
Abstract
In this article, we unveil a new property of linear interference cancellation detectors. Particularly, we focus in this study on the linear parallel interference cancellation (LPIC) detector and show that it exhibits a semi-convergence property. The roots of the semi-convergence behavior of the LPIC detector are clarified and the necessary conditions for its occurrence are determined. In addition, we show that the LPIC detector is in fact a regularization scheme and that the stage index and the weighting factor are the regularization parameters. Consequently, a stopping criterion based on the Morozov discrepancy rule is investigated and tested. Simulation results are presented to support our theoretical findings.
Similar content being viewed by others

Introduction
Multi access interference (MAI) is the main limiting factor for the capacity of the third generation cellular system employing Code Division Multiple Access (CDMA) scheme [1]. Similarly, MAI is also limiting the capacity of optical networks using optical CDMA (OCDMA) technology. Other types of interference exist in other systems and may reduce capacity if not mitigated properly, i.e., the inter-carrier interference (ICI) in orthogonal frequency division multiple access (OFDMA) and inter-antenna interference (IAI) in multi input multi output (MIMO) systems, just to name a few [1].
The effect of interference on wireless systems such as 4G and beyond is expected to be more severe due to the fact that the cells are expected to become more condensed (i.e.,femto-cells) and the dimension of wireless technologies keeps increasing from one generation to another. For example, large MIMO systems with tens to hundreds of transmit/receive antennas are proposed for 4G and beyond in order to achieve high spectral efficiencies [2, 3]. To combat these different types of interferences, multiuser detectors (MUDs) have been developed [1]. MUDs are used mainly to reduce the effect of interference in wireless/wired systems and hence to increase system capacity and throughput. A large variety of MUDs was developed in the literature [1]. Typically, they range from simple but poor performance MUDs to complex but excellent performance MUDs. The challenge is usually to devise MUDs that tradeoff between low complexity and good performance. Applications of MUDs are diverse and in fact they have been applied to various wireless/wired systems such as MIMO-OFDM, SFBC-OFDM, OCDMA, just to name a few [4–6].
The decorrelating and the linear minimum mean square error (LMMSE) detectors are effective MUDs to eliminate MAI. They are also important for nonlinear multistage detectors (decorrelating decision feedback detector, LMMSE decision feedback detector, etc.) because the latter usually take their initial estimates from the decorrelator/LMMSE detector. Hence, reducing the computational complexity of the decorrelator/LMMSE detector reduces the total computational complexity of these nonlinear multistage detectors.
One constraint that limits the implementation of the decorrelator/LMMSE detector is its computational complexity which is in the order of O(N3) [1], where N is the dimension of the system’s cross-correlation matrix. For example, N in mobile WIMAX (IEEE 802.16Wireless MAN standard) [7] can reach up to 2048,and therefore to implement the decorrelator or the LMMSE detector, an inversion of a 2048-by-2048 system’s cross-correlation matrix is needed which imposes real challenges for its practical implementation. To overcome this problem, linear interference cancellation (IC) structures such as the linear successive interference cancellation (LSIC) and the linear parallel interference cancellation (LPIC) detectors, are introduced to approximate the decorrelator/LMMSE detector but with much less computational complexity O(N2) [8–10].
An important phenomenon that was noticed in the literature of linear IC detectors is their semi-convergence behavior, i.e., the best Bit Error Rate (BER) is obtained prior to convergence. This phenomenon was noticed first in [11–15], and recently in [16], and it seems to be a common feature in most linear IC’s if some conditions are met. However, no study has been yet carried out to explain the roots of this phenomenon and to devise necessary conditions for its occurrence. This study is needed to facilitate the development of appropriate stopping rules for terminating the linear IC detector’s iterations at the best BER performance before noise enhancement gets pronounced due to convergence to the decorrelator detector’s solution.
The contributions of this study are twofold: first we explain the rationale behind the semi-convergence behavior of the LPIC detector and derive necessary conditions for the occurrence of such a behavior. Specifically, we show that the LPIC detector exhibits a spectral filtering property where it attenuates solution components pertaining to small singular values of the system matrix and retains solution components pertaining to large singular values of the system matrix. Second, we exploit this property for the purpose of avoiding noise enhancement by early stopping the LPIC detector’s iterations. Towards that objective, we investigate a stopping rule based on the Morozov discrepancy principle [17]. The effectiveness of the proposed stopping rule is examined and extensively tested through simulations.
This article is organized as follows: in Section 2, the system model used in this study is briefly described. In Section 3, the naïve solution is analyzed and the common approaches used to overcome the effect of noise enhancement are detailed. Section 4 describes the structure of the LPIC detector, presents the proof for its spectral filtering property, analyzes its semi-convergence behavior and finally details the Morozov discrepancy rule for early stopping of its iterations. Finally, Section 5 supports the theoretical findings by a number of simulations and Section 6 concludes the article with some recommendations and possible future extensions of this study.
Notations
Throughout this article, the following notations are used.
-
∘ denotes the Schur product.
-
⊗ denotes the Kronecker product.
-
denotes a 1-by-N vector of ones.
-
diag. denotes the diagonal operator.
-
denotes the transpose operator.
-
denotes the hermitian operator.
-
denotes the norm-2 operator.
-
|.| denotes the absolute value.
-
denotes the pseudo inverse.
-
lim. denotes the limit operator.
-
tr. denotes the trace operator.
-
max. denotes the maximum operator.
System model
A generic communication system is expressed in vector–matrix form as
where r is the received signal vector and is the system matrix and b is the vector of transmitted data symbols, and finally n is the vector of independently and identicallydistributed additive white Gaussian noise (AWGN) samples with zero-mean and variance ρ2.
The system matrix differs from one communication system to another, i.e., in a CDMA system it represents the matrix of the spreading codes whereas in a MIMO-OFDM system, the matrix is in fact a combination of two matrices: the matrix of channel coefficients and the matrix of orthogonal IFFT subcarriers.
For illustration purposes, we consider the LPIC detector in the context of mitigating the ICI due to the misalignment of the carrier frequencies and the Doppler shifts of different users in an OFDMA system. Specifically, we consider a scenario of an uplink OFDMA system where K users transmit simultaneously over a synchronous Rayleigh fading channel using Quadrature Phase Shift Keying. We consider in this study the effect of ICI due to the misalignment of the carrier frequencies and the Doppler shifts of different users and we neglect the effect of ICI due to inter-symbol interference and inter-block interference. This is justified by assuming a flat fading channel for each subcarrier of each user and assuming that the users transmit synchronously; therefore, it is reasonable to omit the cyclic prefix operation. This is illustrated in Figure 1.

