
Abstract
In this paper, we consider the schedule-based network localization concept, which does not require synchronization among nodes and does not involve communication overhead. The concept makes use of a common transmission sequence, which enables each node to perform self-localization and to localize the entire network, based on noisy propagation-time measurements. We formulate the schedule-based localization problem as an estimation problem in a Bayesian framework. This provides robustness with respect to uncertainty in such system parameters as anchor locations and timing devices. Moreover, we derive a sequential approximate maximum a posteriori (AMAP) estimator. The estimator is fully decentralized and copes with varying noise levels. By studying the fundamental constraints given by the considered measurement model, we provide a system design methodology which enables a scalable solution. Finally, we evaluate the performance of the proposed AMAP estimator by numerical simulations emulating an impulse-radio ultra-wideband (IR-UWB) wireless network.
Similar content being viewed by others

1 Introduction
Localization of nodes in wireless networks is required in various applications[1]. In many scenarios, it is important for the nodes to know their own position and the position of other nodes in the network. As an example, the first responder situation considered in[2] benefits from self-localization and localization of other members by each member of the team.
Research done to address the above issues provides a variety of practical techniques. Extensive surveys of such techniques are provided in[3, 4]. In time-of-arrival (TOA)-based systems, in particular, measuring time delays with the knowledge of anchor positions provides localization. The common challenges in location estimation are measurement noise, availability of accurate timing models and anchor uncertainty. Authors in[5–8] have proposed estimation methods and algorithms which are robust to anchor and timing uncertainty.
Cooperation between the nodes is used in position estimation solutions, as described in, e.g.,[9–13]. Specifically, in[11], a distributed localization method is presented which is based on factor graphs and relies on cooperation and message-passing between nodes. The method enables accurate and robust localization in networks which are not fully connected and its performance is studied in a numerical simulation scenario based on experimental measurements. In[12], a cooperative localization algorithm is derived, which extends the non-parametric belief propagation (NBP) message-passing method first introduced in[13]. The method, which is based on approximating the junction-tree, improves performance with a reduced number of particles with respect to other NBP algorithms in the literature. The algorithm is validated by simulation and by applying it to experimental indoor ranging data acquired independently by[14].
The concept of schedule-based localization was introduced in[15–17]. It consists in the adoption of a common transmission sequence, known throughout the network. This concept achieves cooperative positioning in a decentralized manner even without communication overhead required for message passing[11–13]. Since the transmissions are event-driven, the schedule-based localization concept provides other advantages, such as asynchronous operation and high update rate. The concept can be realized with low complexity hardware[18–21]. The importance of removing communication overhead is particularly high in systems like the tactical locator system, TOR, described in[22]. In the TOR system, the inter-agent ranging device is an ‘intelligent sensor’, among others, with an internal update rate which is high compared with the 1-Hz pace of the overall system. Such a system is employed in polluted RF environments where communication resources have to be used for voice and video communication. Therefore, the use of schedule-based localization is motivated from a robust communication perspective, because it allows to replace all unnecessary communication/RF waveforms with predetermined internal sequences to ensure maximum robustness.
