
Abstract
Background
Electronic Medical Record (EMR) comprises patients’ medical information gathered by medical stuff for providing better health care. Named Entity Recognition (NER) is a sub-field of information extraction aimed at identifying specific entity terms such as disease, test, symptom, genes etc. NER can be a relief for healthcare providers and medical specialists to extract useful information automatically and avoid unnecessary and unrelated information in EMR. However, limited resources of available EMR pose a great challenge for mining entity terms. Therefore, a multitask bi-directional RNN model is proposed here as a potential solution of data augmentation to enhance NER performance with limited data.
Methods
A multitask bi-directional RNN model is proposed for extracting entity terms from Chinese EMR. The proposed model can be divided into a shared layer and a task specific layer. Firstly, vector representation of each word is obtained as a concatenation of word embedding and character embedding. Then Bi-directional RNN is used to extract context information from sentence. After that, all these layers are shared by two different task layers, namely the parts-of-speech tagging task layer and the named entity recognition task layer. These two tasks layers are trained alternatively so that the knowledge learned from named entity recognition task can be enhanced by the knowledge gained from parts-of-speech tagging task.
Results
The performance of our proposed model has been evaluated in terms of micro average F-score, macro average F-score and accuracy. It is observed that the proposed model outperforms the baseline model in all cases. For instance, experimental results conducted on the discharge summaries show that the micro average F-score and the macro average F-score are improved by 2.41% point and 4.16% point, respectively, and the overall accuracy is improved by 5.66% point.
Conclusions
In this paper, a novel multitask bi-directional RNN model is proposed for improving the performance of named entity recognition in EMR. Evaluation results using real datasets demonstrate the effectiveness of the proposed model.
Similar content being viewed by others


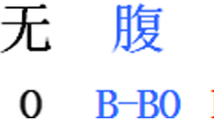
Background
Electronic Medical Record (EMR) [1], a digital version of storing patients’ medical history in textual format, has shaped our medical domain in such a promising way that can gather all information into a place for healthcare providers. It comprises both structured and unstructured data that consists of patients’ health condition and information such as symptoms, medication, disease, progress notes, and discharge summaries. EMR facilitates medical specialists and providers to track digital information and monitor them for patients’ regular check-up. It can also provide healthcare suggestions to patients even they live in a remote area. Moreover, when a patient switches to a new healthcare provider, the provider can easily obtain patients’ medical history and current health condition by studying patient’s EMR. Therefore, information extraction [2] from EMR is one of the most important tasks in medical domain. The intent of information extraction system is to identify and connect the related information and organize them in such a way that can help people to draw conclusions from it, and by avoiding the unnecessary and unrelated information.
To extract information like entity recognition from EMR is labor intensive and time consuming. Although there are many developed models for extraction of entity terms from textual documents, adopting these models for the purpose of medical entity recognition from EMR has been demonstrated as a challenging task, because most of the EMRs are hastily written and incompatible to preprocess [2]. Moreover, incomplete syntax, numerous abbreviation, units after numerical values make the recognition task even more complicated [3]. Standard Natural Language Processing (NLP) tools cannot perform efficiently when they are applied on EMR, since the entity terms of standard NLP is not designed for medical domain. Therefore, it is necessary to develop effective method to perform entity recognition from EMR.
In recent years, various deep learning based methods have been developed for Named Entity Recognition (NER) [4] from EMR. Convolutional Neural Network (CNN) model is used for NER by using data mining to enhance the performance [5]. Zao et al. [6] proposed multiple label CNN based disease NER architecture by capturing correlation between adjacent labels. Dong et al. [7] developed multiclass classification based CNN for mining medical entity types from Chinese EMR.
Most recently, Recurrent Neural Network (RNN) such as Long Short-Term Memory (LSTM) is taking prominent place in NER due to its ability of dependency building in neighboring words. A hybrid LSTM-CNN is proposed in [8]. The authors used CNN to extract the features and fed them to LSTM model for recognizing entity types from CoNLL2003 dataset. Wang et al. [9] studied bi-directional LSTM architecture and concluded that this model is very effective for predicting sequential data. Moreover, the performance of the model is not based on language dependency. Simon et al. [10] and Vinayak et al. [11] used bi-directional RNN model on their Swedish EMR and Hindi dataset, respectively. In each case, the model shows better performance comparing to the state-of-the-art model. Similarly, the approach of using bi-directional RNN with LSTM cell has proven to perform well in extracting named entity recognition task [12].