Typical uplink OFDMA channel.
Two main subcarrier allocation schemes are commonly used in the literature. In the first one, known as the block subcarrier allocation scheme, each user is assigned a block of adjacent subcarriers whereas in the second one, known as interleaved subcarrier allocation scheme, the total subcarriers are uniformly interleaved across all users. In this study, and since we are dealing with ICI, we consider the interleaved subcarrier allocation scheme because it is well known that this scheme suffers more from ICI compared to the block subcarrier allocation scheme [18].
An OFDM symbol consisting of N u samples with sampling time T u where N u is the total number of data samples is transmitted using N orthogonal subcarriers. Without loss of generality, we assume that the total number of subcarriers of the IFFT matrix Ψ with elements , 1 ≤ n u ≤ N u and 1 ≤ n ≤ N is divided equally among all users; therefore, the total number of subcarriers per user is N k = N/K.
The received signal is expressed in vector–matrix form as
where isa combination of the IFFT and normalized carrier frequency offset (NCFO) matrices as follows: where Ε is the NCFO matrix. The NCFO matrix is obtained as where is given by and ɛ k is the NCFO of user k obtained as where is the subcarrier spacing. H(m) is the matrix of Rayleigh fading coefficients at the m thOFDM symbol where 1 < m < M, and it is given by where . Channel fading coefficients are obtained in practice through channel estimation. Without loss of generality, we assume throughout this article perfect knowledge of the channel state information. A is the power weighting matrix and it is used to scale the signals of different users with different powers to simulate near–far scenarios. It can be even used to weight the subcarriers of the same user differently if needed. This matrix is given by where.b(m) is the vector of transmitted symbols and it is formed as where . n(m) is an N-length vector of independently and identically distributed additive white Gaussian distributed samples with zero-mean and variance ρ2,and finally is a combination of the IFFT, the NCFO, the channel gain and power weighting matrices, respectively. This matrix can be decomposed as where is the n th column of the matrix . For simplicity and conciseness we drop the OFDM symbol index m in all subsequent equations.
The naïve solution and the noise enhancement effect
The naïve solution or the decorrelator detector (sometimes known also as the zero forcing detector) is one of the basic detectors that completely eliminates the interference and it can be formulated as a least square minimization problem:
The solution to this optimization problem is the decorrelator detector’s solution and it is given by
The naïve solution for ill-conditioned systems tends to amplify noise. To get more insight let us examine the singular value decomposition (SVD) of the decorrelator detector’s solution. Using the SVD, the system matrix can be factorized as
where U and V are both the N-by-N unitary matrices, respectively, and Σ is an N-by-N diagonal matrix with elements , 1 ≤ n ≤ N. The N columns of U represent the left singular vectors of and the N columns of V represent the right singular vectors of and the N diagonal entries of Σ represent the singular values of . We assume without loss of generality that the singular values are ordered from the largest to the smallest with indices ranging from 1 to N. Consequently, the decorrelator detector’s solution can be written in terms of the SVD of as
and its norm is given by
As it can be seen from the equation above, the norm of yDEC will not be too large as long as for large n. This is known as the discrete Picard condition [19].
Discrete picard condition
A meaningful solution is obtained if the Fourier coefficients decay to zero on average faster than the singular values .
It can be seen that if the discrete Picard condition is not satisfied, the decorrelator’s solution goes unbounded. This is specifically true for ill-conditioned system matrices that tend to have many small singular values near zero. Moreover, since the noise tends to reside in the space spanned by singular vectors corresponding to singular values that are equal or less than the noise level, then noise components corresponding to singular values not satisfying the discrete Picard condition are magnified and consequently result in the noise enhancement effect observed in the decorrelator detector’s solution.
A typical scenario where an OFDMA system matrix gets ill-conditioned is the case of large frequency offsets. To illustrate this, the singular values of a system matrix with 128 subcarriers and 64 users are plotted in Figure 2. It can be seen that due to large values of the NCFO, many singular values are close to zero and therefore, for these singular values, there is a large chance that the discrete Picard condition will not be satisfied. This is illustrated in Figure 2 where the singular values, Fourier coefficients, and their ratio are plotted.