In this paper, we provide a general Bayesian framework for schedule-based localization which takes into account uncertainty in anchor location and in timing devices. The contribution of this paper is the extension of previous works in[15–17]. Here, we derive a new sequential estimator that, unlike previous works, is scalable to an arbitrary number of nodes and can be implemented online rather than processing large records of collected samples offline. The estimator also has an inherent robustness with respect to varying levels of measurement noise. In addition to this, we provide insight on the fundamental constraints of the considered problem. Based on this analysis, we develop a methodology to obtain a scalable solution, which achieves identifiability of individual nodes in a sequential manner. The methodology assists the formulation of the common transmission sequence.
Moreover, we evaluate the performance of the proposed estimator by numerical simulations in a case study consisting of a network of wireless nodes. For this scenario, numerous time-based localization technologies have been applied in the literature, including commercial communication infrastructure, such as wireless local area networks[23] and personal area networks[24, 25], as well as specialized ranging and positioning systems such as chirp spread spectrum[26]. In this context, the impulse-radio ultra-wideband (IR-UWB) technology, cf.[27], is widely studied in the literature and has been considered for the implementation of cooperative localization methods in[11, 28]. The sub-nanosecond time resolution property of IR-UWB, in fact, allows for centimeter-level measurement accuracy when applying time-of-arrival methods[29–31]. The characterization and modeling of the indoor UWB propagation channel are outside of the scope of the present paper and have been extensively studied in[32, 33]. The method proposed in this paper is based on several assumptions that are valid in an IR-UWB set-up, which is our main interest. Therefore, here, we present numerical simulation results obtained using a network of IR-UWB nodes, where we set the parameters of the network configuration and error based on previous experimental work[18–21]. We highlight however that the method is applicable for a plurality of other localization technologies, mutatis mutandis, yielding varying degrees of accuracy depending on the ability to resolve time signatures. Furthermore, we compare the performance of the proposed estimator to the fundamental limitations provided by a Cramér-Rao bound.
The remainder of this paper is organized as follows: Section 2 provides the problem formulation. Then, the sequential AMAP estimator is derived in section 3 along with a methodology for sequence construction. A numerical evaluation of the AMAP performance is provided in section 4. Finally, section 5 reports conclusions.
2 Problem formulation
We consider a fully connected wireless network of N - 1 transceiving nodes and an indefinite number of passive receiving nodes. The transceiving nodes transmit according to a given sequence, denoted , which is known across the network. When a node transmits a signal, it is received by the other nodes, then the next node in the sequence transmits, making the process event-driven. Delays at all nodes are assumed to be analog as mentioned in[16–18]. On the basis of observed time intervals between received signals at an arbitrary node n, the goal is to achieve both self-localization and localization of other transceiving nodes participating in the sequence,
, which is known across the network. When a node transmits a signal, it is received by the other nodes, then the next node in the sequence transmits, making the process event-driven. Delays at all nodes are assumed to be analog as mentioned in[16–18]. On the basis of observed time intervals between received signals at an arbitrary node n, the goal is to achieve both self-localization and localization of other transceiving nodes participating in the sequence, at node n without the need for clock synchronization or additional communication.
at node n without the need for clock synchronization or additional communication.
Moreover, for the purposes of this paper, the passive receiving nodes are defined as non-transmitting nodes, which therefore do not take part in the transmission sequence. In this context, the goal of such nodes is self-localization and localization of the transceiving nodes.
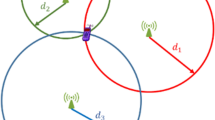
The signals are assumed to have a resolvable temporal signature that allows for timing events, e.g., pulses, symbol boundaries, etc. and the propagation velocity c is known. Let denote the position of node i, where d = 2 or 3, and denote the range between nodes i and j. Figure1 illustrates the ranges between three different nodes i,j, and n.

