
Abstract
Background
Reliability is an important parameter in breeding. It measures the precision of estimated breeding values (EBV) and, thus, potential response to selection on those EBV. The precision of EBV is commonly measured by relating the prediction error variance (PEV) of EBV to the base population additive genetic variance (base PEV reliability), while the potential for response to selection is commonly measured by the squared correlation between the EBV and breeding values (BV) on selection candidates (reliability of selection). While these two measures are equivalent for unselected populations, they are not equivalent for selected populations. The aim of this study was to quantify the effect of selection on these two measures of reliability and to show how this affects comparison of breeding programs using pedigree-based or genomic evaluations.
Methods
Two scenarios with random and best linear unbiased prediction (BLUP) selection were simulated, where the EBV of selection candidates were estimated using only pedigree, pedigree and phenotype, genome-wide marker genotypes and phenotype, or only genome-wide marker genotypes. The base PEV reliabilities of these EBV were compared to the corresponding reliabilities of selection. Realized genetic selection intensity was evaluated to quantify the potential of selection on the different types of EBV and, thus, to validate differences in reliabilities. Finally, the contribution of different underlying processes to changes in additive genetic variance and reliabilities was quantified.
Results
The simulations showed that, for selected populations, the base PEV reliability substantially overestimates the reliability of selection of EBV that are mainly based on old information from the parental generation, as is the case with pedigree-based prediction. Selection on such EBV gave very low realized genetic selection intensities, confirming the overestimation and importance of genotyping both male and female selection candidates. The two measures of reliability matched when the reductions in additive genetic variance due to the Bulmer effect, selection, and inbreeding were taken into account.
Conclusions
For populations under selection, EBV based on genome-wide information are more valuable than suggested by the comparison of the base PEV reliabilities between the different types of EBV. This implies that genome-wide marker information is undervalued for selected populations and that genotyping un-phenotyped female selection candidates should be reconsidered.
Similar content being viewed by others
Background
Selection in livestock breeding programs is commonly based on estimated breeding values (EBV) of selection candidates. In addition to EBV, the variance of prediction errors of EBV (PEV) is also routinely calculated based on the statistical model that is used for genetic evaluation in order to provide a measure of the precision with which the EBV are estimated [1, 2]. PEV for genetic evaluations are routinely produced, either by computationally intensive direct inversion of the left hand side of the mixed model equations or, where this is not possible, by approximations [3–7] or selection index theory [8, 9]. To make interpretation of the precision of published EBV easier for the end user and because of the relationship between reliability and response to selection [10], many breeding programs report the reliability of EBV derived from PEV instead of directly reporting PEV, calculated as 1 minus the ratio between PEV and additive genetic variance. Typically, additive genetic variance in the base population is available and used in calculations, what we will call the base PEV reliability, which quantifies the magnitude of PEV in relation to the base additive genetic variance. This measure of reliability is commonly used to reflect the extent to which EBV may change when more information becomes available, which is particularly relevant in breeding programs with overlapping generations, e.g., in dairy cattle breeding, but much less so in, e.g., pig and poultry breeding programs.
Another measure of the reliability of EBV is the squared correlation between breeding values (BV) and EBV of selection candidates. This measure will hereafter be called the reliability of selection because it measures the response to selection that can be obtained when individuals are selected on those EBV, since response to selection is proportional to the accuracy of the EBV, i.e., to the square root of the reliability [10]. The base PEV reliability and the reliability of selection are equivalent for unselected populations (See Appendix) but not for selected populations, because selection reduces additive genetic variance and therefore also the reliability of selection [9, 11–15]. A recent study [16] showed that base PEV reliability may substantially overestimate the reliability of selection for selected populations, and that the equilibrium value of the latter, i.e., the equilibrium reliability, can be predicted from the parameters of unselected populations. The theoretical basis of this overestimation is demonstrated in Additional file 1 [See Additional file 1]. In summary, this overestimation is due to the reduced additive genetic variance among selection candidates in populations under selection and the magnitude of the overestimation varies depending on the information that contributes to the EBV. The overestimation is larger when the EBV depend more on old information from the parental generation than on new information from the current generation. The old information has lower predictive ability for selected populations than for unselected populations, because that information was already used to perform selection of parents and the base PEV reliability does not consider this selection. More specifically, the EBV of selected parents have a reduced variance and a low correlation with the true BV of progeny, which vary between progeny due to recombination and segregation of parental genomes. An example of an extreme case of overestimation of reliability of selection by the base PEV reliability is when the EBV of selection candidates are based on a pedigree prediction, which uses only the old information to estimate the parent average (PA) component of the EBV. A counter example, for which the overestimation is very small is when the EBV are based on a large progeny test, which provides new information to precisely estimate both the PA and the Mendelian sampling (MS) components of the EBV.
Since the base PEV reliability is a measure of the precision of EBV, it is often used as a measure of efficiency when comparing alternative breeding programs, i.e., as a measure of the reliability of selection. If comparisons between the alternative breeding programs that undergo selection are based on the base PEV reliabilities, then the contribution of old information to response to selection will be overestimated and the contribution of new information will be underestimated. With the introduction of genomics, such comparisons have become very common, e.g., comparing the reliability of progeny-tested males and genomically-tested young males [17]. In addition, these comparisons often involve different types of reliabilities: the base PEV reliability for progeny-tested males and the reliability of selection for genomically-tested young males via either forward validation or cross-validation. These two types of reliabilities are not always comparable because the base PEV reliabilities are the expected theoretical values under the assumption of no selection, while validation measures reliability of selection for the analyzed case.