Discrete Picard condition for N = 128, K = 64, SNR = 10, and NCFO randomly generated from a uniform distribution between –0.5 and 0.5.
By virtue of Figure 2, it is evident that the norm of the decorrelator’s solution gets amplified if the singular values are below a certain threshold [19] (<0.7 in our case). All singular values below this threshold do not satisfy the discrete Picard condition and therefore contribute to the noise enhancement effect.
To combat this phenomenon, several regularization techniques have been developed. The main idea behind regularization is to filter out solution components pertaining to small singular values, that is
where F is an N-by-N diagonal matrix with elements , known as filtering factors and should satisfy
Hence, these factors tend to discard small singular values of the system matrix and retain large ones.
Many regularization techniques exist in the literature such as the truncated SVD, Tikhonov, etc.; however, due to space limitation we refer the readers to [20] for more information on these techniques. In the next section, we show after a brief description of the LPIC detector that it can be used as a regularization scheme with two regularization parameters.
The LPICdetector
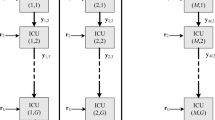
The LPIC detector is an effective scheme for the approximation of the decorrelator/LMMSE detector and it consists of IC units arranged in a multistage structure as shown in Figure 3. The internal structure of each IC unit is illustrated in Figure 4. The vector of decision variables of the pth stage, nth branch yp,n is first multiplied with ,added to the vectors of decision variables of the other branches, and then subtracted from the received signal r to obtain a cleaned version of the received signal where all users exhibit less mutual interference. The vector of decision variables of the (p + 1)th stage, nth branch yp+ 1,n is obtained by matched filtering the cleaned signal with , multiplying the result by a weighting factor ω and finally adding the result to the vector of decision variables of the previous stage, that is

Multi-stage structure of the LPIC detector.