Example network setup involving the three nodes i , j , and n .
Now suppose node i initiates the transmission sequence and node j is the next node in the sequence. When it receives the signal, it transmits in return after a certain delay δ j . The signal events at all nodes are then illustrated in Figure2.

Timing diagram for the example network setup in Figure1. Here, the solid black dots denote transmission events, whereas the arrows denote reception events.
Using the relations to the ranges, the observed time interval at node n can be expressed as[17, 34, 35]
where w(i,j) is modeled as zero-mean Gaussian noise with unknown variance. The noise may not be stationary or may be range-dependent[36]. For any given variance, the additive Gaussian noise model results in the least favorable Cramér-Rao bound for parameter estimation. Under the model, therefore, any estimator that attains the lower bound can be considered min-max optimal[37].
If the next node in the sequence is denoted k, then the next observed time interval is
which uses one timing measurement from the previous observation y(i,j). Therefore, there is a correlation between all consecutive measurements. In addition to the random noise, the delay δ j is subject to uncertainty due to hardware imperfections and is modeled as, where μ δ is the nominal delay and the standard deviation σ δ is assumed to be known. To avoid signal collisions, it is necessary that the delays exceed ρmax/c, where ρmax is the maximum range between any pair of transceivers and can easily be ensured in any bounded localization scenario.
Prior knowledge about the node positions in the network is modeled as, where the nominal position μ i and error covariance matrix C i is set for all i[5–7]. With we can also model complete ignorance of a node position.
The goal is to formulate an estimator for any node n that performs self-localization as well as localization of an arbitrary number of transceiving nodes, by processing batches of observed time intervals sequentially.
3 Proposed estimator
Let denote the positions of all N - 1 transceiving nodes and the position of a passive receiver node N. Note that a necessary condition for x N to be identifiable is that localization is performed at node N since, clearly, other nodes cannot localize the passive receiver nodes. For notational simplicity, let denote the sought parameters, where δ contains the delays at the N-1 transceiving nodes and T = dN + N - 1.
We aim to formulate a sequential estimator that processes the observations in batches of B samples. The batches are indexed by b = 1,2,…, so that we can write
where
The nonlinear mapping is g(ϑ) = [ρ⊤(θ) δ⊤]⊤, where ρ(θ) contains the N(N - 1)/2 unique ranges ρi,j in a fixed order. Here, the integer matrix S
b
is determined by the transmission sequence for batch b, cf. (1). The noise follows and
for batch b, cf. (1). The noise follows and
is an unknown band-diagonal matrix, as consecutive samples are correlated.
In the next subsection, we derive an estimator which solves an approximate MAP problem using the observation model in (3). Subsequently, in subsection 3.3, we provide a schedule construction approach to achieve parameter identifiability. In this subsection, we will also discuss how the sequential formulation of the estimation problem allows for robustness to random link failures in the network.
3.1 Approximate sequential MAP estimator
Suppose that, at batch b, we have a prior estimate. We model the errors of as zero-mean Gaussian with error covariance matrix Pb-1. For b = 1, and. The maximum a posteriori estimator of ϑ and R b is given by the maximization of
where K is a constant. For tractability, we approximate. Using a noninformative prior, we have[38]. Then the approximated log-posterior is
where the maximizing noise variance is. Inserting the estimate back into (7), the approximate MAP estimator, denoted AMAP, can be written as
where
and γ b = B + 2.
After solving (8), the estimate can be used for the next batch b + 1. An approximate error covariance matrix P b can be derived using the information matrix. Then using the approximation, the information is additive[39]. Inserting the estimates, the latter term becomes, where and. Then we have the recursive update of the approximate error covariance matrix
3.2 Iterative solution
To solve (8) iteratively, we linearize g(ϑ) around an initial estimate, i.e.,, where and the increment is denoted for notational simplicity. Then the cost function (9) is approximated by
where and. The initial estimate is updated by the optimal increment.
To compute the optimal, we find a stationary point of using the gradient
where. Holding fixed we solve, and update resulting in a fixed-point iteration
Starting with, we converge to a stationary point. As a standard analysis of the convergence properties does not appear to be tractable, we provide a numerical evaluation of convergence in a practical scenario in section 4. The sequential estimator is summarized in Algorithm 1. Note that when B is small, the computational complexity of processing a batch is low as the computation of only involves the nodes participating in the batch b and therefore G ℓ is a sparse matrix. Further, the matrix inversion on Line 12 in Algorithm 1 scales with the size of the batch B rather than the total number of nodes N.
Algorithm 1 Sequential approximate MAP estimator

3.3 Sequence construction
To achieve identifiability, it is required that a subset of the transceiving nodes have highly informative priors. We denote such nodes as anchors. The other transceiving nodes are denoted as auxiliary nodes.
We propose a strategy to localize sequentially an arbitrary number of auxiliary nodes at node n. First, we exploit the anchors to enable self-localization of node n. Subsequently, we devote each batch to the localization of one auxiliary node at a time. To achieve it, we interleave the transmissions of the auxiliary node with those of the anchors.
As an example, assume that nodes 1, 2, and 3 are anchors and node N as a passive receiving node. Then, given the sequence, the proposed estimator operation is described in Figure3 for batch sizes B = 1 and B = 2, where the cost function V b (ϑ) in (9) is plotted. From the figures, it can be seen that, when B = 1, node N cannot perform self-localization unambiguously, based only on the hyperbolic constraint imposed by a single time-difference measurement of (1), cf. time-difference-of-arrival localization[40, 41]. However, when B = 2, node N can perform self-localization using a single batch due to the joint imposition of two hyperbolic constraintsa.

Cost function V b ( ϑ ) with respect to variables x N , using sequence. Anchor nodes are denoted by crosses and the passive receiving node N is denoted by an asterisk. (a) Batch size B = 1, batch index b = 1. (b) Batch size B = 2, batch index b = 1.
Now, let us assume that node 4 is an auxiliary node with a noninformative prior. Then, given the sequence, the cost function V b (ϑ) in (9) is illustrated in Figure4. For batch size B = 1, node N cannot localize auxiliary node 4 unambiguously, based only on the elliptical constraint imposed by a single time-difference measurement of (1), cf.[42]. However, as node 4 is interleaved with anchor nodes in the sequence and node N has self-localized, (1) produces elliptical and hyperbolic constraints alternatingly depending on whether node i is an anchor or auxiliary node, respectively. Hence for B = 3, node N can localize the auxiliary node due to the joint imposition of two elliptical and one hyperbolic constraint.

