
Abstract
Background
N-linked glycoprotein is a highly interesting class of proteins for clinical and biological research. The large-scale characterization of N-linked glycoproteins accomplished by mass spectrometry-based glycoproteomics has provided valuable insights into the interdependence of glycoprotein structure and protein function. However, these studies focused mainly on the analysis of specific sample type, and lack the integration of glycoproteomic data from different tissues, body fluids or cell types.
Methods
In this study, we collected the human glycosite-containing peptides identified through their de-glycosylated forms by mass spectrometry from over 100 publications and unpublished datasets generated from our laboratory. A database resource termed N-GlycositeAtlas was created and further used for the distribution analyses of glycoproteins among different human cells, tissues and body fluids. Finally, a web interface of N-GlycositeAtlas was created to maximize the utility and value of the database.
Results
The N-GlycositeAtlas database contains more than 30,000 glycosite-containing peptides (representing > 14,000 N-glycosylation sites) from more than 7200 N-glycoproteins from different biological sources including human-derived tissues, body fluids and cell lines from over 100 studies.
Conclusions
The entire human N-glycoproteome database as well as 22 sub-databases associated with individual tissues or body fluids can be downloaded from the N-GlycositeAtlas website at http://nglycositeatlas.biomarkercenter.org.
Similar content being viewed by others


Introduction
It is known that post-translational modifications (PTM) are among the most important factors that increase the diversity of proteins in terms of both structures and functions [1]. The expression analysis of proteins and their PTMs is a key step for the functional characterization of genes and proteins. In the last decade, mass spectrometry has become the most important tool for large-scale proteomic and PTM analysis. Due to the rapid accumulation of a vast amount of proteomic data, many proteome-, sub-proteome-, and protein modification databases have been created in recent years to facilitate proteomic and PTM studies. These databases include ProteomicsDB [2], Human Proteome Map [3], GPMDB [4] and PeptideAtlas [5] for global proteomes; PhosphoSitePlus [6] for phosphorylation sites, acetylation sites, and ubiquitination sites; Unipep [7] for N-glycosite-containing peptides; and Cell Surface Protein Atlas [8] for cell surface proteins. The public availability of these databases has facilitated the progress of several studies in their corresponding fields.
Glycosylation is one of the most common PTMs, which plays important roles in many biological processes [9]. Aberrant glycosylation is associated with the pathological progression of many diseases [9]. N-linked glycosylation is a common feature shared by a large fraction of transmembrane proteins, cell surface proteins, and proteins secreted in body fluids [9, 10]. Transmembrane or cell surface glycoproteins are easily accessible to therapeutic drugs, antibodies, and ligands. The glycoproteins secreted in body fluids such as serum, cerebrospinal fluid, and urine are easily accessible and are thought to provide a detailed window into the state of health of an individual. These features make glycoproteins a highly interesting class of proteins for clinical and biological research.
In the last decade, thousands of N-linked glycoproteins have been identified through identifying their glycosite-containing peptides using mass spectrometry [11]. These data have facilitated a better understanding of the glycoprotein contents in humans and other organisms. However, these studies only analyzed specific tissue types, body fluids or cell lines. Unipep is the only database that is specifically dedicated for predicted and identified N-glycosite-containing peptides [7], which unfortunately does not contain the information about sources of the identified glycopeptides. Hence, a systematic and integrated analysis of these identified glycoproteins and glycosites is urgently needed.
In this study, we collected more than 30,000 unique human glycosite-containing peptides (de-glycosylated) identified by mass spectrometry, representing > 14,000 unique N-glycosites from > 7200 N-glycoproteins, from over 100 publications and unpublished datasets. A database resource termed N-GlycositeAtlas was created and further used for the distribution analyses of glycoproteins among different human cells, tissues and body fluids. Finally, a web interface of N-GlycositeAtlas (http://nglycositeatlas.biomarkercenter.org) was created to maximize the utility and value of the database by providing an online search platform as well as a comprehensive and tissue- or body fluid-specific glycoprotein database that can be downloaded.
Experimental section
Collection of N-linked human glycosite-containing peptides
The mass spectrometry identified glycosite-containing peptides from human sources (including tissues, body fluids, and cell lines) were obtained from two main resources: (1) 34 datasets generated from our laboratory (including 15 published and 19 unpublished datasets); (2) 70 papers published by other groups since 2003 (collected on November, 2015). These publications were collected based on their citation of one of the following glycoproteomics technology papers: (1) hydrazide chemistry [12,13,14,15]; (2) lectin enrichment [16]; (3) hydrophilic affinity [17]; (4) size extraction chromatography [18]; and (5) FASP-based lectin enrichment [19]. All unpublished glycosite-containing peptides were enriched using the hydrazide chemistry (SPEG) method [12, 13] from different human-related samples. It should be noted that only glycosite-containing peptides identified by their de-glycosylated forms were collected, the glycoproteins identified through intact glycopeptides or other non-glycosylated peptides were not included in this study. After glycosite-containing peptide collection from these published papers, the data were further filtered by N-X-S/T motif (X can be any amino acid except proline) with deamidation (de-glycosylated form) at the asparagine residue. In order to keep the original records from published papers, no further quality control step was performed prior to the database assembly.
Among these unpublished datasets generated in our laboratory, eleven of them were generated before 2008 and have been included in the Unipep website (http://www.unipep.org) [7] and/or PeptideAtlas website (http://www.peptideatlas.org) [20]. These samples were enriched by the SPEG method and analyzed by an LTQ ion trap (Thermo Fisher, San Jose, CA) or Q-TOF (Waters, Beverly, MA) mass spectrometers followed by being searched with the SEQUEST algorithm [21] against a human International Protein Index database (IPI) [22]. The peptide mass tolerance was 2.0 Da. Carbamidomethylation (C, + 57.0215 Da) was set as a static modification; oxidation (M, + 15.9949 Da) and deamination (N, + 0.98 Da) were set as dynamic modifications. The output files were further evaluated by INTERACT and ProteinProphet [23, 24]. The identified peptides were filtered by a PeptideProphet probability score ≥ 0.9 and the deamidation of asparagine (N) in the N-X-S/T motif. The identification of glycosite-containing peptides from these data was filtered by deamidation (de-glycosylated form) in the N-X-S/T motif.