While traditional pedigree-based evaluations are reasonably accurate at estimating the PA component of breeding values, they often provide limited information to estimate the MS component accurately, particularly for young selection candidates. Genomic data provides new information to estimate both the PA and MS components with moderate reliability, which accounts for its usefulness in breeding programs [17–19]. If the benefit of this new (genome-wide marker) information is evaluated using the base PEV reliability, its usefulness in a breeding program may be undervalued, particularly when compared to the value of old information from the parental generation, i.e., the EBV of selected parents [16]. There are potentially many scenarios that need to take the predictive value of old and new information into account when evaluating the usefulness of genome-wide marker information in breeding programs undergoing selection, as for example, the value of collecting genome-wide marker information on un-phenotyped female selection candidates. To date, most breeding programs have predominantly used genome-wide marker information to select un-phenotyped males, but not females. One of the reasons for this is that the perceived improvement in response to selection when selecting un-phenotyped females using genome-wide marker information is limited, e.g., [20–22].
The aim of this research was to quantify the effect of selection on the two measures of reliability for pedigree-based and genomic evaluation of selection candidates, with the following working objectives: (i) to complement the study of Bijma [16] by comparing the base PEV reliability and reliability of selection for pedigree-based and genomic evaluations in populations under selection; (ii) to evaluate the benefit of having genome-wide marker information in such breeding programs; and (iii) to quantify the effect of selection on additive genetic variance and the reliability of selection and compare these obtained values with theoretical equilibrium reliabilities of [16].
Methods
The effect of selection on the two measures of reliability was quantified using simulated data by comparing a scenario with random selection to a scenario with selection on best linear unbiased prediction (BLUP) EBV. The simulation procedure involved generating genome, pedigree, and phenotype data, which were in turn used in genetic evaluation of selection candidates with the different types of information. The effect of selection on the two measures of reliability was evaluated by: (i) comparing the base PEV reliabilities and reliabilities of selection, (ii) quantifying the realized genetic selection intensities, and (iii) evaluating the reduction of the reliability of selection due to reduction in additive genetic variance and comparing it to the theoretical equilibrium reliabilities. Ten replicates were simulated and all the calculated statistics were summarized with their average and standard deviation or 95 % confidence interval. All calculations were done in R [23] unless otherwise stated.
Genome
Sequence data were generated for 4000 base haplotypes for each of 30 chromosomes of the genome using the Markovian Coalescent Simulator (MaCS) [24]. The chromosomes were each 100 cM long, comprised 1.0 × 108 base pairs and were simulated using a per site mutation rate of 2.5 × 10−8, a per site recombination rate of 1.0 × 10−8, and an effective population size (N e ) that varied over time, reflecting the estimates for the Holstein cattle population [25]; in the base generation, N e was equal to 100 and was increased linearly to 1256 at 1000 years ago, 4350 at 10 000 years ago, and 43 500 at 100 000 years ago. A set of 9000 segregating sites were selected at random from the simulated base haplotypes to represent causative loci affecting a complex trait, with a restriction that 300 were sampled from each chromosome. The allele substitution effect at each causative locus (α i ) was sampled from a normal distribution with a mean of 0 and standard deviation of 1 divided by the square root of the number of causative loci, i.e., 1/9000. A second sample of 60 000 segregating sites was selected at random as genome-wide markers on a single nucleotide polymorphism (SNP) array, with a restriction that 2000 SNPs were sampled from each chromosome. There was no restriction on the frequency of causal loci or SNPs.
Pedigree and phenotypes
The base haplotypes were dropped through a simulated pedigree of 25 generations using the AlphaDrop program [26]. Each generation was generated by factorial mating of 20 males and 500 females, with four half-sib progenies per female. Altogether, there were 20 × 25 × 4 = 2000 individuals per generation, of which half were males and half females.
The true BV of an individual was obtained as the sum of all allele substitution effects of the causative loci, accounting for the individuals’ genotype at these loci. The base additive genetic variance was equal to σ 2 A,0 = a T a/(n − 1), where a is a 0 mean vector of BV of the n base individuals. Phenotypes were obtained by adding a residual term to the BV. The residual variance was scaled according to the base additive genetic variance to give a heritability that was set to a high value (0.75). Phenotypes were assigned only to males, which resulted in a breeding scheme in which males had a performance record of their own and records on 51 male half sibs, whereas females had records on 52 male half sibs. This setup was used to mimic the level of reliabilities that are commonly achieved in dairy cattle breeding programs with progeny testing, but keeping the size of the simulated population small. The base PEV reliabilities of the different types of EBV from these data matched closely the level of reported reliabilities from real dairy cattle breeding programs, e.g., [17, 20, 22].
Scenarios
In the random selection scenario (Table 1), each of the 25 generations were simulated by mating 20 males and 500 females that were each selected at random from a set of 1000 selection candidates of each gender. In the BLUP selection scenario, the simulation involved two stages to generate genomes influenced by selection. In the first stage, 10 generations were generated as in the random selection scenario to reach equilibrium in the pedigree information, so that subsequent selection on this information would induce a reduction in additive genetic variance, i.e., the Bulmer effect [11, 15, 16]. In the second stage, each of the 15 generations were simulated by mating 20 males and 500 females that were each selected from a set of 1000 selection candidates of one sex based on BLUP evaluation using pedigree and phenotype information from the current and all previous generations. This procedure provided data to analyze the effect of selection on the two measures of reliability when the Bulmer effect had reached equilibrium, which was conservatively assumed to be reached after five generations of selection. The results confirmed this assumption. Therefore, the data from generations 16 to 25 were in equilibrium and used to analyze the effect of selection on reliabilities, as described in the following.
Genetic evaluation
The simulated data were subject to retrospective genetic evaluation of selection candidates in each generation using different combinations of the following information (Table 1): pedigree for 25 generations, 60 000 genome-wide marker genotypes for 5000 males from generations 16 to 20 and for 2500 males and females from generations 21 to 25 (i.e., a random sample of 500 individuals from each generation), and 5000 phenotypes for males from generations 16 to 20. Individuals in generations 21 through 25 had no phenotypes and served as a validation set to show the reduction in reliabilities with each next generation of prediction. To limit the amount of computing, a random sample of 500 validation individuals per generation was taken to represent the whole generation and evaluated using the different types of information.