Cost function V b ( ϑ ) with respect to variables x 4 , using sequence. Here, anchor nodes are denoted by crosses, the auxiliary node 4 is denoted by a triangle, and the passive receiving node N is denoted by an asterisk. (a) Batch size B = 1, batch index b = 4. (b) Batch size B = 3, batch index b = 2.
The above example can easily be extended to N a anchor nodes. Let the anchor nodes be indexed as 1,2,…,N a and the auxiliary nodes as N a + 1,N a + 2,…. Then a generic sequence can be constructed on the form
where the k th auxiliary node is localized as long as it is interleaved by at least two anchor nodes in its corresponding batch. Thus, for a given batch size B, the sequence will be padded by interleaving anchor nodes to fulfill this constraint. Once all auxiliary nodes have been localized, the sequence is simply repeated which improves the estimates in the next round of measurements.
Finally, note that the sequential nature of the estimator allows for robustness to random link failures. In fact, in the event of a lost measurement, the corresponding batch is discarded and the estimator proceeds with the subsequent batches.
4 Numerical results
In this section, we provide a numerical performance evaluation of the estimator derived in section 3. As a case study, we consider the two-dimensional localization of nodes in an IR-UWB wireless sensor network[11, 18, 28]. In such a scenario, the timing information is obtained by measuring the propagation time of subnanosecond UWB pulses. The measurement noise is generated according to numerical values that are consistent with this scenario, i.e. subnanosecond- to nanosecond-order standard deviation, based on the experimental characterization in[18–21].
We analyze the localization of all nodes in the network performed at a passive receiver node. The analysis is applicable in a straightforward manner to any transceiver node which participates in the sequence.
Reproducible research: Code for reproducing results in this section is provided at the webpage of KTH Signal Processing, under ‘reproducible research’http://www.kth.se/en/ees/omskolan/organisation/avdelningar/sp/research/reproducibleresearch-1.433797.
4.1 Setup
We consider a fully connected network of N nodes consisting of N a = 4 anchors and N u = N - N a unknown position nodes. The latter includes one passive receiver node, which we denote as self-localizing node, and N u - 1 auxiliary nodes, i.e., transceiver nodes with noninformative prior which participate in the transmission sequence. We assume that the anchors are deployed according to nominal positions affected by a Gaussian error with a known covariance. The remaining nodes have noninformative priors, i.e.,, and the delay δ i has a nominal value of μ δ = 10-6 s with known error variance.
In the numerical simulations, we consider a total of M samples. Except where otherwise indicated, the noise is generated as, where
and q i = 1, ∀i.
The transmission sequence is constructed by interleaving the transmissions from the auxiliary nodes with those of anchors, according to the approach described in section 3.3. Furthermore, the batch length is set to B = 7, which enables localization using all N
a
= 4 anchors within the same batch.
is constructed by interleaving the transmissions from the auxiliary nodes with those of anchors, according to the approach described in section 3.3. Furthermore, the batch length is set to B = 7, which enables localization using all N
a
= 4 anchors within the same batch.
We initialize the AMAP estimator of Algorithm 1 with, where μ i s are the nominal anchor positions and is the centroid of the nominal anchor positions. Furthermore, we set the termination criterion ε = 10-2N u except where otherwise indicated.
The average RMSE of the position and delay estimates is given by
where ξ can be either θ u , in which case N ξ = N u , or δ, and N ξ = N - 1. Here is the MSE matrix of ξ. We estimated the RMSE from 103 Monte Carlo iterations.
4.2 Cramér-Rao bound
The mean square error when using the complete set of M samples,, is constrained by the Cramér-Rao bound[39]. Here we derive the bound when the noise covariance matrix equals σ2Q as of (14)[17]. Note, however, that the covariance structure Q is not given in the AMAP estimator; hence, the bound is optimistic and may not be attainable. Nevertheless, the bound provides a benchmark for evaluating the performance of the proposed estimator.
Let, then we treat the parameters with noninformative priors as deterministic quantities. Suppose be any estimator that is conditionally unbiased with respect to the deterministic parameters. Then its mean square error (MSE) matrix is constrained by the hybrid Cramér-Rao bound (HCRB)[43],, where.
Here, is the expected Fisher information matrix, where denotes the subset of parameters that are modeled as random quantities and
as given in[39]. As the expectation does not have a closed form solution, we evaluate it by the Monte Carlo simulation. If a subset of node positions, θ u , and the noise level, σ2, are treated as deterministic and unknown parameters, and the remaining parameters, θ a and δ, are random Gaussian, then the prior information matrix is given by
where is the covariance matrix of θ a . In the following, we use this division between deterministic and random parameters to study practical configurations where we lack prior knowledge on the position of a subset of nodes.
4.3 Error analysis
We analyze the node deployment shown in Figure5, where the nominal positions of the anchors are the corners of a 10 × 10 m2 area. The positions of the five auxiliary nodes and of the self-localizing nodes are randomly generated according to a uniform distribution within this area. Here, N
u
= 6 and we use a transmission sequence with.
with.