The other eight big datasets were generated using Orbitrap Velos and/or Q-Exactive mass spectrometers (Thermo Fisher Scientific, Bremen, Germany) after former glycopeptide enrichment using SPEG method and searched against an NCBI Reference Sequence (RefSeq) human protein database [25] using SEQUEST [21] in Proteome Discoverer v1.4 (Thermo Fisher Scientific). The database searching parameters for glycosite-containing peptide identification were set as follows: two missed cleavages were allowed for trypsin digestion with 10 ppm precursor mass tolerance and 0.06 Da fragment mass tolerance. Carbamidomethylation (C) was set as a static modification, while oxidation (M) and deamination (N) were set as dynamic modifications. For iTRAQ-labeled samples, iTRAQ-4plex (peptide N-terminal) and iTRAQ-4plex (K) were added as dynamic modifications. The glycosite-containing peptide identifications were filtered by 1% FDR and deamination in the N-X-S/T motif of the peptides. Four of these unpublished datasets (raw data) have been deposited to the ProteomeXchange Consortium (http://proteomecentral.proteomexchange.org) via the PRIDE partner repository [26] with the dataset identifier PXD005143. Another glycoproteome dataset is accessible through the Clinical Proteomic Tumor Analysis Consortium (CPTAC) website (https://cptac-data-portal.georgetown.edu/cptac/s/S020).
Glycoprotein mapping and database assembly
All identified glycosite-containing peptides from different published papers and unpublished datasets were matched to the UniProt human protein database (downloaded at Nov. 3rd, 2015 from website http://www.uniprot.org) using an in-house software. Using this in-house software, all glycosite-containing peptides were first mapped into the reviewed UniProt database, and unmatched peptides were further mapped into an un-reviewed UniProt database. The matched protein IDs, gene names, protein names, glycosylation site locations, and peptide sequences with ± 20 amino acids surrounding each glycosite (N-X-S/T motif, X ≠ P) were extracted and assembled into a human glycoprotein and glycosite database, termed N-GlycositeAtlas. When a peptide could match to more than one protein, all protein records were included in the database. In addition, only peptides containing the typical N-X-S/T N-glycosylation motif were included in the database.
Data access
The N-GlycositeAtlas is accessible at http://nglycositeatlas.biomarkercenter.org. The user can download the entire and 22 tissue/body fluid specific human glycoprotein databases from the website.
Results and discussions
Assembly of N-GlycositeAtlas
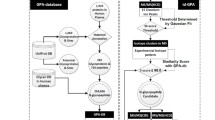
Here, we present a mass spectrometry-identified N-linked glycoprotein and glycosite database, named N-GlycositeAtlas, to facilitate human protein glycosylation studies. The human glycosite-containing peptides identified via their de-glycosylated forms were initially collected from all human glycosylation-related datasets with thousands of LC–MS/MS data including 15 published [7, 27,28,29,30,31,32,33,34,35,36,37,38,39,40] and 19 newly generated datasets (> 1000 LC–MS/MS files) generated in our laboratory (Fig. 1). The glycosite-containing peptides were then matched to their proteins in a common UniProt human protein database (http://www.uniprot.org). For each matched protein, the protein accession number, protein name, gene name, N-linked glycosylation location and the protein sequence at ± 20 amino acids surrounding the glycosylation site were extracted from the protein database to constitute the N-GlycositeAtlas. Using this strategy, we collected 13,811 human glycosite-containing peptides representing 11,336 unique glycosites from 34 datasets generated in our laboratory (Fig. 1).

Assembly of the mass spectrometry-based human glycoprotein and glycosite database (N-GlycositeAtlas). The identified glycosite-containing peptides were collected from 85 publications and 19 newly generated or unpublished datasets. The peptides were then matched to a UniProt protein database. The relevant information for each glycosite was then extracted for glycosite and glycoprotein database development
To expand the database, we also collected human glycosite-containing peptides from all papers regarding to human glycosite-containing peptide analysis published since 2003. Using the same strategy as above, we eventually collected 22,618 glycosite-containing peptides that belong to 8818 unique glycosites from 70 papers published by other laboratories [7, 14, 15, 17, 18, 33, 41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104]. Altogether, the N-GlycositeAtlas contains 30,872 unique glycosite-containing peptides that match to 14,644 unique glycosites in 7204 glycoproteins (Fig. 1 and Additional file 1: Table S1).
The confidence of the data is one of most important considerations in measuring the quality of a database. In N-GlycositeAtlas, only peptides containing the typical N-X-S/T N-glycosylation motif were included in the database to ensure the high confidence of the data, even though recent studies indicated that N-glycans can also be attached to other atypical motifs [19, 40]. In addition, all glycosite-containing peptides identified from studies conducted in our laboratory must contain ≥ 1 deamidation site at the former glycosylation sites (after PNGase F treatment). It is considerably more difficult for us to control the quality of the data published from other groups. Nevertheless, the confidence of a given glycosite or glycosite-containing peptide could still be estimated according to its identification frequency. Generally, glycosites that were identified more frequently from different samples or studies (based on either the same glycosite-containing peptide or a glycosite-containing peptide with a different length resulting from missed cleavages or different enzyme digestion) had a higher confidence. In N-GlycositeAtlas, 2247 glycosites were identified more than 10 times, 7182 glycosites were identified 2-10 times, and 5215 glycosites (35.6%) were identified only once in all different datasets (Fig. 2a).

Overview of the human glycoprotein and glycosite database. a The identification frequencies of each glycosite in the database. The identification frequencies of each glycosite were determined based on their identification in different samples, different studies or glycosite-containing peptides of various lengths (due to different enzyme digestion or different missed cleavages). b Accumulation of identified glycosite-containing peptides, unique glycosites and glycoproteins with time. c Classification of glycosites according to their year of publication
The confidence of these identified glycosites, especially the glycosites that were only identified once, can be further estimated based on their original mass spectrometry data and subsequent analytical methods. Owing to the huge improvement of mass spectrometry technology, liquid chromatography (LC) separation, analysis software and glycoprotein/glycosite-containing peptide isolation methods in recent years, the number of confidently identified N-linked glycosite-containing peptides has increased dramatically. As most of the glycosite-containing peptides in N-GlycositeAtlas were identified as their de-glycosylation form with deamidation (+ 0.98 Da) at the former glycosites (after PNGase F treatment), the high resolution and accuracy of the mass spectrometers that were used to conduct these studies in recent years greatly increased the identification confidence of the glycosites and glycoproteins as well as increased the numbers of identified glycosite-containing peptides at pre-determined false discovery rates (FDR). In order to estimate the confidence of the glycosite-containing peptides in the database using this information, we simply analyzed the data according to their date of publication. Our results showed that although the identified human glycoproteins and glycosites have been steadily increasing since 2003 when the first two glycoproteomic studies were published [12, 16], the huge increase mainly occurred in recent years (Fig. 2b). We found that the majority of the glycosites (83.4%) in the database were published during 2010–2015 (Fig. 2c), and these sites were most likely identified with high confidence by using high resolution and high accurate mass spectrometry.
