing. Nature. 2011;475(7356):348–52. https://doi.org/10.1038/nature10242.
Esfandyarpour H, Parizi KB, Barmi MR, Rategh H, Witney FR. High accuracy DNA sequencing on a small, scalable platform via electrical detection of single base incorporations; 2019.
Goodwin S, McPherson JD, McCombie WR. Coming of age: ten years of next-generation sequencing technologies. Nat Rev Genet. 2016;17(6):333–51. https://doi.org/10.1038/nrg.2016.49.
A., S. ILLUMINA TO SEQUENCE 100,000 U.K. GENOMES. Chem Eng News. 2014;92(32):11.
Huang J, Liang X, Xuan Y, Geng C, Li Y, Lu H, et al. A reference human genome dataset of the BGISEQ-500 sequencer. Gigascience. 2017;5(5):1–9. https://doi.org/10.1093/gigascience/gix024.
Zhu FY, Chen MX, Ye NH, Qiao WM, Bei G, Wai-Ki L, et al. Comparative performance of the BGISEQ-500 and Illumina HiSeq4000 sequencing platforms for transcriptome analysis in plants. Plant Methods. 2018;14(1):69.
Sandoval-Velasco M, Rodríguez J, Perezestrada C, Zhang G, Smith O. Hi-C chromosome conformation capture sequencing of avian genomes using the BGISEQ-500 platform. GigaScience. 2020;9(8):giaa087. https://doi.org/10.1093/gigascience/giaa087.
Hak-Min K, Sungwon J, Oksung C, Hoon JJ, Hui-Su K, Asta B, et al. Comparative analysis of 7 short-read sequencing platforms using the Korean reference genome: MGI and Illumina sequencing benchmark for whole-genome sequencing. GigaScience. 2021;3:3.
Wang Y, Dai Z, Zhang Z, Zhu L, Jiang L. Draft genome sequence of a multidrug-resistant Stenotrophomonas sp. B1–1 strain isolated from radiation-polluted soil and its pathogenic potential. J Glob Antimicrob Resist. 2020;24:121–3.
Zhao L, Deng L, Li G. Single molecule sequencing of the M13 virus genome without amplification. PLoS One. 2017;12(12):34209. https://doi.org/10.1371/journal.pone.0188181.
Kumar KR, Cowley MJ, Davis RL. Next-generation sequencing and emerging technologies. Thieme Medical Publishers. 2019;45:661–73.
Kim D, Langmead B, Salzberg SL. HISAT: A fast spliced aligner with low memory requirements. Nat Methods. 2015;12(4):360. https://doi.org/10.1038/nmeth.3317.
Pertea M, Pertea GM, Antonescu CM, Chang TC, Mendell JT, Salzberg SL. StringTie enables improved reconstruction of a transcriptome from RNA-seq reads. Nat Biotechnol. 2015;33(3):290–5. https://doi.org/10.1038/nbt.3122.
Mckenna A, Hanna M, Banks E, Sivachenko A, Cibulskis K, Kernytsky A, et al. The genome analysis toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010;20(9):1297–303. https://doi.org/10.1101/gr.107524.110.
Cingolani P, Platts A, Wang LL, Coon M, Nguyen T, Wang L, et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff. Fly. 2012;6(2):80–92. https://doi.org/10.4161/fly.19695.
Florea L, Song L, Salzberg SL. Thousands of exon skipping events differentiate among splicing patterns in sixteen human tissues. F1000 Res. 2013;2:188.
Dewey CN, Li B. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics. 2011;12(1):323. https://doi.org/10.1186/1471-2105-12-323.
Luo H, Bu D, Sun L, Fang S, Liu Z, Yi Z. Identification and function annotation of long intervening noncoding RNAs. Brief Bioinform. 2017;18:789–97. https://doi.org/10.1093/bib/bbw046.
Sun L, Luo H, Bu D, Zhao G, Yu K, Zhang C, et al. Utilizing sequence intrinsic composition to classify protein-coding and long non-coding transcripts. Nucleic Acids Res. 2013;17(17):e166. https://doi.org/10.1093/nar/gkt646.