True node positions and error ellipses for all nodes estimated at self-localizing node indicated by an asterisk. The anchor nominal positions are indicated by crosses, the auxiliary nodes by triangles and the centroid of the nominal anchor positions by a square. The solid black ellipses indicate the HCRB and the dashed red ellipses indicate the MSE performance of the proposed AMAP estimator. Here, σ a = 3 cm and σ = 1 ns. The average RMSE of the position estimate is 7.3 cm and the HCRB is 6.2 cm.
The performance of the proposed estimator is compared with the HCRB by means of error ellipses. For visual clarity, the sizes of the ellipses have been scaled to correspond to 99% confidence ellipses of a zero-mean Gaussian distribution[16].
In Figure5, a highly informative prior on the anchor positions, of centimeter level, is used. Further, in Figure6, a relatively less informative prior is employed, i.e., a decimeter-level prior, to model uncertainty in the deployment of the anchors in a practical scenario. It can be seen that the proposed AMAP estimator is close to the HCRB in both cases. In both cases, the gap between the average RMSE and the HCRB is less than 2 cm. Thus, the estimator is inherently robust with respect to anchor position uncertainty.

True node positions and error ellipses for the same node deployment as that in Figure5. Here, σ a = 30 cm and σ = 1 ns. The average RMSE of the position estimate is 13.2 cm and the HCRB is 11.5 cm.
In Figures5 and6, the ellipses related to the self-localizing node are considerably smaller than those of the auxiliary nodes, and are of the same order of magnitude as the prior on the anchor positions. Further, the minor axes of the ellipses of the auxiliary nodes are approximately aligned along the direction connecting to the self-localizing node. This phenomenon, previously observed in[16], is due to the fact that the self-localizing node performs an independent measurement of its own distance to a generic node i every time node i transmits. Therefore, the self-localization performance is improved at every measurement, and the error variance of the position estimate for node i is reduced along the direction connecting it to the self-localizing node.
Moreover, from the magnified comparison for an auxiliary node in Figure7, it is possible to visually analyze the effect of the anchor position priors on the performance. In particular, the ratio between the major and minor axes of both the HCRB and MSE ellipses decreases when the the prior becomes less informative. This is due to the increased error in the estimate of the self-localizing node position, which causes poorer performance in the direction connecting every auxiliary node and the self-localizing node.

Error ellipses of a single auxiliary node in the scenario of Figure5, under two different values of priors of anchor positions. The solid black ellipse is the HCRB for σ a = 3 cm whereas the dashed red ellipse indicates the performance of the AMAP estimator in the same scenario. The larger dash-dotted black ellipse and the dotted red ellipse indicate the HCRB and the performance of the AMAP estimator, respectively, in the σ a = 30 cm case. Here, σ = 1 ns.
4.4 Error statistics
We now provide a statistical performance evaluation of the position and delay estimates as a function of the noise level, which is parameterized by σ. The simulation results, obtained using the same network configuration as that of Figure5, are shown in Figures8,9,10, and11, where different priors for the anchor positions and the delay are used.

Average RMSE of the position estimate vs noise level under different anchor position priors. Here, σ δ = 100 ps.

Average RMSE of the delay estimate vs noise level under different anchor position priors. Here, σ δ = 100 ps.

Average RMSE of the position estimate vs noise level under different delay priors. Here, σ a = 3 cm.

Average RMSE of the delay estimate vs noise level under different delay priors. Here, σ a = 3 cm.
Specifically, in Figures8 and9, the uncertainty of the anchor positions, parameterized by σ a , is varied from centimeter-level to decimeter-level. It is possible to notice that, in low noise conditions, the RMSE of the position estimation is of the same order of magnitude as the uncertainty of the anchor positions. Also, as shown in Figure9, the delay estimator achieves a performance close to the HCRB, and is robust with respect to parameter uncertainty in the anchor positions.
Moreover, the parameter σ δ , related to the uncertainty in the delay, is varied over two orders of magnitude in Figures10 and11. The results show that the proposed AMAP estimator is also robust with respect to uncertainty in the delay.
The behavior of the estimator with respect to the length of the transmission sequence is shown in Figure12. The different sequence lengths in the figure are obtained by repeating . Two values of the batch length B are reported. As expected, the performance improves as the length of the sequence increases. It can also be noticed that the performance of the proposed AMAP estimator improves as the batch length increases, given a fixed sequence length. This improvement establishes a performance trade-off since it comes at the expense of a reduced update rate of the system.
. Two values of the batch length B are reported. As expected, the performance improves as the length of the sequence increases. It can also be noticed that the performance of the proposed AMAP estimator improves as the batch length increases, given a fixed sequence length. This improvement establishes a performance trade-off since it comes at the expense of a reduced update rate of the system.