Additional information about the detailed mass spectrometers and search parameters for the identification of a given glycosite or glycoprotein can be obtained from the original publications listed in the database.
Distribution of glycoproteins and glycosites across tissues and biological fluids
Determining the current status of glycoprotein analysis in each human tissue and body fluid will benefit future human glycoproteomic studies. Using N-GlycositeAtlas, we investigated the distribution of identified glycoproteins across different human tissues and body fluids. Among eight tissues including prostate, liver, ovary, breast, pancreas, colon, lung and bladder, prostate has the most number of identified glycosites (> 6000; Fig. 3a) and glycoproteins (> 3000; Fig. 3b). There were also more than 5000 glycosites and 2000 glycoproteins identified from liver and ovary. In addition to the tissue glycoproteins, 311 glycoproteins with 585 glycosites were identified from spermatozoa [71]. However, there are still many tissues with no glycoproteomics data or with only limited data obtained from the related cell lines. In fact, this is the case even with many essential organs of the human body, such as heart, stomach, brain, and kidney. Glycoproteomic analysis of these tissues will promote human glycoproteomics studies and enhance our understanding of the distribution and function of glycoproteins in different tissues.

Distribution of identified glycosites and glycoproteins across different human tissues or body fluids. The blue columns represent the glycosites (a) and glycoproteins (b) identified from human tissues or body fluids; the orange columns represent the glycosites (a) and glycoproteins (b) identified from the related cell lines. CSF cerebrospinal fluid, PBMC peripheral blood mononuclear cell
As N-linked glycoproteins account for a large portion of the protein content in serum and other body fluids, identifying the glycoprotein components in these body fluids is essential for their clinical utility. N-GlycositeAtlas contains 2645 and 1845 glycoproteins that were identified from urine and serum, respectively (Fig. 3). Based on these results, we found that more glycoproteins were identified from urine than from serum. The possible reason is that serum contains many high abundant glycoproteins, and these glycoproteins might inhibit the identification of low abundant glycoproteins in serum. Removal of these high abundant proteins before mass spectrometry-based proteomic or sub-proteomic analyses would increase the number of identified serum glycoproteins [14]. Several hundred glycoproteins have also been identified from saliva and cerebrospinal fluid (CSF). In addition, > 1000 glycoproteins have been detected from platelets and T cell cell lines, and > 500 glycoproteins have been identified from B-cell cell lines (Fig. 3).
The glycoprotein and glycosite databases associated with individual tissues or body fluids can be downloaded from the N-GlycositeAtlas website.
Comparison of serum and urinary glycoproteins with tissue-derived glycoproteins
Serum is the most widely used biospecimen for disease detection and monitoring due to its ease of access and rich physiological and pathological information. The detection of disease-related glycoprotein changes in serum is an important strategy for disease biomarker discovery [105]. Using the data in N-GlycositeAtlas, we compared the glycoprotein contents between serum and eight different tissues (cell line-related glycoproteins were not included) to investigate the detectability of tissue glycoproteins in serum. The results indicated that different tissues had different numbers and percentages of glycoproteins overlapped with serum-derived glycoproteins (Fig. 4a). An average of 47.6 ± 16.5% glycoproteins identified in tissues were also detected in serum. The data confirmed the high value of serum tests in the detection of glycoprotein changes associated with various diseases.

Glycoproteins identified in common between tissues and serum (a) or urine (b)
Body fluids other than serum such as urine and CSF are also important specimens for clinical tests. In this study, we also analyzed urine-derived glycoproteins based on the clinical utility of urine. The urinary glycoproteins were also compared with glycoproteins from eight different tissues. The results indicated that a lot of glycoproteins were also commonly identified from urine and tissues, with an average of 63.1 ± 12.1% tissue-derived glycoproteins overlapping with urine-derived glycoproteins (Fig. 4b). More tissue-derived glycoproteins were detected in urine than in serum, which could be attributed to the larger number of glycoproteins that were identified in urine compared to serum. To further investigate the potential of urine in clinical tests and biomarker discovery, we also compared the glycoproteins between urine and serum. Among 1845 glycoproteins identified in serum, 827 (44.8%) were also identified in urine. The abundance glycoprotein content in urine and the high percentage of glycoproteins that overlap with tissue-derived glycoproteins suggests the high potential of urine in clinical detection and biomarker discovery. However, additional studies are required to confirm whether these urinary glycoproteins change with disease and reflect different pathological states within different parts of the human body.
N-GlycositeAtlas web interface
To make the database readily accessible and easy to update, we designed a web interface (http://nglycositeatlas.biomarkercenter.org) to facilitate the online searching of the database and the downloading of data. By using the web interface, users can easily search the database either using the general search function for basic search or advanced search by restricting the search based on protein accession number, gene name, protein name, glycosylation site location, glycosite-containing peptide, N-glycosylation motif (N-X-S/T), the name of tissue/liquid/cell line, year of publication, and/or reference for specific searches (Fig. 5a). Multiple search parameters can be used together for multiple searches (link with “or”) or more specific searches (link with “and”, Fig. 5a).