In general, large corpus dataset is required to train deep learning models. However, there are limited number of corpus in many existing datasets that hinders the development of NER. Moreover, building labeled Chinese EMR data faces many challenges [13], and most organizations do not want to share their data publicly as the data contains private information of patients. In order to address this challenge, a multitask bi-directional RNN model is proposed in this work for extracting entity terms from Chinese EMR. It is motivated by the observation that the performance of multitask learning model is much better comparing to individual learning approach when there is limited corpus dataset [14]. The framework of the proposed multitask bi-directional RNN model for NER is given in Fig. 1.

Framework of the proposed multitask bi-directional RNN model for NER
Methods
In this work, a multitask bi-directional RNN model is proposed for extracting entity terms from Chinese EMR. The proposed model can be divided into two parts: shared layer and task specific layer, see Fig. 1. Specifically, vector representation of each word is a concatenation of word embedding and character embedding in the proposed model, see Fig. 2. Bi-directional RNN is used to extract context information from sentence. Then all these layers are shared by two different task layers, namely the parts-of-speech tagging task layer and the named entity recognition task layer. These two tasks layers are trained alternatively so that the knowledge learned from named entity recognition task can be enhanced by the knowledge gained from parts-of-speech tagging task.

Vector Representation as concatenation of word embeddings and character embeddings. Vector representation of each word is presented as concatenation of word embeddings and character embeddings. The flow of word embedding is highlighted by red shaded box and character embedding is highlighted by white shaded box
RNN [15] is an artificial neural network which can capture previous word information of a sequence in its memory. It computes each word of input sequence (x1, x2, ⋯, xn) and transforms it into a vector form (yt) by using the following equations:
where Uxh, Uhh, Uhy denote the weight matrices of input-hidden, hidden-hidden and hidden-output processes, respectively. ht is the vector of hidden states that capture the information from current input xt and the previous hidden state ht−1.
Here the bi-directional RNN is used to exploit both past and future context, where forward hidden states compute forward hidden sequence while backward hidden states compute backward hidden sequence. The output yt is generated by integrating the two hidden states. In this work, we use a special form of bi-directional RNN, the bi-directional RNN with LSTM cell [16]. LSTM is a special kind of RNN where hidden states are replaced by memory cells to capture long term dependent contextual phrase. The computation of LSTM is quite similar to RNN except for the hidden units, and it is given below:
where i, g, c, o and σ are the input gate, forget gate, cell activation vector, output gate, and logistic sigmoid function of LSTM cell, respectively. These gates and activation functions soothe LSTM to avoid the limitation of vanishing gradients by storing long term dependencies terms of a sequence.
The shared layer contains two consecutive parts, illustrated by Figs. 2 and 3. In Fig. 2, each word is represented by a vector developed by Mikolov [17]. The vector is built as a concatenation of word embeddings [18] and character embeddings. Bi-directional RNN with LSTM cell is used to extract features at the character level and represent the features as character embeddings. Word embedding is achieved by word to vector representation. Character embeddings and word embeddings are then combined to represent each word in a vector representation. In Fig. 3, another bi-directional RNN with LSTM cell is used to extract context information from text sequence. Then the outputs (contextual word representations) are shared by two different bi-directional RNN with LSTM cell for two different tasks: parts-of-speech tagging and named entity recognition. These two task layers are trained alternatively so that knowledge from parts-of-tagging task can be used to improve the performance of named entity recognition task [19]. The detailed settings of the proposed model is shown in Table 1.

