
Abstract
In machinery fault diagnosis, labeled data are always difficult or even impossible to obtain. Transfer learning can leverage related fault diagnosis knowledge from fully labeled source domain to enhance the fault diagnosis performance in sparsely labeled or unlabeled target domain, which has been widely used for cross domain fault diagnosis. However, existing methods focus on either marginal distribution adaptation (MDA) or conditional distribution adaptation (CDA). In practice, marginal and conditional distributions discrepancies both have significant but different influences on the domain divergence. In this paper, a dynamic distribution adaptation based transfer network (DDATN) is proposed for cross domain bearing fault diagnosis. DDATN utilizes the proposed instance-weighted dynamic maximum mean discrepancy (IDMMD) for dynamic distribution adaptation (DDA), which can dynamically estimate the influences of marginal and conditional distribution and adapt target domain with source domain. The experimental evaluation on cross domain bearing fault diagnosis demonstrates that DDATN can outperformance the state-of-the-art cross domain fault diagnosis methods.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.1 Introduction
As a critical part of modern equipment, bearing always works under harsh conditions and suffers from time-varying load, which results in a significant risk of failure [1]. Bearing failure is the main cause of the machinery breakdowns, and sometimes can lead to huge economic loss and severe casualties [2, 3]. To ensure the operational reliability of equipment, researchers have conducted related studies for bearing fault diagnosis and proposed many effective methods [4,5,6,7,8].
Among these methods, deep learning based methods have shown its excellent performance in recent years, which can learn diagnosis knowledge from large amount of labeled data and reduce the dependence on expertise [9,10,11,12]. Although deep learning based methods are not expertise-dependent, they are heavily data-dependent. Unfortunately, collecting labeled machinery failure data are expensive or even impossible [13]. Under such circumstance, transfer learning [14] begins to attract researchers’ attention, which could transfer the related knowledge of fully labeled source domain to enhance the fault diagnosis performance in sparsely labeled or unlabeled target domain [15, 16].
Han et al. [17] introduced adversarial learning for feature distribution adaptation and transferred the source domain fault diagnosis model to the target domain. Guo et al. [18] utilized both Maximum mean discrepancy (MMD) and adversarial learning to adapt the feature distribution, which can transfer the fault diagnosis model to other machineries. Yang et al. [19] transferred fault diagnosis model from laboratory bearings to locomotive bearings with MMD-based multi-layer feature alignment and pseudo label learning. Wang et al. [20] utilized conditional maximum mean discrepancy (CMMD) to align feature distribution for cross-domain bearing fault diagnosis. Li et al. [21] proposed a novel cross domain fault diagnosis method, which take full advantage of the availability of target domain health labels.
These transfer learning methods have achieved great success in unsupervised domain adaptation, which can build fault diagnosis models for unlabeled target domain. However, these works only tend to adapt either marginal or conditional distributions (MDA or CDA) between source and target domain. In practice, both marginal and conditional distribution discrepancies have significant but different influences on domain divergence [22]. Recently, researchers have carried out some work in joint distribution adaptation (JDA) [23, 24], which simultaneously adapt marginal and conditional distribution. Although these works have achieved better performance, they allocate equal weights to marginal and conditional distributions discrepancies, which cannot quantify the different contributions of these distributions discrepancies.
In this paper, a dynamic distribution adaptation based transfer network (DDATN) is proposed for cross domain bearing fault diagnosis, which utilizes the proposed instance-weighted dynamic maximum mean discrepancy (IDMMD) for dynamic distribution adaptation (DDA). The main contributions of the paper are as follows.
-
(1)
Introduce DDA framework for cross domain bearing fault diagnosis, which can dynamically adjust the weights of marginal and conditional distributions discrepancies in domain adaptation.
-
(2)
Propose a novel dynamic distribution discrepancy metric (IDMMD) for unsupervised DDA. IDMMD uses a novel dynamic factor estimation method to dynamically estimate the contributions of MDA and CDA, which further considers the contribution of CDA of each class. In addition, it takes the confidence of target domain pseudo labels into account when calculates the conditional distribution discrepancy.
The remainder of the paper are organized as follows. The theoretical and technical bases are introduced in Section 2. Section 3 describes the detail of the proposed DDATN, which has been experimental evaluated in Section 4. Finally, the conclusion is drawn in Section 5.