Representative N-GlycositeAtlas web interface output showing an N-linked glycoprotein and its glycosites. Endoplasmin (HSP90B1) is used as an example. a The database search. The database can be searched online according to the protein accession number, gene name, protein name, glycosylation site location, glycosite-containing peptide, N-glycosylation motif (N-X-S/T), name of tissue/liquid/cell line, year of publication, and/or reference. Multiple search parameters can be used for a combined or parameter-specific search. b The search results are shown in the first display page. In the first display page, the glycoprotein accession number (UniProt), gene name, protein name and glycosylation site location are exhibited. The detailed information for each glycoprotein can be accessed in the second display page by clicking the glycoprotein accession number. In the second display page, the following information is shown: c glycoprotein information; d glycosite and glycosite-containing peptide information of the glycoprotein as well as their references; and e glycosites (red) and glycosite-containing peptides (bold font) highlighted in the protein sequence
We designed two layers of display pages to exhibit the results. The first layer of the display page only exhibits general information of the glycoproteins, including glycoprotein accession numbers (UniProt), gene names, protein names and identified glycosylation sites (Fig. 5b). The additional information for each glycoprotein can be gained in the second display page by clicking the related glycoprotein accession number. In the second display page, the user will obtain the tissue/liquid/cell line types where the glycoprotein was identified (Fig. 5c), all glycosite-containing peptides identified at each glycosite with the reference information (Fig. 5d), as well as the highlighted the location of the identified glycosites and glycosite-containing peptides in the protein sequence (Fig. 5e).
In addition, the entire human glycoprotein and glycosite database as well as the glycoprotein database for each individual tissue or body fluid can also be downloaded from the N-GlycositeAtlas website in a Microsoft Excel format. The following information is included in the database: (1) UniProt accession numbers of glycoproteins; (2) whether the protein has been reviewed in the UniProt database; (3) protein names; (4) gene names; (5) location of the glycosylation sites; (6) identified glycosite-containing peptides; (7) the protein sequence at ± 20 amino acids surrounding the identified glycosylation site; (8) names of tissues/body fluids/cell lines where the glycosite-containing peptide was identified; (9) year of publication; and (10) references. It should be noted that each line of text only contains one glycosite-containing peptide and one glycosite location. When a peptide contains more than one glycosite, each glycosite is displayed on a separate line. In addition, different proteins are also listed on separate lines when one glycosite-containing peptide was matched to more than one protein. The detailed information for each identified glycosite or glycosite-containing protein can be acquired from their original publications that are listed after each record.
Conclusions
In this study, we created a human glycoprotein and glycosite database containing > 14,000 N-glycosites and more than 7200 N-glycoproteins that were identified through their de-glycosylated forms of glycosite-containing peptides by mass spectrometry from over 100 publications or unpublished datasets. Based on the data in the database, we observed that although several thousand glycoproteins could be identified from one single tissue, there were still many tissues where no mass spectrometry-based glycosite data has been generated yet. A considerable amount of additional work is still needed to profile the human glycoproteomes at the human genomic level. Many common glycoproteins identified between tissues and serum confirmed the high value of serum in clinical tests, while the large proportion of common glycoproteins between different tissues and urine suggested the high potential of urine for clinical detection and biomarker discovery. Finally, the web interface of N-GlycositeAtlas (http://nglycositeatlas.biomarkercenter.org) was created to maximize the utility and value of the database by providing an online search platform as well as a comprehensive and tissue- or body fluid-specific glycoprotein database that can be downloaded.
Abbreviations
- Glycosite:
-
N-linked glycosylation site
- LC–MS/MS:
-
liquid chromatography combined with tandem-mass spectrometry
- CSF:
-
cerebrospinal fluid
- PBMC:
-
peripheral blood mononuclear cell
References
Olsen JV, Mann M. Status of large-scale analysis of post-translational modifications by mass spectrometry. Mol Cell Proteomics. 2013. https://doi.org/10.1074/mcp.O113.034181.
Wilhelm M, Schlegl J, Hahne H, Gholami AM, Lieberenz M, Savitski MM, Ziegler E, Butzmann L, Gessulat S, Marx H. Mass-spectrometry-based draft of the human proteome. Nature. 2014;509(7502):582–7.
Kim M-S, Pinto SM, Getnet D, Nirujogi RS, Manda SS, Chaerkady R, Madugundu AK, Kelkar DS, Isserlin R, Jain S. A draft map of the human proteome. Nature. 2014;509(7502):575–81.
Craig R, Cortens JP, Beavis RC. Open source system for analyzing, validating, and storing protein identification data. J Proteome Res. 2004;3(6):1234–42.
Desiere F, Deutsch EW, King NL, Nesvizhskii AI, Mallick P, Eng J, Chen S, Eddes J, Loevenich SN, Aebersold R. The peptideatlas project. Nucleic Acids Res. 2006;34(suppl 1):D655–8.
Hornbeck PV, Kornhauser JM, Tkachev S, Zhang B, Skrzypek E, Murray B, Latham V, Sullivan M. PhosphoSitePlus: a comprehensive resource for investigating the structure and function of experimentally determined post-translational modifications in man and mouse. Nucleic Acids Res. 2011. https://doi.org/10.1093/nar/gkr1122.
Zhang H, Loriaux P, Eng J, Campbell D, Keller A, Moss P, Bonneau R, Zhang N, Zhou Y, Wollscheid B, et al. UniPep—a database for human N-linked glycosites: a resource for biomarker discovery. Genome Biol. 2006;7(8):R73.
Bausch-Fluck D, Hofmann A, Bock T, Frei AP, Cerciello F, Jacobs A, Moest H, Omasits U, Gundry RL, Yoon C. A mass spectrometric-derived cell surface protein atlas. PLoS ONE. 2015;10(4):e0121314.
Ohtsubo K, Marth JD. Glycosylation in cellular mechanisms of health and disease. Cell. 2006;126(5):855–67.
Zhang H, Chan DW. Cancer biomarker discovery in plasma using a tissue-targeted proteomic approach. Cancer Epidemiol Biomark Prev. 2007;16(10):1915–7.
Tian Y, Zhang H. Characterization of disease-associated N-linked glycoproteins. Proteomics. 2013;13(3–4):504–11.
Zhang H, Li XJ, Martin DB, Aebersold R. Identification and quantification of N-linked glycoproteins using hydrazide chemistry, stable isotope labeling and mass spectrometry. Nat Biotechnol. 2003;21(6):660–6.
Tian Y, Zhou Y, Elliott S, Aebersold R, Zhang H. Solid-phase extraction of N-linked glycopeptides. Nat Protoc. 2007;2(2):334–9.
Liu T, Qian W-J, Gritsenko MA, Camp DG, Monroe ME, Moore RJ, Smith RD. Human plasma N-glycoproteome analysis by immunoaffinity subtraction, hydrazide chemistry, and mass spectrometry. J Proteome Res. 2005;4(6):2070–80.