The p th stage IC unit of the LPIC detector.
The weighting factor ω is used to ensure convergence of the LPIC detector. This process is repeated in a multistage structure as shown in Figure 3.
If all N branches of the LPIC detector are considered, then Equation (10) becomes
where is the residual error. Therefore, the vector of decision variables and residual error signal can be written in closed form as [21]
and
respectively, where and . This allows obtaining the average BER at the pth stage as [21]
where Q(.) denotes the Q- function. Moreover, the LPIC detector converges if
which translates to the following condition
where λ n is the nth eigenvalue of the system cross-correlation matrix .
Furthermore, it is easy to show that as the number of stages tends to infinity the LPIC detector converges to the decorrelator detector’s solution, that is
Therefore, if the LPIC detector converges, it converges to the decorrelator detector’s solution that suffers from noise enhancement.
Spectral filtering property of the LPIC detector
In the following, we show that the LPIC detector exhibits a spectral filtering property in the sense that it filters some components of the solution while it retains others. This important property can be exploited to develop a new regularization scheme. To get more insight, we use the SVD of the system matrix to analyze the convergence behavior of the LPIC detector. After some algebraic manipulations, Equation (12) can be written as (see the Appendix for the proof):
where F(p + 1,ω) is a K-by-K diagonal matrix with elements f n (p + 1,ω), known as filtering factors and are given by
These factors tend to attenuate small singular values of the matrix and retain large ones. Moreover, it is clear from Equation (19) that the amount of filtering introduced by the filtering matrix F(p + 1,ω) can be controlled through the stage index p and the weighting factor ω; thus, the stage index and the weighting factor act as regularization parameters for the LPIC detector. Figure 5 depicts the filtering factor f n (p + 1,ω) as a function of the singular value σ n for different values of ω and p.

Filter factors of the LPIC detector.
It is clear that as the number of stages p gets larger, more small singular values are included in the reconstruction of the solution yp+1. However, if small singular values that are below the noise level are involved and the discrete Picard condition is not satisfied, the noise enhancement effect starts dominating the solution. Therefore, the performance of the LPIC detector is expected to improve at early stages but after a certain number of stages the noise starts dominating the solution and deteriorating the performance of the LPIC detector. This explains the phenomenon pointed out in [11–16], which we call here the semi-convergence property of the LPIC detector.
Similar to the stage index p, the weighting factor ω also acts as a regularization factor where the performance of the LPIC detector is expected to improve for small values of ω, but after a certain threshold the noise enhancement effect starts taking place and the performance of the LPIC detector worsens. However, in addition to its regularization effect, the weighting factor ω controls the convergence speed of the LPIC detector, and therefore, the optimal value for this parameter has to balance between high convergence speed and low noise enhancement.
Nevertheless, in practice, the role of the weighting factor is confined to maximize the convergence speed and not to control the amount of noise enhancement introduced into the solution. Consequently, we also restrict the role of the weighting factor to maximize the convergence speed of the LPIC detector and use only the stage index p as a regularization parameter.
Semi-convergence property of the LPIC detector
As mentioned earlier, the LPIC detector exhibits a semi-convergence property where it reaches an average BER that is better than that achieved at final convergence. To get more insight, let us consider the error between yp+1 and the vector of the transmitted data symbols b, that is
It can be seen that the error between yp+1 (which is an estimate of the vector of the transmitted symbols b) and the vector of the transmitted symbols b consists of two components: the data error and the noise error. The data error is caused by using a modified inverse of the system cross-correlation matrix instead of the true inverse, whereas the noise error is caused by the magnified/filtered noise. Depending on the filtering matrix F(p + 1,ω), two cases can be distinguished:
-
If F(p + 1,ω) ⋍ I, the data error is small but the noise error is large due to the noise enhancement effect. The solution yp+1 is under-smoothed.
-
If F(p + 1,ω) ⋍ 0, the noise error is small but the data error is large, and as a result the solution is heavily damped. The solution yp+1 is over-smoothed.
So, a proper choice of the filtering matrix F(p + 1,ω)should balance between the data and noise errors. And since the amount of filtering introduced by the filtering matrix is proportional to the stage index p and the weighting factor ω, a proper stopping rule needs to be devised. The semi-convergence behavior of the LPIC detector with respect to the stage index p is illustrated in Figure 6 where the norm of the relative error defined by is plotted against the stage index p for several values of ω. Since , and , we vary ω asfor β = 2, 5, 7, 10, 14.