Average RMSE of the position estimate vs sequence length, in number of transmissions. Each point represents one repetition of a sequence.
4.5 Convergence evaluation
In order to analyze the convergence behavior of the proposed estimator, we evaluate simulation results obtained in the loose-prior scenario of Figure6, where we set the termination threshold ε = 10-5N
u
. Figure13a shows the behavior of the proposed estimator in a realization of the transmission sequence . It can be noticed that the error decreases at each batch within the sequence, as each auxiliary node is successfully localized.
. It can be noticed that the error decreases at each batch within the sequence, as each auxiliary node is successfully localized.

Error behavior of proposed AMAP estimator, in sample realization. With respect to (a) batch index b within sequence and (b) iteration index ℓ for b = 1. Here, the average error is defined as.
and (b) iteration index ℓ for b = 1. Here, the average error is defined as.
Furthermore, Figure13b shows a sample realization of the iteration at line 3 of Algorithm 1 during the first batch. The error decreases monotonically with the number of iterations ℓ.
A histogram of the number of iterations until convergence for the first batch is shown in Figure14a. The average number of iterations is 5.54. With ε = 10-2N u , which yields negligible RMSE performance loss, the histogram is shown in Figure14b and we observe an average number of iterations of 3.71. Finally, simulation results show that the inner loop of line 8 in Algorithm 1 exhibits a fast convergence behavior with an average of approximately 1.23 iterations.

Convergence behavior for two values of stopping criterion ε : (a) ε = 10-5N u . (b) ε = 10-2N u .
4.6 Large-scale setup
In order to provide insight on the scalability of the proposed estimator, we present an extensive scenario in Figure15. We consider N = 29 nodes, including N a = 4 anchors in the same nominal positions as the previous scenario of Figure5, and N u = 25 unknown position nodes. The positions of the latter are generated by adding noise uniformly distributed in a square region with an area of 1 m2 to a fixed 5 × 5 grid of evenly distributed nodes. A transmission sequence, with is used, and the batch size is set to B = 7. The figure shows that the proposed method is capable of localizing 24 auxiliary nodes with an accuracy of the same order of magnitude as the considered anchors position prior.

Large-scale setup on a 5 × 5 grid of unknown position nodes. Each of the nominal positions is randomized by adding a random variable which is uniformly distributed in a square region with an area of 1 m2. Here, σ = 1 ns, σ a = 3 cm, and σ δ = 100 ps. The average RMSE is 3.8 cm and the HCRB is 3.3 cm.
4.7 Noise outliers
To evaluate the effect of varying noise levels on the proposed AMAP estimator, we generate noise as, where Q is fixed and given by (14), but in which we set
Such a noise model is equivalent to randomly picking 10% of the observations and assigning a standard deviation σoutl = 10σ to the noise affecting those observations. As an illustrative example, one realization of w′ is shown in Figure16.

Realization of Gaussian noise having a standard deviation of σ = 1 ns, which is affected by 10% of outliers with σ outl = 10σ.
Figure17 shows the behavior of the AMAP estimator when the outlier measurement noise model is considered, whereas a magnification of the error ellipses for one auxiliary node is shown in Figure18. The results show that the proposed estimator is still operational and capable of providing accurate results even in the presence of relatively large outliers.

HCRB and MSE ellipses in the presence of outliers. The RMSE of the proposed AMAP estimator is 9.3 cm and the HCRB is 4.7 cm.