Sun B, Ranish JA, Utleg AG, White JT, Yan X, Lin B, Hood L. Shotgun glycopeptide capture approach coupled with mass spectrometry for comprehensive glycoproteomics. Mol Cell Proteomics. 2007;6(1):141–9.
Kaji H, Saito H, Yamauchi Y, Shinkawa T, Taoka M, Hirabayashi J, Kasai K-I, Takahashi N, Isobe T. Lectin affinity capture, isotope-coded tagging and mass spectrometry to identify N-linked glycoproteins. Nat Biotechnol. 2003;21(6):667–72.
Hagglund P, Bunkenborg J, Elortza F, Jensen ON, Roepstorff P. A new strategy for identification of N-glycosylated proteins and unambiguous assignment of their glycosylation sites using HILIC enrichment and partial deglycosylation. J Proteome Res. 2004;3(3):556–66.
Alvarez-Manilla G, Atwood J, Guo Y, Warren NL, Orlando R, Pierce M. Tools for glycoproteomic analysis: size exclusion chromatography facilitates identification of tryptic glycopeptides with N-linked glycosylation sites. J Proteome Res. 2006;5(3):701–8.
Zielinska DF, Gnad F, Wiśniewski JR, Mann M. Precision mapping of an in vivo N-glycoproteome reveals rigid topological and sequence constraints. Cell. 2010;141(5):897–907.
Farrah T, Deutsch EW, Omenn GS, Campbell DS, Sun Z, Bletz JA, Mallick P, Katz JE, Malmström J, Ossola R. A high-confidence human plasma proteome reference set with estimated concentrations in PeptideAtlas. Mol Cell Proteomics. 2011. https://doi.org/10.1074/mcp.M110.006353.
Eng J, McCormack A, Yates J. An approach to correlate tandem mass spectral data of peptides with amino acid sequences in a protein database. J Am Soc Mass Spectrom. 1994;5(11):976–89.
Kersey PJ, Duarte J, Williams A, Karavidopoulou Y, Birney E, Apweiler R. The International Protein Index: an integrated database for proteomics experiments. Proteomics. 2004;4(7):1985–8.
Keller A, Nesvizhskii AI, Kolker E, Aebersold R. Empirical statistical model to estimate the accuracy of peptide identifications made by MS/MS and database search. Anal Chem. 2002;74(20):5383–92.
Nesvizhskii AI, Keller A, Kolker E, Aebersold R. A statistical model for identifying proteins by tandem mass spectrometry. Anal Chem. 2003;75(17):4646–58.
Pruitt KD, Tatusova T, Maglott DR. NCBI reference sequences (RefSeq): a curated non-redundant sequence database of genomes, transcripts and proteins. Nucleic Acids Res. 2007;35(suppl 1):D61–5.
Vizcaíno JA, Côté RG, Csordas A, Dianes JA, Fabregat A, Foster JM, Griss J, Alpi E, Birim M, Contell J. The PRoteomics IDEntifications (PRIDE) database and associated tools: status in 2013. Nucleic Acids Res. 2013;41(D1):D1063–9.
Sun S, Shah P, Eshghi ST, Yang W, Trikannad N, Yang S, Chen L, Aiyetan P, Hoti N, Zhang Z, et al. Comprehensive analysis of protein glycosylation by solid-phase extraction of N-linked glycans and glycosite-containing peptides. Nat Biotechnol. 2015. (Advance online publication).
Sun S, Zhang B, Aiyetan P, Zhou J-Y, Shah P, Yang W, Levine DA, Zhang Z, Chan DW, Zhang H. Analysis of N-glycoproteins using genomic N-glycosite prediction. J Proteome Res. 2013;12(12):5609–15.
Shah P, Wang X, Yang W, Eshghi ST, Sun S, Hoti N, Chen L, Yang S, Pasay J, Rubin A, et al. Integrated proteomic and glycoproteomic analyses of prostate cancer cells reveal glycoprotein alteration in protein abundance and glycosylation. Mol Cell Proteomics. 2015;14(10):2753–63.
Yang W, Laeyendecker O, Wendel SK, Zhang B, Sun S, Zhou J-Y, Ao M, Moore RD, Jackson JB, Zhang H. Glycoproteomic study reveals altered plasma proteins associated with HIV elite suppressors. Theranostics. 2014;4(12):1153.
Liu Y, Chen J, Sethi A, Li QK, Chen L, Collins B, Gillet LC, Wollscheid B, Zhang H, Aebersold R. Glycoproteomic analysis of prostate cancer tissues by SWATH mass spectrometry discovers N-acylethanolamine acid amidase and protein tyrosine kinase 7 as signatures for tumor aggressiveness. Mol Cell Proteomics. 2014;13(7):1753–68.
Chen J, Shah P, Zhang H. Solid phase extraction of N-linked glycopeptides using hydrazide tip. Anal Chem. 2013;85(22):10670–4.
Li QK, Shah P, Li Y, Aiyetan PO, Chen J, Yung R, Molena D, Gabrielson E, Askin F, Chan DW. Glycoproteomic analysis of bronchoalveolar lavage (BAL) fluid identifies tumor-associated glycoproteins from lung adenocarcinoma. J Proteome Res. 2013;12(8):3689–96.
Tian Y, Almaraz RT, Choi CH, Li QK, Saeui C, Li D, Shah P, Bhattacharya R, Yarema KJ, Zhang H. Identification of sialylated glycoproteins from metabolically oligosaccharide engineered pancreatic cells. Clin Proteomics. 2015;12(1):11.
Tian Y, Esteva FJ, Song J, Zhang H. Altered expression of sialylated glycoproteins in breast cancer using hydrazide chemistry and mass spectrometry. Mol Cell Proteomics. 2012. https://doi.org/10.1074/mcp.M111.011403.
Almaraz RT, Tian Y, Bhattarcharya R, Tan E, Chen S-H, Dallas MR, Chen L, Zhang Z, Zhang H, Konstantopoulos K. Metabolic flux increases glycoprotein sialylation: implications for cell adhesion and cancer metastasis. Mol Cell Proteomics. 2012. https://doi.org/10.1074/mcp.M112.017558.
Tian Y, Yao Z, Roden R, Zhang H. Identification of glycoproteins associated with different histological subtypes of ovarian tumors using quantitative glycoproteomics. Proteomics. 2011;11(24):4677–87.
