
Abstract
Background
Natural products are considered a rich source of new chemical structures that may lead to the therapeutic agents in all major disease areas. About 50% of the drugs introduced in the market in the last 20 years were natural products/derivatives or natural products mimics, which clearly shows the influence of natural products in drug discovery.
Results
In an effort to further support the research in this field, we have developed an integrative knowledge base on Marine Sponge Compounds Interactions (Dragon Exploration System on Marine Sponge Compounds Interactions - DESMSCI) as a web resource. This knowledge base provides information about the associations of the sponge compounds with different biological concepts such as human genes or proteins, diseases, as well as pathways, based on the literature information available in PubMed and information deposited in several other databases. As such, DESMSCI is aimed as a research support resource for problems on the utilization of marine sponge compounds. DESMSCI allows visualization of relationships between different chemical compounds and biological concepts through textual and tabular views, graphs and relational networks. In addition, DESMSCI has built in hypotheses discovery module that generates potentially new/interesting associations among different biomedical concepts. We also present a case study derived from the hypotheses generated by DESMSCI which provides a possible novel mode of action for variolins in Alzheimer’s disease.
Conclusion
DESMSCI is the first publicly available (http://www.cbrc.kaust.edu.sa/desmsci) comprehensive resource where users can explore information, compiled by text- and data-mining approaches, on biological and chemical data related to sponge compounds.
Similar content being viewed by others


Background
Natural products are chemical compounds that originate from living organisms and play a major role in the drug discovery and development process. The importance of natural products in drug discovery has been discussed in several reviews and reports [1–5]. About 200,000 natural compounds are currently known [6]. The chemical diversity of natural compounds, especially the diversity of scaffolds and the large number of chiral centers represent a basis for their use in drug therapy. About 50% of the drugs introduced in the market during the last 20 years are derived directly or indirectly from natural products [7]. A total of 1,184 new approved drugs have been identified covering all diseases/countries/sources in the years 01/1981-06/2006. Out of these, only 30% were synthetic in origin, which demonstrates the influence of natural products/derivatives/natural product mimics on drug discovery process [8].
The marine organisms adapted to unusual conditions of higher salt content, low or zero light, unusually low or high temperature and pressure, have offered a number of lead bioactive molecules with unique novel structures and distinct biological activities. Marine sponges have been considered a valuable source of bioactive molecules with different pharmacological activities. Sponges produce a wide array of secondary metabolites ranging from derivatives of amino acids and nucleosides to porphyrins, terpenoids macrolids, sterols, and others. Reports of isolation and identification of natural products from marine sponges are being published since early 1950’s. The isolation and identification of spongothymidine and spongouridine from the Caribbean sponge Tethya crypta[9–11], led to the discovery of close analogues, cytosine arabinoside or Ara-C, as a potent antileukemic agent and adenine arabinoside or Ara-A, an antiviral compound, as commercial drugs. The sponge-derived apoptosis-inducing lead compounds that have potential use in cancer treatment have been described in a recent review [12].
The investigation of several sponge compounds in clinical trials (Table 1) for various diseases proved the significance of sponges as an important source organism in the drug discovery [13]. Due to the importance of the sponges and their bioactive compounds, the voluminous research work in this area has generated a plethora of published scientific reports. A query in PubMed database (http://www.ncbi.nlm.nih.gov) using keywords “porifera OR sponge OR sponges” retrieved 16,023 abstracts (31 December, 2012).
The significance of sponge bioactive compounds in the drug discovery process and the lack of the public resource with the relevant information, motivated us to develop Dragon Exploration System on Marine Sponge Compounds Interactions (DESMSCI) as a public web-based knowledge base that integrates and allows exploration of information about sponge natural products and their potential biological and chemical associations. It is compiled from the published literature available in PubMed and complemented by the information from 25 other resources (Table 2). DESMSCI is the first publicly available, fully searchable, web-enabled knowledge base, where the information related to the sponge natural products can be explored at molecular levels, providing insights into related or affected human genes and proteins, diseases, and associated biological pathways, as well as potential mutual links among these entities. The information is generated by Dragon Exploration System (DES), a biomedical text mining and data mining system. DES has been previously used as the engine in creation of a number of topic-specific knowledge bases [15–18].