2 Preliminaries
2.1 Dynamic Distribution Adaptation
Marginal and conditional distributions have different contributions on domain divergence and their contributions dynamically change during the transfer learning procedures. To improve transfer learning performance, DDA [22] is proposed as a general transfer learning framework, which considers the different and ever-changing contributions of marginal and conditional distributions on domain divergence. In DDA, the dynamic distribution discrepancy has the general form as
where Ps and Qs are marginal and conditional distributions of source domain Ωs, respectively; Pt and Qt are marginal and conditional distributions of source domain Ωt, respectively; D(Ps, Pt) is marginal distribution discrepancy, D(c)(Qs, Qt) is conditional distribution discrepancy for class c, C is the number of classes; μ is the dynamic weight which changes when the training goes on.
From Eq. (1), DDA degenerates to MDA and CDA when μ=0 and μ=1, respectively. Therefore, DDA can be regarded as a more general distribution adaptation framework.
2.2 Maximum Mean Discrepancy
Maximum mean discrepancy (MMD) [25] which is an effective distribution discrepancy metric widely used in transfer learning. Given datasets Xs and Xt sampled from distributions P(Xs) and P(Xt), the MMD between P(Xs) and P(Xt) is can be calculated as
where xis∈Xs, xjt∈Xt; ns and nt are the numbers of samples in Xs and Xt, respectively; \(\phi\) is a nonlinear mapping function in reproducing kernel Hilbert space (RKHS) \({\mathcal{H}}\).
From Eq. (2), the MMD is expressed as the distance in \({\mathcal{H}}\) between mean embeddings of Xs and Xt.
3 Dynamic Distribution Adaptation Based Transfer Network
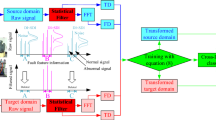
In this paper, DDA is introduced for improving the cross domain bearing fault diagnosis performance. The framework of DDATN is shown in Figure 1. It consists of DDA and supervised learning. The DDA part aims to constrain the feature extractor Gf to extract domain-invariant features by minimizing the proposed dynamic distribution discrepancy IDMMD. The supervised learning part realized by minimizing the supervised loss LC will guide the Gf to extract features which are discriminative for bearing health conditions, and train the effective classifier Gy which can accurately diagnosis bearing fault with these features.

Framework of DDATN
3.1 Supervised Learning
The DDATN is proposed for unsupervised domain adaptation, which target domain data are totally unlabeled. The supervised learning is realized using labeled source domain data, whose loss can be defined as
where \(J\left( { \cdot , \cdot } \right)\) is cross-entropy loss function, yis is the labeled of source domain sample xis.
3.2 Instances-weighted Dynamic Maximum Mean Discrepancy (IDMMD)
In unsupervised domain adaptation, target domain cannot provide label information. The final fault diagnosis process can just be conducted by the shared classifier Gy which trained by labeled source domain data. To prevent the interference of target domain specific features and domain divergence, it is important to extract the domain-invariant features.
In DDATN, a novel dynamic distribution discrepancy metric IDMMD is proposed for constraining Gf to extract domain-invariant features. IDMMD based on the DDA framework, which considers the ever-changing contributions of marginal and conditional distribution discrepancy on domain divergence. In addition, IDMMD further considers the different contributions of conditional distributions discrepancies of different class, and the confidence of target domain samples’ pseudo labels. The IDMMD between Ωs and Ωt is defined as:
where IDMMDM is the marginal distributions discrepancy, IDMMDC(c) is the conditional distributions discrepancy for class c, μ(c) is the dynamic factor for IDMMDC(c). They are defined as
where yi(c) is the real one-hot label of xis for class c, ŷj(c) is the prediction probabilities of xjt for class c.
The IDMMDM is the original form of MMD. For unsupervised domain adaptation, the labels of target domain samples which are necessary for calculating conditional distributions discrepancy is unavailable. Therefore, the predictions of Ωt are regarded as its soft labels. Considering the confidence of the soft labels, different weights are allocated to different target domain samples while calculating IDMMDC(c), which are their prediction probabilities for class c. Intuitively, MMD calculates the distance between the centers of two datasets in the embedded feature space. In target domain, the center of each class will tend to be closer to the samples which have higher prediction probabilities with the proposed weight allocation. Therefore, the negative effects of misclassification will be diminished.