Tian Y, Bova GS, Zhang H. Quantitative glycoproteomic analysis of optimal cutting temperature-embedded frozen tissues identifying glycoproteins associated with aggressive prostate cancer. Anal Chem. 2011;83(18):7013–9.
Sun S, Zhang H. Large-scale measurement of absolute protein glycosylation stoichiometry. Anal Chem. 2015;87(13):6479–82.
Sun S, Zhang H. Identification and validation of atypical N-glycosylation sites. Anal Chem. 2015;87(24):11948–51.
Weng Y, Sui Z, Jiang H, Shan Y, Chen L, Zhang S, Zhang L, Zhang Y. Releasing N-glycan from peptide N-terminus by N-terminal succinylation assisted enzymatic deglycosylation. Sci Rep. 2015;5:9770.
Wang M, Zhang X, Deng C. Facile synthesis of magnetic poly(styrene-co-4-vinylbenzene-boronic acid) microspheres for selective enrichment of glycopeptides. Proteomics. 2015;15(13):2158–65.
Tan ZJ, Yin HD, Nie S, Lin ZX, Zhu JH, Ruffin MT, Anderson MA, Simone DM, Lubman DM. Large-scale identification of core-fucosylated glycopeptide sites in pancreatic cancer serum using mass spectrometry. J Proteome Res. 2015;14(4):1968–78.
Smeekens JM, Chen WX, Wu RH. Mass spectrometric analysis of the cell surface N-glycoproteome by combining metabolic labeling and click chemistry. J Am Soc Mass Spectrom. 2015;26(4):604–14.
Ma C, Zhang Q, Qu JY, Zhao XY, Li X, Liu YP, Wang PG. A precise approach in large scale core-fucosylated glycoprotein identification with low- and high-normalized collision energy. J Proteomics. 2015;114:61–70.
Li Y, Shah P, De Marzo AM, Van Eyk JE, Lo Q, Chan DW, Zhang H. Identification of glycoproteins containing specific glycans using a lectin-chemical method. Anal Chem. 2015;87(9):4683–7.
Kim DS, Hahn Y. The acquisition of novel N-glycosylation sites in conserved proteins during human evolution. BMC Bioinform. 2015;16:29.
Goyallon A, Cholet S, Chapelle M, Junot C, Fenaille F. Evaluation of a combined glycomics and glycoproteomics approach for studying the major glycoproteins present in biofluids: application to cerebrospinal fluid. Rapid Commun Mass Spectrom. 2015;29(6):461–73.
Cheow ESH, Sim KH, de Kleijn D, Lee CN, Sorokin V, Sze SK. Simultaneous enrichment of plasma soluble and extracellular vesicular glycoproteins using prolonged ultracentrifugation-electrostatic repulsion–hydrophilic interaction chromatography (PUC-ERLIC) approach. Mol Cell Proteomics. 2015;14(6):1657–71.
Zhu J, Sun Z, Cheng K, Chen R, Ye M, Xu B, Sun D, Wang L, Liu J, Wang F, et al. Comprehensive mapping of protein N-glycosylation in human liver by combining hydrophilic interaction chromatography and hydrazide chemistry. J Proteome Res. 2014;13(3):1713–21.
Zhang Z, Sun Z, Zhu J, Liu J, Huang G, Ye M, Zou H. High-throughput determination of the site-specific N-sialoglycan occupancy rates by differential oxidation of glycoproteins followed with quantitative glycoproteomics analysis. Anal Chem. 2014;86(19):9830–7.
Zhang L, Jiang H, Yao J, Wang Y, Fang C, Yang P, Lu H. Highly specific enrichment of N-linked glycopeptides based on hydrazide functionalized soluble nanopolymers. Chem Commun. 2014;50(8):1027–9.
Xu Y, Bailey U-M, Punyadeera C, Schulz BL. Identification of salivary N-glycoproteins and measurement of glycosylation site occupancy by boronate glycoprotein enrichment and liquid chromatography/electrospray ionization tandem mass spectrometry. Rapid Commun Mass Spectrom. 2014;28(5):471–82.
Weng Y, Qu Y, Jiang H, Wu Q, Zhang L, Yuan H, Zhou Y, Zhang X, Zhang Y. An integrated sample pretreatment platform for quantitative N-glycoproteome analysis with combination of on-line glycopeptide enrichment, deglycosylation and dimethyl labeling. Anal Chim Acta. 2014;833:1–8.
Wang Y, Liu M, Xie L, Fang C, Xiong H, Lu H. Highly efficient enrichment method for glycopeptide analyses: using specific and nonspecific nanoparticles synergistically. Anal Chem. 2014;86(4):2057–64.
Wang J, Zhou C, Zhang W, Yao J, Lu HJ, Dong QZ, Zhou HJ, Qin LX. An integrative strategy for quantitative analysis of the N-glycoproteome in complex biological samples. Proteome Sci. 2014;12:4.
Takakura D, Harazono A, Hashii N, Kawasaki N. Selective glycopeptide profiling by acetone enrichment and LC/MS. J Proteomics. 2014;101:17–30.
Sun Z, Dong J, Zhang S, Hu Z, Cheng K, Li K, Xu B, Ye M, Nie Y, Fan D, et al. Identification of chemoresistance-related cell-surface glycoproteins in leukemia cells and functional validation of candidate glycoproteins. J Proteome Res. 2014;13(3):1593–601.
Song E, Zhu R, Hammond ZT, Mechref Y. LC–MS/MS quantitation of esophagus disease blood serum glycoproteins by enrichment with hydrazide chemistry and lectin affinity chromatography. J Proteome Res. 2014;13(11):4808–20.
Pan C, Zhou Y, Dator R, Ginghina C, Zhao Y, Movius J, Peskind E, Zabetian CP, Quinn J, Galasko D, et al. Targeted discovery and validation of plasma biomarkers of Parkinson’s disease. J Proteome Res. 2014;13(11):4535–45.
Nicastri A, Gaspari M, Sacco R, Elia L, Gabriele C, Romano R, Rizzuto A, Cuda G. N-glycoprotein analysis discovers new up-regulated glycoproteins in colorectal cancer tissue. J Proteome Res. 2014;13(11):4932–41.
Liu L, Yu M, Zhang Y, Wang C, Lu H. Hydrazide functionalized core-shell magnetic nanocomposites for highly specific enrichment of N-glycopeptides. ACS Appl Mater Interfaces. 2014;6(10):7823–32.