Kai C, Lei W, Xu C, Zhang X, Xing L, Zuo H, et al. Influence on surgical treatment of intertrochanteric fracture with or without preoperative skeletal traction. Chinese J Joint Surg (Electronic Edition). 2015;41(6):e74.
Bateman A. The Pfam protein families database. Nucleic Acids Res. 2000;28(1):263–6. https://doi.org/10.1093/nar/28.1.263.
Chen G, Wang Z, Wang D, Qiu C, Liu M, Xing C, et al. LncRNADisease: a database for long-non-coding RNA-associated diseases. Nucleic Acids Res. 2013;D1(D1):D983–6. https://doi.org/10.1093/nar/gks1099.
Kim D, Leek JT, Pertea GM, Salzberg SL. Transcript-level expression analysis of RNA-seq experiments with HISAT, StringTie and Ballgown. Nat Protoc Erecipes Res. 2016;11(9):1650-67.
Mardis ER. The impact of next-generation sequencing technology on genetics. Trends Genet. 2008;24(3):133–41. https://doi.org/10.1016/j.tig.2007.12.007.
Jeon SA, Park JL, Park SJ, Kim JH, Kim SY. Comparison between MGI and Illumina sequencing platforms for whole genome sequencing. Genes Genomics. 2021;43(7):713-24.
Jeon SA, Park JL, Kim J-H, Kim JH, Kim YS, Kim JC, et al. Comparison of the MGISEQ-2000 and Illumina HiSeq 4000 sequencing platforms for RNA sequencing. Genomics Inform. 2019;17(3):e32. https://doi.org/10.5808/GI.2019.17.3.e32.
Raine A, Liljedahl U, Nordlund J. Data quality of whole genome bisulfite sequencing on Illumina platforms. PLoS One. 2018;13(4):e0195972. https://doi.org/10.1371/journal.pone.0195972.
Wainberg M, Sinnott-Armstrong N, Mancuso N, Barbeira AN, Knowles DA, Golan D, et al. Opportunities and challenges for transcriptome-wide association studies. Nat Genet. 2019;51(4):592–9. https://doi.org/10.1038/s41588-019-0385-z.
Deveson IW, Hardwick SA, Mercer TR, Mattick JS. The dimensions, dynamics, and relevance of the mammalian noncoding transcriptome. Trends Genet. 2017;33(7):464–78. https://doi.org/10.1016/j.tig.2017.04.004.
Acknowledgements
We would like to thank all current and past members of the GeneMind team who contributed to the development of the sequencing technology.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
Lei Sun conceived and designed the research, reviewed and revised the manuscript. Yongfeng Liu and XiaoChao Zhao wrote the manuscript. Zhiliang Zhou reviewed and revised the manuscript. Ran Han and Yukun Ma and performed sample prepared and RNA extract, and preliminary analysis. Mingjie Luo took charge of sequencing. Letian Zhou supported data mining and figure drawing. Lidong Zeng developed GenoLab M’s bioinformatics pipeline. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Ethics Committee of GeneMind Biosciences Company Limited. All methods were carried out in accordance with relevant guidelines and regulations. Mouse testicular tissue, human Lieming Xu-2 cells and bean hairy root tissue were from Beijing Guoke Biotechnology co., LTD.
Consent for publication
Not applicable.
Competing interests
Lei Sun, Yongfeng Liu, XiaoChao Zhao, Zhiliang Zhou, Mingjie Luo, Letian Zhou, and Lidong Zeng are employees of GeneMind Biosciences Company Limited. All other authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article was revised: the ‘Competing Interests’ and ‘Availability of data declarations’ were updated.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Liu, Y., Han, R., Zhou, L. et al. Comparative performance of the GenoLab M and NovaSeq 6000 sequencing platforms for transcriptome and LncRNA analysis. BMC Genomics 22, 829 (2021). https://doi.org/10.1186/s12864-021-08150-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12864-021-08150-8