Contextual word representation from vector representation. To extract relevant context information from sentence, bi-directional RNN with LSTM cell is used to extract information from a vector associated with word embedding (red shaded box) and character embedding (white shaded box) to form contextual word representation (green shaded box)
Results
Dataset details
The EMR dataset used in our experiment was collected from the departments of the Second Affiliated Hospital of Harbin Medical University, and the personal information of the patients have been discarded. An annotated/labeled corpus consisting of 500 discharge summaries and 492 progress notes has been manually created. The EMR data are written in Chinese with 55,485 sentences. The annotation was made by two Chinese physicians (A1 and A2) independently [7, 13]. It is categorized into five entity types: disease, symptom, treatment, test, and disease group. An annotation example is shown in Fig. 4. The character n-grams are conducted by word segmentation and named entity recognition on Chinese sentences. In the domain of natural language processing (NLP) on Chinese, the first step is to segment the sentence into words containing n-gram characters since for Chinese the minimum semantic units are words, not individual characters. It can be accomplished by NLP tools like Stanford Word Segmenter [20, 21]. Then for recognizing medical concepts from EMR, we define the named entity classes and use different labels to indicate these classes. For example, B/I/O labels denote the beginning word, inside word, and outside word of the named entities. Moreover, for named entity recognition on EMR, we attach the medical information to these three labels in order to denote different categories of named entities. For example, B_disease and B_treatment are denoting beginning words of disease and treatment named entities, respectively. The descriptions of entity types are given in Table 2.

Tagging results on Chinese EMR [7]
The categorized entity types are labeled in BIO format: B, starting of the medical entity type; I, inside of the medical entity type; O, apart from the entity type. The categorization of entities in BIO format is given in Table 3.
Experimental settings
In this experiment, our proposed model is employed to extract medical information from EMR dataset. The key hyper parameters are: Number of hidden neurons for each hidden layer: 150, Minibatch size: 20, Number of epoch: 100, Optimizer: Adam optimizer, Learning rate: 0.01, Learning rate decay: 0.9. They are determined by trial and error.
Evaluation metric
Different metrics in terms of micro-average F score (MicroF), macro-average F score (MacroF) [22] and accuracy have been used to evaluate the performance of our proposed model. Accuracy is calculated by dividing the number of predicted entities that is exactly matched with dataset entities over the total number of entities in the dataset. MicroF is calculated by MicroP and MicroR values whereas MacroF is affected by the average F values of each class:
where P indicates precision measurement that defines the capability of a model to represent only related entities [23] and R (recall) computes the aptness to refer all corresponding entities:
whereas TP (True Positive) counts total number of entity matched with the entity in the labels. FP (False Positive) measures the number of recognized label does not match the annotated corpus dataset. FN (False Negative) counts the number of entity term that does not match the predicted label entity. Then,
where T denotes the total number of categorized entities and Fj, Pj, Rj are F, P, R values in the jth category of entities [7].
MicroP, MicroR, and MicroF are defined as following.
Experimental results
Our experiments are implemented in different phases namely micro average, macro average and accuracy comparison. Precision, Recall and F-score are measured using our proposed multitask bi-directional RNN model and compared with the following classifiers: Naive Bayes (NB), Maximum Entropy (ME), Support Vector Machine (SVM), Conditional Random Field (CRF) [7], and deep learning models including Convolutional Neural Network (CNN) [7], single task bi-directional RNN (Bi-RNN) and transfer bi-directional RNN [24], where NER can be defined as a multiclass classification problem for these classifiers [7]. Among all the models, we have considered Bi-RNN model as baseline model.
Firstly, performances are compared based on micro values and summarized in Tables 4 and 5. The results show that our proposed multitask bi-directional RNN model outperforms other models. For instance, the MicroF value of our proposed model is improved by 2.41% point and 4.67% point compared to the baseline model (Bi-RNN) and CNN, respectively in terms of results in Table 4. In addition, the MicroF value of our proposed model is improved by 3.07% point and 5.52% point compared to the baseline model (Bi-RNN) and CNN, respectively in terms of results in Table 5.
Since micro average only measures the effectiveness of model on a large number of entity, macro average is computed to evaluate the model’s performance in the case of small number of entity terms [25]. Table 6 shows the comparison results of NER on discharge summaries. The macro average F-score is improved by 4.16% point compared to the baseline model. The F-measure ranged from 57.14% point to 88.61% point in different categorized entities when it is computed on our proposed model whereas the range is from 54.54% point to 84.68% point when it is computed from the baseline model. Table 7 shows the comparison results of NER on progress note. The macro average F-score is improved by 13.82% compared to the baseline model. The F-measure ranged from 79.06% point to 94.56% point in different categorized entities when it is computed on our proposed model whereas the range is from 40.00% point to 89.52% point when it is computed from the baseline model.