Norm of the relative error of the LPIC detector vis-à-vis the stage index p.
Similarly, the semi-convergence behavior of the LPIC detector with respect to the weighting factor ω is illustrated in Figure 7 where the norm of the relative error is plotted against the weighting factor ω for several values of p, that is p = 10, 20, 50, 100, and 500.

Norm of the relative error of the LPIC detector vis-à-vis the weighting factor ω.
It is clear from Figure 6 that with increasing values of the weighting factor ω, the convergence speed increases as well and the norm of the relative error exhibits a bowl-shaped curve with a sharp curvature towards the minimum. However, with decreasing values of the weighting factor, the convergence speed decreases and more importantly the bowl-shaped curve exhibits a flat minimum. Similar conclusion can be derived for Figure 7 for the stage index p.
As it will be shown in the simulation results, the average BER of the LPIC detector exhibits the same semi-convergence behavior as for the norm of the relative error in Figures 6 and 7.
Stopping rule for the LPIC detector
In this section, we investigate the possible use of the Morozov discrepancy rule [17, 22] to develop a proper criterion for stopping the iterations of the LPIC detector before the noise enhancement effect starts dominating the solution.
Morozov discrepancy rule for the LPIC detector
The accuracy of the regularized solution y p cannot exceed that of the received data vector r .
Therefore, if we have an LPIC detector in which the only regularization parameter is the stage index p (the weighting factor is set to one), the best regularized solution y p is obtained by iterating till the residual error is equal to the noise level, that is
However, due to the fact that the regularization parameter (stage index p) is an integer, the discrepancy principle defined by Equation (21) may not be satisfied exactly; therefore, we reformulate the definition to
This condition is illustrated in Figure 8 where at each stage the norm of the residual error ‖e p ‖2 of the LPIC detector is evaluated and compared to the noise level ρ. If the residual error becomes less than the noise level then the LPIC detector’s iterations should be stopped. The difference between the norm of the residual error and the noise level is termed the discrepancy error δ and it quantifies the amount of discrepancy resulting from using the modified Morozov discrepancy rule of Equation (22) instead of the exact one described by Equation (21).

Illustration of the Morozov discrepancy rule.
But since we do not have only one regularization parameter (i.e., the stage index p) but we have two instead, that is, p and ω, direct application of Equation (22) is not possible. Therefore, the Morozov discrepancy rule of Equation (22) is modified using the following theorem.
Theorem:
The optimal stage index for the linear PIC detector with regularization parameters p and ω using the Morozov discrepancy rule can be approximated as
Proof:
Two regularization schemes are equivalent if they have the same filter factors. Therefore, an LPIC scheme with only one regularization parameter p is equivalent to another LPIC scheme with two regularization parameters p′ and ω if their filter factors are equal, that is. As shown in[20, 23], the following approximation can be made
Thus, and consequently . Hence, Equation ( 23 ) is obtained.
Lemma
Proof:
Sinceis upper bounded byand, that is, hence Equation ( 24 ) is obtained.
Moreover, the discrepancy error δ due to not satisfying the Morozov discrepancy rule is given by
As shown in Figure 8, the discrepancy error δ is a function of two parameters: the initial residual error e 0 and the weighting factor ω. Obviously, in order to minimize the discrepancy error δ, one should better estimate the noise level ρ using the residual error e p , that is, making as close as possible to ρ. This can be realized by reducing the difference between the successive residual errors through employing smaller values of the weighting factor ω[15]. But, unfortunately this will lead to slower convergence of the LPIC detector. Therefore, the weighting factor should be adjusted to realize two conflicting goals: fast convergence and low discrepancy error. A possible solution is to use a stage-dependent weighting factor that exhibits large values in the initial stages where the main goal is improving the convergence speed and small values at later stages where the main goal is reducing the discrepancy error. This subject is outside the scope of this study and it is a research topic by itself and therefore will be treated independently in future study.
Simulation results
This section presents results illustrating the semi-convergence behavior of the linear PIC detector and showing the performance of the LPIC detector equipped with the Morozov discrepancy principle. Figures 9 and 10 depict the average BER of the LPIC detector plotted against the stage index p and the weighting factor ω at SNR = 10 and 20 dB, respectively, with N = 32, K = 4 and the frequency offsets of the four users set to (ɛ1 = –0.35, ɛ2 = 0.38, ɛ3 = 0.36, ɛ4 = –0.39). The following remarks can be stated.
-
It can be seen that the average BER for both cases (a) and (b) with increasing values of both/either p and/or ω starts initially large, decreases until it reaches the LMMSE detector’s performance and then increases again resulting in an L-shaped valley that illustrates clearly the semi-convergence behavior of the LPIC detector.
-
For varying p, the smaller the value of ω, the more the average BER curve becomes flat around its minimum, and hence the less the sensitivity of the solution to the accuracy of the stopping criterion employed. Note that this reduction in sensitivity is achieved at the expense of slow convergence speed. However, larger values of the weighting factor are needed for faster convergence, but unfortunately this requires a highly reliable stopping criterion to determine the stage index minimizing the average BER. Therefore, the challenge is to develop efficient stopping rules that can be used with high values of the weighting factor so that we can gain both high convergence speed and low average BER.