DESMSCI Resource
DESMSCI knowledge base is a resource that is compiled using as its primary engine, the KAUST-customized version of Dragon Exploration System (DES). Original DES is a proprietary text-mining and data-mining tool from OrionCell (http://www.orioncell.org). The titles and abstract of PubMed records are downloaded and indexed using several dictionaries. Each of the dictionaries consists of curated names and symbols and their variants customary for the specific types of entities (Table 3). For the data integration purposes the MRS [19] was deployed. Data was downloaded from 25 sources and indexed, producing more than 76,000,000 records (Table 2). The data are linked to annotated terms on-demand basis.
DESMSCI database was built on 31 December, 2012, with a document collection consisting of 16,023 abstracts downloaded from PubMed using “porifera OR sponge OR sponges” as a query. Annotation terms we used (Table 3) were from the following dictionaries: “Sponge compounds”, “Human genes and proteins”, “Mode of action”, “Pathways”, and “Disease concepts”. The dictionary of “Sponge compounds” contains manually curated 3,050 sponge compounds (including synonyms), compiled from the published literature. The dictionary of genes and proteins contains 269,908 variants of entities covering the names, symbols, aliases, previous names and previously used symbols of human genes and proteins. The DES engine performed annotation and created indexes of terms, terms pairs and clustering of PubMed articles. Finally, DESMSCI web interface was built by using DES customizable modules. Data integration to local MRS installation was implemented by using SOAP based MRS client [http://search.cpan.org/dist/MRS-Client/].
The details about the methods applied by DES, how to use the knowledge base and other relevant details are provided in the documentation (http://www.cbrc.kaust.edu.sa/desmsci/desmsci.pdf). The accuracy of the integrated data was evaluated earlier in Sagar et al. [18] in terms of precision (ability to identify the correct entities of a specific type in PubMed abstracts relative to all identified entities of that type) and recall (the ability to identify correct entities of a specific types present in the abstracts relative to all entities of that type present in the abstracts) and were found to be in the range of 81%–100% for different categories, with an average F-measure of 92.9%. In another report from our group, precison and recall were in ranged from 78%–99% and 87%–100% [15]. A brief comparison with PolySearch [20], a web based text-mining system, has also been reported [18]. However, these accuracy assessments can only be used as a guide and not as a claim of absolute accuracy of the system.
Generation of text-mined and data-mined reports
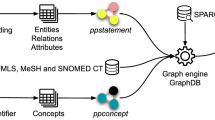
DESMSCI contains query engine for the processing of user’s queries. The system uses a set of abstracts (obtained as a result of querying PubMed) and mines these abstracts for the presence of terms listed in the curated dictionaries (Table 2). Therefore, the concepts present in the dictionaries are mapped to only that set of abstracts. These mapped concepts are further used to generate results that users see. It is important to understand the work-flow of the process and to know how the system works (Figure 1). The results of queries to DESMSCI are presented in the form of tables or networks which enable users to view the associations of a chemical compound of interest with other biological concepts, such as genes, proteins, diseases, pathways, etc. The links to other external databases are provided that enables users to explore the entity of interest in several external resources (to study structure, function etc.). DESMSCI also provides search options through the use of simple logical operators "AND", "OR" and "NOT" that further allow users an easier and direct access to each of the reports. Simple association networks can be generated for each of the identified concepts. A user-chosen concept represents a center node for such a network. This concept is connected to other concepts based on the co-occurrence metrics. Edge connects two concepts co-occurring in same abstracts and carries a weight representative of the number of those abstracts. Networks can be expanded or shrunk by selecting various weight thresholds and subsets of dictionaries. This is a convenient and efficient method to explore huge amounts of literature data in shorter time and to visualize the important associations among different terms in an easy to follow graphical representations. This functioning of the text-mining modules is based on similar concepts as used in Bajic et al. [21].

An overview of the text mining methodology.