To quantify the ever-changing contributions of marginal and conditional distributions, the dynamic factors for each class are calculated as Eq. (7). The class has larger IDMMDC value will be allocated larger dynamic factor, and the dynamic factor of marginal distribution will be calculated as Eq. (4). The proposed dynamic factor allocation method aims at guiding the DDA to focus on the main cause of domain shift.
3.3 General Procedure of DDATN
As mentioned above, DDATN contain two parts: supervised learning and DDA. Therefore, the total loss function of DDATN can be defined as
where λ is the trade-off factor.
The procedures of DDATN are presented in Figure 2 and summarized as follows.
-
(1)
Datasets generation. The source and target domain signals are segmented and standardized to form the source and target domain datasets (Ωs and Ωt), respectively.
-
(2)
Batch optimization. Source and target domain samples batches are generated from Ωs and Ωt, respectively. These batches are forward propagated to calculate the loss Ltotal. The loss is back-propagated to update the whole network.
-
(3)
Traverse datasets. Repeat step 2 to traverse the Ωs and Ωt.
-
(4)
Iterative optimization. Repeat step 3 for nepochs times.
-
(5)
Model evaluation. Evaluate the final fault diagnosis model with testing dataset.

Flowchart of DDATN
4 Experiment
4.1 Dataset Description
In this section, the CWRU [26] bearing dataset (CW) and the bearing dataset from our laboratory (OL) are utilized for verifying the effectiveness of the DDATN.
The test rig of CWRU bearing dataset is shown in Figure 3, which consists of a driven motor (left), a torque transducer and an encoder (middle), and a dynamometer (right). The test bearing is installed at the output side of the motor and support the motor shaft. This bearing test includes four health conditions with four fault diameters (0.18, 0.36, 0.53, 0.071 mm), and it is conducted on four different loads (0, 1, 2, 3 hp) with sampling rates of 12 kHz and 48 kHz. The details of the used part of data whose sampling rate is 12 kHz are listed in Table 1.

CWRU bearing test rig
The bearing test rig of our laboratory is shown in Figure 4. The test rig is driven by the motor, and the power transfer to the shaft which is supported by the test bearing with belt drive. The loading device exert radial force on the shaft to simulate the load of bearing. In this test, inner and outer race faults with size 0.5 mm are introduced to the test bearing by wire-electrode cutting. The acceleration signals are collected with sampling rate of 12 kHz. The details of this dataset are listed in Table 2.

Bearing test rig
For each health condition, 100 samples are segmented from the original vibration signals. Therefore, there are 300 and 1200 (300 for each speed) sampled from CW and OL bearing datasets, respectively. The length of the sample is set as 2048.
4.2 Comparison Setting
Thirty-six cross equipment tasks are conducted to verify the effectiveness of DDATN, which are listed in Table 3. For target domain dataset, half are used for training and the rest are served as testing dataset. In Table 3, S denotes source domain dataset, T denotes target domain training dataset, OL 500 (150) denotes the OL bearing data with speed of 500 r/min and the number of samples are 150 (50 samples for each health condition). CW0.18_1(300) denotes the CWRU data with 0.18 mm fault diameter and 1 hp load, and the number of samples are 300 (100 samples for each health condition).
The structures of features extractor Gf and classifier Gy are presented in Table 4, where Conv1D denotes 1D convolutional layer, MP1D denotes 1D max pooling layer, FC denotes fully connected layer. The Gf and Gy are trained by Adam optimizer (learning rate = 0.001, β1 = 0.9, β2 = 0.999). The tradeoff factor λ is set as 1.
The details of the comparison methods are as following. They use the same CNN structure as DDATN.
-
Method 1 (DDC): Deep domain confusion (DDC) [27] is a deep transfer learning method proposed by Tzeng et al., which utilizes MMD for single-layer feature alignment.
-
Method 2 (FTNN): Feature-based transfer neural network (FTNN) [19] is proposed by Yang et al, which applied MMD-based multi-layer feature alignment and pseudo label learning to transfer fault diagnosis knowledge from laboratory bearings to locomotive bearings.
-
Method 3 (DTN) [23]: Deep transfer network (DTN) is a cross-domain fault diagnosis method proposed by Han et al. It utilizes MMD and CMMD to evaluate the marginal and conditional distributions discrepancies, respectively. They are given equal weights for single-layer feature joint distribution adaptation.