Genetic evaluation was based on the following standard mixed model [2]:
where y is a vector of phenotype records, b is a vector of fixed effects (only intercept was used), a ~ N(0, V a) is a vector of BV with an additive genetic covariance matrix V a , e ~ N(0, V e) is a vector of residuals with a residual covariance matrix of V e = I σ 2 E , and X and Z are incidence matrices that link phenotype records to b and a, respectively. Pedigree and genomic evaluations differed in the specification of the covariance structure for a; V a = A σ 2 A,0 for the pedigree model and V a = G σ 2 A,0 for the genomic model, where A and G are the respective relationship matrices based on pedigree [2] and genome-wide marker genotypes [27]. A complete pedigree with all 25 generations was used when setting up the A matrix. All analyses were performed with the assumed known intercept (b) and variances (σ 2 A,0 and σ 2 E ) to facilitate comparison of reliabilities and to avoid variation in the results due to the estimation of parameters that were not of interest in this study. For this reason, the intercept value was first estimated with model (1) and then reused as a known parameter when estimating a.
Using the available data (Table 1), four types of EBV were computed for the selection candidates: (i) EBVP was estimated from pedigree information only, using the pedigree model for all individuals in generations 20 to 25 that were free of phenotypic information from their own performance, collateral relatives, or descendants; (ii) EBVP &Y was estimated from pedigree and phenotype information, using the pedigree model for males and females in generation 20, in which the males had own performance phenotype records and records on male half-sibs, while the females only had records on male half-sibs; (iii) EBVM &Y was estimated from genome-wide marker and phenotype information, using the genomic model for males in generation 20 that had an own performance phenotype record; (iv) EBVM was estimated from genome-wide marker information only, using the genomic model for a random sample of validation individuals from generations 21 to 25 that had no phenotype information.
Reliability
The reliability of selection was calculated as the squared correlation between the EBV and BV for selection candidates. The PEV reliability of an EBV was computed as:
where Var(a i − â i ) is the variance of prediction errors of the EBV of animal i (PEV), which was obtained by inverting the coefficient matrix corresponding to the model used (1), and Var(a i ) is a measure of additive genetic variance σ 2 A (See Appendix). The base PEV reliability was calculated using equation (2), with Var(a i ) set to the base additive genetic variance σ 2 A,0 corrected for inbreeding. This correction was applied due to substantial reduction in σ 2 A,0 caused by the deep pedigree and limited number of parents used in the simulation. In addition to this, the PEV reliability was calculated using equation (2) with Var(a i ) set to different values of additive genetic variance σ 2 A (See subsection “Variances” for details).
Realized genetic selection intensity
The realized genetic selection intensity was defined as the selection differential of BV realized by retrospectively selecting the candidates on a particular type of EBV, standardized by σ A,0. This metric was chosen to show the potential for generating response to selection based on the different types of EBV in order to confirm the effect of selection on the reliability of selection. Otherwise, this metric does not provide any additional information beyond the reliability of selection and can be computed only when simulated data is available.
Variances
To quantify the effect of changes in genetic variance on the reliability of selection, the following variances were computed for each generation: (i) the observed additive genic variance; (ii) the expected additive genic variance; and (iii) the additive genetic variance. Here, the additive genetic variance (σ 2 A ) refers to the variance of true breeding values and the additive genic variance (σ 2 α ) refers to the additive genetic variance under the assumption of linkage equilibrium between the causative loci, e.g., [10, 28]. The observed additive genic variance in generation t (including the base generation) was computed as:
where p i,t and q i,t are the allele frequencies in generation t and alpha i is the allele substitution effect of the i-th causative locus. Inbreeding changes the additive genic variance and its expectation in generation t of a randomly mated finite population was computed as:
where N e is the effective size of the population and \( {\overline{F}}_t \) is a mean inbreeding coefficient in generation t [29]. The equation (4) was also used to correct for the effect of inbreeding on the additive genetic variance when calculating the base PEV reliability using equation (2). Note that σ 2 α,0 ≈ σ 2 A,0 because the base generation was in linkage equilibrium. The difference between the observed additive genic variance in the base generation (3) and the expected additive genic variance in generation t (4) was used to estimate the cumulative change in additive genic variance due to inbreeding up to generation t:
while the difference between the expected and observed additive genic variance in generation t was used to estimate the cumulative change in additive genic variance due to selection up to generation t:
The total change in the additive genic variance up to generation t was therefore equal to:
The additive genetic variance in generation t (σ 2 A,t ) was computed as the variance of BV in generation t prior to any selection within that generation. The difference between the additive genic and the additive genetic variances in the BLUP selection scenario was used to estimate the gametic phase disequilibrium covariance due to the Bulmer effect [11]:
These variances (3) to (8) were used to gradually correct (reduce) the base additive genetic variance and calculate the PEV reliability based on these corrected values to analyze the effect of the different underlying processes on the reduction of the reliability of selection in comparison to the base PEV reliability. In addition, the theoretical expectation of reliability in selected populations, referred to as equilibrium reliabilities, were also calculated for comparison to the base PEV reliabilities corrected for inbreeding (see above) and the proportion of the selected individuals, i.e., 2 % selected males and 50 % selected females [16].
Analysis
The focal generations for comparison of the base PEV reliabilities and reliabilities of selection and realized genetic selection intensities were generation 20 based on phenotyped males and un-phenotyped females and generations 21 to 25 based on un-phenotyped individuals of both sexes. Changes in the variances were evaluated across all generations. The effect of changes in variances on the PEV reliability and the reliability of selection was analyzed in detail in generations 20 and 21 and compared to the equilibrium reliabilities.