Kim JY, Oh D, Kim S-K, Kang D, Moon MH. Isotope-coded carbamidomethylation for quantification of N-glycoproteins with online microbore hollow fiber enzyme reactor-nanoflow liquid chromatography-tandem mass spectrometry. Anal Chem. 2014;86(15):7650–7.
Huang G, Sun Z, Qin H, Zhao L, Xiong Z, Peng X, Ou J, Zou H. Preparation of hydrazine functionalized polymer brushes hybrid magnetic nanoparticles for highly specific enrichment of glycopeptides. Analyst. 2014;139(9):2199–206.
Hirao Y, Matsuzaki H, Iwaki J, Kuno A, Kaji H, Ohkura T, Togayachi A, Abe M, Nomura M, Noguchi M, et al. Glycoproteomics approach for identifying glycobiomarker candidate molecules for tissue type classification of non-small cell lung carcinoma. J Proteome Res. 2014;13(11):4705–16.
Fang C, Xiong Z, Qin H, Huang G, Liu J, Ye M, Feng S, Zou H. One-pot synthesis of magnetic colloidal nanocrystal clusters coated with chitosan for selective enrichment of glycopeptides. Anal Chim Acta. 2014;841:99–105.
Deeb SJ, Cox J, Schmidt-Supprian M, Mann M. N-linked glycosylation enrichment for in-depth cell surface proteomics of diffuse large B-cell lymphoma subtypes. Mol Cell Proteomics. 2014;13(1):240–51.
Chen R, Seebun D, Ye M, Zou H, Figeys D. Site-specific characterization of cell membrane N-glycosylation with integrated hydrophilic interaction chromatography solid phase extraction and LC-MS/MS. J Proteomics. 2014;103:194–203.
Zhou H, Froehlich JW, Briscoe AC, Lee RS. The GlycoFilter: a simple and comprehensive sample preparation platform for proteomics, N-glycomics and glycosylation site assignment. Mol Cell Proteomics. 2013;12(10):2981–91.
Yin X, Bern M, Xing Q, Ho J, Viner R, Mayr M. Glycoproteomic analysis of the secretome of human endothelial cells. Mol Cell Proteomics. 2013;12(4):956–78.
Wang GG, Wu YB, Zhou T, Guo YS, Zheng B, Wang J, Bi Y, Liu FJ, Zhou ZM, Guo XJ, et al. Mapping of the N-Linked glycoproteome of human spermatozoa. J Proteome Res. 2013;12(12):5750–9.
Ma C, Zhao X, Han H, Tong W, Zhang Q, Qin P, Chang C, Peng B, Ying W, Qian X. N-linked glycoproteome profiling of human serum using tandem enrichment and multiple fraction concatenation. Electrophoresis. 2013;34(16):2440–50.
Liu Y, Huettenhain R, Surinova S, Gillet LCJ, Mouritsen J, Brunner R, Navarro P, Aebersold R. Quantitative measurements of N-linked glycoproteins in human plasma by SWATH-MS. Proteomics. 2013;13(8):1247–56.
Li X, Jiang J, Zhao X, Wang J, Han H, Zhao Y, Peng B, Zhong R, Ying W, Qian X. N-glycoproteome analysis of the secretome of human metastatic hepatocellular carcinoma cell lines combining hydrazide chemistry, HILIC enrichment and mass spectrometry. PLoS ONE. 2013;8(12):e81921.
Kaji H, Ocho M, Togayachi A, Kuno A, Sogabe M, Ohkura T, Nozaki H, Angata T, Chiba Y, Ozaki H, et al. Glycoproteomic discovery of serological biomarker candidates for HCV/HBV infection-associated liver fibrosis and hepatocellular carcinoma. J Proteome Res. 2013;12(6):2630–40.
Boersema PJ, Geiger T, Wisniewski JR, Mann M. Quantification of the N-glycosylated secretome by super-SILAC during breast cancer progression and in human blood samples. Mol Cell Proteomics. 2013;12(1):158–71.
Zhu J, Wang F, Chen R, Cheng K, Xu B, Guo Z, Liang X, Ye M, Zou H. Centrifugation assisted microreactor enables facile integration of trypsin digestion, hydrophilic interaction chromatography enrichment, and on-column deglycosylation for rapid and sensitive N-glycoproteome analysis. Anal Chem. 2012;84(11):5146–53.
Yen T-Y, Macher BA, McDonald CA, Alleyne-Chin C, Timpe LC. Glycoprotein profiles of human breast cells demonstrate a clear clustering of normal/benign versus malignant cell lines and basal versus luminal cell lines. J Proteome Res. 2012;11(2):656–67.
Yeh C-H, Chen S-H, Li D-T, Lin H-P, Huang H-J, Chang C-I, Shih W-L, Chern C-L, Shi F-K, Hsu J-L. Magnetic bead-based hydrophilic interaction liquid chromatography for glycopeptide enrichments. J Chromatogr A. 2012;1224:70–8.
Whitmore TE, Peterson A, Holzman T, Eastham A, Amon L, McIntosh M, Ozinsky A, Nelson PS, Martin DB. Integrative analysis of N-linked human glycoproteomic data sets reveals PTPRF ectodomain as a novel plasma biomarker candidate for prostate cancer. J Proteome Res. 2012;11(5):2653–65.
Kim JY, Kim S-K, Kang D, Moon MH. Dual lectin-based size sorting strategy to enrich targeted N-glycopeptides by asymmetrical flow field-flow fractionation: profiling lung cancer biomarkers. Anal Chem. 2012;84(12):5343–50.
Danzer C, Eckhardt K, Schmidt A, Fankhauser N, Ribrioux S, Wollscheid B, Mueller L, Schiess R, Zuellig R, Lehmann R, et al. Comprehensive description of the N-glycoproteome of mouse pancreatic beta-cells and human islets. J Proteome Res. 2012;11(3):1598–608.
Nagano K, Shinkawa T, Kato K, Inomata N, Yabuki N, Haramura M. Distinct cell surface proteome profiling by biotin labeling and glycoprotein capturing. J Proteomics. 2011;74(10):1985–93.
Chen Y, Cao J, Yan G, Lu H, Yang P. Two-step protease digestion and glycopeptide capture approach for accurate glycosite identification and glycoprotein sequence coverage improvement. Talanta. 2011;85(1):70–5.