Hypothesis generation
Hypothesis generation is one of the most useful features in DESMSCI. It allows users to infer potentially new/interesting relationships among different concepts. The module is based on Swanson’s ABC model [22]. It would be very difficult if not impossible to manually extract the associations between the concepts (which do not appear in the same document), to infer potentially new hypotheses, especially with the large amount of available concepts and literature. DESMSCI allows for the inspection of automatically generated hypotheses and their validity by retrieving the PubMed document(s) related to the concepts linked through the hypothesis. The initial hint that the association between the two concepts may be a candidate for a hypothesis appears in the case when there is no connection (co-occurrence in the same PubMed entry) of the concepts found in the analyzed set of PubMed entries. DESMSCI provides for the further inspection if the same two concepts co-occur in the same PubMed entry by querying the whole PubMed (22,000,000+ entries). If no PubMed document containing both of the terms is found, it suggests a possible new association between such concepts, a hypothesis for further exploration.
Case studies
Variolins for preventing neurodegeneration in Alzheimer’s disease
According to hypothesis generated by DESMSCI (Figure 2), the term ‘variolins’ from “Sponge compounds” dictionary is linked to the term ‘cyclin’ from “Human Genes and Proteins” dictionary through one abstract, while ‘cyclin’ is further linked to ‘Alzheimer’s disease’ (AD) from “Disease concepts” dictionary via two abstracts. On searching the whole PubMed using the “test” button for the co-occurence of terms ‘variolins’ and ‘Alzheimer’s disease’, no PubMed record with such two terms was available. Thus, it was not possible to establish a link between variolins and AD. We further explored the underlying biology to search for any indirect link between these two concepts and to check the validity of the hypothesis generated.

Hypotheses describing links between ‘Variolins’ and ‘Disease concepts’ through ‘Cyclin’ in human genes and protein dictionary. The interactions are based on co-occurrence of two entities in relevant PubMed literature.
Variolins are anti-tumor marine alkaloids isolated from a rare Antarctic sponge Kirkpatrickia Varialosa in 1994 [23]. Variolin-B (VAR-B) was most cytotoxic among the four compounds isolated from sponge and later derivatives of variolins were synthesized to enhance aqueous stability as well as their anti-cancer activities [24]. The studies on a derivative (dVAR-B) of VAR-B showed that variolins are CDK (cyclin-dependent kinases) inhibitors and induce apoptosis via p53 independent mechanism [25]. Cyclins, CDKs and cyclin-dependent kinase inhibitors (CKIs) are cell cycle regulatory proteins that control cell cycle transition from one phase to another (G1, S and G2). Cyclins and CDKs form heterodimers leading to progression or inhibition of cell cycle and these pairs are further inhibited or inactivated by small CKI peptides. The cell cycle deregulation leads to neurogeneration. In neurons, cell cycle normally does not progress beyond G1 phase checkpoint, but in AD, cell cycle progresses to G2 phase that leads the cell to death [26], and also drives the formation of neurofibrillary tangles and amyloid plaques [27–29]. This leads to neurodegeneration which is a characteristic phenotype linked to AD [30]. CDKs (CDK1, CDK2, and CDK5) have been associated with tau hyperphosphorylation, amyloid precursor protein processing, and apoptosis due to the cell cycle deregulation in AD [31]. Therefore, the agents that block cyclins or CDKs may further block neurodegeneration in AD patients [32]. Thus, we can propose a hypothesis that variolins, being inhibitors of CDKs, could block neurodegeneration in AD. Consequently, this potential activity of variolins could be tested for its effects in AD.