Error ellipses of single auxiliary node. Ellipses show effect of error outliers on HCRB and AMAP performance in scenario of Figure5. Solid black and dashed red ellipses and for the outliers case, dash-dotted black ellipse and dotted red ellipse.
5 Conclusion
We considered the schedule based network localization concept, proposed in[15–17]. This concept does away with the need for synchronization among nodes and does not involve communication overhead. It utilizes a common transmission sequence, which enables each node to perform joint self- and network localization, based on noisy propagation time measurements. The schedule-based localization problem has been posed as an estimation problem with probabilistic prior information. We derived a sequential estimator, AMAP, which is fully decentralized and copes with varying noise levels. The estimator is robust with respect to uncertainty in anchor locations and delay.
The measurement model we considered contains well-established constraints in the positioning literature, i.e., circular, hyperbolic, and elliptical constraints. The analysis of such constraints provides a schedule design methodology which enables a scalable solution. Specifically, the system can localize a large number of transceiving nodes with unknown positions by building transmission sequence batches in which such nodes are interleaved with anchor nodes. Numerical results in an IR-UWB network scenario show that AMAP provides localization accuracy close to a HCRB matched to the problem. Furthermore, AMAP is shown to be robust with respect to noise outliers.
Endnote
a If node N is participating in the sequence, it also gives rise to circular constraints which are analogous to those provided by the two-way TOA technique[29].
References
Patwari N, Ash J, Kyperountas S, Hero III A, Moses R, Correal N: Locating the nodes: cooperative localization in wireless sensor networks. IEEE Signal Process. Mag 2005, 22(4):54-69.
Rantakokko J, Rydell J, Stromback P, Handel P, Callmer J, Tornqvist D, Gustafsson F, Jobs M, Grudén M: Accurate and reliable soldier and first responder indoor positioning: multisensor systems and cooperative localization. Wireless Commun. IEEE 2011, 18(2):10-18.
Liu H, Darabi H, Banerjee P, Liu J: Survey of wireless indoor positioning techniques and systems. IEEE Trans. Syst., Man, Cybernet., Part C: Appl. Rev 2007, 37(6):1067-1080.
Mao G, Fidan B, Anderson B: Wireless sensor network localization techniques. Comput. Netw 2007, 51(10):2529-2553. 10.1016/j.comnet.2006.11.018
Lui K, Ma WK, So H, Chan F: Semi-definite programming algorithms for sensor network node localization with uncertainties in anchor positions and/or propagation speed. IEEE Trans. Signal Process 2009, 57(2):752-763.
Shirazi G, Shenouda M, Lampe L: Second order cone programming for sensor network localization with anchor position uncertainty. In Proceedings on Workshop on Positioning Navigation and Communication (WPNC). Dresden, Germany;7–8April 2011:51-55.
Zheng J, Wu YC: Joint time synchronization and localization of an unknown node in wireless sensor networks. IEEE Trans. Signal Process 2010, 58(3):1309-1320.
Gholami M, Gezici S, Strom E: TDOA based positioning in the presence of unknown clock skew. IEEE Trans. Commun 2013, 61(6):2522-2534.
Win M, Conti A, Mazuelas S, Shen Y, Gifford W, Dardari D, Chiani M: Network localization and navigation via cooperation. IEEE Commun. Mag 2011, 49(5):56-62.
Shen Y, Win M: Fundamental limits of wideband localization - Part I: A general framework. IEEE Trans. Inform. Theory 2010, 56(10):4956-4980.
Wymeersch H, Lien J, Win M: Cooperative localization in wireless networks. Proceedings of IEEE 2009, 97(2):427-450.
Savic V, Zazo S: Nonparametric generalized belief propagation based on pseudo-junction tree for cooperative localization in wireless networks. EURASIP J. Adv. Signal Process 2013, 2013: 16. 10.1186/1687-6180-2013-16
Ihler AT, Fisher III JW, Moses RL, Willsky AS: Nonparametric belief propagation for self-localization of sensor networks. Select. Areas Commun. IEEE J 2005, 23(4):809-819.
Patwari N, Hero III AO, Perkins M, Correal NS, O’dea RJ: Relative location estimation in wireless sensor networks. Signal Process., IEEE Trans 2003, 51(8):2137-2148. 10.1109/TSP.2003.814469
Dwivedi S, De Angelis A, Händel P: Scheduled UWB pulse transmissions for cooperative localization. In Proceedings of the IEEE Int. Conf. Ultra-Wideband (ICUWB). Syracuse, New York; 17-20 Sept. 2012:6-10.
Dwivedi S, Zachariah D, De Angelis A, Händel P: Cooperative decentralized localization using scheduled wireless transmissions. IEEE Commun. Lett 2013, 17(6):1240-1243.