Bandhakavi S, Van Riper SK, Tawfik PN, Stone MD, Haddad T, Rhodus NL, Carlis JV, Griffin TJ. Hexapeptide libraries for enhanced protein PTM identification and relative abundance profiling in whole human saliva. J Proteome Res. 2011;10(3):1052–61.
Zeng X, Hood BL, Sun M, Conrads TP, Day RS, Weissfeld JL, Siegfried JM, Bigbee WL. Lung cancer serum biomarker discovery using glycoprotein capture and liquid chromatography mass spectrometry. J Proteome Res. 2010;9(12):6440–9.
Liu Z, Cao L, He Y, Qiao L, Xu C, Lu H, Yang P. Tandem O-18 stable isotope labeling for quantification of N-glycoproteome. J Proteome Res. 2010;9(1):227–36.
Lee H-J, Na K, Choi E-Y, Kim KS, Kim H, Paik Y-K. Simple method for quantitative analysis of N-linked glycoproteins in hepatocellular carcinoma specimens. J Proteome Res. 2010;9(1):308–18.
Zhang L, Xu Y, Yao H, Xie L, Yao J, Lu H, Yang P. Boronic acid functionalized core-satellite composite nanoparticles for advanced enrichment of glycopeptides and glycoproteins. Chem Eur J. 2009;15(39):10158–66.
McDonald CA, Yang JY, Marathe V, Yen T-Y, Macher BA. Combining results from lectin affinity chromatography and glycocapture approaches substantially improves the coverage of the glycoproteome. Mol Cell Proteomics. 2009;8(2):287–301.
Jia W, Lu Z, Fu Y, Wang H-P, Wang L-H, Chi H, Yuan Z-F, Zheng Z-B, Song L-N, Han H-H, et al. A strategy for precise and large scale identification of core fucosylated glycoproteins. Mol Cell Proteomics. 2009;8(5):913–23.
Goo YA, Lilu AY, Ryu S, Shaffer SA, Malmstrom L, Page L, Nguyen LT, Doneanu CE, Goodlett DR. Identification of secreted glycoproteins of human prostate and bladder stromal cells by comparative quantitative proteomics. Prostate. 2009;69(1):49–61.
Chen R, Jiang X, Sun D, Han G, Wang F, Ye M, Wang L, Zou H. Glycoproteomics analysis of human liver tissue by combination of multiple enzyme digestion and hydrazide chemistry. J Proteome Res. 2009;8(2):651–61.
Cao J, Shen C, Wang H, Shen H, Chen Y, Nie A, Yan G, Lu H, Liu Y, Yang P. Identification of N-glycosylation sites on secreted proteins of human hepatocellular carcinoma cells with a complementary proteomics approach. J Proteome Res. 2009;8(2):662–72.
Arcinas A, Yen T-Y, Kebebew E, Macher BA. Cell surface and secreted protein profiles of human thyroid cancer cell lines reveal distinct glycoprotein patterns. J Proteome Res. 2009;8(8):3958–68.
Picariello G, Ferranti P, Mamone G, Roepstorff P, Addeo F. Identification of N-linked glycoproteins in human milk by hydrophilic interaction liquid chromatography and mass spectrometry. Proteomics. 2008;8(18):3833–47.
Calvano CD, Zambonin CG, Jensen ON. Assessment of lectin and HILIC based enrichment protocols for characterization of serum glycoproteins by mass spectrometry. J Proteomics. 2008;71(3):304–17.
Lewandrowski U, Zahedi RP, Moebius J, Walter U, Sickmann A. Enhanced N-glycosylation site analysis of sialoglycopeptides by strong cation exchange prefractionation applied to platelet plasma membranes. Mol Cell Proteomics. 2007;6(11):1933–41.
Larsen MR, Jensen SS, Jakobsen LA, Heegaard NHH. Exploring the sialiome using titanium dioxide chromatography and mass spectrometry. Mol Cell Proteomics. 2007;6(10):1778–87.
Hanson SR, Hsu T-L, Weerapana E, Kishikawa K, Simon GM, Cravatt BF, Wong C-H. Tailored glycoproteomics and glycan site mapping using saccharide-selective bioorthogonal probes. J Am Chem Soc. 2007;129(23):7266.
Hagglund P, Matthiesen R, Elortza F, Hojrup P, Roepstorff P, Jensen ON, Bunkenborg J. An enzymatic deglycosylation scheme enabling identification of core fucosylated N-glycans and O-glycosylation site mapping of human plasma proteins. J Proteome Res. 2007;6(8):3021–31.
Ramachandran P, Boontheung P, Xie YM, Sondej M, Wong DT, Loo JA. Identification of N-linked glycoproteins in human saliva by glycoprotein capture and mass spectrometry. J Proteome Res. 2006;5(6):1493–503.
Qiu RQ, Regnier FE. Use of multidimensional lectin affinity chromatography in differential glycoproteomics. Anal Chem. 2005;77(9):2802–9.
Qiu RQ, Regnier FE. Comparative glycoproteomics of N-linked complex-type glycoforms containing sialic acid in human serum. Anal Chem. 2005;77(22):7225–31.
Zhang H, Liu AY, Loriaux P, Wollscheid B, Zhou Y, Watts JD, Aebersold R. Mass spectrometric detection of tissue proteins in plasma. Mol Cell Proteomics. 2007;6(1):64–71.
Funding
This work was supported by the National Natural Science Foundation of China (Grant Nos. 91853123, 81773180, and 21705127), and Natural Science Foundation of Shaanxi Province (Grant No: 2018JM7086074). HZ was supported by the National Institutes of Health (Grant Nos.: U01CA152813, U24CA210985, P01HL107153, and R21AI122382).
Author information
Authors and Affiliations
Contributions
SS collected and analyzed human glycosites with support from other co-authors; YH and MA wrote the in-house program for glycosite mapping and developed the web interface of the database; SS, PS, JC, WY, XJ, YT and HZ provided unpublished and newly generated datasets; ST provided suggestions on data analysis and manuscript preparation. SS and HZ prepared the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: Table S1.
The mass spectrometry-based human glycoprotein and glycosite database.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Sun, S., Hu, Y., Ao, M. et al. N-GlycositeAtlas: a database resource for mass spectrometry-based human N-linked glycoprotein and glycosylation site mapping. Clin Proteom 16, 35 (2019). https://doi.org/10.1186/s12014-019-9254-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12014-019-9254-0