-
Method 4 (IWC): IWC is derived from DDATN, which only takes the conditional part of IDMMD as the evaluation of the domain divergence.
-
Method 5 (IWCM): IWCM is also derived from DDATN, which allocates equal weights to the marginal and conditional parts of the IDMMD.
4.3 Result and Discussion
The experiment is conducted on a computer with two E5-2630 v3 CPUs, a Nvidia GeForce RTX 2080 Ti GPU (11 GB memory), and 64 GB memory. To avoid the influence of randomness, each task is repeated 10 times. The mean accuracies, standard deviations, training and testing time are listed in Table 5. The overall accuracy curves of these methods are presented in Figure 5. In addition, for each method, the average accuracy and standard deviation among all tasks are also presented in Avg.

Comparison result
The comparison shows that IWC, IWCM and DDATN have better performances than other methods. DDC has the worst accuracy in in almost all tasks except task 14. FTNN and DTN are both derived from DDC, whereas they have different improving directions. FTNN extends the single-layer adaptation to multi-layer adaptation and introduces pseudo label learning for further improvement, which has demonstrated to be effective in this case. DTN extends the MDA to JDA and achieves higher average accuracy than FTNN.
IWC achieves the average accuracy of 91.24% with standard deviation of 11.16%, which indicates that the proposed conditional distribution discrepancy metric is effective and robust. IWCM shows better performance than IWC in all tasks. The extension from CDA to JDA is proved valid while comparing IWCM with IWC. In addition, the IWCM can be regarded as the variation of DTN, which replaces the pseudo label strategy with instance-weighted strategy when calculating conditional distribution discrepancy. The comparison between IWCM and DTN demonstrates the effectiveness of the instance-weighted strategy.
Specifically, DDATN outperforms other methods in all tasks and achieves the highest average accuracy of 98.43% with lowest standard deviation, which indicates its superior effectiveness and robustness. In tasks 3, 7, 13, 21, 23, DDATN does not perform best, but it still gains a very close accuracy with the highest one. In tasks 4 (CW0.18_1 to OL1400) and 8 (CW0.18_2 to OL1400), the accuracies of DDATN are relatively low (67.07% for both tasks), which indicates that DDATN cannot gain very high accuracy in some transfer tasks. However, the accuracies of DDATN in these tasks still higher than other methods. In some difficult transfer tasks, DDATN may not be able to gain very high accuracy, but it can improve the performance to some degree.
In summary, the comparison indicates that the proposed conditional distribution discrepancy metric is effective and robust, whereas the extension from MDA, CDA and JDA to DDA can further improve the cross-domain fault diagnosis performance.
4.4 Feature Visualization
All the methods used in this experiment are feature-based transfer learning methods. To further evaluate the feature alignment performance of DDATN, t-distributed stochastic neighbor embedding (t-SNE) [28] is utilized for feature visualization. Tasks 33 and 36 are selected for visualization. For DDC, IWC, IWCM and DDATN, the feature visualizations are conducted on Flatten layer, whereas it is conducted on FC_2 layer for FTNN and DTN. In Figures 6 and 7, the legend consists of two parts: bearing health condition (outside the bracket) and the domain label (inside the bracket). For example, IR (T) denotes the inner race fault sample of the target domain. The marker of source and target domain samples are circle and triangle, respectively. The color represents the health condition, e.g., blue represent Normal (N), red represent Inner Race fault (IR), green represent Outer Race fault (OR).

Feature visualization of task 33 (CW0.53_3 to OL500)

Feature visualization of task 36 (CW0.53_3 to OL1400)
In task 33, the features of IWC, IWCM and DDATN show good fusion of source and target domains, whereas great discriminability with respect to bearing health conditions is also observed. For other methods, their features still have related good interclass discriminability, but the aggregation of source and target domains is poor. Especially, the source and target domain samples can be linearly separated with the feature of DDC.
In task 36, the features of IWC, IWCM and DDATN still show superior performance compared with the features of other methods, which still have good fusion of source and target domains. However, there has been a significant degeneration of the interclass separability of IWC and IWCM, whereas DDATN still hold excellent interclass separability. For DDC, FTNN and DTN, the interclass separability and intraclass aggregation are both poor, whereas the fusion of source and target domains are hard to be observed.