Results
Reliability
In the random selection scenario, the base PEV reliabilities and reliabilities of selection were equal, within the bounds of sampling, for both the pedigree model and the genomic model (Table 2) and, therefore, only base PEV reliabilities will be described. In general, reliabilities increased with more information on the MS component of BV. The base PEV reliability of EBVP was equal to 27 % in generations 20 and 21 and decreased each generation to 0 % in generation 25. The base PEV reliability of EBVP &Y in generation 20 was higher than that of EBVP due to the availability of phenotypic information (35 % for females and 76 % for males). The base PEV reliability of EBVM &Y was even higher due to the availability of genome-wide marker and phenotype information (84 % in generation 20). The base PEV reliability of EBVM decreased at a slower rate over generations than that of EBVP,, i.e., it was equal to 67 % in generation 21 and decreased to 53 % in generation 25.
In the BLUP selection scenario, the base PEV reliabilities followed the same pattern as in the random selection scenario. However, the reliabilities of selection were consistently lower than the base PEV reliabilities, especially for EBV with a large dependency on PA information (Table 2), which shows that the base PEV reliabilities overestimated the reliabilities of selection in this scenario. The ratio of the reliability of selection to the base PEV reliability in generation 20 was equal to 0.11 for EBVP, 0.37 for EBVP &Y for females, 0.89 for EBVP &Y for males, and 0.94 for EBVM &Y. In generation 21, the ratio of reliabilities for EBVP was equal to 0.11 and 0.00 in the following generations, while for EBVM the ratio was equal to 0.90, 0.91, 0.87, 0.86, and 0.88 in generations 21 to 25, respectively (Table 2).
Comparison of reliabilities of the different types of EBV obtained with the BLUP selection scenario showed that genomic prediction had a greater advantage over pedigree prediction when based on the reliability of selection than when based on base PEV reliability. For example, the difference between the reliability of genomic and pedigree predictions in generation 21 was 17 % larger when based on reliability of selection than when based on base PEV reliability, which indicates that genotyping un-phenotyped females might be more valuable than previously suggested, e.g., [20–22].
Realized genetic selection intensity
To confirm differences between base PEV reliabilities and reliabilities of selection, selection on the different types of EBV was compared in terms of realized genetic selection intensities of BV that could have been achieved if candidates were selected on those EBV. In general, realized genetic selection intensities reflected the reliabilities of selection for both the random selection scenario and the BLUP selection scenario and confirmed that base PEV reliabilities overestimate reliabilities of selection in the BLUP selection scenario. Differences between the realized genetic selection intensities were smaller than between the two measures of reliability, because realized genetic selection intensities are proportional to the accuracy of selection, i.e., to the square root of reliability of selection.
In the random selection scenario, selecting candidates directly on true BV gave realized genetic selection intensities that ranged from 0.73 to 0.76 with 50 % selected and from 2.16 to 2.24 with 2 % selected (Table 3). Selection on EBVP gave the lowest realized genetic selection intensities, which ranged from 0.19 to 0.22 with 50 % selected and from 0.55 to 0.60 with 2 % selected in generations 20 and 21. These values practically decreased by 50 % in each next generation due to the low predictive ability of EBVP. Selection on EBVP &Y gave higher realized genetic selection intensities than selection on EBVP due to the higher reliabilities of EBV when based on phenotype information on full-sibs and half-sibs for females, as well as own performance records for males. Realized genetic selection intensities with EBVP &Y were equal to 0.24 and 0.55 with 50 % selected, and to 0.75 and 1.67 with 2 % selected, respectively. Selection on EBVM &Y gave the highest realized genetic selection intensity due to the use of genome-wide marker and phenotype information. In generation 20, the realized genetic selection intensities for EBVP &Y and EBVM &Y were equal to 0.55 and 0.62 with 50 % selected and to 1.67 and 1.90 with 2 % selected, respectively. In the later generations, selecting on EBVM gave more than half of the realized genetic selection intensity compared to selecting directly on true BV.
In the BLUP selection scenario, selection on true BV gave realized genetic selection intensities that ranged from 0.58 to 0.62 with 50 % selected and from 1.74 to 1.87 with 2 % selected and remained constant (within the bounds of sampling) over all generations (Table 3). These results in the BLUP selection scenario are between 16 and 22 % lower than for the random selection scenario, with an increasing trend over time. Selection on EBVP gave a realized genetic selection intensity of only 0.02 with 50 % selected and between 0.09 and 0.10 with 2 % selected in generation 20, and dropped to 0 in the later generations much more quickly than with the random selection scenario. These realized intensities with EBVP were more than 80 % lower than with the random selection scenario. With EBVP &Y, the reduction of realized genetic selection intensity in comparison to the random selection scenario was 66 % for females and 25 % for males. With EBVM &Y and EBVM, the reduction of realized genetic selection intensity was between 12 and 30 %, with the largest difference observed in generation 21, which was the first generation of prediction without phenotype information.
Changes in variances and effect on reliability
Additive genic variance decreased with each generation in both the random and BLUP selection scenarios, although the reduction was larger with the BLUP selection scenario (Fig. 1). Additive genic variance in the base generation was equal to 0.28 with both scenarios and by generation 20 it was reduced to 0.25 with the random selection scenario and to 0.22 with the BLUP selection scenario. These reductions were mainly caused by inbreeding and were quantified by subtracting the expected additive genic variance under the finite population model from the base generation value (5). The reduction caused by inbreeding up to generation 20 was equal to 0.03 with the random selection scenario and 0.045 with the BLUP selection scenario. The remaining loss of 0.015 in genic variance with the BLUP selection scenario was attributed to the effect of selection.