The comparison results of accuracy on discharge summaries and progress notes are given in Tables 8 and 9. It is observed that the overall accuracy is improved by 5.66% point and 9.41% point on discharge summary and progress note, respectively, compared to the baseline model. According to the evaluation results, our proposed model shows better performance on recognizing medical entity terms comparing with other models including CRF model. CRF uses the feature templates to extract features in order to build the NER model by introducing prior knowledge. On the other hand, the proposed model performs the NER task on Chinese EMRs without any prior knowledge.
It is observed that the best accuracy is enlisted as 89.20% point in test terms and lowest performance is 36.00% point in recognizing disease terms for the case of discharge summary. The accuracy of recognizing disease terms is lowest comparing with other entities since there are very limited number of disease group (0.56% point) [24] in sample which is not enough to train the model. Similar observations are gained for the case of progress note.
In addition, we examine how different features affect the model performance on the discharge summary data. We compare the proposed models built by word level features, character level features, and combined word level features and character level features. The comparison results are shown in Table 10. It is observed that combined features improve the model performance.
Discussion
In our proposed multitask model, we have been concentrating on improving the accuracy of named entity recognition task. Therefore, we have used different task layer (parts-of-speech tagging task) to enhance recognition performance which in turn improves the accuracy of named entity recognition task. More training time is needed for the proposed model since two task specific layers need to be trained, which involves two loss functions and two optimizers. We plan to use a joint loss function and joint optimizer to reduce the training time and improve the accuracy in our future research.
Conclusions
In this paper, a novel multitask bi-directional RNN model is proposed for improving the performance of named entity recognition in EMR. Two different task layers, namely parts of speech tagging task layer and named entity recognition task layer are used in order to improve the information extraction method from EMR dataset by sharing the word embedding and character embedding layer. The feature sharing layer has a great impact on improving the accuracy of extracting entity information. Evaluation results using real datasets demonstrate the effectiveness of the proposed model.
Abbreviations
- CNN:
-
Convolutional neural network
- CRF:
-
Conditional random field
- EMR:
-
Electronic medical record
- FN:
-
False negative
- FP:
-
False positive
- LSTM:
-
Long short-term memory
- ME:
-
Maximum entropy
- NB:
-
Naive Bayes
- NER:
-
Named entity recognition
- NLP:
-
Natural language processing
- RNN:
-
Recurrent neural network
- SVM:
-
Support vector machine
- TP:
-
True positive
References
Gunter TD, Terry NP. The emergence of national electronic health record architectures in the united states and australia: models, costs, and questions. J Med Internet Res. 2005; 7(1):e3.
Ford E, Carroll JA, Smith HE, Scott D, Cassell JA. Extracting information from the text of electronic medical records to improve case detection: a systematic review. J Am Med Inform Assoc. 2016; 23(5):1007–15.
Tange HJ, Hasman A, de Vries Robbé PF, Schouten HC. Medical narratives in electronic medical records. Int J Med Inform. 1997; 46(1):7–29.
Nadeau D, Sekine S. A survey of named entity recognition and classification. Lingvisticae Investigationes. 2007; 30(1):3–26.
Yao C, Qu Y, Jin B, Guo L, Li C, Cui W, Feng L. A convolutional neural network model for online medical guidance. IEEE Access. 2016; 4:4094–103.
Zhao Z, Yang Z, Luo L, Zhang Y, Wang L, Lin H, Wang J. Ml-cnn: A novel deep learning based disease named entity recognition architecture. In: 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE: 2016. p. 794–794.
Dong X, Qian L, Guan Y, Huang L, Yu Q, Yang J. A multiclass classification method based on deep learning for named entity recognition in electronic medical records. In: Scientific Data Summit (NYSDS). New York: IEEE: 2016. p. 1–10.
Chiu JP, Nichols E. Named entity recognition with bidirectional lstm cnns. Trans Assoc Comput Linguist. 2016; 4:357–70.
Wang P, Qian Y, Soong FK, He L, Zhao H. A unified tagging solution: Bidirectional lstm recurrent neural network with word embedding. arXiv preprint arXiv:1511.00215. 2015.