Furospongolide as an angiogenesis blocker
The term ‘furospongolide’ from “Sponge compounds” dictionary is linked to vascular endothelial growth factor ‘VEGF’ from “Human genes and proteins” dictionary through one PubMed record, while ‘VEGF’ is further linked to ‘angiogenesis’ from “Disease concepts” dictionary via 73 PubMed records. Thus, we have an indirect link between ‘furospongolide’ and ‘angiogenesis’ (Figure 3). Testing the co-occurrence of these two terms in the whole PubMed retrieved no results. The in-depth analysis of the mechanism of action of furospongolide reveals that this compound is an inhibitor of HIF-1 via a mitochondrial respiratory chain mechanism, where it exerts an inhibitory effect on mitochondrial respiratory chain complex I without any effect on other complexes. Furospongolide inhibits HIF-1 by suppressing tumor cell respiration via NADH-ubiquinone oxidoreductase (complex I)-mediated mitochondrial electron transfer [33]. The inhibition of HIF-1 further leads to suppression of expression of several genes that are activated by binding of HIF-1 on their promoters [34, 35]. Furospongolide also inhibits HIF-1 targeted vascular endothelial growth factor (VEGF). VEGF is a key stimulant of tumor angiogenesis (formation of new blood vessels that feeds cancerous cell growth) and suppression of VEGF normally blocks the angiogenesis in tumor cells [36]. Thus, the proposed hypothesis is that furospongolide could be used as a drug to block angiogenesis in tumors (Figure 4).

Potential hypothesis linking ‘Furospongolide’ to ‘Angiogenesis’ via ‘Vascular endothelial growth factor’. The interactions are based on co-occurrence of two entities in the relevant PubMed records.

Possible mechanisms of action of Furospongolide in a tumor cell.
Conclusions
DESMSCI is the first publicly available knowledge base where users can explore various types of information about sponge natural products at chemical, biological and molecular levels. Hypothesis generation is an important component of this system and it can help researchers to develop new ideas and test them by using the available literature and other information repositories. We hope that this knowledge base will serve as a useful complement to the existing public resources and for researchers involved in natural products’ research at any level across different disciplines.
Future directions
DESMSCI will be updated every six months and the information from all new studies published in that period will be incorporated. As the number of concepts grows with new incoming literature, the dictionaries will also be further curated and expanded. The improvement in the quality of dictionaries will certainly enhance the accuracy of the knowledge base. The comments obtained from the users will also help to improve the functionality of DESMSCI.
Abbreviations
- DES:
-
Dragon Exploration System
- DESMSCI:
-
Dragon Exploration System on Marine Sponge Compounds Interactions
- VAR-B:
-
Variolin-B
- CDK:
-
Cyclin-dependent kinases
- CKI:
-
Cyclin-dependent kinase inhibitors
- AD:
-
Alzheimer’s disease
- VEGF:
-
Vascular endothelial growth factor
- HIF:
-
Hypoxia inducing factor
References
Newman DJ, Cragg GM, Snader KM: The influence of natural products upon drug discovery. Nat Prod Rep. 2000, 17: 215-234. 10.1039/a902202c.
Newman DJ, Cragg GM, Snader KM: Natural products as sources of new drugs over the period 1981–2002. J Nat Prod. 2003, 66: 1022-1037. 10.1021/np030096l.
Chin YW, Balunas MJ, Chai HB, Kinghorn AD: Drug discovery from natural sources. AAPS J. 2006, 8: E239-E253.
Koehn FE, Carter GT: The evolving role of natural products in drug discovery. Nat Rev Drug Discov. 2005, 4: 206-220. 10.1038/nrd1657.
Paterson I, Anderson EA: Chemistry, The renaissance of natural products as drug candidates. Science. 2005, 310: 451-453. 10.1126/science.1116364.
Tulp M, Bohlin L: Rediscovery of known natural compounds: nuisance or goldmine?. Bioorg Med Chem. 2005, 13: 5274-5282. 10.1016/j.bmc.2005.05.067.
Vuorelaa P, Leinonenb M, Saikkuc P, Tammelaa P, Rauhad JP, Wennberge T, Vuorela H: Natural products in the process of finding new drug candidates. Curr Med Chem. 2004, 11: 1375-1389. 10.2174/0929867043365116.
Newman DJ, Cragg GM: Natural products as sources of new drugs over the last 25 years. J Nat Prod. 2007, 70: 461-477. 10.1021/np068054v.
Bergmann W, Burke DC: Contribution to the study of marine products. XXXIX. The nucleosides of sponges. III. 1. Spongothymidine and Spongouridine 2. J Org Chem. 1955, 20: 1501-1507. 10.1021/jo01128a007.