Additive genic variance (σ 2 α ) and changes due to inbreeding and selection by scenario and generation. Average values with 95 % confidence intervals are presented
For both scenarios, the additive genetic variance also decreased with each generation, but with a significant change in generation 10 when selection on EBV was introduced in the BLUP selection scenario (Fig. 2). Additive genetic variance was equal to 0.28 in the base generation with both scenarios and by generation 10, it decreased to 0.26 for both scenarios because of inbreeding. Introduction of selection in generation 10 reduced the additive genetic variance to 0.21 in generation 11, while the additive genic variance was equal to 0.26. The difference between these two variances gave an estimate of −0.05 for the gametic phase disequilibrium covariance. By generation 20, the additive genetic variance was further reduced to 0.16. The overall reduction of the base additive genetic variance (0.28) was due half to the Bulmer effect (0.06) and half to loss in additive genic variance caused by inbreeding (0.045) and selection (0.015). In the random selection scenario, the additive genetic variance in generation 20 was equal to 0.24, which was equal to additive genic variance within the bounds of sampling.

Additive genetic variance (σ 2 A ) and Bulmer effect (σ 2 α − σ 2 A ) by scenario and generation. Average values with 95 % confidence intervals are presented
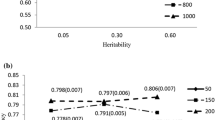
The effect of changes in variances (Figs. 1 and 2) on the reliability of selection was quantified in detail in generations 20 and 21 by calculating the PEV reliability with different values of additive genetic variance (Table 4). In the random selection scenario, the reliability of selection tended to be lower than the base PEV reliabilities. Taking into account the reduction in variance due to inbreeding, or using the additive genetic variance from generation 20 or 21, gave a PEV reliability that matched the reliability of selection within the bounds of sampling. In the BLUP selection scenario, the base PEV reliabilities considerably overestimated the reliability of selection, as previously noted (Table 2). This overestimation was, due to the reduction in additive genetic variance, as caused by several underlying processes (Table 4). Inbreeding, and to a small extent selection, reduced the additive genic variance and therefore also the additive genetic variance by changing the allele frequencies of causative loci. More importantly, the additive genetic variance was also reduced by the generation of gametic phase disequilibrium between the causative loci by selection, i.e., the Bulmer effect. These reductions in additive genetic variance due to inbreeding, selection, and the Bulmer effect were used to gradually reduce the base additive genetic variance to the additive genetic variance in generation 20 or 21 and to recalculate the PEV reliabilities for each reduction. The resulting PEV reliabilities matched the reliability of selection within the bounds of sampling. These results not only show which processes contribute to the reduction of the reliability of selection in selected populations but also that the base PEV reliabilities overestimate the reliability of selection in such populations by using the base additive genetic variance instead of actual additive genetic variance of selection candidates. Finally, the equilibrium reliabilities matched the reliability of selection for EBVP and EBVP &Y (Table 4 and Figs. 3 and 4, while there were minor discrepancies for EBVM &Y and EBVM. Figures 3 and 4 show contours of equilibrium reliabilities for the different proportion of selected males and females and a dot for the reliability of selection obtained in this study (Table 4). The discrepancies for EBVM &Y and EBVM arose because, in this study, selection was on EBVP &Y and calculating the equilibrium reliabilities with the higher EBVM &Y or EBVM base PEV reliabilities, as if selection was on the EBVM &Y or EBVM, leads to underestimation of the equilibrium reliabilities. Changing the proportion of selected males and females when calculating the equilibrium reliability for EBVP &Y and EBVM &Y in generation 20 (Fig. 3) and for EBVP and EBVM in generation 21 (Fig. 4) showed that the observed base PEV reliabilities were recovered when selection was absent, i.e., the equilibrium reliabilities from the bottom-left corners of Figs. 3 and 4 matched the base PEV reliabilities corrected for inbreeding in Table 4.

Equilibrium reliability and reliability of selection of different types of estimated breeding values in generation 20. Breeding values estimated using (a) pedigree and phenotype information in males (EBVP &Y,m), (b) marker and phenotype information in males (EBVM &Y,m), and (c) pedigree and phenotype information in females (EBVP &Y,f). Equilibrium reliabilities are shown with contours, as a function of the proportions of males and females selected, while reliability of selection is shown as a point at the proportions selected used in this study

Equilibrium reliability and reliability of selection of different types of estimated breeding values in generation 21. Breeding values estimated (predicted) using (a) pedigree information (EBVP) and (b) marker information (EBVM). Equilibrium reliabilities are shown with contours as a function of the proportions of males and females selected, while reliability of selection is shown as a point at the proportions selected used in this study
Discussion
Reliability is important in breeding because it measures the potential for response to selection in a breeding program. The results of this study show that, in populations under selection, reliability computed from PEV and the base additive genetic variance (base PEV reliability) is not equal to the squared correlation between the EBV and BV in selection candidates (reliability of selection), with which potential for response to selection is measured. The difference between these two measures of reliability arises from their different scopes of interpretation. The base PEV reliability overestimates the reliability of selection in selected populations because it is computed from PEV and the base additive genetic variance. The latter describes genetic variation in the base population and not in the selection candidates. As shown in this study, this overestimation can be mitigated either by calculating the PEV reliability based on the reduced additive genetic variance of the selection candidates or by using theoretical equilibrium reliabilities. It was also shown that the degree of overestimation differs between types of EBV and that this has important consequences when breeding schemes and genotyping strategies are compared based on the base PEV reliability; in particular when the base PEV reliability of pedigree prediction is compared to that of other types of EBV.