Zachariah D, De Angelis A, Dwivedi S, Handel P: Self-localization of asynchronous wireless nodes with parameter uncertainties. IEEE Signal Process. Lett 2013, 20(6):551-554.
De Angelis A, Dwivedi S, Händel P: Characterization of a flexible UWB sensor for indoor localization. IEEE Trans. Instrum. Meas 2013, 62(5):905-913.
De Angelis A, Dwivedi S, Handel P: Development of a radio front end for a UWB ranging embedded test bed. In Proceedings of IEEE Int. Conf. Ultra-Wideband (ICUWB). Syracuse, New York; 17-20 Sept. 2012:31-35.
De Angelis A, Dwivedi S, Händel P: Development of a test bed for UWB radio indoor localization of first responders. In IEEE/ION Position Location and Navigation Symposium (PLANS). Grande Dunes, Myrtle Beach, SC; 23-26 April 2012:1106-1110.
De Angelis A, Nilsson J, Skog I, Händel P, Carbone P: Indoor positioning by ultrawide band radio aided inertial navigation. Metrol. Meas. Syst 2010, 17(3):12.
Nilsson JO, Zachariah D, Skog I, Händel P: Cooperative localization by dual foot-mounted inertial sensors and inter-agent ranging. EURASIP Journal on Advances in Signal Processing 2013, 2013: 164. 10.1186/1687-6180-2013-164
Ciurana M, Barcelo-F Arroyo, Izquierdo F: A ranging method with IEEE 802.11 data frames for indoor localization. In Proceedings on IEEE Wireless Comm. and Networking Conf. (WCNC). Hong Kong, China; 11-15 March 2007:2092-2096.
Santinelli G, Giglietti R, Moschitta A: Self-calibrating indoor positioning system based on ZigBee devices. In IEEE Instrumentation and Measurement Technology Conference, I2MTC. Singapore;5–7May 2009:1205-1210.
Pichler M, Schwarzer S, Stelzer A, Vossiek M: Multi-channel distance measurement with IEEE 802.15. 4 (ZigBee) devices. IEEE J. Select. Topics Signal Process 2009, 3(5):845-859.
Wang J, Gao Q, Yu Y, Wang H, Jin M: Toward robust indoor localization based on Bayesian filter using chirp-spread-spectrum ranging. Industrial Electron., IEEE Trans 2012, 59(3):1622-1629.
Win M, Scholtz R: Impulse radio: how it works. IEEE Commun. Lett 1998, 2(2):36-38.
Conti A, Guerra M, Dardari D, Decarli N, Win MZ: Network experimentation for cooperative localization. IEEE J. Select. Areas Commun 2012, 30(2):467-475.
Gezici S, Tian Z, Giannakis G, Kobayashi H, Molisch A, Poor H, Sahinoglu Z: Localization via ultra-wideband radios: a look at positioning aspects for future sensor networks. IEEE Signal Process. Mag 2005, 22(4):70-84.
Gezici S, Poor H: Position estimation via ultra-wide-band signals. Proceedings of IEEE 2009, 97(2):386-403.
Dardari D, Conti A, Ferner U, Giorgetti A, Win M: Ranging with ultrawide bandwidth signals in multipath environments. Proceedings of the IEEE 2009, 97(2):404-426.
Cassioli D, Win M, Molisch A: The ultra-wide bandwidth indoor channel: from statistical model to simulations. IEEE J. Select. Areas Commun 2002, 20(6):1247-1257. 10.1109/JSAC.2002.801228
Molisch A: Ultra-wide-band propagation channels. Proceedings of the IEEE 2009, 97(2):353-371.
Garcia G, Muppirisetty L, Wymeersch H: On the trade-off between accuracy and delay in UWB navigation. IEEE Commun. Lett 2013, 17: 39-42.
Gholami M, Gezici S, Ström E: Improved position estimation using hybrid tw-toa and tdoa in cooperative networks. IEEE Trans. Signal Process 2012, 60(7):3770-3785.
Larsson E: Cramér-Rao bound analysis of distributed positioning in sensor networks. IEEE Signal Process. Lett 2004, 11(3):334-337. 10.1109/LSP.2003.822899
Park S, Serpedin E, Qaraqe K: Gaussian assumption: the least favorable but the most useful [Lecture Notes]. IEEE Signal Process. Mag. 2013, 30(3):183-186.
Tiao GC, Zellner A: On the Bayesian estimation of multivariate regression. J R. Stat. Soc. Series B 1964, 26(2):277-285.
Kay SM: Fundamentals of Statistical Signal Processing: Estimation Theory. Englewood Cliffs: Prentice Hall; 1993.
Stoica P, Li J: Lecture notes: source localization from range-difference measurements. IEEE Signal Process. Mag 2006, 23(6):63-66.
Beck A, Stoica P, Li J: Exact and approximate solutions of source localization problems. IEEE Trans. Signal Process 2008, 56(5):1770-1778.
Zhou Y, Law CL, Guan YL, Chin F: Indoor elliptical localization based on asynchronous UWB range measurement. IEEE Trans. Instrumentation Meas 2011, 60: 248-257.
Van Trees H: Optimum Array Processing. New York: Wiley-Interscience; 2002.
Acknowledgements
Parts of this work have been funded by The Swedish Agency for Innovation Systems (VINNOVA).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zachariah, D., Angelis, A.D., Dwivedi, S. et al. Schedule-based sequential localization in asynchronous wireless networks. EURASIP J. Adv. Signal Process. 2014, 16 (2014). https://doi.org/10.1186/1687-6180-2014-16
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-6180-2014-16