Bergmann W, Feeney RJ: The isolation of a new thymine pentoside from sponges1. J Am Chem Soc. 1950, 72: 2809-2810.
Bergmann W, Feeney RJ: Contributions to the study of marine products. XXXII. The nucleosides of sponges 1.1. J Org Chem. 1951, 16: 981-987. 10.1021/jo01146a023.
Essack M, Bajic VB, Archer JA: Recently confirmed apoptosis-inducing lead compounds isolated from marine sponge of potential relevance in cancer treatment. Mar Drugs. 2011, 9: 1580-1606. 10.3390/md9091580.
Newman DJ, Cragg GM: Marine natural products and related compounds in clinical and advanced preclinical trials. J Nat Prod. 2004, 67: 1216-1238. 10.1021/np040031y.
Cortes J, O'Shaughnessy J, Loesch D, Blum JL, Vahdat LT, Petrakova K, Chollet P, Manikas A, Diéras V, Delozier T: Eribulin monotherapy versus treatment of physician's choice in patients with metastatic breast cancer (EMBRACE): a phase 3 open-label randomised study. Lancet. 2011, 377: 914-923. 10.1016/S0140-6736(11)60070-6.
Dawe AS, Radovanovic A, Kaur M, Sagar S, Seshadri SV, Schaefer U, Kamau AA, Christoffels A, Bajic VB: DESTAF: A database of text-mined associations for reproductive toxins potentially affecting human fertility. Reprod Toxicol. 2011, 33: 99-105.
Kaur M, Radovanovic A, Essack M, Schaefer U, Maqungo M, Kibler T, Schmeier S, Christoffels A, Narasimhan K, Choolani M, Bajic VB: Database for exploration of functional context of genes implicated in ovarian cancer. Nucleic Acids Res. 2009, 37: D820-823. 10.1093/nar/gkn593.
Kwofie SK, Radovanovic A, Sundararajan VS, Maqungo M, Christoffels A, Bajic VB: Dragon exploratory system on hepatitis C virus (DESHCV). Infect Genet Evol. 2011, 11: 734-739. 10.1016/j.meegid.2010.12.006.
Sagar S, Kaur M, Dawe A, Seshadri SV, Christoffels A, Schaefer U, Radovanovic A, Bajic VB: DDESC: Dragon database for exploration of sodium channels in human. BMC Genomics. 2008, 9: 622-10.1186/1471-2164-9-622.
Hekkelman ML, Vriend G: MRS: a fast and compact retrieval system for biological data. Nucleic Acids Res. 2005, 33: W766-769. 10.1093/nar/gki422.
Cheng D, Knox C, Young N, Stothard P, Damaraju S, Wishart DS: PolySearch: a web-based text mining system for extracting relationships between human diseases, genes, mutations, drugs and metabolites. Nucleic Acids Res. 2008, 36: W399-405. 10.1093/nar/gkn296.
Bajic VB, Veronika M, Veladandi PS, Meka A, Heng MW, Rajaraman K, Pan H, Swarup S: Dragon Plant Biology Explorer. A text-mining tool for integrating associations between genetic and biochemical entities with genome annotation and biochemical terms lists. Plant Physiol. 2005, 138: 1914-1925. 10.1104/pp.105.060863.
Swanson DR: Fish oil, Raynaud's syndrome, and undiscovered public knowledge. Perspect Biol Med. 1986, 30: 7-18.
Perry NB, Ettouati L, Litaudon M, Blunt JW, Munro MHG, Parkin S, Hope H: Alkaloids from the antarctic sponge < i > Kirkpatrickia varialosa</i >. Part 1: Variolin b, a new antitumour and antiviral compound. Tetrahedron. 1994, 50: 3987-3992. 10.1016/S0040-4020(01)89673-3.
Molina P, Fresneda PM, Delgado S: Carbodiimide-mediated preparation of the tricyclic pyrido[3',2':4,5]pyrrolo[1,2-c]pyrimidine ring system and its application to the synthesis of the potent antitumoral marine alkaloid variolin B and analog. J Org Chem. 2003, 68: 489-499. 10.1021/jo026508x.