Reliability in selected populations
The following example illustrates that selection reduces the reliability of selection and that this effect differs between types of EBV. Selecting the parents of the next generation on any type of EBV reduces the variance of these EBV, which are in turn used to obtain pedigree predictions (EBVP) of the progeny. In the extreme case, selecting and mating only two parents (with EBV1 and EBV2 and corresponding base PEV reliabilities \( {R}_{EB{V}_1}^2 \) and \( {R}_{EB{V}_2}^2\Big) \) would create a new generation for which all individuals have the same pedigree prediction, \( EB{V}_P=\frac{1}{2}\left( EB{V}_1+ EB{V}_2\right), \) although there would be variation in their BV due to the Mendelian sampling of parental genomes. In such a situation, the EBVP has no predictive ability to differentiate between individuals, although the base PEV reliability of EBV P would be greater than 0, i.e., \( {R}_{EB{V}_P}^2\ge \frac{1}{4}\left({R}_{EB{V}_1}^2+{R}_{EB{V}_2}^2\right) \) [See Additional file 1]. Consequently, these EBVP have no potential to generate response to selection if selection is carried out among progeny. In contrast, genomic predictions (EBVM) for these individuals would have some predictive ability and potential to generate response to selection, because genome-wide markers provide new information to estimate both the PA and MS component of EBV for each individual [17–19], which can then be differentiated. However, in selected populations, the predictive ability of EBVM is also overestimated by the base PEV reliability, albeit less so than for EBVP.
A detailed illustration on how selection reduces the reliability of selection and how this effect differs between types of EBV is in Additional file 1 [See Additional file 1]. In summary, selection of parents reduces the variance of BV (i.e., additive genetic variance) in progeny but in particular the variance of EBVP in progeny. The reduction of additive genetic variance in progeny reduces the reliability of selection because the unchanged precision of EBV coupled with a smaller variation in BV make it more difficult to differentiate between individuals. The reduction in variance of EBVP in progeny reduces the reliability of selection because EBVP only predicts the PA component of BV and with increasing selection in parents, the predictive ability of EBVP decreases, as illustrated previously. The reduced additive genetic variance in progeny has the same effect on the reliability of selection for any type of EBV. In contrast, the reduced variance of EBVP in progeny has a different effect on the reliability of selection for different types of EBV and is larger for EBV that are primarily based on the PA component and smaller for EBV that are primarily based on the MS component.
These illustrations indicate that the base PEV reliability overestimates the reliability of selection because it does not take into account the effect of selection on variances. The expression for the base PEV reliability involves PEV and the base additive genetic variance. Selection does not affect the PEV [1, 13] but it does affect the additive genetic variance. It causes a reduction in the additive genetic variance that should be taken into account if the PEV reliability is to be used as a measure of the reliability of selection. The rationale behind the expression for the base PEV reliability derives from the PEV being the (posterior) variance of BV conditional on the observed phenotypic information and the base additive genetic variance being the (prior) unconditional variance of BV in the base population. Relating this posterior to the prior quantifies the amount by which the uncertainty in BV is reduced after phenotypic information has been collected [2]. While the base additive genetic variance must be used when calculating EBV and PEV [2], which unconditional variance of BV should be used when calculating the PEV reliability depends on the scope of interpretation. If the aim is to measure the reliability of selection among parents and progeny, then the PEV reliability should be calculated based on the additive genetic variance in parents. However, if the aim is to measure the reliability of selection among progeny, as in the present study, then the PEV reliability should be calculated based on the additive genetic variance in progeny. When the scope of interpretation is not taken into account, the PEV reliability can overestimate the reliability of selection. The amount of overestimation depends on the type of EBV, its base PEV reliability, and the intensity of selection, which determines how much additive genetic variance has been lost over the generations of selection [16].
Therefore, if the PEV reliability is used as a measure of the reliability of selection, it should be computed based on the additive genetic variance of selection candidates. However, this is often not possible because the additive genetic variance for sets of individuals is usually unknown in real populations and its estimation is computationally demanding [13]. In addition, there is usually no clear definition of the generation or groups of individuals of interest in livestock populations, which complicates estimation even more. In such situations, the base additive genetic variance may be the only estimate available and therefore the base PEV reliabilities can only be used as a measure of precision of EBV in relation to the base population variation and not as a measure of the reliability of selection to compare breeding schemes. However, the difference between these two measures of reliability can be predicted using the equilibrium reliabilities calculated from the base PEV reliabilities and the proportions selected among males and females [16]. As shown in this study, the equilibrium reliabilities matched the reliability of selection for any type of EBV, which confirms the utility of theoretical expressions to calculate the equilibrium reliability [16].
In this study, the reduction of additive genetic variance across generations was caused by three processes: the initial cycles of selection caused changes in gametic phase disequilibrium (i.e., the Bulmer effect), and inbreeding and selection caused changes in allele frequencies. The Bulmer effect was responsible for 50 % of the loss of variance, while changes in allele frequencies due to inbreeding and selection were responsible for 37.5, and 12.5 % of the loss of variance, respectively. The theoretical expressions for the equilibrium reliability derived in [16] only account for the reduction in variance due to the Bulmer effect, and not for reductions due to changes in allele frequencies resulting from inbreeding and selection. However, our study demonstrates that the Bulmer effect is the largest source of reduction in variance. In addition, the expected loss of additive genetic variance in finite populations [29] can be used to account for the effect of inbreeding on variance. The effect of inbreeding was substantial in this study, because of the deep pedigree and a small number of parents. In more typical scenarios, the pedigree is not as deep, which suggests that the impact of reduction in additive genetic variance due to selection changing allele frequency would also be smaller than in this study.