Semi-convergence behavior of linear LPIC detector with respect to the stage index p and the weighting factor ω for SNR = 10 dB.

Semi-convergence behavior of linear LPIC detector with respect to the stage index p and the weighting factor ω for SNR = 20 dB.
In the following, we evaluate the performance of the LPIC detector equipped with the Morozov discrepancy principle, that we call here Morozov-LPIC detector for brevity. First, we evaluate its convergence behavior by varying the stage index p and assessing its average BER performance for different values of .We set β to 2, 4, 5, 7, 10, SNR = 20 dB, N = 32 and K = 4 with frequency offsets of the four user set to (ɛ1 = –0.35, ɛ2 = 0.38, ɛ3 = 0.36, ɛ4 = –0.39). Figure 11 shows the results for the four detectors: Morozov-LPIC, LMMSE, Matched Filter (MF), and Decorrelator (DEC).

Convergence behavior of the Morozov-LPIC detector in AWGN channel.
As expected, it is clear that the average BER of the Morozov-LPIC detector gets better and closer to that of the LMMSE detector for smaller values of the weighting factor ω at the expense of slower convergence. Larger values of the weighting factor ω result in faster convergence but unfortunately, with a larger discrepancy error and bad average BER as well.
In Figure 12, the average stopping stage index for each Morozov-LPIC stage is obtained simply by summing up the stopping stage indices determined by the Morozov discrepancy rule for M OFDM symbols and then dividing by M. The average stopping stage index is plotted versus the number of Morozov-LPIC stages. Obviously, as the weighting factor gets smaller (i.e., β = 2) the residual error decreases slower as well and therefore needs more stages to satisfy the Morozov discrepancy rule and hence the average stopping stage index increases with decreasing values of ω as depicted in Figure 12.

Average stopping stage index versus the number of Morozov-LPIC stages in AWGN channel.
Figure 13 illustrates the average BER performance versus the SNR of the Morozov-LPIC and the other three detectors for different values of the weighting factor ω. The maximum number of stages P is fixed to 1000, we set β to 2, 4, 5, 7, 10, N to 32 and K to 4 with frequency offsets as follows (ɛ1 = –0.35, ɛ2 = 0.38, ɛ3 = 0.36, ɛ4 = –0.39).

Average BER versus SNR performance of the Morozov-LPIC detector in AWGN channel.
As expected, the Morozov-LPIC detector exhibits the best average BER performance for small values of the weighting factor (β = 2). This is clear at high SNRs where the radius of the circle determined by the noise level in Figure 8 gets smaller with increasing SNRs. Hence, for large values of the weighting factor the discrepancy error becomes large as well and consequently the average BER of the Morozov-LPIC detector becomes large too.
In Figure 14, the average stopping stage index for each SNR is obtained simply by summing up the stopping stage indices determined by the Morozov discrepancy rule for M OFDM symbols and then dividing by M. The averaged stopping stage index is plotted versus the SNR.