Simone M, Erba E, Damia G, Vikhanskaya F, Di Francesco AM, Riccardi R, Bailly C, Cuevas C, Fernandez Sousa-Faro JM, D'Incalci M: Variolin B and its derivate deoxy-variolin B: new marine natural compounds with cyclin-dependent kinase inhibitor activity. Eur J Cancer. 2005, 41: 2366-2377. 10.1016/j.ejca.2005.05.015.
Bonda DJ, Lee HP, Kudo W, Zhu X, Smith MA, Lee HG: Pathological implications of cell cycle re-entry in Alzheimer disease. Expert Rev Mol Med. 2010, 12: e19-
Suzuki T, Oishi M, Marshak DR, Czernik AJ, Nairn AC, Greengard P: Cell cycle-dependent regulation of the phosphorylation and metabolism of the Alzheimer amyloid precursor protein. EMBO J. 1994, 13: 1114-1122.
Baumann K, Mandelkow EM, Biernat J, Piwnica-Worms H, Mandelkow E: Abnormal Alzheimer-like phosphorylation of tau-protein by cyclin-dependent kinases cdk2 and cdk5. FEBS Lett. 1993, 336: 417-424. 10.1016/0014-5793(93)80849-P.
Nagy Z: The dysregulation of the cell cycle and the diagnosis of Alzheimer's disease. Biochim Biophys Acta. 2007, 1772: 402-408. 10.1016/j.bbadis.2006.11.001.
Zhu X, Lee HG, Perry G, Smith MA: Alzheimer disease, the two-hit hypothesis: an update. Biochim Biophys Acta. 2007, 1772: 494-502. 10.1016/j.bbadis.2006.10.014.
Neve RL, McPhie DL: The cell cycle as a therapeutic target for Alzheimer's disease. Pharmacol Ther. 2006, 111: 99-113. 10.1016/j.pharmthera.2005.09.005.
Savage MJ, Gingrich DE: Advances in the development of kinase inhibitor therapeutics for Alzheimer's disease. Drug Dev Res. 2009, 70: 125-144. 10.1002/ddr.20287.
Liu Y, Liu R, Mao SC, Morgan JB, Jekabsons MB, Zhou YD, Nagle DG: Molecular-targeted antitumor agents. 19. Furospongolide from a marine Lendenfeldia sp. sponge inhibits hypoxia-inducible factor-1 activation in breast tumor cells. J Nat Prod. 2008, 71: 1854-1860. 10.1021/np800342s.
Schodel J, Oikonomopoulos S, Ragoussis J, Pugh CW, Ratcliffe PJ, Mole DR: High-resolution genome-wide mapping of HIF-binding sites by ChIP-seq. Blood. 2011, 117: e207-217. 10.1182/blood-2010-10-314427.
Benita Y, Kikuchi H, Smith AD, Zhang MQ, Chung DC, Xavier RJ: An integrative genomics approach identifies Hypoxia Inducible Factor-1 (HIF-1)-target genes that form the core response to hypoxia. Nucleic Acids Res. 2009, 37: 4587-4602. 10.1093/nar/gkp425.
Pradeep CR, Sunila ES, Kuttan G: Expression of vascular endothelial growth factor (VEGF) and VEGF receptors in tumor angiogenesis and malignancies. Integr Cancer Ther. 2005, 4: 315-321. 10.1177/1534735405282557.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
VBB and AR are partners in the OrionCell Company whose product, Dragon Exploration System, has been used in the creation of DESMSCI. Other authors declare no conflict of interest.
Authors’ contribution
SS and MK conceptualized the study and analyzed the results. SS, MK, AR and VBB wrote the manuscript. AR and VBB developed the DES system. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Sagar, S., Kaur, M., Radovanovic, A. et al. Dragon exploration system on marine sponge compounds interactions. J Cheminform 5, 11 (2013). https://doi.org/10.1186/1758-2946-5-11
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1758-2946-5-11