The feature visualization demonstrates that DDATN can effectively adapt the target domain features distributions to that of source domain. The target samples can be accurately aggregated to the corresponding source cluster, and the extracted features shows good fusion of domains and excellent discriminability of bearing health conditions.
5 Conclusions
This article proposes a novel unsupervised domain adaptation method termed DDATN. It introduces DDA for cross domain bearing intelligent fault diagnosis. The DDA is realized by the proposed IDMMD, which combines novel dynamic factor estimation method and instance-weighted conditional distribution discrepancy metric. The cross domain bearing fault diagnosis experiment is conducted to verify the effectiveness of DDATN. DDATN achieved better performance than other state-of-the-art cross domain fault diagnosis methods. The results demonstrate that the proposed conditional distribution discrepancy metric and the dynamic factor calculation method are effective and robust for DDA. Therefore, DDATN can effectively adapt the target domain features distributions to that of source domain for better cross domain bearing fault diagnosis.
Change history
10 August 2021
A Correction to this paper has been published: https://doi.org/10.1186/s10033-021-00592-1
References
R N Liu, B Y Yang, E Zio, et al. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mechanical Systems and Signal Processing, 2018, 108: 33-47.
Z Z Pan, Z Meng, Z J Chen, et al. A two-stage method based on extreme learning machine for predicting the remaining useful life of rolling-element bearings. Mechanical Systems and Signal Processing, 2020, 144: 106899.
L L Cui, X Wang, H Q Wang, et al. Remaining useful life prediction of rolling element bearings based on simulated performance degradation dictionary. Mechanism and Machine Theory, 2020, 153: 103967.
D Z Zhao, J Y Li, W D Cheng, et al. Generalized demodulation transform for bearing fault diagnosis under nonstationary conditions and gear noise interferences. Chinese Journal of Mechanical Engineering, 2019, 32: 7.
Y T Hu, S Q Zhang, A Q Jiang, et al. A new method of wind turbine bearing fault diagnosis based on multi-masking empirical mode decomposition and fuzzy c-means clustering. Chinese Journal of Mechanical Engineering, 2019, 32: 46.
G Q Jiang, P Xie, X Wang, et al. Intelligent fault diagnosis of rotary machinery based on unsupervised multiscale representation learning. Chinese Journal of Mechanical Engineering, 2017, 30(6): 1314-1324.
F B Zhang, J F Huang, F L Chu, et al. Mechanism and method for the full-scale quantitative diagnosis of ball bearings with an inner race fault. Journal of Sound and Vibration, 2020, 488: 115641.
J P Li, R Y Huang, G L He, et al. A deep adversarial transfer learning network for machinery emerging fault detection. IEEE Sensors Journal, 2020, 20(15): 8413-8422.
S Y Shao, W J Sun , R Q Yan, et al. A deep learning approach for fault diagnosis of induction motors in manufacturing. Chinese Journal of Mechanical Engineering, 2017, 30(6): 1347-1356.
H Q Wang, S Li, L Y Song, et al. An enhanced intelligent diagnosis method based on multi-sensor image fusion via improved deep learning network. IEEE Transactions on Instrumentation and Measurement, 2019, 69(6): 2648-2657.
R Y Huang, J P Li, S H Wang, et al. A robust weight-shared capsule network for intelligent machinery fault diagnosis. IEEE Transactions on Industrial Informatics, 2020, 16(10): 6466-6475.
Z Y Chen, K Gryllias, W H Li. Mechanical fault diagnosis using convolutional neural networks and extreme learning machine. Mechanical Systems and Signal Processing, 2019, 133: 106272.
J P Li, R Y Huang, G L He, et al. A two-stage transfer adversarial network for intelligent fault diagnosis of rotating machinery with multiple new faults. IEEE/ASME Transactions on Mechatronics, 2020, doi: https://doi.org/10.1109/TMECH.2020.3025615.
S J Pan, Q Yang. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2009, 22(10): 1345-1359.
R Zhao, R Q Yan, Z H Chen, et al. Deep learning and its applications to machine health monitoring. Mechanical Systems and Signal Processing, 2019, 115: 213-237.
R Q Yan, F Shen, C Sun, et al. Knowledge transfer for rotary machine fault diagnosis. IEEE Sensors Journal, 2019, 20(15): 8374-8393.
T Han, C Liu, W G Yang, et al. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowledge-Based Systems, 2019, 165: 474-487.