Average stopping stage index versus SNR of the Morozov-LPIC detector in AWGN channel.
Obviously, the average stopping stage index increases with the SNR because high SNRs translates into smaller noise-level circles as illustrated in Figure 8; therefore, the Morozov-LPIC detector needs more stages to satisfy the Morozov discrepancy rule.
Figure 15 depicts the condition number of the system cross-correlation matrix for both AWGN channel and Rayleigh fading channels. The different simulation parameters for the AWGN case are set to: N = 32 and K = 4 with frequency offsets set to (ɛ1 = –0.35,2 = 0.38, ɛ3 = 0.36, ɛ4 = –0.39). For the Rayleigh fading channel case, in addition to the aforementioned simulation parameters, we set the carrier frequency to 3.5 GHz and the speed of different users to, 80, 120, 90, and 100 km/h, respectively. The main difference between the two cases is that the system matrix in a Rayleigh fading channel is time variant and severely ill-conditioned due to the nature of the time-varying fading channel. This imposes some challenges to the performance of the Morozov-LPIC detector where due to the time varying nature of the condition number a fixed weighting factor that might be optimal for one ODFM symbol might result in bad performance for another symbol. In order to overcome this problem, a reasonably small value of the weighting factor should be selected to achieve good performance at the expense of slow convergence rate.

Condition number of the system cross-correlation matrix in case of AWGN and Rayleigh fading channels.
The average BER performance versus the SNR for a Rayleigh fading channel of the Morozov-LPIC detector for different values of the weighting factor ω is plotted in Figure 16. The figure also shows the performance of the DEC, LMMSE, and MF. The maximum number of stages P is fixed to 1000. The remaining parameters are set as follows: β to 2, 4, 6, 12, N to 32, and K to 4 with frequency offsets of the four users are set to (ɛ1 = –0.35,2 = 0.38, ɛ3 = 0.36, ɛ4 = –0.39). The carrier frequency is set to 3.5 GHz and the speed of different users is set to, 80, 120, 90, and 100 km/h, respectively. Similar to the AWGN channel, using relatively small values of the weighting factor enhances the performance of the Morozov-LPIC detector, however, this results in a very slow convergence rate. For this case, the best performance is achieved for β = 2, and it is expected that for smaller values of β the performance of the Morozov-LPIC detector would improve further.

Average BER versus SNR performance of the Morozov-LPIC detector in Rayleigh fading channel.
In Figure 17, the average stopping stage index is plotted versus the SNR. Similar to Figure 14, the average stopping stage index increases with the SNR and the rate of increase becomes larger for decreasing values of β.