Implications for comparison of breeding programs
The difference between the base PEV reliabilities and the reliability of selection has important consequences for the design of breeding programs using genome-wide marker information. Genome-wide marker information is often considered to be of much lower value for un-phenotyped females than for males. This perception is in part due to the smaller impact that females have on the next generation, but also due to the relatively small difference between the base PEV reliability of EBVP or EBVP &Y and the base PEV or validation reliabilities of EBVM. For example, in the BLUP selection scenario used in this study, the base PEV reliabilities of EBVP and EBVM in generation 21 were equal to 27 and 70 %, respectively, with an absolute difference of 43 %. Several studies have derived the value of genotyping un-phenotyped females on the basis of gains in reliability, while accounting for cost of genotyping and raising replacement females, e.g., [20–22]. However, our results show that the gain in reliability of selection is much higher than expected from comparison of the base PEV reliabilities; in generation 21, reliability of selection was 3 % for EBVP and 63 % for EBVM, with an absolute difference of 60 %. This large difference demonstrates that there is more value in genotyping un-phenotyped females in selected populations than previously reported. This was further demonstrated by measuring the realized genetic selection intensity for the different types of EBV; in generation 21 of the BLUP selection scenario, selecting 50 % of selection candidates gave realized genetic selection intensity of 0.02 when selecting on EBVP and of 0.38 when selecting on EBVM. These results clearly show the benefit of investing in genotyping un-phenotyped females. With increased selection intensity, the effect of selection on realized genetic selection intensity was even more pronounced due to further reductions of the base PEV reliability of EBVP. Comparing the predictive abilities of EBVP and EBVM is, in some sense, a comparison of extremes. Smaller but still significant differences can be expected when the EBV of selection candidates have a large dependency on information from the parental generation. Failing to take the effect of selection on additive genetic variance into account, can overstate the reliability of selection on such EBV in comparison with EBVM [15, 16]. This is not an issue when the comparison of predictive abilities of EBVP or EBVP &Y and EBVM are all based on validation correlations among selection candidates.
Conclusions
Selection reduces genetic variance and the reliability of selection, which is usually not accounted for when the base additive genetic variance is used to calculate base PEV reliabilities. This reduction in reliability of selection is more pronounced for EBV that are based mainly on information from the parental generation. An extreme example of this is when EBV are based solely on parent average. This implies that the genome-wide marker information has been undervalued in populations that are under selection, and that genotyping un-phenotyped females must be reconsidered.
References
Henderson CR. Best linear unbiased estimation and prediction under a selection model. Biometrics. 1975;31:423–47.
Henderson CR. Applications of Linear Models in Animal Breeding. Schaeffer LR, editor. 3rd ed. University of GuelphL: Guelph;1984. http://cgil.uoguelph.ca/pub/Henderson.html.
Misztal I, Wiggans GR. Approximation of prediction error variance in large-scale animal models. J Dairy Sci. 1988;71:27–32.
Meyer K. Approximate accuracy of genetic evaluation under an animal model. Livest Prod Sci. 1989;21:87–100.
Jamrozik J, Schaeffer LR, Jansen GB. Approximate accuracies of prediction from random regression models. Livest Prod Sci. 2000;66:85–92.
Tier B, Meyer K. Approximating prediction error covariances among additive genetic effects within animals in multiple-trait and random regression models. J Anim Breed Genet. 2004;121:77–89.
Hickey JM, Veerkamp RF, Calus MPL, Mulder HA, Thompson R. Estimation of prediction error variances via Monte Carlo sampling methods using different formulations of the prediction error variance. Genet Sel Evol. 2009;41:23.
Harris B, Johnson D. Approximate reliability of genetic evaluations under an animal model. J Dairy Sci. 1998;81:2723–8.
VanRaden PM, Wiggans GR. Derivation, calculation, and use of national animal model information. J Dairy Sci. 1991;74:2737–46.
Falconer DS, Mackay TFC. Introduction to quantitative genetics. Harlow: Pearson Education Limited; 1996.
Bulmer MG. The effect of selection on genetic variability. Am Nat. 1971;105:201–11.
Fimland E. The effect of selection on additive genetic parameters. J Anim Breed Genet. 1979;96:120–34.
Henderson CR. Best linear unbiased prediction in populations that have undergone selection. In: Barton RA, Smith WC, editors. Proceedings of the world congress on sheep and beef cattle breeding. 1982. p. 191–200.
Wray NR, Hill WG. Asymptotic rates of response from index selection. Anim Prod. 1989;49:217–27.
Dekkers JCM. Asymptotic response to selection on best linear unbiased predictors of breeding values. Anim Prod. 1992;54:351–60.
Bijma P. Accuracies of estimated breeding values from ordinary genetic evaluations do not reflect the correlation between true and estimated breeding values in selected populations. J Anim Breed Genet. 2012;129:345–58.
Schaeffer LR. Strategy for applying genome-wide selection in dairy cattle. J Anim Breed Genet. 2006;123:218–23.
Meuwissen THE, Hayes BJ, Goddard ME. Prediction of total genetic value using genome-wide dense marker maps. Genetics. 2001;157:1819–29.
Van Grevenhof EM, Van Arendonk JA, Bijma P. Response to genomic selection: the Bulmer effect and the potential of genomic selection when the number of phenotypic records is limiting. Genet Sel Evol. 2012;44:26.
De Roos APW. Recent trends in genomic selection in dairy cattle. In: Proceedings of the 62nd Annual Meeting of the European Federation of Animal Science: 29 August-2 September 2011; Stavanger. 2011. p. Contribution 01–7.
Simianer H, Chen J, Erbe M. Animal breeding in the genomics era: challenges and opportunities for the maintenance of genetic diversity. In: Proceedings of the 62nd Annual Meeting of the European Federation of Animal Science: 29 August-2 September 2011; Stavanger. 2011. p. Contribution 11–3.
Strandberg E. Opportunities to optimize the role of functional traits in dairy breeding goals using genomics information. In Proceedings of the 62nd Annual Meeting of the European Federation of Animal Science: 29 August-2 September 2011; Stavanger. 2011:Contribution 11–2.
R Development Core Team. R: A Language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2014.
Chen GK, Marjoram P, Wall JD. Fast and flexible simulation of DNA sequence data. Genome Res. 2009;19:136–42.
Villa-Angulo R, Matukumalli LK, Gill CA, Choi J, Van Tassell CP, Grefenstette JJ. High-resolution haplotype block structure in the cattle genome. BMC Genet. 2009;10:19.
Hickey JM, Gorjanc G. Simulated data for genomic selection and genome-wide association studies using a combination of coalescent and gene drop methods. G3 (Bethesda). 2012;2:425–7.