Almgren S, Pavlov S, Mogren O. Named entity recognition in swedish health records with character-based deep bidirectional lstms. In: Proceedings of the Fifth Workshop on Building and Evaluating Resources for Biomedical Text Mining (BioTxtM2016): 2016. p. 30–39.
Athavale V, Bharadwaj S, Pamecha M, Prabhu A, Shrivastava M. Towards Deep Learning in Hindi NER: An approach to tackle the Labelled Data Sparsity. In: Proceedings of the 13th International Conference on Natural Language Processing: 2016. p. 154–60.
Luong M-T, Manning CD. Achieving open vocabulary neural machine translation with hybrid word-character models. arXiv preprint arXiv:1604.00788. 2016.
He B, Dong B, Guan Y, Yang J, Jiang Z, Yu Q, Cheng J, Qu C. Building a comprehensive syntactic and semantic corpus of chinese clinical texts. J Biomed Inform. 2017; 69:203–17.
Zhang Y, Yang Q. A survey on multi-task learning. arXiv preprint arXiv:1707.08114. 2017.
A Beginner’s Guide to Recurrent Networks and LSTMs. https://deeplearning4j.org/lstm.html. Accessed Jan 2018.
Understanding LSTM Networks. http://colah.github.io/posts/2015-08-Understanding-LSTMs/. Accessed Jan 2018.
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems: 2013. p. 3111–3119.
Habibi M, Weber L, Neves M, Wiegandt DL, Leser U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics. 2017; 33(14):37–48.
Sequence Tagging with Tensorflow. https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html. Accessed Dec 2017.
Stanford Word Segmenter. https://nlp.stanford.edu/software/segmenter.html. Accessed Nov 2017.
Chang P-C, Galley M, Manning CD. Optimizing chinese word segmentation for machine translation performance. In: Proceedings of the Third Workshop on Statistical Machine Translation. Association for Computational Linguistics (ACL): 2008. p. 224–232.
Yang Y. A study of thresholding strategies for text categorization. In: Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM: 2001. p. 137–145.
Oliveira JL, Matos S, Campos D. Biomedical named entity recognition: A survey of machine-learning tools In: Sakurai S, editor. Theory and Applications for Advanced Text Mining. Rijeka: InTech: 2012. Chap. 8. https://doi.org/10.5772/51066.
Dong X, Chowdhury S, Qian L, Guan Y, Yang J, Yu Q. Transfer bi-directional lstm rnn for named entity recognition in chinese electronic medical records. In: 2017 IEEE 19th International Conference one-Health Networking, Applications and Services (Healthcom). IEEE: 2017. p. 1–4.
Suominen H, Zhou L, Hanlen L, Ferraro G. Benchmarking clinical speech recognition and information extraction: new data, methods, and evaluations. JMIR Med Inform. 2015; 3(2):e19.
Acknowledgements
Not applicable.
Funding
Publication of this article was sponsored in part by the Texas A&M Chancellor’s Research Initiative (CRI), the U.S. National Science Foundation (NSF) award 1464387 and 1736196, and by the U.S. Office of the Assistant Secretary of Defense for Research and Engineering (OASD(R&E)) under agreement number FA8750-15-2-0119. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. National Science Foundation (NSF) or the U.S. Office of the Assistant Secretary of Defense for Research and Engineering (OASD(R&E)) or the U.S. Government.
Availability of data and materials
Not applicable.
About this supplement
This article has been published as part of BMC Bioinformatics Volume 19 Supplement 17, 2018: Selected articles from the International Conference on Intelligent Biology and Medicine (ICIBM) 2018: bioinformatics. The full contents of the supplement are available online at https://bmcbioinformatics.biomedcentral.com/articles/supplements/volume-19-supplement-17.
Author information
Authors and Affiliations
Contributions
SC, XD, LQ and XL come up with the proposed method; SC and XD complete the simulations; YG, JY, and QY provide the data sets and medical ground truth of the data. All of the authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Chowdhury, S., Dong, X., Qian, L. et al. A multitask bi-directional RNN model for named entity recognition on Chinese electronic medical records. BMC Bioinformatics 19 (Suppl 17), 499 (2018). https://doi.org/10.1186/s12859-018-2467-9
Published:
DOI: https://doi.org/10.1186/s12859-018-2467-9