Average stopping stage index versus SNR of the Morozov-LPIC detector in Rayleigh fading channel.
Conclusion
In this study,we unveiled a new property of linear IC detectors. Specifically, we proved that the LPIC detector exhibits a semi-convergence behavior if the discrete Picard condition is not satisfied. Moreover, we showed that this phenomenon can be circumvented if the iterations are stopped before final convergence using a suitable stopping rule. Consequently, we investigated the possible use of the Morozov discrepancy principle to derive a proper stopping condition for the LPIC iterations. Performance analyzes of the LPIC detector using the Morozov discrepancy principle showed that the value of the weighting factor should tradeoff between two conflicting goals: convergence speed and small discrepancy error. Simulation results coincide well with our theoretical findings. Future study includes extending these results to other linear IC detectors such as the SIC, hybrid SIC/PIC, etc., use of stage-dependent weighting factors to compromise between convergence speed and small discrepancy error and finally exploring other stopping rules.
Appendix
Recall that the vector of decision variables is given by
By expanding the summation in (26) we obtain
Multiplying both terms by and adding the identity matrix I, we obtain:
Therefore, the summation in (27) can be expressed as
Hence,
Using the SVD of H defined in (4), Equation (30) can be expressed as
which finally can be written as
where .
This concludes the proof.
References
Honig ML: Advances in Multiuser Detection Wiley Series in Telecommunications and Signal Processing. 2009. ISBN: 9780470473801
Vardhan VK, Mohammed SK, Chockalingam A, Rajan BS: A low-complexity detector for large MIMO systems and multicarrier CDMA systems. IEEE J. Sel. Areas Commun. 2008, 26(3):473-485.
Mohammed SK, Zaki A, Chockalingam A, Rajan BS: High-rate space-time coded large-MIMO systems: low-complexity detection and channel estimation. IEEE J. Sel. Topics Signal Process. 2009, 3(6):958-974.
Hou SW, Ko CC: Intercarrier interference suppression for OFDMA uplink in time- and frequency-selective fading channels. IEEE Trans. Veh. Technol. 2009, 58(6):2741-2754.
Sreedhar D, Chockalingam A: Interference mitigation in cooperative SFBC-OFDM. EURASIP J. Adv. Signal Process 2008., 11: Article ID 125735, 11
Mrabet H, Dayoub I, Attia R, Haxha S: Performance improving of OCDMA system using 2-D optical codes with optical SIC receiver. J. Lightw. Technol. 2009, 27(21):4744-4753.
IEEE Standard for Local and Metropolitan area networks Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems Amendment 2: Physical and Medium Access Control Layers for Combined Fixed and Mobile Operation in Licensed Bands. The Institute of Electrical and Electronics Engineering, Inc 2005. Std. IEEE 802.16E-2005
Buehrer RM, Correal-Mendoza NS, Woerner BD: A simulation comparison of multi-user receivers for cellular CDMA. IEEE Trans. Veh. Technol. 2000, 49(4):1065-1085. 10.1109/25.875213
Molisch AF, Toeltsch M, Vermani S: Iterative methods for cancellation of intercarrier interference in OFDM systems. IEEE Trans. Veh. Technol. 2007, 56(4):2158-2167.
Ancora A, Montalbano G, Slock DTM: Preconditioned iterative inter-carrier interference cancellation for OFDM reception in rapidly varying channels. in Proc. ICASSP 2010, 3066-3069.
Juntti MJ, Aazhang B, Lilleberg JO: Iterative implementation of linear multiuser detection for dynamic asynchronous CDMA systems. IEEE Trans. Commun. 1998, 46: 503-508. 10.1109/26.664306
Johansson AL, Rasmussen LK: in Proceedings of the IEEE Int. Symp. Spread Spectrum Techniques and Appl, Sun City, South Africa 1998, 1: 121-126.
Sun S, Rasmussen LK, Lim TJ, Sugimoto H: A matrix-algebraic approach to linear hybrid interference canceller in CDMA. Proceedings of the IEEE Int. Conf. Univ. Personal Commun. Florence, Italy 1998, 2: 1319-1323.
Rasmussen LK, Lim TJ, Johansson AL: A matrix-algebraic approach to successive interference cancellation in CDMA. IEEE Trans. Commun. 2000, 48(1):145-151. 10.1109/26.818882
Rasmussen LK, Oppermann IJ: Ping-pong effects in linear parallel interference cancellation for CDMA. IEEE Trans. Wirel. Commun. 2003, 2: 357-363. 10.1109/TWC.2003.809122
Bentrcia A, Zerguine A: A new approach to the analysis of the linear group-wise parallel interference cancellation detector. inPIMRC 2008, Canne, France; 2008:1-5.
Samarskii AA, Vabishchevich PN: Numerical Methods for Solving Inverse Problems of Mathematical Physics. Walter de Gruyter, Berlin; 2007. ISBN 978-3-11-019666-5
Hashemizadeh SK, Saeedi-Sourck H, Omidi MJ: Sensitivity analysis of interleaved OFDMA system uplink to carrier frequency offset. in IEEE 22nd International Symposium on Personal Indoor and Mobile Radio Communications 2011, 1631-1635.
ThambanNair M: Linear Operator Equations. Approximation and Regularization World Scientific Publishing Company, Singapore; 2009. ISBN 9812835644
Hansen PC: Rank-Deficient and Discrete Ill-Posed Problems. Numerical Aspects of Linear Inversion(Society for Industrial and Applied Mathematics, Philadelphia, PA; 1998. ISBN: 0-89871-403-6
Bentrcia A, Zerguine A: A new linear group-wise parallel interference cancellation detector. Wirel. Personal Commun. 2009, 49(1):23-34. 10.1007/s11277-008-9553-7
Bertero M, Boccacci P: Introduction to Inverse Problems in Imaging. IOP Publishing Ltd, Bristol; 1998.
Hamarik U, Palm R: On rules for stopping the conjugate gradient type methods in ill-posed problems. Math. Model. Anal. 2007, 12(1):61-70. 10.3846/1392-6292.2007.12.61-70
Acknowledgment
The authors acknowledge the support of KSU. The study was supported by the KACST under project number ARP 29-55.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Bentrcia, A., Alshebeili, S.A. Regularization property of linear interference cancellation detectors. EURASIP J. Adv. Signal Process. 2012, 145 (2012). https://doi.org/10.1186/1687-6180-2012-145
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-6180-2012-145