VanRaden PM. Efficient methods to compute genomic predictions. J Dairy Sci. 2008;91:4414–23.
Gianola D, de los Campos G, Hill WG, Manfredi E, Fernando R. Additive genetic variability and the Bayesian alphabet. Genetics. 2009;183:347–63.
Wright S. The genetical structure of populations. Ann Eugen. 1949;15:323–54.
Rendel JM, Robertson A. Estimation of genetic gain in milk yield by selection in a closed herd of dairy cattle. J Genet. 1950;50:1–8.
Cochran WG. Improvement by means of selection. In: Neyman J, editor. Proceedings of the 2nd Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press; 1951. p. 449–70.
Acknowledgements
We acknowledge input from the three reviewers and the associate editors JCM Dekkers and H Hayes whose comments improved the manuscript. GG and JH acknowledge support from the BBSRC ISP grant to The Roslin Institute.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All authors participated in the design of the study. GG performed analyses and wrote the manuscript. PB and JMH assisted in the interpretation of the results and in writing the manuscript. All authors read and approved the final manuscript.
Additional files
Additional file 1:
Theoretical basis of the effect of selection on reliability. Detailed illustration on how selection reduces the reliability of selection and how this effect differs between types of estimated breeding values [31]. (PDF 7873 kb)
Appendix
Appendix
Equivalence between base PEV reliability and reliability of selection in unselected populations
The purpose of this appendix is to show that the two measures of reliability, the base PEV reliability and the reliability of selection, are equivalent for unselected populations. This is first shown by defining the reliability of selection as the squared correlation between the true breeding values (BV) and estimated breeding values (EBV) in an unselected population [10], and then by demonstrating that this is equivalent to the commonly used expression to compute the base PEV reliability [1, 2, 13].
The reliability of selection is defined as a squared correlation between the BV (a) and EBV (â) for selection candidates. This value is commonly presented as a single value for a group of individuals [10], which is likely based on the intuition of obtaining the sample correlation between a vector of BV and a vector of EBV. However, expression for the correlation between two vectors results in a matrix of correlations C â,a and squaring its elements via the Hadamard product (∘) gives a matrix of squared correlations:
where the diagonal elements are the squared correlation between BV and EBV for each individual, i.e., the reliability for each individual, while the off-diagonal elements are the squared correlation between BV of one individual and EBV of another individual, i.e., the “co-reliability” for each pair of individuals. In the expression (A1), the notation diag(X) indicates a diagonal matrix with the diagonal equal to the diagonal of matrix X. If the evaluated individuals were unrelated and all of them had a single own phenotype pre-corrected for any other effect without error, then the reliability of this evaluation would be the same for all individuals, R 2, and (A1) could be written as R 2(â) = I R 2, which is in line with the common usage [10]. However, in real applications, evaluated individuals are related, they might have different amounts of information, and phenotypes are not pre-corrected, which leads to different reliabilities for different individuals and to non-zero “co-reliabilities”. In such cases, the mean of these reliabilities can be used to obtain a single measure of reliability to predict response to selection. Alternatively, the individual specific reliability could be used along with the individual specific selection intensity and generation interval as is done when response to selection is predicted for breeding programs with different “paths” of selection [17, 30].
The additive genetic covariance matrix Var(a) = V a = A σ 2 A in (A1) holds covariances between BV of selection candidates, where A is the relationship matrix between the selection candidates and σ 2 A is the additive genetic variance for the selection candidates. If the selection candidates either represent the whole unselected population or are a random sample from such a population, then σ 2 A is equal to the base additive genetic variance σ 2 A,0 in such a population. The other two components in (A1), Cov(a, â T) and Var(â), depend on σ 2 A as well as on the properties of the estimator of BV and will be worked out in the following.
Using the standard linear mixed model (1) and assuming known fixed effects (E(y) = Xb) and variance components (σ 2 A,0 and σ 2 E ), the EBV can be obtained by regressing BV on the observed phenotypes pre-corrected for fixed effects. The conditional expectation and variance of this regression can be expressed in two equivalent ways [1, 2, 13]:
where Var(a) = V a = A σ 2 A,0 is the additive genetic covariance matrix with respect to the base population, Var(e) = V e = E σ 2 E is the residual covariance matrix, and Var(y) = V y = ZV a Z T + V e is the phenotypic covariance matrix. The two equivalent expressions are shown to point out that the conditional variance of BV given the phenotypes is the variance of prediction errors (PEV) of EBV, i.e., Var(a|y) = Var(a − â), which is commonly obtained by inverting the coefficient matrix (V − 1 a + Z T V − 1 e Z).
Using (A2) it can be shown that the components of (A1), Cov(a, â T) and Var(â), are equal to [1, 2, 13]:
which along with Var(a) gives all the required components for computing the individual specific reliabilities in (A1). Since Cov(a, â T) = Var(â) and Var(a − â) = Var(a) − Var(â) the individual reliabilities in (A1) can be equivalently expressed by contrasting the conditional variance of BV to the variance of BV, i.e., additive genetic variance [1, 2, 13]:
Since the conditional variance of BV, Var(a i − â i ), is not affected by selection [1], the expressions (A1) and (A6) give the same reliability when they refer to the same group of individuals, i.e., when the same additive genetic variance is used in both expressions. However, the two expressions do not give the same reliability, if they refer to two different additive genetic variances. Commonly, the base additive genetic variance (σ 2 A,0 ) is used to compute the base PEV reliability (A6), while the reliability of selection is computed as squared correlation between the EBV and BV in a selected group of individuals (A1) that do not necessarily have the same additive genetic variance (σ 2 A ) as the base population.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Gorjanc, G., Bijma, P. & Hickey, J.M. Reliability of pedigree-based and genomic evaluations in selected populations. Genet Sel Evol 47, 65 (2015). https://doi.org/10.1186/s12711-015-0145-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12711-015-0145-1