L Guo, Y G Lei, S B Xing, et al. Deep convolutional transfer learning network: A new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Transactions on Industrial Electronics, 2018, 66(9): 7316-7325.
B Yang, Y G Lei, F Jia, et al. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mechanical Systems and Signal Processing, 2019, 122: 692-706.
X Wang, C Q Shen, M Xia, et al. Multi-scale deep intra-class transfer learning for bearing fault diagnosis. Reliability Engineering & System Safety, 2020, 202: 107050.
X Li, X D Jia, W Zhang, et al. Intelligent cross-machine fault diagnosis approach with deep auto-encoder and domain adaptation. Neurocomputing, 2020, 383: 235-247.
J D Wang, Y Q Chen, W J Feng, et al. Transfer learning with dynamic distribution adaptation. ACM Transactions on Intelligent Systems and Technology, 2020, 11(1): 1-25.
T Han, C Liu, W G Yang, et al. Deep transfer network with joint distribution adaptation: A new intelligent fault diagnosis framework for industry application. ISA Transactions, 2020, 97: 269-281.
M Li, Z H Sun, W H He, et al. Rolling bearing fault diagnosis under variable working conditions based on joint distribution adaptation and SVM. 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, Jul. 19-24, 2020: 1-8.
A Gretton, K M Borgwardt, M J Rasch, et al. A kernel two-sample test. The Journal of Machine Learning Research, 2012, 13(1): 723-773.
X S Lou, K A Loparo. Bearing fault diagnosis based on wavelet transform and fuzzy inference. Mechanical Systems and Signal Processing, 2004, 18(5): 1077-1095.
E Tzeng, J Hoffman, N Zhang, et al. Deep domain confusion: Maximizing for domain invariance. arXiv preprint, http://arxiv.org/abs/1412.3474;2014.
L Maaten, G E Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 2008, 9: 2579-2605.
Acknowledgements
Not applicable.
Funding
Supported by National Natural Science Foundation of China (Grant Nos. 51875208, 51475170), National Key Research and Development Program of China (Grant No. 2018YFB1702400).
Author information
Authors and Affiliations
Contributions
WL was in charge of the whole trial; YL wrote the manuscript; RH, JL and ZC assisted with sampling and laboratory analyses. All authors read and approved the final manuscript.
Authors’ Information
Yixiao Liao, born in 1992, is currently a PhD candidate at School of Mechanical & Automotive Engineering, South China University of Technology, China, where he received his bachelor’s degree in 2015. His research interests include deep learning, transfer learning, and adversarial learning for fault diagnosis and prognostics.
Ruyi Huang, born in 1992, is currently a PhD candidate at School of Mechanical & Automotive Engineering, South China University of Technology, China. He received his B.S degree on mechanical engineering in Qingdao University, China, in 2014. His current research interests include deep learning and transfer learning methods for intelligent fault diagnostics and prognostics of rotating machinery.
Jipu Li, born in 1994, is currently a PhD candidate at School of Mechanical & Automotive Engineering, South China University of Technology, China. He received his B.S. and M.S. degree on mechanical engineering from Lanzhou University of Technology, China, in 2015 and 2018, respectively. His current research interests include deep learning and deep transfer learning methods for fault diagnosis and prognostics.
Zhuyun Chen, born in 1991, is currently a post doctor at School of Mechanical & Automotive Engineering, South China University of Technology, China. He received his B.S degree on mechanical design, manufacturing, and automation from Nanjing Agricultural University, China, in 2013. His current research interests include dynamic signal processing and deep learning methods for mechanical fault diagnosis and prognostics. His current research interests include deep learning and deep transfer learning methods for fault diagnosis and prognostics.
Weihua Li, born in 1973, is currently a professor at School of Mechanical & Automotive Engineering, South China University of Technology, China. His main research interests include nonlinear time series analysis, dynamic signal processing, autonomous driving, and machine learning methods for condition monitoring and health diagnosis of complex dynamical systems.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing financial interests.
Additional information
The original version of this article was revised: the affiliation has been updated.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liao, Y., Huang, R., Li, J. et al. Dynamic Distribution Adaptation Based Transfer Network for Cross Domain Bearing Fault Diagnosis. Chin. J. Mech. Eng. 34, 52 (2021). https://doi.org/10.1186/s10033-021-00566-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1186/s10033-021-00566-3